• 右の画像で、Question: which city is this? Answer:というプ ロンプトに対してa car driving down a highway with a factory in the backgroundと出力される! • 一方で細かな物体検出は苦手であり、Question: are there traffic lights in this photo? Answer:という プロンプトに対してyesと出力される… • 画像全体の情報をテキストにする!
• GRiT[Wu et al. 2022]はDense Captioningにおける高精度なモデル • 画像の細かな領域の情報をテキストにする! • 前方のバイクに対して → a person riding a motorcycle • 前方の奥の対向車に対して → white car on the road • 空に対して → a cloudy gray sky • 左の標識に対して → a white sing on the side of the road など GRiTより一部改変[Wu et al. 2022]
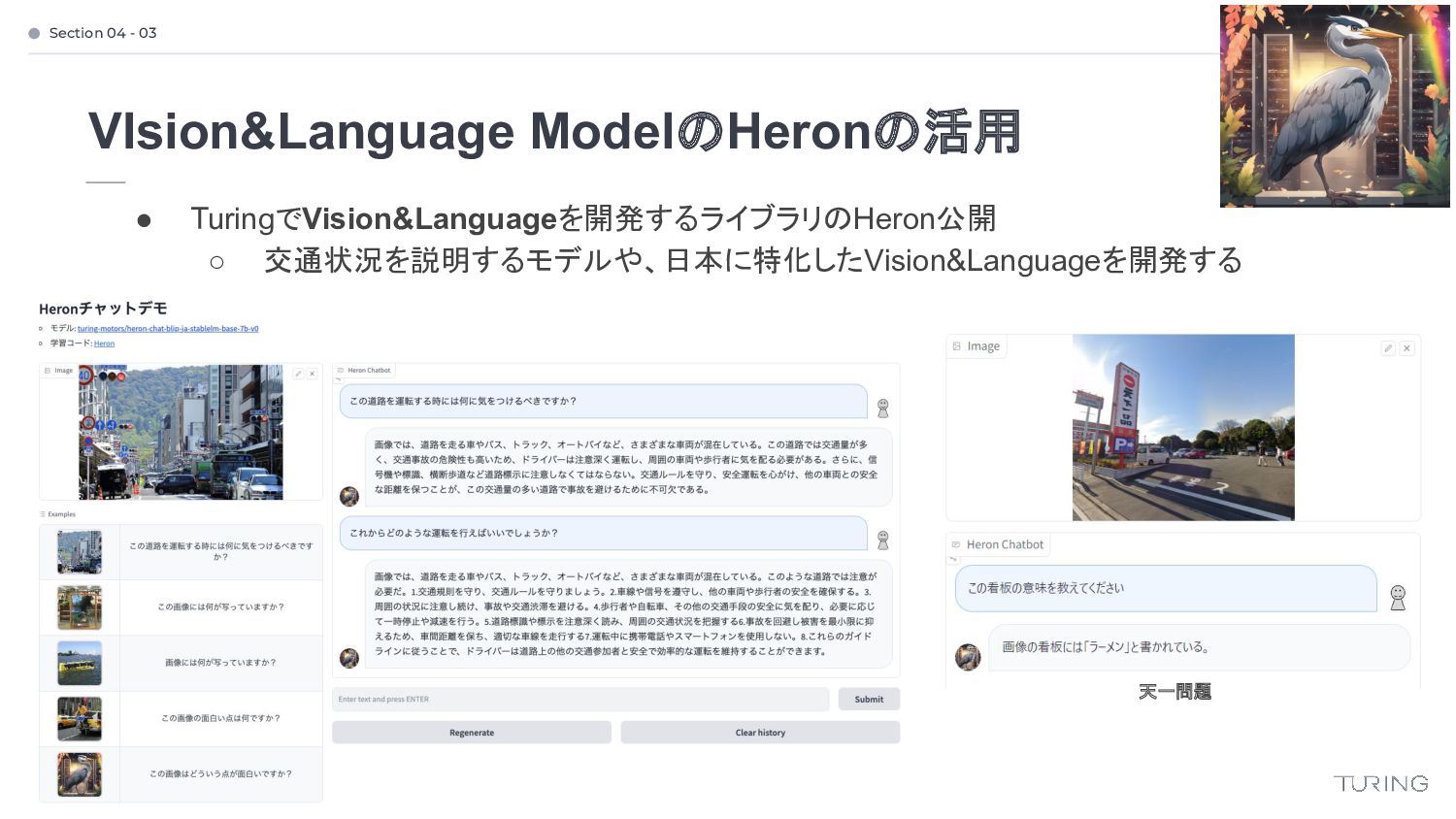
