Processing Unit (GPU) o Definition o Future Trends o Advantages o Differences o Parallel Computing o GPU types • Compute Unified Device Architecture (CUDA) o Definition o Advantages o Architecture o Kernel and Thread o Memory Management o Code sample
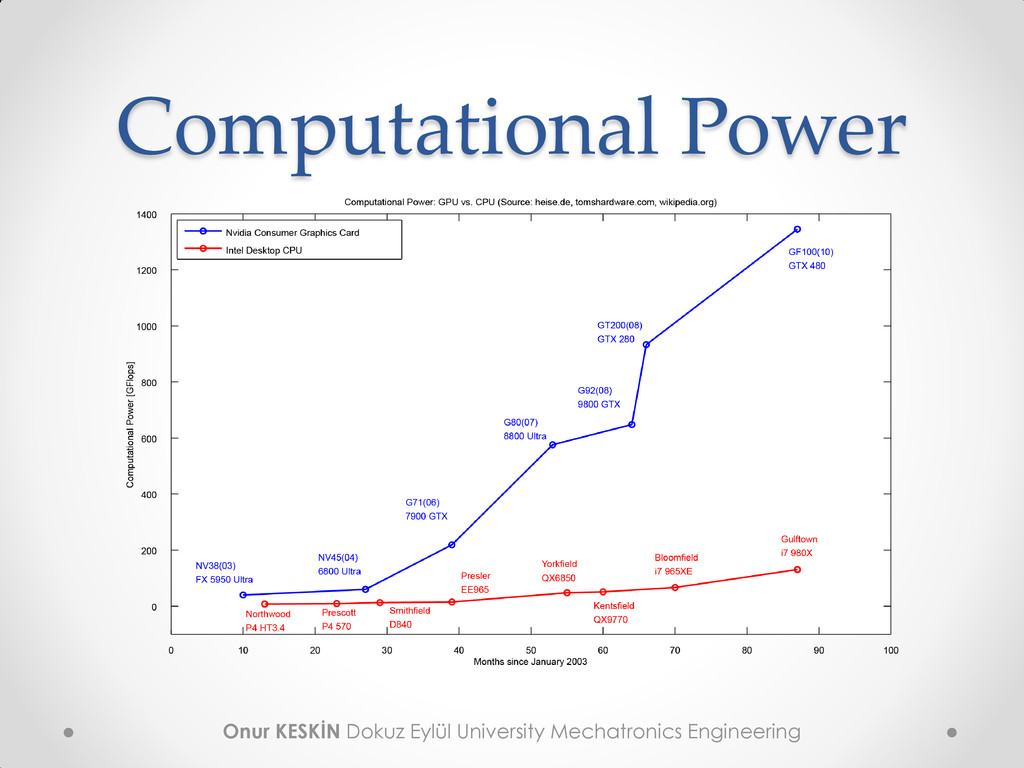
hardware usually used for graphics but also computing o But not all vendors allow GPU to be used for computing • Provides high computing power o 128 core GPU = 500 GFLOPS (500 billion floating point operations per second) o 4 core CPU = 90 GFLOPS • Designed for mathematical or parallel problems CPU GPU
Computing is evolving from central processing on the CPU to co-processing on CPU and GPU • Can not continue to develop processor frequencies o Hardware limit 10 GHz chips • Can not continue to increase power consumption o Chip temperatures might melt chip it self • Can continue to increase the number transistors o From Moore’s Law
