Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Polarsで始める時系列データ処理 #atmaCup 19 振り返り会 LT枠
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Kohei Iwamasa
April 11, 2025
790
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Polarsで始める時系列データ処理 #atmaCup 19 振り返り会 LT枠
Kohei Iwamasa
April 11, 2025
More Decks by Kohei Iwamasa
See All by Kohei Iwamasa
numpyやPyTorchの配列にdtypeとshapeをアノテーションするjaxtypingのススメ
koheiiwamasa
4
2.2k
[関西Kaggler会2025#2LT] 初学者+MLエンジニア対象! モダンなPythonの書き方
koheiiwamasa
5
4.6k
[Turing Inc.] DUSt3R勉強会
koheiiwamasa
1
2.1k
自動運転開発の実験管理とKagglerたちの実験管理術
koheiiwamasa
1
870
FiT3D: Improving 2D Feature Representations by 3D-Aware Fine-Tuning - 第62回 コンピュータビジョン勉強会 ECCV論文読み会
koheiiwamasa
0
480
[IBIS2024 ビジネスと機械学習] 近年のData-Centricな 自動運転AI開発
koheiiwamasa
5
3.2k
LaneSegNet: Map Learning with Lane Segment Perception for Autonomous Driving - ICLR2024論文読み会
koheiiwamasa
0
1.2k
Unsupervised_3D_Perception_with_2D_Vision-Language_Distillation_for_Autonomous_Driving_CV勉強会
koheiiwamasa
3
650
大規模走行データを 効率的に活用する検索システムの開発 第3回Data-Centric AI勉強会
koheiiwamasa
0
1.3k
Featured
See All Featured
Claude Code のすすめ
schroneko
67
230k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
200
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
370
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
420
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
56
3.4k
The Limits of Empathy - UXLibs8
cassininazir
1
570
Large-scale JavaScript Application Architecture
addyosmani
515
110k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
310
