Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
富士通研のAI基盤の話し/Talk about AI Infrastructure in Fu...
Search
kobaski
August 01, 2019
Technology
740
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
富士通研のAI基盤の話し/Talk about AI Infrastructure in Fujitsu Labs
kobaski
August 01, 2019
Other Decks in Technology
See All in Technology
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
180
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
200
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
370
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
3
260
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
430
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
0
100
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
1
270
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
150
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.4k
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
330
企業でAWS Organizationsを動かすための組織設計の考え方
nrinetcom
PRO
1
100
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
270
Featured
See All Featured
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Speed Design
sergeychernyshev
33
1.9k
A Tale of Four Properties
chriscoyier
163
24k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Music & Morning Musume
bryan
47
7.3k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Faster Mobile Websites
deanohume
310
32k
For a Future-Friendly Web
brad_frost
183
10k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
240
Everyday Curiosity
cassininazir
0
250
Transcript
富士通研のAI基盤の話し こばし@MLPP the 3rd Copyright 2019 FUJITSU LABORATORIES LTD.
こばし ひろみち • 所属: 株式会社富士通研究所 人工知能研究所 • 主任研究員 • むかしは「kobaski」でコンペとか出ていました
• 東工大 首藤先生の日記 • http://www.shudo.net/diary/2010jun.html • http://www.shudo.net/diary/2011jun.html Copyright 2019 FUJITSU LABORATORIES LTD.
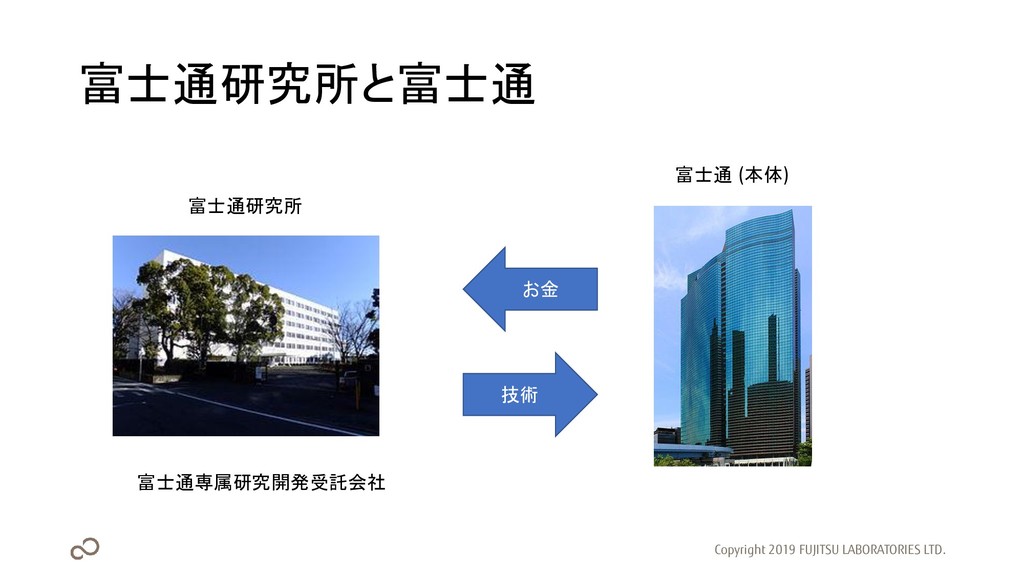
富士通研究所と富士通 Copyright 2019 FUJITSU LABORATORIES LTD. 富士通研究所 富士通 (本体) お金
技術 富士通専属研究開発受託会社
富士通研究所 人工知能研究所 • 黒魔術独自技術を生み出すのが至上命題 • 結構宣伝してる(つもりな)んですが、知らないですよね • でも頑張ってるんです Copyright 2019
FUJITSU LABORATORIES LTD. Deep Tensor Wide Learning Topological Data Analytics
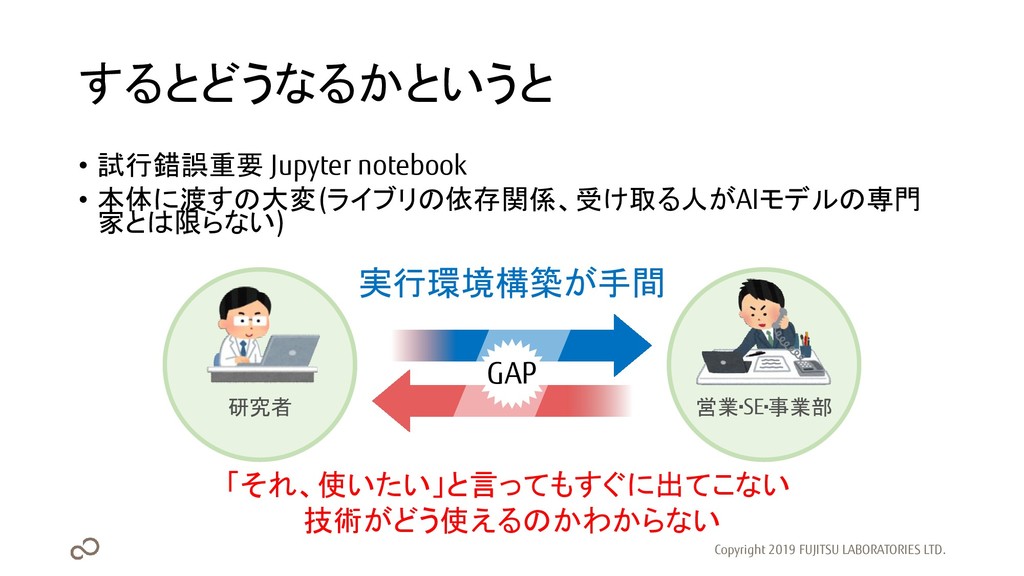