Computers are no longer get faster o Serial development will eventually stop • Computers will expand o Parallel development is the future • There will always more data than cores SO • Algorithms need to be also parallel
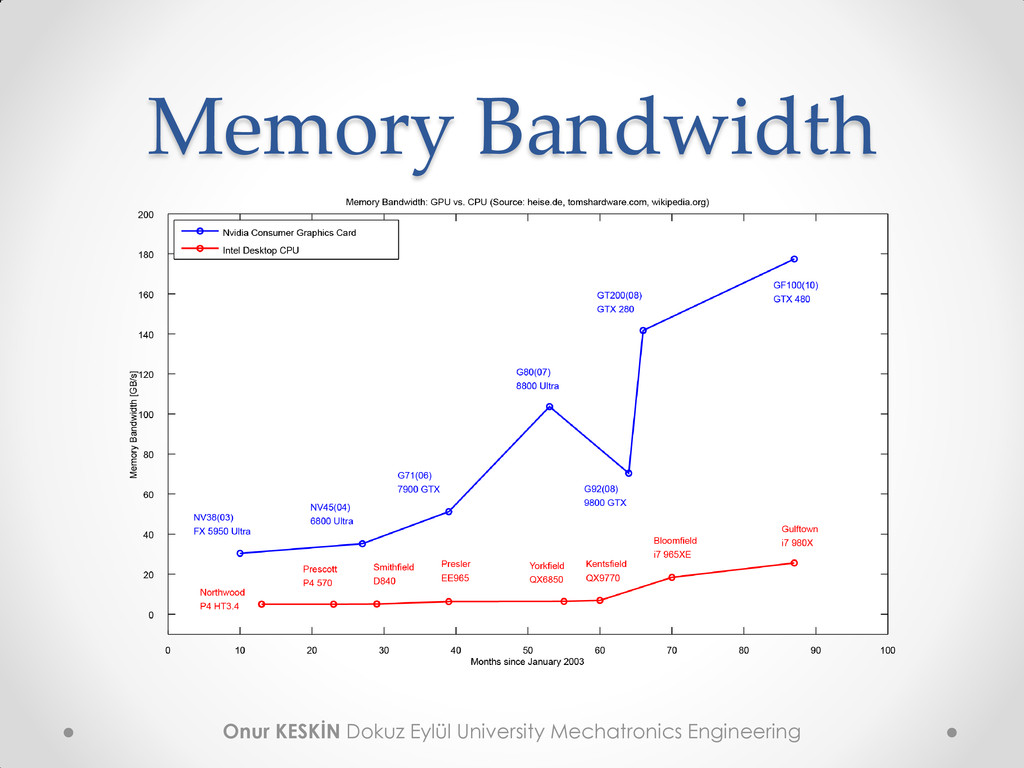
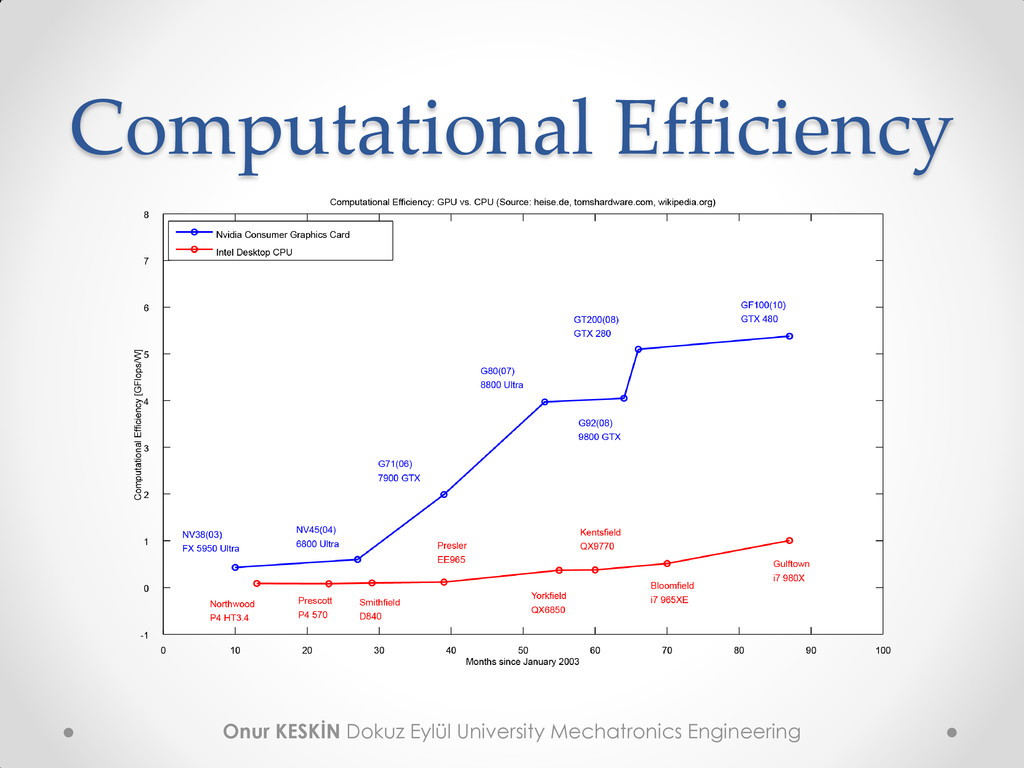
• High computing output o For example 933 GFLOP/s • High memory bandwidth o For example 140 GB/s • High hardware availability o 200+ million CUDA supported GPUs
• GPU’s work load is parallel o CPU must be work both parallel and serial • GPU is used for maximum output in all threads o CPU is for decrease latency in one thread • GPU has lots of mathematical units o CPU has many of all units • GPU can access memory fast o CPU can cache fast and reuse data • GPU runs a program on each fragment / vertex o CPU runs lots of different processes / threads
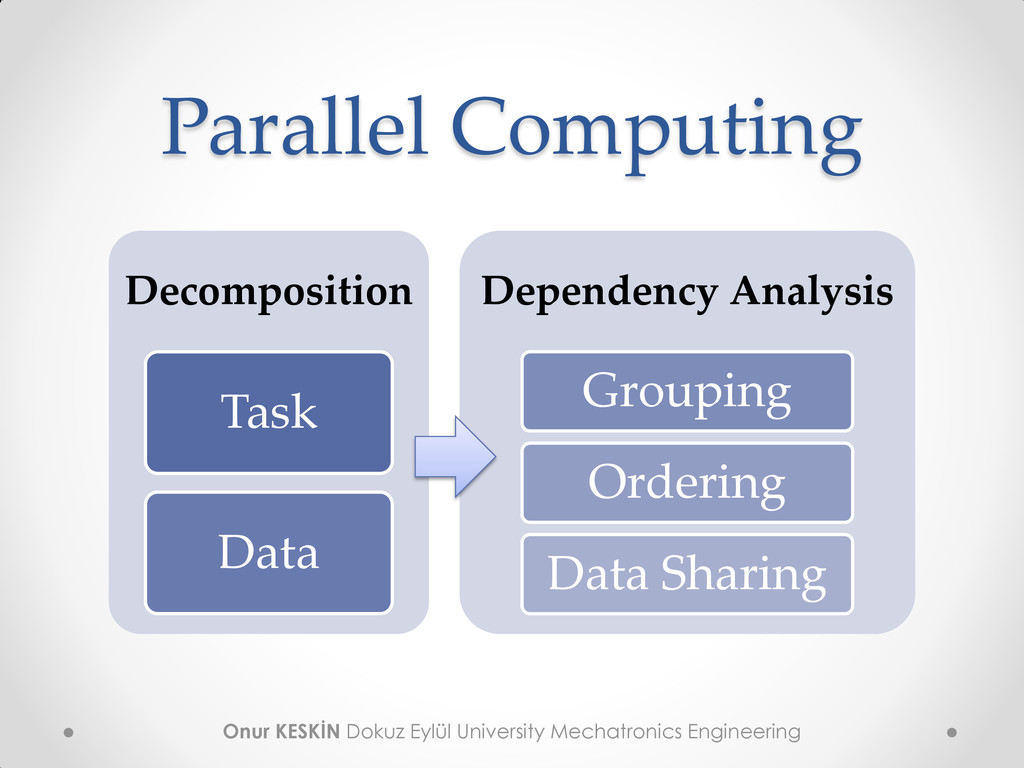
