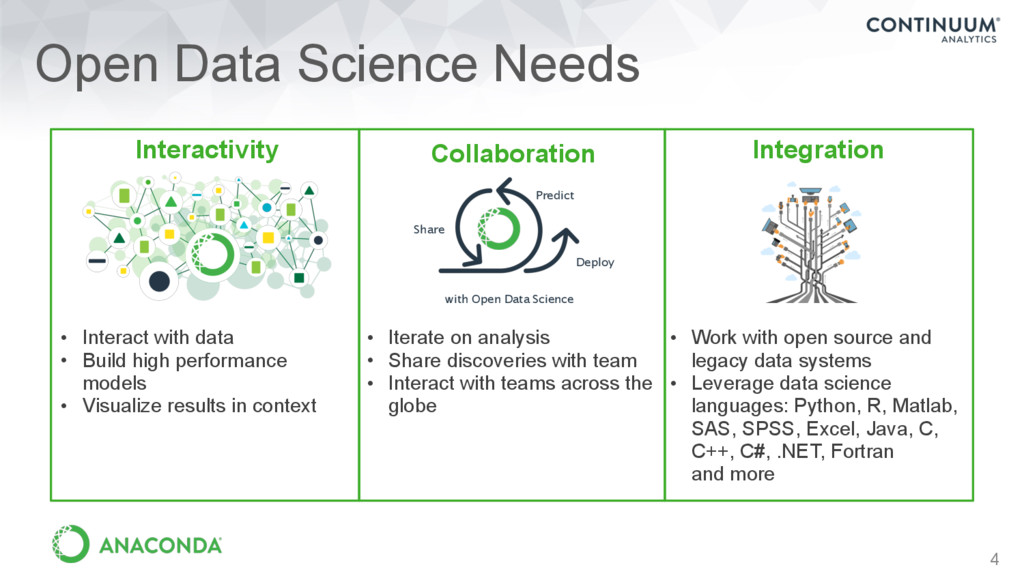
• Share discoveries with team • Interact with teams across the globe Interactivity • Interact with data • Build high performance models • Visualize results in context Integration • Work with open source and legacy data systems • Leverage data science languages: Python, R, Matlab, SAS, SPSS, Excel, Java, C, C++, C#, .NET, Fortran and more Predict Share Deploy with Open Data Science
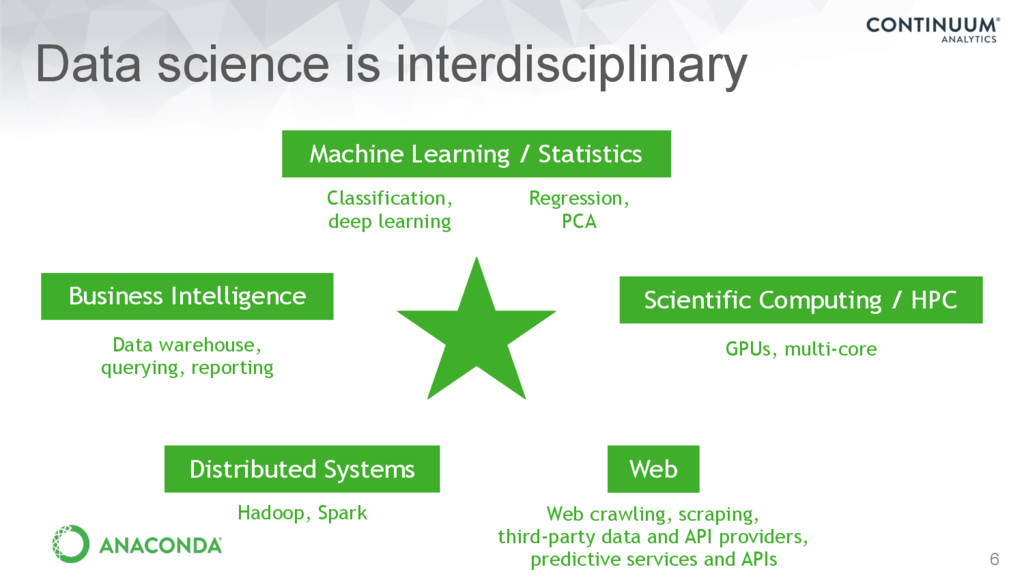
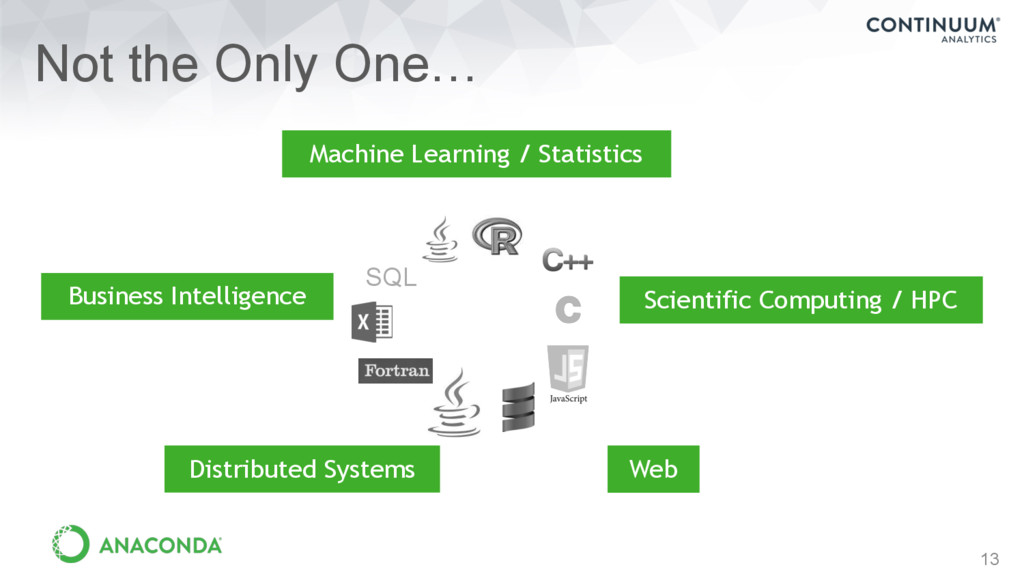
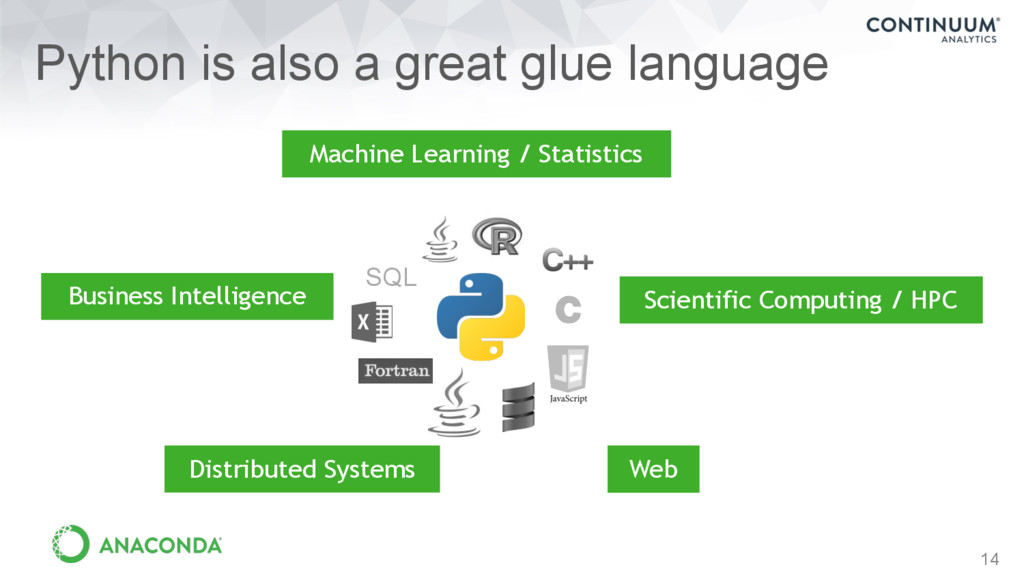
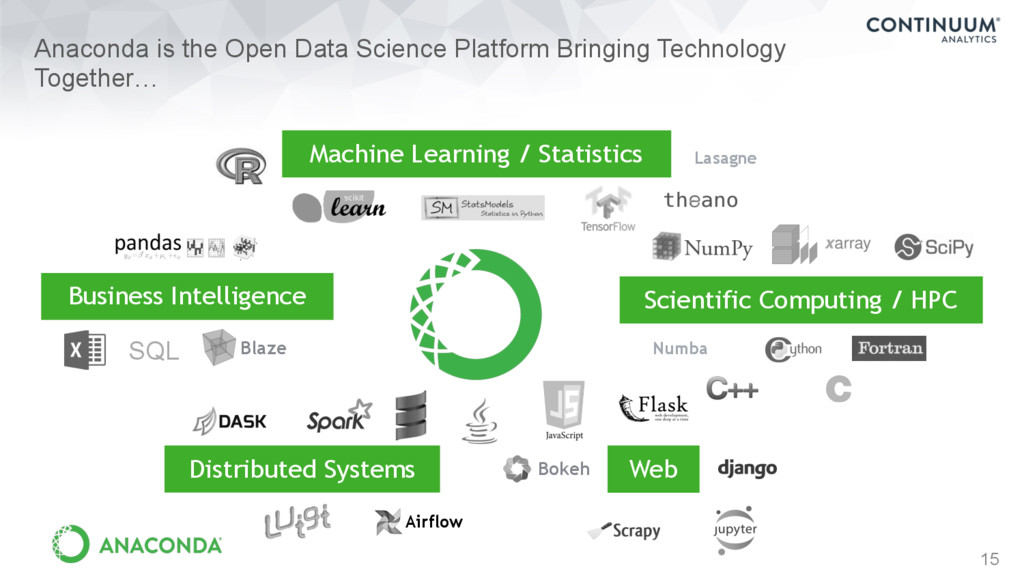
Computing / HPC GPUs, multi-core Machine Learning / Statistics Classification, deep learning Regression, PCA