するとどうなるかというと • 試行錯誤重要 Jupyter notebook • 本体に渡すの大変(ライブリの依存関係、受け取る人がAIモデルの専門 家とは限らない) Copyright 2019
FUJITSU LABORATORIES LTD. 「それ、使いたい」と言ってもすぐに出てこない 技術がどう使えるのかわからない 実行環境構築が手間 研究者 営業・SE・事業部 GAP
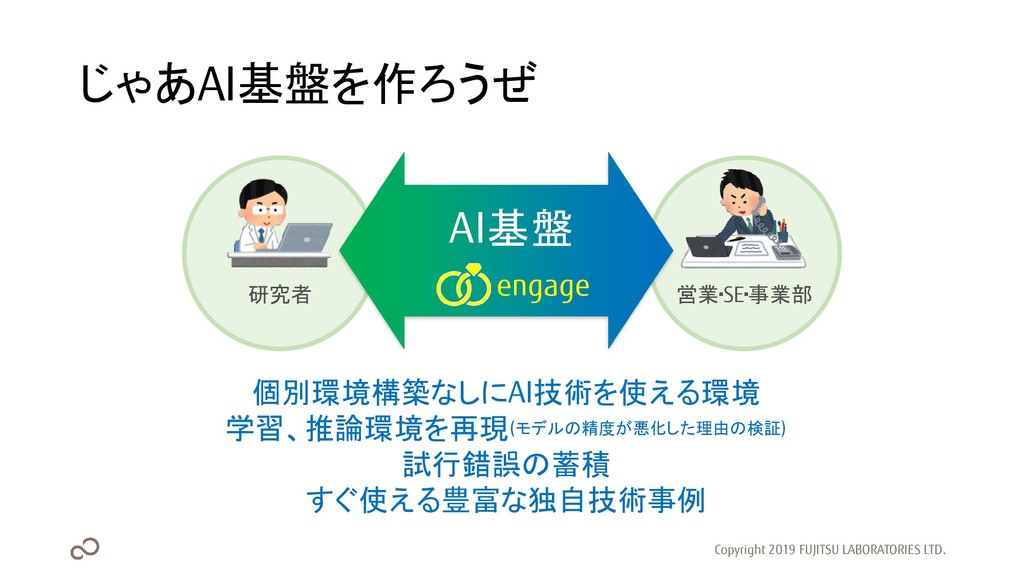
じゃあAI基盤を作ろうぜ Copyright 2019 FUJITSU LABORATORIES LTD. 個別環境構築なしにAI技術を使える環境 学習、推論環境を再現(モデルの精度が悪化した理由の検証) 試行錯誤の蓄積 すぐ使える豊富な独自技術事例
研究者 営業・SE・事業部 AI基盤 engage
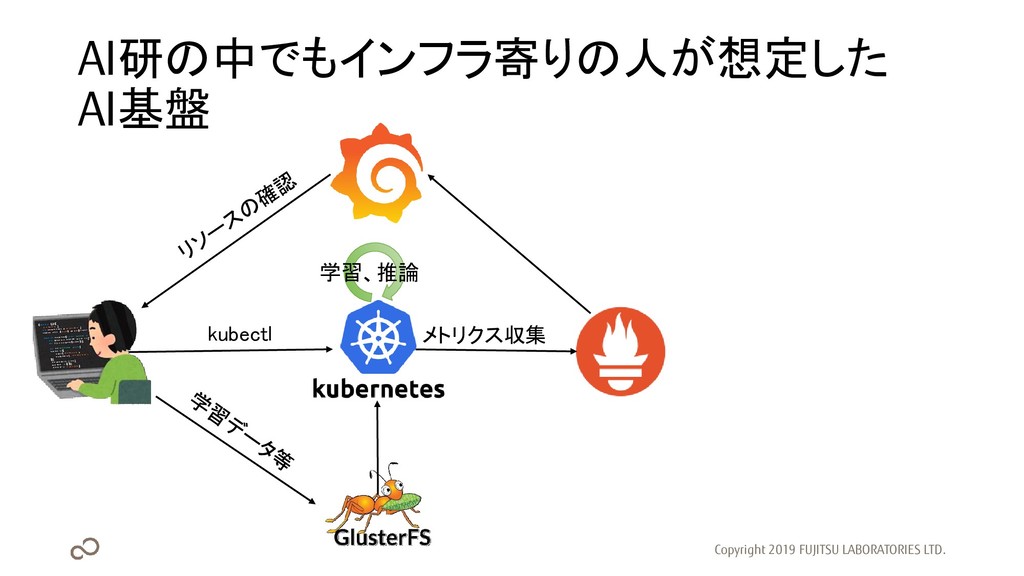
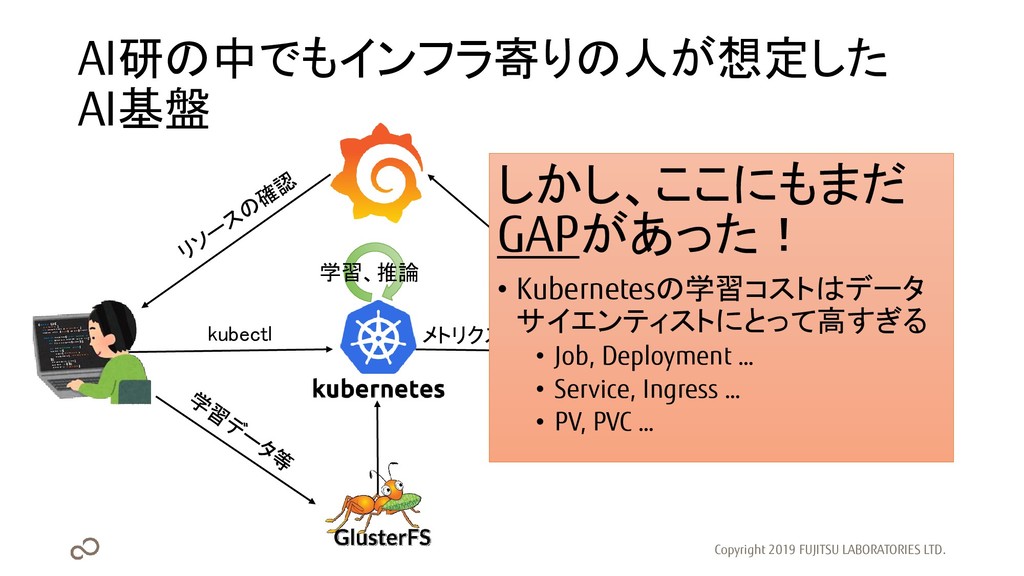
AI研の中でもインフラ寄りの人が想定した AI基盤 Copyright 2019 FUJITSU LABORATORIES LTD. メトリクス収集 kubectl 学習、推論
AI研の中でもインフラ寄りの人が想定した AI基盤 Copyright 2019 FUJITSU LABORATORIES LTD. メトリクス収集 kubectl 学習、推論
