m i n ) 1 . 検 証 目 的 ・ 発 表 目 的 に つ い て 2 . 前 回 の セ ッ シ ョ ン 内 容 振 り 返 り 3 . 今 回 の セ ッ シ ョ ン 内 容 に つ い て 2 . 本 題 ( 2 0 m i n ) 1 . 本 検 証 前 提 条 件 説 明 1 . 検 証 シ ナ リ オ 2 . ソ ー ス デ ー タ 1 . S h i f t 1 5 M ( 初 期 デ ー タ ・ 日 次 デ ー タ ) 2 . 天 気 デ ー タ ( o p e n w e a t h e r ) 2 . ア ー キ テ ク チ ャ 概 要 説 明 1 . ア ー キ テ ク チ ャ 全 体 像 2 . ア ー キ テ ク チ ャ 概 要 ( デ ー タ レ イ ク ) 3 . ア ー キ テ ク チ ャ 概 要 ( S t r e a m i n g ) 4 . 参 考 文 献 紹 介 3 . ア ー キ テ ク チ ャ 詳 細 説 明 ( デ ー タ 蓄 積 【 B a t c h レ イ ヤ 】 ) 1 . S o u r c e t o r a w ( L a n d i n g ) 2 . r a w ( L a n d i n g t o C o n f o r m a n c e ) 3 . r a w ( C o n f o r m a n c e ) t o e n r i c h e d / c u r a t e d ( S t a n d a r i z e d ) 4 . e n r i c h e d / c u r a t e d ( S t a n d a r i z e d t o c u r a t e d ) 4 . ア ー キ テ ク チ ャ 詳 細 説 明 ( デ ー タ 蓄 積 【 S p e e d レ イ ヤ 】 ) 1 . S o u r c e t o E v e n t H u b 2 . E v e n t H u b t o D a t a E x p l o e r 5 . T i p s ( 実 際 に 実 装 し て 困 っ た と こ ろ ・ う ま く い っ た と こ ろ ) 3 . 運 用 し て み て ( 5 m i n ) 1 . B a t c h レ イ ヤ 1 . 