Web Web crawling, scraping, third-party data and API providers, predictive services and APIs Business Intelligence Data warehouse, querying, reporting
Spark • Programming Languages • Analytic Libraries • IDE • Notebooks • Visualization Biz Analyst • Spreadsheets • Visualization • Notebooks • Analytic Development Environment Data Engineer • Database / Data Warehouse • ETL Developer • Programming Languages • Analytic Libraries • IDE • Notebooks • Visualization DevOps • Database / Data Warehouse • Middleware • Programming Languages Right technology and tools for the problem
multiple versions of software packages and their dependencies • Easily create multiple environments and switch between them • Powered by Python, but can package anything! • http://conda.pydata.org Conda 18 Windows Mac Linux Python R Java Scala
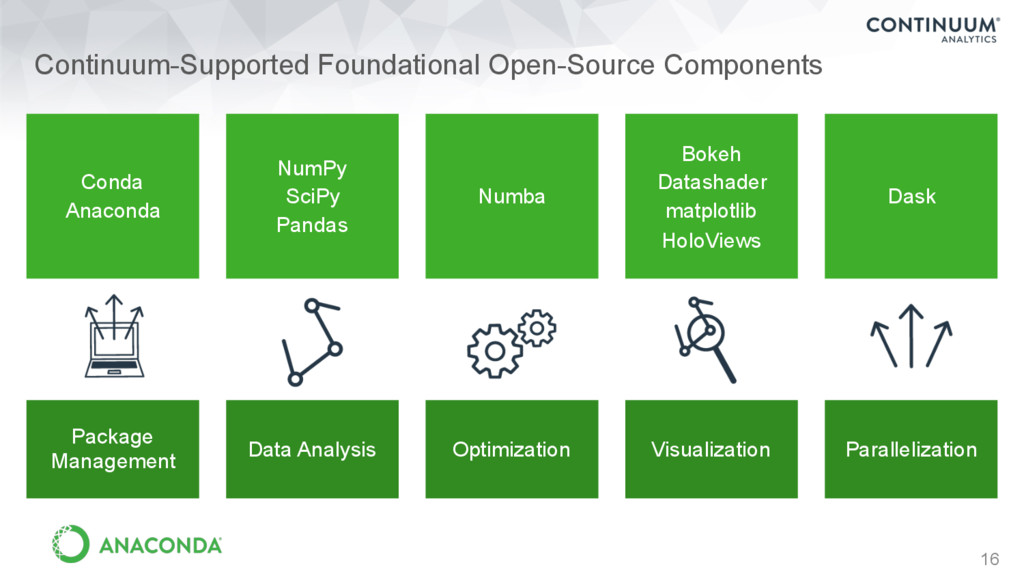
for Everyone • Flexible conda package manager • Sandboxed packages and libraries • Cross-platform - Windows, Linux, Mac • Not just Python - over 230 R packages Anaconda 19 Leading Open Data Science platform powered by Python
on: • Windows (AppVeyor) • Mac (Travis CI) • Linux (CircleCI) • https://conda-forge.github.io conda config --add-channels conda-forge conda install <package-name>
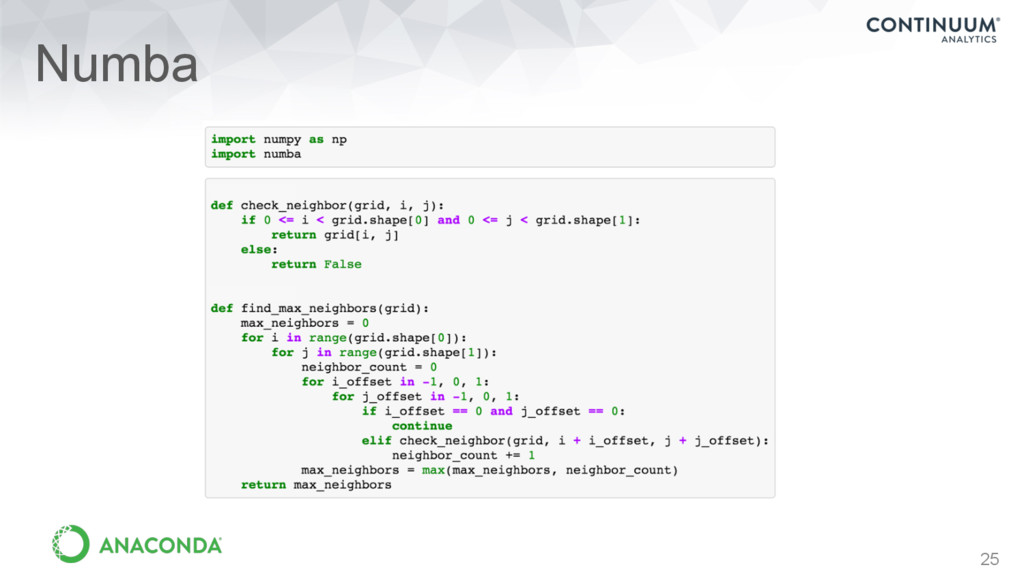
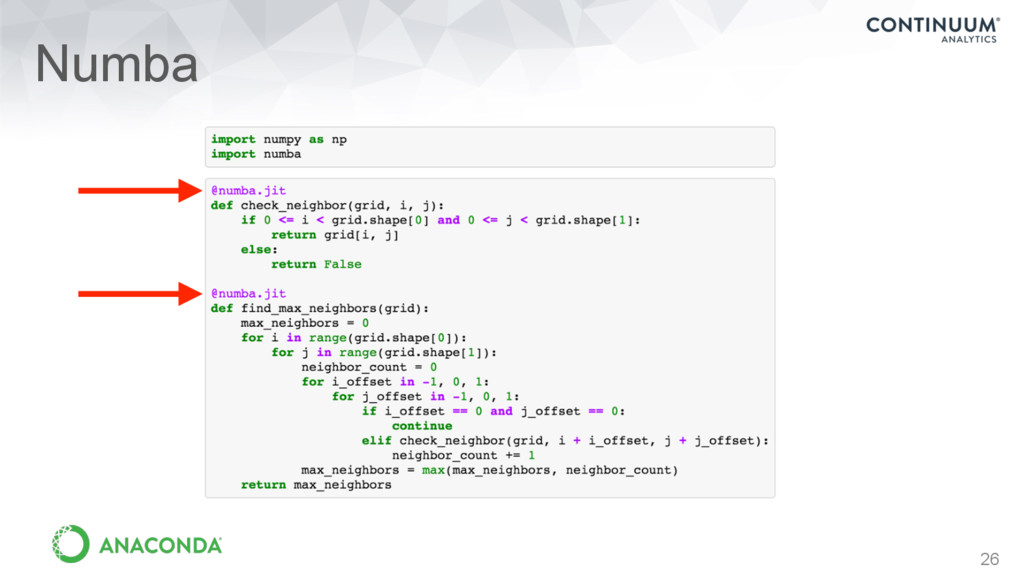
