本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、
より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。
speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
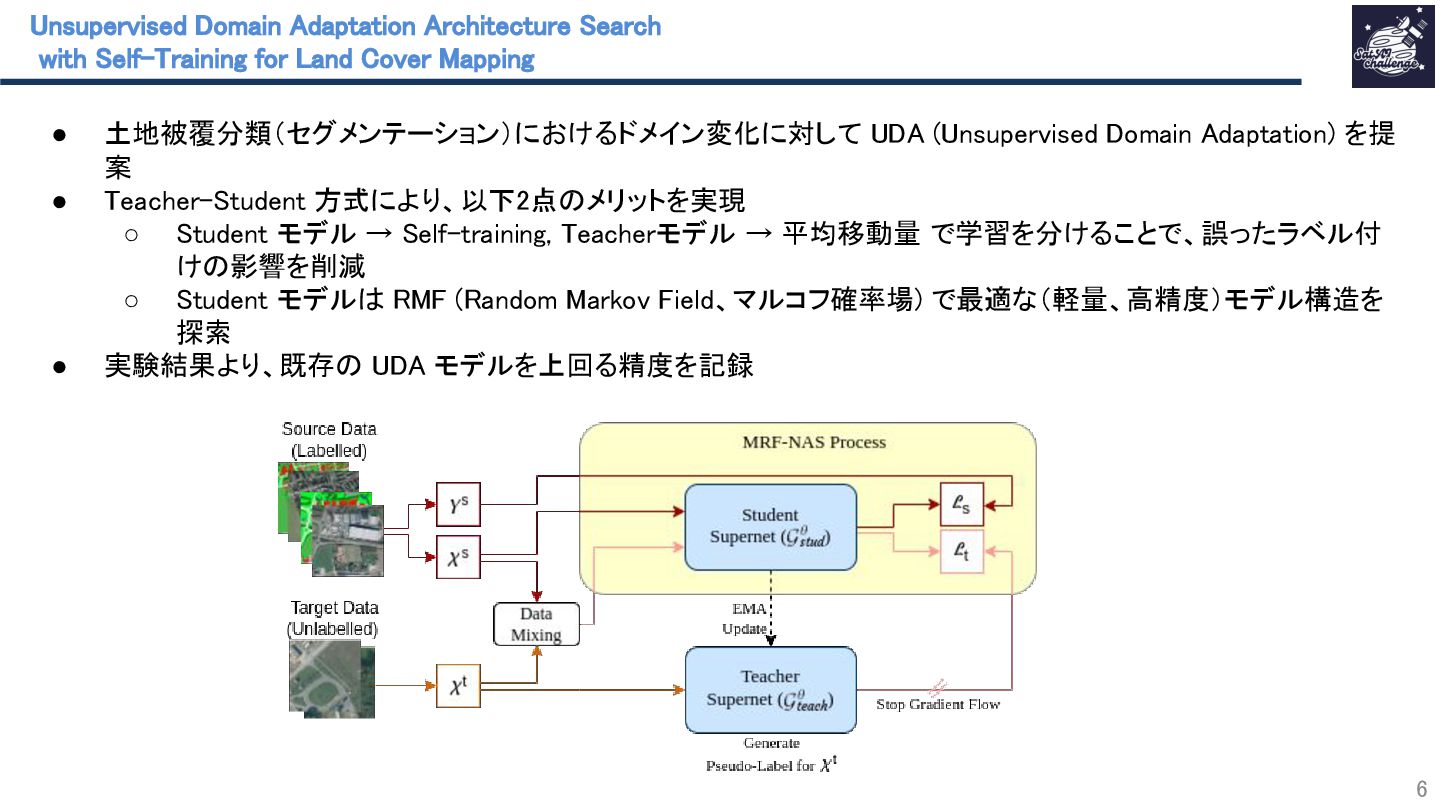
紹介する論文は、「Unsupervised Domain Adaptation Architecture Search with Self-Training for Land Cover Mapping」です。
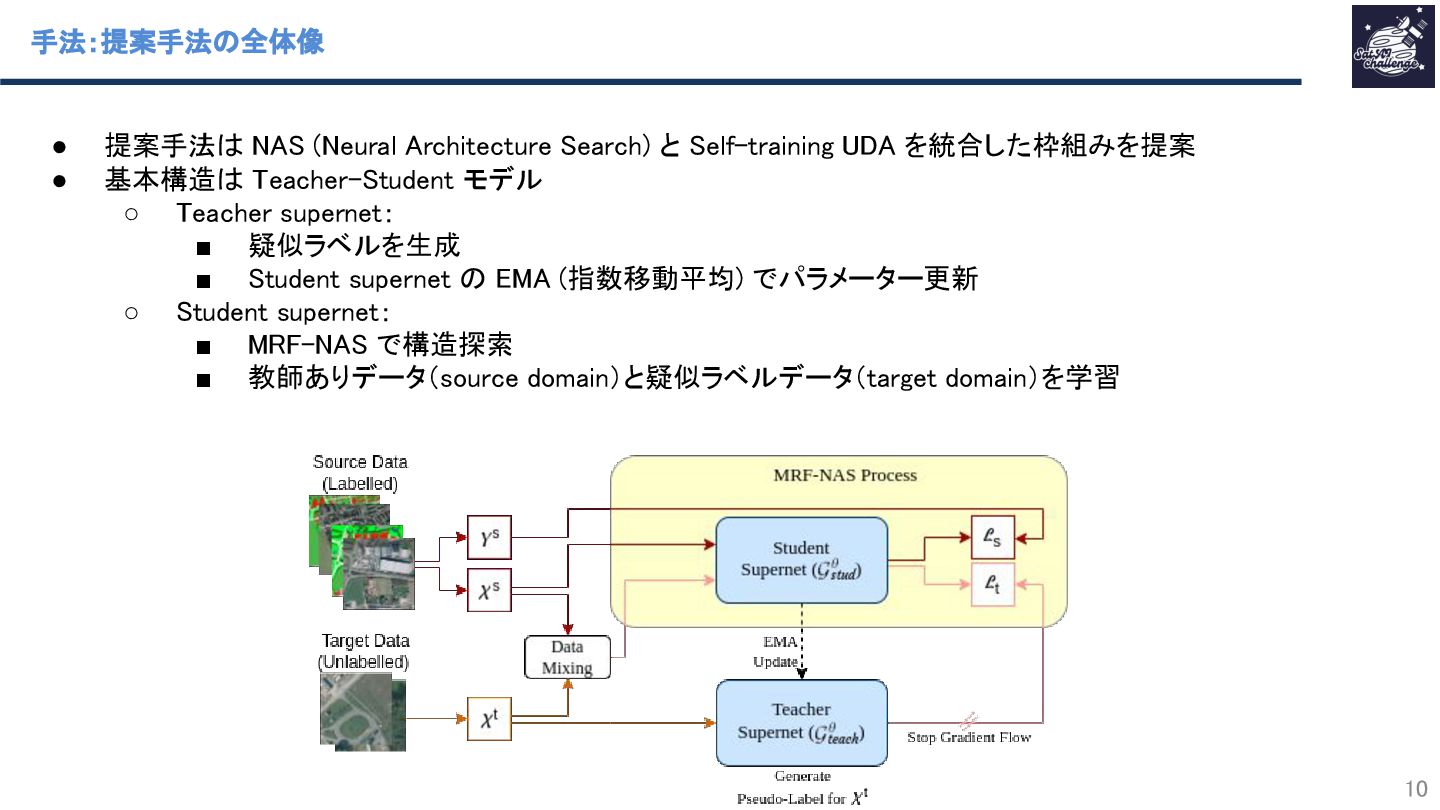
