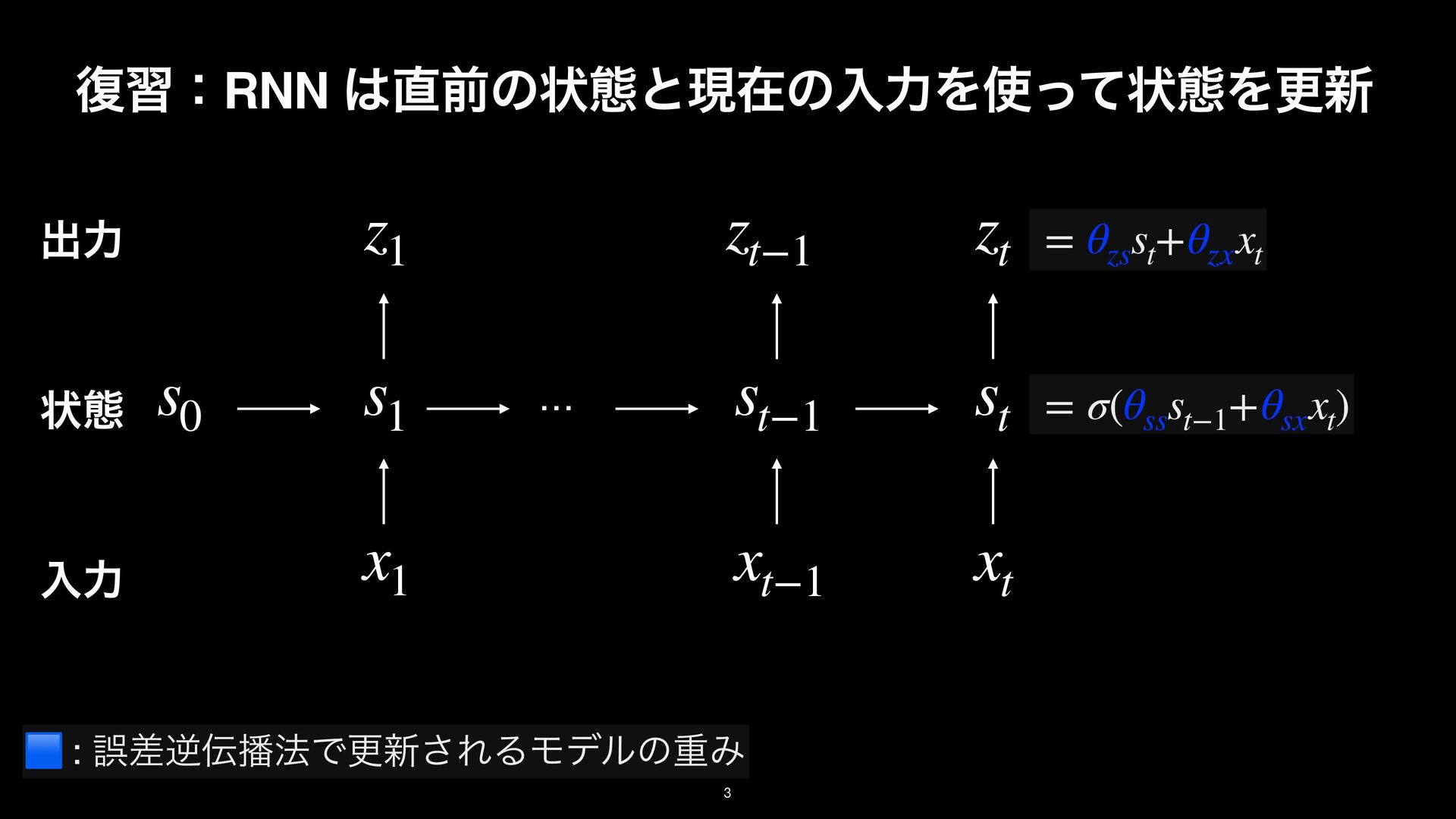
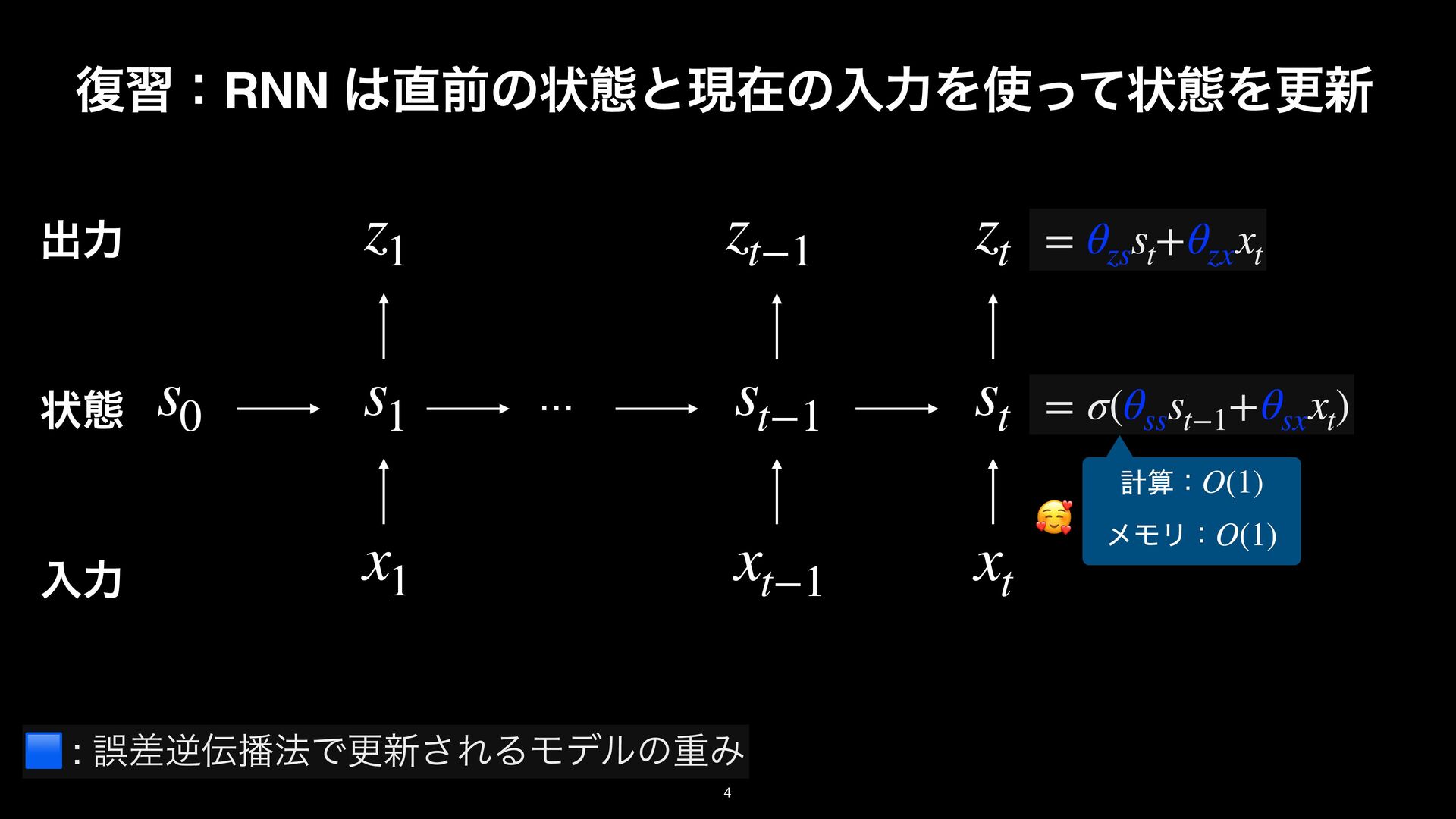
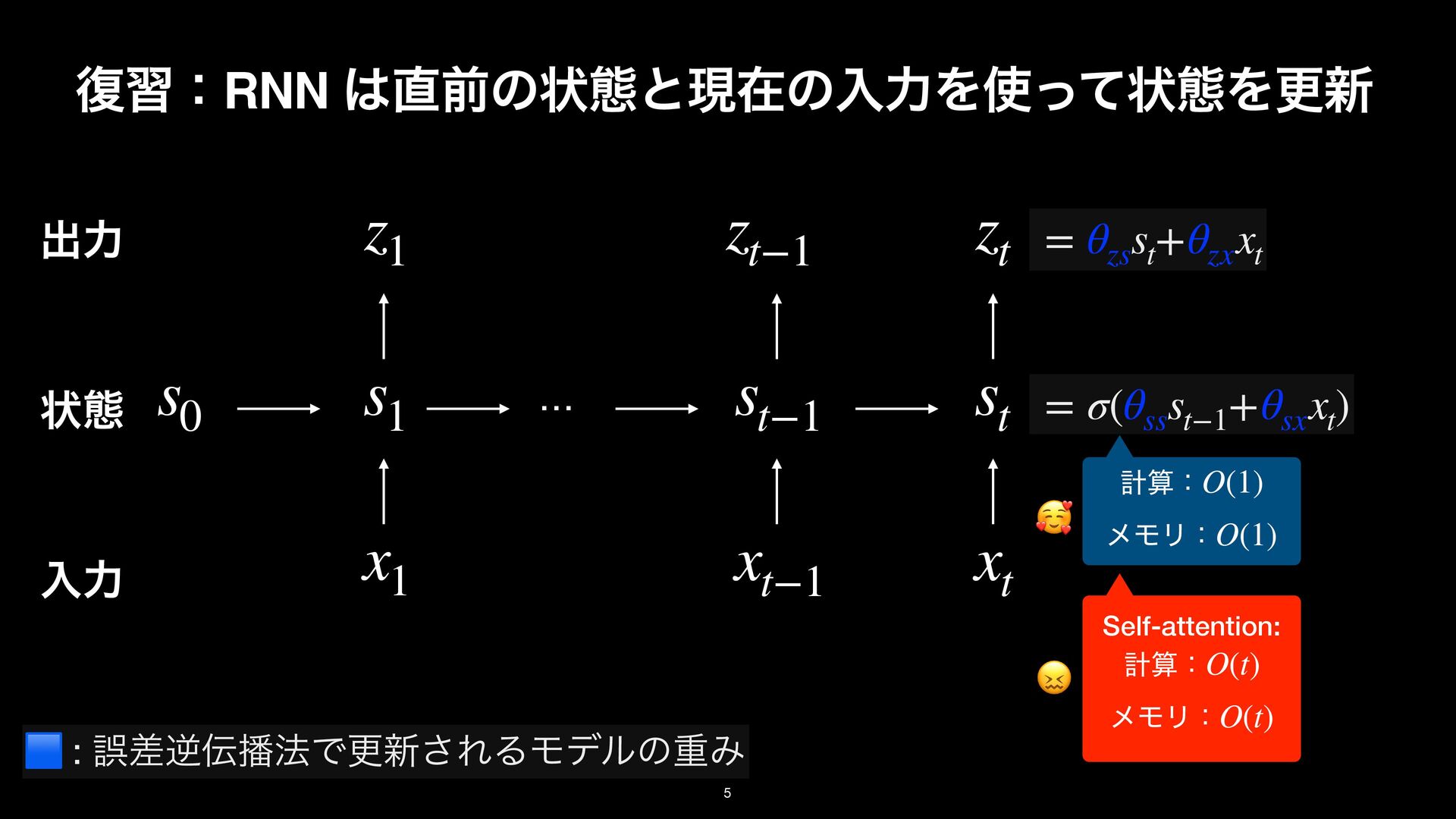
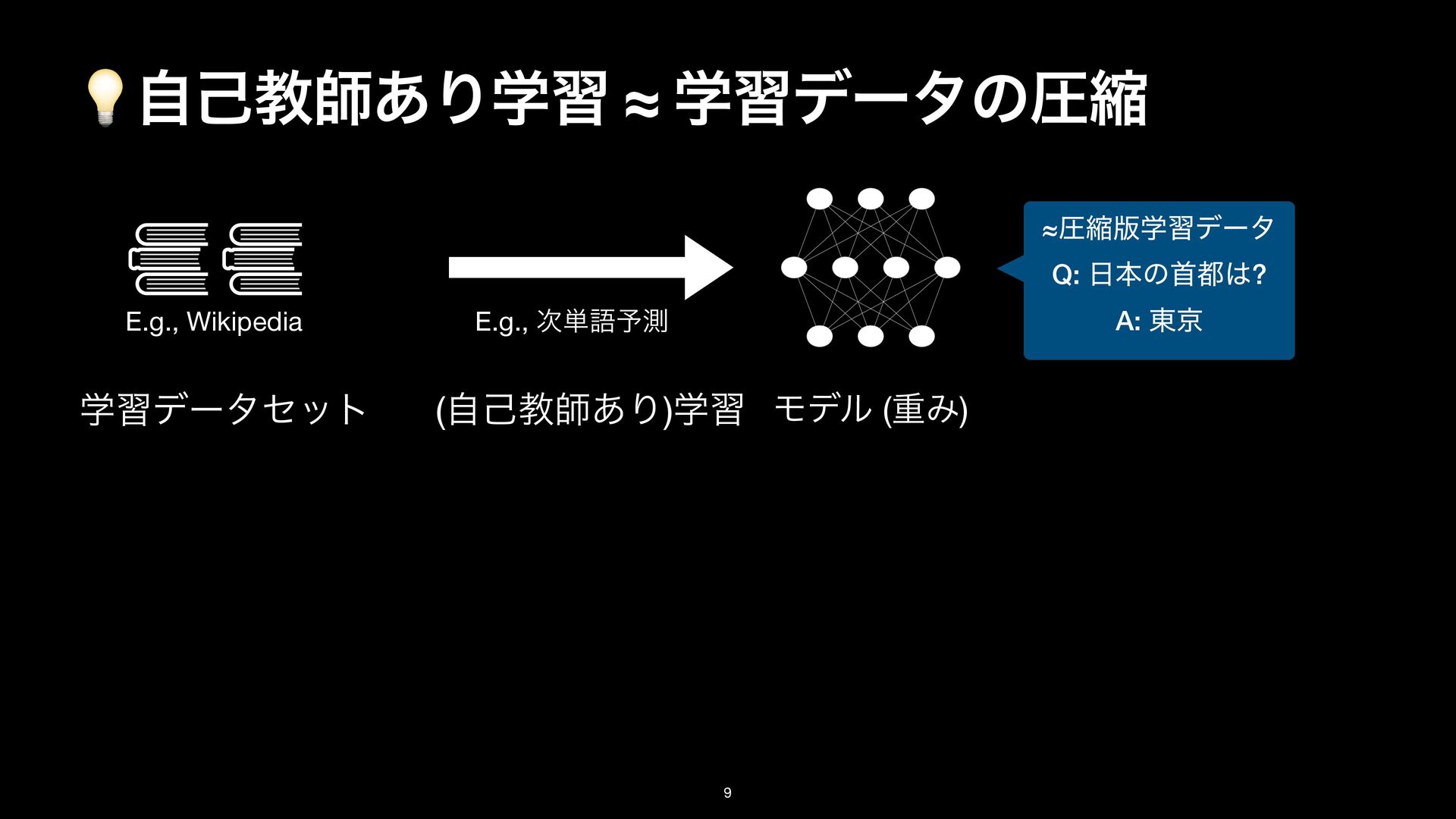
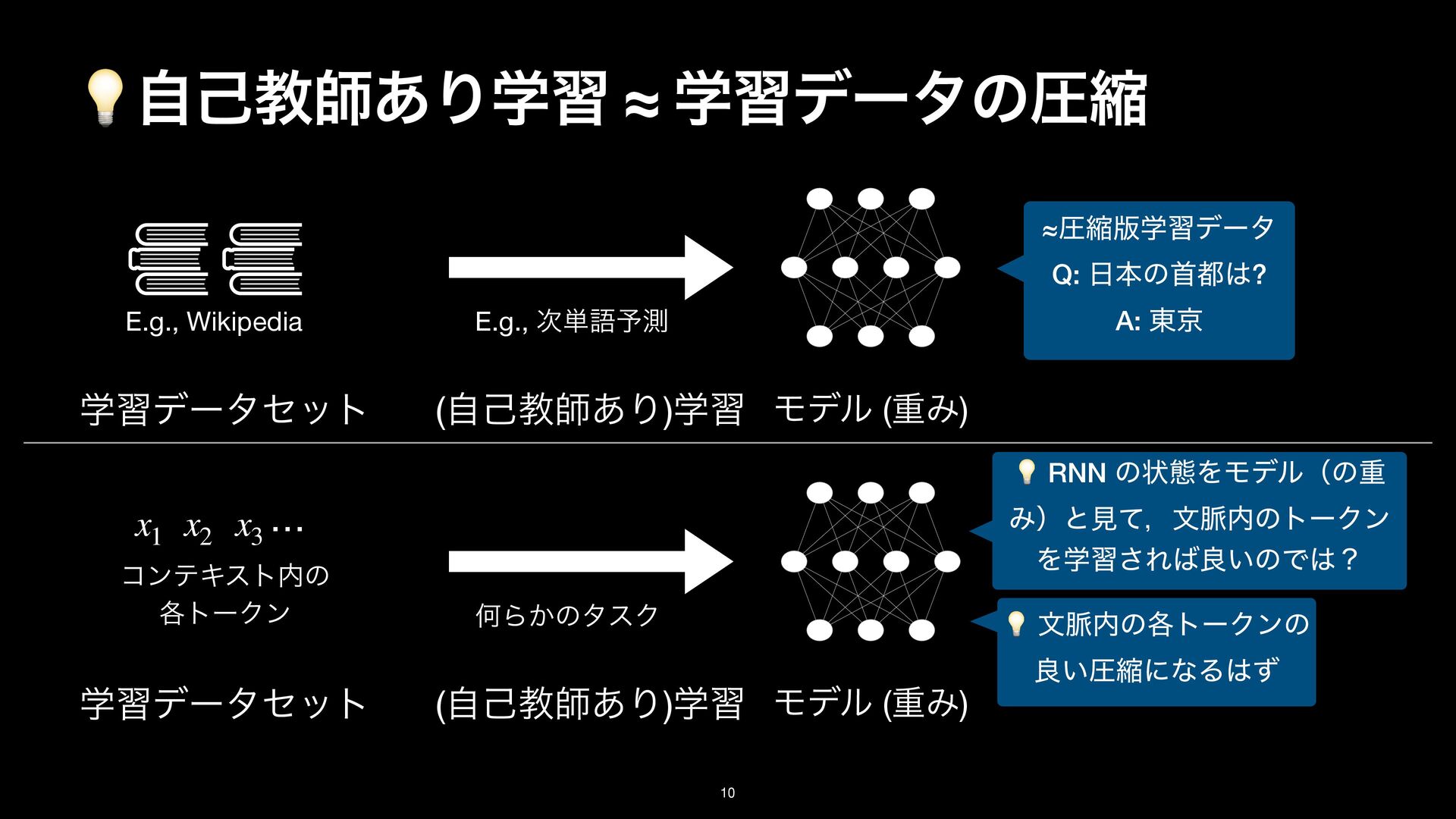
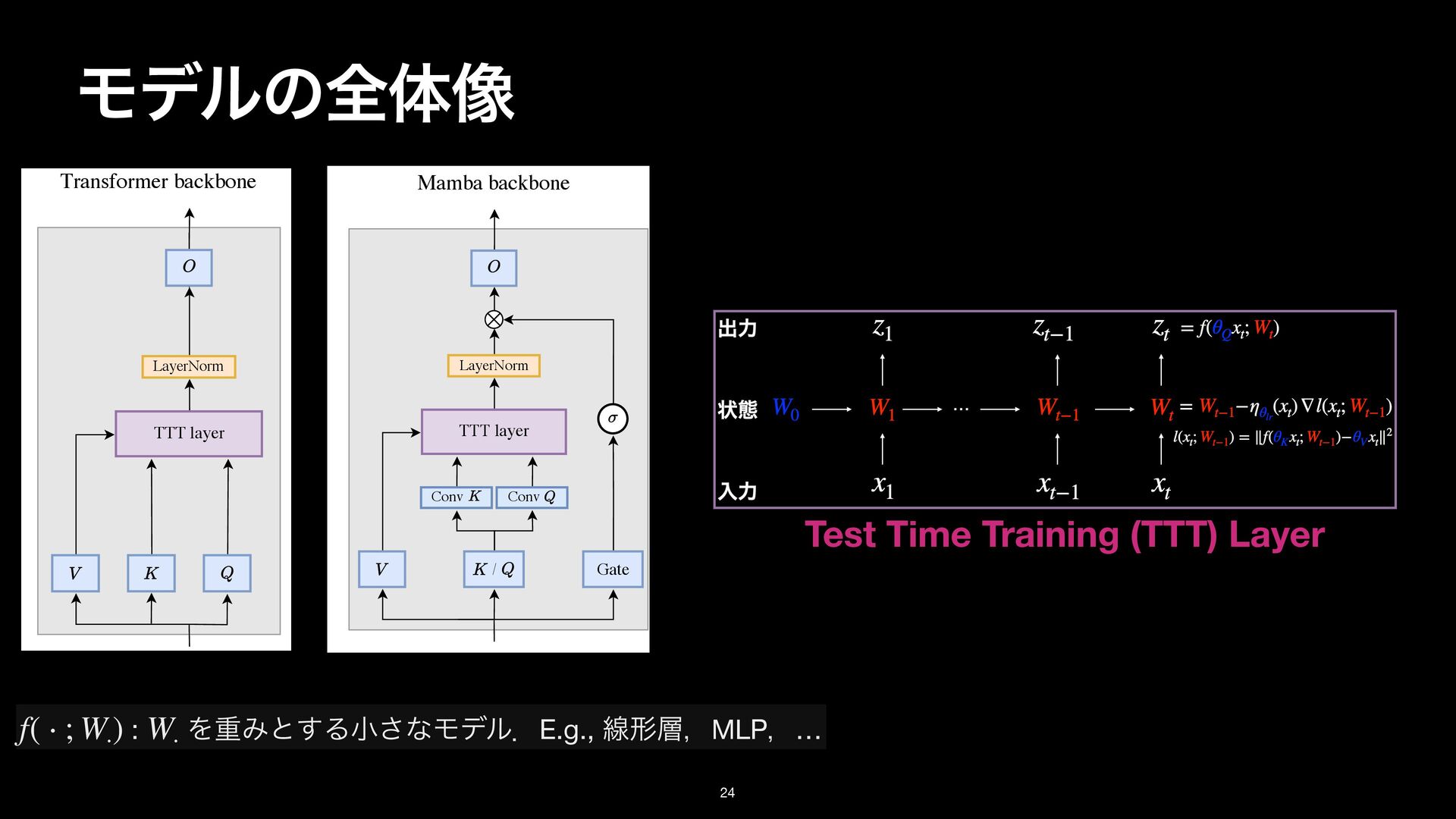
LayerNorm Gate Transformer backbone Mamba backbone ock, the basic building block for Transformers. The sequence modeling block nts: the Transformer backbone and