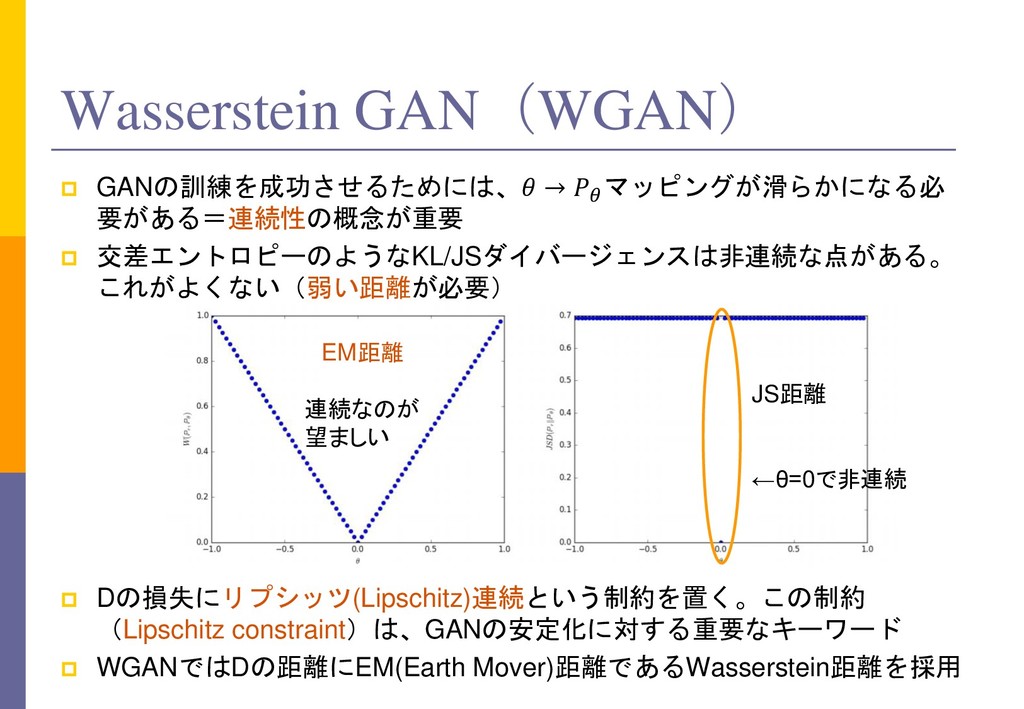
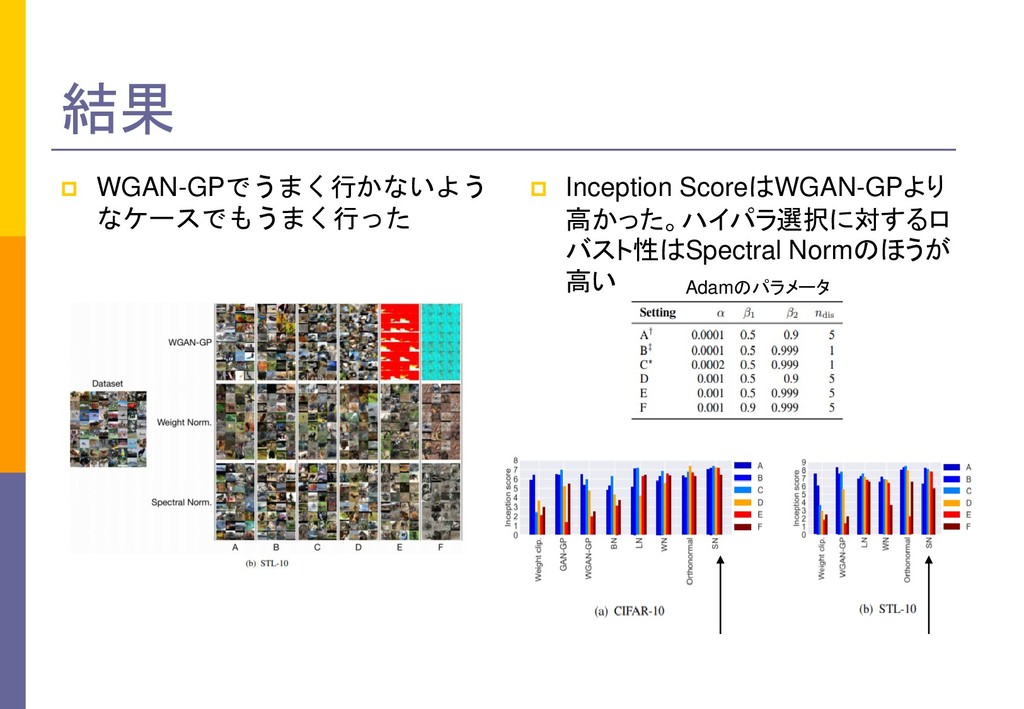
Wasserstein GAN. 2017 https://arxiv.org/abs/1701.07875 →非常に理論的な内容で難しい。この実装の改良がWGAN-GP。理論部分に 価値がある WGAN-GP(Gradient Penalty) I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, A. Courville. Improved Training of Wasserstein GANs. 2017 https://arxiv.org/abs/1704.00028 →WGANの改良。WGANよりは実践的な内容で読みやすい。WGANの実験部 分を補完する内容。 Spectral Normalization T. Miyato, T. Kataoka, M. Koyama, Y. Yoshida. Spectral Normalization for Generative Adversarial Networks. 2018. https://arxiv.org/abs/1802.05957 →おすすめ。WGANの前提であるDの損失関数のリプシッツ連続性を Batch Normzalitionの置き換えで実践。著者は日本人(うち2人がPFN)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
に頭打ち 実はこれはよくない。著者もひどい(terrible)方法と言っている。他にも学 習率の非常に低いRMSPropを使っていたり学習方法が極端。収束も遅い ](https://files.speakerdeck.com/presentations/be217f0750b749c7b821863e8e34e118/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}