for end-to-end RAG workflow" Amazon Bedrock Knowledge Bases (KB) integrates with S3 and OpenSearch to automatically split, embed, and store documents. It quickly retrieves the most relevant context in response to user queries and passes the results to an LLM, abstracting and simplifying the entire Retrieval + Generation workflow. This reduces the burden of building and managing complex RAG pipelines, allowing developers to focus on application development.
RAG application which can answer questions about Tokyo Resources List Resource Acount A Acount B IAM role for notebook arn:aws:iam::aaaaaaaaaaaa:role/service-role/AmazonSageMak er-ExecutionRole-A arn:aws:iam::bbbbbbbbbbbb:role/service-role/AmazonSa geMaker-ExecutionRole-b Jupyter notebook Your own resource S3 s3://bedrock-study-session-a s3://bedrock-study-session-b Knowledge Bases Your own resource
A Acount B OpenSearch Your own resource Embedding model amazon.titan-embed-text-v2:0 LLM Notice Basis: This hands-on session is based on the book "AWS Generative AI Application Development Practical Guide" (Japanese: "AWS生成AIアプリ構築実践ガイド"). Disclaimer: Since the book was written during 2024 to early 2025, the situation and specifications may differ from the current state. We recommend re-investigating and verifying the latest information before using this content for business purposes. amazon.nova-lite-v1:0 anthropic.claude-3-haiku-20240307-v1:0
the Amazon Bedrock service from the AWS Management Console. 2 Select Knowledge Bases Menu From the left navigation menu, select Knowledge Bases. 3 Click Create Button Click the Create button to start creating a new Knowledge Base. 4 Select Vector Store Type Select Knowledge Base with vector store and proceed to the next step.
→ "Titan Text Embeddings V2" Vector Store Type Amazon OpenSearch Serverless Other fields Keep at default settings Important Notes Knowledge Base creation takes several minutes to 5 minutes. After creation, copy the KB ID and Data Source ID from the management console. Sync the data source after creation.
Role Use shared IAM role Execution Steps 1 Launch Notebook Instance Start the Notebook instance you created from the SageMaker console. 2 Open JupyterLab After the instance starts, click Open JupyterLab. 3 Clone GitHub Repository Clone the GitHub repository in the SageMaker directory. 4 Open Notebook File Open ch06_rag_handson/rag_handson.ipynb. Other fields: Keep other fields at their default settings.
ch06_rag_handson/rag_handson.ipynb step by step. 2 Execute each cell in order and verify the output results. 3 The final cell will automatically launch the Streamlit app. Browser Access Once the Streamlit app is running, open the following URL in your browser to access the application. https://bedrock-study-session-<your-name>.notebook.ap-northeast-1.sagemaker.aws/proxy/absolute/8501
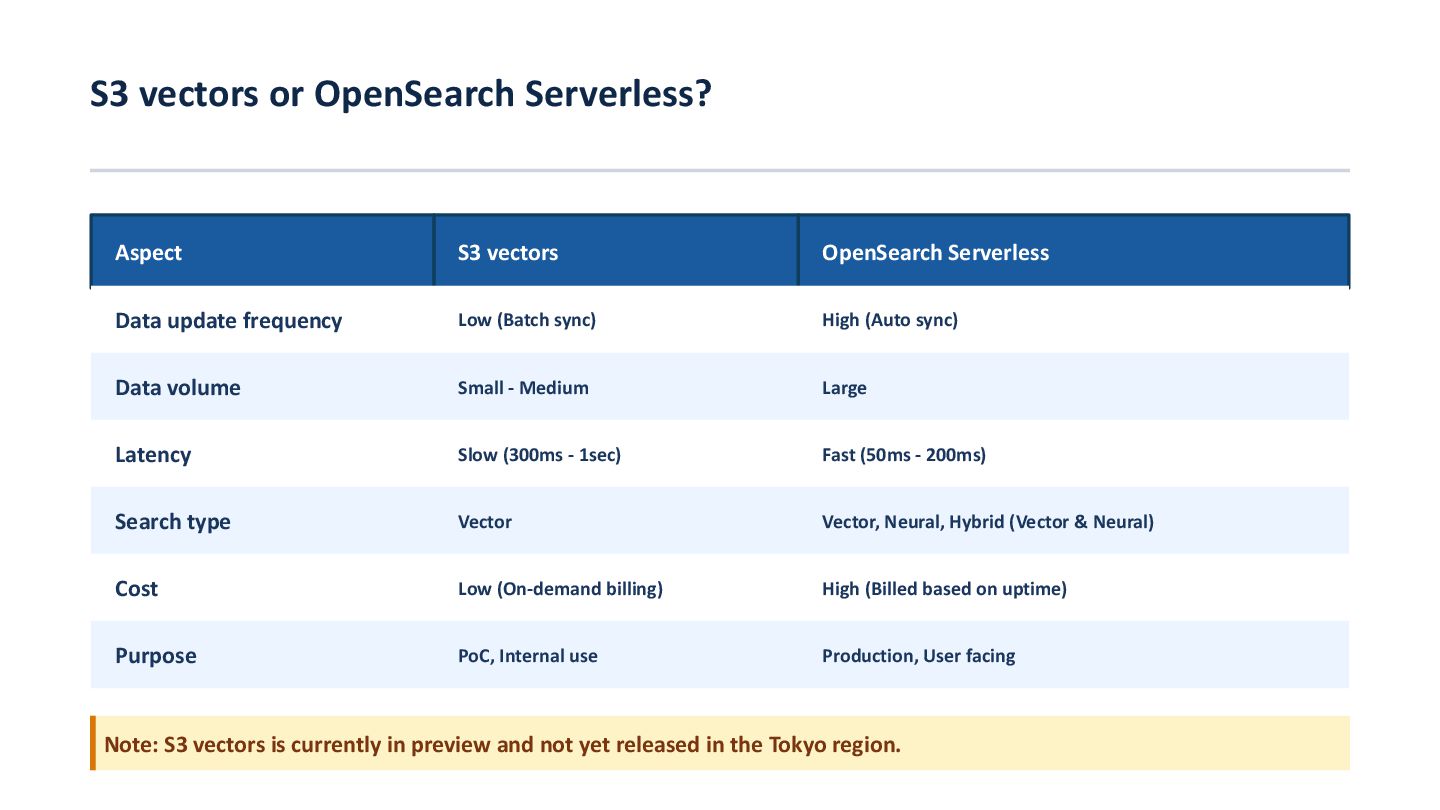
Data update frequency Low (Batch sync) High (Auto sync) Data volume Small - Medium Large Latency Slow (300ms - 1sec) Fast (50ms - 200ms) Search type Vector Vector, Neural, Hybrid (Vector & Neural) Cost Low (On-demand billing) High (Billed based on uptime) Purpose PoC, Internal use Production, User facing Note: S3 vectors is currently in preview and not yet released in the Tokyo region.
the search accuracy of Knowledge Bases RAG. Evaluation Methods LLM as a Judge Evaluation-Driven Development Use LLM as an evaluator to automatically assess the response quality of the RAG system. This enables continuous improvement. Search Accuracy Measurement Quantify metrics such as relevance, completeness, and accuracy of search results to objectively evaluate Knowledge Base performance. Reference Materials Bedrock Evaluations for quantitative evaluation of Knowledge Bases RAG search accuracy - LLM as a Judge evaluation-driven development | DevelopersIO
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}