Designing Powerful Visuals for Engaging Learning
tmiket
1
470
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
450
The Invisible Side of Design
smashingmag
301
52k
Transcript
Polarsで始める 時系列データ処理 #19 atmaCup 振り返り会 LT枠 @colum2131
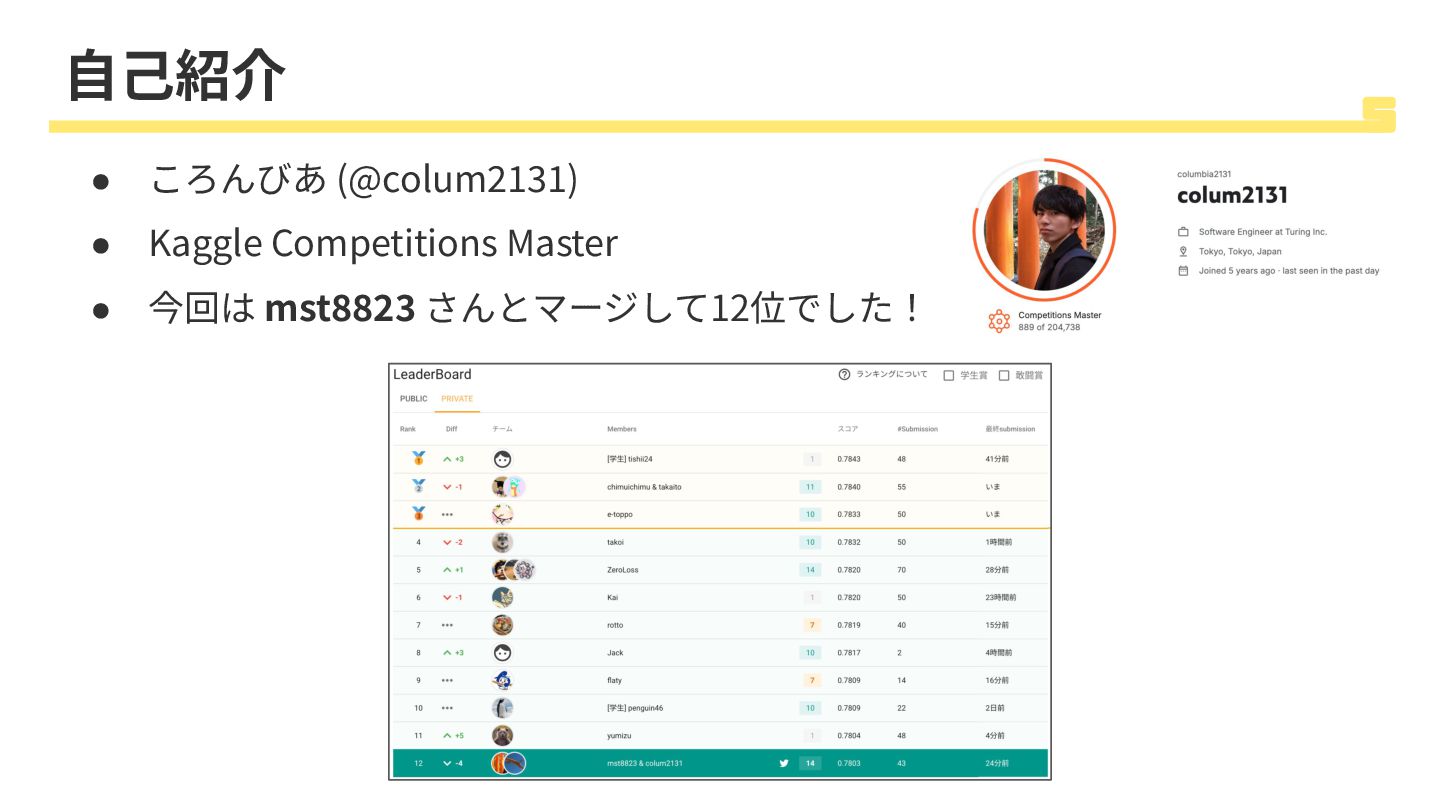
⾃⼰紹介 • ころんびあ (@colum2131) • Kaggle Competitions Master • 今回は
mst8823 さんとマージして12位でした!
Polarsはいいぞ • データ処理ライブラリ Polars の便利な時系列処理を紹介します • 本発表の発表はPolarsでデータ操作をしたことがある⽅を想定しています • Polarsのバージョンは 1.21.0
です これからPolarsを触る⼈にオススメな本!
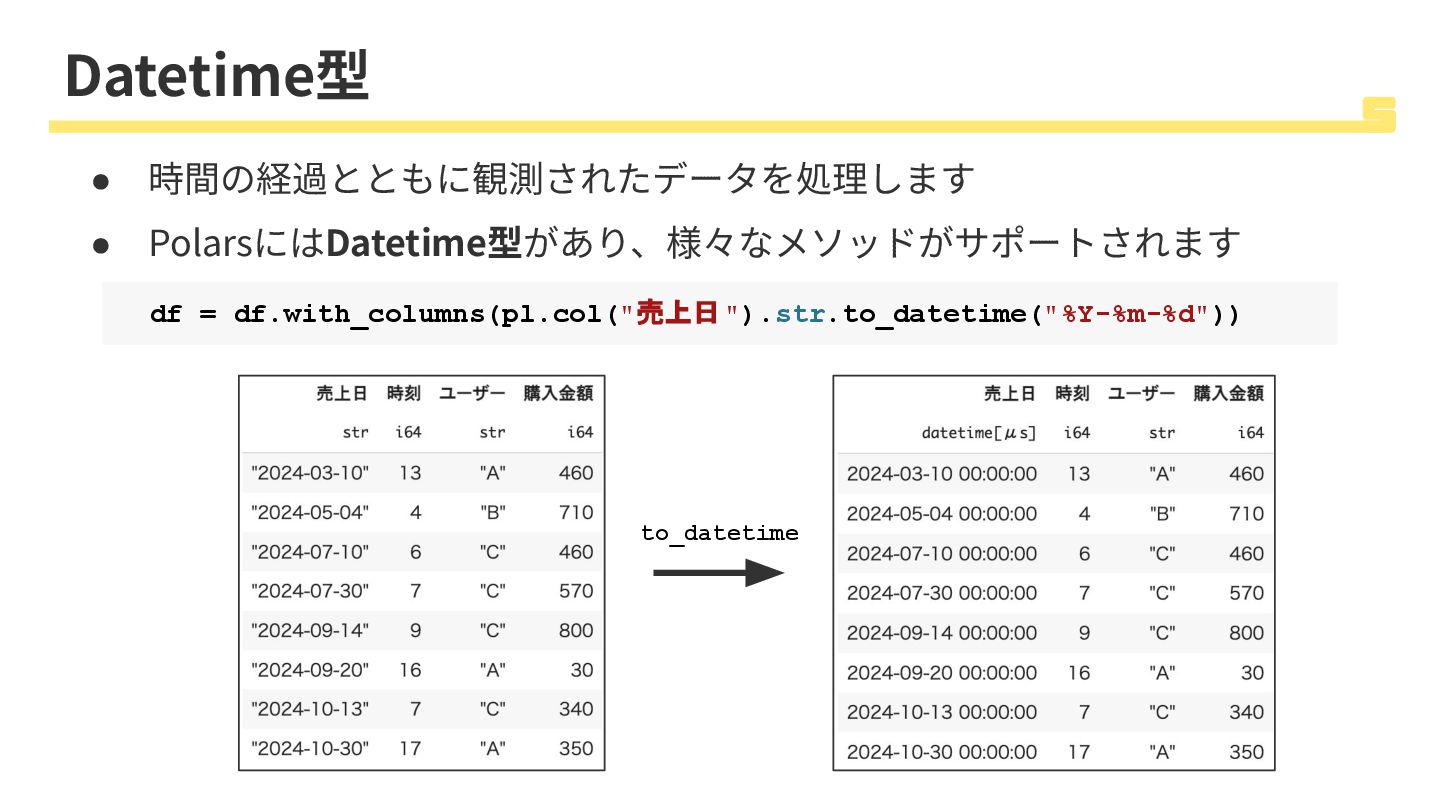
Datetime型 • 時間の経過とともに観測されたデータを処理します • PolarsにはDatetime型があり、様々なメソッドがサポートされます df = df.with_columns(pl.col("売上日").str.to_datetime("%Y-%m-%d")) to_datetime
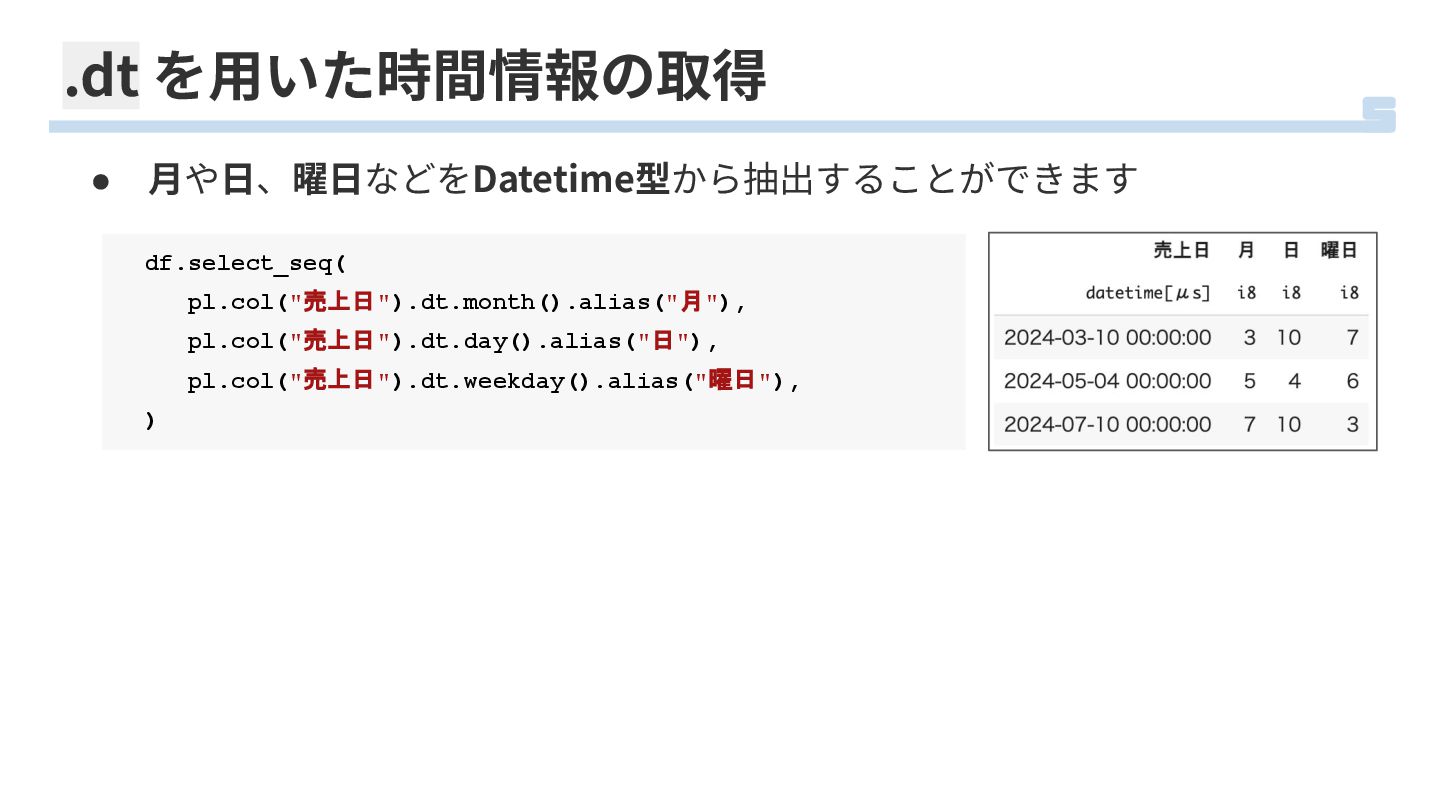