Simple, easy to read/write syntax • Batteries included • Ships with lots of basic functions • Innovations from open source • Open access to a huge variety of existing libraries and algorithms • Very easy to get high performance when you need it…
No need to write JavaScript • Python, R, Scala, and Lua bindings • Easy to embed in web applications • Easy to develop interactive applications and dashboards • bokeh.pydata.org
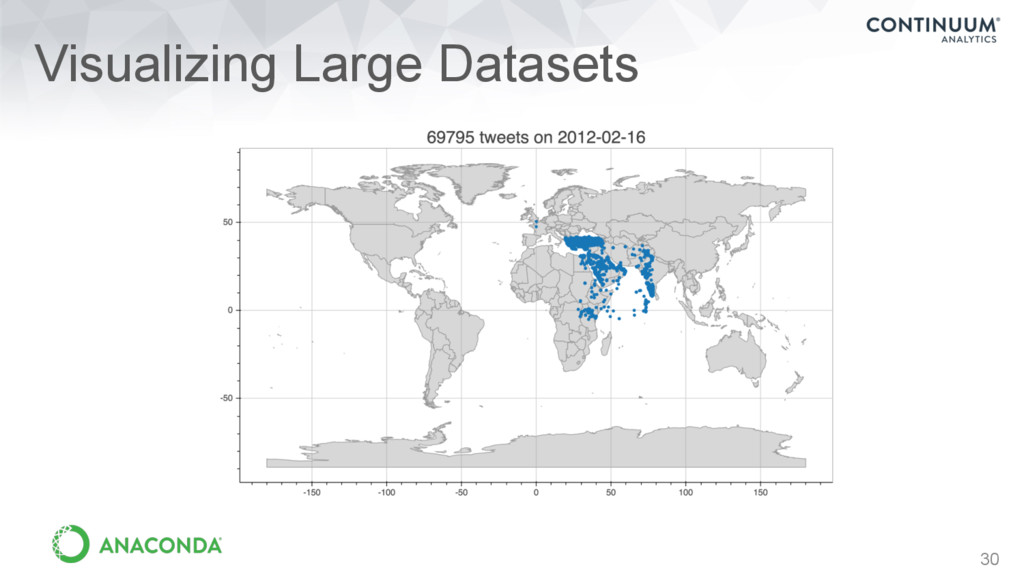
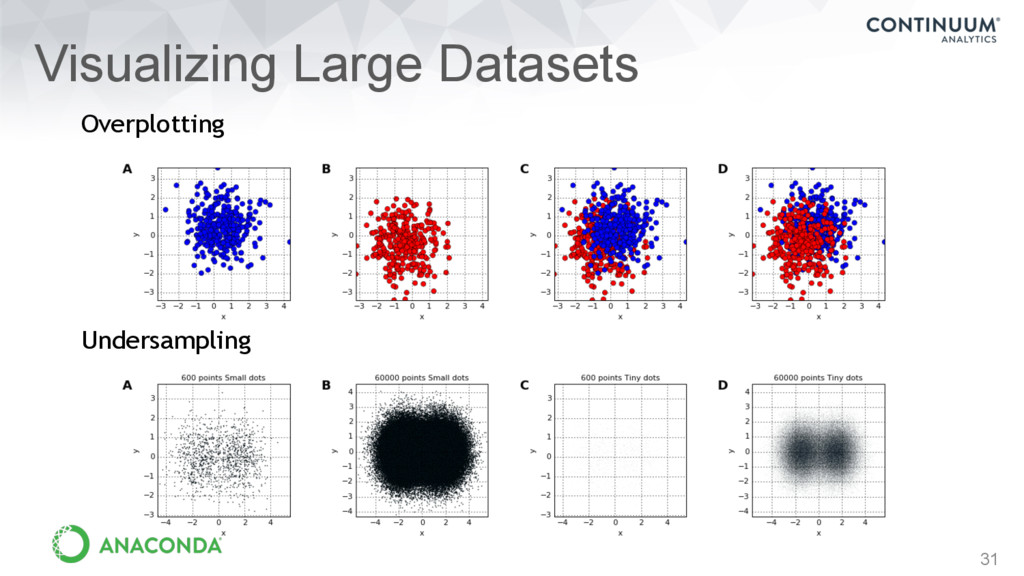
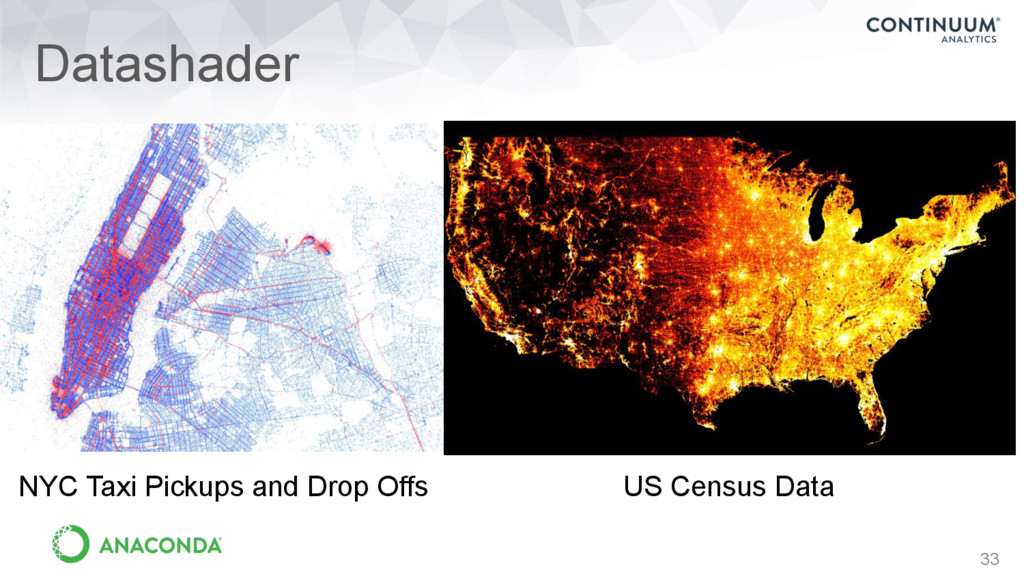
of large amounts of data • Handles very large datasets in and out of core (e.g., billions of data points) • datashader.readthedocs.io NYC Census data by race
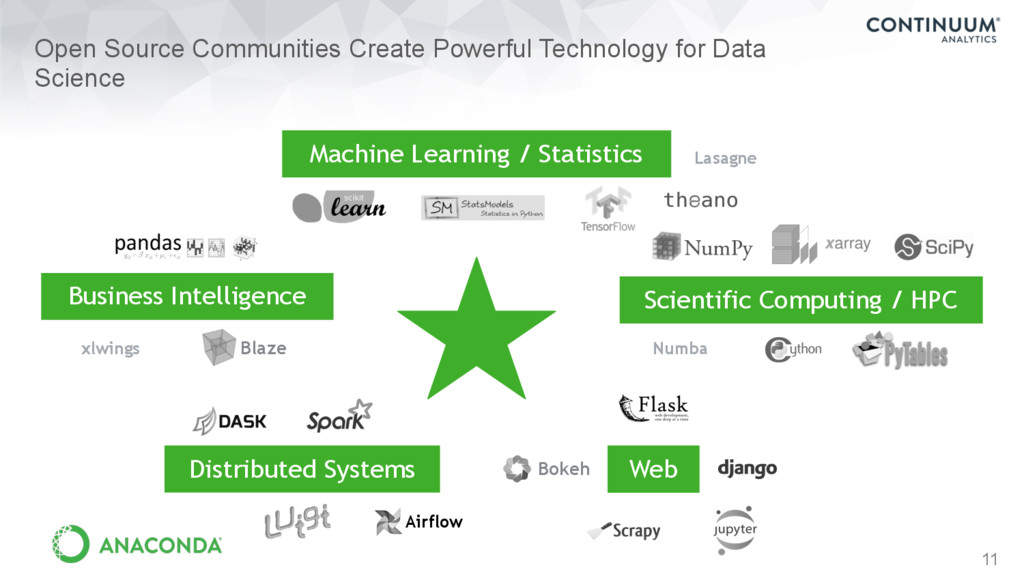
