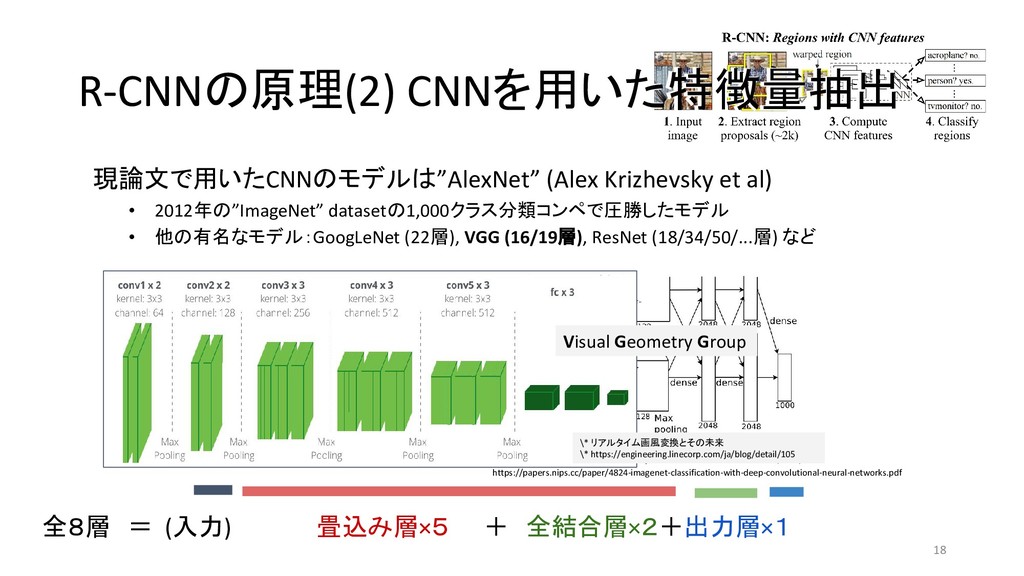
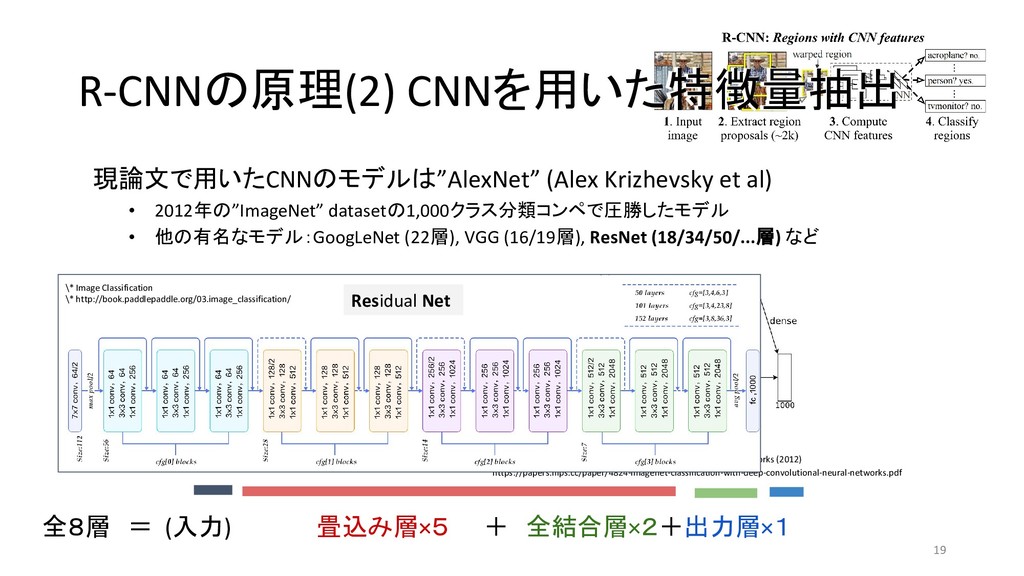
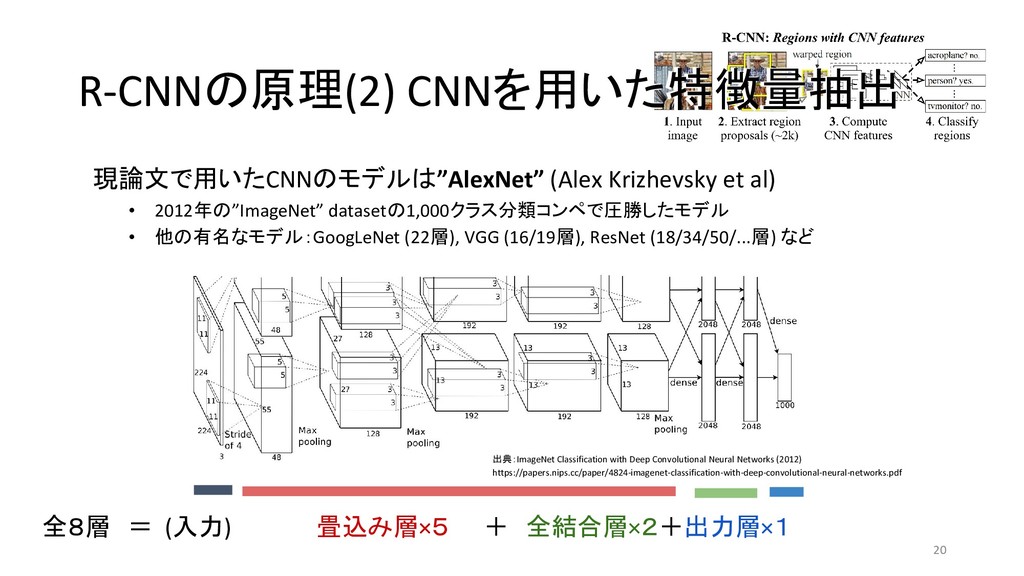
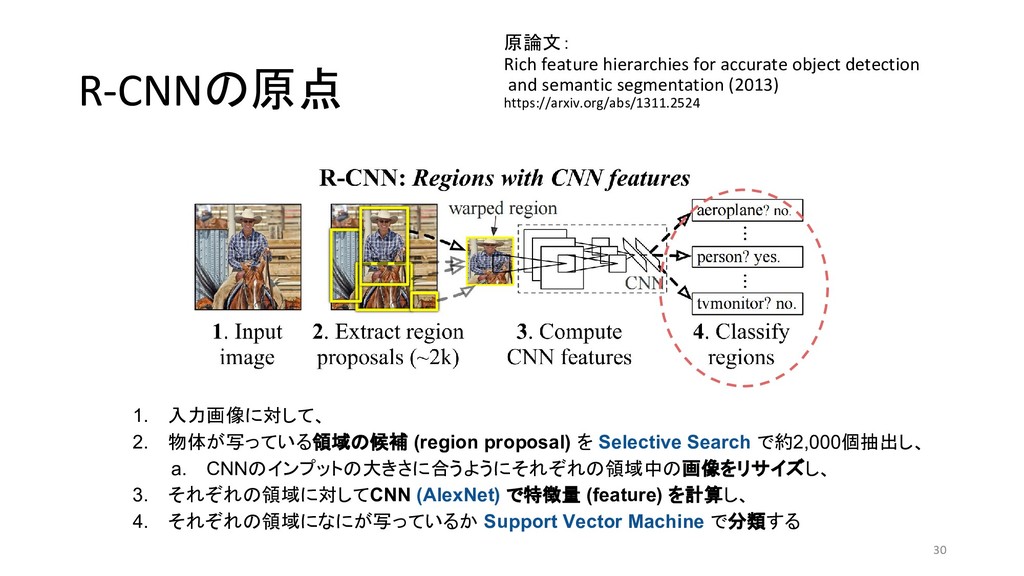
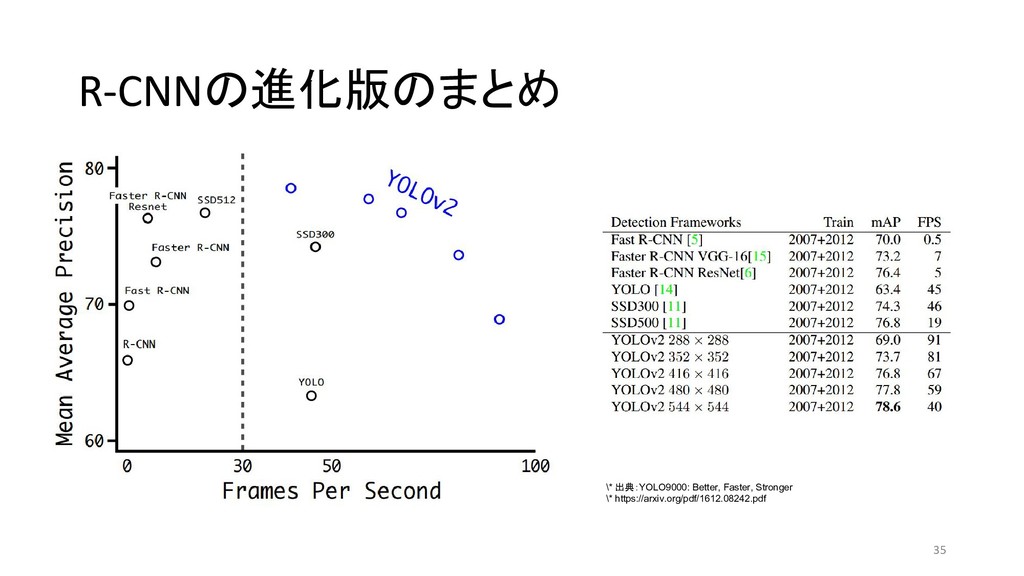
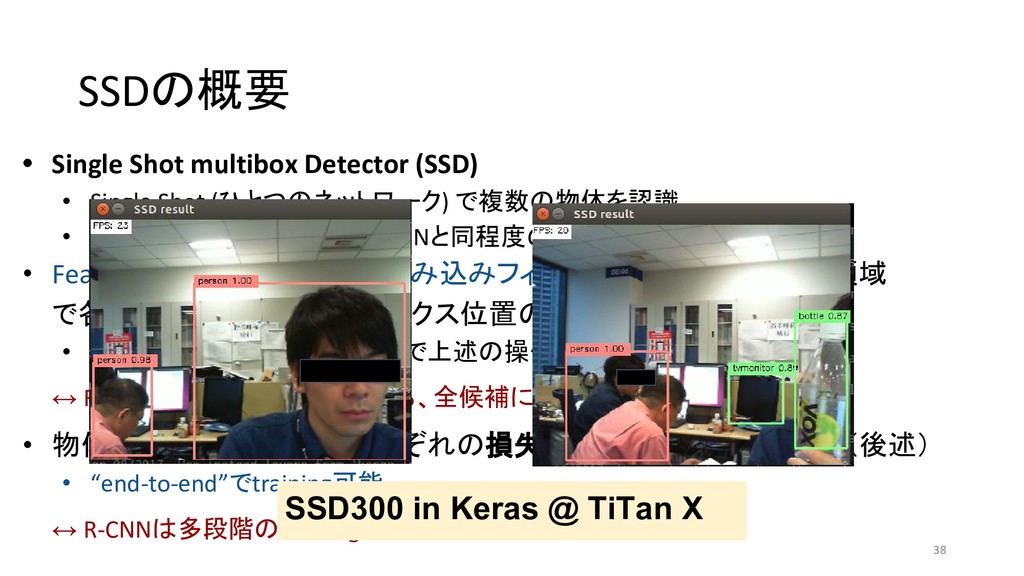