初 期 移 行 時 の 各 パ フ ォ ー マ ン ス 2 . 日 次 デ ー タ の 各 パ フ ォ ー マ ン ス 2 . S p e e d レ イ ヤ 1 . 天 気 デ ー タ の 各 パ フ ォ ー マ ン ス 4 . ご 相 談 ( 時 間 が 余 れ ば 、 、 ) 1 . デ ー タ レ イ ク の パ ー テ ィ シ ョ ン の 分 割 に つ い て
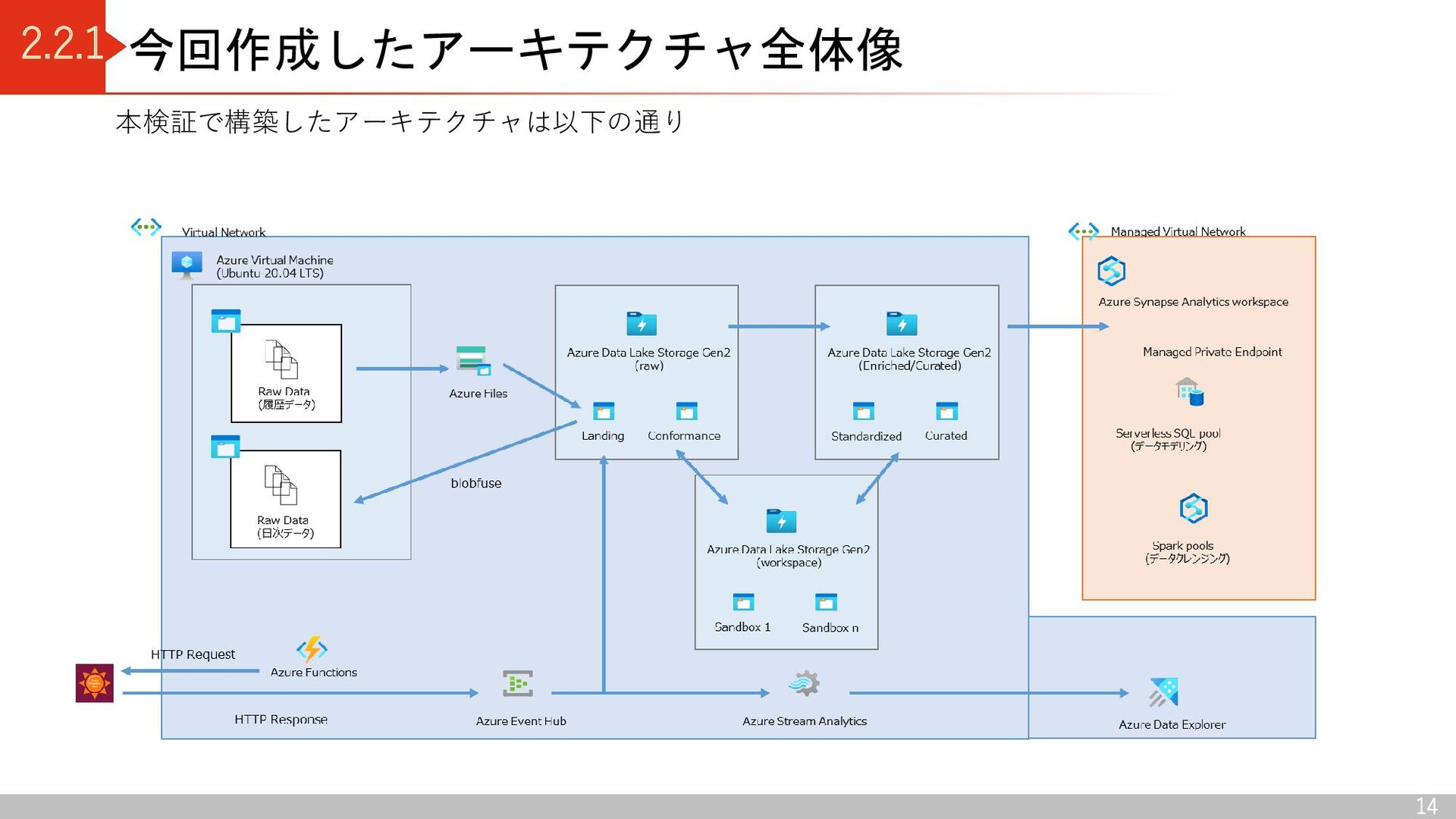
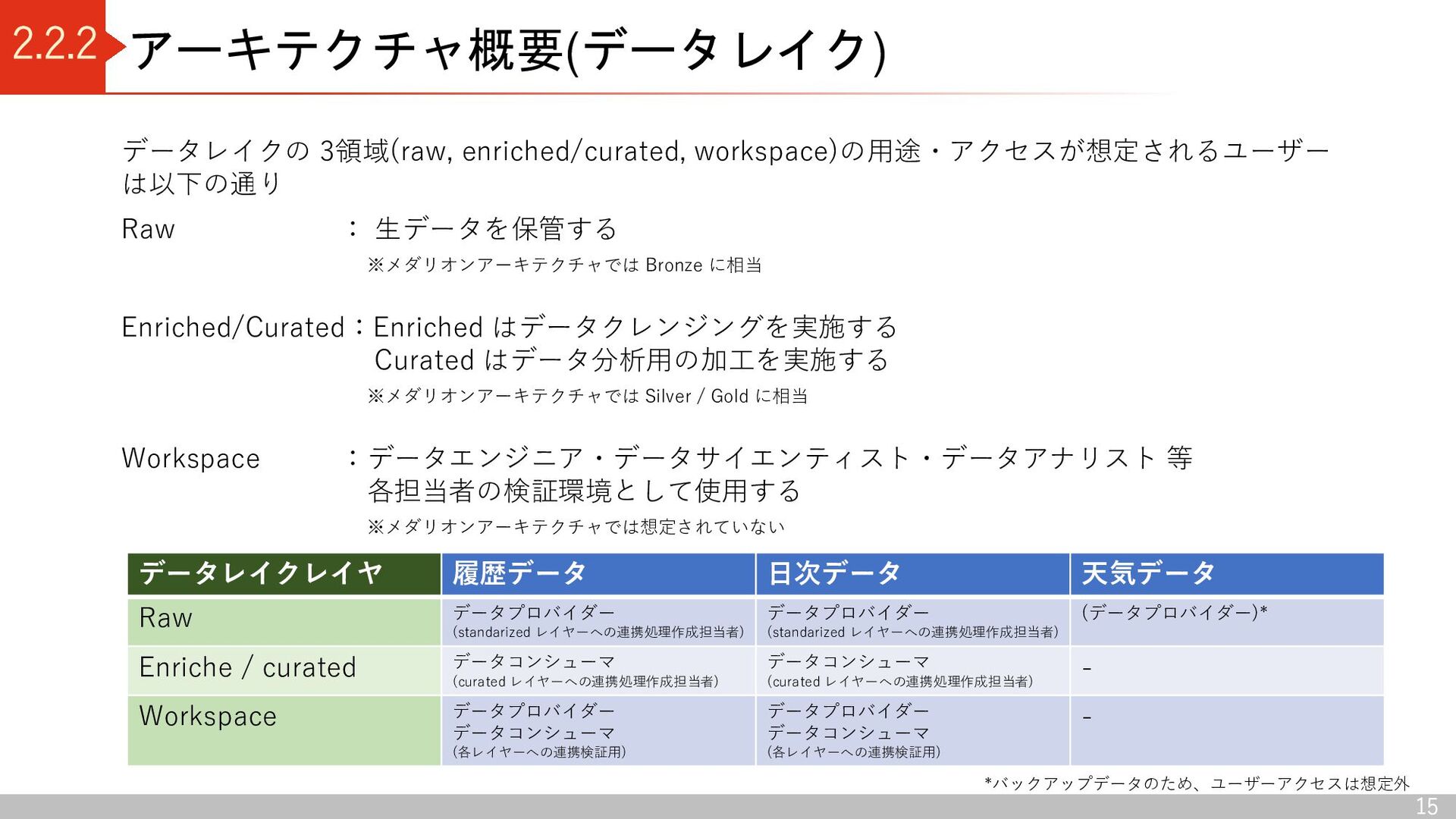
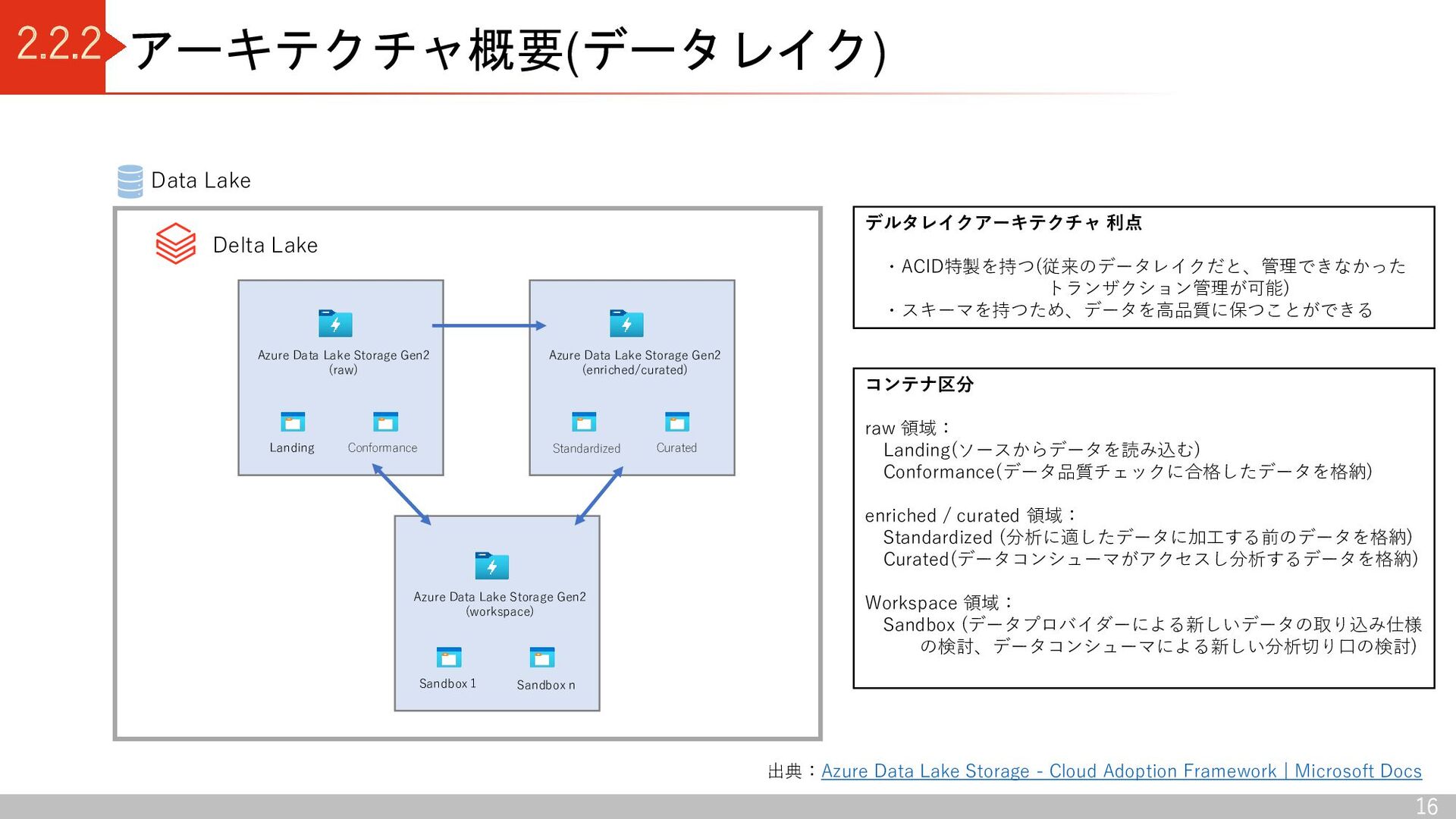
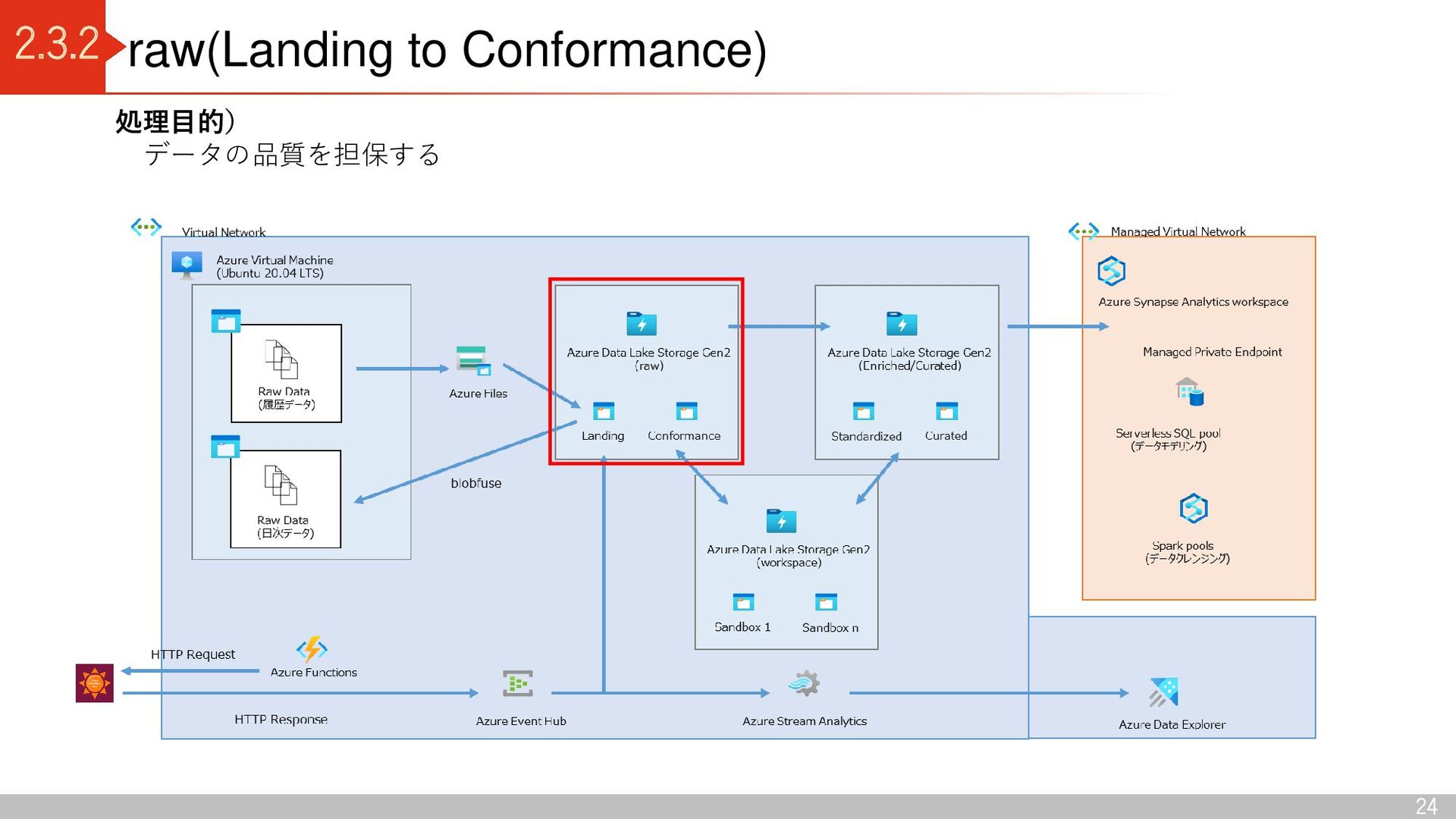
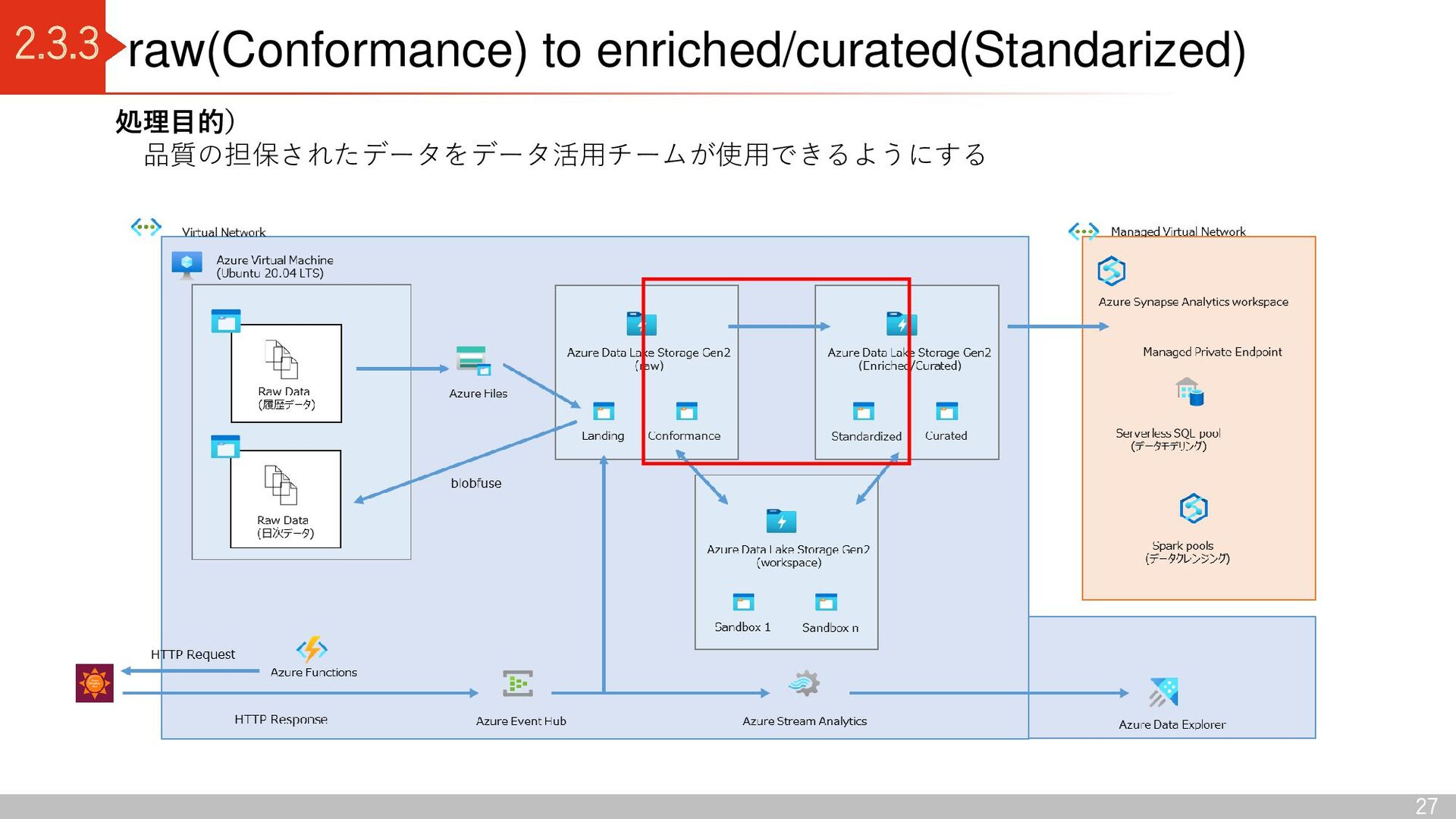
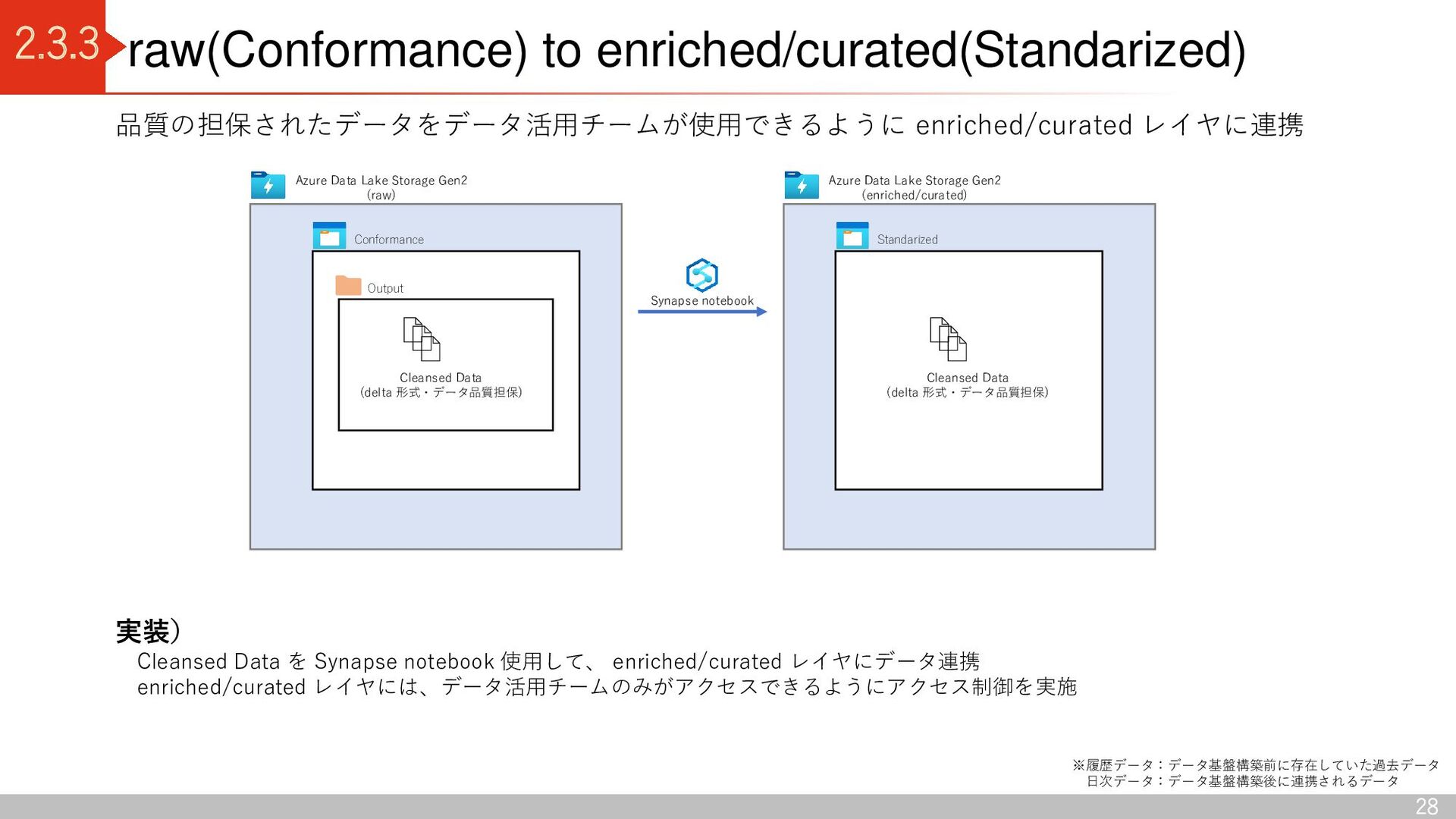
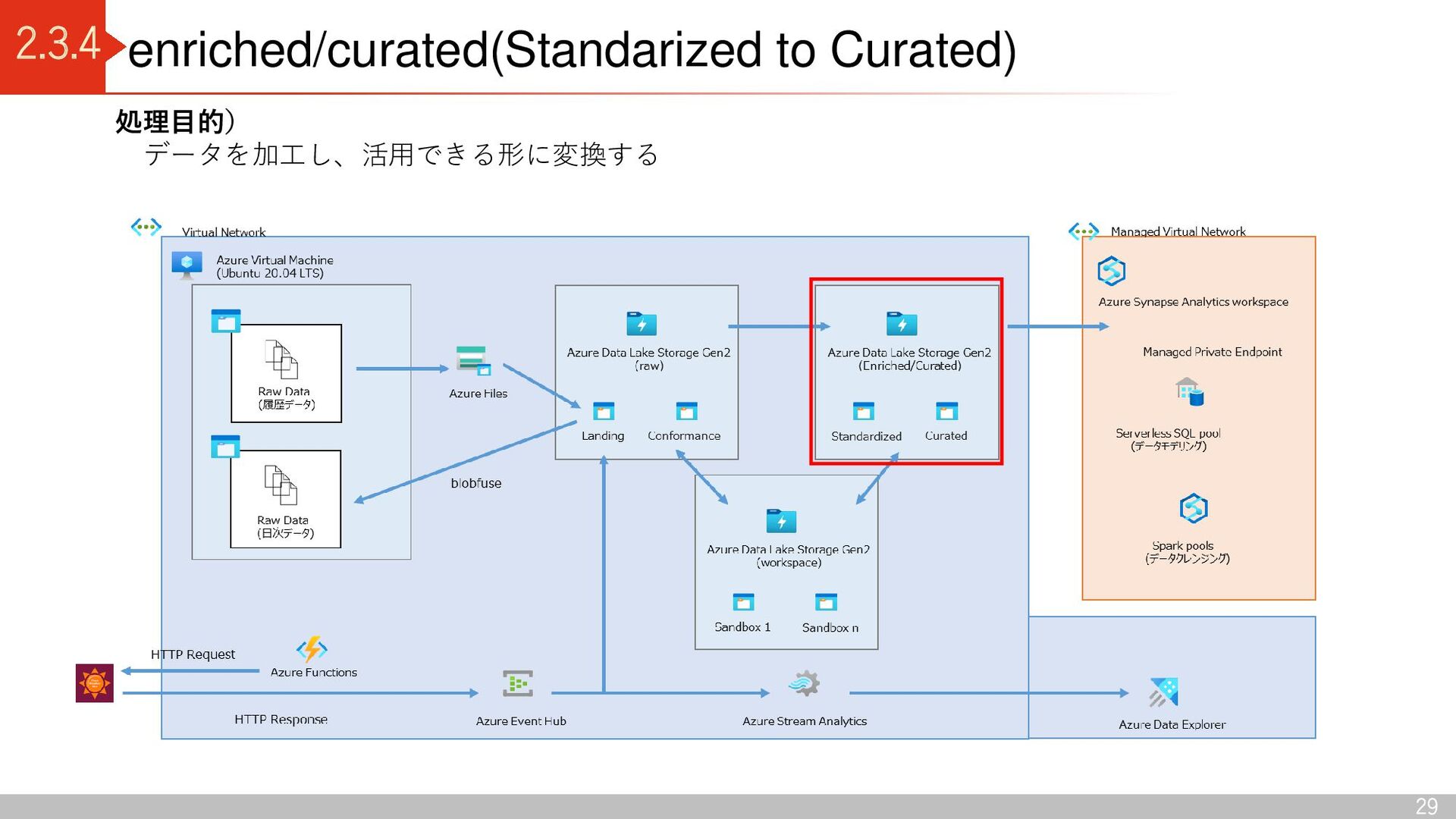