しかし、ここにもまだ GAPがあった! • Kubernetesの学習コストはデータ サイエンティストにとって高すぎる • Job, Deployment … • Service, Ingress … • PV, PVC …
Kubernetesを隠蔽する独自WebAPIサーバ • 機械学習の学習・推論のためにKubernetesの機能を取捨選択して APIを整理 • 最終的にdockerコマンドを叩く場合とほとんど差がない使い方のパラメータ に落ち着いた • WebAPIサーバはマニフェストを生成してkubernetes client経由でコン
テナを生成 • KubernetesをアップグレードしてもWebAPIサーバがKubernetesのAPIの変更 を吸収するのでユーザはパラメータを変更する必要はない Copyright 2019 FUJITSU LABORATORIES LTD.
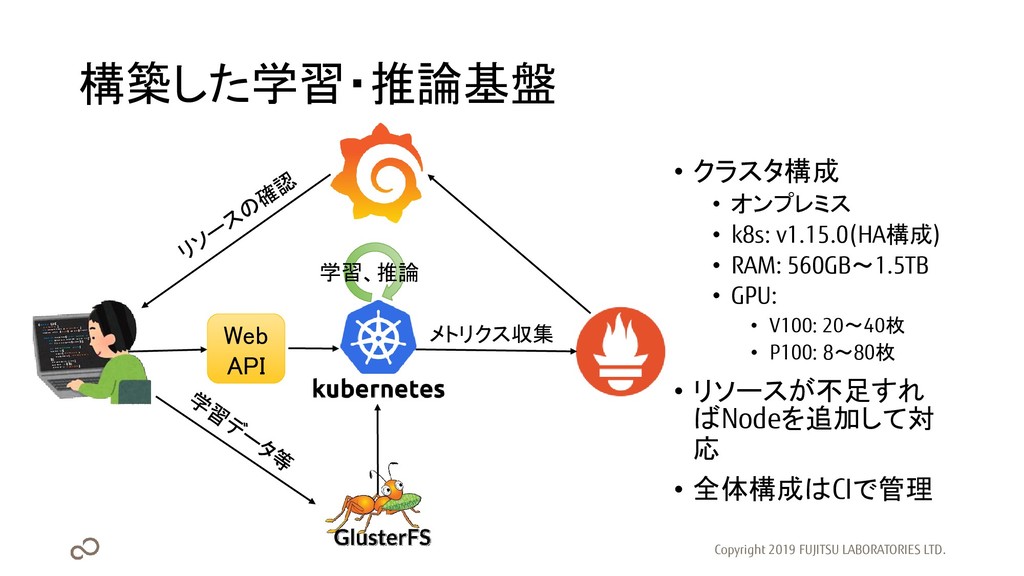
構築した学習・推論基盤 • クラスタ構成 • オンプレミス • k8s: v1.15.0(HA構成) • RAM:
560GB~1.5TB • GPU: • V100: 20~40枚 • P100: 8~80枚 • リソースが不足すれ ばNodeを追加して対 応 • 全体構成はCIで管理 Copyright 2019 FUJITSU LABORATORIES LTD. メトリクス収集 学習、推論 Web API
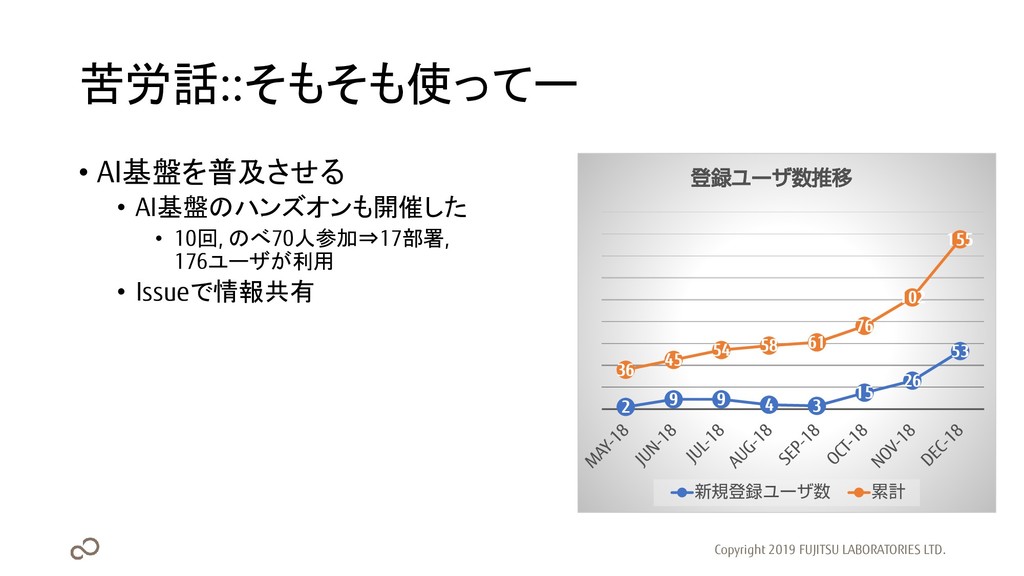
苦労話::そもそも使ってー • AI基盤を普及させる • AI基盤のハンズオンも開催した • 10回, のべ70人参加⇒17部署, 176ユーザが利用 •
