능력의 지수적 향상 온라인 및 모바일 서비스 대중화로 다양한 빅데이터 수집 HPC/딥러닝 모델을 쉽게 개발할 수 있는 SW 생태계의 발전 • 결과 머신러닝 방법론의 특성 : 광범위한 분야에 다양한 스케일로 적용 가능 각 분야의 도메인 전문가 또는 취미로 배우고자 하는 일반인, 학생 사이의 수요가 크게 증가 머신러닝 기반 / 머신러닝 융합 기술의 보급 ICT 산업, 제조, 교통, 환경 / 교육, 의료, 금융, 공공 부문 • 플랫폼 구축의 기술적 난이도 상승 다른 분야와의 차이점 : 빠른 변화 사이클 (하드웨어 및 소프트웨어 플랫폼, AI 프레임웍, 모델 등) 구축이 끝나는 시점에서는 이미 구세대 플랫폼이 됨 이로 인한 관리의 어려움 MLOps의 대두: 인공지능/HPC 기술의 폭발적 성장
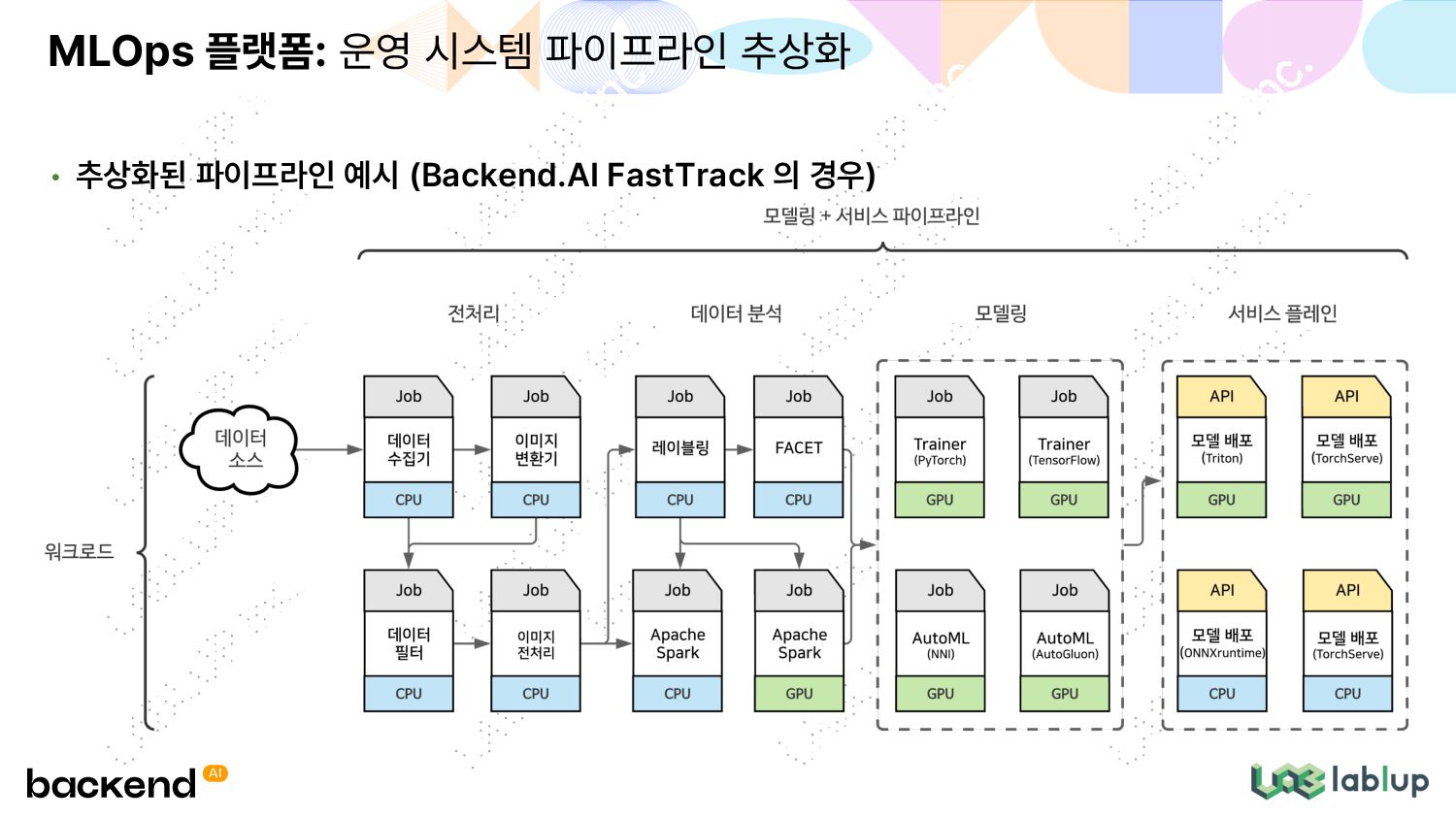