Calculations are carried out simultaneously • Large problems are divided into smaller ones then solved concurrently - in parallel • Algorithms and data structures need to be redesigned • A serial algorithm can convert into parallel by finding operable synchronicity / simultaneity
Task Parallel o Independent processes with low communication o Most of the operating systems is using with Symmetric Multiprocessing (SMP) o Two or more identical processors with shared memory controlled by single OS instance o CPUs are generally used • Data Parallel o Large data of the one computation is executed o Independent data elements in each computational step o Can use many ALUs o Require algorithmic redesign o GPUs are generally used
Dedicated o Most powerful ones o PCI, PCIe or AGP interface o Use its own dedicated RAM o Multiple GPU support • Integrated o Uses system’s RAM o Integrated with motherboard o Cheap but low capacity
Hybrid o Has shared memory with system and also dedicated memory cache o ATI HyperMemory & NVIDIA TurboCache • General Purpose GPU (GPGPU) o Allows to make computation itself rather than using CPUs o Problems need to defined as graphics – texture maps o Algorithms must be in terms of image synthesis – rendering steps o Hard to learn especially for non-graphics experts o Highly constrained memory layout and access model o Algorithms may cause bandwidth consumption
is NVIDIA’s parallel computing architecture • Simplify usage of GPU computing performance • CUDA enabled GPUs are already in market • Usage areas o Image and video processing o Computational biology and chemistry o Simulation of fluid dynamics o CT image reconstruction o Seismic analysis o Ray tracing
enables GPU computing without any graphics knowledge • Programmer-friendly design o Let use focus on parallel algorithms o Random and unlimited access to memory o Can be used in hybrid architecture with combining CPU and GPU • Tools and Ecosystem o GPU Accelerated Applications – HPC, super