rights reserved. Kubernetes とは 5 コンテナを複数のホストにわたって管理するオープンソースシステム いわゆる ”コンテナオーケストレーション” 主要な機能 ü 宣⾔的なリソース管理 ü "あるべき状態" を定義してそこに収束させる ü Reconciliation Loop ü スケジューリング ü さまざまな戦略を元にワークロードを適切なサーバーに 配置 ü サービスディスカバリー ü ワークロード間の通信 ü オートヒーリング ü コンテナに障害が発⽣した場合の⾃動回復
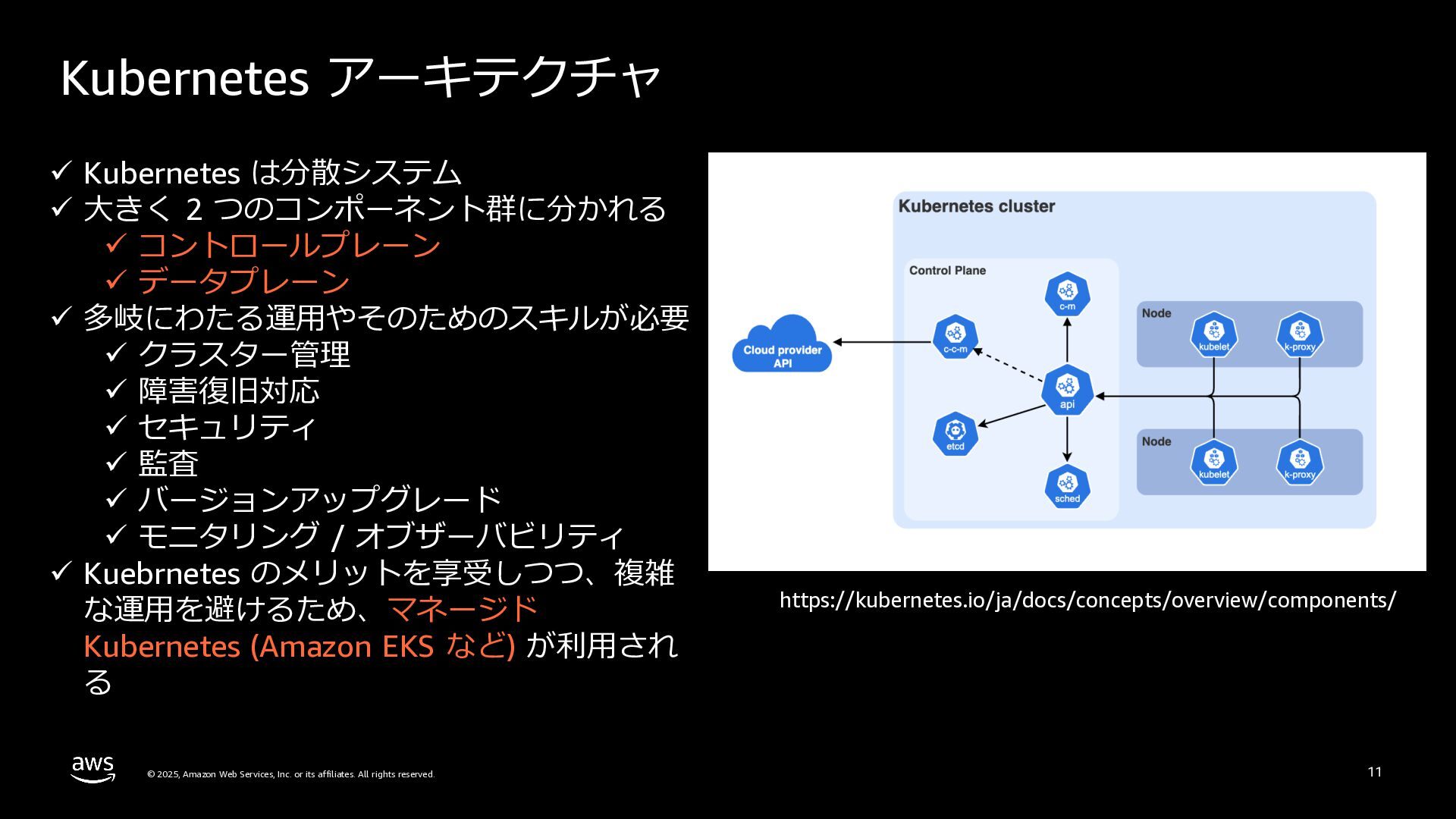
rights reserved. 11 Kubernetes アーキテクチャ https://kubernetes.io/ja/docs/concepts/overview/components/ ü Kubernetes は分散システム ü ⼤きく 2 つのコンポーネント群に分かれる ü コントロールプレーン ü データプレーン ü 多岐にわたる運⽤やそのためのスキルが必要 ü クラスター管理 ü 障害復旧対応 ü セキュリティ ü 監査 ü バージョンアップグレード ü モニタリング / オブザーバビリティ ü Kuebrnetes のメリットを享受しつつ、複雑 な運⽤を避けるため、マネージド Kubernetes (Amazon EKS など) が利⽤され る
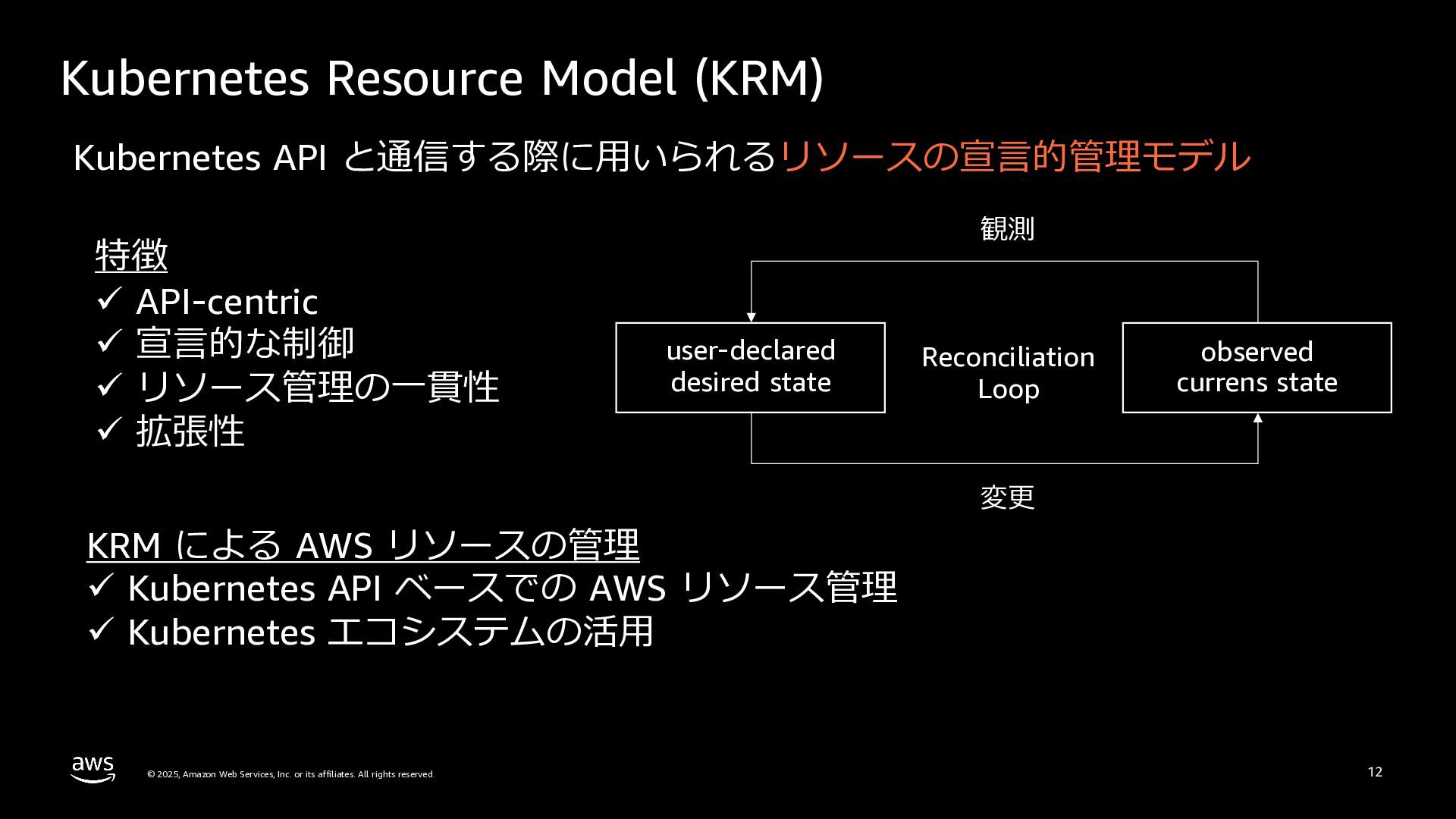
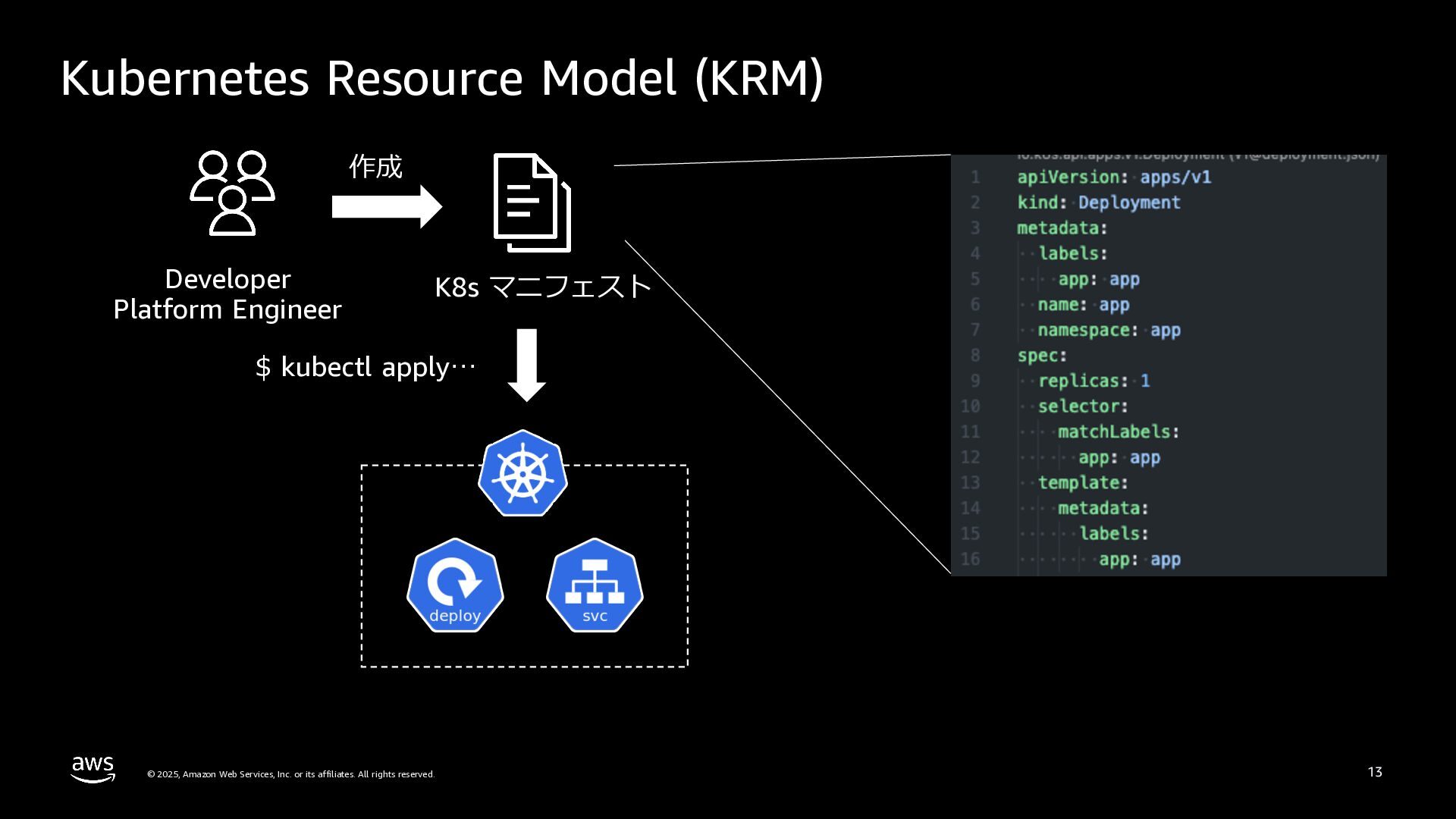
rights reserved. 12 Kubernetes Resource Model (KRM) Kubernetes API と通信する際に⽤いられるリソースの宣⾔的管理モデル 特徴 ü API-centric ü 宣⾔的な制御 ü リソース管理の⼀貫性 ü 拡張性 user-declared desired state observed currens state KRM による AWS リソースの管理 ü Kubernetes API ベースでの AWS リソース管理 ü Kubernetes エコシステムの活⽤ 変更 観測 Reconciliation Loop
