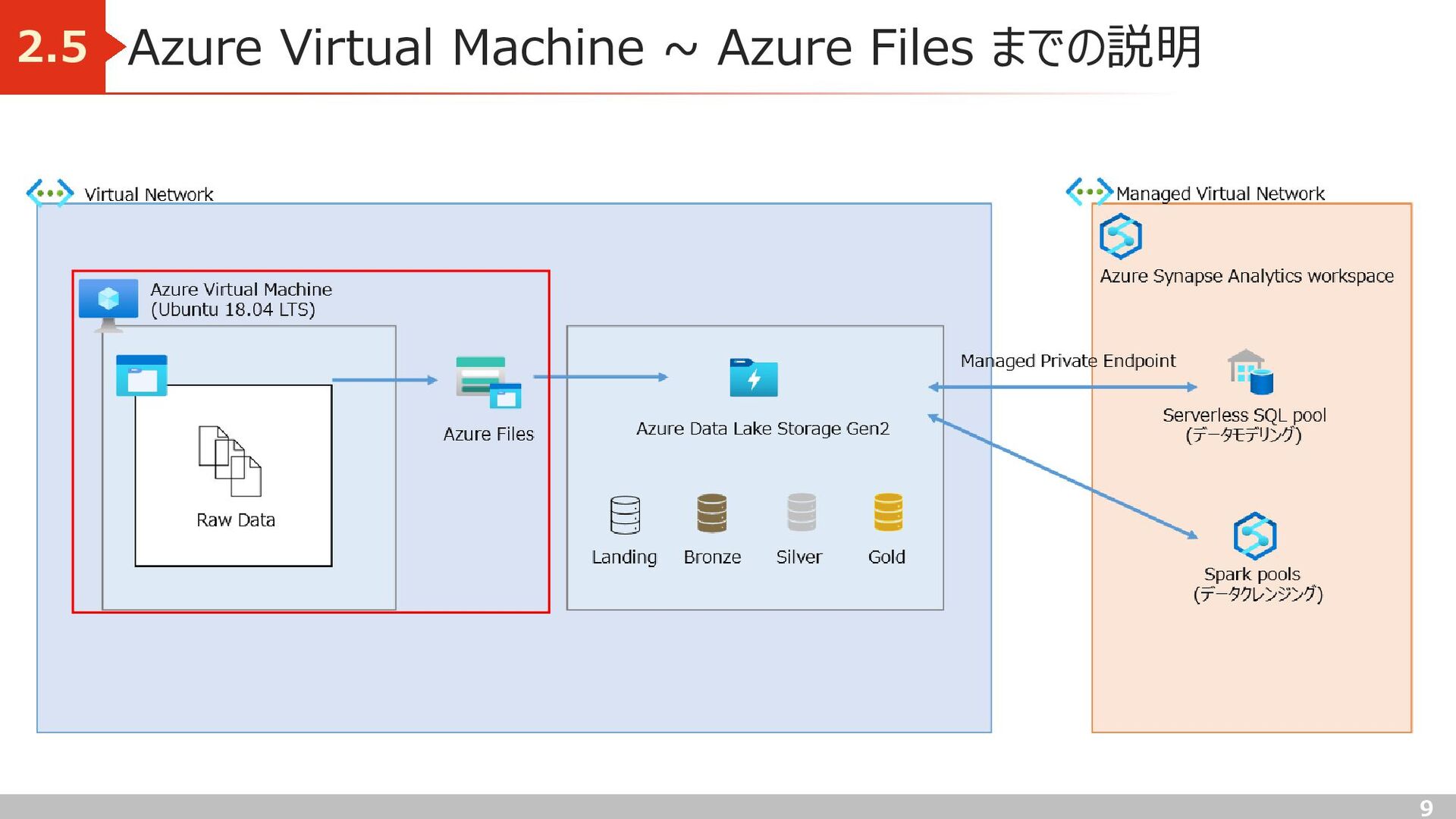
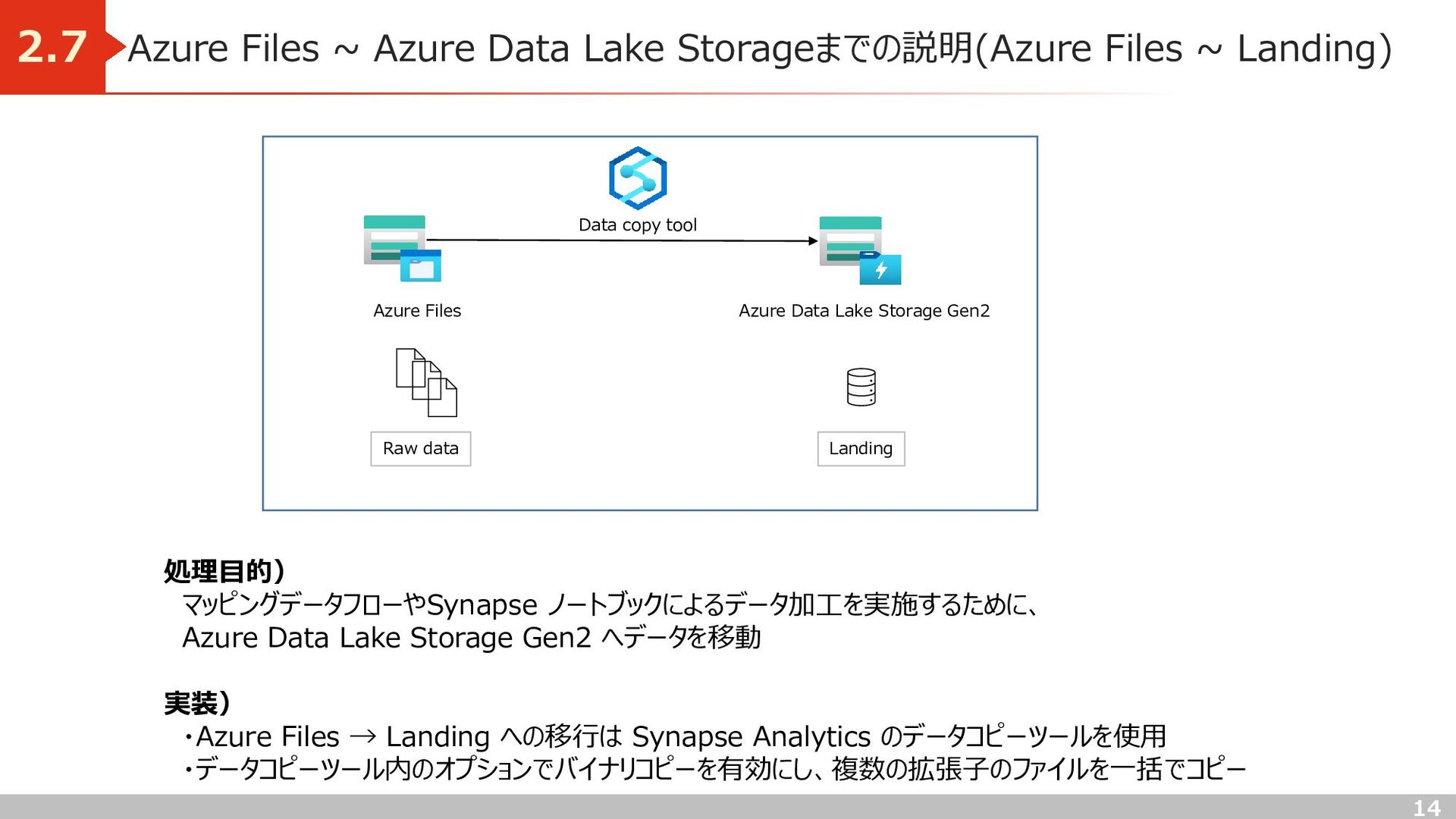
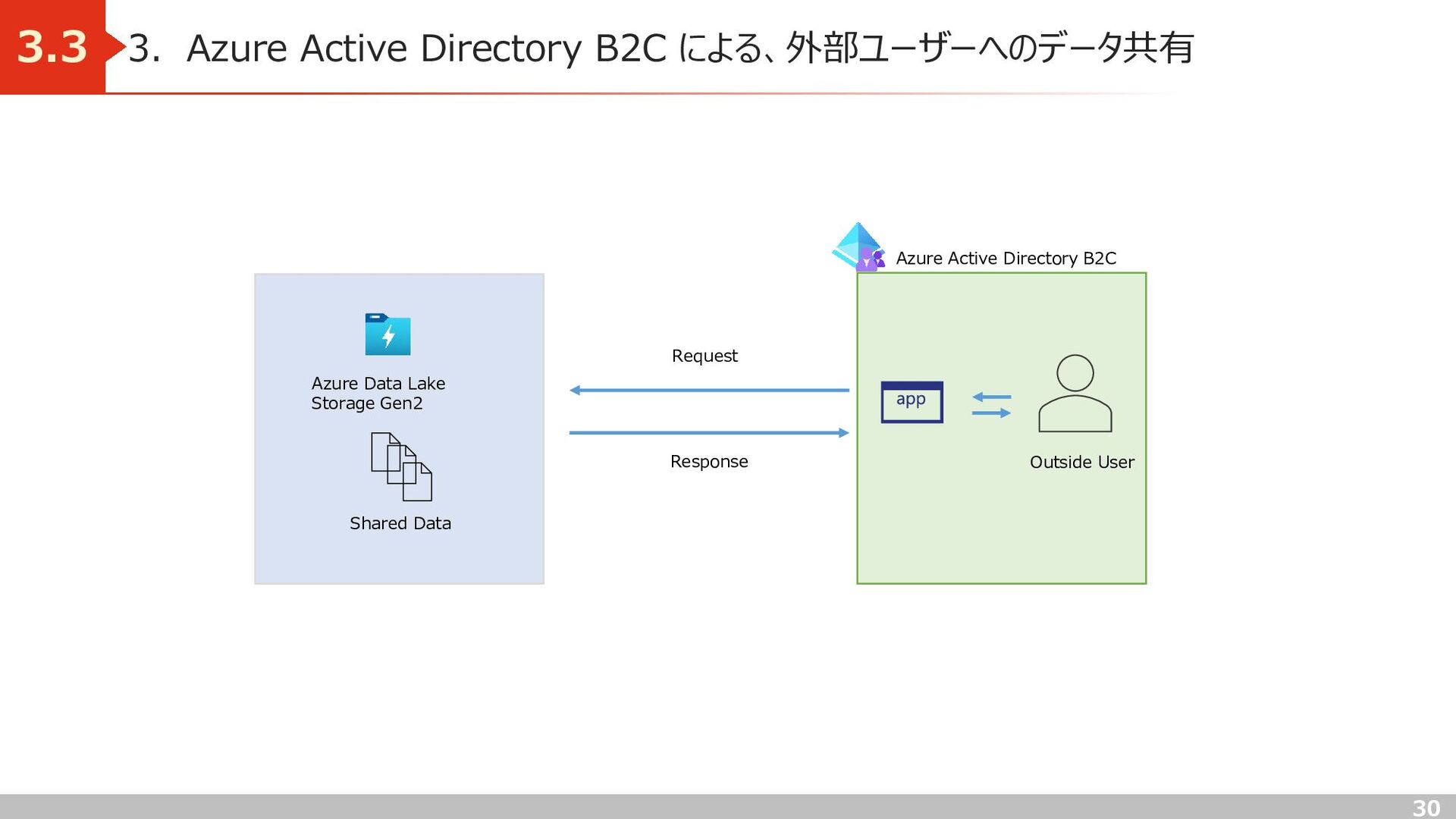
Landing) 2.7 処理目的) マッピングデータフローやSynapse ノートブックによるデータ加工を実施するために、 Azure Data Lake Storage Gen2 へデータを移動 実装) ・Azure Files → Landing