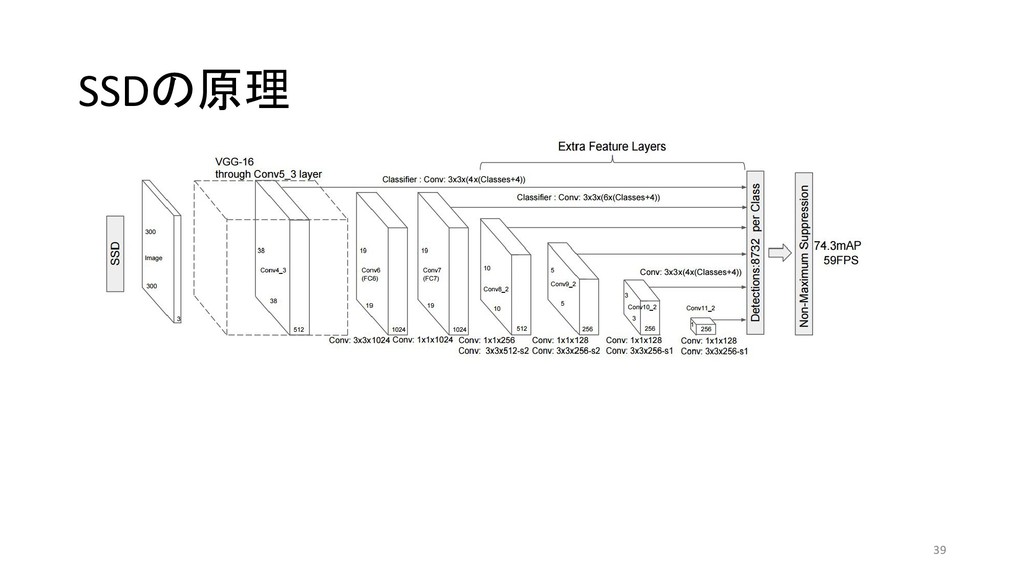
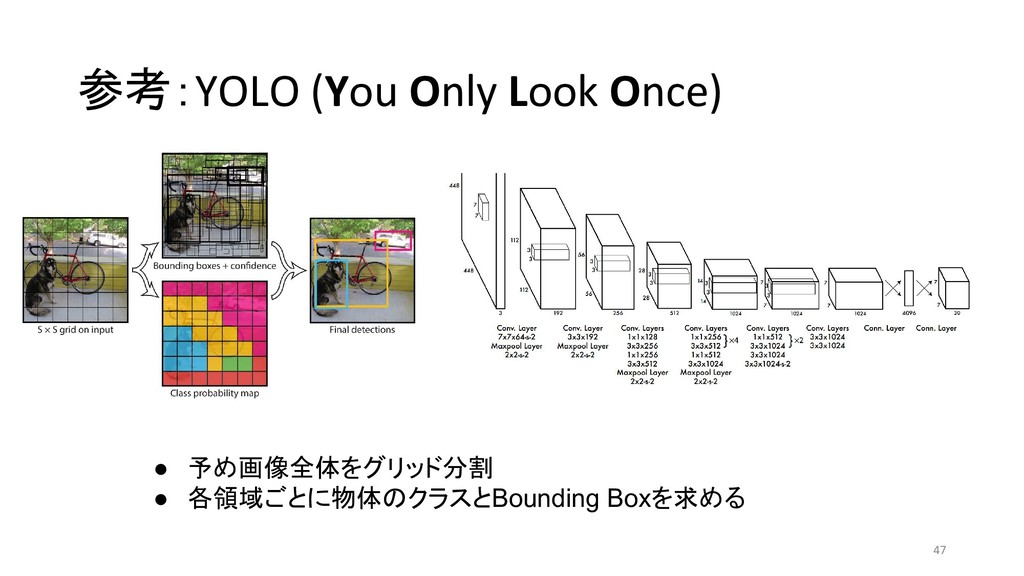
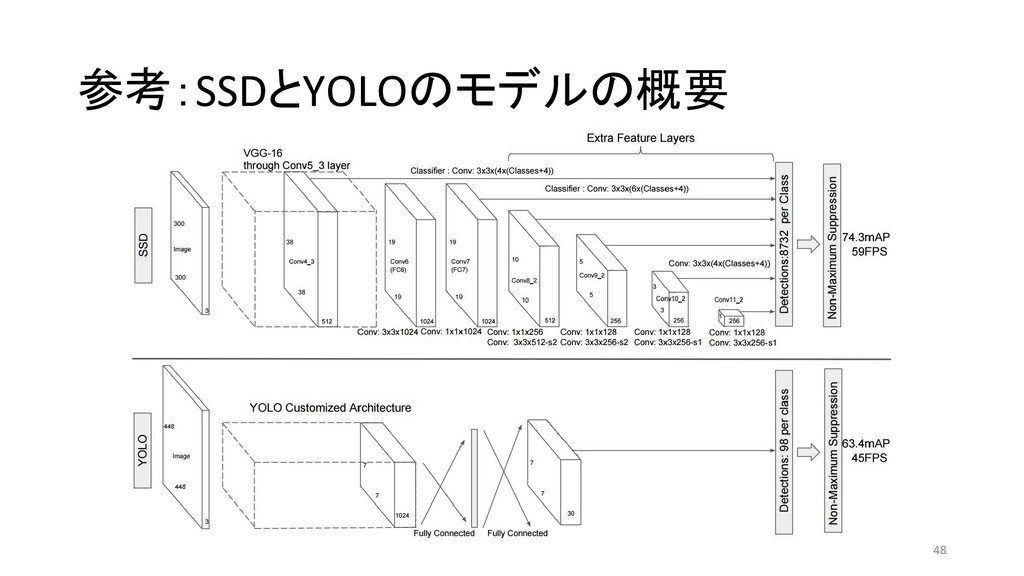
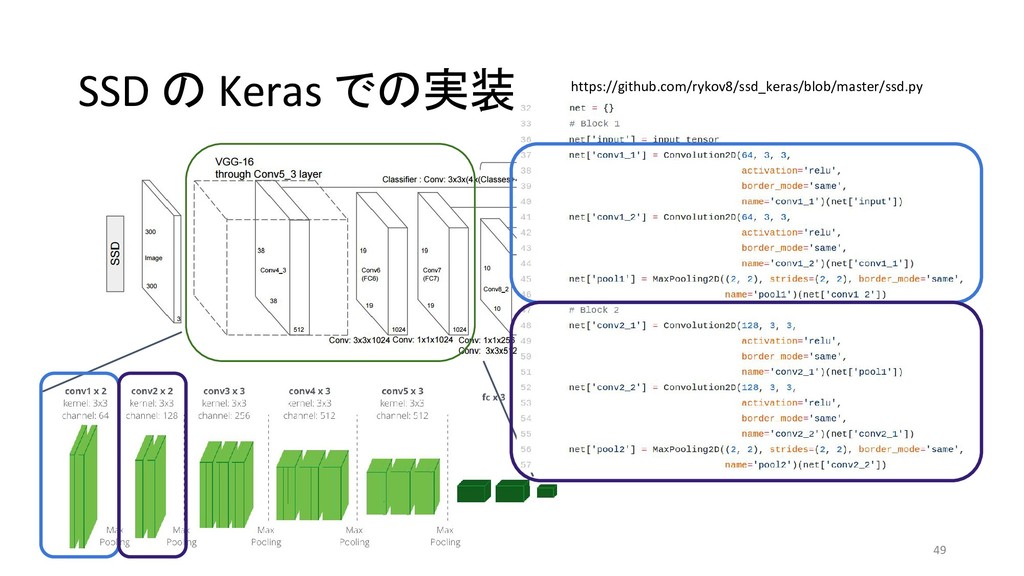
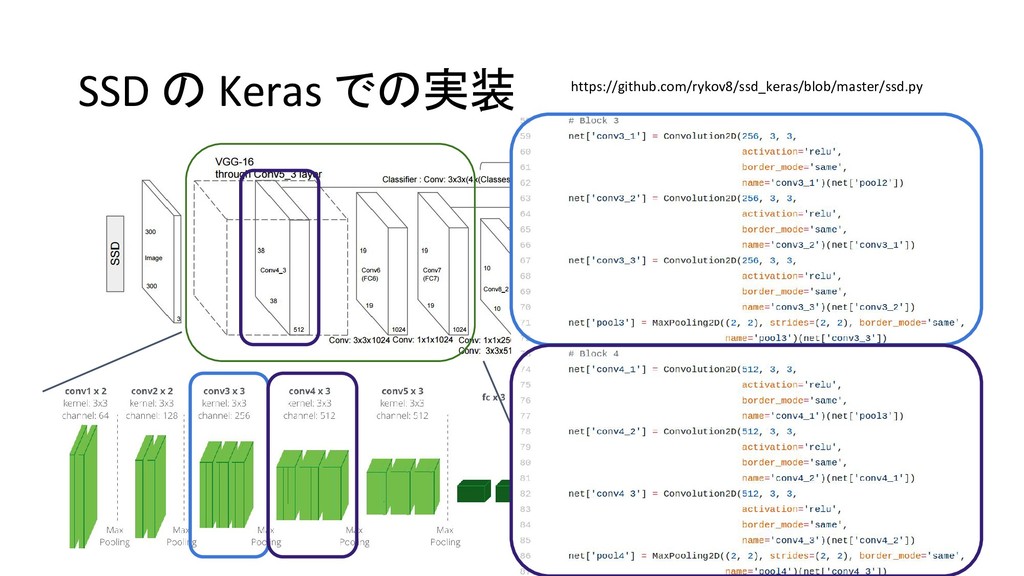