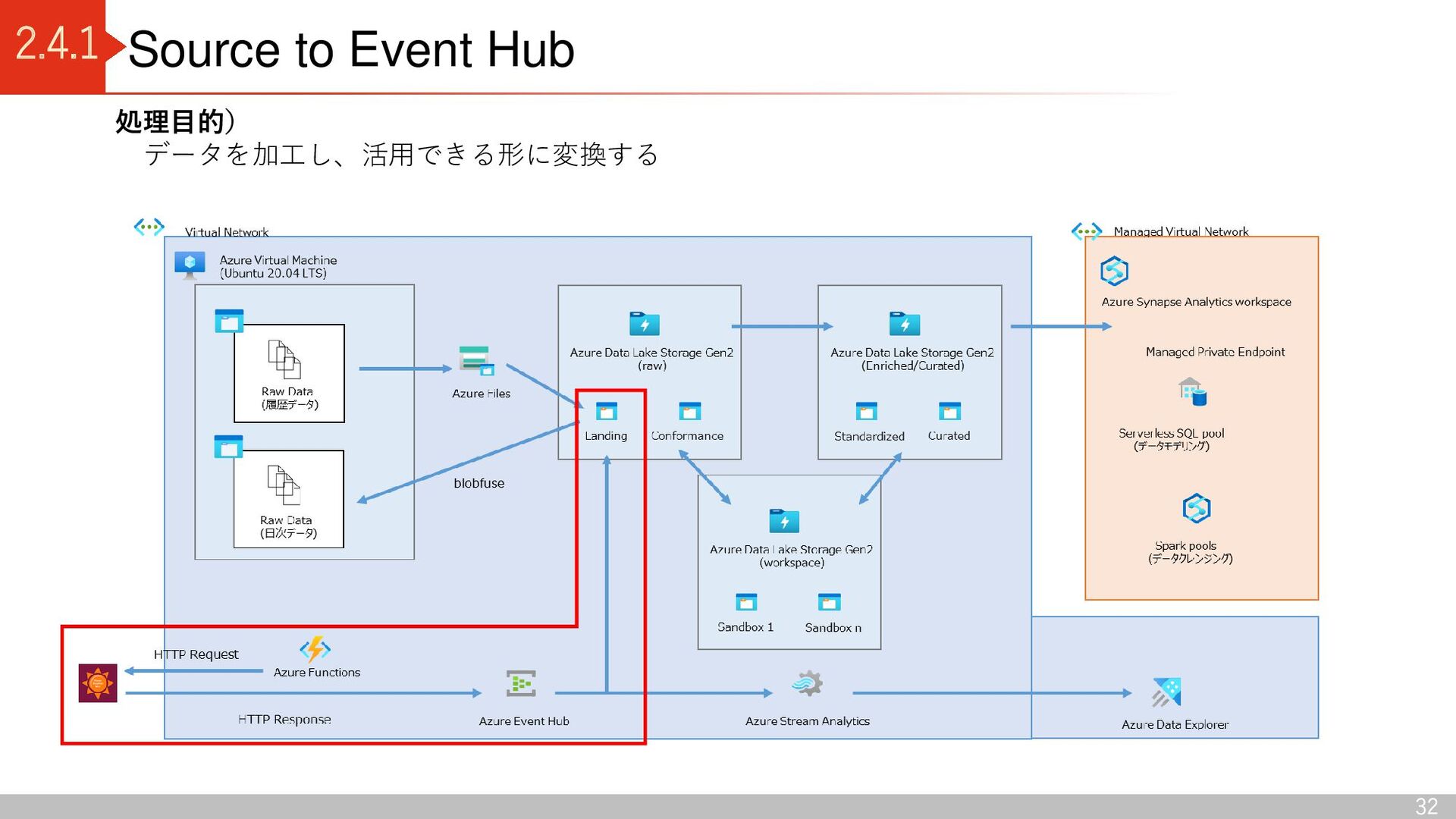
Conformance Azure Data Lake Storage Gen2 (enriched/curated) Standardized Curated Azure Data Lake Storage Gen2 (workspace) Sandbox 1 Sandbox n Data Lake 出典:Azure Data Lake Storage - Cloud Adoption Framework | Microsoft Docs Delta Lake コンテナ区分 raw 領域: Landing(ソースからデータを読み込む) Conformance(データ品質チェックに合格したデータを格納) enriched / curated 領域: Standardized (分析に適したデータに加工する前のデータを格納) Curated(データコンシューマがアクセスし分析するデータを格納) Workspace 領域: Sandbox (データプロバイダーによる新しいデータの取り込み仕様 