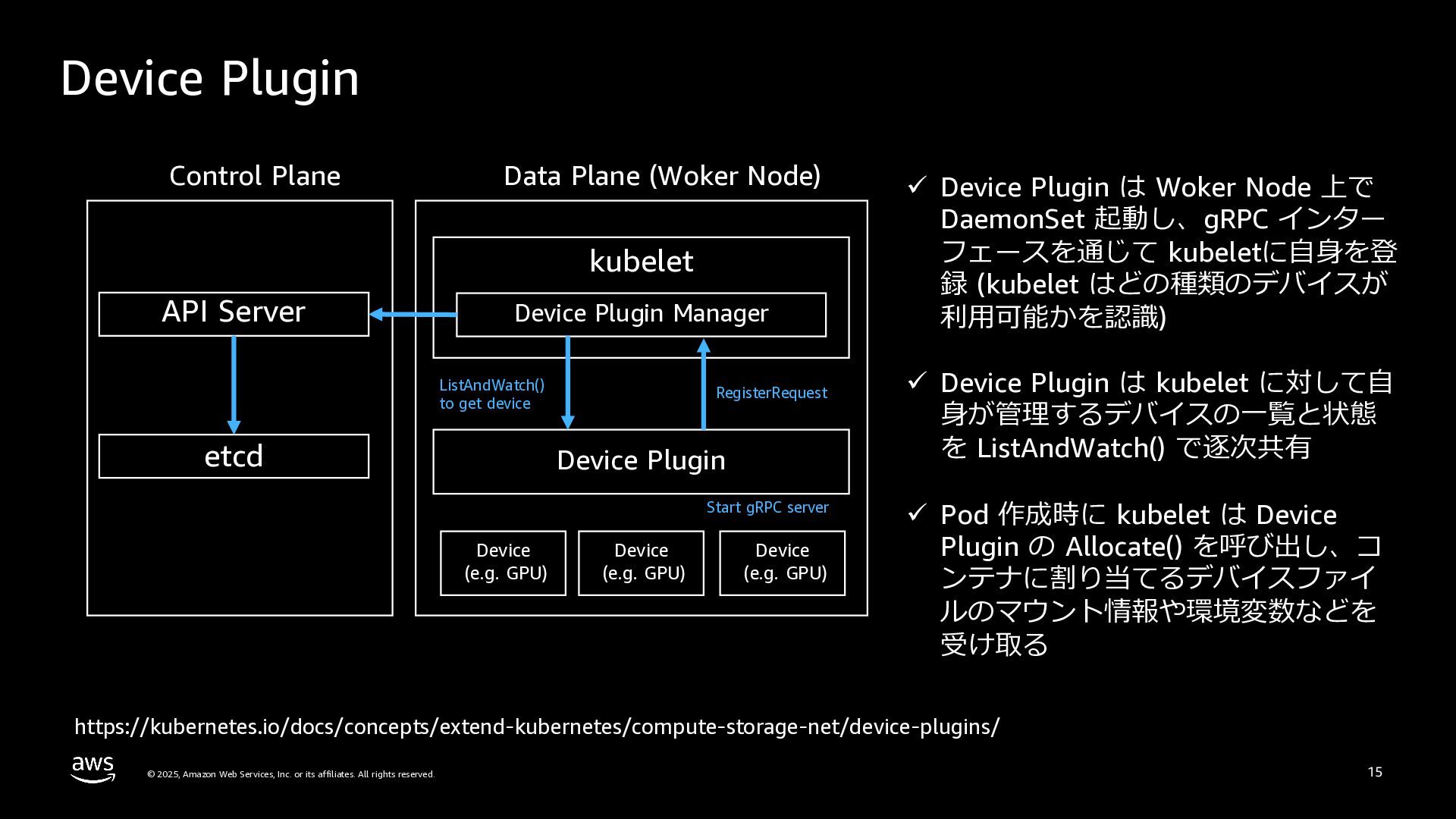
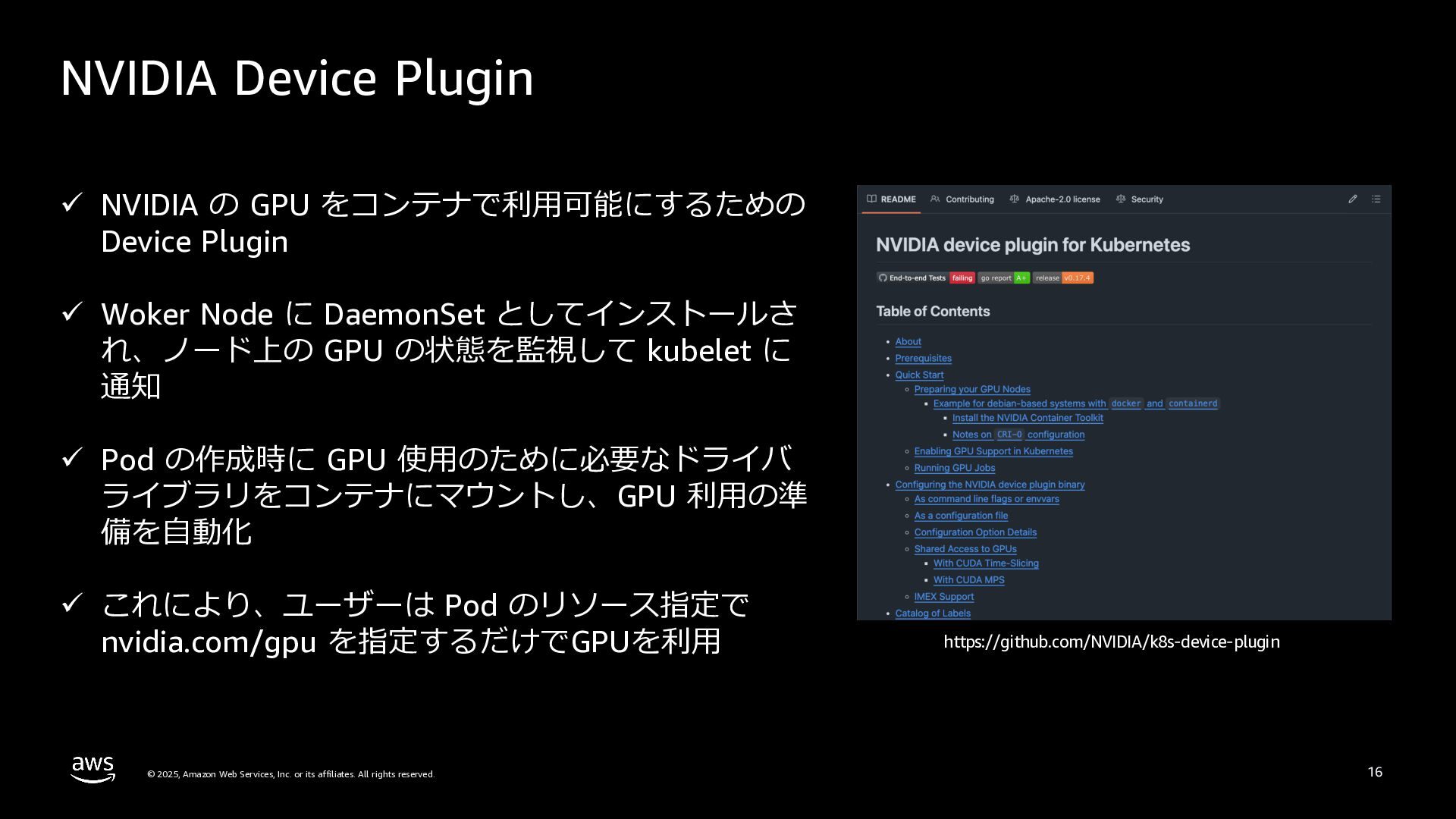
rights reserved. 19 ü Kubernetes v1.34 で GA となった Kubernetes API ü Kubernetes クラスタ内の特殊ハードウェア資 源(例︓GPU、FPGA)を柔軟に割り当てる ü 以下を実現 • 異なる Pod およびコンテナ内から同じリ ソースへのアクセス • リソース要求に応じた最適なリソースを割 り当て • ユーザーが指定したパラメーターに従って リソースの初期化を実⾏ Dynamic Resource Allocation https://kubernetes.io/blog/2025/09/01/kubernetes-v1-34-dra-updates/
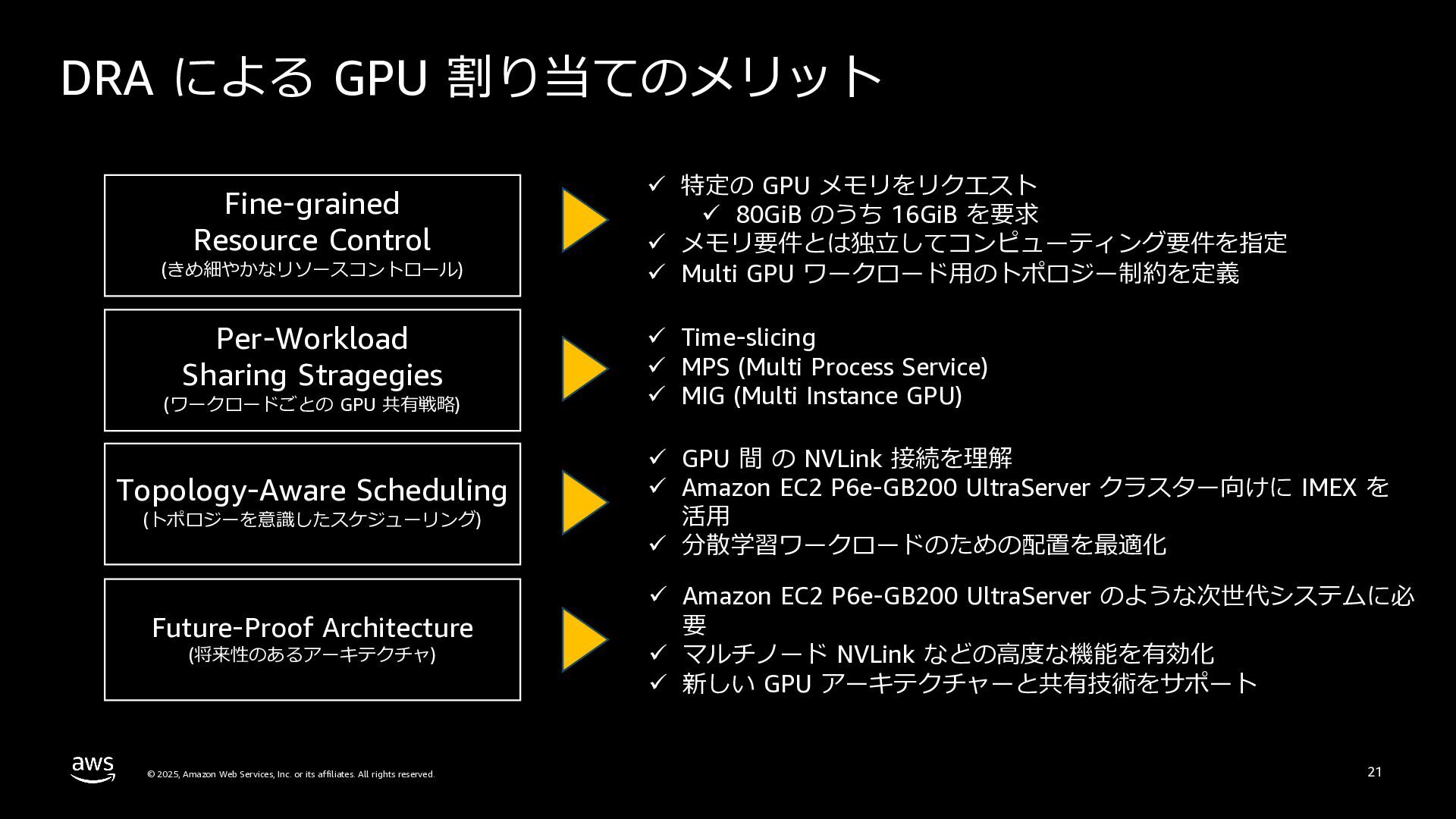
rights reserved. 21 ü 特定の GPU メモリをリクエスト ü 80GiB のうち 16GiB を要求 ü メモリ要件とは独⽴してコンピューティング要件を指定 ü Multi GPU ワークロード⽤のトポロジー制約を定義 ü Time-slicing ü MPS (Multi Process Service) ü MIG (Multi Instance GPU) ü GPU 間 の NVLink 接続を理解 ü Amazon EC2 P6e-GB200 UltraServer クラスター向けに IMEX を 活⽤ ü 分散学習ワークロードのための配置を最適化 ü Amazon EC2 P6e-GB200 UltraServer のような次世代システムに必 要 ü マルチノード NVLink などの⾼度な機能を有効化 ü 新しい