Kun Jiang, Junchi Yan and Hongyang Li. LaneSegNet: Map Learning with Lane Segment Perception for Autonomous Driving. In ICLR, 2024. 2. Huijie Wang, Tianyu Li, Yang Li, Li Chen, Chonghao Sima, Zhenbo Liu, Yuting Wang, Shengyin Jiang, Peijin Jia, Bangjun Wang, Feng Wen, Hang Xu, Ping Luo, Junchi Yan, Wei Zhang, and Hongyang Li. Openlane-v2: A topology reasoning benchmark for scene understanding in autonomous driving. In NeurIPS, 2023. 3. Bencheng Liao, Shaoyu Chen, Xinggang Wang, Tianheng Cheng, Qian Zhang, Wenyu Liu, and Chang Huang. MapTR: Structured modeling and learning for online vectorized HD map construction. In ICLR, 2023. 4. Tianyu Li, Li Chen, Huijie Wang, Yang Li, Jiazhi Yang, Xiangwei Geng, Shengyin Jiang, Yuting Wang, Hang Xu, Chunjing Xu, Junchi Yan, Ping Luo, and Hongyang Li. Graph-based topology reasoning for driving scenes. arXiv preprint arXiv:2304.05277, 2023. 5. Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko. End-to-End Object Detection with Transformers. In ECCV, 2020. 6. Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. In ICLR, 2020. 7. Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In ECCV, 2022. 8. Shihao Wang, Yingfei Liu, Tiancai Wang, Ying Li and Xiangyu Zhang. Exploring Object-Centric Temporal Modeling for Efficient Multi-View 3D Object Detection. In ICCV, 2023.
{kind=link}
{kind=link}