への移行は Synapse Analytics のデータコピーツールを使用 ・データコピーツール内のオプションでバイナリコピーを有効にし、複数の拡張子のファイルを一括でコピー Azure Files Landing Azure Data Lake Storage Gen2 Raw data Data copy tool
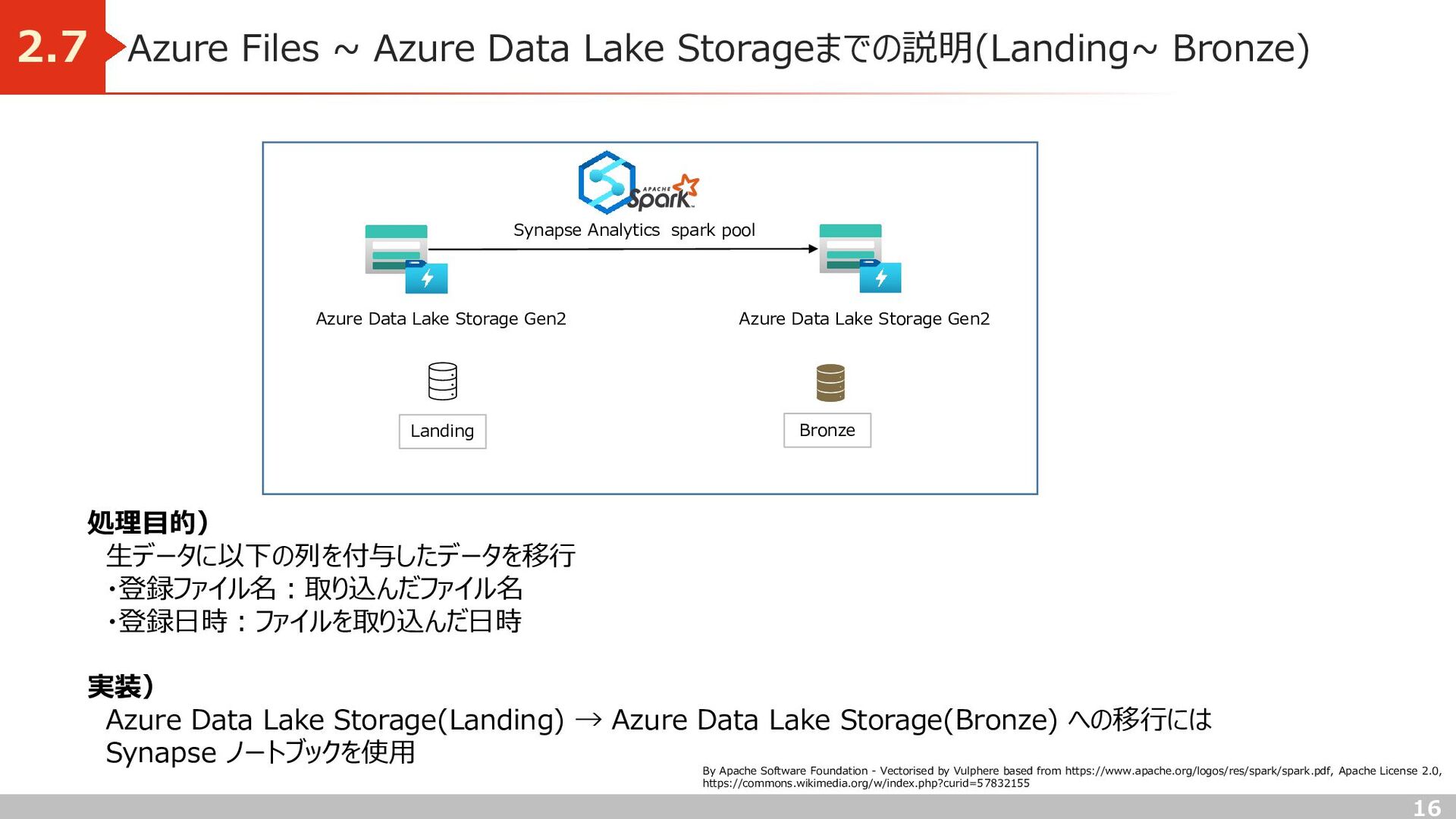
処理目的) 生データに以下の列を付与したデータを移行 ・登録ファイル名:取り込んだファイル名 ・登録日時:ファイルを取り込んだ日時 実装) Azure Data Lake Storage(Landing) → Azure Data Lake Storage(Bronze) への移行には Synapse ノートブックを使用 Azure Data Lake Storage Gen2 Bronze Azure Data Lake Storage Gen2 Synapse Analytics spark pool Landing By Apache Software Foundation - Vectorised by Vulphere based from https://www.apache.org/logos/res/spark/spark.pdf, Apache License 2.0, https://commons.wikimedia.org/w/index.php?curid=57832155
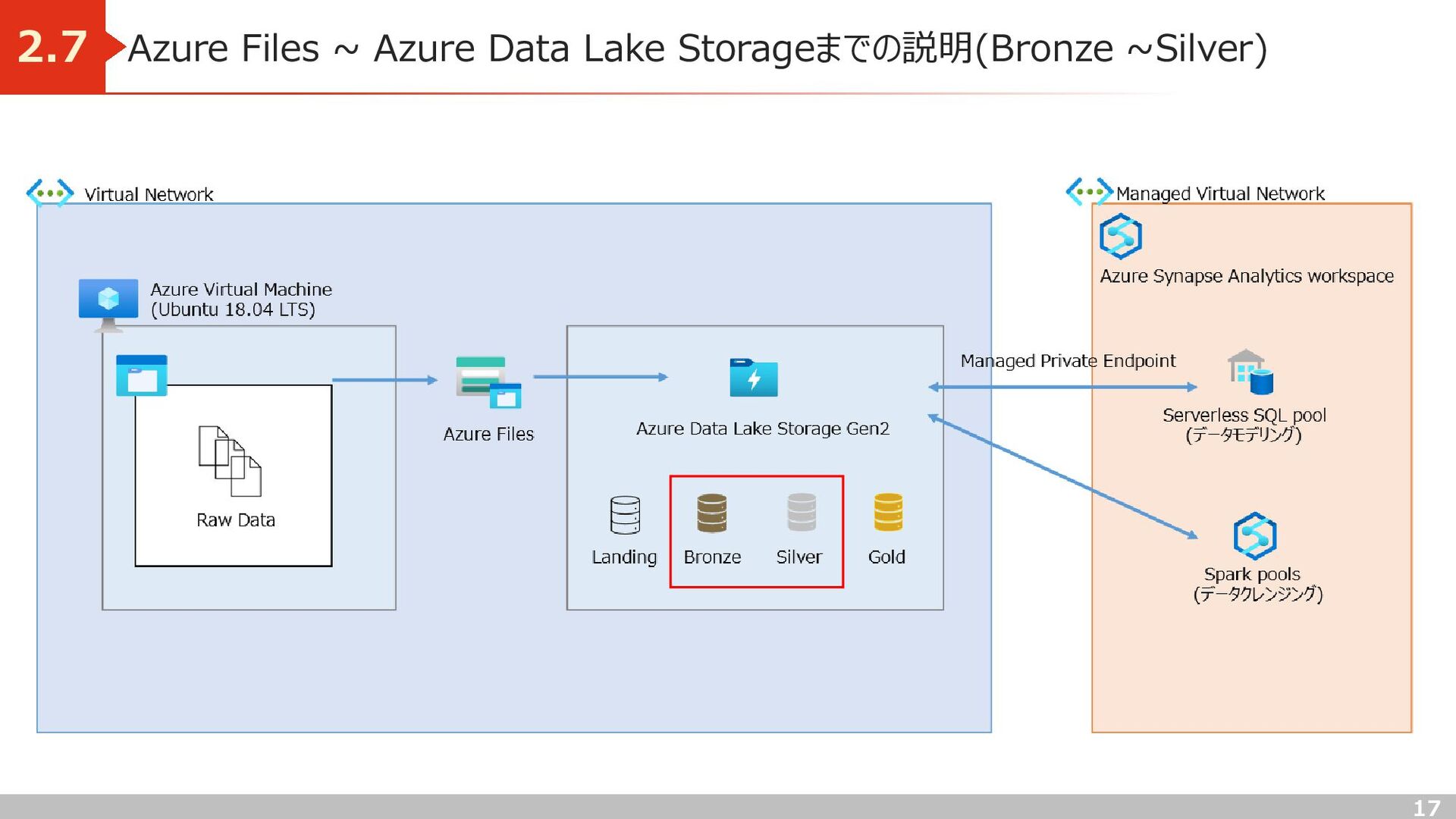
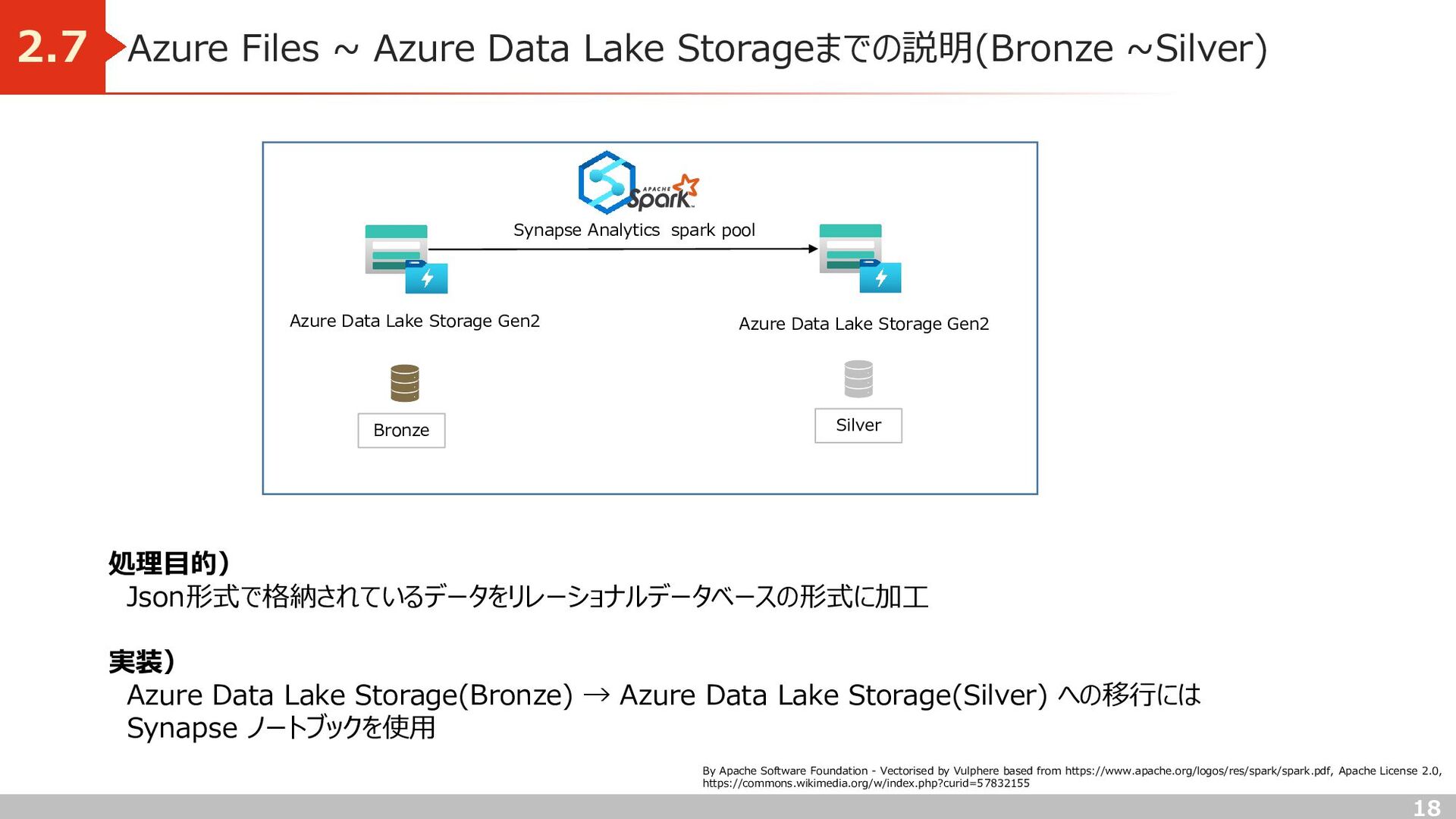