포함한 전기능 플랫폼 수요 증가 • Human in the loop: 자동화되지 못한 부분들 설정, 데이터 수집, 검증, 특징 추출, 리소스 관리, 인프라스트럭처 관리 등 종단간 기계학습 파이프라인 수요로의 진화 데이터 입력 데이터 분석 + 검증 데이터 변환 훈련 모델 평가 및 검증 모델 서비스 로깅 가비지 컬렉션 및 데이터 접근 컨트롤을 위한 공유 도구 파이프라인 저장소 튜너 공유 설정 프레임워크 및 일감 오케스트레이션 일감 관리, 모니터링, 디버깅, 데이터/모델/검증 시각화
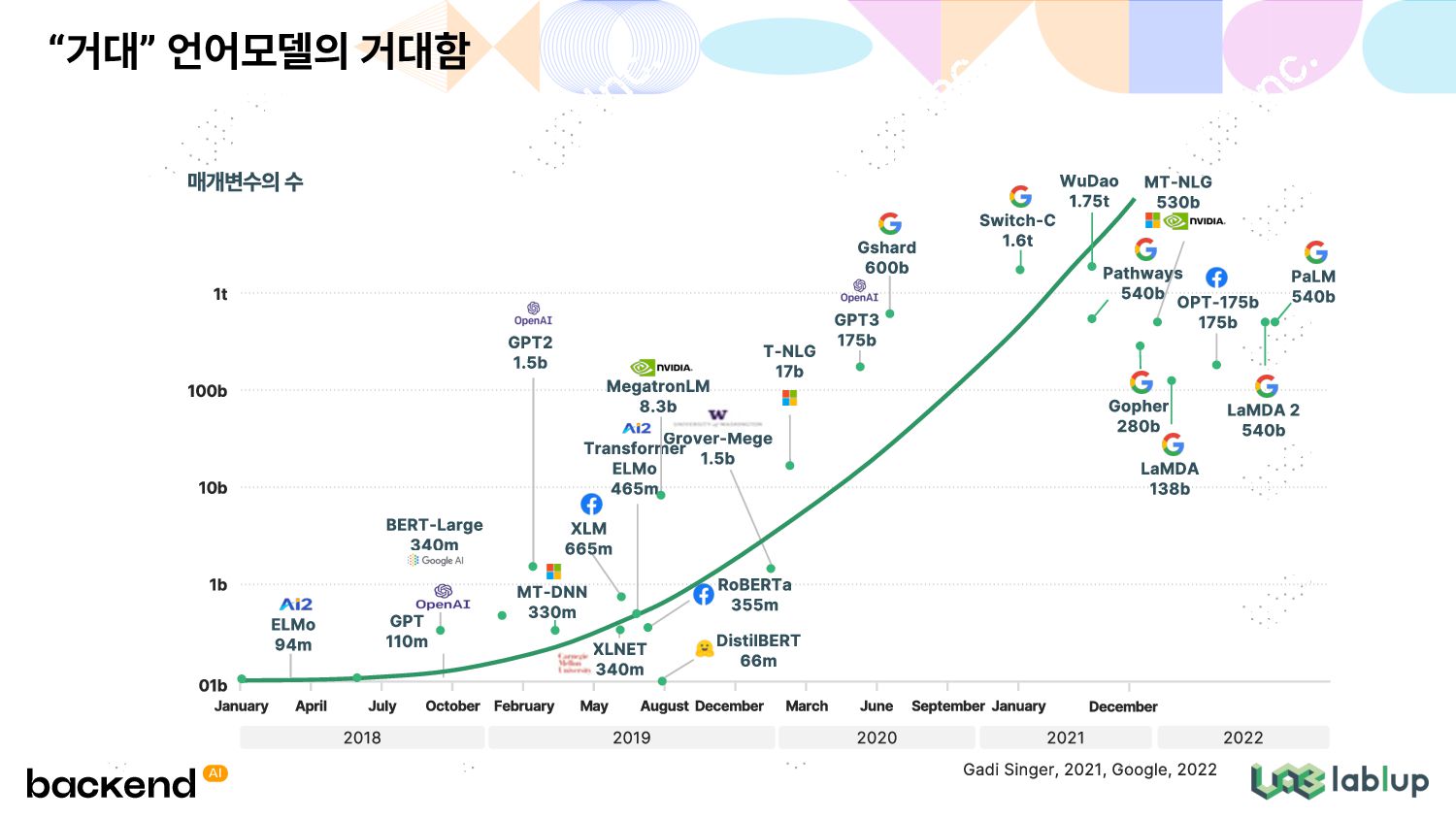
다른 파이프라인 내 워크로드 특성 딥러닝 연산 가속기의 급성장 대규모 연산으로 인한 높은 모델 개발 비용 단계별 성능 병목 지점 차이 - 데이터 전처리: Data I/O - 데이터 분석: CPU - 딥러닝 훈련: GPU/ASIC - 모델 서빙: CPU/GPU 딥러닝용 