Mamba backbone. Middle: TTT layer The LN before O comes from NormFormer [60]. Right: TTT layer in the [25] and Griffin [18]. Following these two architectures, ω here is GELU [29]. rameters of the gate without changing the embedding dimension, we simply TTT layer LayerNorm / Conv TTT layer Conv LayerNorm Gate Transformer backbone Mamba backbone the basic building block for Transformers. The sequence modeling block the Transformer backbone and Mamba backbone. Middle: TTT layer he LN before O comes from NormFormer [60]. Right: TTT layer in the ] and Griffin [18]. Following these two architectures, ω here is GELU [29]. eters of the gate without changing the embedding dimension, we simply projection. : ΛॏΈͱ͢Δখ͞ͳϞσϧɽE.g., ઢܗɼMLPɼ… f( ⋅ ; W⋅ ) W⋅ Test Time Training (TTT) Layer
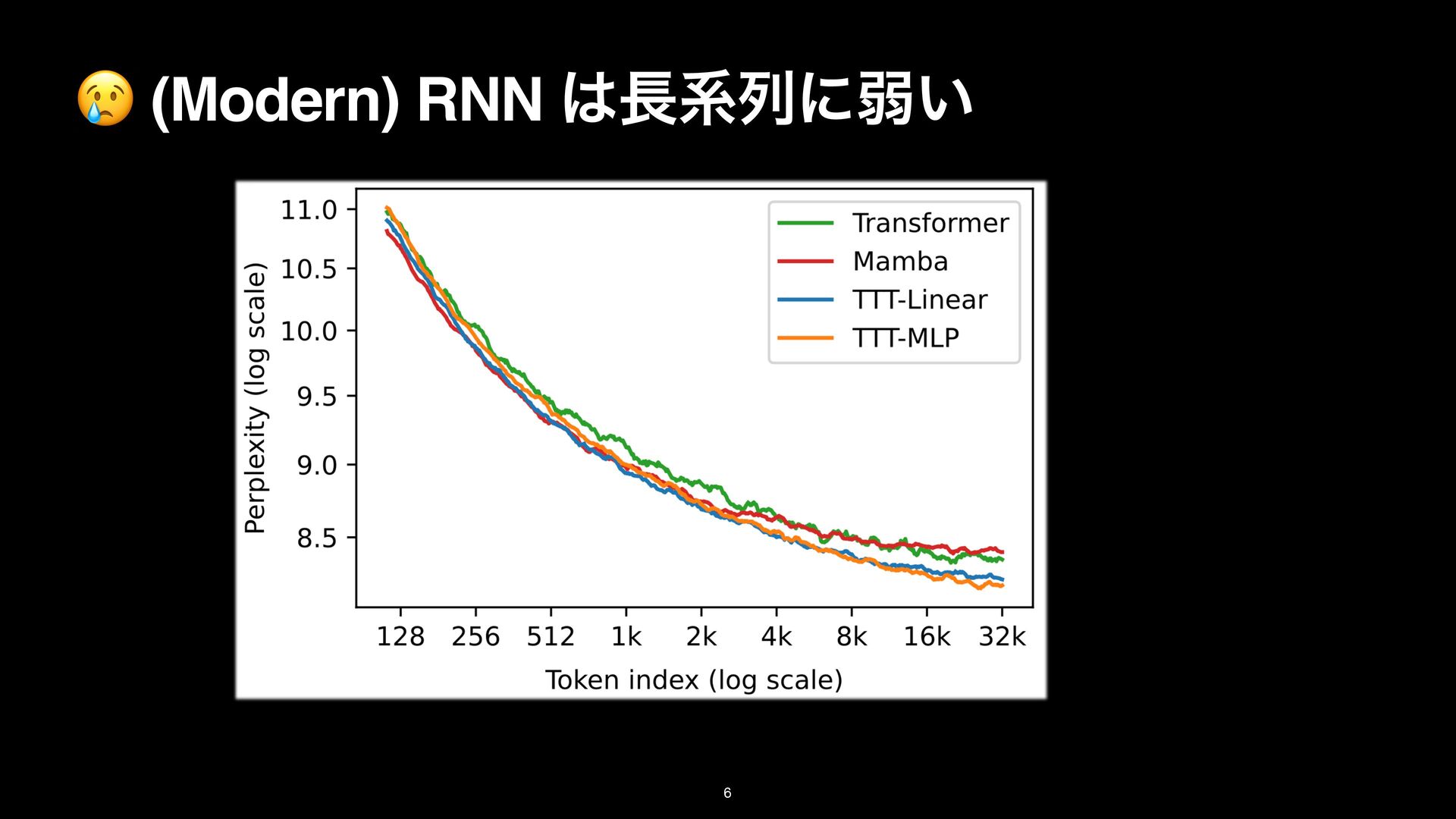