![データセット - OpenLane-V2 [Wang+ NeruIPS2023] • 既存のデータセットをもとに⾞線や中⼼線、交通要素(e.g., 標識、信号機)が付与 ◦ 加えて、中⼼線間のトポロジーや中⼼線と交通要素のトポロジーも付与](https://files.speakerdeck.com/presentations/14bdc7a51161438bbd70a1b20e011b9b/slide_2.jpg){kind=link}
![先⾏研究 MapTR [Liao+ ICLR2023] TopoNet [Li+ 2023] ⭕ ⾞線‧中⼼線検出やトポロジー認識をEnd-to-Endに予測、リアルタイム性 ❌](https://files.speakerdeck.com/presentations/14bdc7a51161438bbd70a1b20e011b9b/slide_3.jpg){kind=link}
![予測対象 LaneSegNet [Li+ ICLR2024]](https://files.speakerdeck.com/presentations/14bdc7a51161438bbd70a1b20e011b9b/slide_4.jpg){kind=link}
![定性的な評価 LaneSegNet [Li+ ICLR2024]](https://files.speakerdeck.com/presentations/14bdc7a51161438bbd70a1b20e011b9b/slide_5.jpg){kind=link}
![モデル構造 • Encoder: マルチカメラ画像からBEV特徴(Bird’s-Eye-View)をBEVFormer[Li+ ECCV2022]で抽出 • Decoder: Lane Attentionを⽤いてBEV特徴からLane Segment](https://files.speakerdeck.com/presentations/14bdc7a51161438bbd70a1b20e011b9b/slide_6.jpg){kind=link}