GPU 시장 - NVIDIA, AMD, Intel 딥러닝 전용 ASIC 시장 - GraphCore - Habana Goya - Google TPU / Coral - NVIDIA 단위시간당 자원 비용 증가[1] - CPU: $0.006 - GPU (A100 기준): $0.93 모델 훈련 비용의 급격한 증가 - GPT-3 (2020): 45억원~ - T5 (2019): 30억원~ - BERT (2018): 1억원~ [1] https://cloud.google.com/compute/gpus-pricing?hl=ko
등장 작업 그래프 기반 파이프라인·워크플로우 저작 도구 등장 다양한 산업 분야에서의 AI 적용 및 활용도 증가 컨테이너 기반 가상 환경 - Docker, Podman - Containerd, LXC - Kubernetes VM 기반 가상환경 - KVM, QEMU, VMWare - Firecracker 오픈소스 파이프라인 도구 - Apache AirFlow - MLFlow - KubeFlow 클라우드 파이프라인 서비스 - Amazon SageMaker MLOps - Google Cloud Composer - Azure MLStudio 데이터 보안 / 프라이버시 - 금융기관, 공공기관 엣지 컴퓨팅 - 스마트 팩토리, 물류, 환경 분야 하이브리드 클라우드 솔루션 - 클라우드 벤더 - 온프레미스 벤더 - 오픈소스
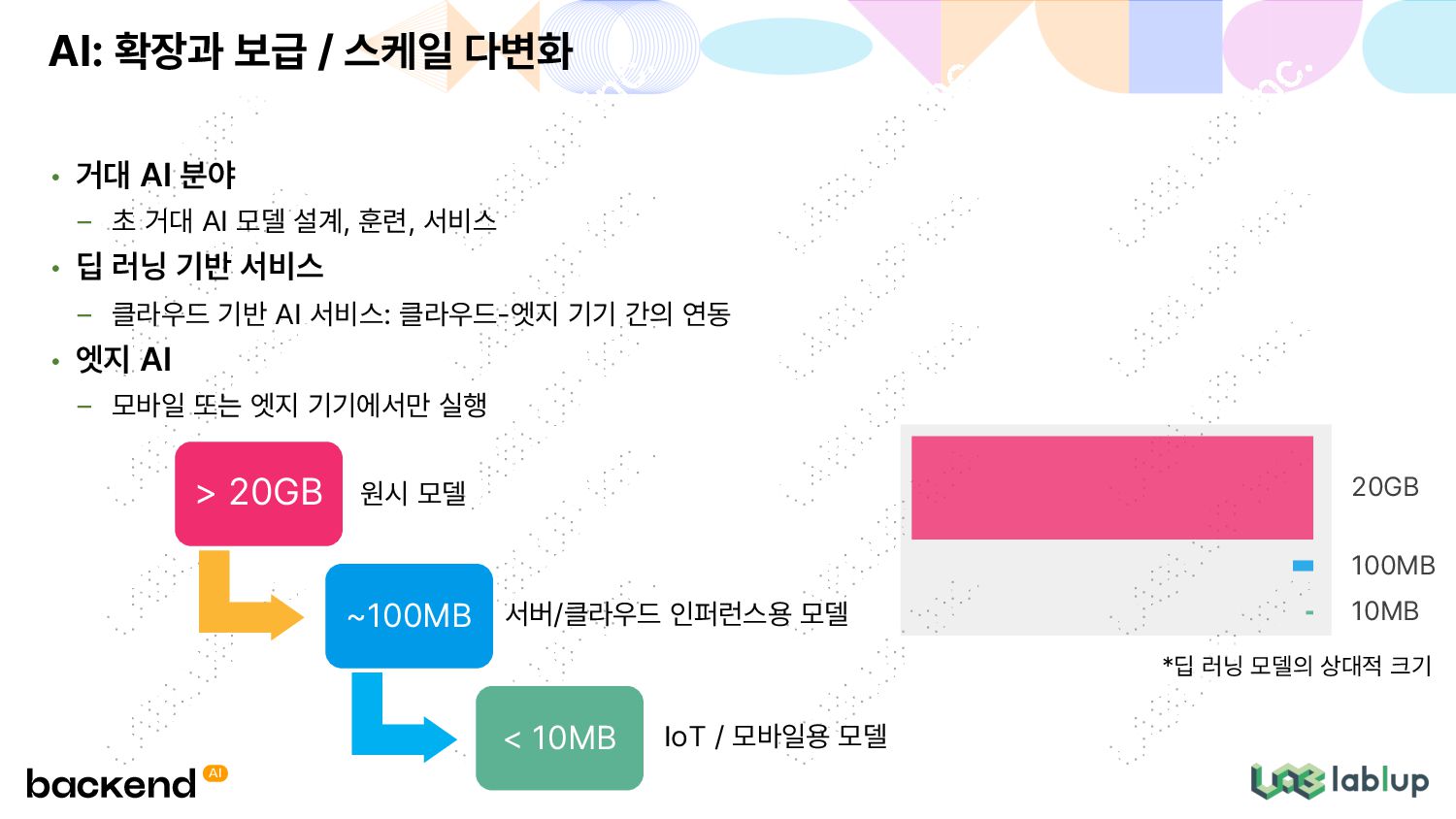
서비스 • 딥 러닝 기반 서비스 클라우드 기반 AI 서비스: 클라우드-엣지 기기 간의 연동 • 엣지 AI 모바일 또는 엣지 기기에서만 실행 AI: 확장과 보급 / 스케일 다변화 *딥 러닝 모델의 상대적 크기 > 20GB 원시 모델 ~100MB 서버/클라우드 인퍼런스용 모델 < 10MB IoT / 모바일용 모델 20GB 100MB 10MB