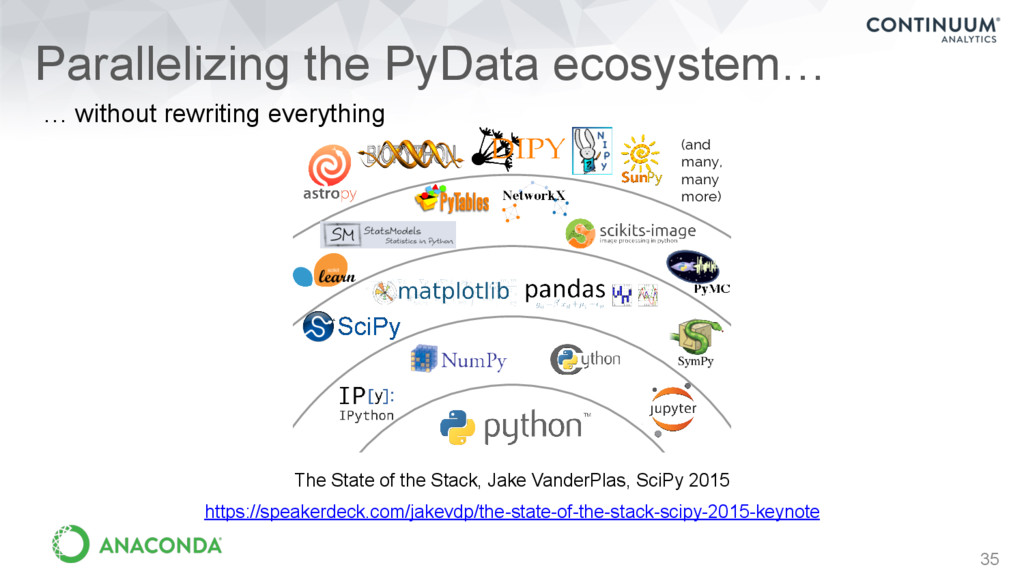
Ecosystem (and many, many more) The State of the Stack, Jake VanderPlas, SciPy 2015 https://speakerdeck.com/jakevdp/the-state-of-the-stack-scipy-2015-keynote … without rewriting everything
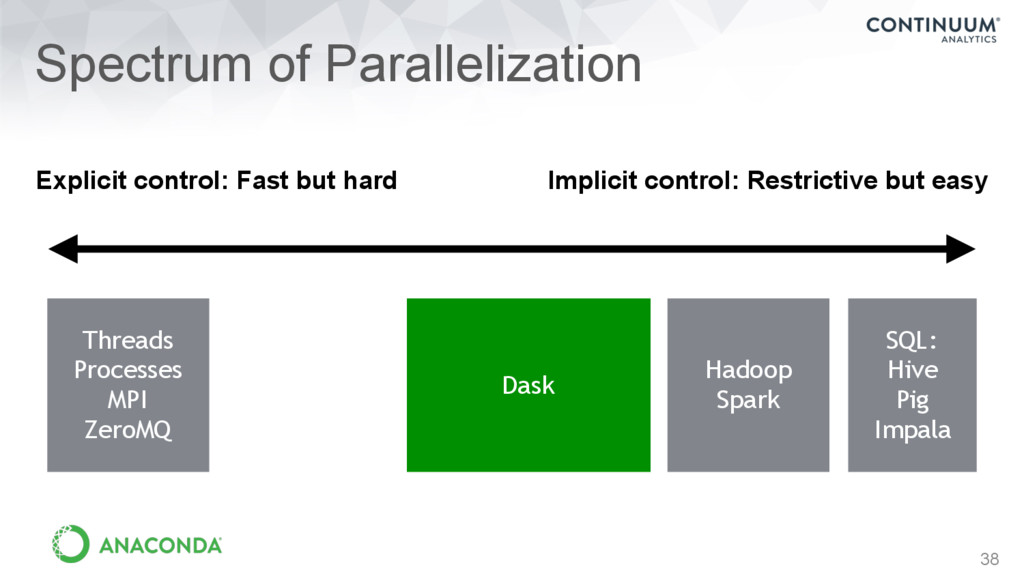
library that is: • Familiar: Implements parallel NumPy and Pandas objects • Fast: Optimized for demanding for numerical applications • Flexible: for sophisticated and messy algorithms • Scales up: Runs resiliently on clusters of 100s of machines • Scales down: Pragmatic in a single process on a laptop • Interactive: Responsive and fast for interactive data science