ahead. It is turning right and intruding into the oncoming lane. The traffic light is red. Please decelerate. What is the vehicle ahead? Where is it headed? What color is the traffic light? Should I accelerate? Should I decelerate? • 現在は動画から文章を生成するVideo2TextのモデルもHeronで開発中!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Section 02 - 06 自然言語で検索できると良さそう? CLIP[OpenAI. 2021]のImage/Text Encoderを用いて簡単な情報検索モデルが構築できる! • 比較的シンプルに文章で画像を検索することが可能](https://files.speakerdeck.com/presentations/ad584cadf54f4aed9a8f2790f219c738/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
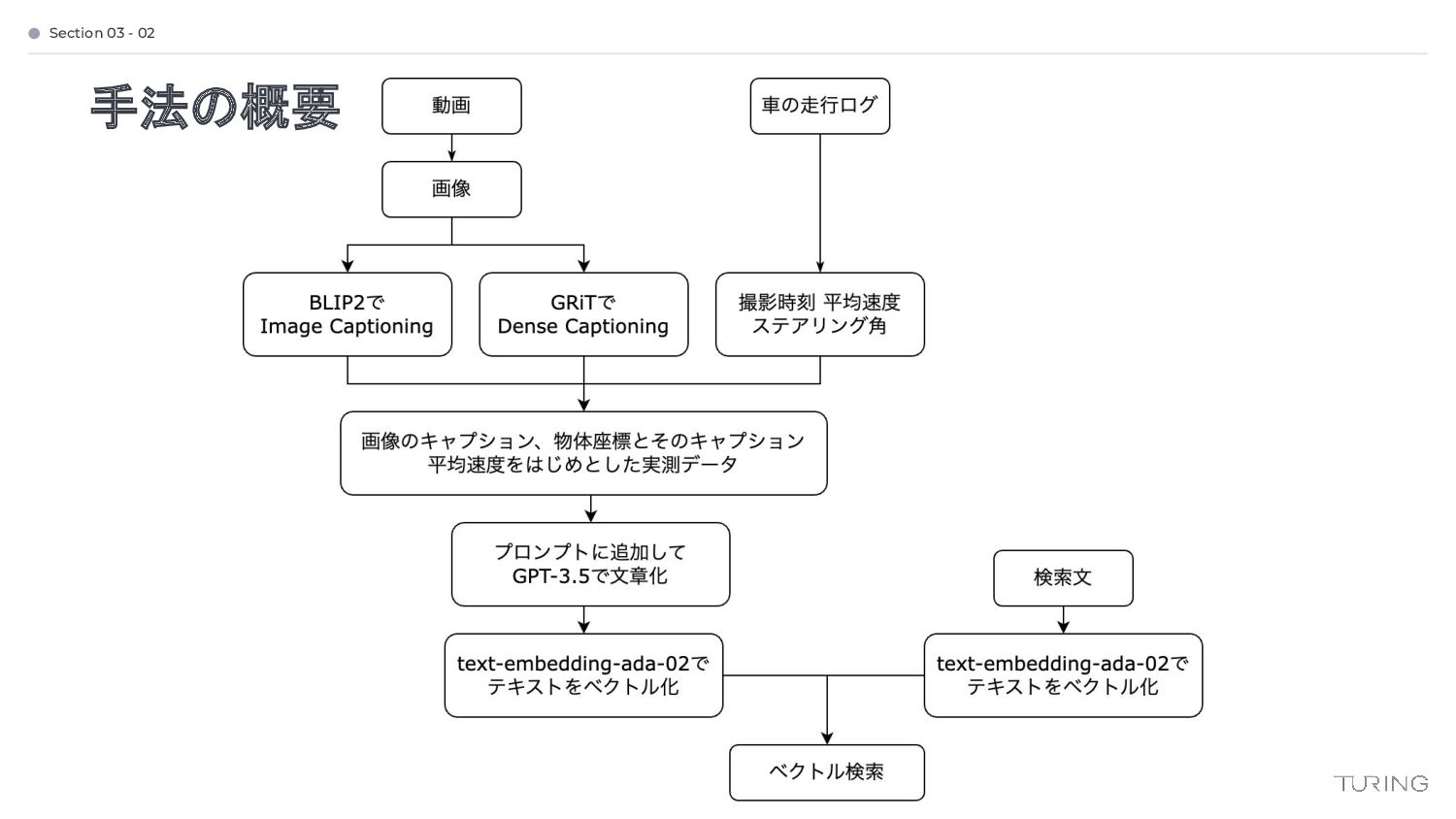{kind=link}
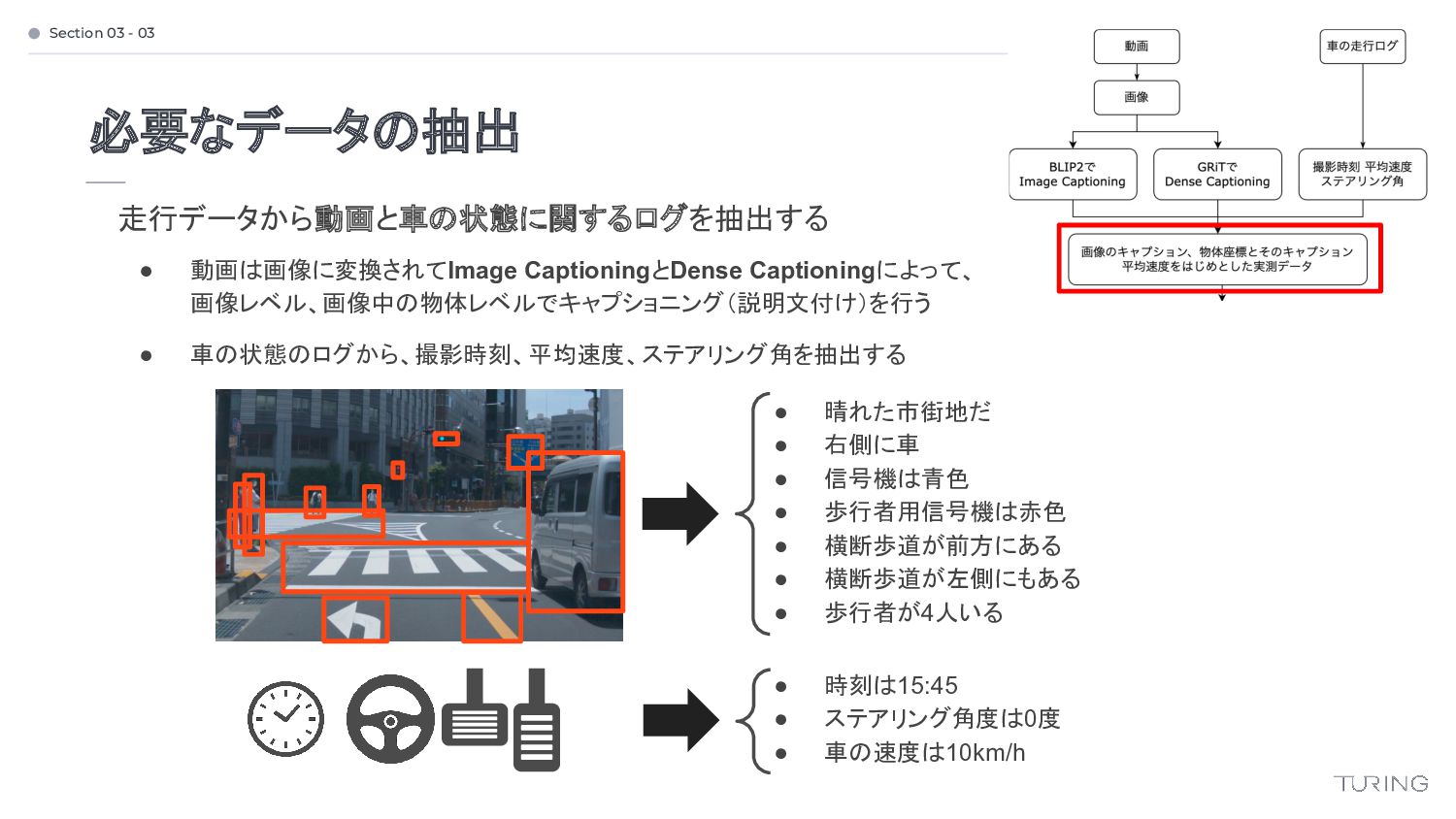{kind=link}
![Section 03 - 04 BLIP2による画像キャプショニング BLIP-2[Li et al. 2023]は、Image CaptioningなどImage-to-Textタスクで高精度なモデル](https://files.speakerdeck.com/presentations/ad584cadf54f4aed9a