GPU アーキテクチャーと共有技術をサポート Per-Workload Sharing Stragegies (ワークロードごとの GPU 共有戦略) Fine-grained Resource Control (きめ細やかなリソースコントロール) Topology-Aware Scheduling (トポロジーを意識したスケジューリング) Future-Proof Architecture (将来性のあるアーキテクチャ) DRA による GPU 割り当てのメリット
rights reserved. Ray とは 28 分散処理を簡単に記述するための Python ライブラリ・処理基盤 あたかもローカルで動くような⾒慣れたプログラムを、そのまま分散実⾏ (複数のスレッド、 複数のコア、複数のサーバで実⾏) できる ü 統合ツールセット ü AI/MLライフサイクル全体をカバーするライブラリ (Ray AI Libraries) を提供 ü Ray Data (データ処理)、Ray Train (分散トレーニング)、Ray Tune (ハイパーパラメータ チューニング)、Ray Serve (モデルサービング)、Ray RLlib (強化学習) ü Python ネイティブ ü 最⼩限のコードで Python による並列処理を実装 (既存の関数にデコレータを追加) ü スケーラビリティとパフォーマンス ü Rayは、異なるハードウェア (CPUとGPU) にまたがる分散学習と推論を実現 ü 耐障害性 ü ノード障害を⾃動的に処理し、クラスター内の他のマシンにタスクをルーティングするこ とで、中断のない実⾏を保証 特徴
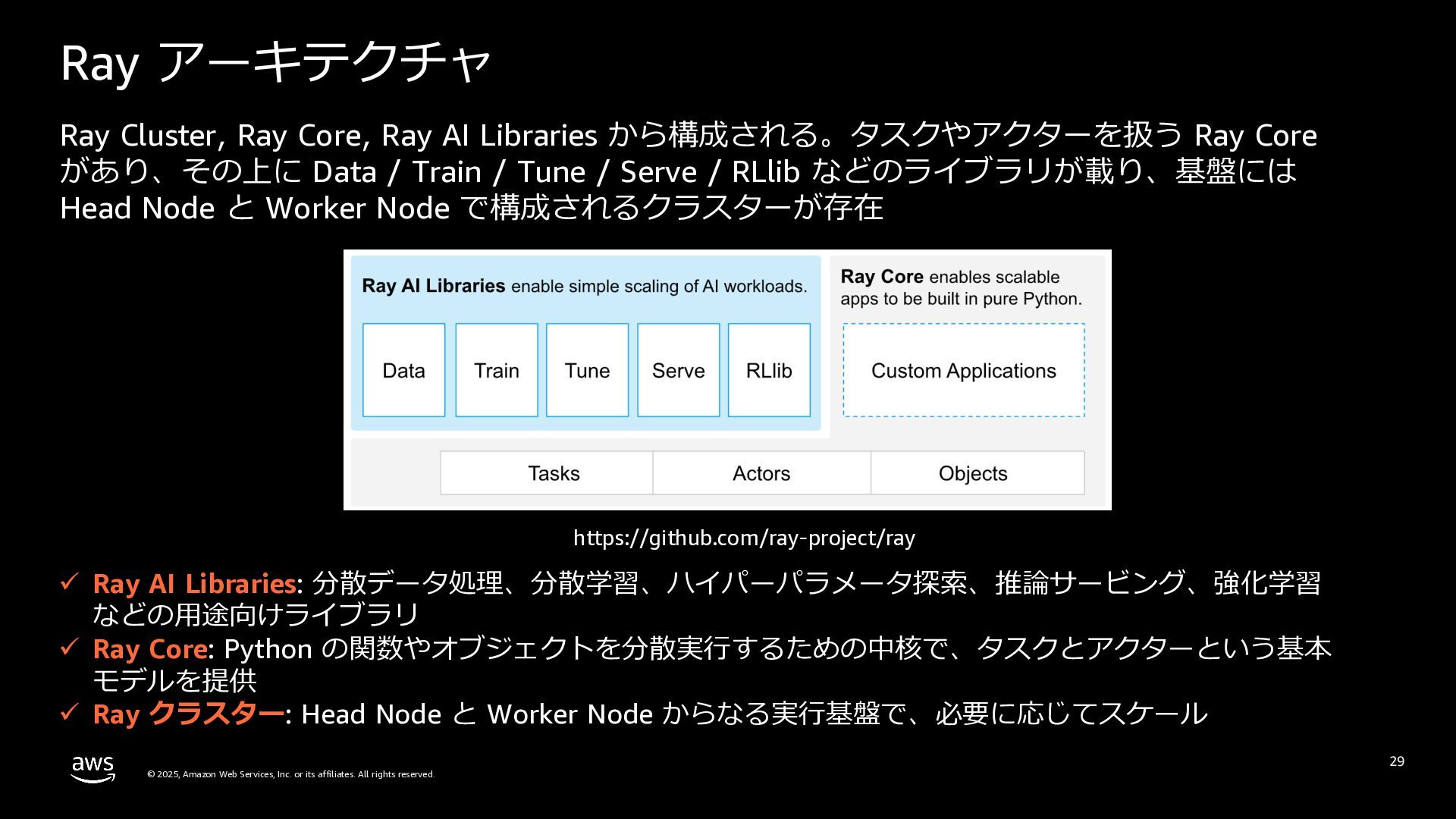
rights reserved. Ray アーキテクチャ 29 ü Ray AI Libraries: 分散データ処理、分散学習、ハイパーパラメータ探索、推論サービング、強化学習 などの⽤途向けライブラリ ü Ray Core: Python の関数やオブジェクトを分散実⾏するための中核で、タスクとアクターという基本 