.dt を⽤いた時間情報の取得 • ⽉や⽇、曜⽇などをDatetime型から抽出することができます df.select_seq( pl.col("売上日").dt.month().alias("月"), pl.col("売上日").dt.day().alias("日"), pl.col("売上日").dt.weekday().alias("曜日"), )
集約と結合 • Polarsでは group_by でグループごとに計算することができます • 集約したテーブルをもとに join でデータフレームどうしを結合しましょう group_df
= df.group_by("ユーザー").agg(pl.col("購入金額").mean().alias("平均購入金額 ")) df.join(group_df, on="ユーザー", how="left") 集約データ join
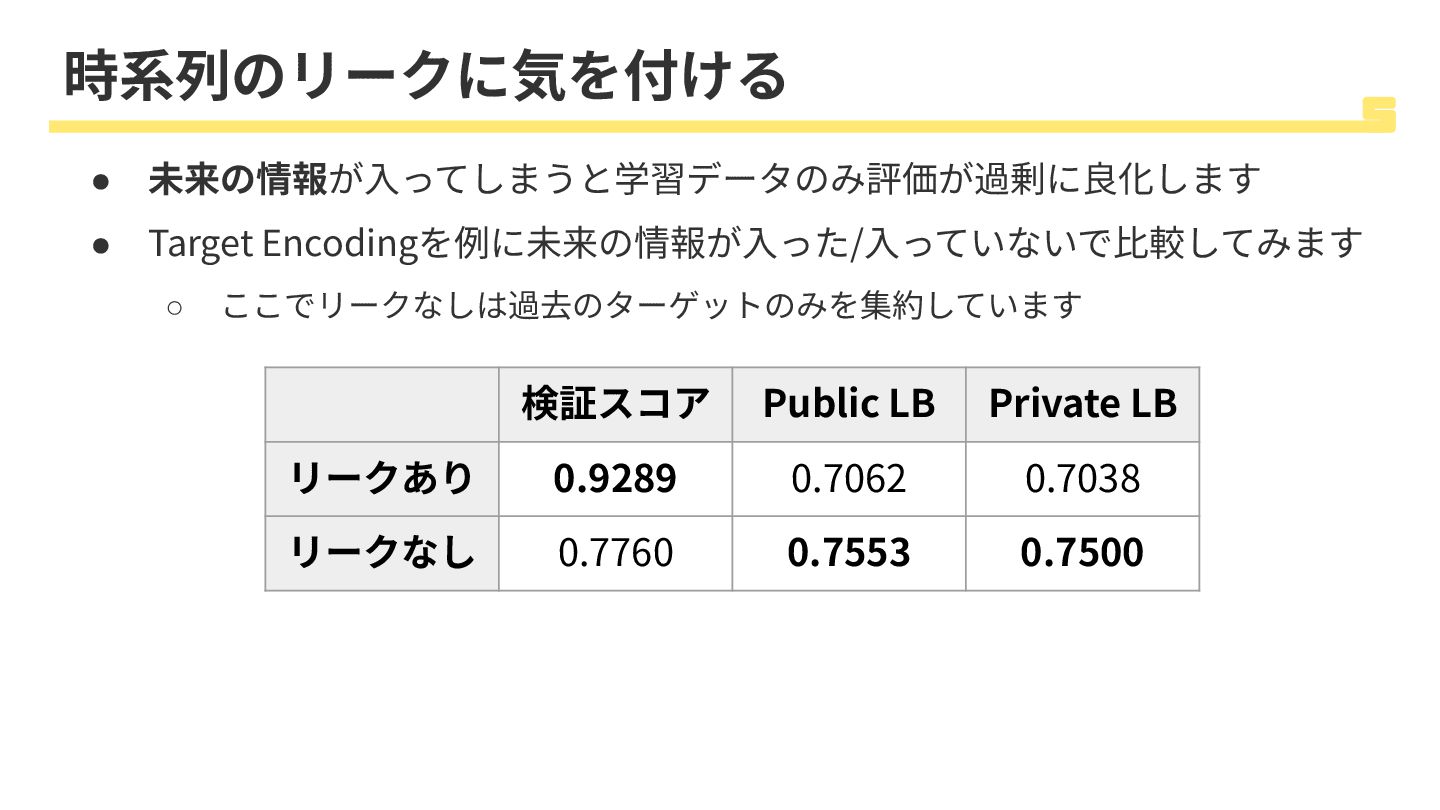
時系列のリークに気を付ける • 未来の情報が⼊ってしまうと学習データのみ評価が過剰に良化します • Target Encodingを例に未来の情報が⼊った/⼊っていないで⽐較してみます ◦ ここでリークなしは過去のターゲットのみを集約しています 検証スコア Public
LB Private LB リークあり 0.9289 0.7062 0.7038 リークなし 0.7760 0.7553 0.7500
Nステップ前の⾏動を抽出する • shift と over を⽤いることでグループごとにスライドすることができます ◦ pandasだとこういう処理: df.groupby("ユーザー")["購入金額"].shift(1) df.with_columns(pl.col("購入金額").shift(1).over("ユーザー").name.prefix("shift1_"))