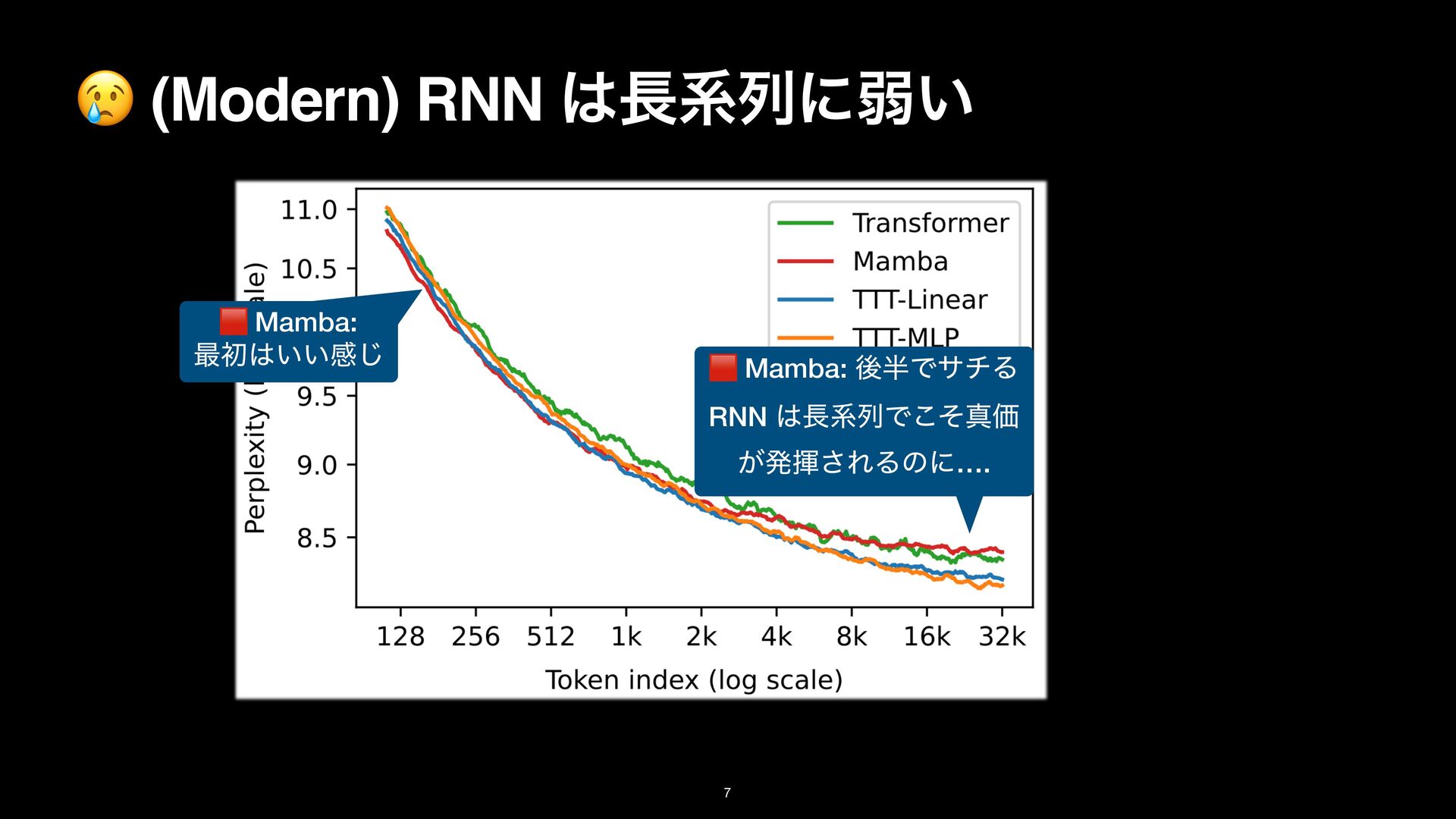
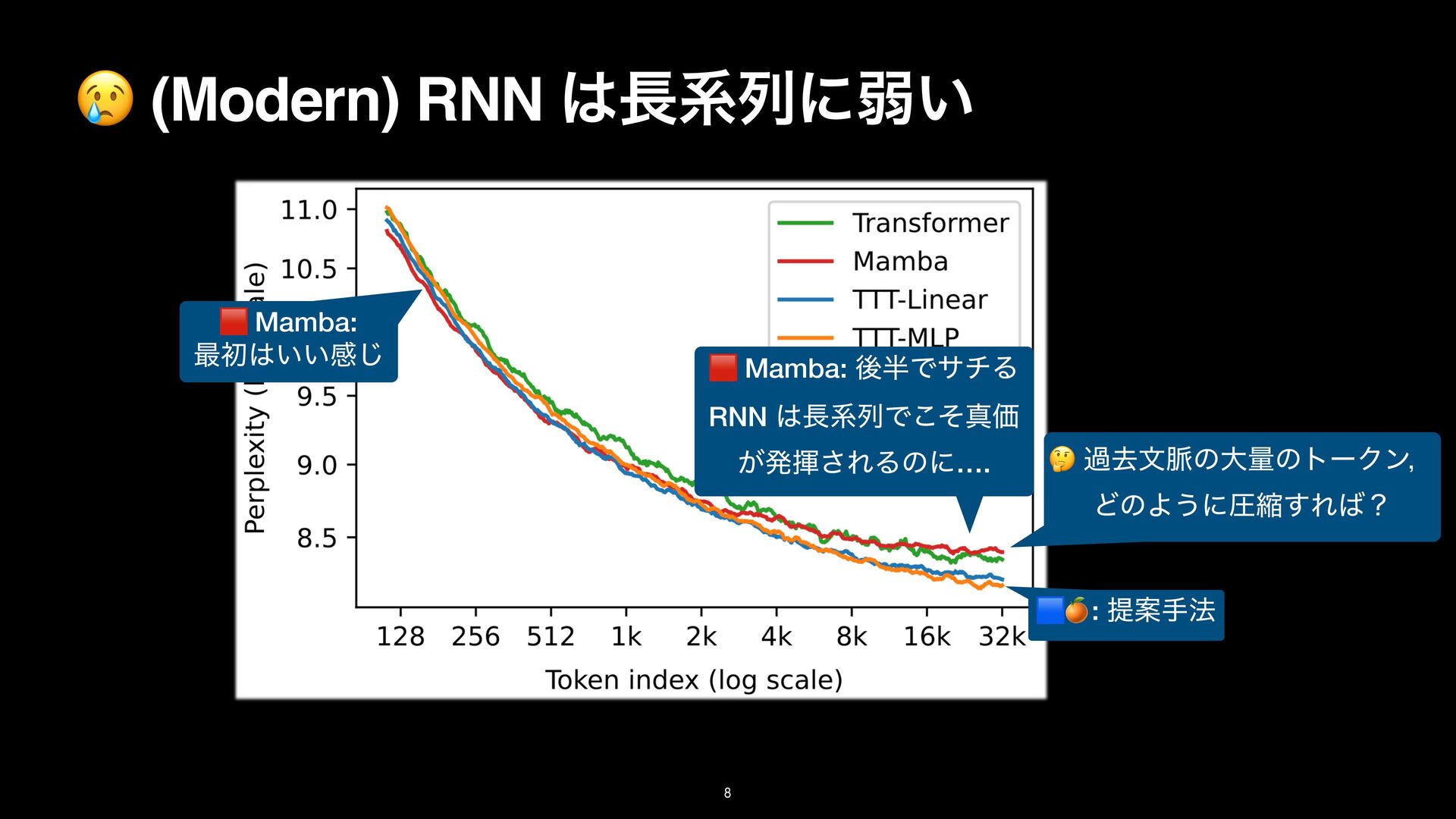
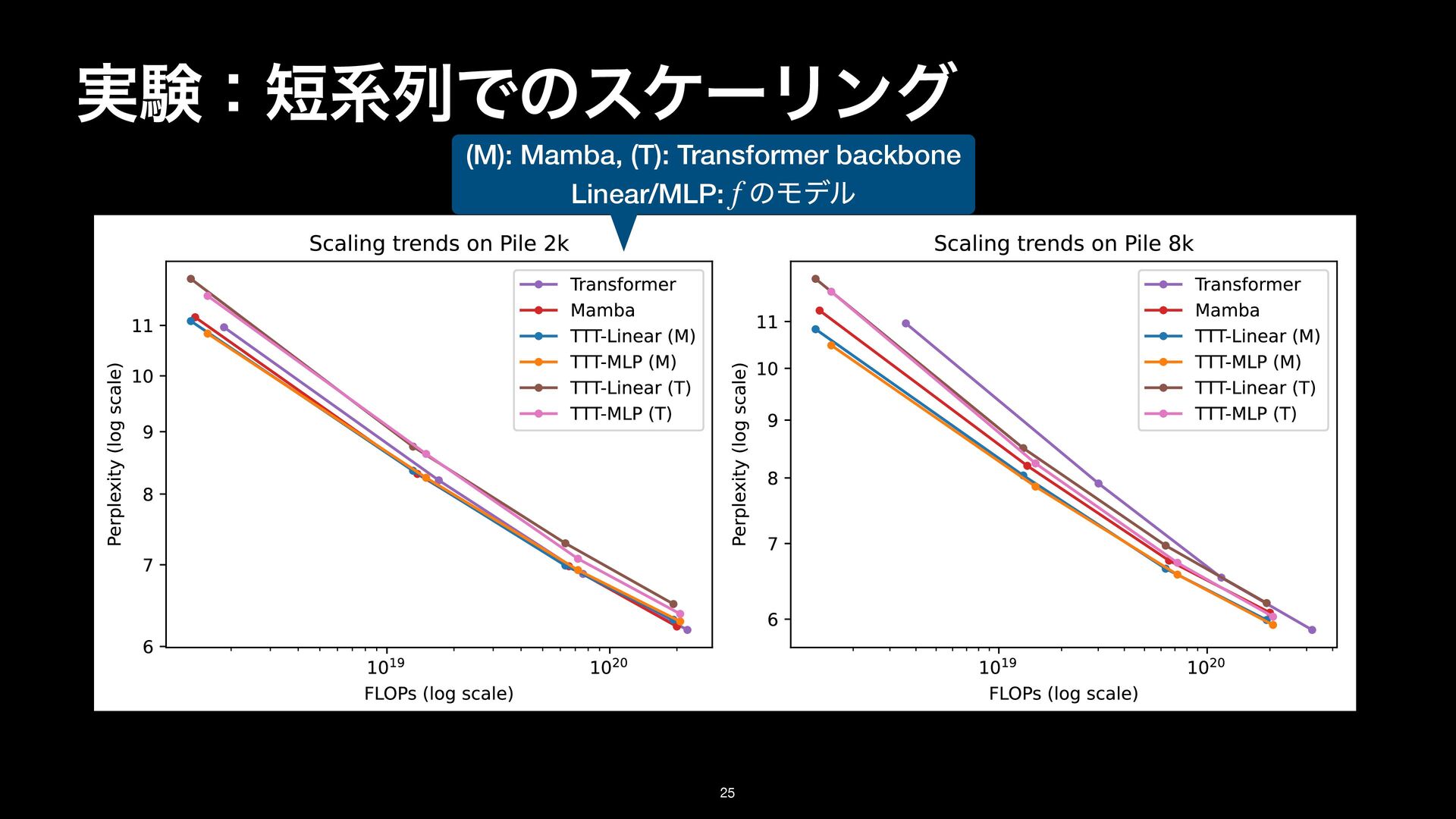
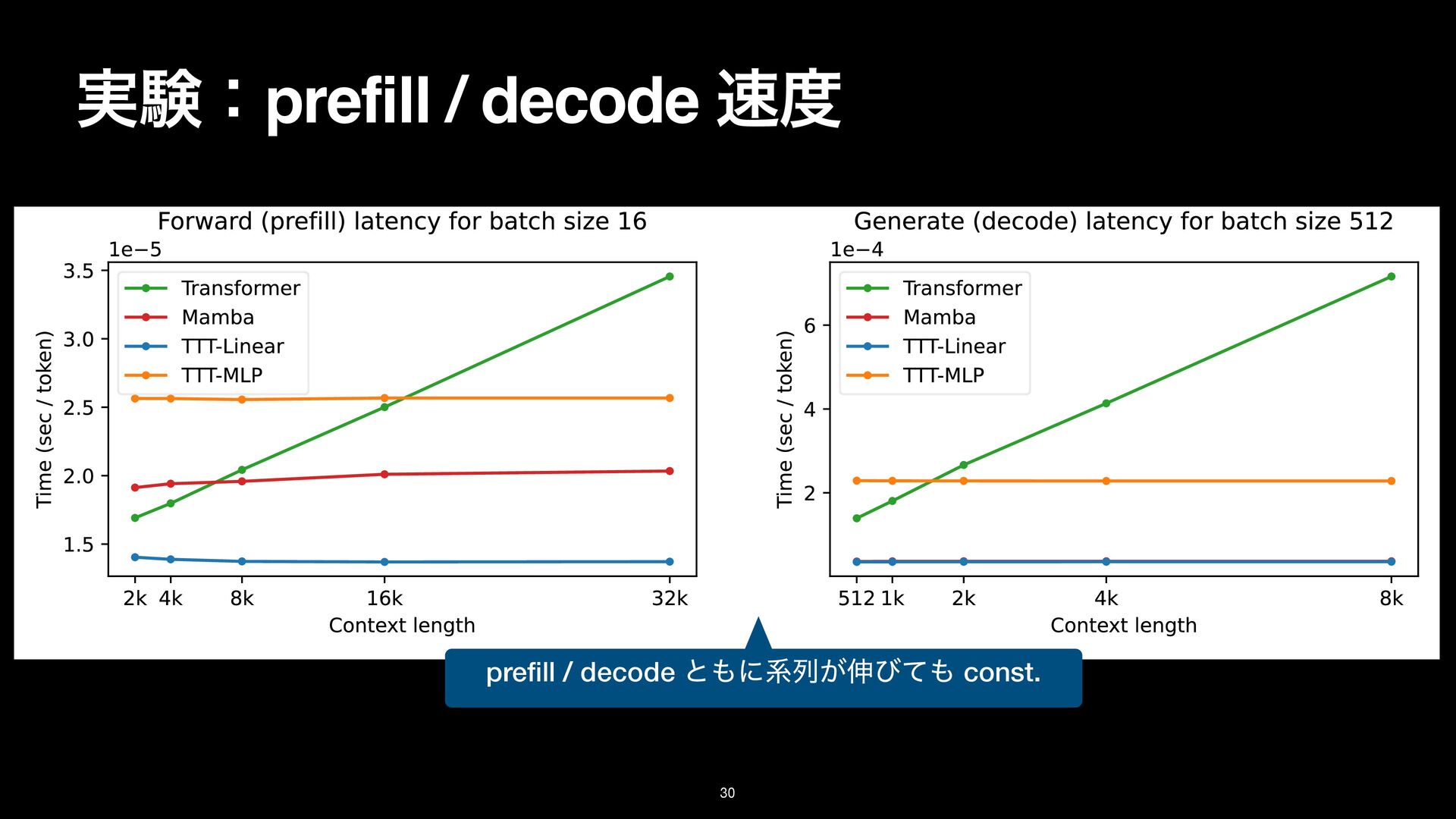
8k on the Pile. Details in Subsection 3.1. TTT-Linear has comparable performance as Mamba at 2k context, and better performance at 8k. (M): Mamba, (T): Transformer backbone Linear/MLP: ͷϞσϧ f
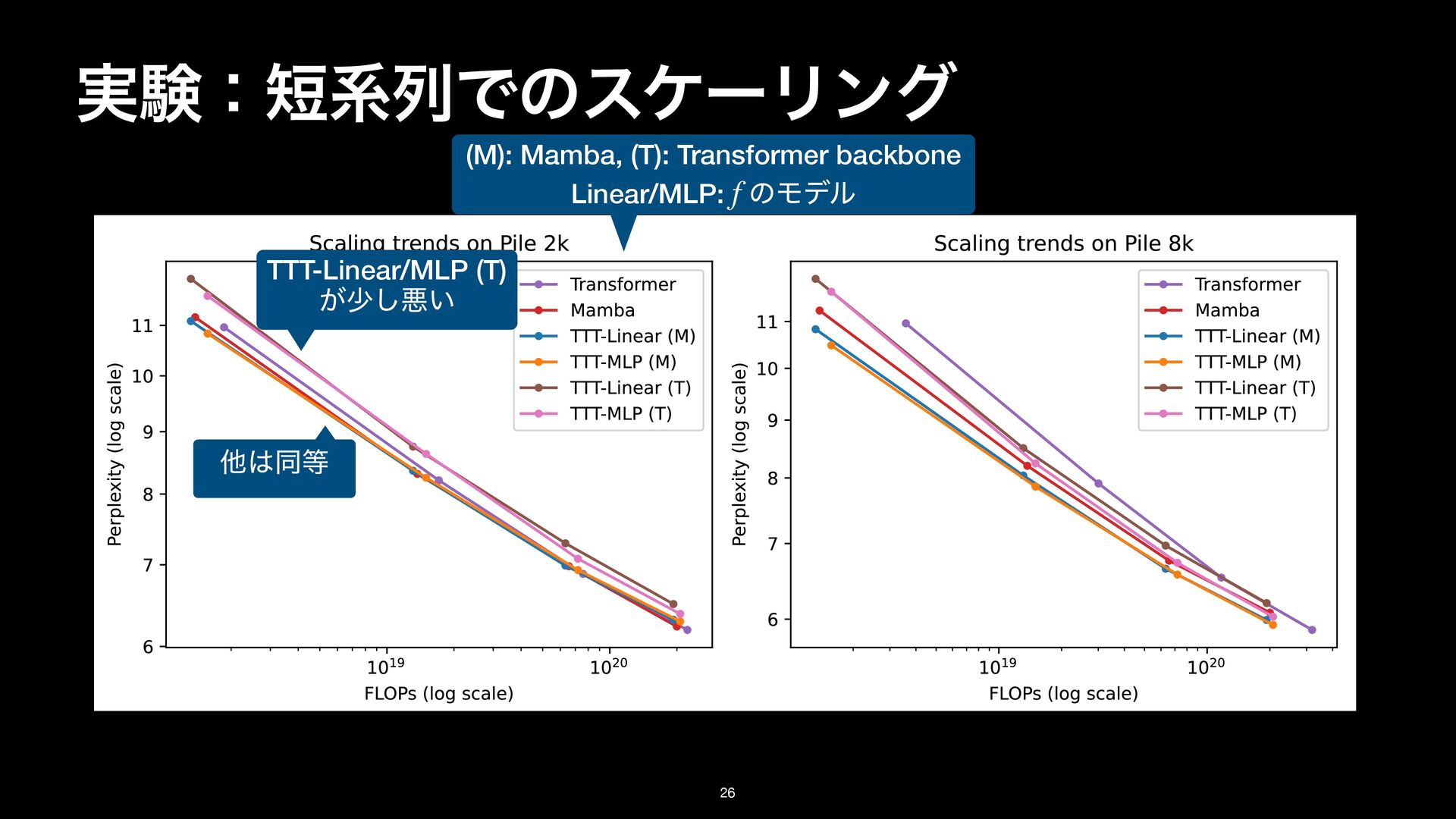