モデルを提供 ü Ray クラスター: Head Node と Worker Node からなる実⾏基盤で、必要に応じてスケール https://github.com/ray-project/ray Ray Cluster, Ray Core, Ray AI Libraries から構成される。タスクやアクターを扱う Ray Core があり、その上に Data / Train / Tune / Serve / RLlib などのライブラリが載り、基盤には Head Node と Worker Node で構成されるクラスターが存在
rights reserved. Ray AI Libraries 32 https://docs.ray.io/en/latest/ray-overview/getting-started.html#ray-core-quickstart ü Ray Data: ⼤規模データの読み込み・前処理・変換を ⾏う分散データ処理ライブラリ。学習や推論パイプラ インへのデータ供給に最適化 ü Ray Train: PyTorch、TensorFlow、HuggingFaceなど のフレームワークと統合し、分散学習(データ並列・ モデル並列)を簡単にスケールアウト ü Ray Tune: ハイパーパラメータチューニングを分散環 境で効率的に実⾏するライブラリ。ASHA、PBTなど 多数のスケジューリングアルゴリズムに対応 ü Ray Serve: モデルサービング(推論)のためのライ ブラリ。複数モデルの構成(パイプライン・アンサン ブル)、動的バッチング、オートスケーリングに対応 し、vLLMなどの推論エンジンと組み合わせてLLMの 分散推論にも利⽤される ü Ray Rllib: 強化学習(Reinforcement Learning)のた めのスケーラブルなライブラリ。多数のアルゴリズム (PPO、DQN、SACなど)を分散環境で実⾏可能
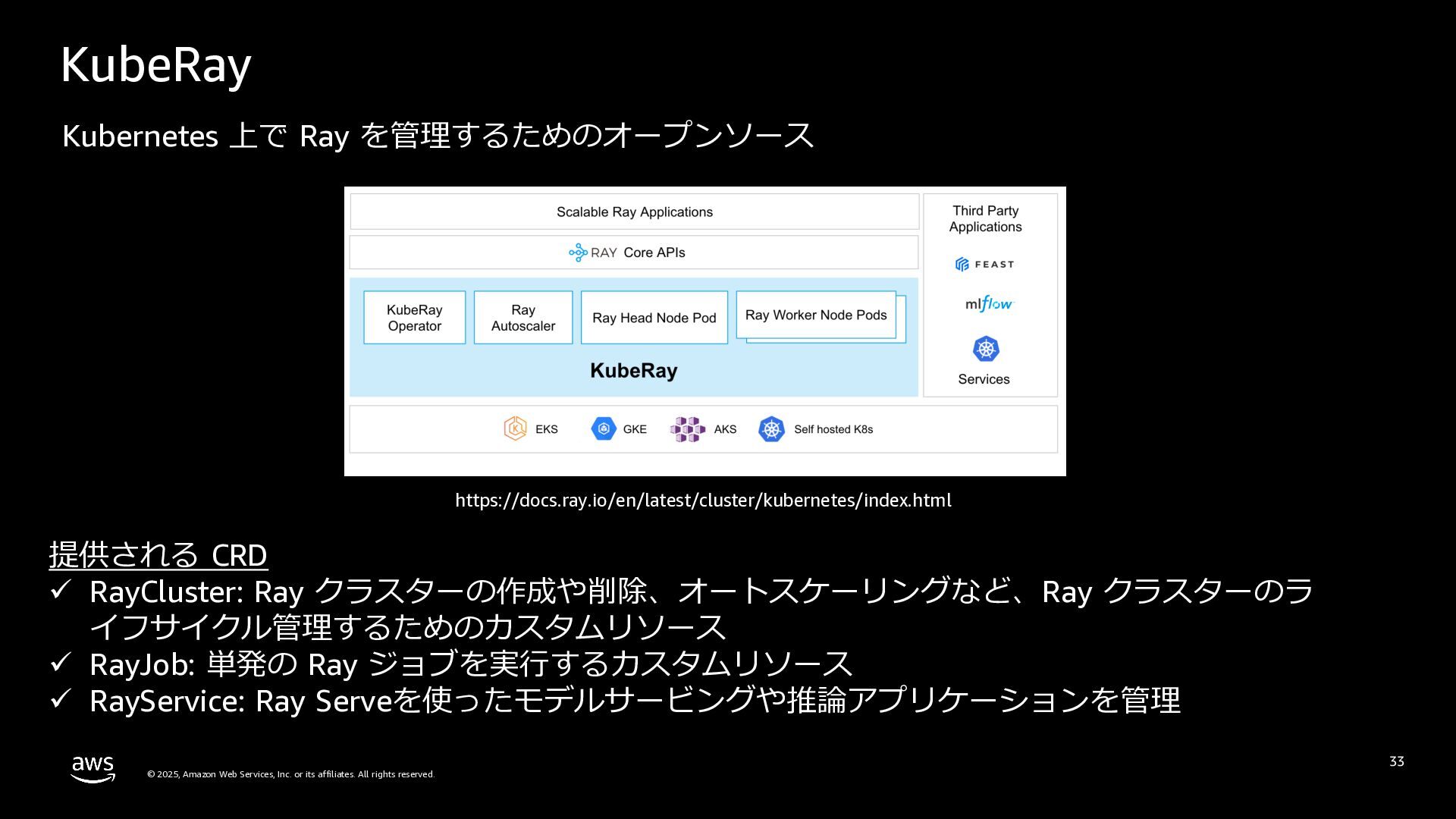