et al 2013/11 MATLAB+Caffe Fast R-CNN Ross G. 2015/04 Caffe / MATLAB Torch Faster R-CNN Shaoqing R. et at 2015/06 MATLAB / Caffe Keras / TensorFlow (TF) / Chainer YOLO (You Only Look Once) Joseph R. et al 2015/06 darknet TF / TF / TF / TF on Android / Keras SSD (Single Shot Multibox Detector) Wei L. et al 2015/12 Caffe Keras / TF / Torch / Chainer YOLOv2 Joseph R. et al 2016/12 darknet Keras / TF *「R-CNN implementation」等でググって1-2ページ以内にヒットしたもののみ掲載 \* 出典:SSD: Single Shot MultiBox Detector \* https://github.com/weiliu89/caffe/tree/ssd \* 出典:YOLO9000: Better, Faster, Stronger \* https://arxiv.org/pdf/1612.08242.pdf (次ページに拡大図)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
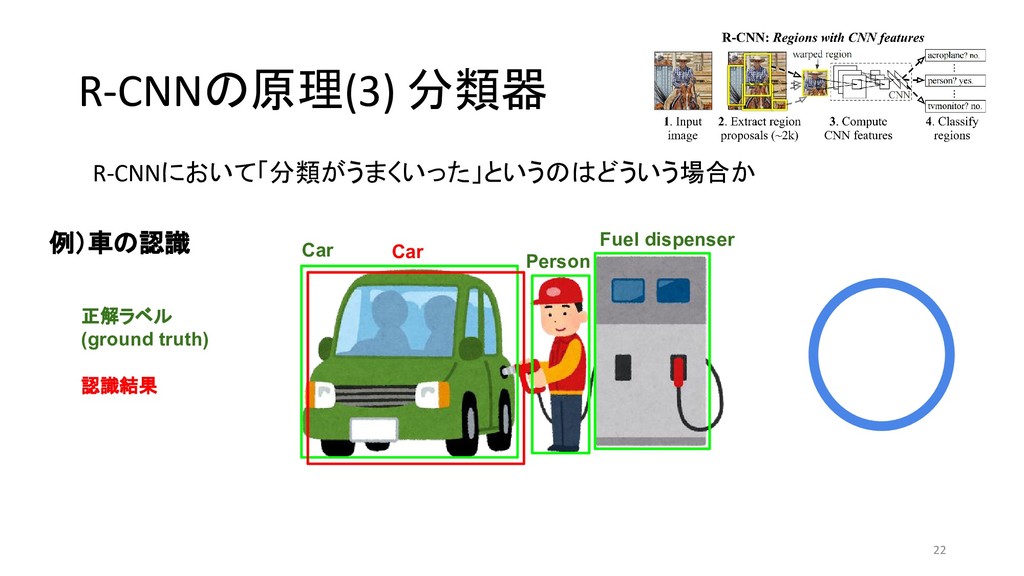{kind=link}