8k on the Pile. Details in Subsection 3.1. TTT-Linear has comparable performance as Mamba at 2k context, and better performance at 8k. (M): Mamba, (T): Transformer backbone Linear/MLP: ͷϞσϧ f TTT-Linear/MLP (T) ͕গ͠ѱ͍ ଞಉ
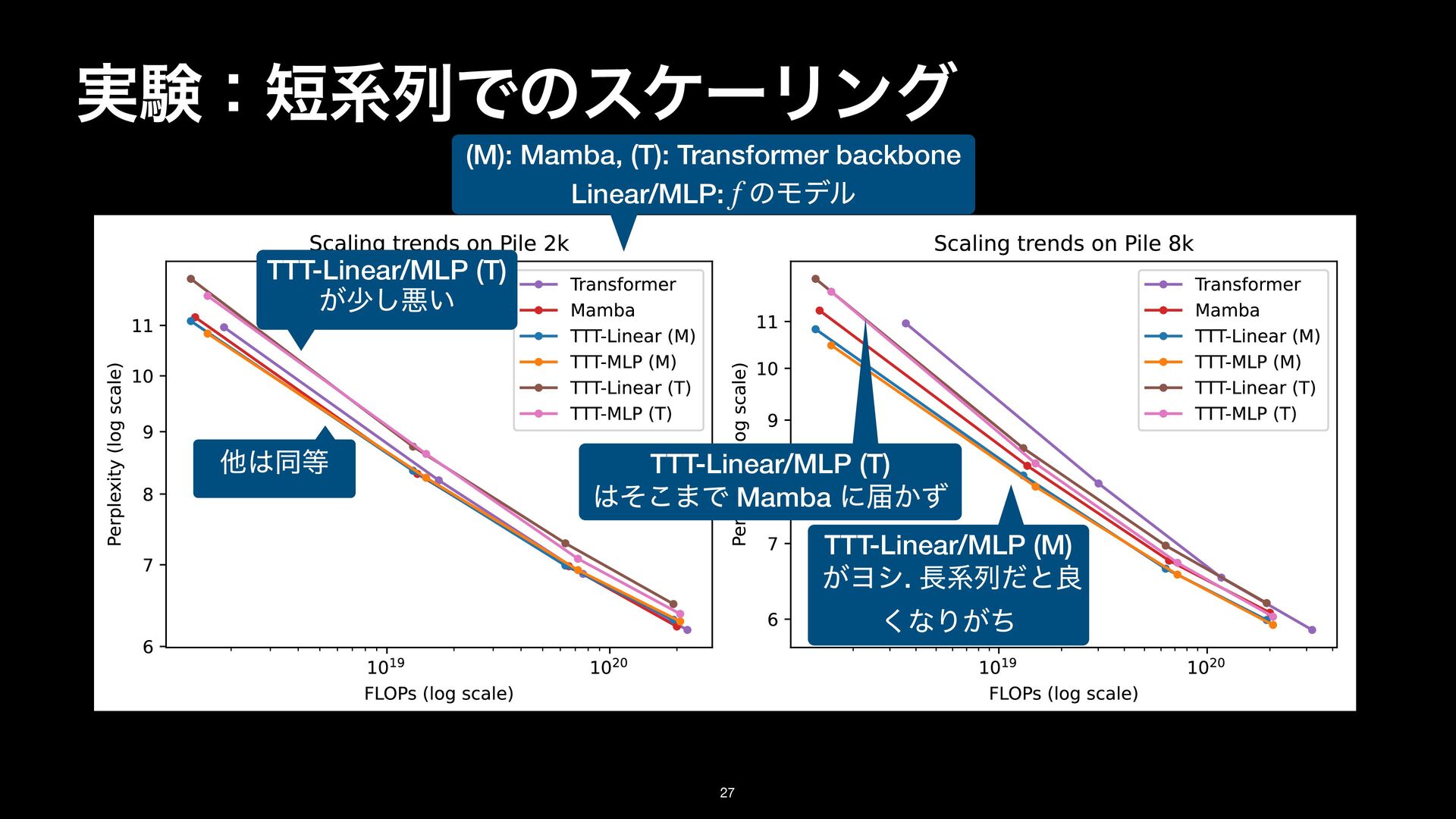
8k on the Pile. Details in Subsection 3.1. TTT-Linear has comparable performance as Mamba at 2k context, and better performance at 8k. (M): Mamba, (T): Transformer