処理目的) Json形式で格納されているデータをリレーショナルデータベースの形式に加工 実装) Azure Data Lake Storage(Bronze) → Azure Data Lake Storage(Silver) への移行には Synapse ノートブックを使用 Azure Data Lake Storage Gen2 Bronze Azure Data Lake Storage Gen2 Synapse Analytics spark pool By Apache Software Foundation - Vectorised by Vulphere based from https://www.apache.org/logos/res/spark/spark.pdf, Apache License 2.0, https://commons.wikimedia.org/w/index.php?curid=57832155 Silver
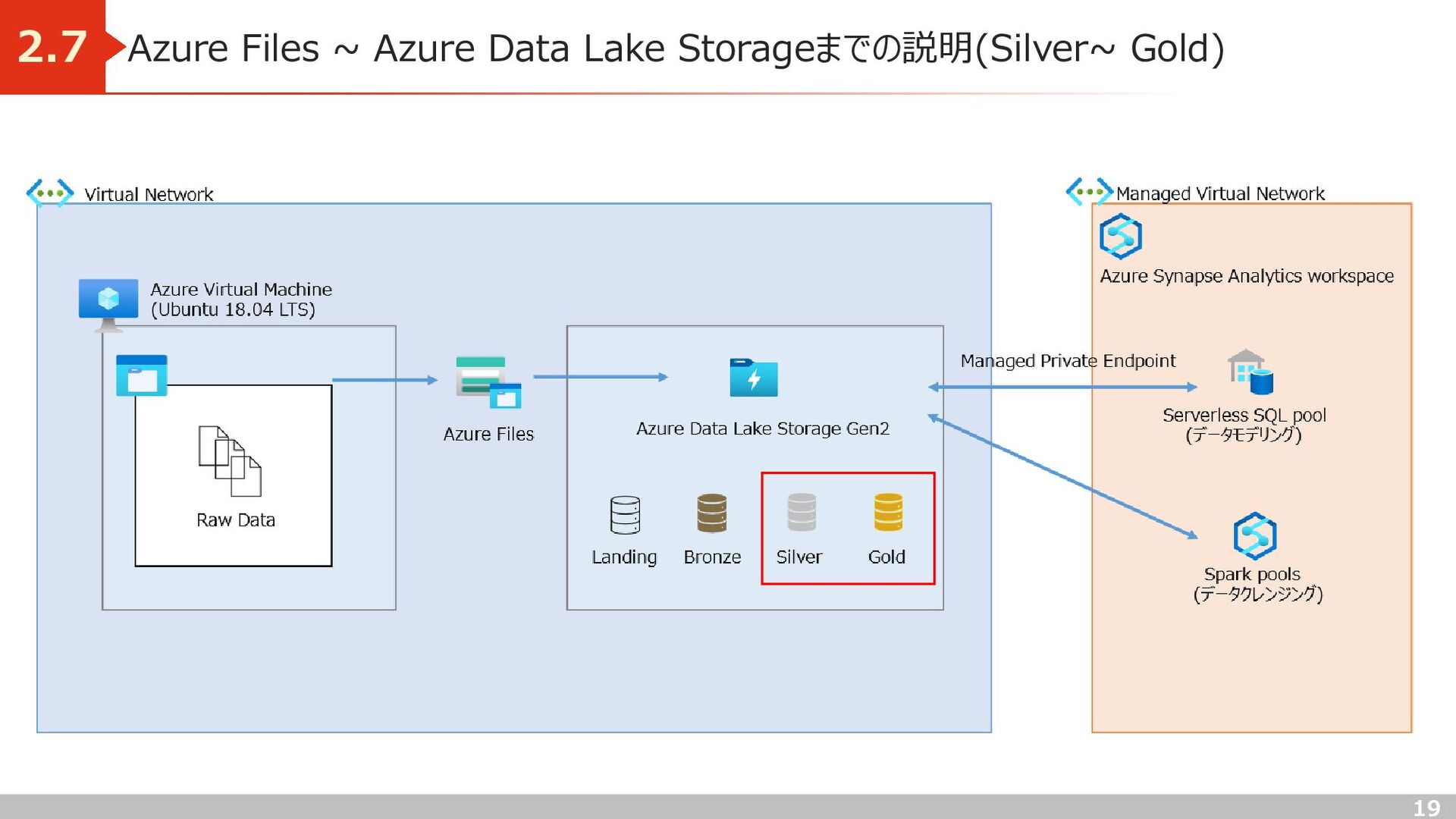
