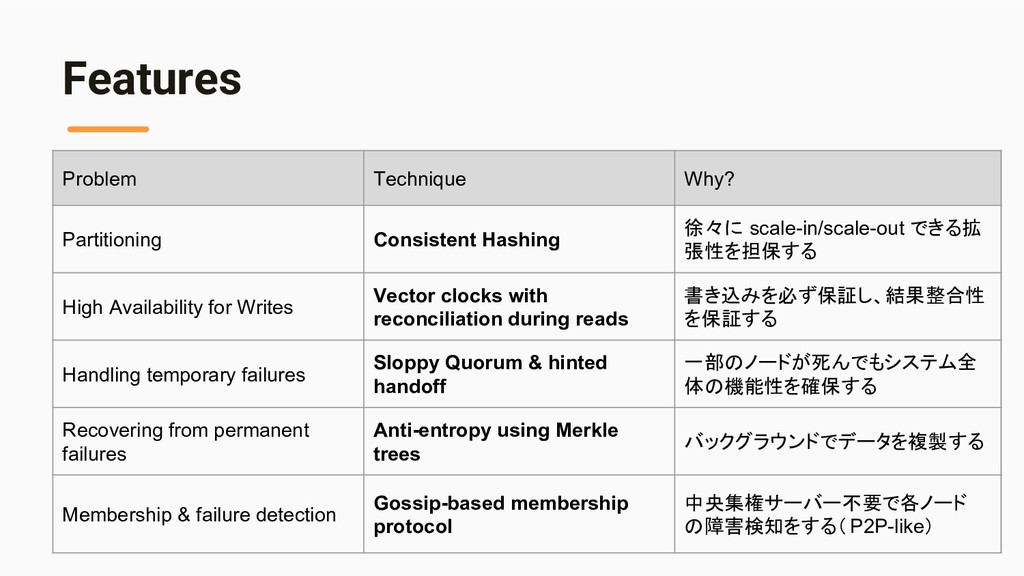
replicas faster and and to minimize the amount of transferred data, Dynamo uses Merkle tree” - [Pros] Hash 値だけ検証すればいいので、レプリカ間の整合性チェック がデータ全体を比較するよりも速い - [Pros] Hash 値だけを転送すればいいので、ネットワーク転送効率も高 い