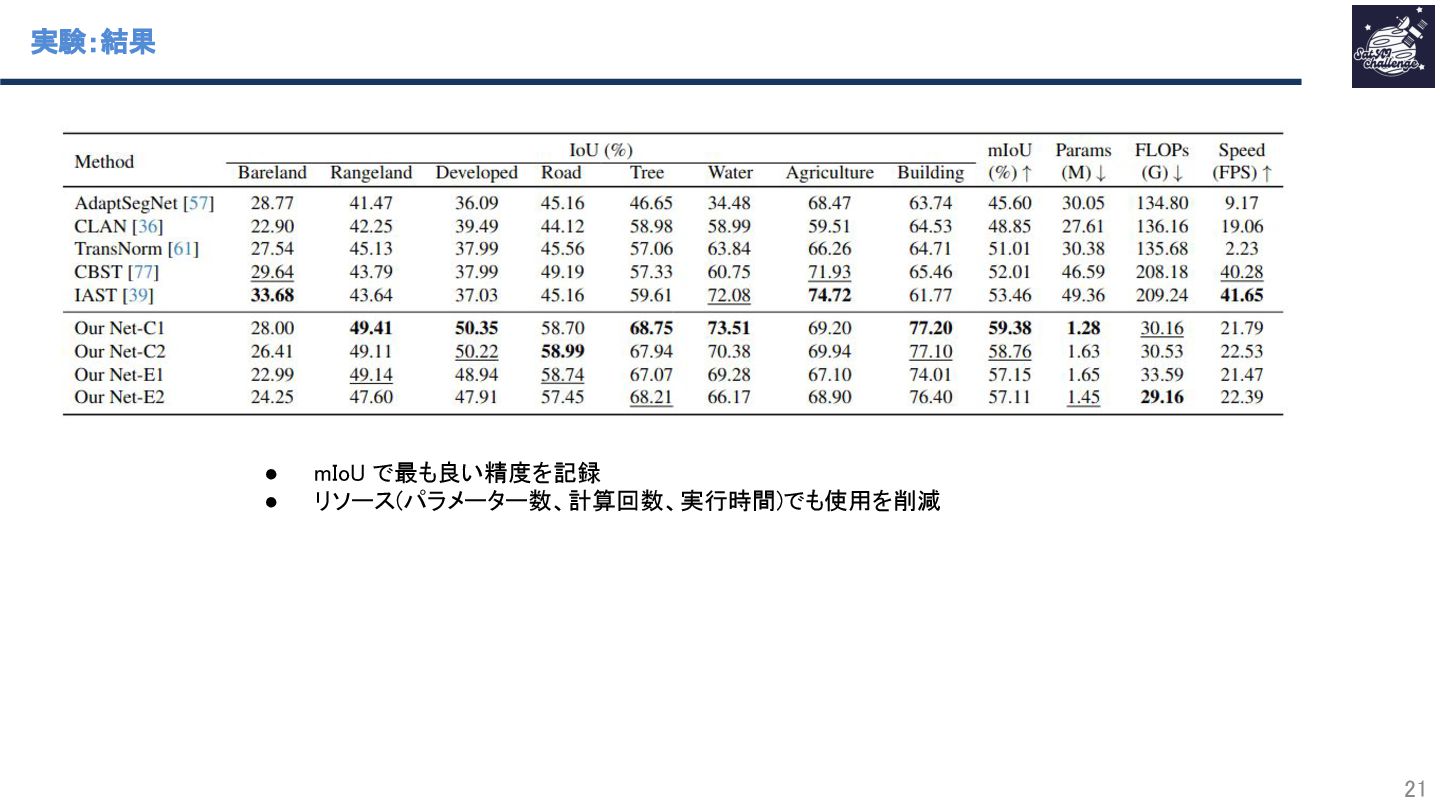
本研究は、土地被覆分類における教師なしドメイン適応(UDA)をSelf-trainingで行いつつ、モデル構造探索をマルコフ確率場(MRF)で行うことで、軽量かつテストドメインで高性能なモデルの獲得を実現しています。