위한 파이프라인의 머신러닝 버전 솔루션이 아닙니다. 개념입니다. 마케팅적으로는 AIOps라는 표현을 쓰기도 합니다. • DevOps · CI/CD 와의 차잇점 각 컴포넌트들의 연산 자원 요구가 매우 불균형 각 컴포넌트들의 발전에 따른 변경사항이 엄청나게 다양 개발 과정 대신 실험 과정이 필요함 배포 단계가 굉장히 다양하고 복잡함 배포시 필요 리소스가 다양함 MLOps 플랫폼: 대규모 AI 인프라스트럭처 관리 완전히 성격이 다른 파이프라인 내 워크로드 특성 딥러닝 연산 가속기의 급성장
/ 매니지먼트 도구 오케스트레이터 / 스케쥴러 스케일러 • 워크로드의 특징으로 인한 차잇점들 모델 A/B 테스트 및 피드백 루틴 데이터 전처리기, 데이터 로더, GPU 가속기 대응 Human in the loop DevOps CI/CD: CI 도구의 오류 대응 MLOps: CI가 모델 A/B 테스트, 밸리데이터 / 코드 검증이 모델 결과 검증으로 대체 개발 단계 대신 실험+자동 모델 개선 루프가 필요 결과 확인 및 판단부터 연구개발 인력이 동원됨 MLOps 플랫폼: 구성요소의 차잇점
복잡도에 대응하는 다양한 기능 및 요구사항들이 반영됨 이는 플랫폼 사용성의 난도를 엄청나게 올림 • 사용 패턴의 강제화 도구 복잡도가 높을 수록 사용 난도가 올라감 그에 따른 사용자 이용 패턴을 일원화를 강제하게 됨 워크로드 유연성 및 플랫폼 이식성 양 측면에서 문제가 됨 MLOps 플랫폼: 실질적인 문젯점들
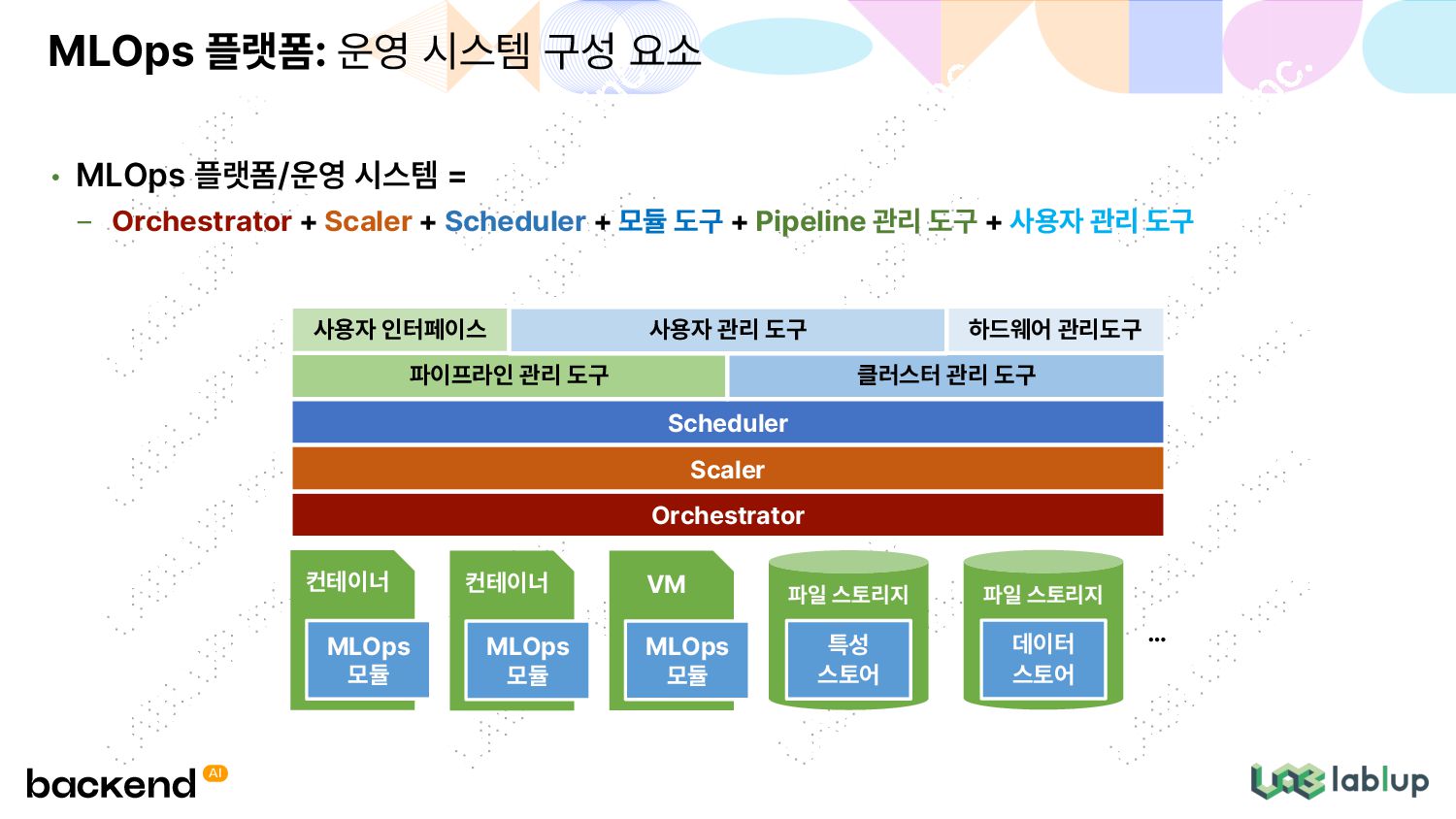
+ 모듈 도구 + Pipeline 관리 도구 + 사용자 관리 도구 MLOps 플랫폼: 운영 시스템 구성 요소 Orchestrator Scheduler Scaler 컨테이너 