の検討、データコンシューマによる新しい分析切り口の検討) デルタレイクアーキテクチャ 利点 ・ACID特製を持つ(従来のデータレイクだと、管理できなかった トランザクション管理が可能) ・スキーマを持つため、データを高品質に保つことができる
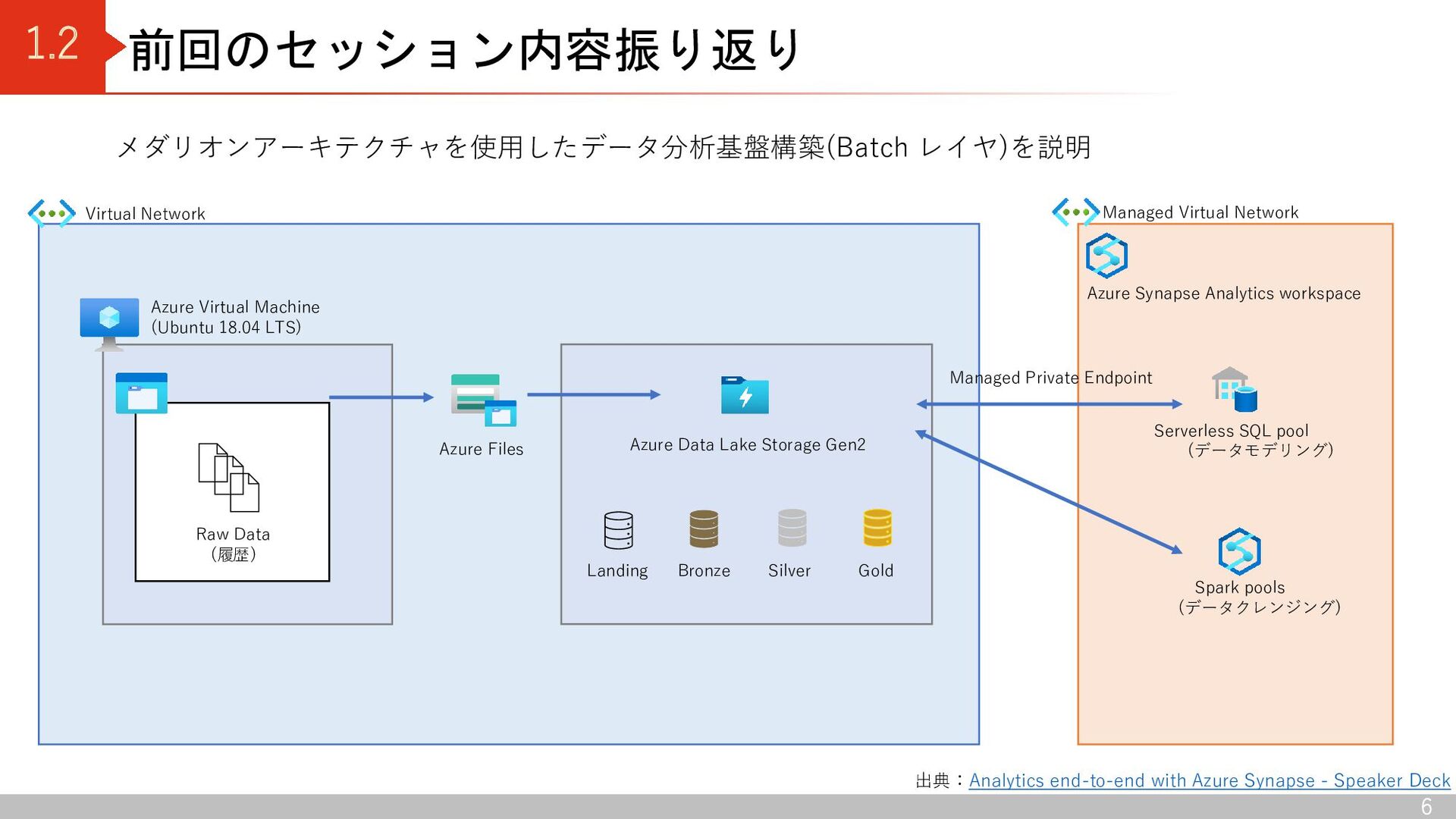
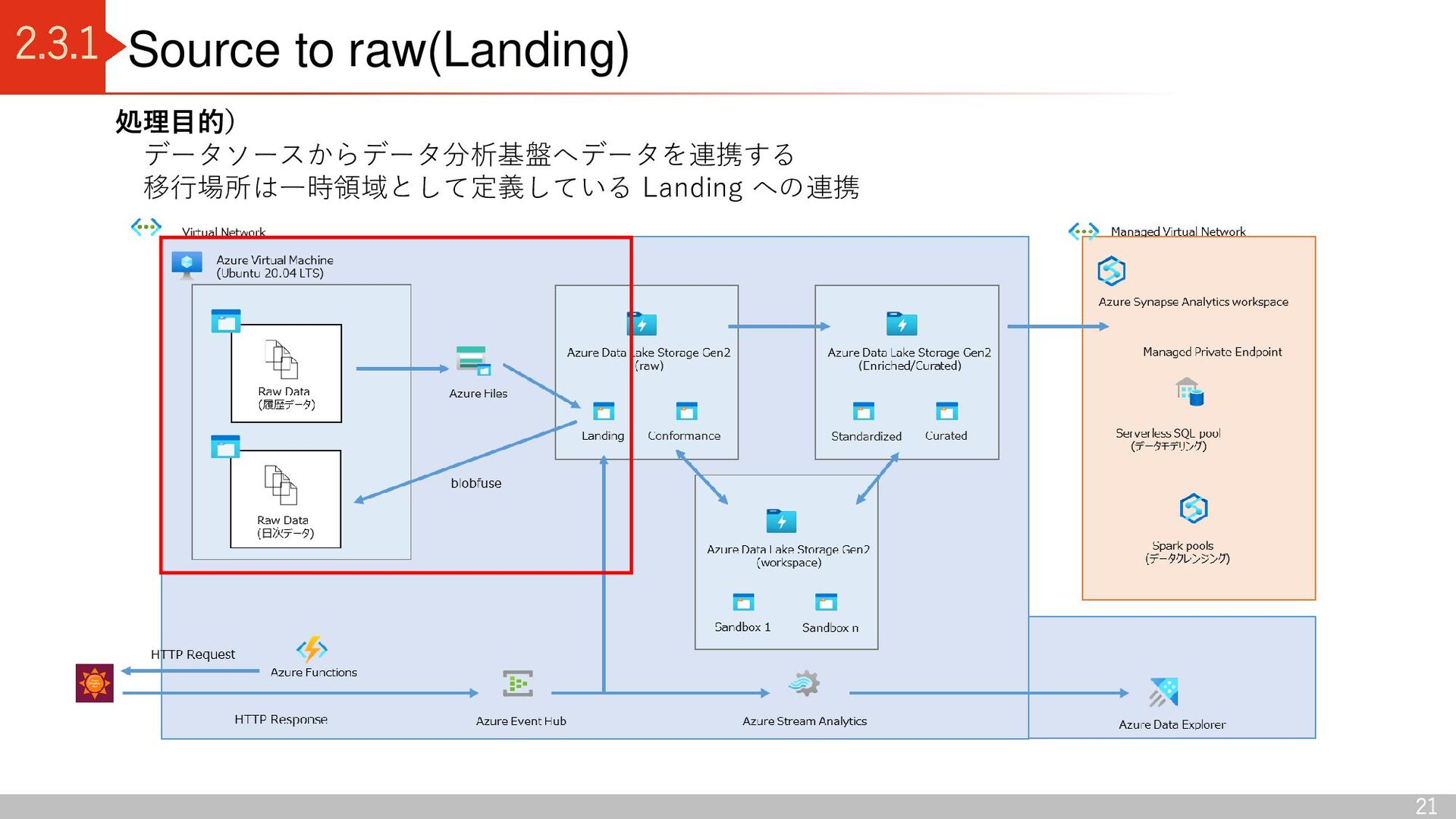
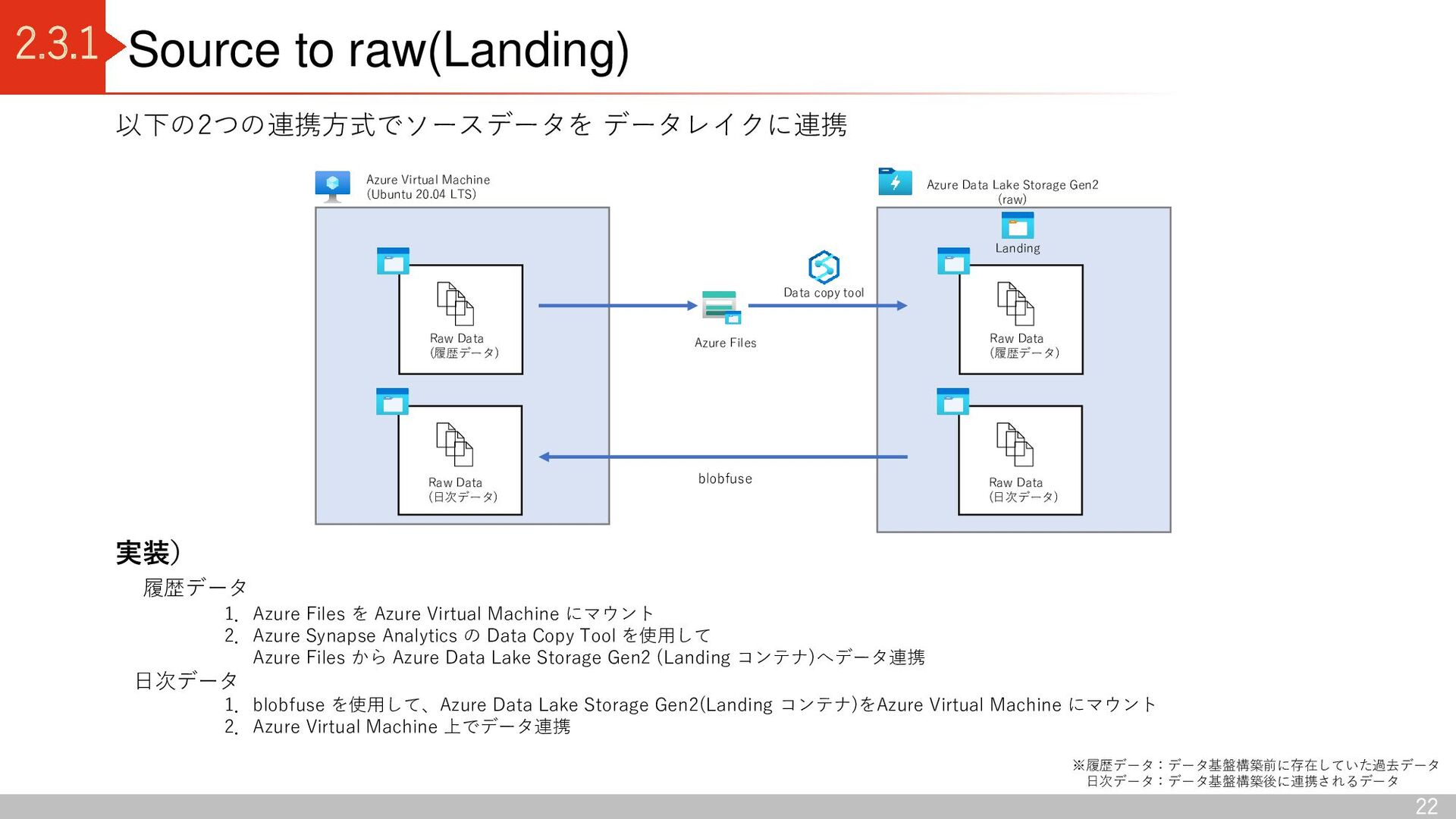
Azure Virtual Machine にマウント 2.Azure Synapse Analytics の Data Copy Tool を使用して Azure Files から Azure Data Lake Storage Gen2 (Landing コンテナ)へデータ連携 日次データ 1.blobfuse を使用して、Azure Data Lake Storage Gen2(Landing コンテナ)をAzure Virtual Machine にマウント 2.Azure Virtual Machine 