Issueで情報共有 Copyright 2019 FUJITSU LABORATORIES LTD. 2 9 9 4 3 15 26 53 36 45 54 58 61 76 102 155 登録ユーザ数推移 新規登録ユーザ数 累計
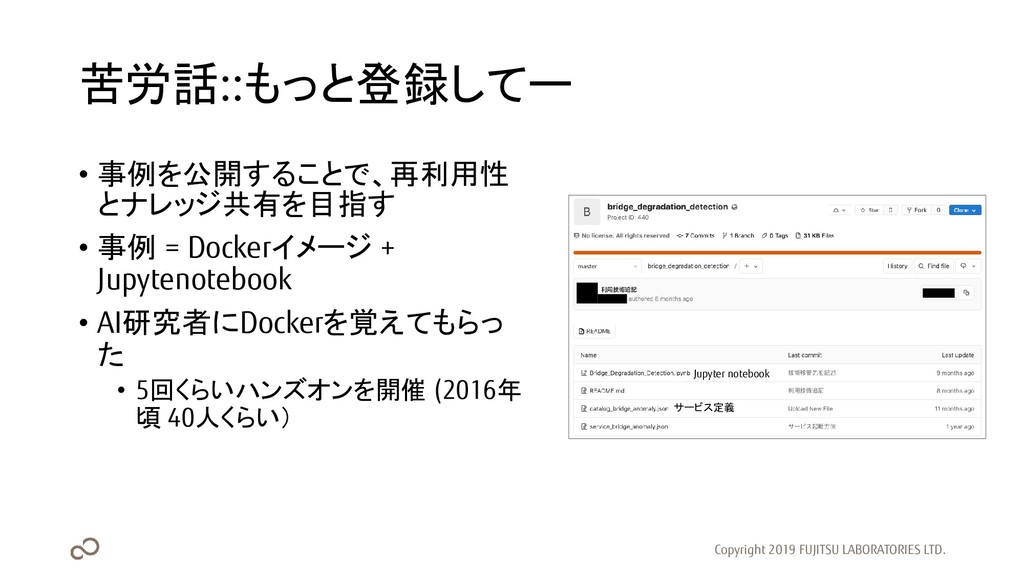
苦労話::もっと登録してー • 事例を公開することで、再利用性 とナレッジ共有を目指す • 事例 = Dockerイメージ + Jupytenotebook
• AI研究者にDockerを覚えてもらっ た • 5回くらいハンズオンを開催 (2016年 頃 40人くらい) Copyright 2019 FUJITSU LABORATORIES LTD. サービス定義 Jupyter notebook
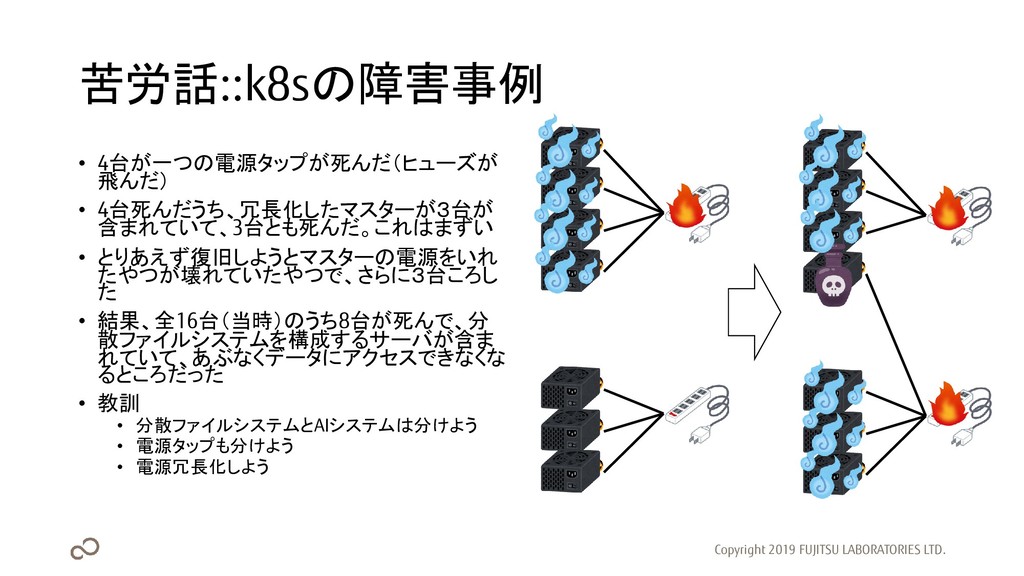
苦労話::k8sの障害事例 • 4台が一つの電源タップが死んだ(ヒューズが 飛んだ) • 4台死んだうち、冗長化したマスターが3台が 含まれていて、3台とも死んだ。これはまずい • とりあえず復旧しようとマスターの電源をいれ たやつが壊れていたやつで、さらに3台ころし
た • 結果、全16台(当時)のうち8台が死んで、分 散ファイルシステムを構成するサーバが含ま れていて、あぶなくデータにアクセスできなくな るところだった • 教訓 • 分散ファイルシステムとAIシステムは分けよう • 電源タップも分けよう • 電源冗長化しよう Copyright 2019 FUJITSU LABORATORIES LTD.