rights reserved. KubeRay 33 Kubernetes 上で Ray を管理するためのオープンソース https://docs.ray.io/en/latest/cluster/kubernetes/index.html 提供される CRD ü RayCluster: Ray クラスターの作成や削除、オートスケーリングなど、Ray クラスターのラ イフサイクル管理するためのカスタムリソース ü RayJob: 単発の Ray ジョブを実⾏するカスタムリソース ü RayService: Ray Serveを使ったモデルサービングや推論アプリケーションを管理
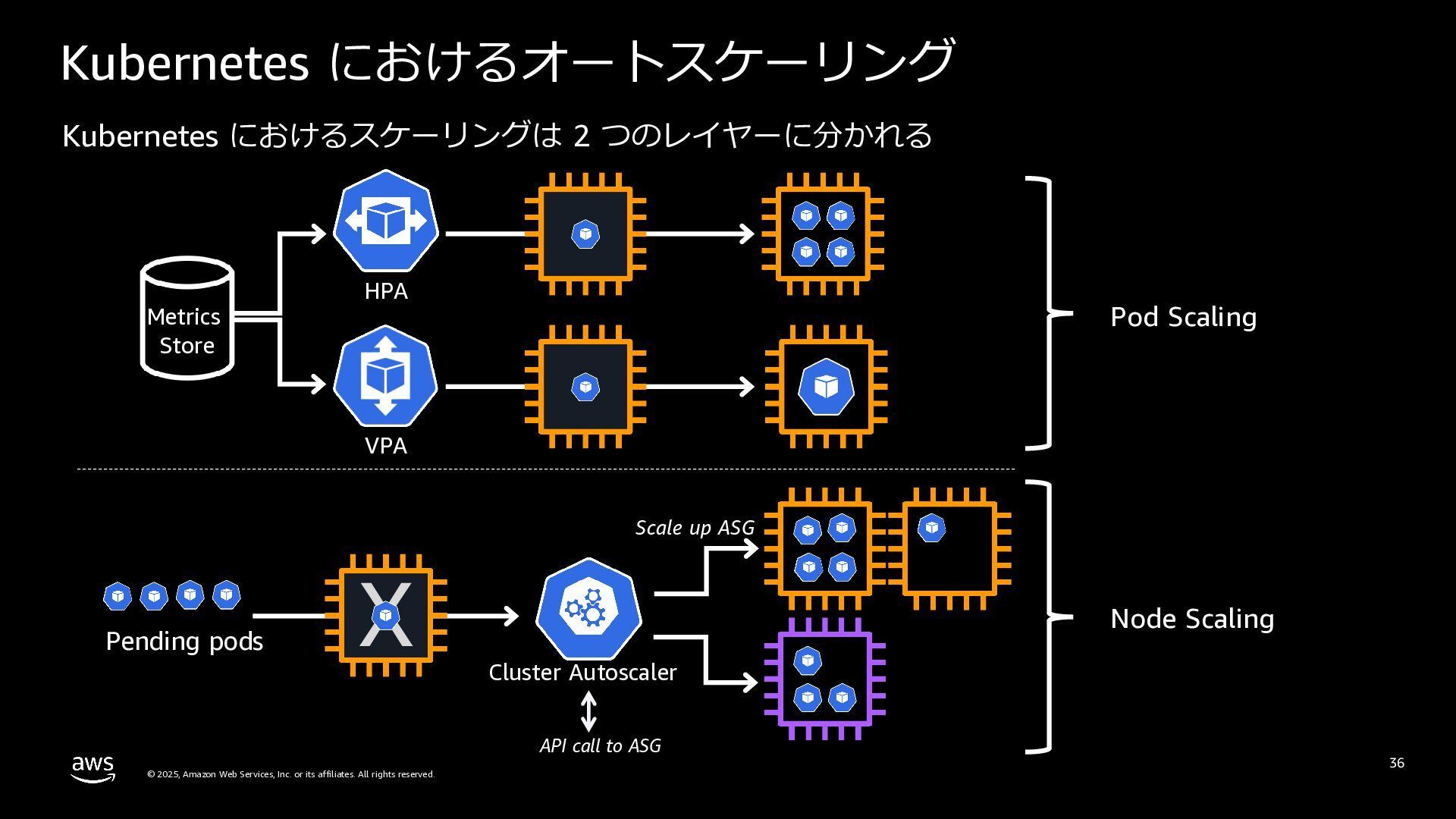
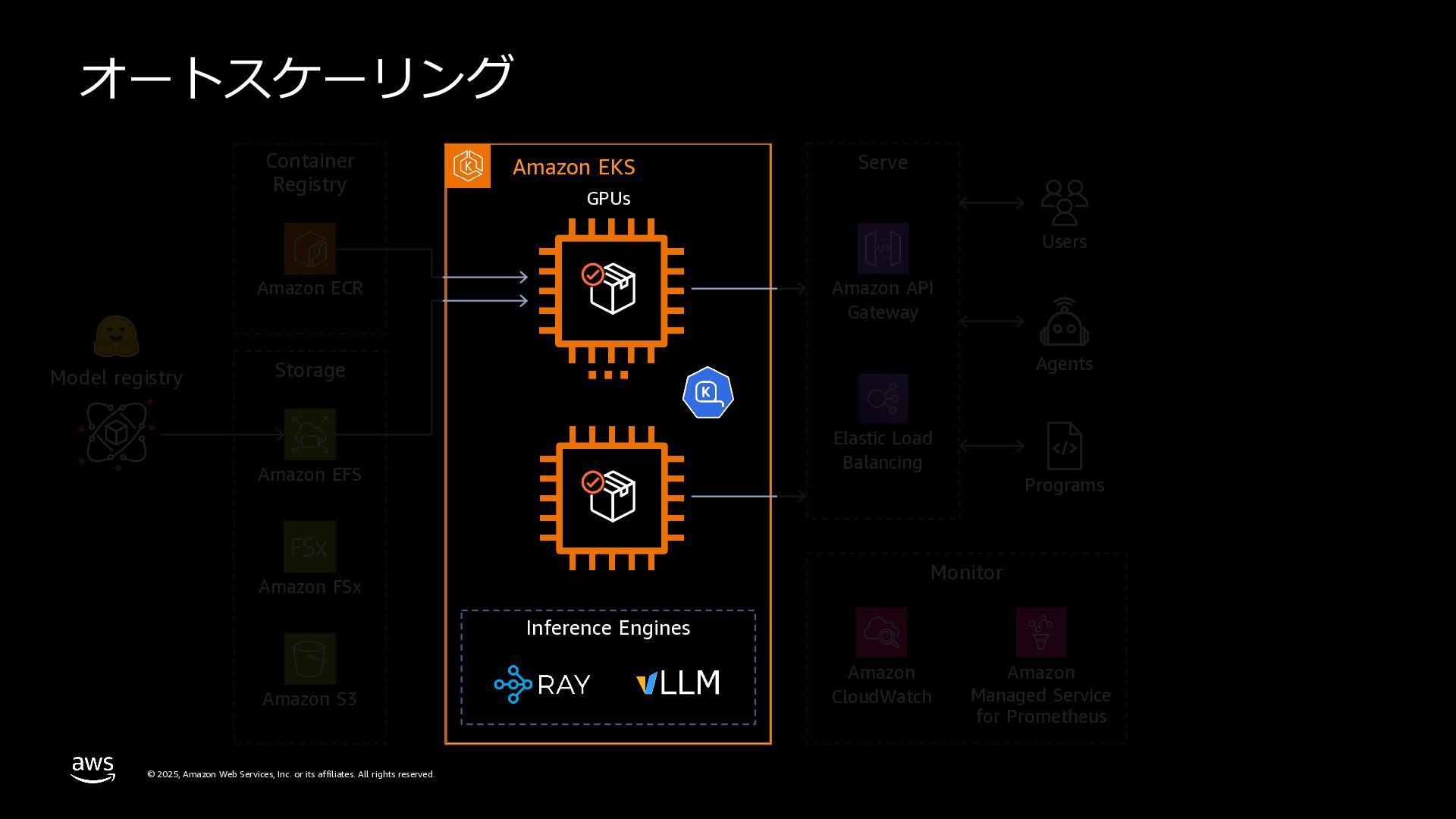
rights reserved. Kubernetes におけるオートスケーリング 36 Metrics Store HPA Pending pods X VPA Scale up ASG Cluster Autoscaler API call to ASG Pod Scaling Node Scaling Kubernetes におけるスケーリングは 2 つのレイヤーに分かれる
rights reserved. Kubernetes におけるオートスケーリング 37 HPA (Horizontal Pod Autoscaler) ü 主にCPUとメモリの使⽤状況を監視 ü そのため、主にGPUに負荷が集中するLLMワーク ロードには適しておらず、より柔軟なオートスケー リングの仕組みが必要になる KPA (Knative Pod Autoscaler) ü KPA はリクエストベースのアプローチ ü LLM では KPA のようなリクエストベースのアプ ローチでは、「リクエスト数」が実際の実⾏負荷と 必ずしも相関しない ü あるリクエストが多数のトークンを⽣成する⼀⽅で、 別のリクエストはごく少数しか⽣成しないなど LLM 推論基盤における、Pod Scaling の選択肢