上でデータ連携 Azure Files Azure Data Lake Storage Gen2 (raw) Raw Data (履歴データ) Landing Azure Virtual Machine (Ubuntu 20.04 LTS) Raw Data (日次データ) blobfuse 以下の2つの連携方式でソースデータを データレイクに連携 Data copy tool ※履歴データ:データ基盤構築前に存在していた過去データ 日次データ:データ基盤構築後に連携されるデータ Raw Data (履歴データ) Raw Data (日次データ)
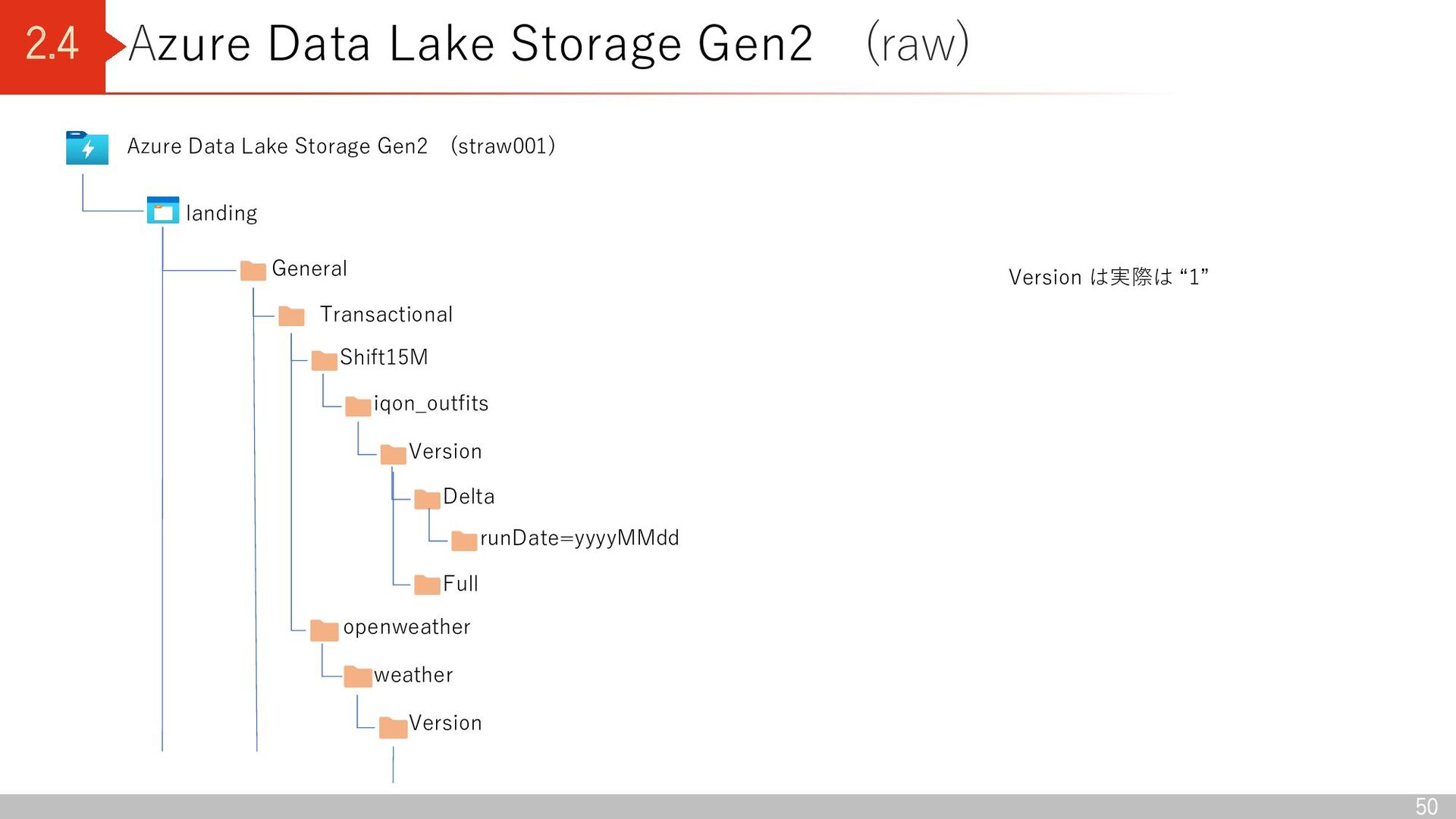
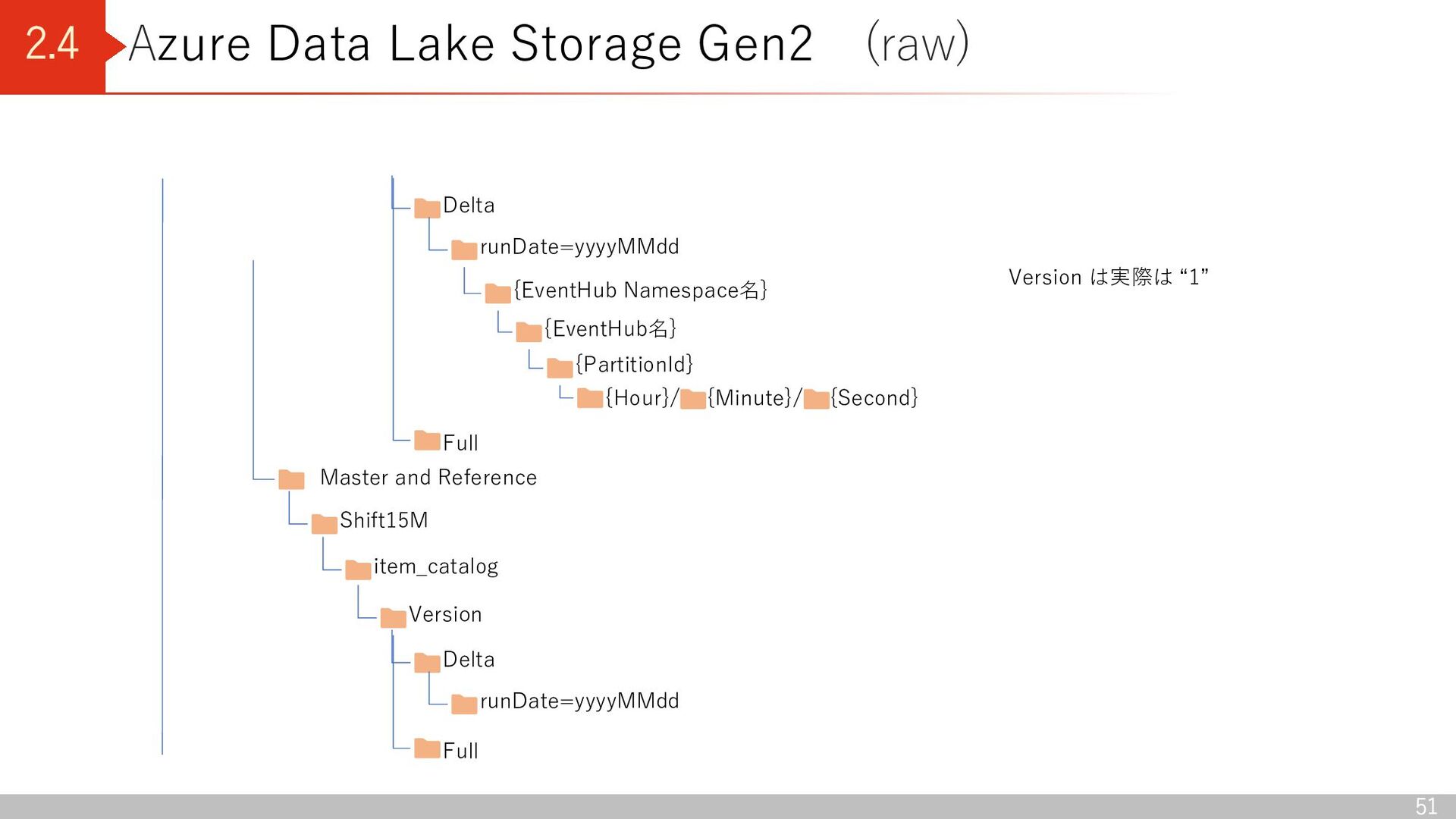
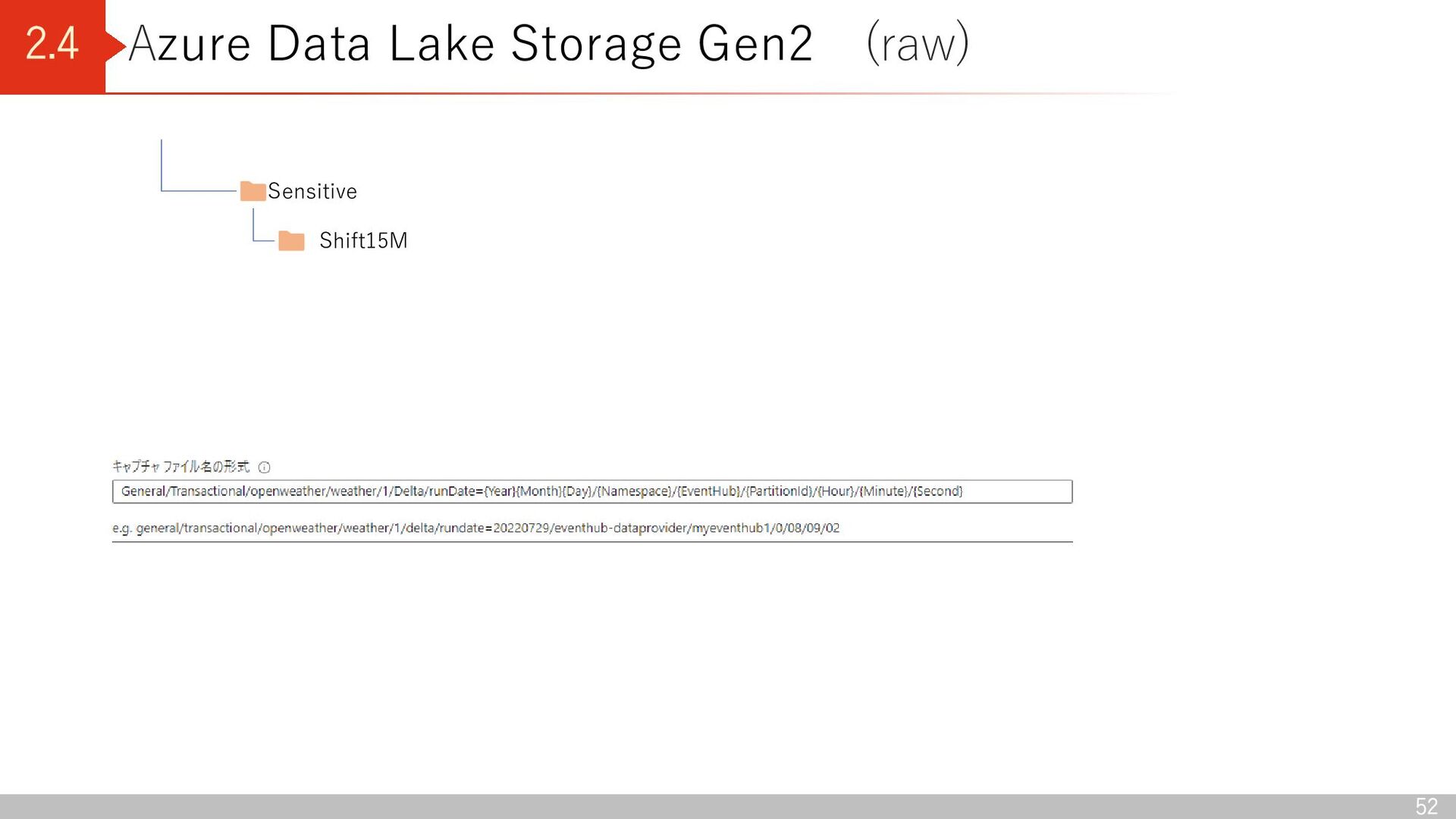
Lake Storage Gen2 (straw001) landing General Transactional Shift15M iqon_outfits Version Delta runDate=yyyyMMdd Full openweather weather Version Version は実際は “1”