maintains a separate Merkle tree for each key range 2. Two nodes exchange the root of the Merkle tree (corresponding to the key ranges that they host in common) 3. Traverse the tree and find if there are any differences 4. If any differences found, start replication
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
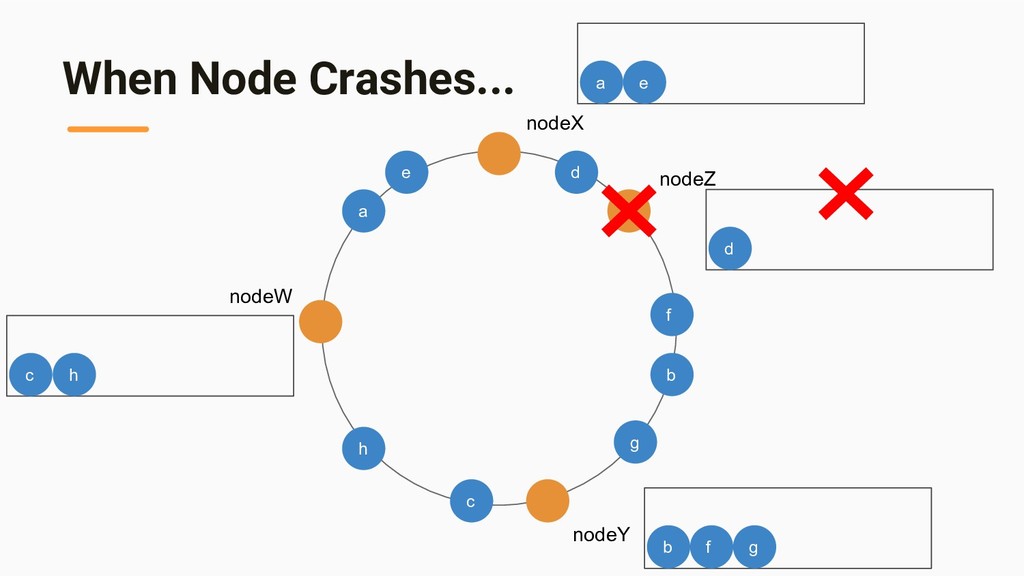{kind=link}
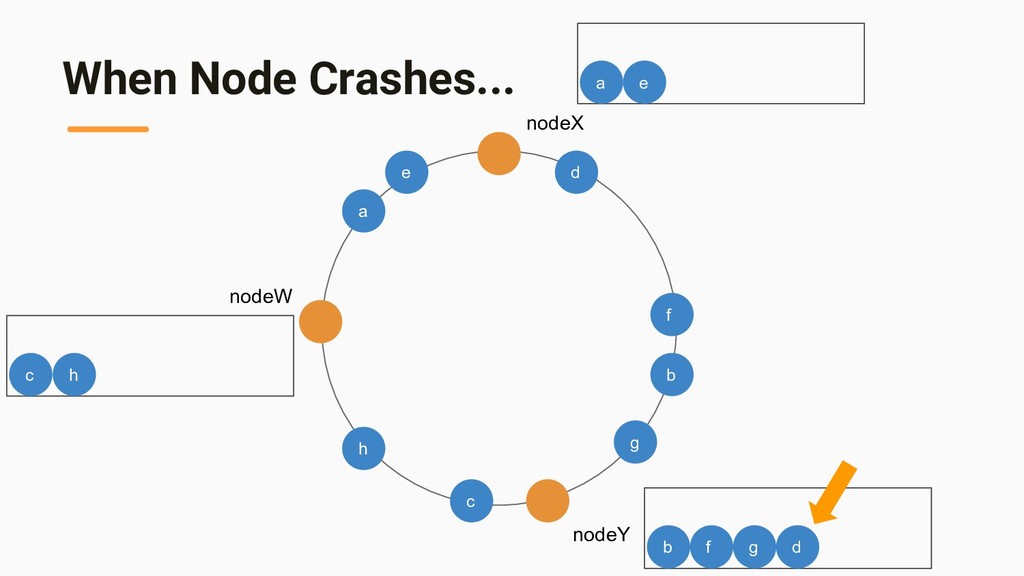{kind=link}
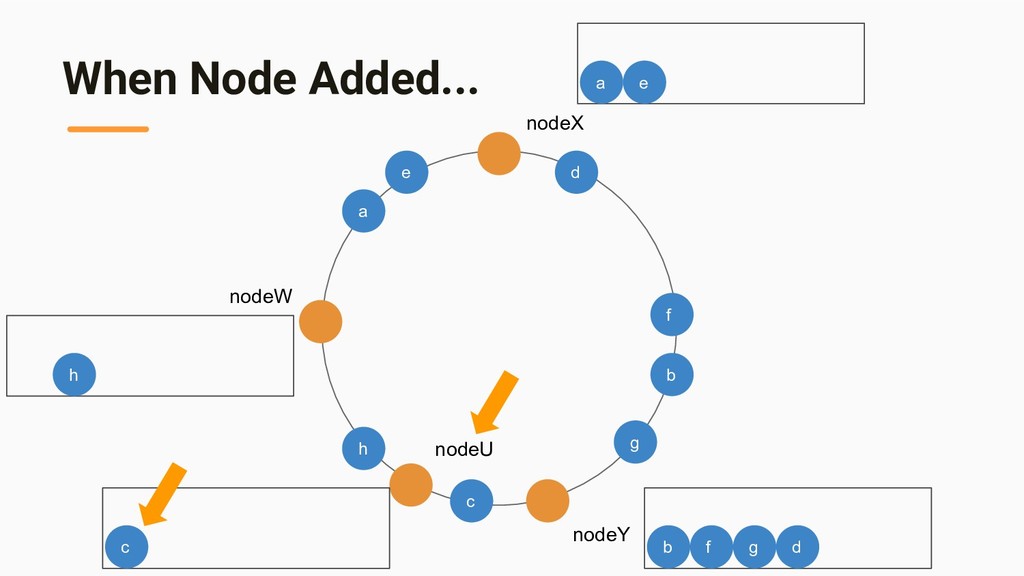{kind=link}
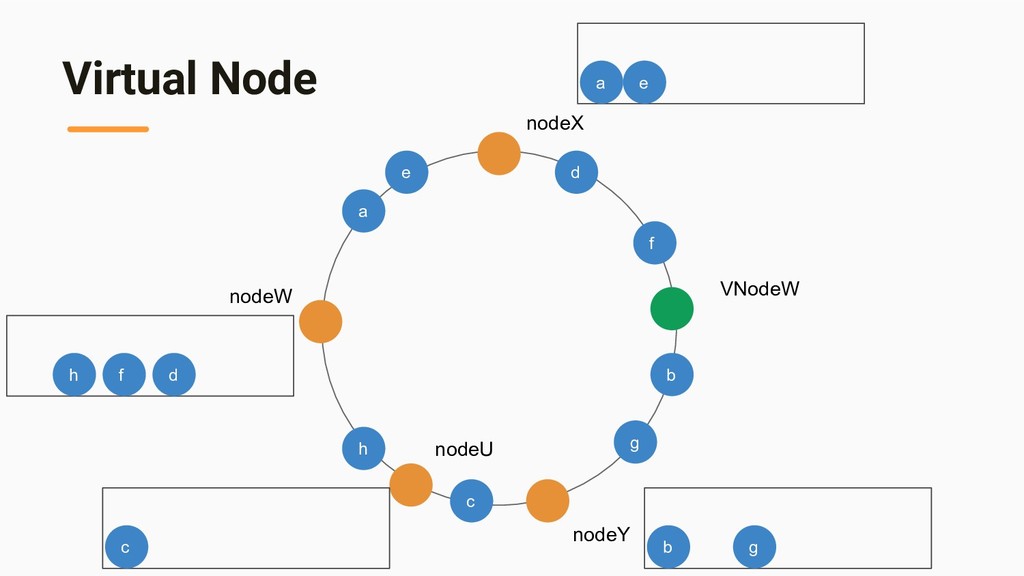{kind=link}
{kind=link}