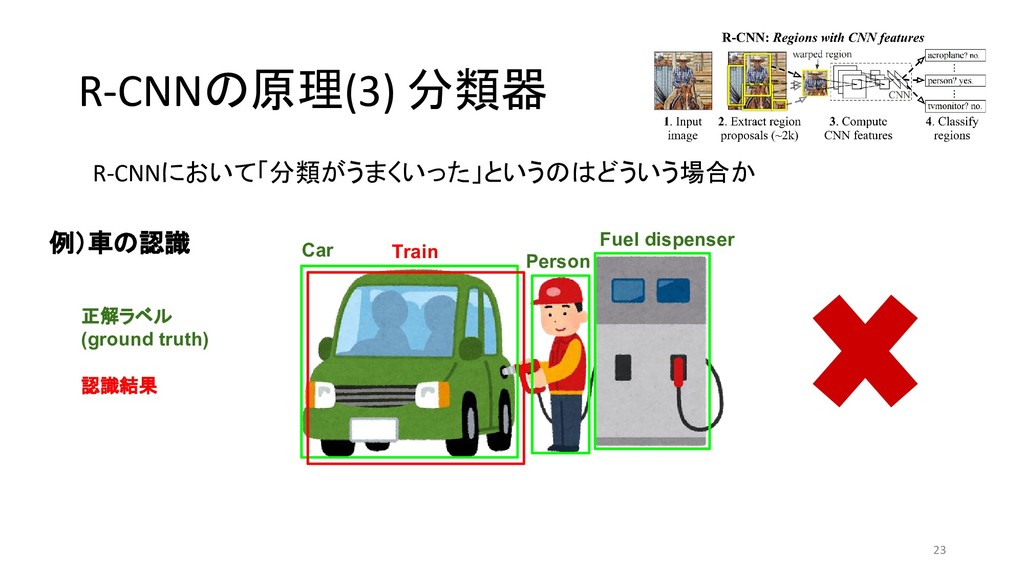{kind=link}
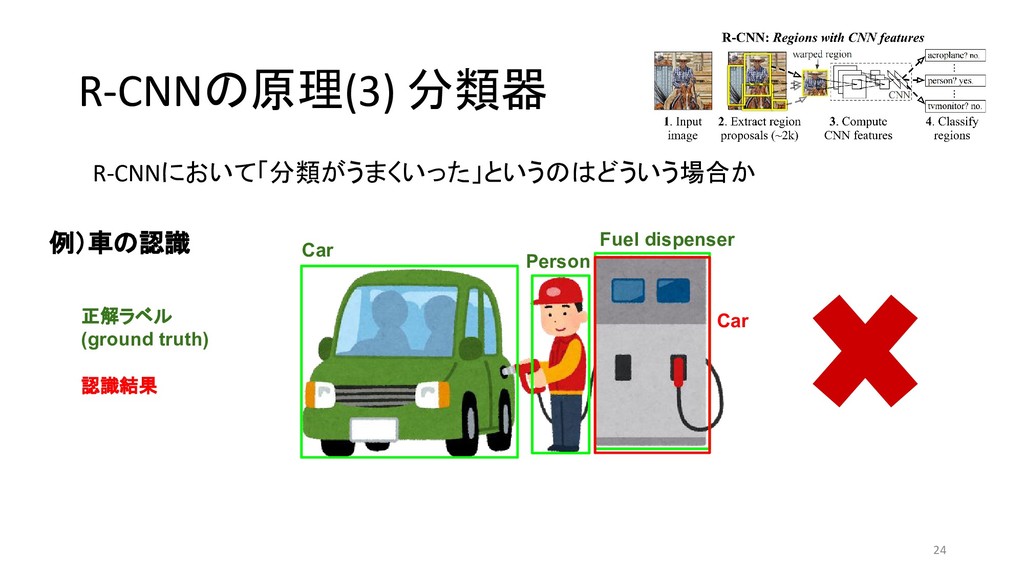{kind=link}
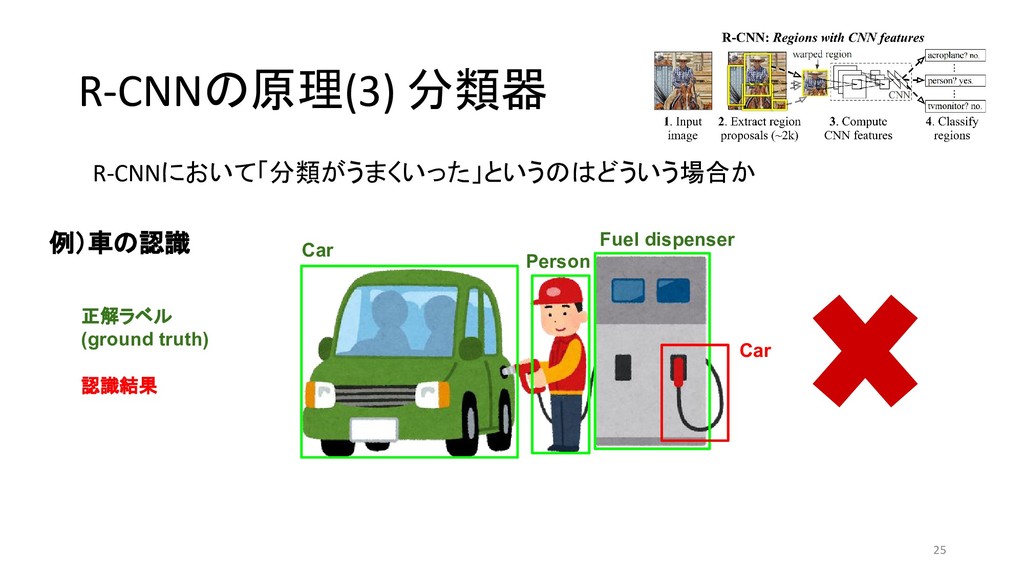{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
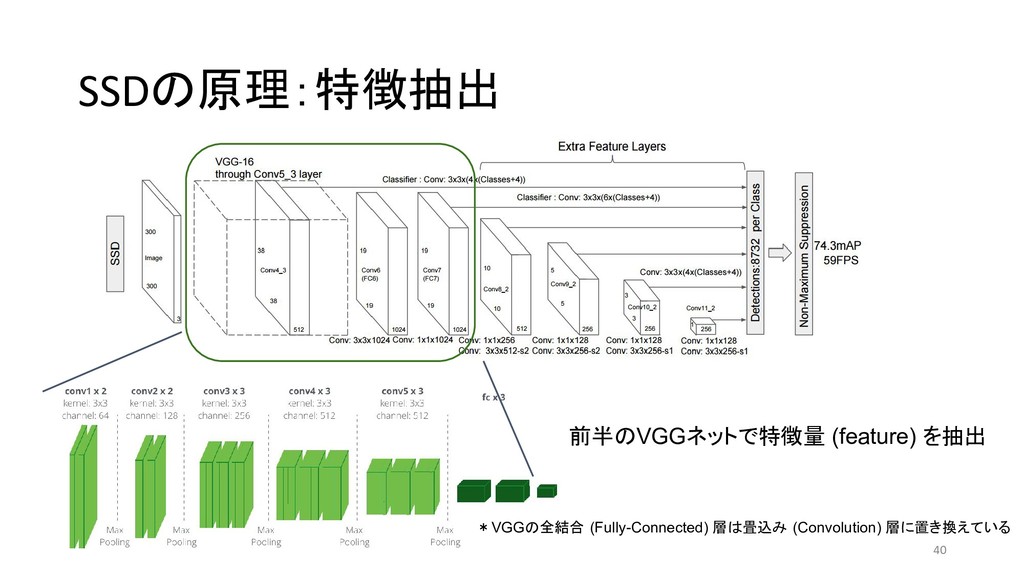{kind=link}