computing across over 40 programming languages. • Allows you to create and share documents that contain live code, equations, visualizations and explanatory text. The Jupyter Notebook is a web application that allows you and share documents that contain live code, equatio visualizations and explanatory text. Open source, interactive data science and scientific computing across over 40 programming languages. Jupyter The Jupyter Notebook is a web application that allows you and share documents that contain live code, equati visualizations and explanatory text. Open source, interactive data science and scientific computing across over 40 programming languages. Jupyter
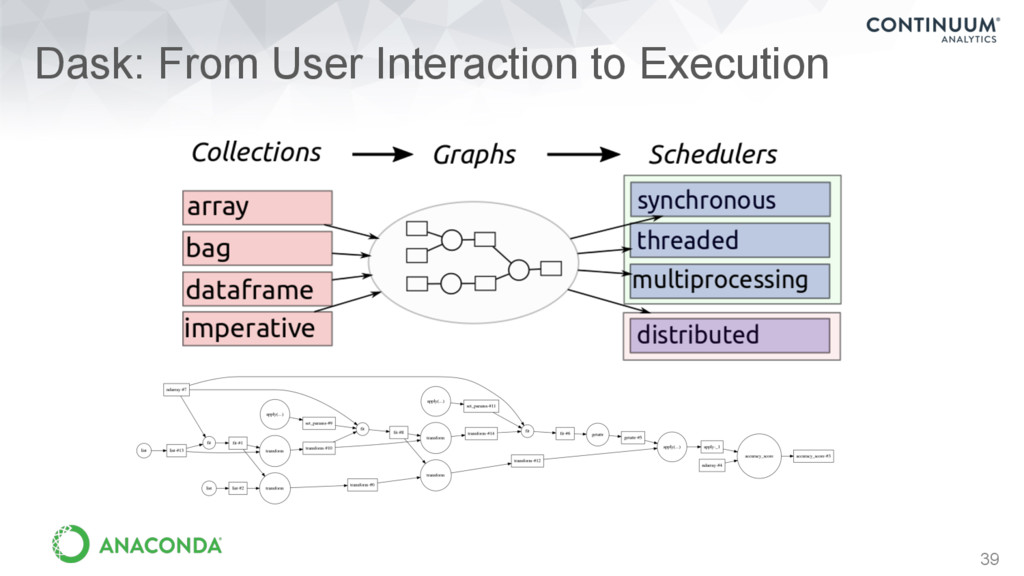
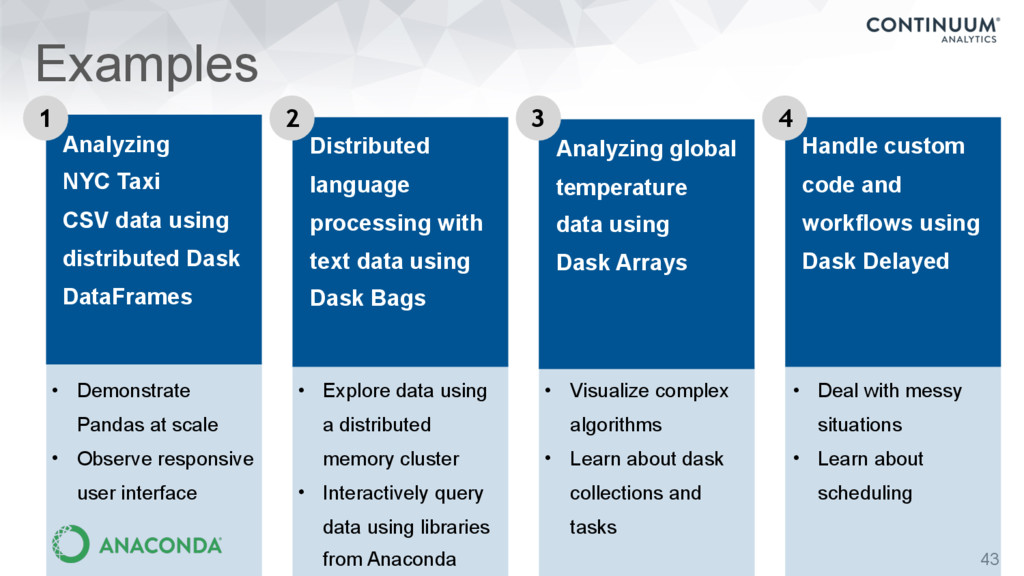