![*DETR [Carion+ ECCV2020] • Transformerを⽤いた物体検出フレームワークで、LaneSegNetはDETR-likeな構造 ◦ 特徴マップに位置埋め込みを⾏いtransformer-encoderで処理してKey, Valueとし、 学習可能なObject Queryにtransformer-decoderで処理して更新した各QueryをMLPで物体予測](https://files.speakerdeck.com/presentations/14bdc7a51161438bbd70a1b20e011b9b/slide_7.jpg){kind=link}
![*Deformable Attention [Zhu+ ICLR2021] • DETRのtransformerを効率的なAttentionに変換して10倍少ないepoch数で収束 • 各特徴マップのQuery座標の参照点(x, y)、Queryを⼊⼒とした線形層でoffsets(Δx, Δy)とattention](https://files.speakerdeck.com/presentations/14bdc7a51161438bbd70a1b20e011b9b/slide_8.jpg){kind=link}
![*BEVFormer [Li+ ECCV2022] • Deformable AttentionベースでBEV Queryを構築するモデル • 各カメラ画像の特徴マップをKey, ValueとしてBEV](https://files.speakerdeck.com/presentations/14bdc7a51161438bbd70a1b20e011b9b/slide_9.jpg){kind=link}
![*BEVFormer [Li+ ECCV2022] • BEV Queryは実世界スケールの平⾯であり、[Height×Width×Channel]のテンソル • Spatial Attentionは各グリッドセルの3次元点(x, y,](https://files.speakerdeck.com/presentations/14bdc7a51161438bbd70a1b20e011b9b/slide_10.jpg){kind=link}