• データの並び順に要注意!sort を忘れずに • over を使った便利メソッドは以下: ◦ diff ◦ cum_sum ◦ cum_count ... Nステップ前との差分 ... これまでの累積和 ... これまでの出現数 など
Datetime型の列間で⽐較する • Datetime型を⽐較 (差) を取るとその差で Duration型 に変換されます df.with_columns((pl.col("売上日") - pl.col("売上日").shift(1).over("ユーザー")).alias("間隔"))
• pl.col("売上日").diff(1).over("ユーザー") も同様 • Duration型からfloat型に変換する場合は pl.duration(days=1) などで割ると👍 ◦ そのままだと μs 単位で値が⼤きくなるため df.with_columns((pl.col("間隔") / pl.duration(days=1)) pl.duration (days=1)で割る pl.col("売上日") + pl.duration(hours=pl.col("時刻")) • Datetime型 に時刻を⾜すことも可能
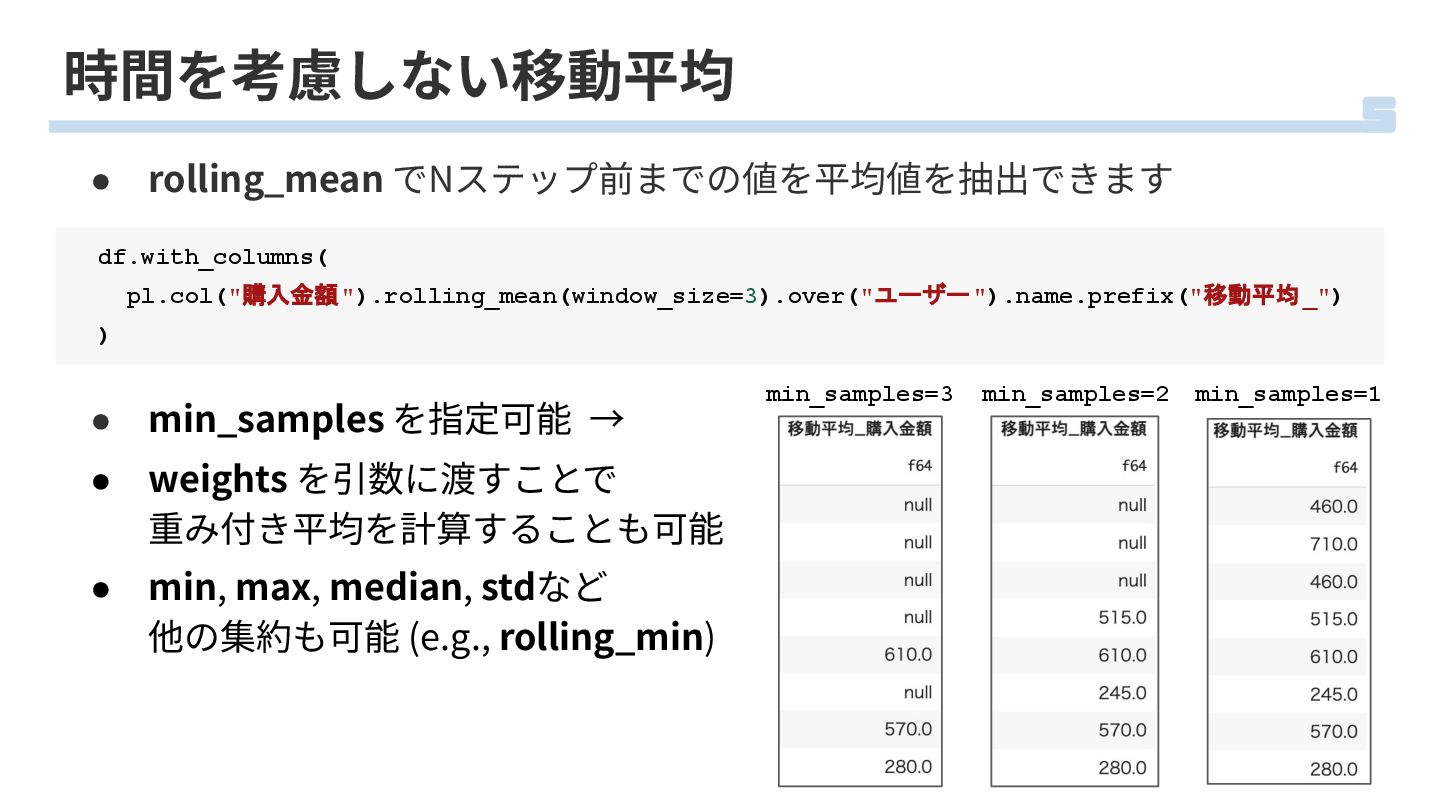
時間を考慮しない移動平均 • rolling_mean でNステップ前までの値を平均値を抽出できます df.with_columns( pl.col("購入金額").rolling_mean(window_size=3).over("ユーザー").name.prefix("移動平均_") ) min_samples=3 min_samples=2 min_samples=1