computing etc. o Numerical Analysis Tools – Matlab, Mathematica, Labview etc. o GPU Accelerated Libraries – cuFFT (Fast Fourier Transform), cuBLAS (Basic Linear Algebra Subroutines) o Programming Language and APIs – C/C++, Fortran, OpenACC o Performance Analysis Tools – Parallel Nsight, NVIDIA Visual Profiler o Debugging Solutions – Paralell Nsight o Cluster Management
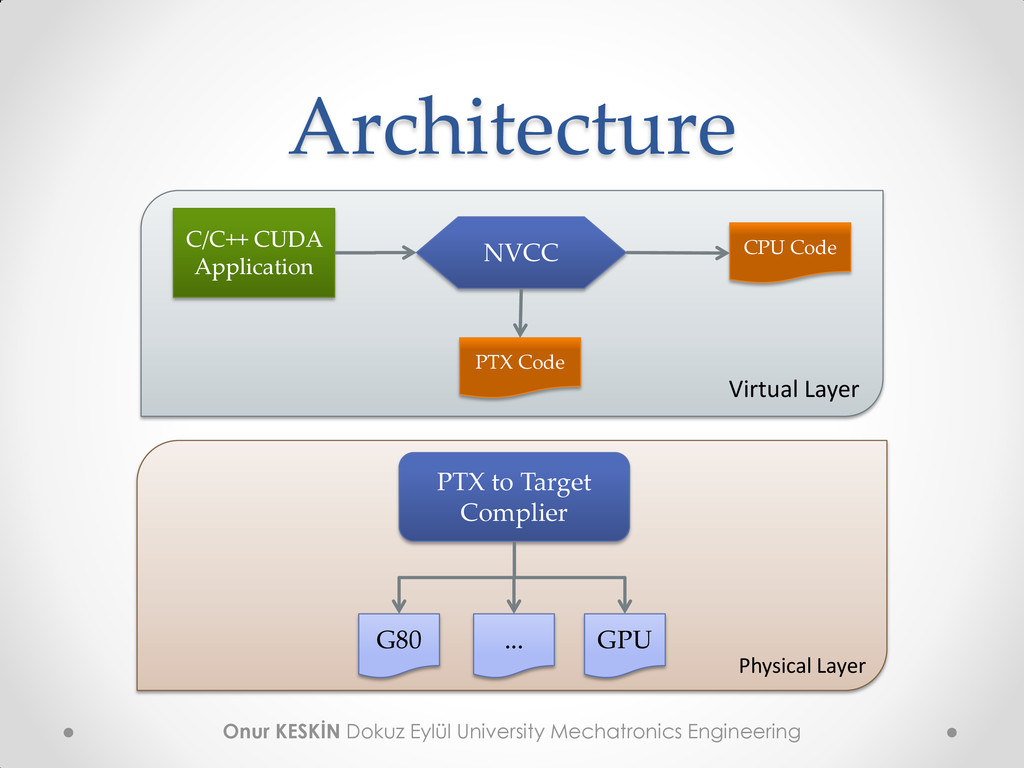
Complier Cuda Optimized Libraries Integrated CPU + GPU C Source Code NVIDIA Assembly for Computing (PTX) CUDA Driver Profiler CPU Host Code Standard C Code CPU GPU
• Kernel o Execution of the parallel portions of an application on the device o C Function that runs on the GPU – device – with some restrictions o One at a time o Threads execute on each kernel o All threads runs the same code o Each thread has an ID to address and control • Thread o CUDA threads are very lightweight o CUDA uses 1000s of threads • Multicore CPUs use only a few o Threads are in cooperation • To avoid computational redundancy • Share memory access decrease bandwidth