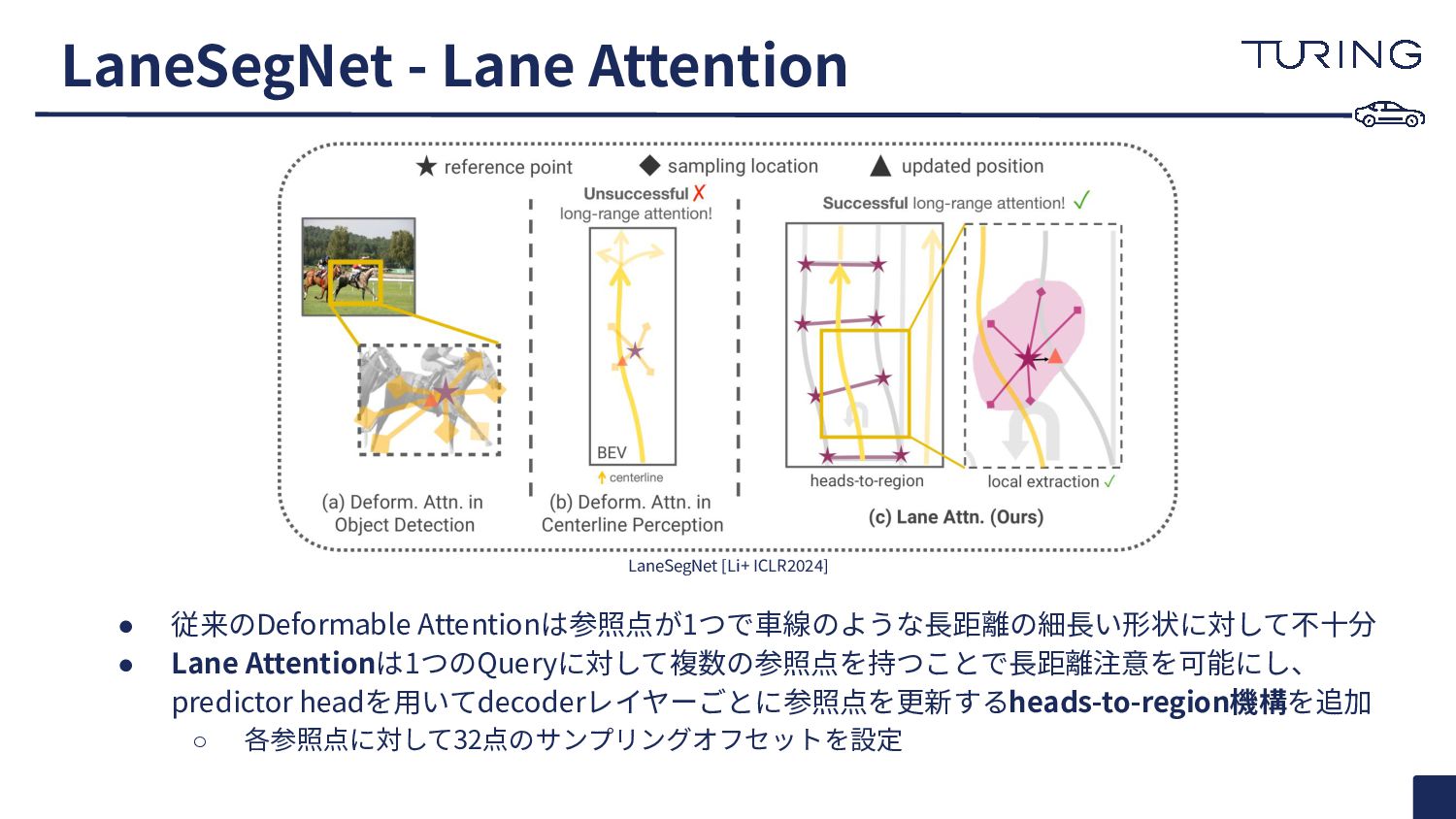{kind=link}
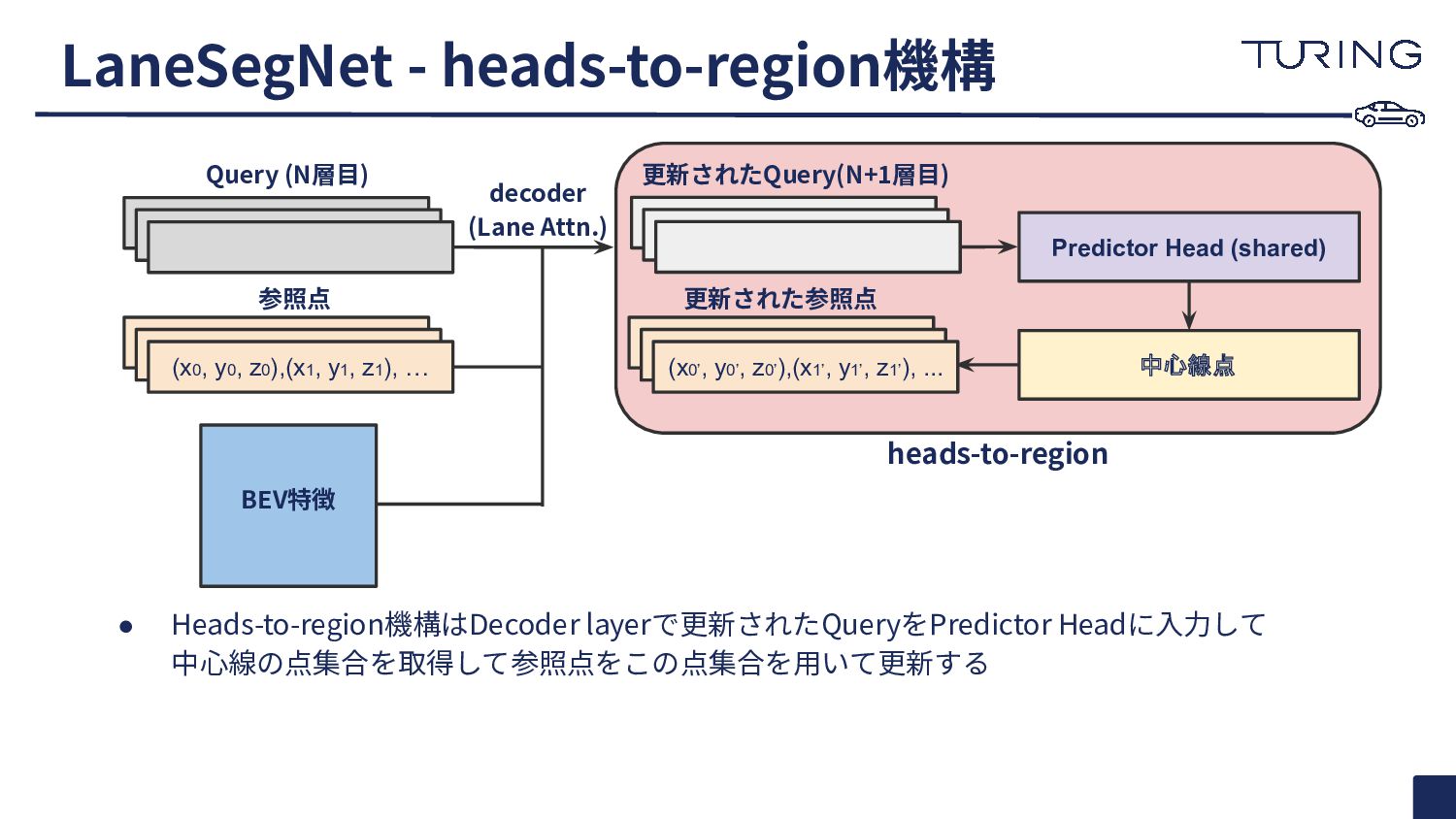{kind=link}
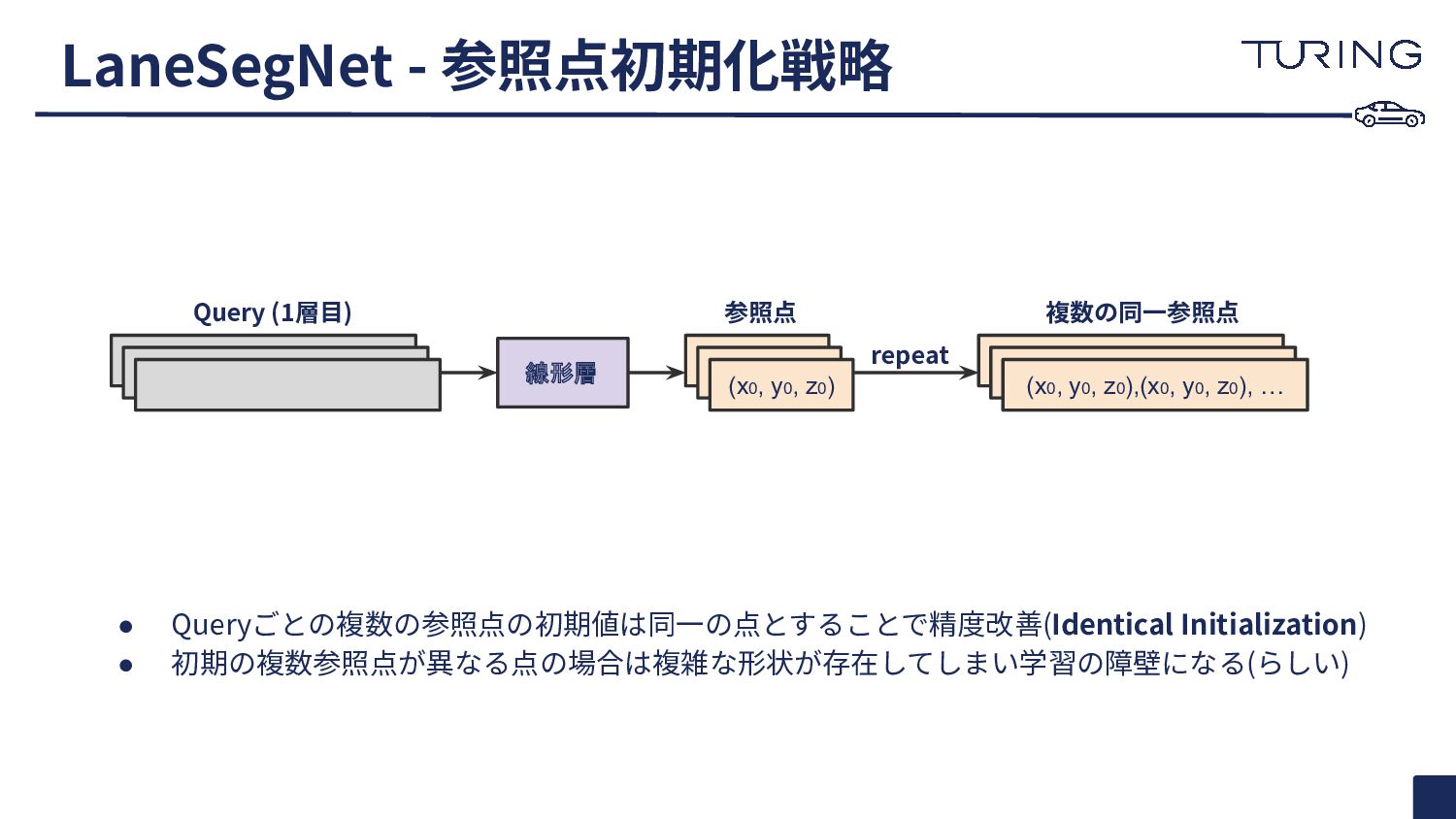{kind=link}
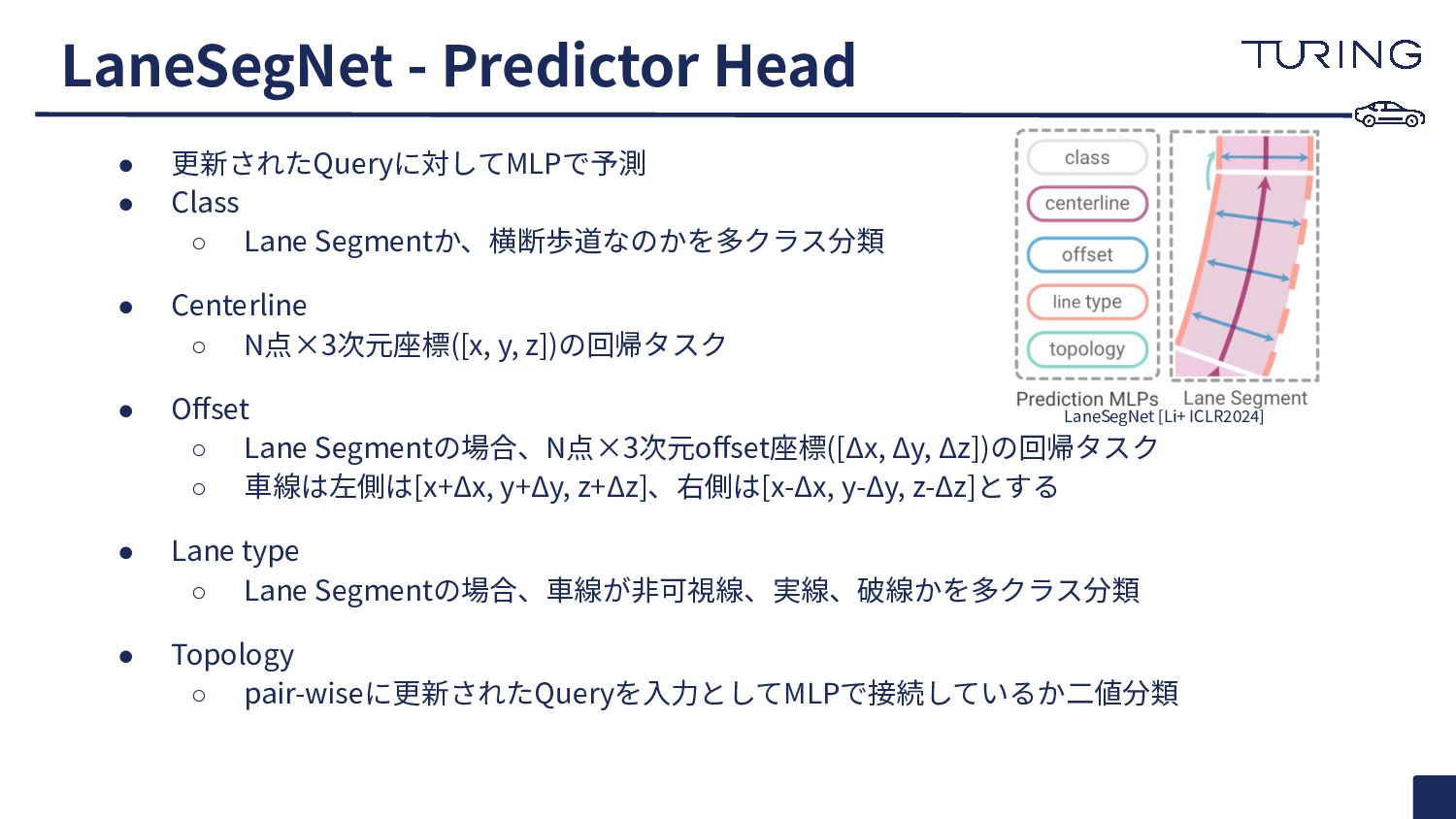{kind=link}
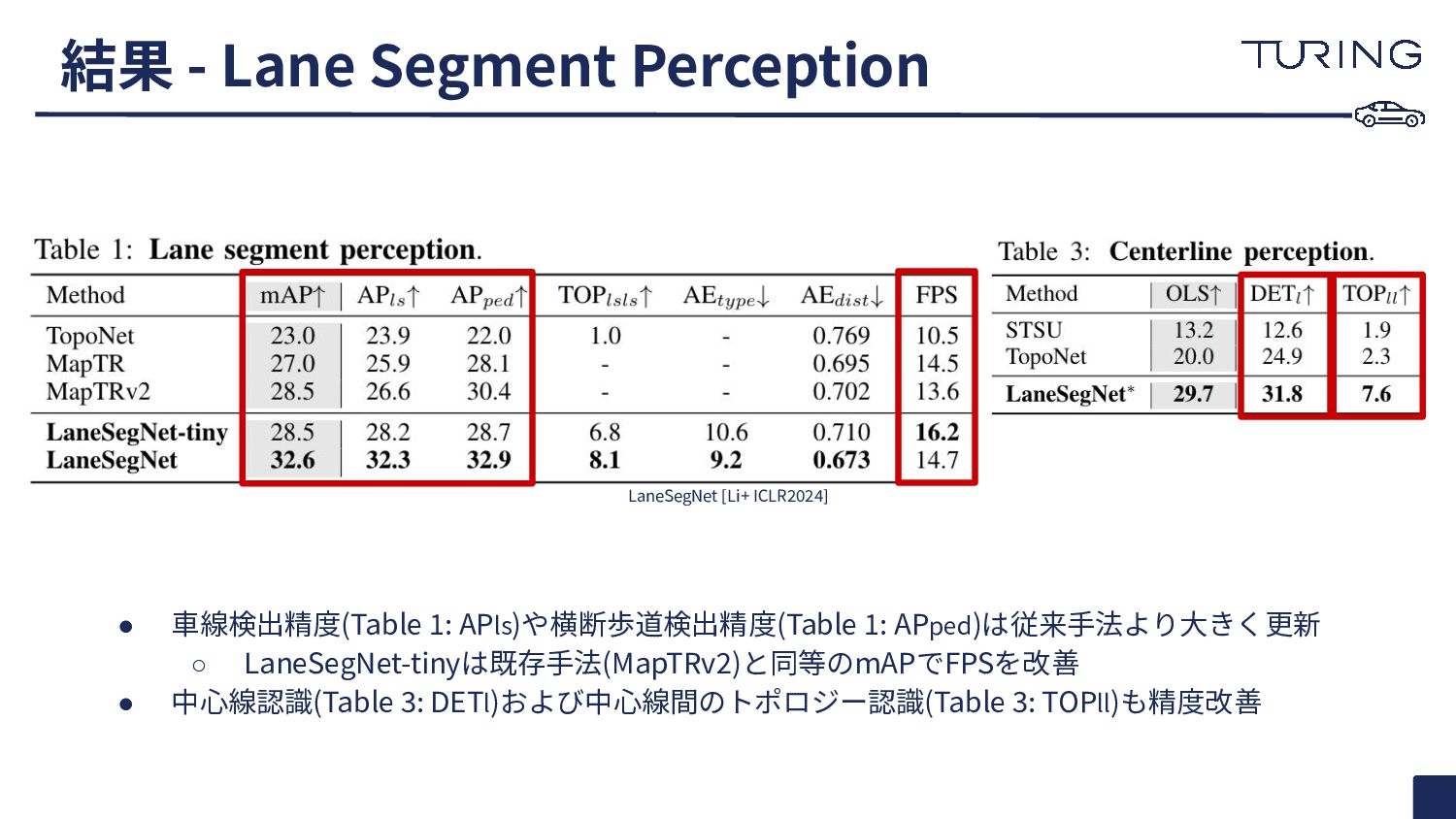{kind=link}
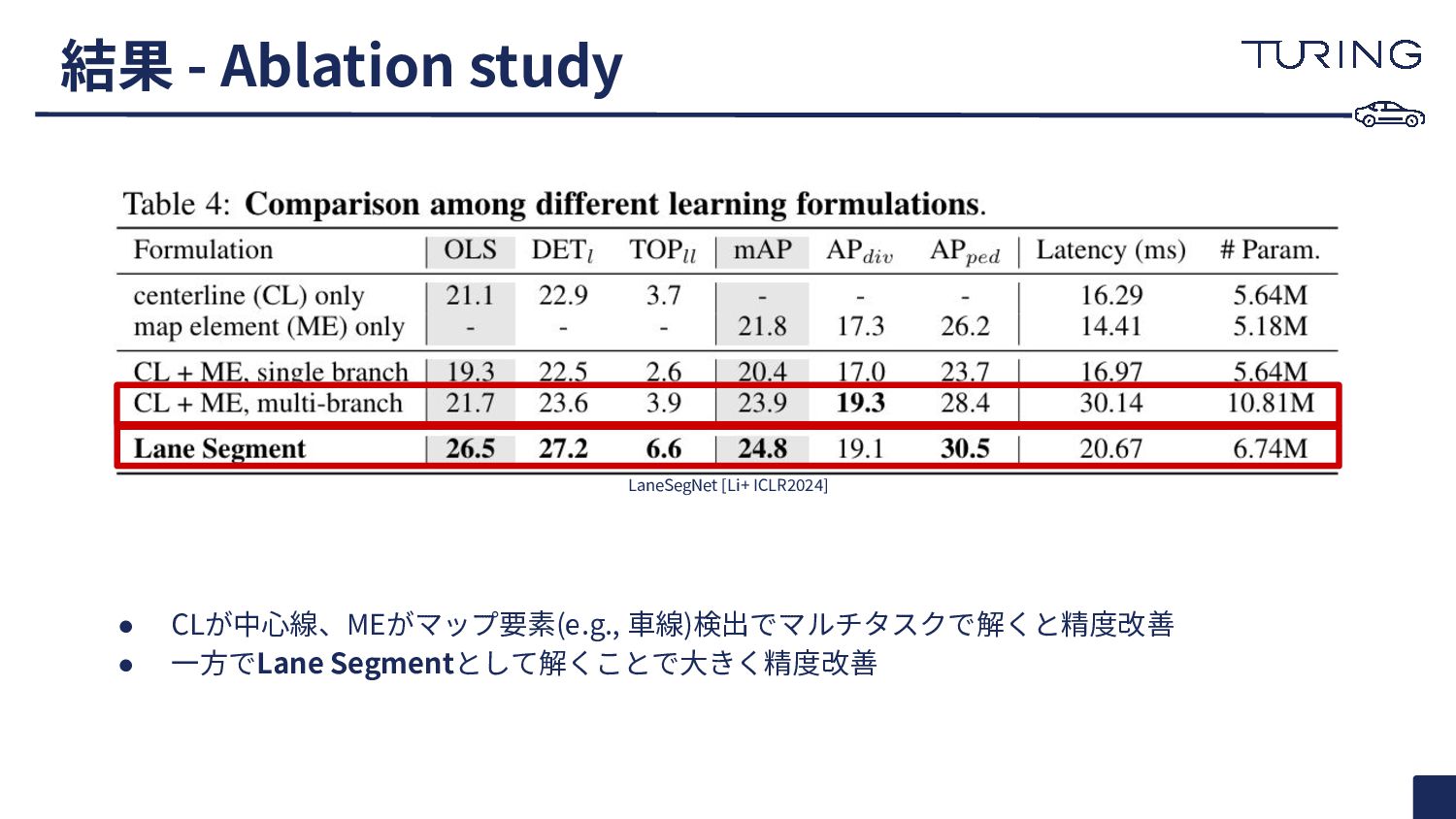{kind=link}
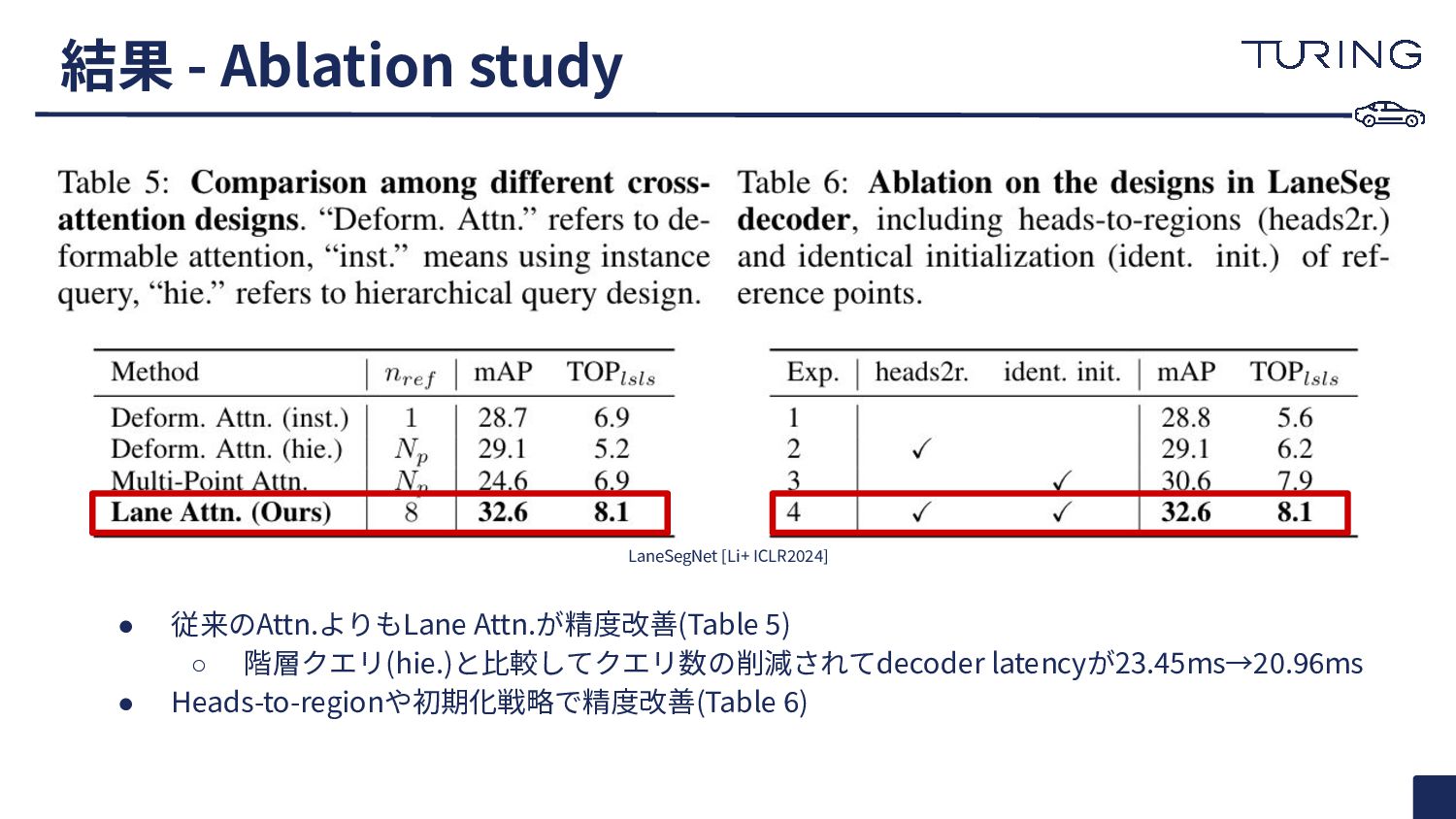{kind=link}
{kind=link}
{kind=link}
{kind=link}