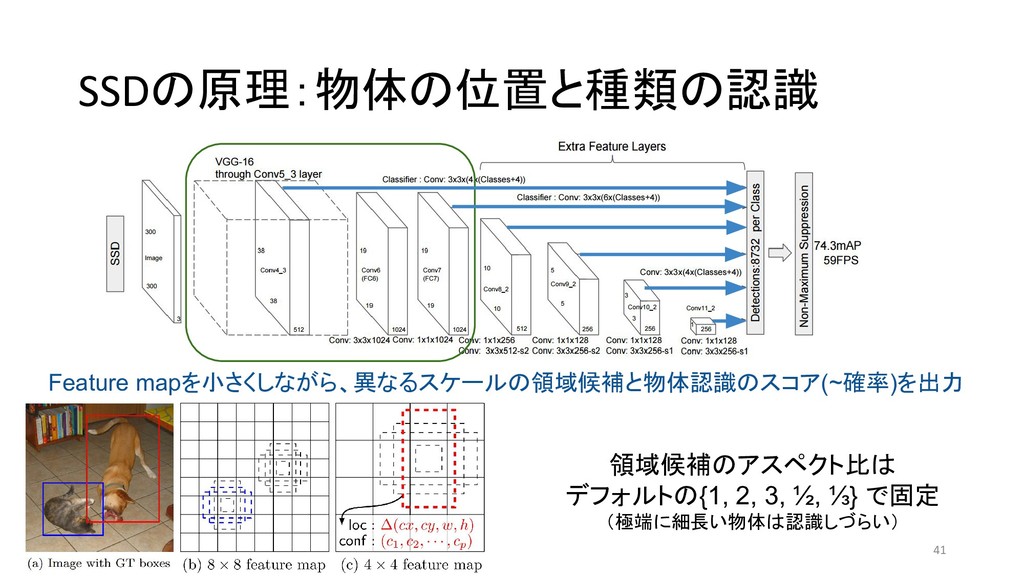{kind=link}
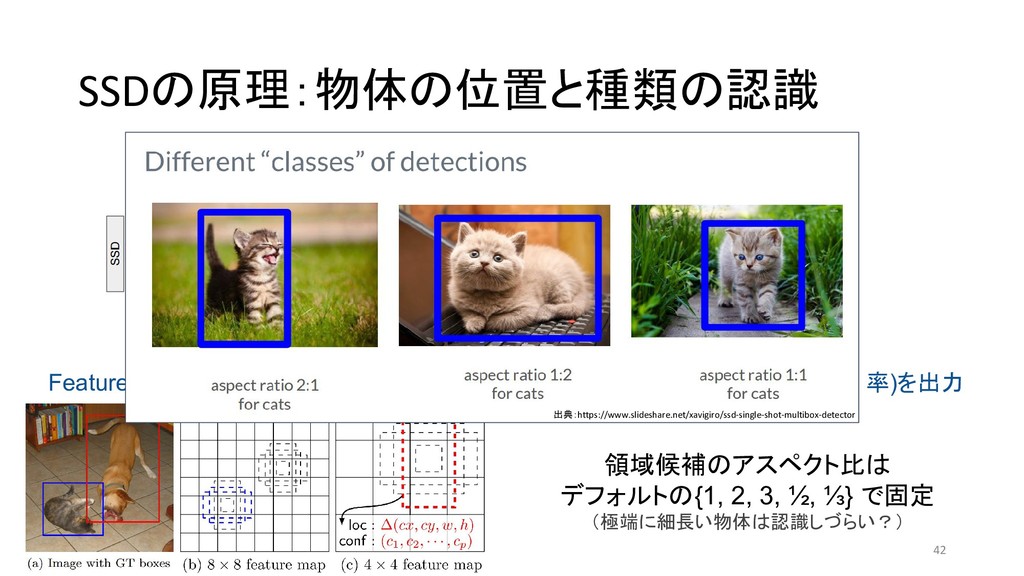{kind=link}
{kind=link}
{kind=link}
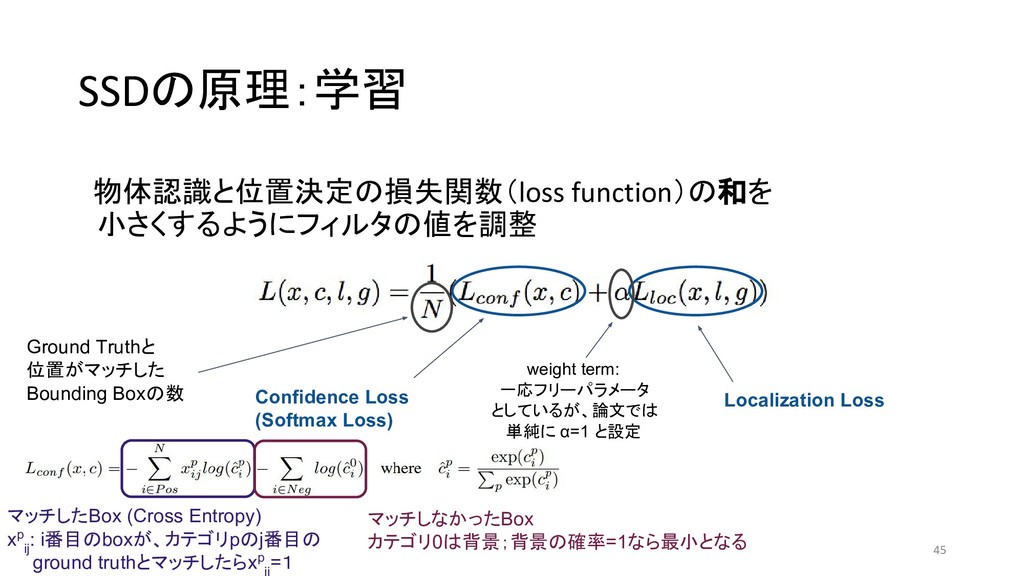{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