DataFrames • Demonstrate Pandas at scale • Observe responsive user interface Distributed language processing with text data using Dask Bags • Explore data using a distributed memory cluster • Interactively query data using libraries from Anaconda Analyzing global temperature data using Dask Arrays • Visualize complex algorithms • Learn about dask collections and tasks Handle custom code and workflows using Dask Delayed • Deal with messy situations • Learn about scheduling 1 2 3 4
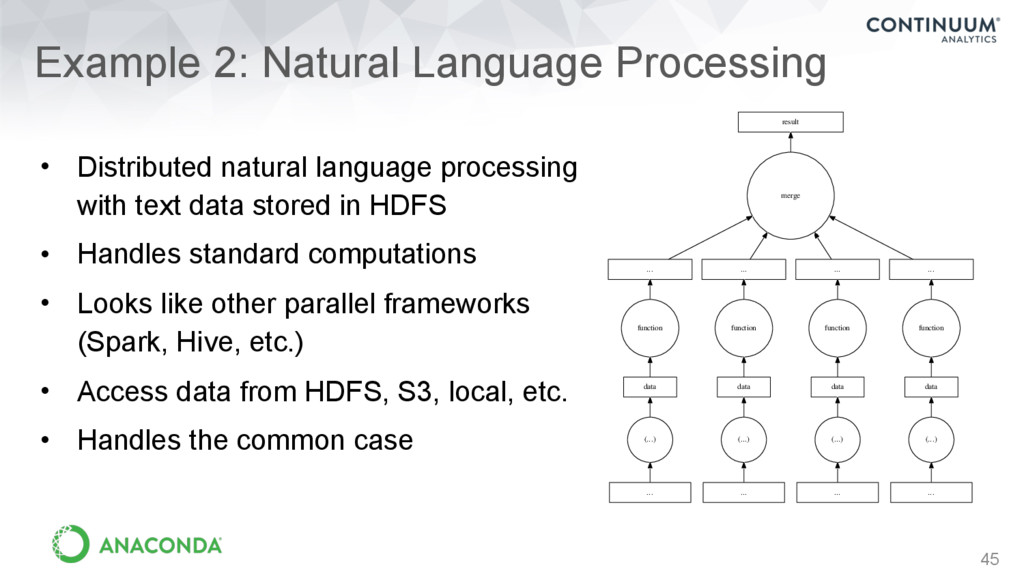
processing with text data stored in HDFS • Handles standard computations • Looks like other parallel frameworks (Spark, Hive, etc.) • Access data from HDFS, S3, local, etc. • Handles the common case ... (...) data ... (...) data function ... ... (...) data function ... result merge ... ... data function (...) ... function
support messy situations • Life saver when collections aren't flexible enough • Combine futures with collections for best of both worlds • Scheduler provides resilient and elastic execution
Management Server Jupyter/IPython Notebook pandas, NumPy, SciPy, Numba, NLTK, scikit-learn, scikit-image, and more from Anaconda … HDFS, YARN, SGE, Slurm or other distributed systems Bare-metal or Cloud-based Cluster Anaconda Parallel Computation Dask Spark Hive, Impala Cluster
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}