rights reserved. KEDA: Kubernetes-based Event-Driven Autoscaling 38 ü HPA より柔軟に Pod や Job のスケールが可能な 軽量 OSS コンポーネント ü 内部的には HPA と連携することで上書きや重 複なくシンプルに機能提供 ü 多数の外部メトリクスをサポート ü ゼロスケール対応 ü カスタムリソースのマニフェストを記載すること で設定が可能 https://keda.sh
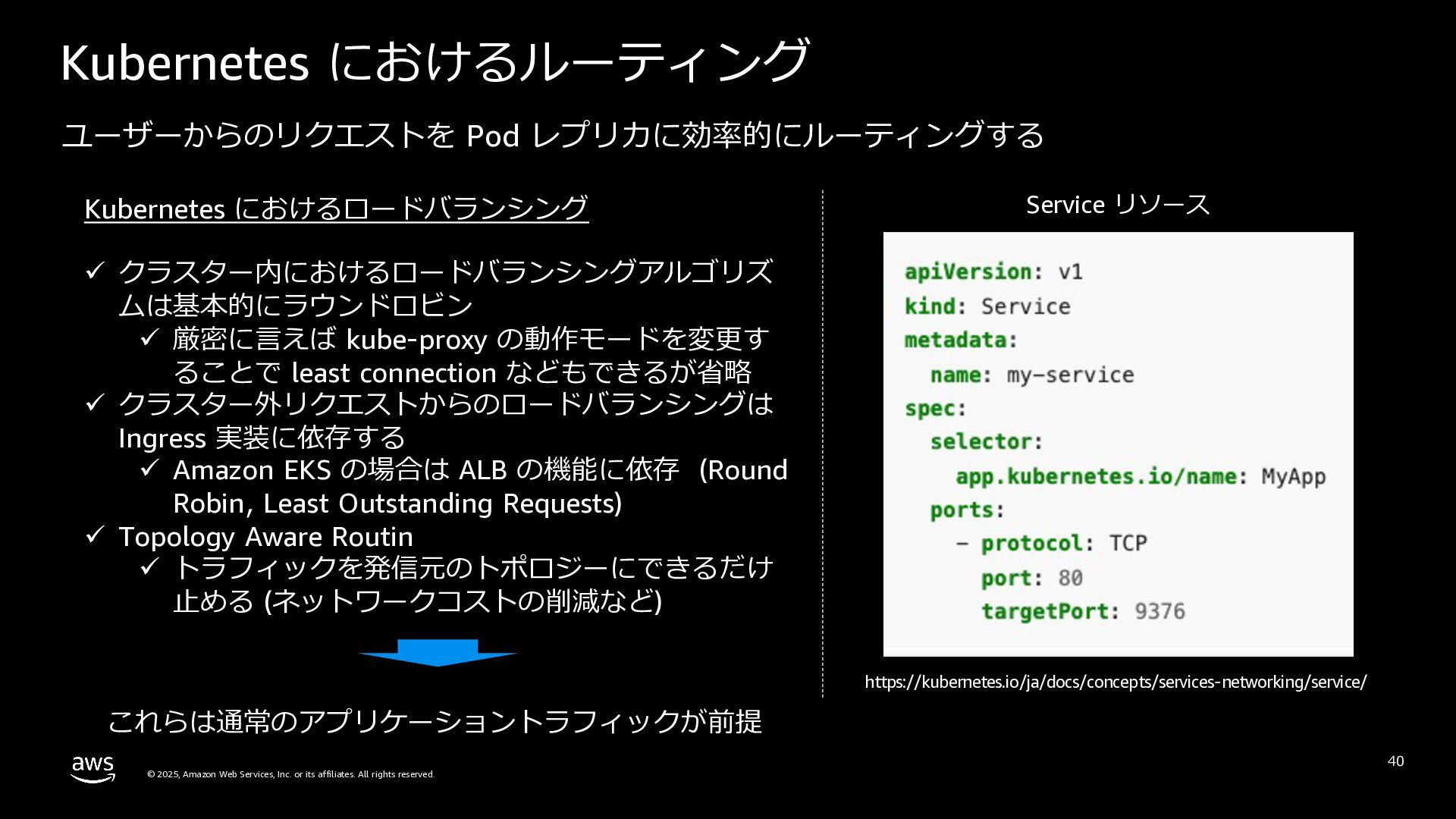
rights reserved. Kubernetes におけるルーティング 40 Kubernetes におけるロードバランシング ü クラスター内におけるロードバランシングアルゴリズ ムは基本的にラウンドロビン ü 厳密に⾔えば kube-proxy の動作モードを変更す ることで least connection などもできるが省略 ü クラスター外リクエストからのロードバランシングは Ingress 実装に依存する ü Amazon EKS の場合は ALB の機能に依存 (Round Robin, Least Outstanding Requests) ü Topology Aware Routin ü トラフィックを発信元のトポロジーにできるだけ ⽌める (ネットワークコストの削減など) ユーザーからのリクエストを Pod レプリカに効率的にルーティングする https://kubernetes.io/ja/docs/concepts/services-networking/service/ Service リソース これらは通常のアプリケーショントラフィックが前提
rights reserved. LLM Gateway に求められる要件 41 LLM トラフィックを認識し、それを最適化できるゲートウェイコンポーネントを実現すること ü リクエスト数ベースのレート制限 ü パスベースのルーティング ü AutN/Z 従来の API Gateway LLM Gateway ü トークン消費量の追跡 ü モデルやユーザーに基づくトークン消 費量の追跡 ü トークンベースでのレート制限 ü リクエスト数ではなく、⽣成された トークン数などに基づいてクォータを 定義 ü モデル名やセマンティクスによ るルーティング