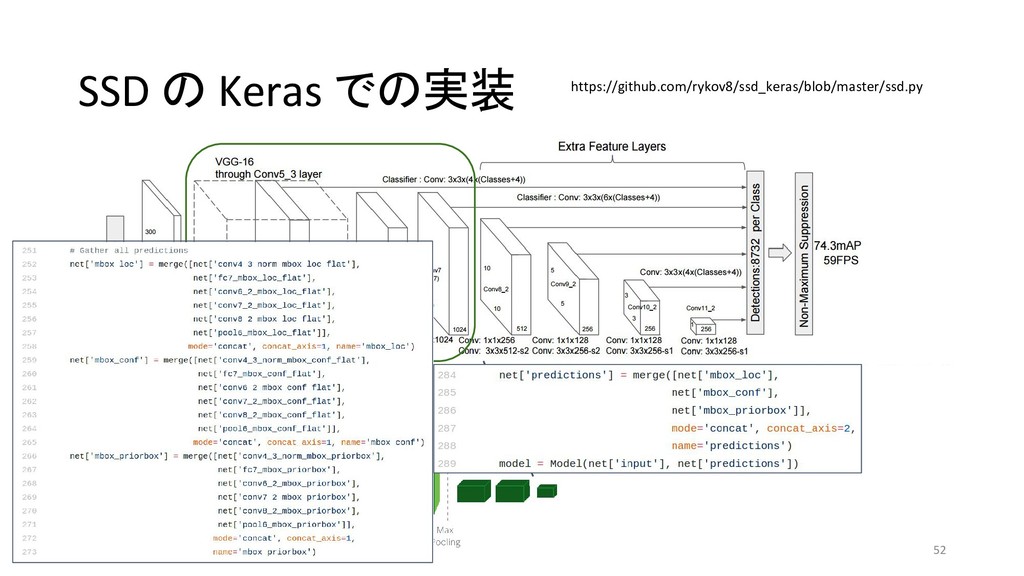{kind=link}
{kind=link}
{kind=link}
{kind=link}
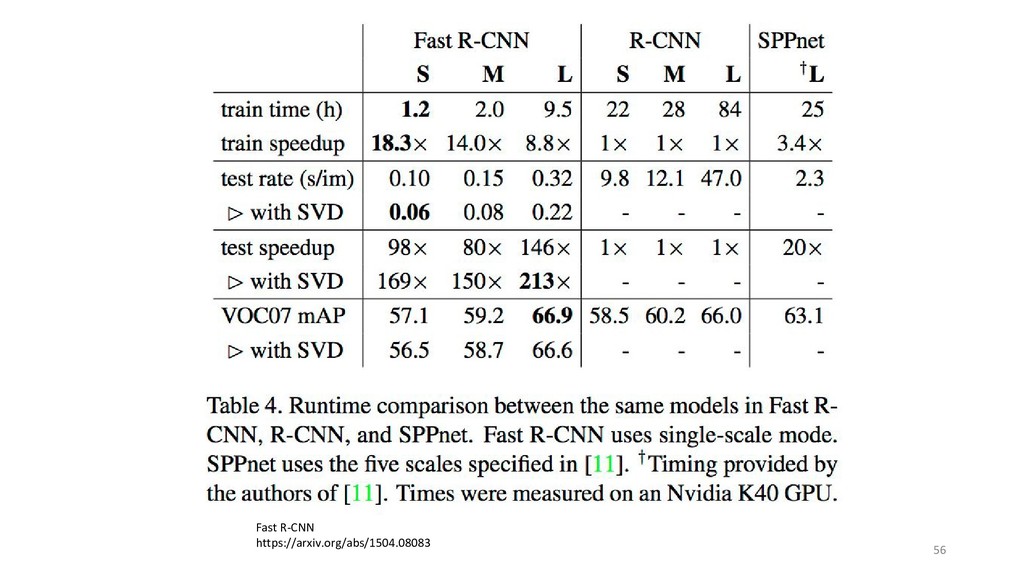{kind=link}
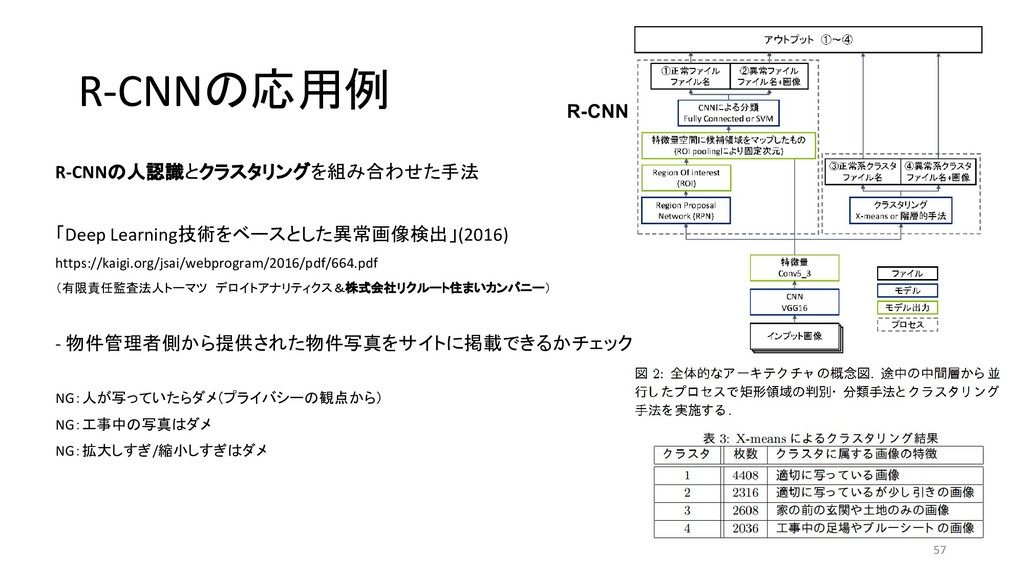{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}