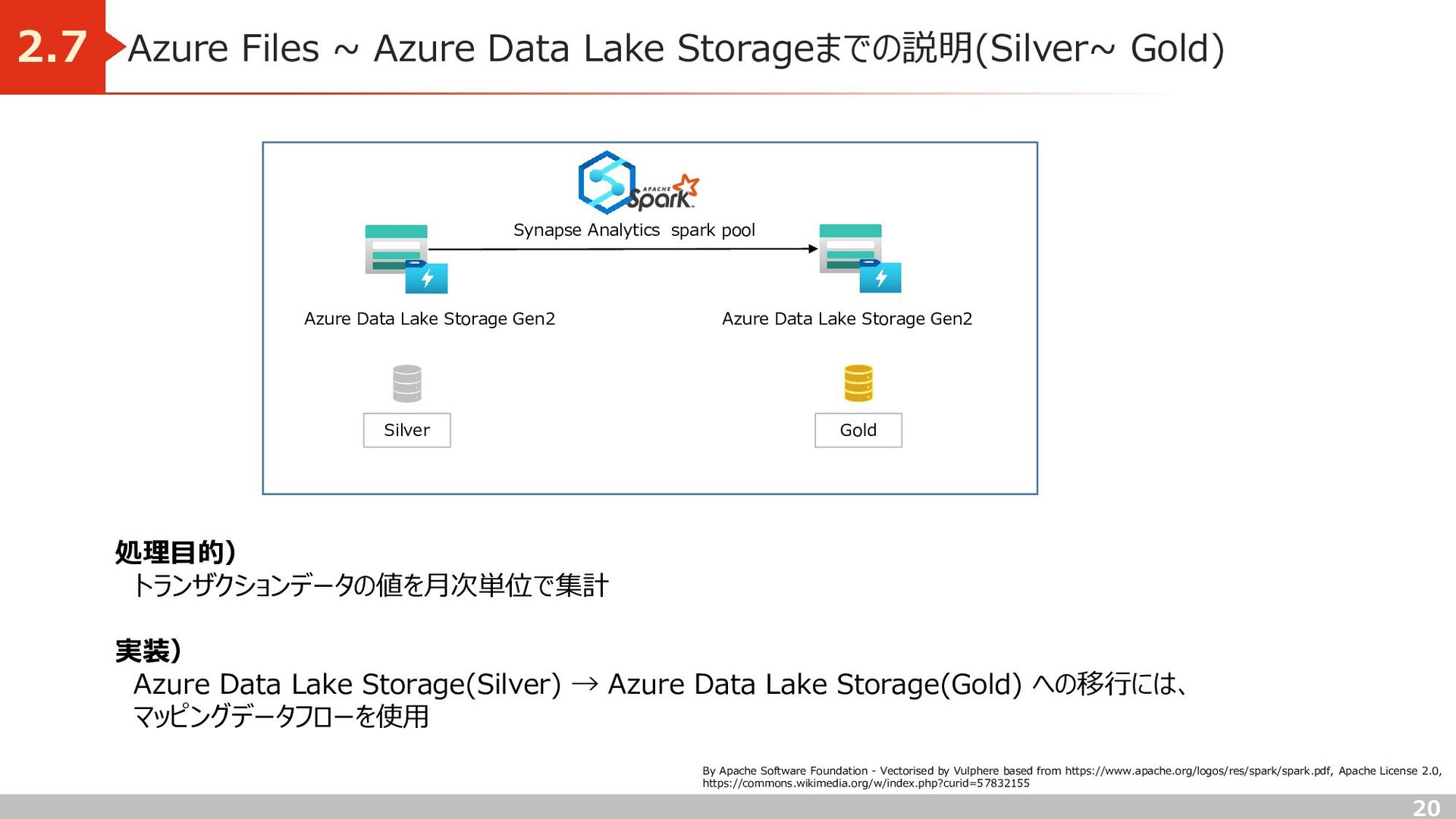
処理目的) トランザクションデータの値を月次単位で集計 実装) Azure Data Lake Storage(Silver) → Azure Data Lake Storage(Gold) への移行には、 マッピングデータフローを使用 Azure Data Lake Storage Gen2 Azure Data Lake Storage Gen2 Synapse Analytics spark pool By Apache Software Foundation - Vectorised by Vulphere based from https://www.apache.org/logos/res/spark/spark.pdf, Apache License 2.0, https://commons.wikimedia.org/w/index.php?curid=57832155 Silver Gold
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}