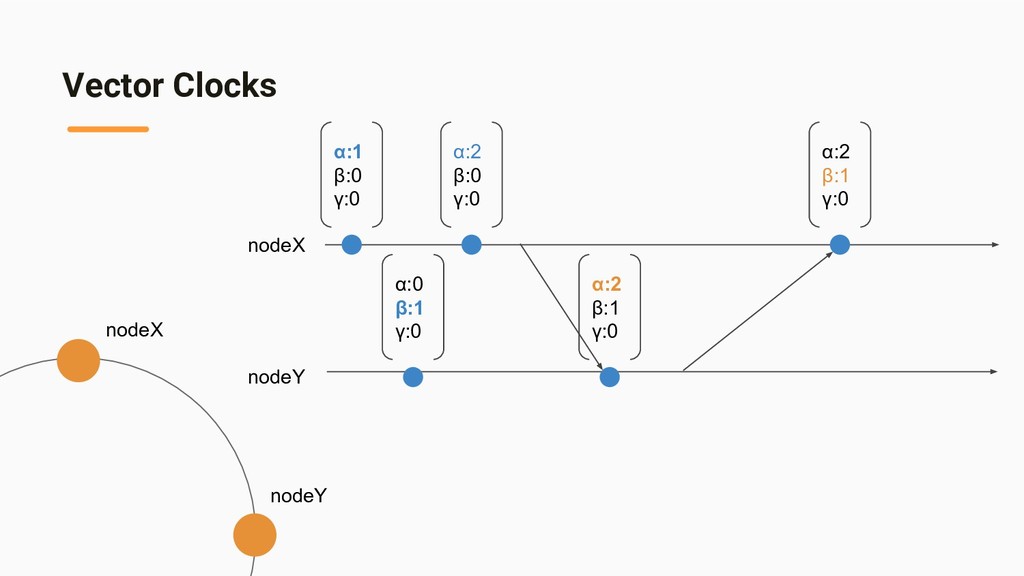{kind=link}
{kind=link}
{kind=link}
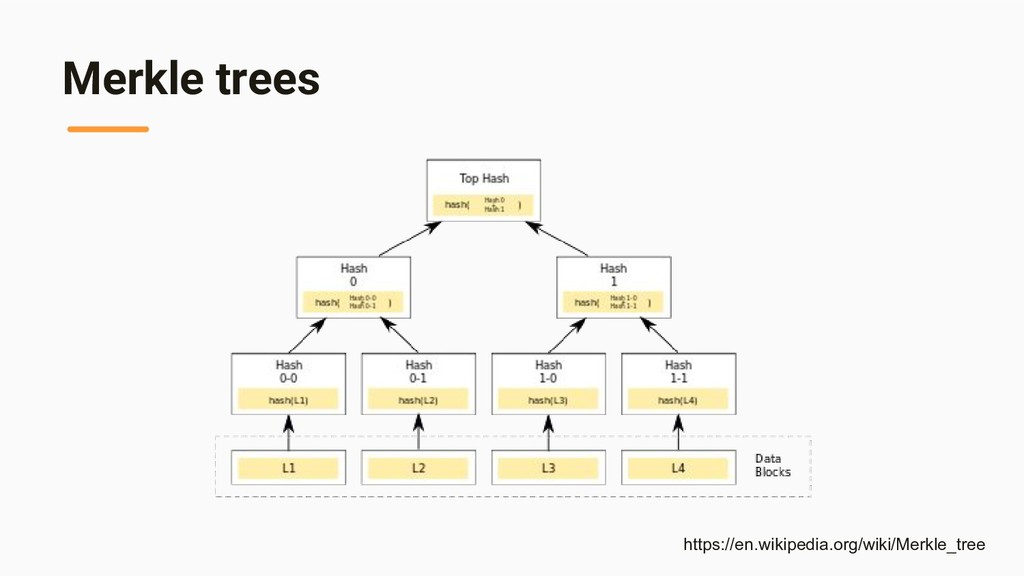{kind=link}
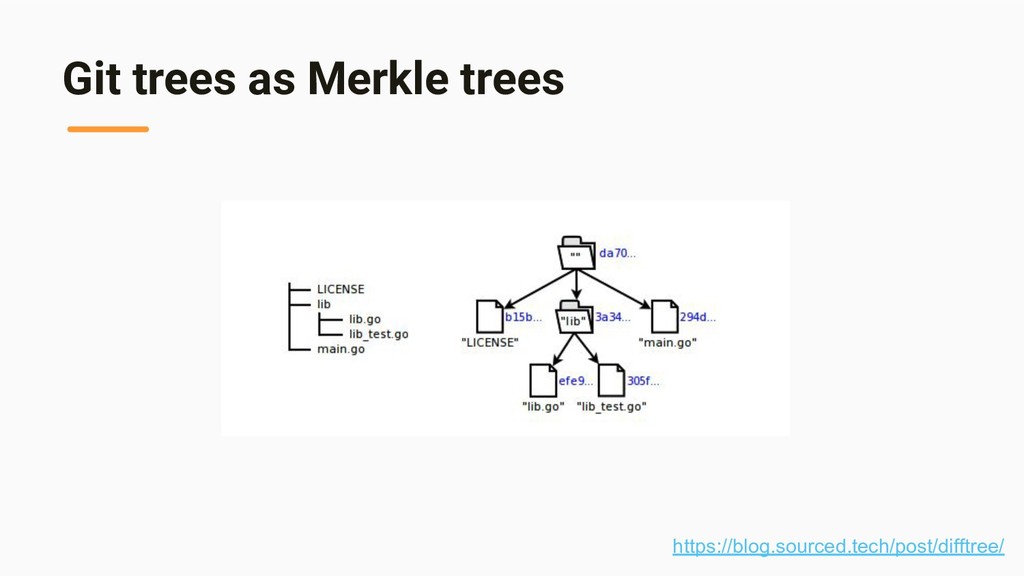{kind=link}
{kind=link}
{kind=link}
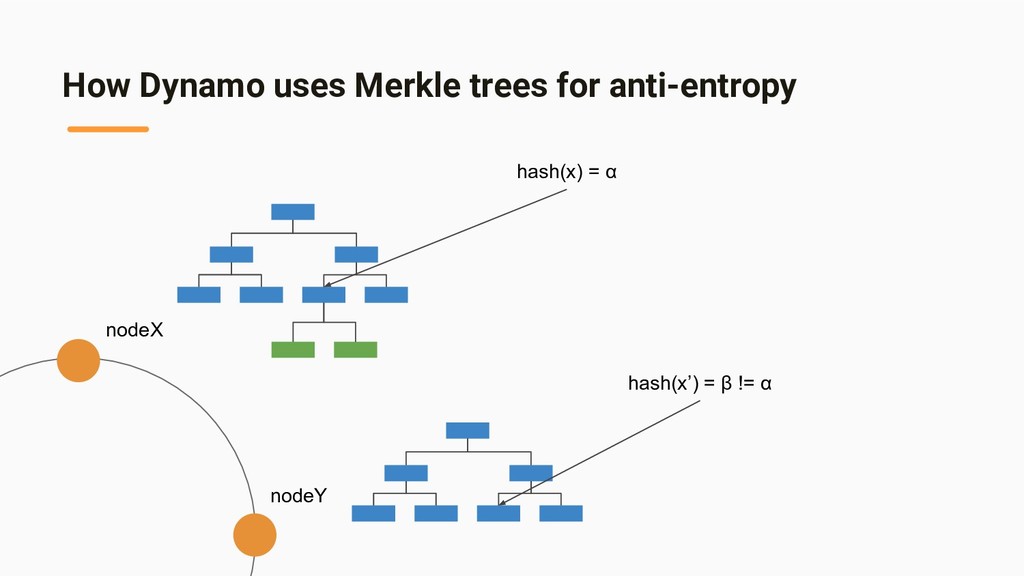{kind=link}
{kind=link}
{kind=link}
{kind=link}