Reference Shift15M item_catalog Version Delta runDate=yyyyMMdd Full Delta runDate=yyyyMMdd Full Version は実際は “1” {EventHub Namespace名} {EventHub名} {PartitionId} {Hour}/ {Minute}/ {Second}
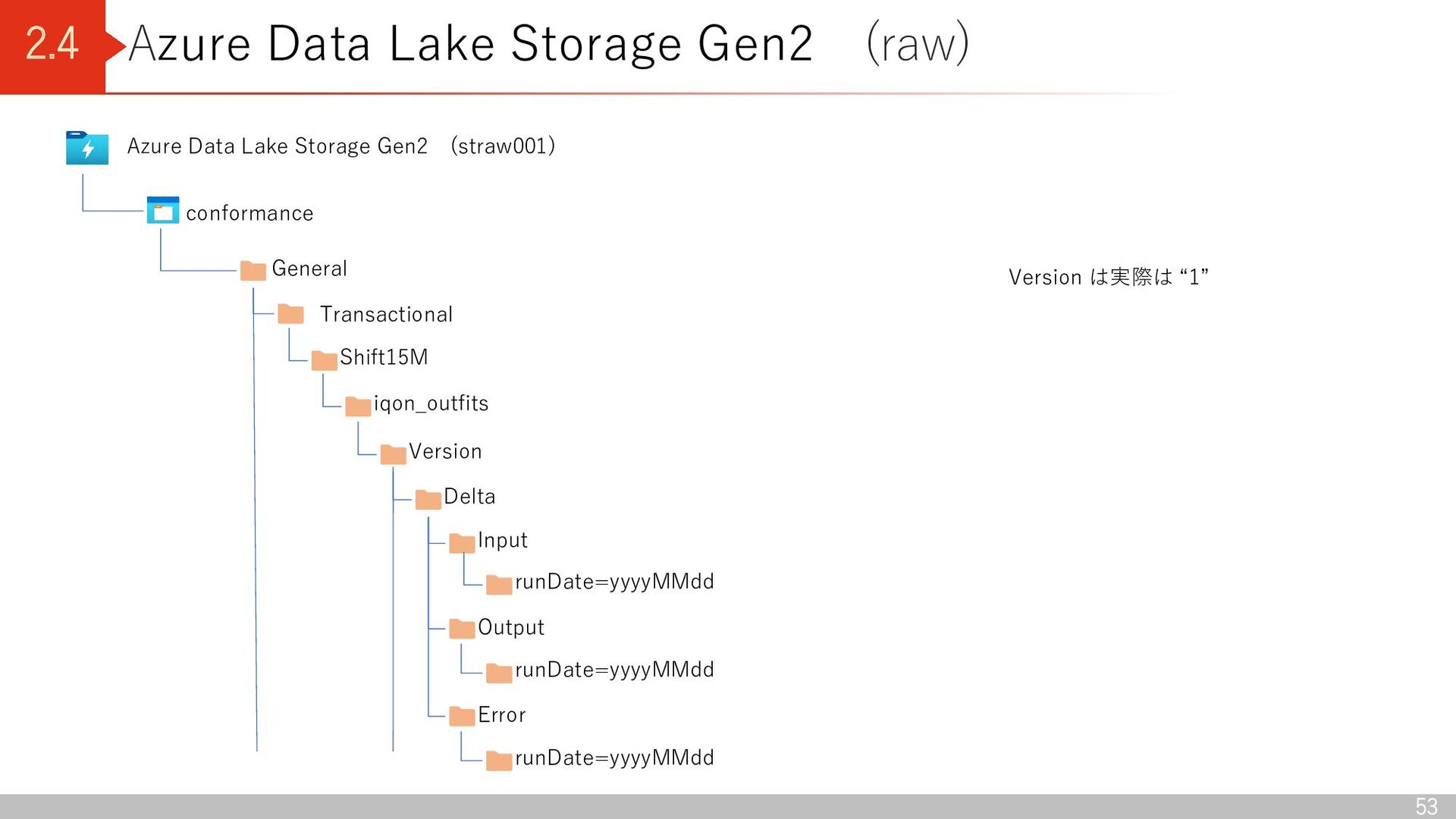
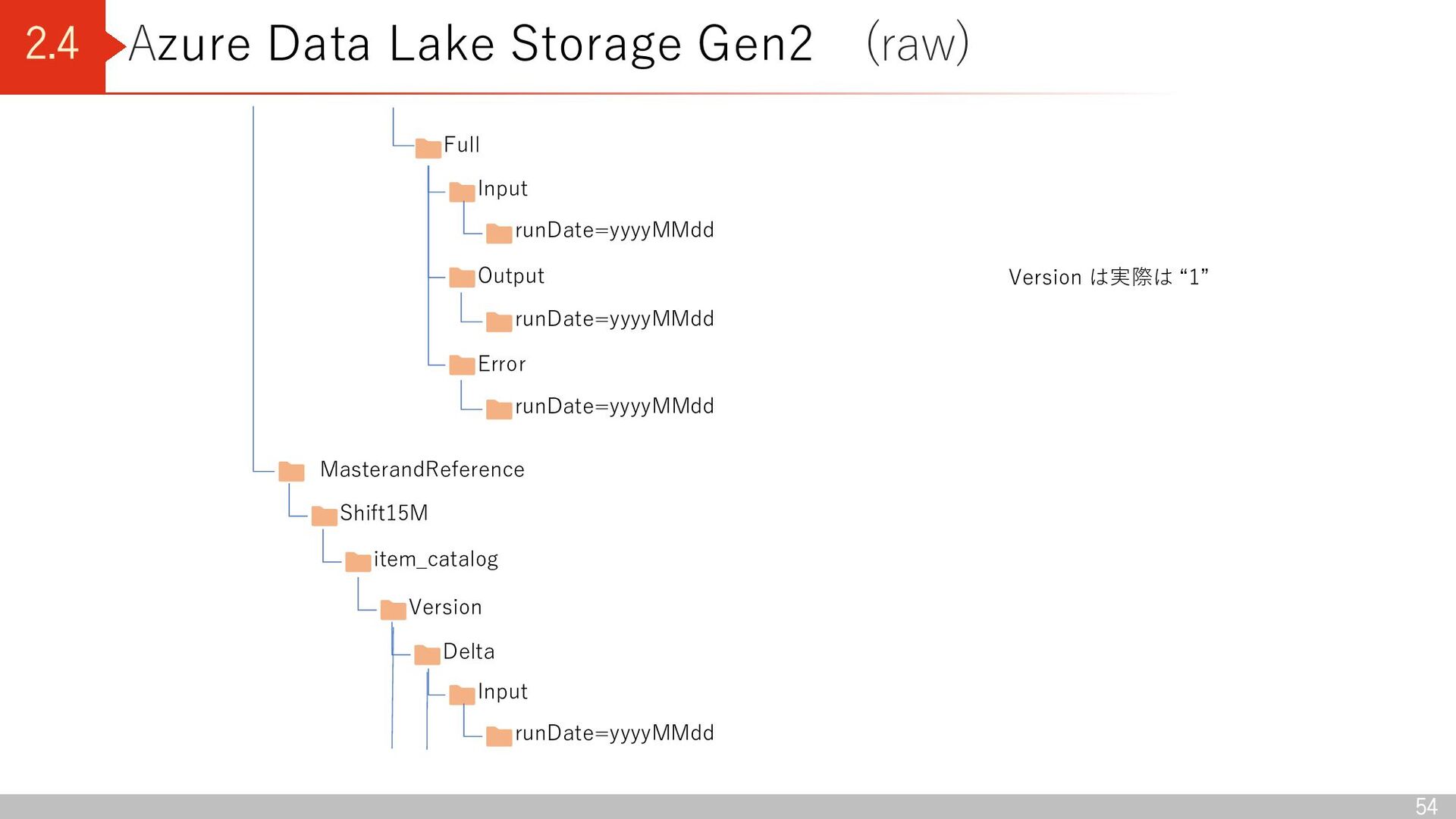
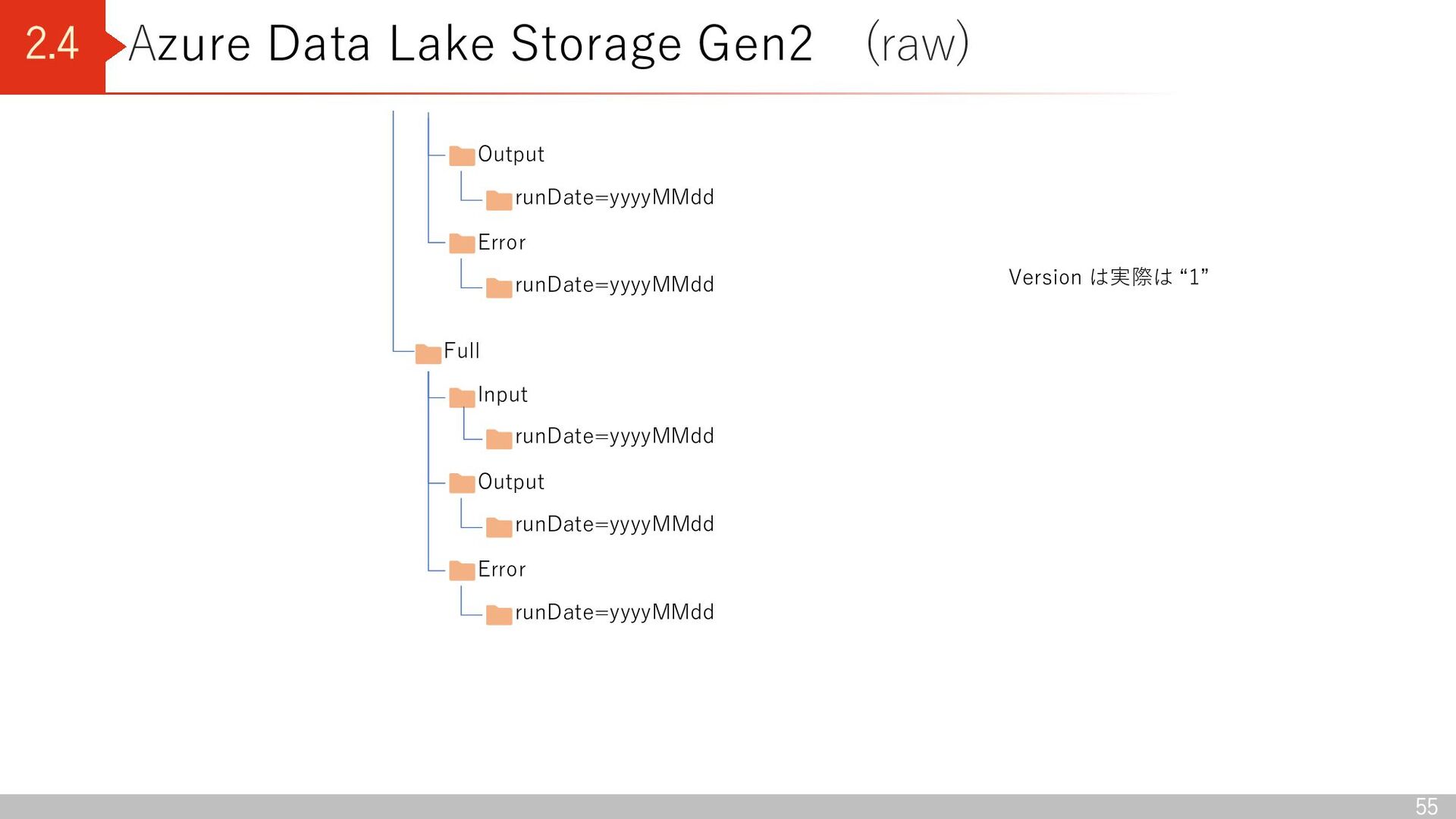
Lake Storage Gen2 (straw001) conformance General Transactional Shift15M iqon_outfits Version Input runDate=yyyyMMdd Output runDate=yyyyMMdd Error runDate=yyyyMMdd Delta Version は実際は “1”
Lake Storage Gen2 (Enriched/Curated) Standardrized General Transactional Shift15M iqon_outfits Version createDate=yyyyMMdd item_catalog Version createDate=yyyyMMdd Shift15M MasterandReference Version は実際は “1”
Lake Storage Gen2 (Enriched/Curated) Curated AnalyticsTeam dimention item_catalog Version aggDate=yyyyMMdd iqon_outfits Version aggDate=yyyyMMdd fact Version は実際は “1”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}