• min_samples を指定可能 → • weights を引数に渡すことで 重み付き平均を計算することも可能 • min, max, median, stdなど 他の集約も可能 (e.g., rolling_min)
時間を考慮する移動平均 • rolling を使うことで時間を考慮した集約が可能です df.rolling(index_column="売上日", group_by="ユーザー", period="1mo") \ .agg(pl.col("購入金額").mean().name.prefix("移動平均_")) •
index_column はDatetime型の列、 group_by はグループの列を指定します • period で範囲を指定することができます ◦ 1d は1⽇、2w は2週間 など • 元の並び順がシャッフルされた異なる データフレームが返されます ◦ そのまま横結合するとダメ (1敗)
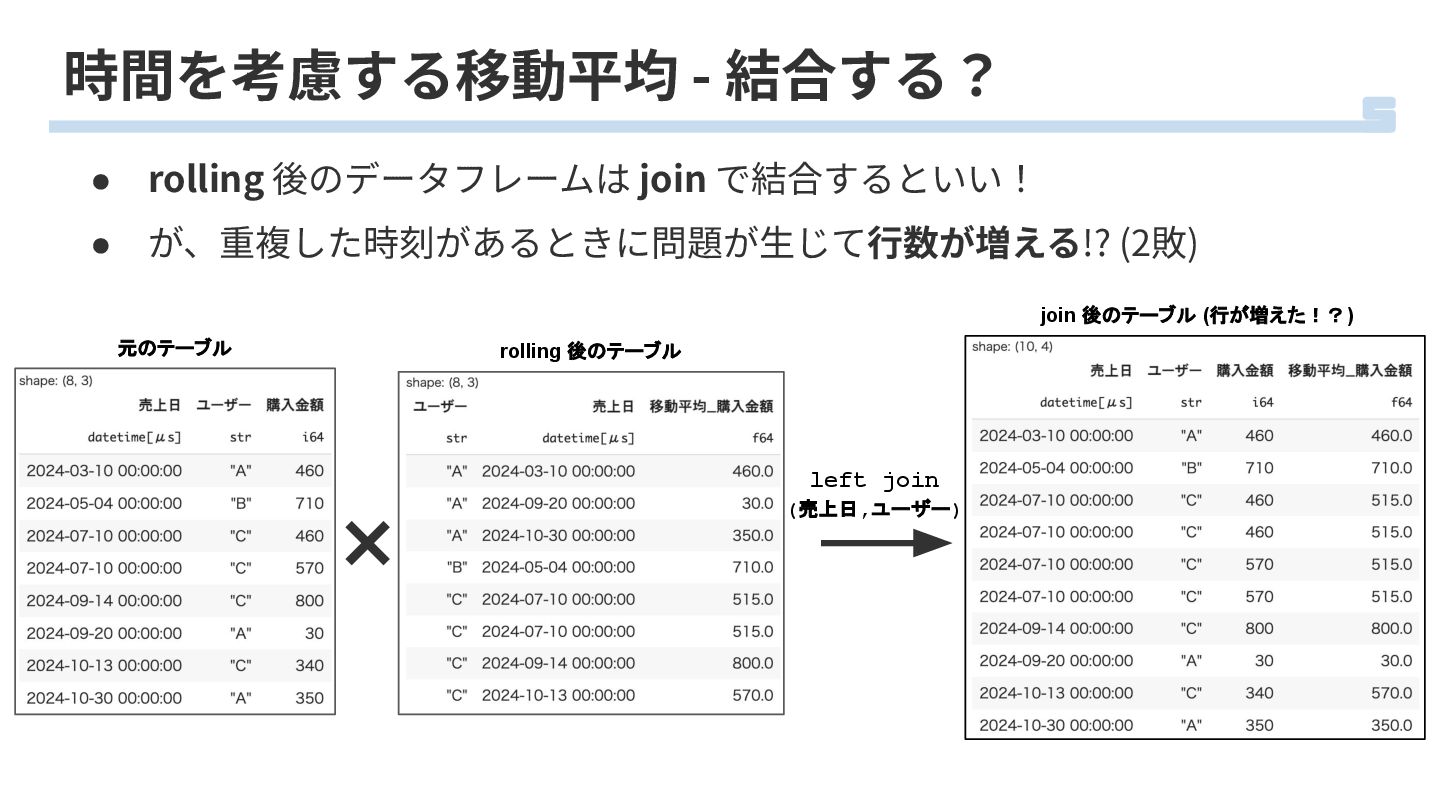
時間を考慮する移動平均 - 結合する? • rolling 後のデータフレームは join で結合するといい! • が、重複した時刻があるときに問題が⽣じて⾏数が増える!?
(2敗) left join (売上日,ユーザー) rolling 後のテーブル 元のテーブル join 後のテーブル (行が増えた!?)
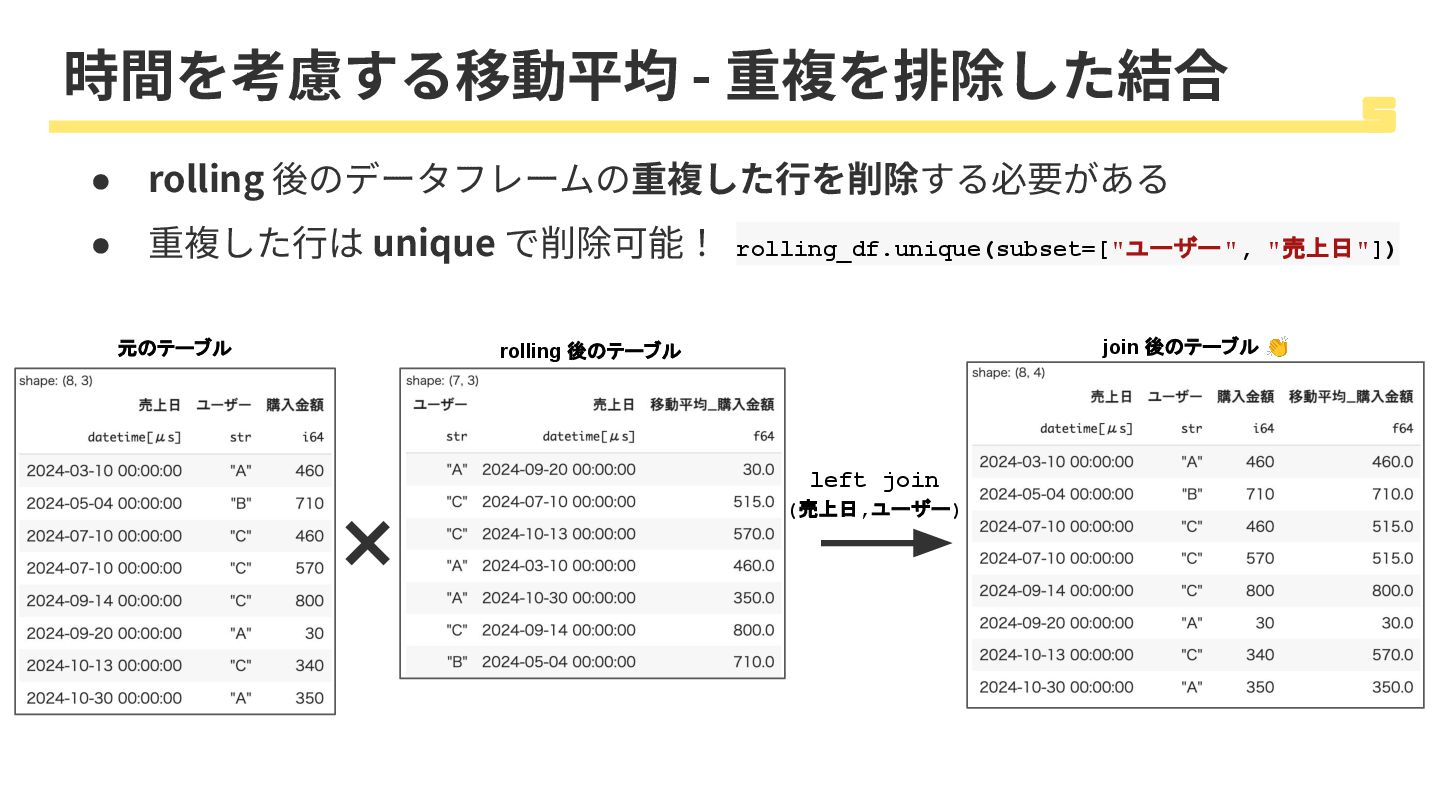
時間を考慮する移動平均 - 重複を排除した結合 • rolling 後のデータフレームの重複した⾏を削除する必要がある • 重複した⾏は unique で削除可能!
rolling_df.unique(subset=["ユーザー", "売上日"]) 元のテーブル join 後のテーブル 👏 rolling 後のテーブル left join (売上日,ユーザー)