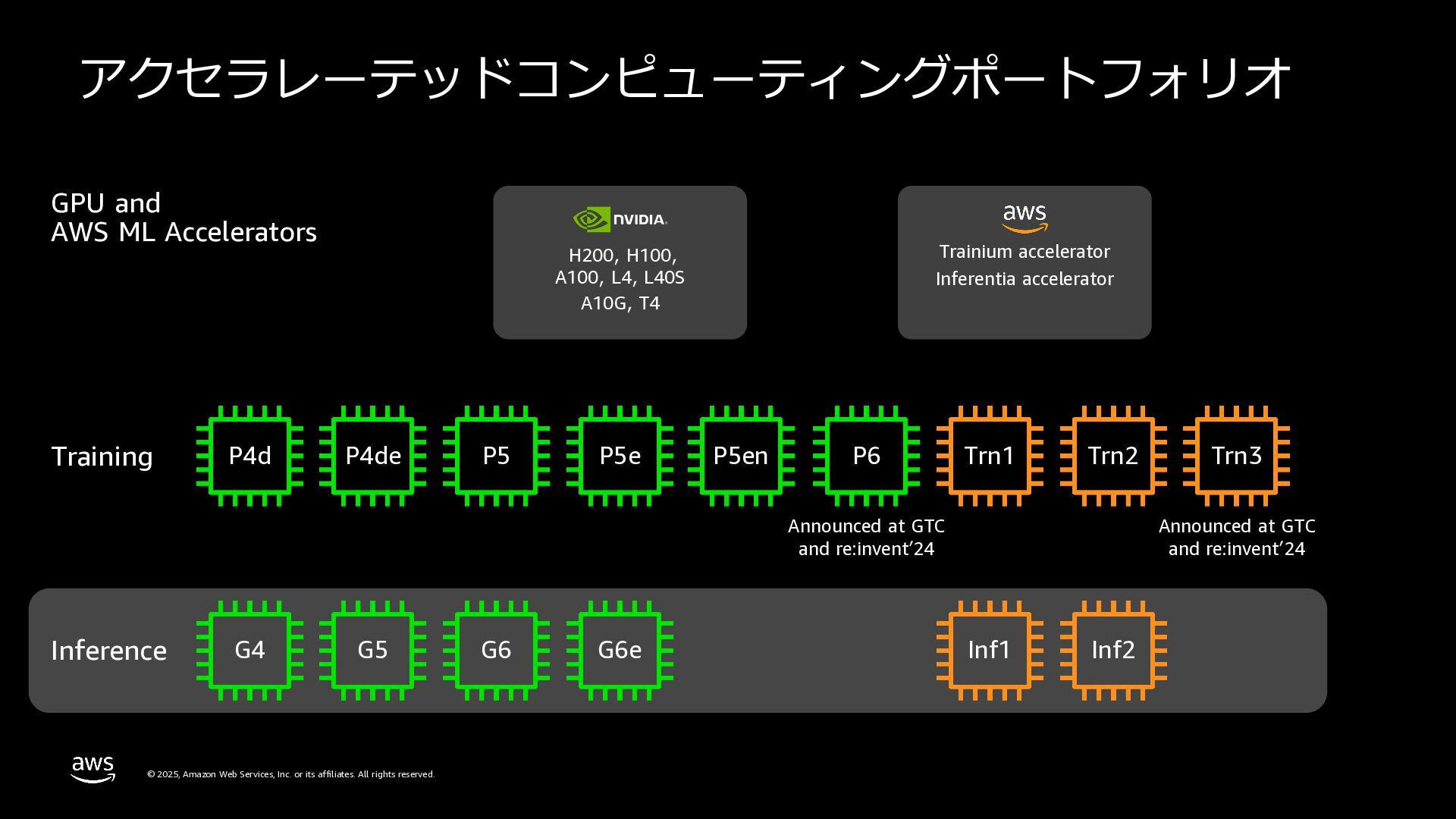
rights reserved. GPU and AWS ML Accelerators Trainium accelerator Inferentia accelerator H200, H100, A100, L4, L40S A10G, T4 Announced at GTC and re:inventʼ24 Training Inference Announced at GTC and re:inventʼ24 Trn3 Trn2 Trn1 Inf2 Inf1 P4d P4de P5 P5e P5en P6 G4 G5 G6 G6e アクセラレーテッドコンピューティングポートフォリオ
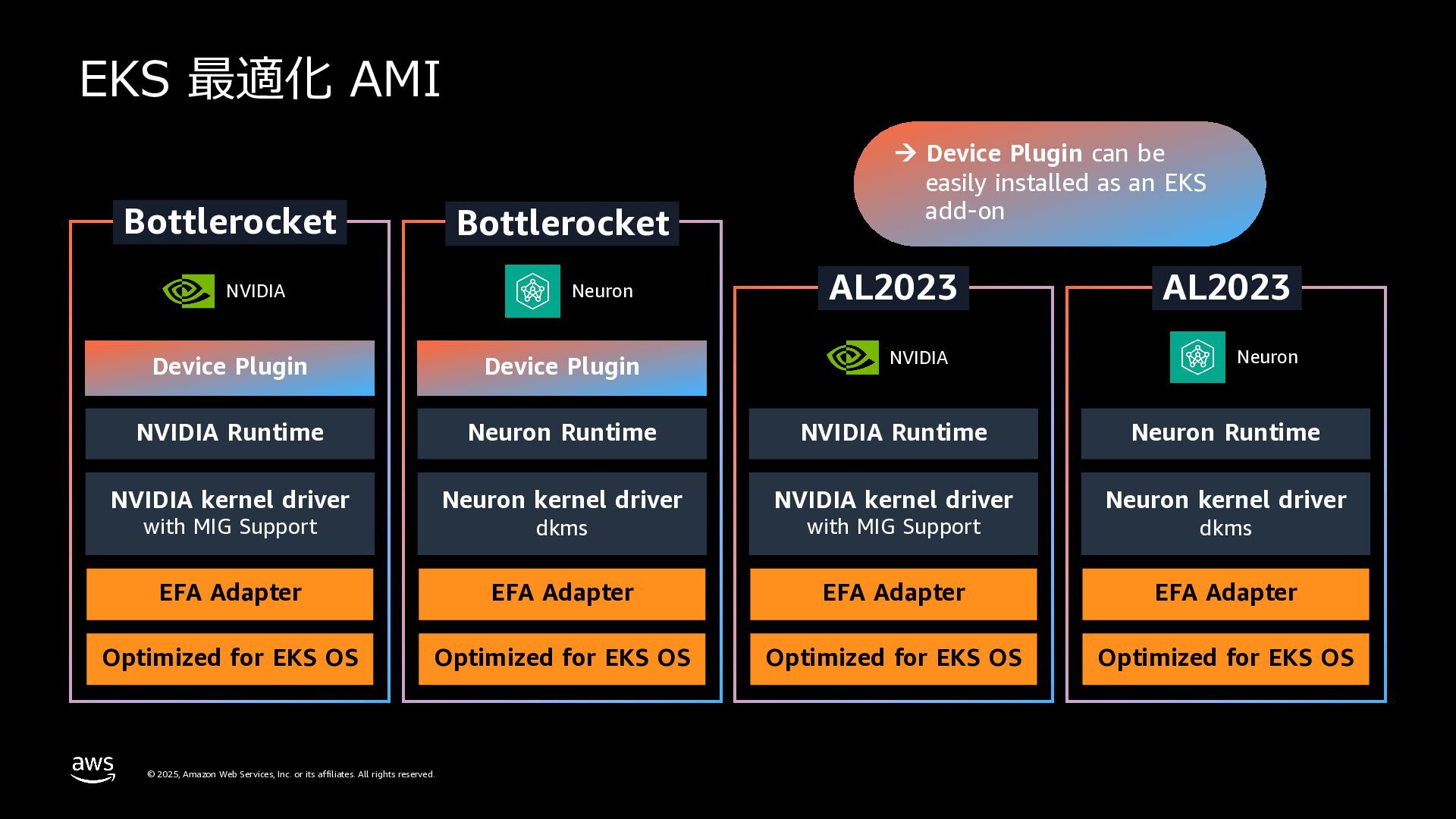
rights reserved. EFA Adapter Bottlerocket Optimized for EKS OS NVIDIA Neuron NVIDIA kernel driver with MIG Support Device Plugin NVIDIA Runtime à Device Plugin can be easily installed as an EKS add-on EFA Adapter Bottlerocket Optimized for EKS OS Neuron kernel driver dkms Device Plugin Neuron Runtime EFA Adapter Optimized for EKS OS NVIDIA Neuron NVIDIA kernel driver with MIG Support NVIDIA Runtime EFA Adapter AL2023 Optimized for EKS OS Neuron kernel driver dkms Neuron Runtime AL2023 EKS 最適化 AMI