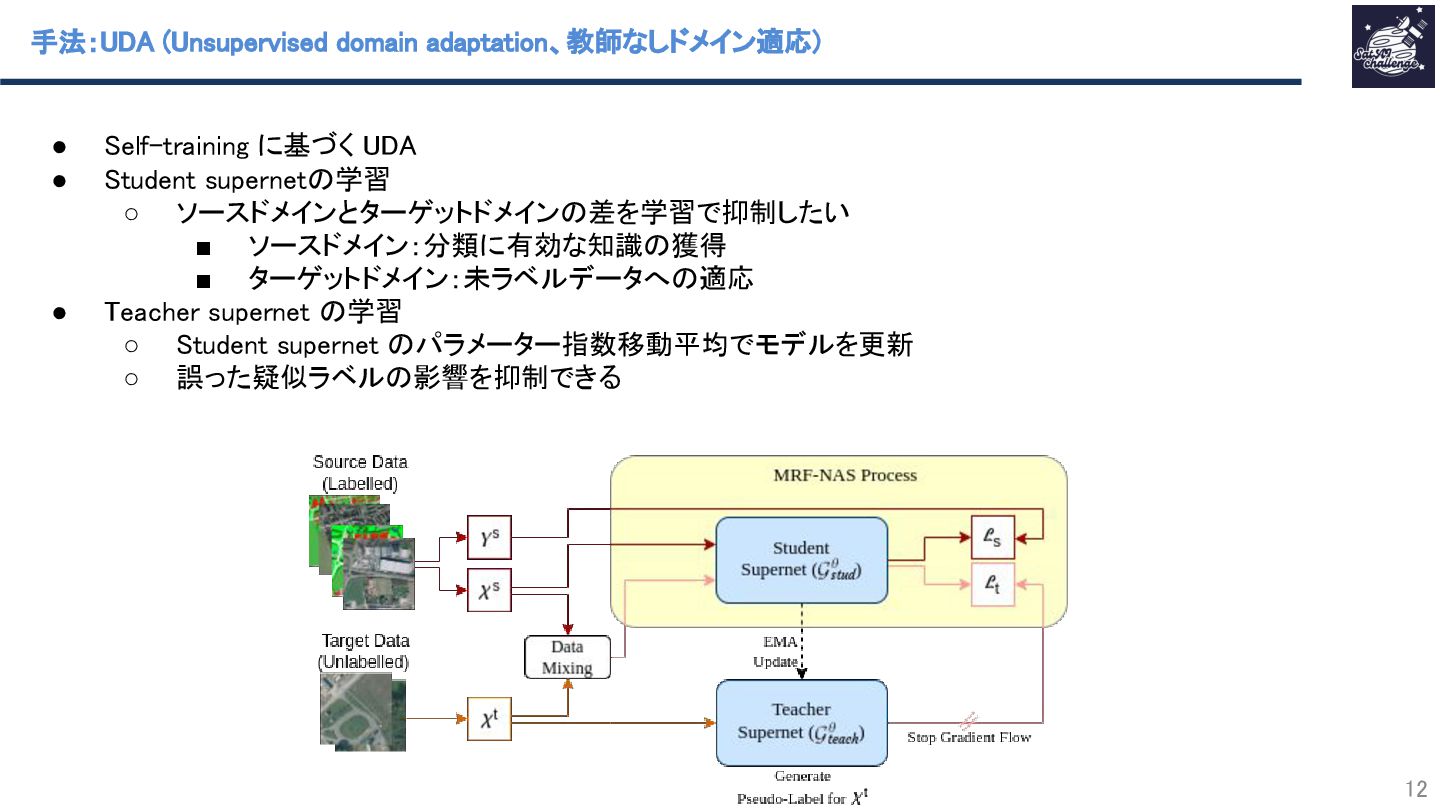
Self-trainingではTeacher/Studentモデルを採用し、Teacherモデル出力の疑似ラベルが誤っている場合でも、指数移動平均によりTeacherモデル学習での影響を抑制することで、正しい疑似ラベル出力になるよう学習しています。
