社内のAI技術共有会で使用した資料です。
様々なドメインに特化したCLIPモデルについて紹介しました。
以下スライド中の参考文献のリンク
[1] https://arxiv.org/abs/2302.00275
[2] https://arxiv.org/abs/2103.00020
[3] https://arxiv.org/abs/2306.11029
[4] https://arxiv.org/abs/2501.02461
[5] https://arxiv.org/abs/2311.17179
[6] https://arxiv.org/abs/2210.10163
[7] https://arxiv.org/abs/2412.10372
[8] https://arxiv.org/abs/2501.15579
[9] https://arxiv.org/abs/2403.09948
[10] https://imageomics.github.io/bioclip/
[11] https://arxiv.org/abs/2106.13043
[12] https://openaccess.thecvf.com/content/ICCV2023/papers/Zhai_Sigmoid_Loss_for_Language_Image_Pre-Training_ICCV_2023_paper.pdf
[13] https://research.google.com/audioset/
[14] https://arxiv.org/abs/2503.19311
[15] https://graft.cs.cornell.edu/static/pdfs/graft_paper.pdf
[16] https://github.com/visipedia/inat_comp/tree/master/2021
[17] https://biodiversitygenomics.net/projects/1m-insects/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AI 8 ▪ リモートセンシング ▪ RemoteCLIP [3] ▪ FedRSCLIP [4]](https://files.speakerdeck.com/presentations/24a677e766524b628ea66594801b4355/slide_7.jpg){kind=link}
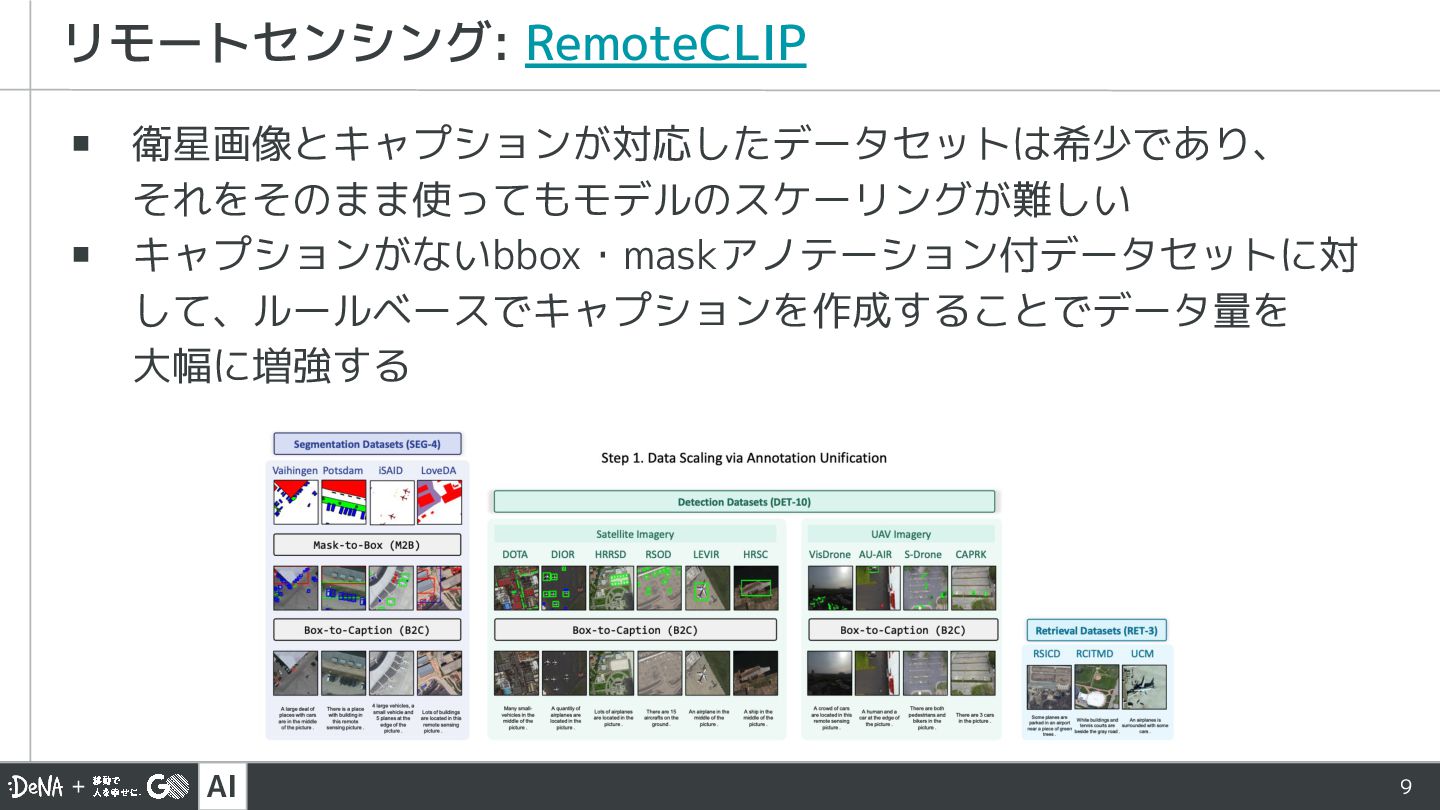{kind=link}
{kind=link}
{kind=link}
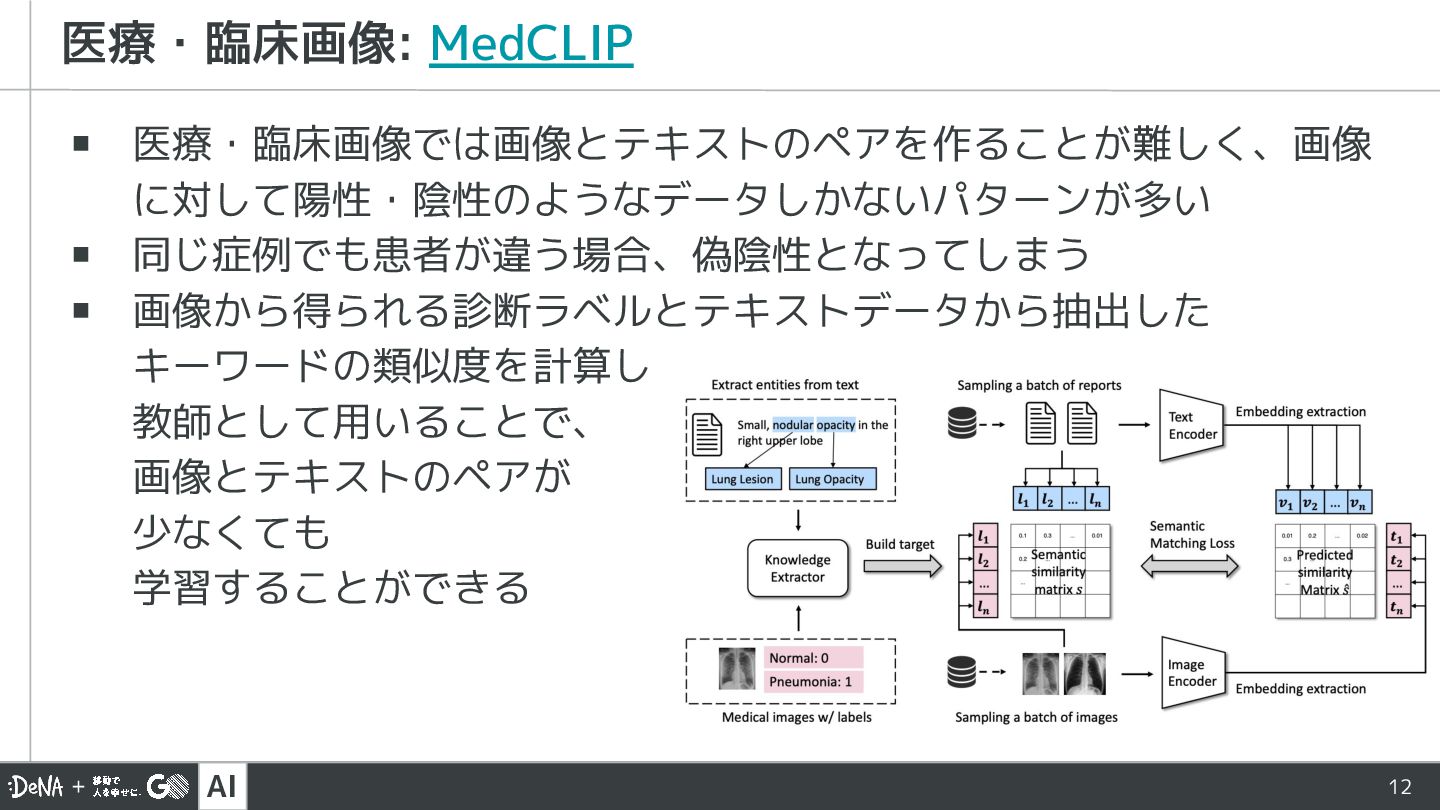{kind=link}
{kind=link}
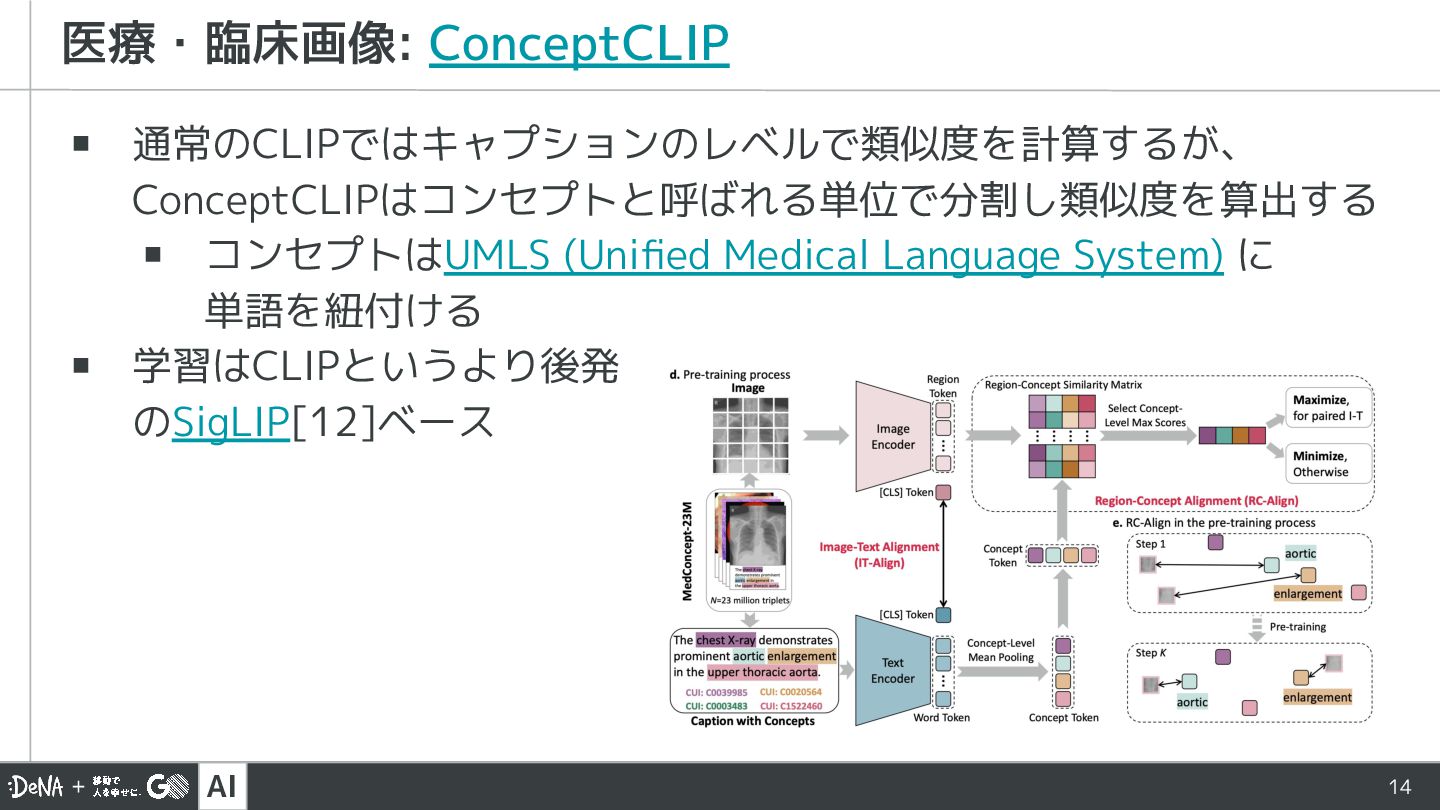{kind=link}
{kind=link}
{kind=link}
![AI 17 ▪ 画像・テキスト・音声のトライモーダルの特徴を共通の意味空間で 関連付けることができるモデル ▪ AudioSet [13]という動画・音声のデータセットから音声とフレーム ・クラスラベルを取得し、トライモーダルな学習に活用 音響・音声分析:](https://files.speakerdeck.com/presentations/24a677e766524b628ea66594801b4355/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![AI 21 ▪ 大規模なコミュニティの活用 ▪ BioCLIPで用いられたTreeOfLife-10MはiNat21 [16]やBioscan-1M [17]、Encyclopedia of Life(eol.org)から得られたデータを統合して](https://files.speakerdeck.com/presentations/24a677e766524b628ea66594801b4355/slide_20.jpg){kind=link}
{kind=link}
![AI 23 [1] https://arxiv.org/abs/2302.00275 [2] https://arxiv.org/abs/2103.00020 [3] https://arxiv.org/abs/2306.11029 [4] https://arxiv.org/abs/2501.02461](https://files.speakerdeck.com/presentations/24a677e766524b628ea66594801b4355/slide_22.jpg){kind=link}
![AI 24 [10] https://imageomics.github.io/bioclip/ [11] https://arxiv.org/abs/2106.13043 [12] https://openaccess.thecvf.com/content/ICCV2023/papers/Zhai_Sigmoid_Loss_for_ Language_Image_Pre-Training_ICCV_2023_paper.pdf [13]](https://files.speakerdeck.com/presentations/24a677e766524b628ea66594801b4355/slide_23.jpg){kind=link}