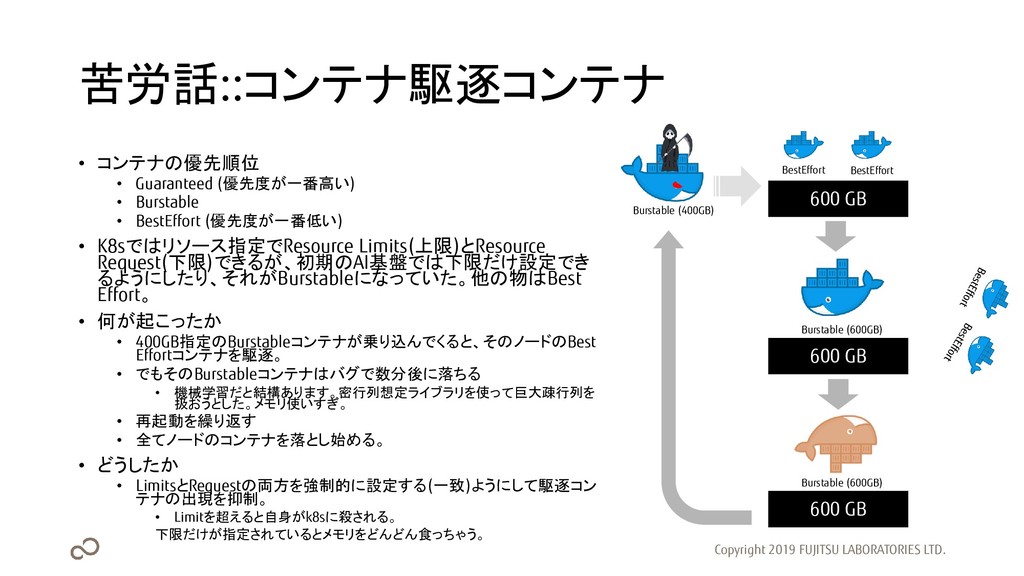
苦労話::コンテナ駆逐コンテナ • コンテナの優先順位 • Guaranteed (優先度が一番高い) • Burstable • BestEffort
(優先度が一番低い) • K8sではリソース指定でResource Limits(上限)とResource Request(下限)できるが、初期のAI基盤では下限だけ設定でき るようにしたり、それがBurstableになっていた。他の物はBest Effort。 • 何が起こったか • 400GB指定のBurstableコンテナが乗り込んでくると、そのノードのBest Effortコンテナを駆逐。 • でもそのBurstableコンテナはバグで数分後に落ちる • 機械学習だと結構あります。密行列想定ライブラリを使って巨大疎行列を 扱おうとした。メモリ使いすぎ。 • 再起動を繰り返す • 全てノードのコンテナを落とし始める。 • どうしたか • LimitsとRequestの両方を強制的に設定する(一致)ようにして駆逐コン テナの出現を抑制。 • Limitを超えると自身がk8sに殺される。 下限だけが指定されているとメモリをどんどん食っちゃう。 Copyright 2019 FUJITSU LABORATORIES LTD. Burstable (400GB) BestEffort BestEffort 600 GB Burstable (600GB) 600 GB Burstable (600GB) 600 GB
苦労話::GPUあるある • GPUを離さない。良いGPUを専有したがる。大して使っていないのに。 • Jupyter使っていると使っていないように見えても隙間時間だったりする。 • ジョブが終わっているのに結果を確認しない人がいる。 • これを消さないように。 •
リテラシの問題 • 根本解決には至っていない • 応急対処 • 明にGPUを指定しないとGPUノードにはいなかないように設定 • Graffanaで誰でも見れるようにしていて、緩い相互監視機能を提供 • 最新GPUのパラメータはデフォルトでは見せてない • ちなみに • 最近停電があったのですが、停電前後で利用率が結構違ったりするのは悲しい Copyright 2019 FUJITSU LABORATORIES LTD.
まとめ • 富士通研の試行錯誤用AI学習基盤 • 今後の課題 • スクリプトが埋没する • 細かいファイルのバックアップ(AI研究者システムは動いて当然。気がつい たら1ディレクトリにファイル大量)
• 本体への引き渡す • 基盤の運用の自動化 Copyright 2019 FUJITSU LABORATORIES LTD.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}