時間を考慮する移動平均 - offsetの指定 • rolling は period の他 offset を引数に加えることで挙動が変わる
• period も offset も同じ⽂字列⽅式で、offset はマイナスの指定も可能 https://docs.pola.rs/api/python/stable/reference/dataframe/api/polars.DataFrame.rolling.html offsetがNoneの場合は、 period遡った時刻から現時刻までを集約 offsetが指定された場合は、 現時刻からoffset分加算された時間から offsetとperiod分加算された時間までを集約
時間を考慮する移動平均 - offsetの指定の例 • 2週間前から1週間前までの集約する場合: df.rolling(index_column="売上日", group_by="ユーザー", period="1w", offset="-2w") •
1週間前から1週間先までの集約する場合: df.rolling(index_column="売上日", group_by="ユーザー", period="2w", offset="-1w") • rolling は closed を設定することで条件に重なる箇所を含めるか変更可能 ◦ offset も None, closedも"none" に設定することで現時刻を含めない処理!
まとめと注意 • Polarsには時系列データ処理⽤の便利なメソッドがたくさんある! • Polarsは特定の処理で⾏の順番が変わることがあるので要注意! • Polarsは破壊的変更が⼊る可能性があるためバージョンには要注意! ◦ 技術書や記事を参考にしながら公式ドキュメントも⾒ましょう •
もし他にいいコードの書き⽅があれば教えてください🙏 ◦ 発表者はPolars歴が浅いです…
Appendix
時系列を考慮したTarget Encoding (ベイズ推定) • クルトンさんのベイズ推定によるシンプルな推論を Target Encodingの代わりに使うことで精度改善! ◦ CatBoostのTarget Encodingとほぼ⼀緒!
TE 検証スコア Public LB Private LB リークなし 0.7760 0.7553 0.7500 ベイズ推定 0.7849 0.7607 0.7562 • コードはこちらに! https://www.guruguru.science/competitions/26/discussions/054b216b-2375-4608-9e2d-ee2a655049e4/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Nステップ前の⾏動を抽出する • shift と over を⽤いることでグループごとにスライドすることができます ◦ pandasだとこういう処理: df.groupby("ユーザー")["購入金額"].shift(1) df.with_columns(pl.col("購入金額").shift(1).over("ユーザー").name.prefix("shift1_"))](https://files.speakerdeck.com/presentations/5f4756e69d924aefbbf049d8a97a6e40/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}