8f2790f219c738/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
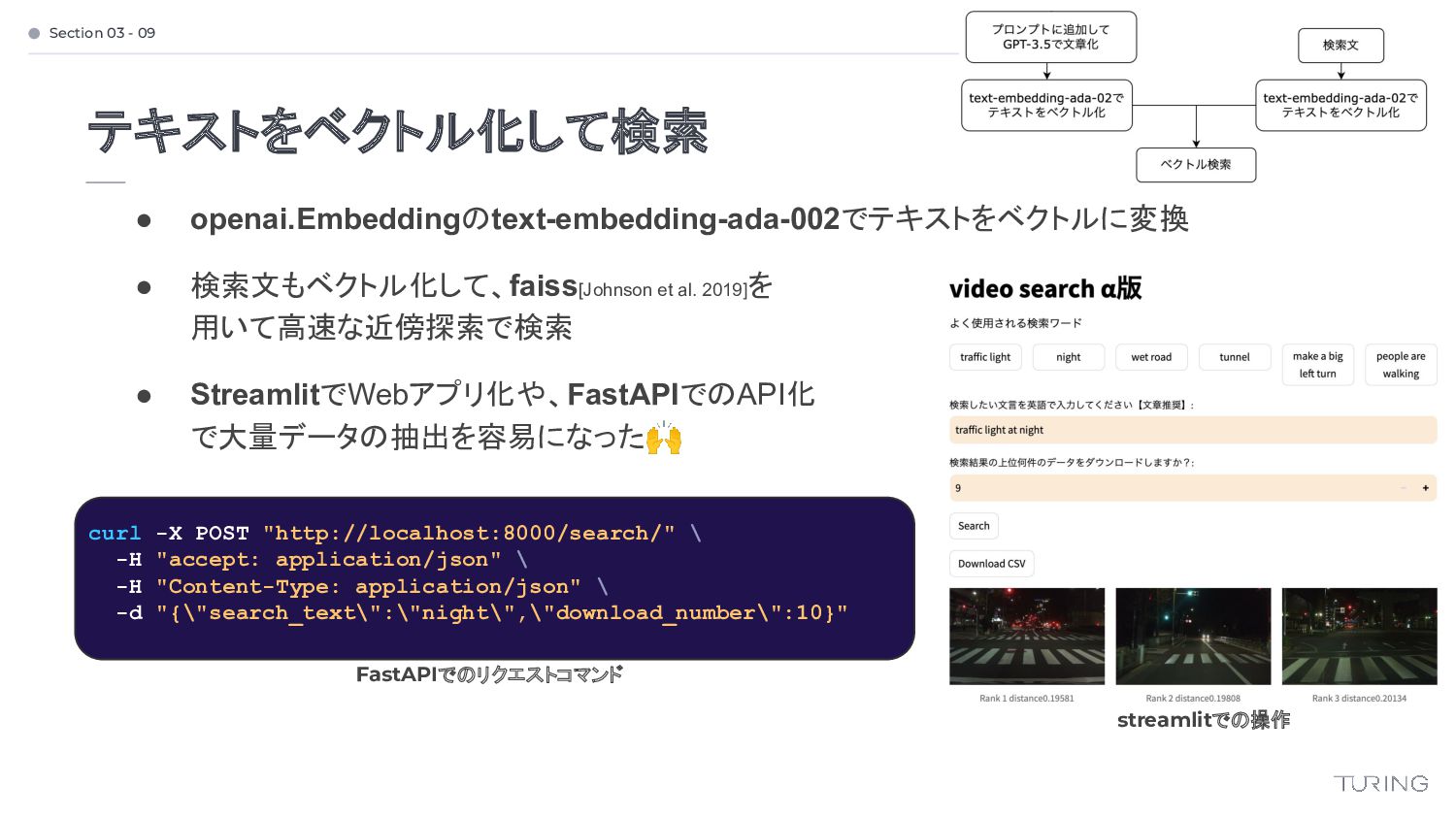{kind=link}
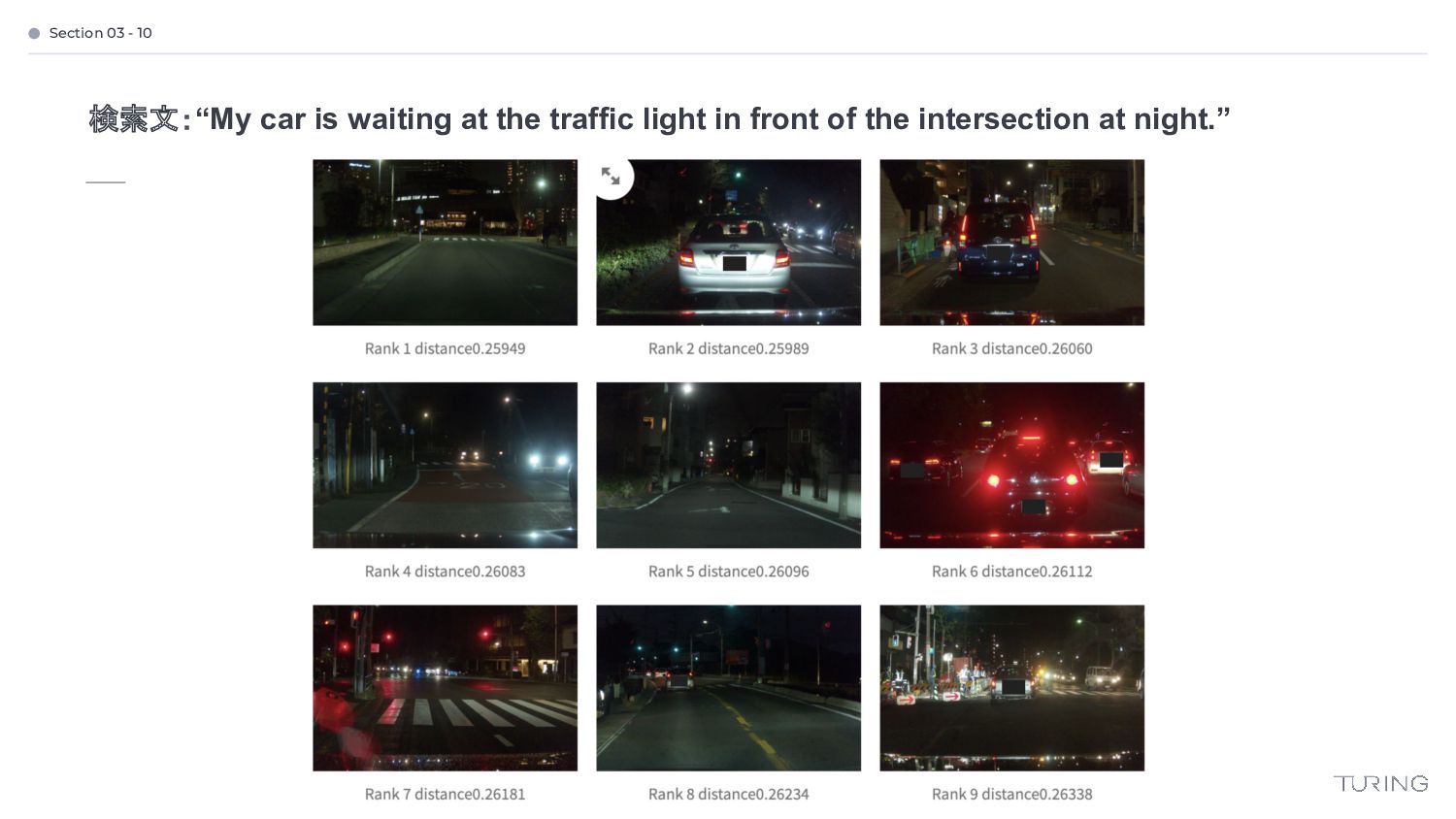{kind=link}
{kind=link}
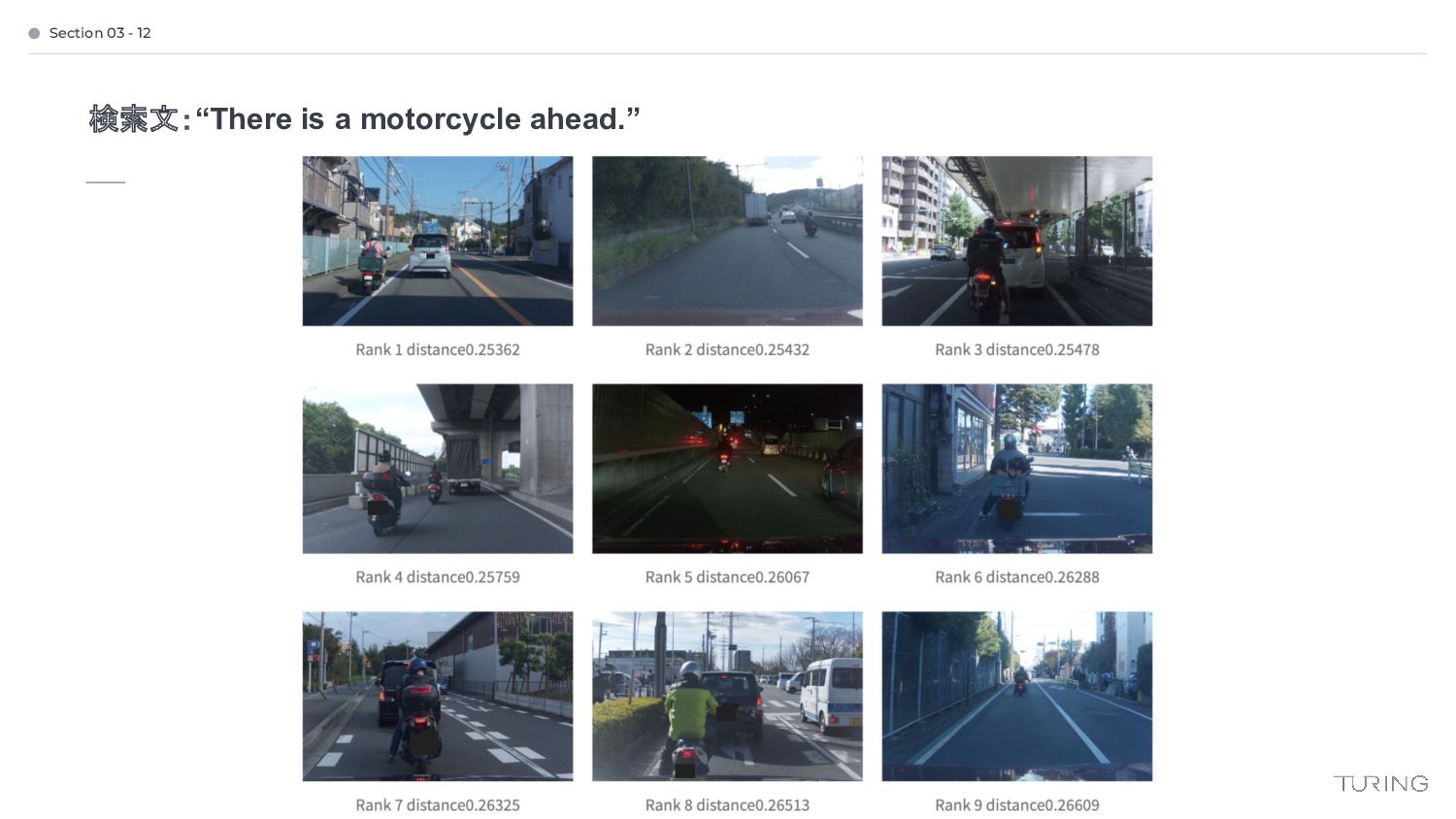{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}