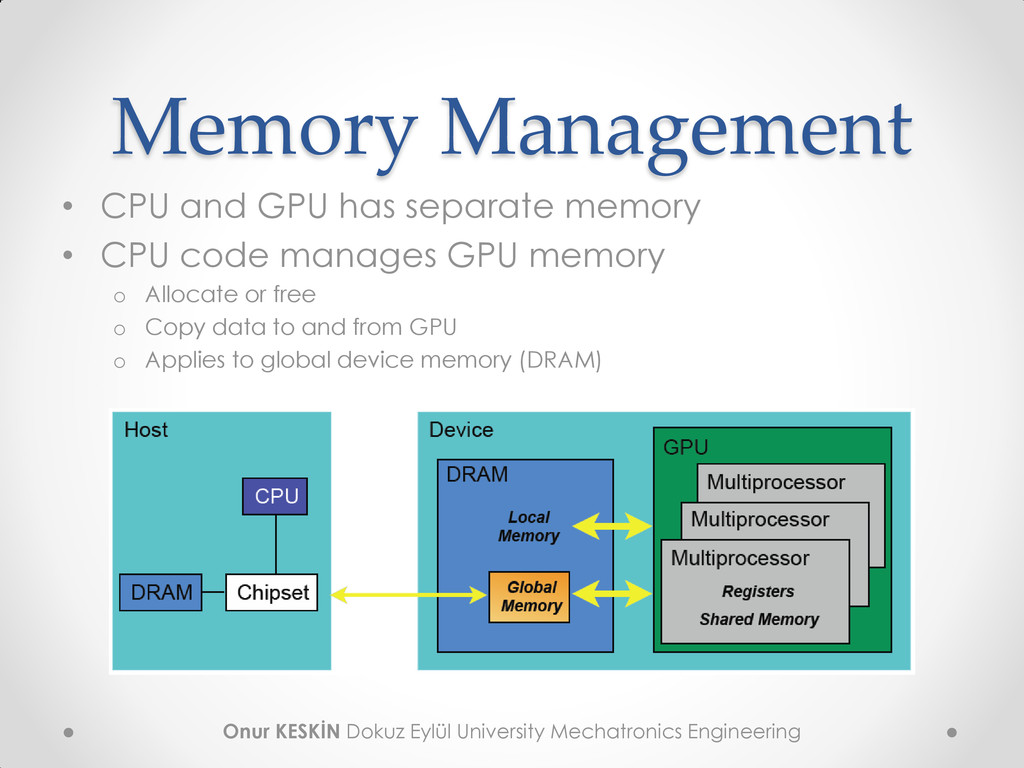
• Kernel function restrictions o Can not access CPU – host memory o Must be void o No variable number of arguments (varargs) o No recursion o No static variables But function arguments automatically copied from CPU to GPU
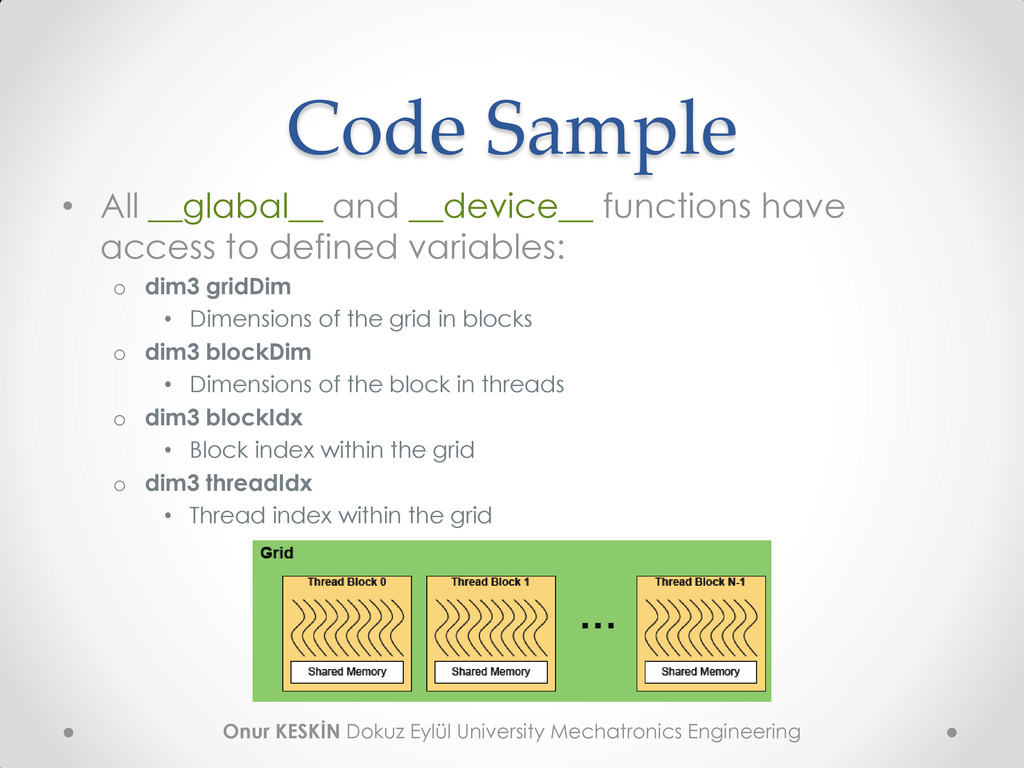
All __glabal__ and __device__ functions have access to defined variables: o dim3 gridDim • Dimensions of the grid in blocks o dim3 blockDim • Dimensions of the block in threads o dim3 blockIdx • Block index within the grid o dim3 threadIdx • Thread index within the grid
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you ! Onur KESKİN [email protected] http://people.deu.edu.tr/onur.keskin Dokuz Eylül University](https://files.speakerdeck.com/presentations/faa1c3d01fd401307ccc12313d145d81/slide_27.jpg){kind=link}
{kind=link}