MRFでは畳み込み層のカーネルサイズ、チャネル数などを最適化し、Teacherモデルよりも軽量なStudentモデルの構造を獲得することで、知識蒸留に近い効果を実現し、エッジコンピューティングなどへの応用の可能性を広げました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• 先行研究 [Wang et al.] の MRF-U-Net を利用 • 表1の構造パラメーターを探索](https://files.speakerdeck.com/presentations/2cef4bb861c944d6a028956f994bd7cd/slide_19.jpg){kind=link}
{kind=link}
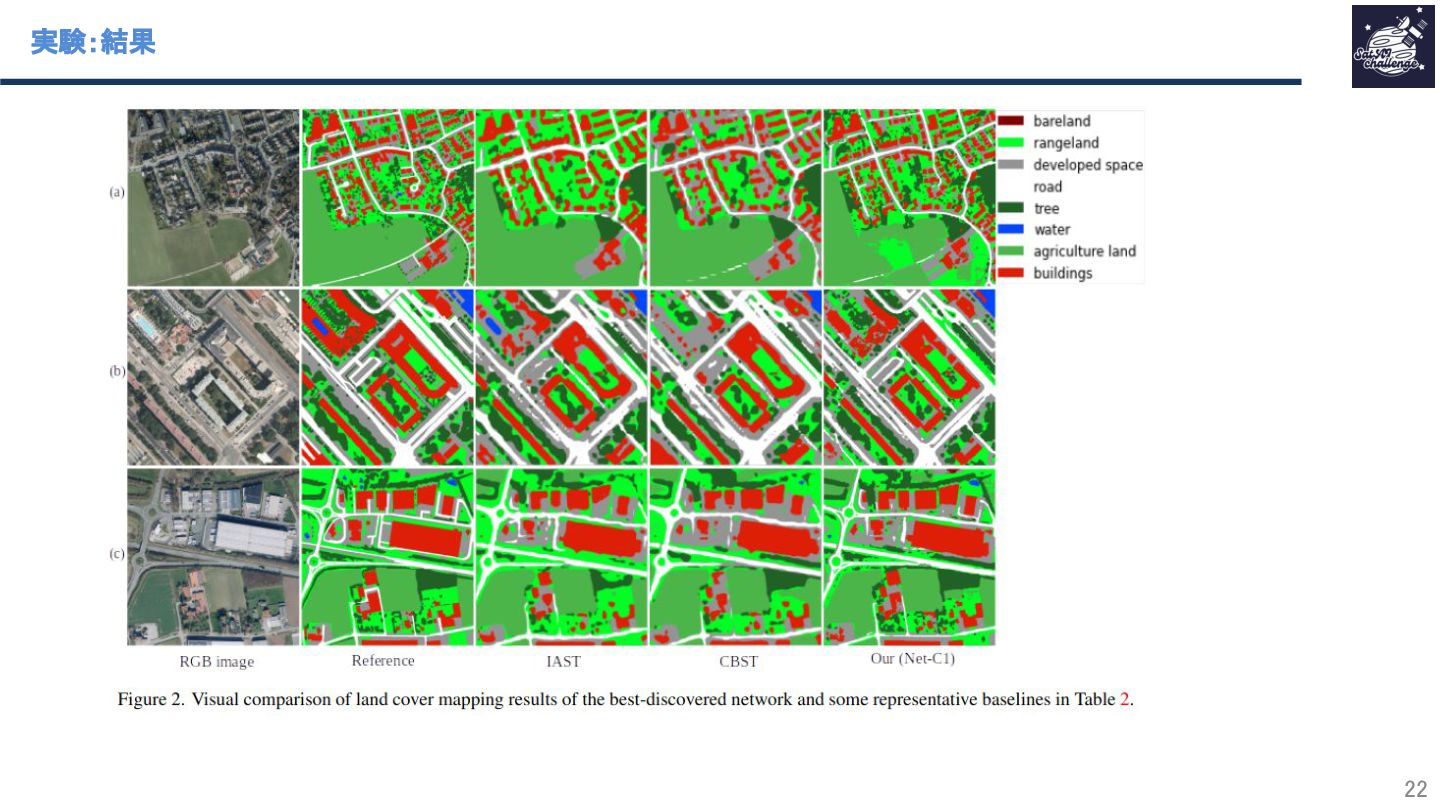{kind=link}
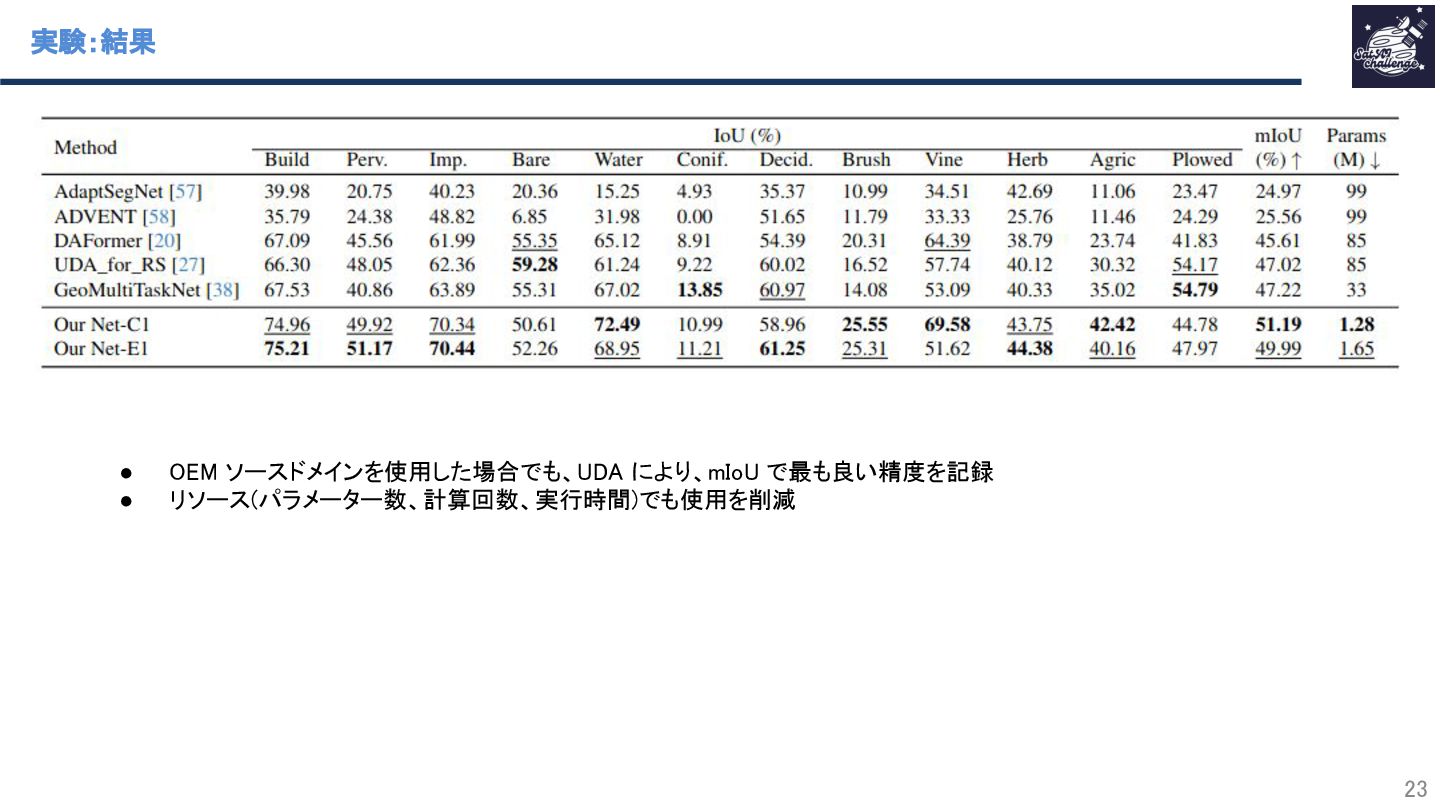{kind=link}
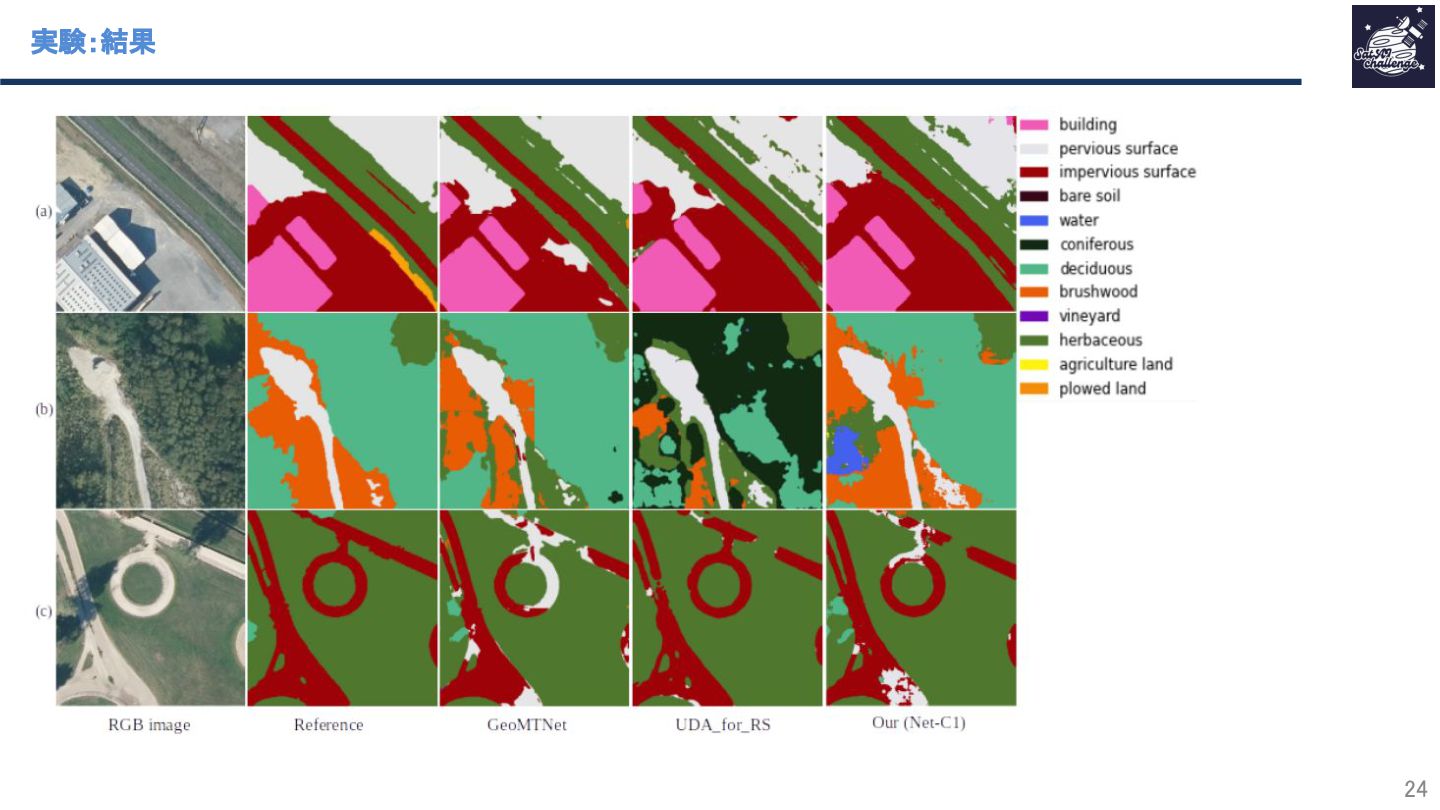{kind=link}
{kind=link}
{kind=link}