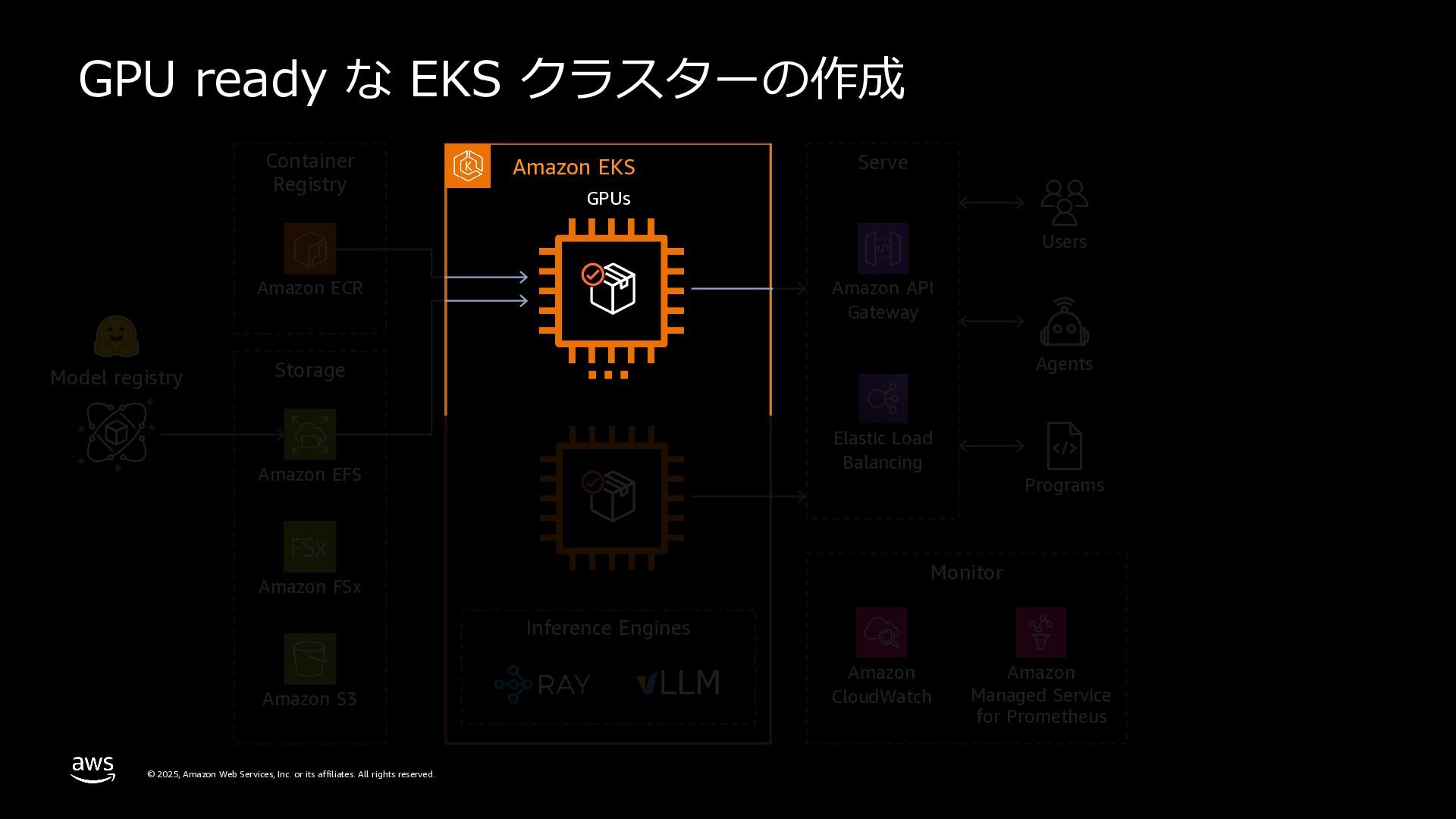
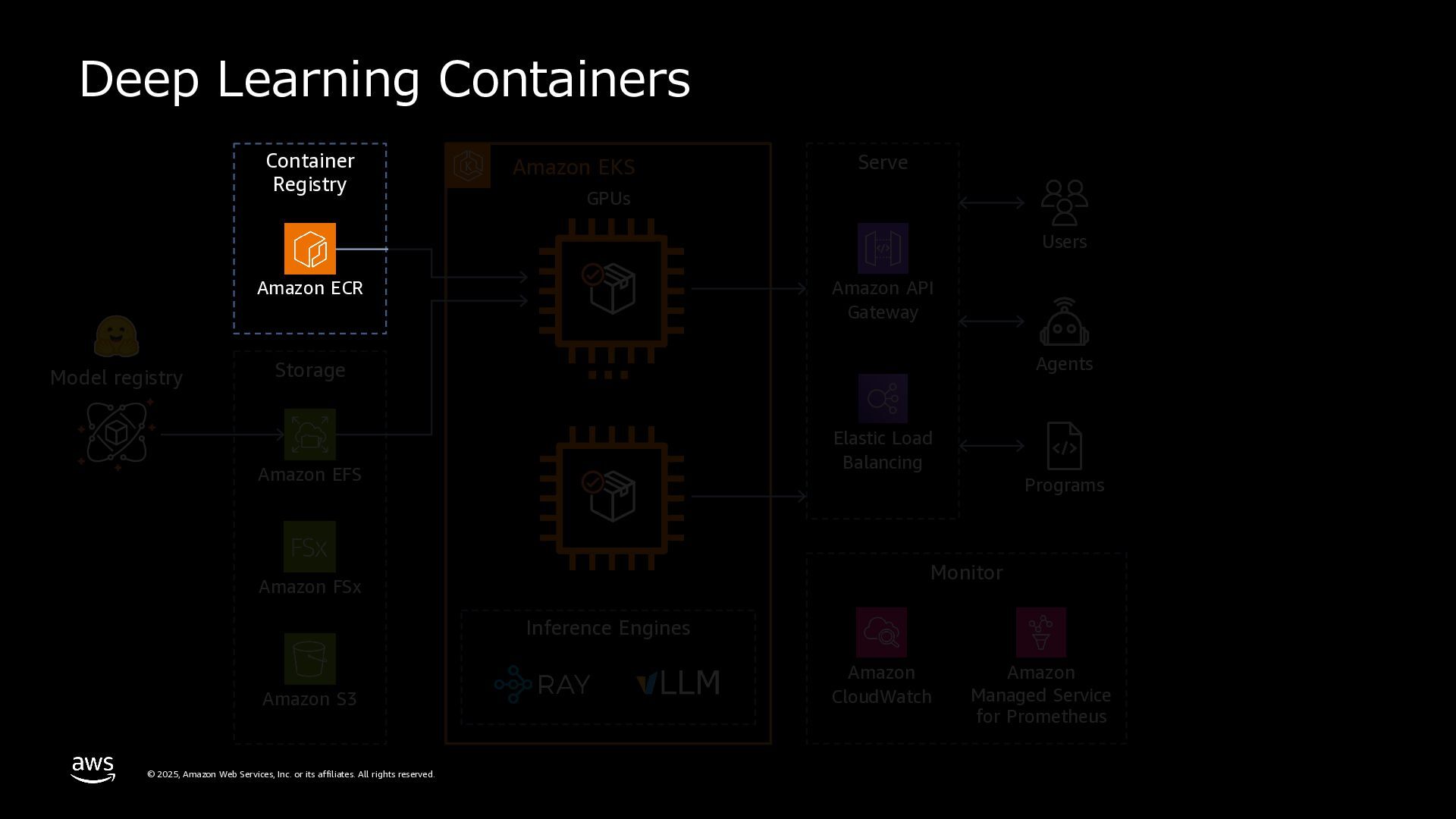
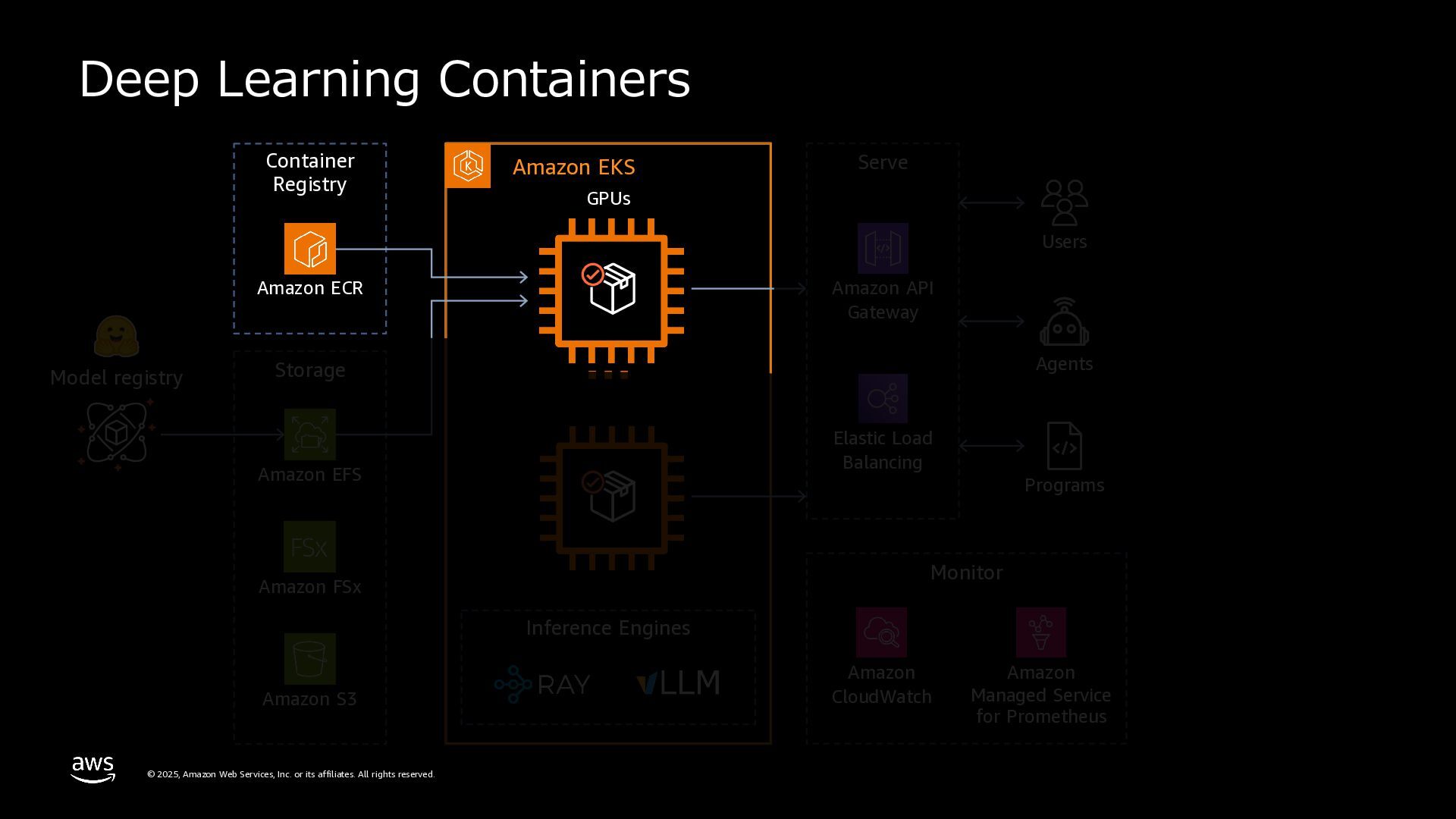
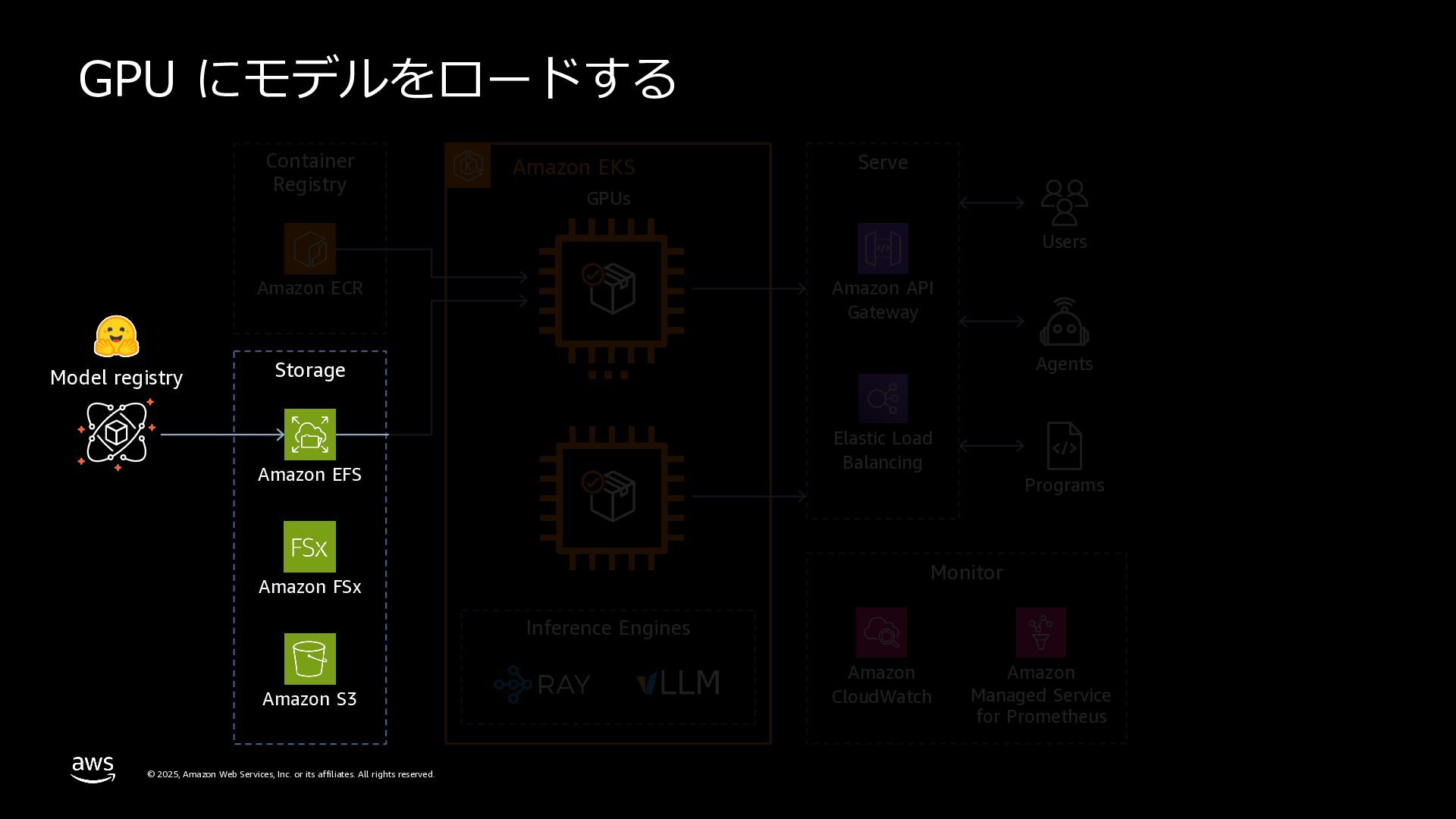
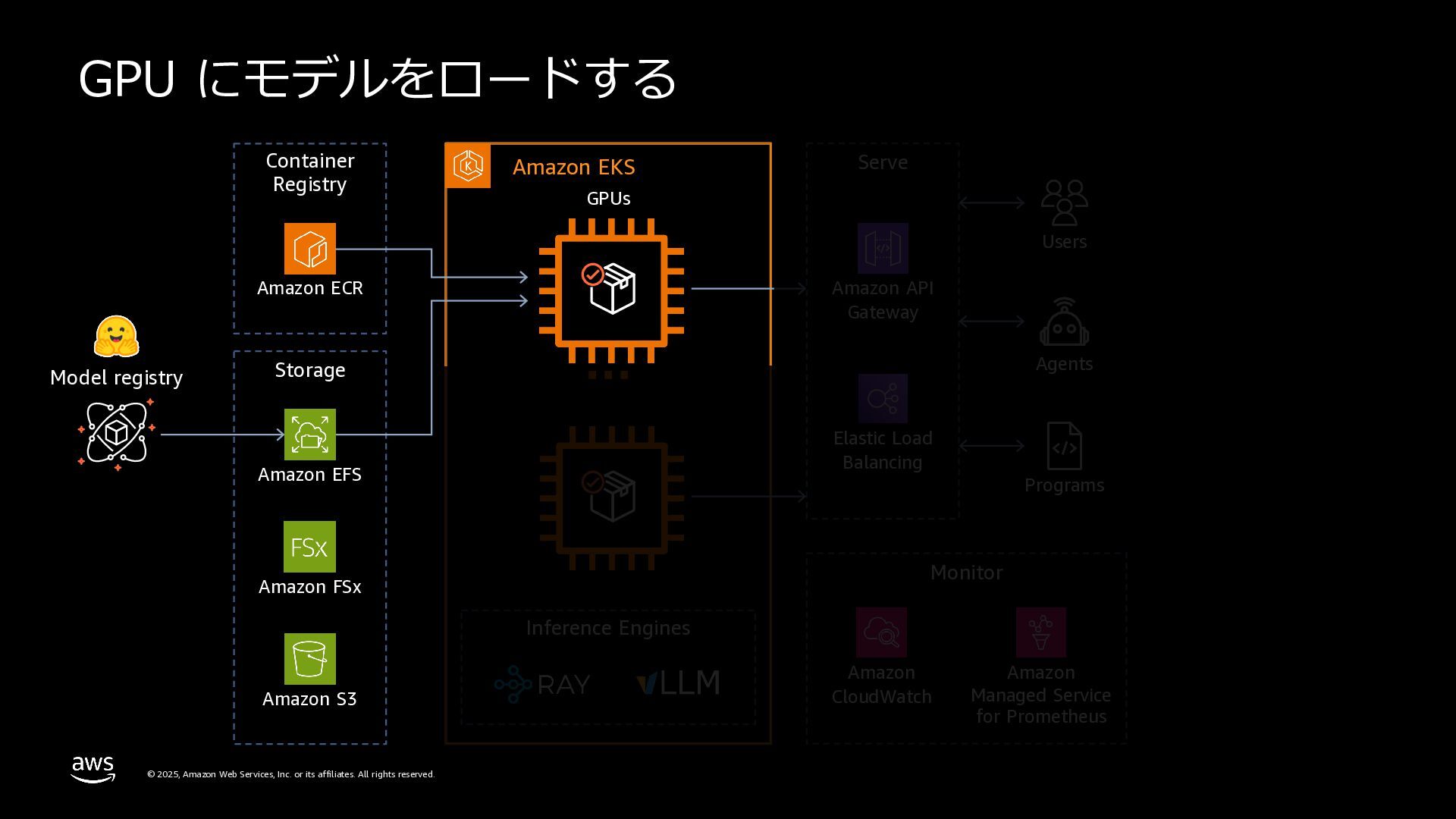
rights reserved. 複数のMLフレームワークサポート TensorFlow、PyTorch、XGBoost、JAXなど、複数のMLフレー ムワークが設定済み。numpy、sklearn、scipy、pandasなど、 多数のPythonパッケージを含む。 Pre-bundled ML libraries テキスト⽣成、テキスト埋め込みツールキット、transformers 、diffusersライブラリを含む。Nvidia、Neuronパッケージ、 CUDA、CuDNN、NCCL、vLLMライブラリを搭載。 OSS integrations vLLMを使⽤してLLMサービングを最適化。Rayなどのフレー ムワーク⾮依存ライブラリを使⽤してモデルサービングをス ケール。 DEEP LEARNING CONTAINER CUDA or Neuron Runtime Model framework CUDA Libraries, NCCL, lib fabric Deep Learning Containers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
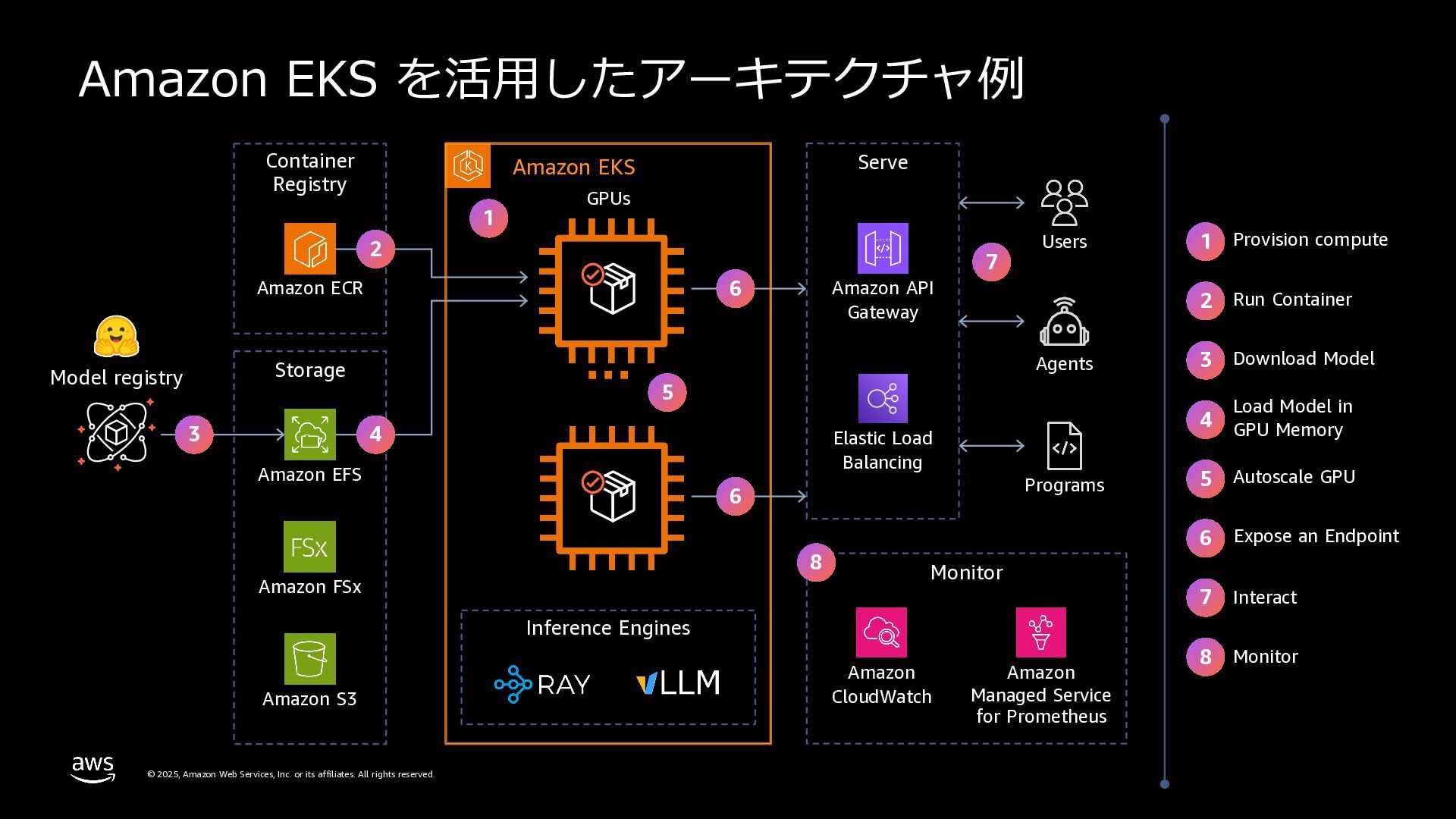{kind=link}
{kind=link}
{kind=link}
{kind=link}