backbone Linear/MLP: ͷϞσϧ f TTT-Linear/MLP (T) ͕গ͠ѱ͍ ଞಉ TTT-Linear/MLP (M) ͕Ϥγ. ܥྻͩͱྑ ͘ͳΓ͕ͪ TTT-Linear/MLP (T) ͦ͜·Ͱ Mamba ʹಧ͔ͣ
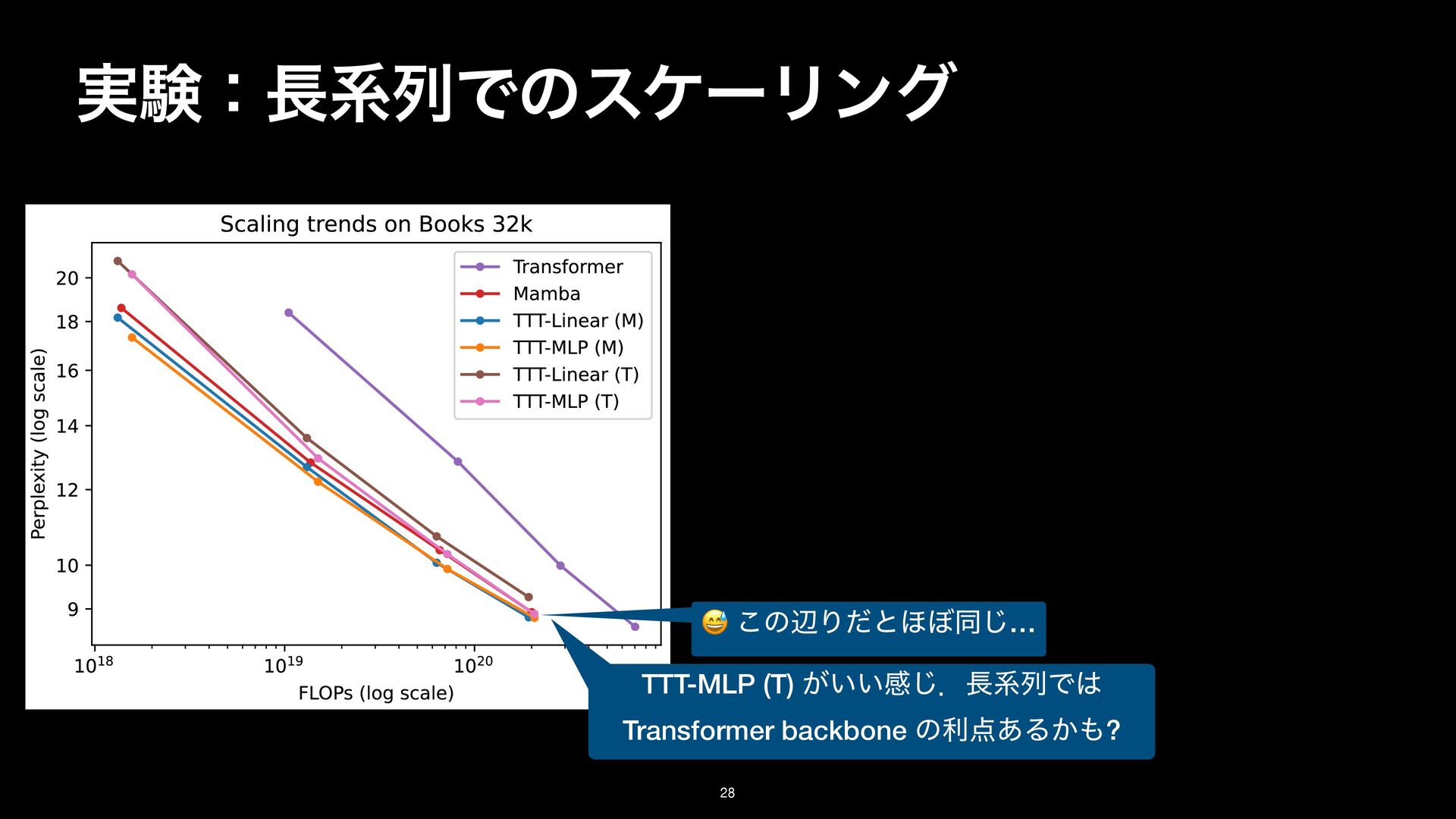
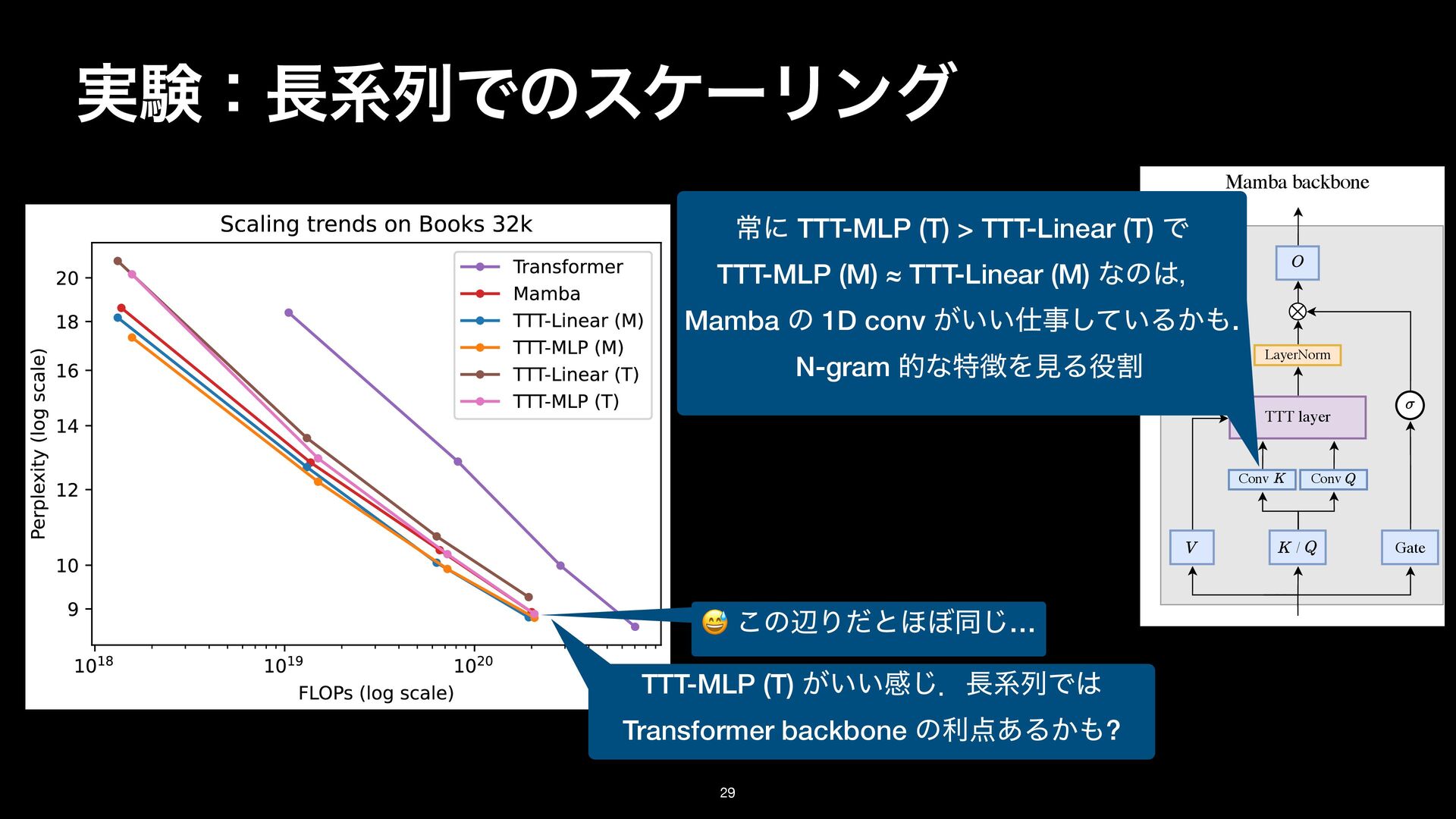
results g Transformer finetuning, are in Figure 15 (in Appendix). TTT-MLP (T) ͕͍͍ײ͡ɽܥྻͰ Transformer backbone ͷར͋Δ͔? 😅 ͜ͷลΓͩͱ΄΅ಉ͡… Sequence modeling block MLP block LayerNorm LayerNorm TTT layer LayerNorm / Conv TTT layer Conv LayerNorm Gate Residual block Transformer backbone Mamba backbone Figure 13. Left: A residual block, the basic building block for Transformers. The sequence modeling block is instantiated into two variants: the Transformer backbone and Mamba backbone. Middle: TTT layer in the Transformer backbone. The LN before O comes from NormFormer [60]. Right: TTT layer in the backbone inspired by Mamba [25] and Griffin [18]. Following these two architectures, ω here is GELU [29]. To accommodate the extra parameters of the gate without changing the embedding dimension, we simply combine εK and εQ into a single projection. ৗʹ TTT-MLP (T) > TTT-Linear (T) Ͱ TTT-MLP (M) ≈ TTT-Linear (M) ͳͷɼ Mamba ͷ 1D conv ͕͍͍ࣄ͍ͯ͠Δ͔. N-gram తͳಛΛݟΔׂ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}