MLOps 모듈 파이프라인 관리 도구 컨테이너 MLOps 모듈 VM MLOps 모듈 클러스터 관리 도구 하드웨어 관리도구 파일 스토리지 특성 스토어 파일 스토리지 데이터 스토어 … 사용자 인터페이스 사용자 관리 도구
• MLOps만의 특징적인 구조 메타데이터 관리 데이터 관리의 필요성 증가: 데이터도 코드처럼 포맷 변환, 버전 컨트롤, 내결함성 데이터 저장소 (data store) 및 전처리 후 특성 저장소 (feature store) 데이터 입출력: 시스템 전체 병목이 발생하는 부분 분산 데이터 로더 / 샤딩 특화 초고속 데이터 입출력 플레인 / 컨트롤 플레인 분리 연산 가속: 딥러닝 모델 훈련 과정에 가장 중요한 요소 GPU 및 AI 가속칩 대응 GPU 사용률 관리 등 MLOps 플랫폼: 고유 특징
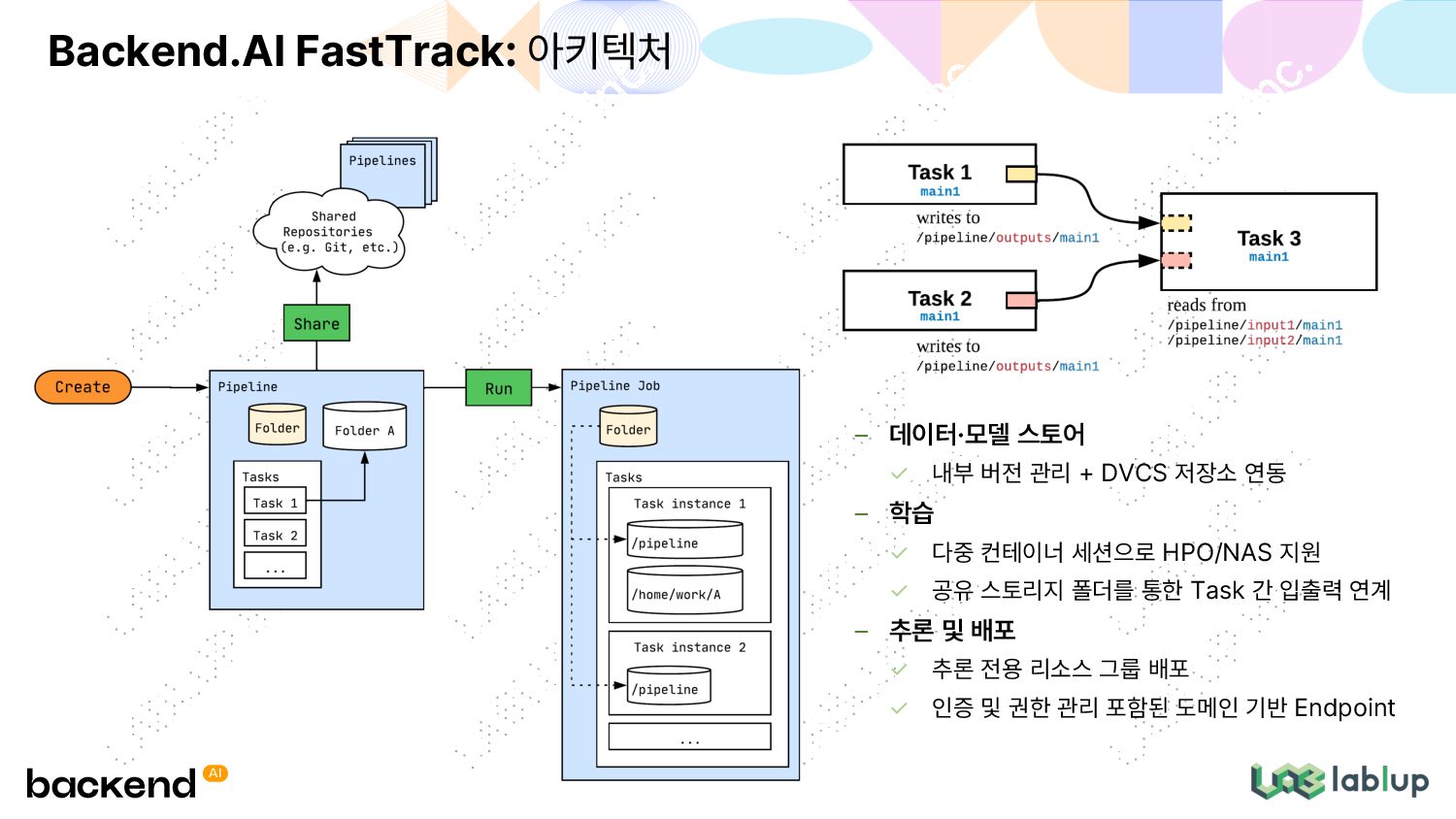
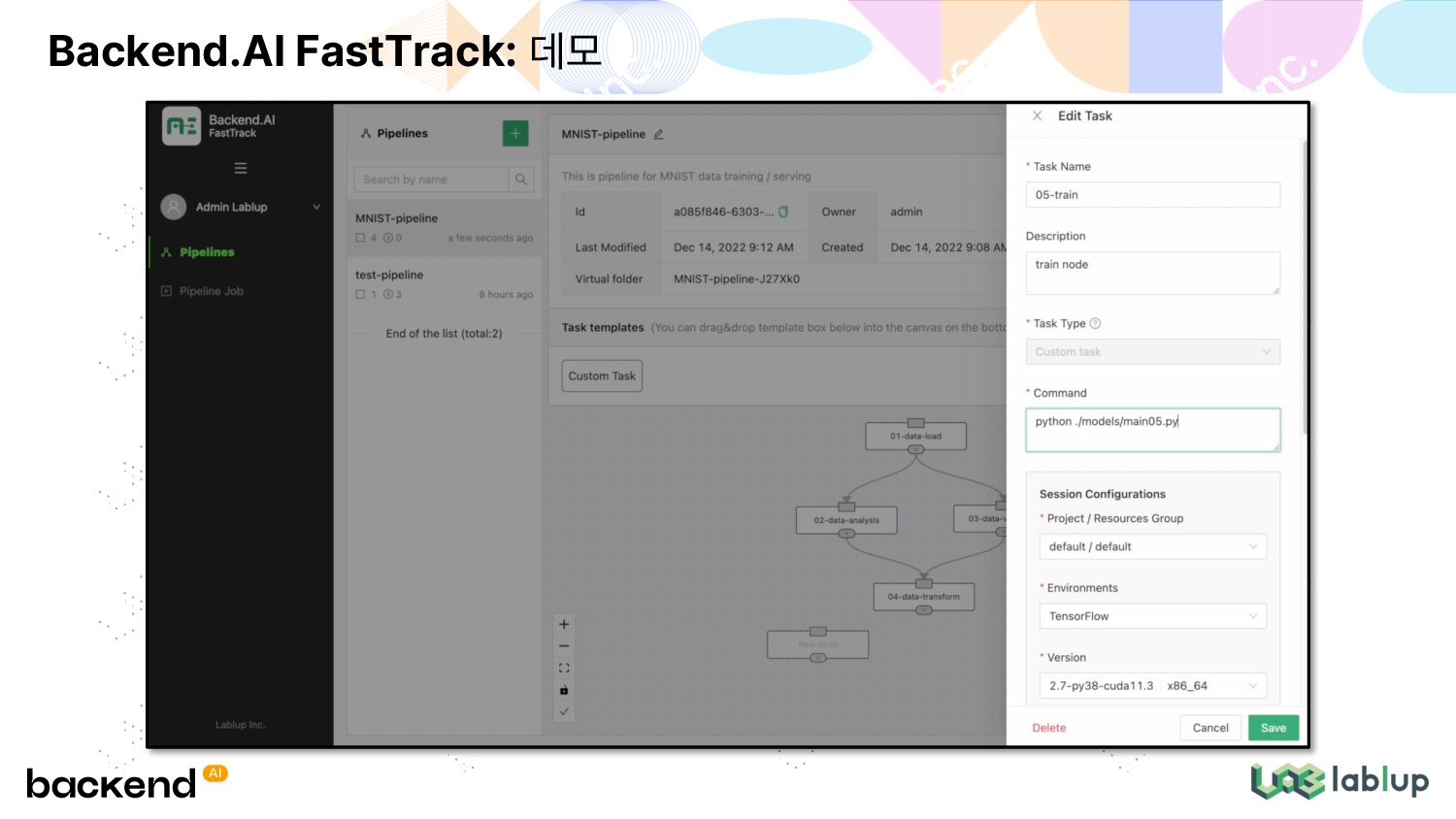
이식성 및 휴대성 (데이터 + 코드 + 환경) 재사용성 및 재현성 다양한 고객사 환경에 배포 가능해야 함 망분리 환경, 복잡한 방화벽·보안 관제 조건 프로젝트·부서·팀 등 복잡한 조직 위계 구조와 사용계·운영계 분리 유연한 확장성 고객이 하드웨어 추가 구축 시 원활한 확장 조직 내 연산자원의 물리적 위치 고려한 최적 시스템 구성 제안 Backend.AI FastTrack: 문제 정의 및 해결책 Backend.AI 해결책 MLOps Pipeline 구축을 돕는 FastTrack 재사용 가능한 이미지 스냅샷을 쉽게 구축하는 Forklift 다층적 접근제어 및 파이프라인 자원 관리를 위한 Resource Group 방화벽 걱정 없는 컨테이너 사용과 모델 서빙을 위한 App Proxy 스토리지 확장성을 위한 Storage Proxy
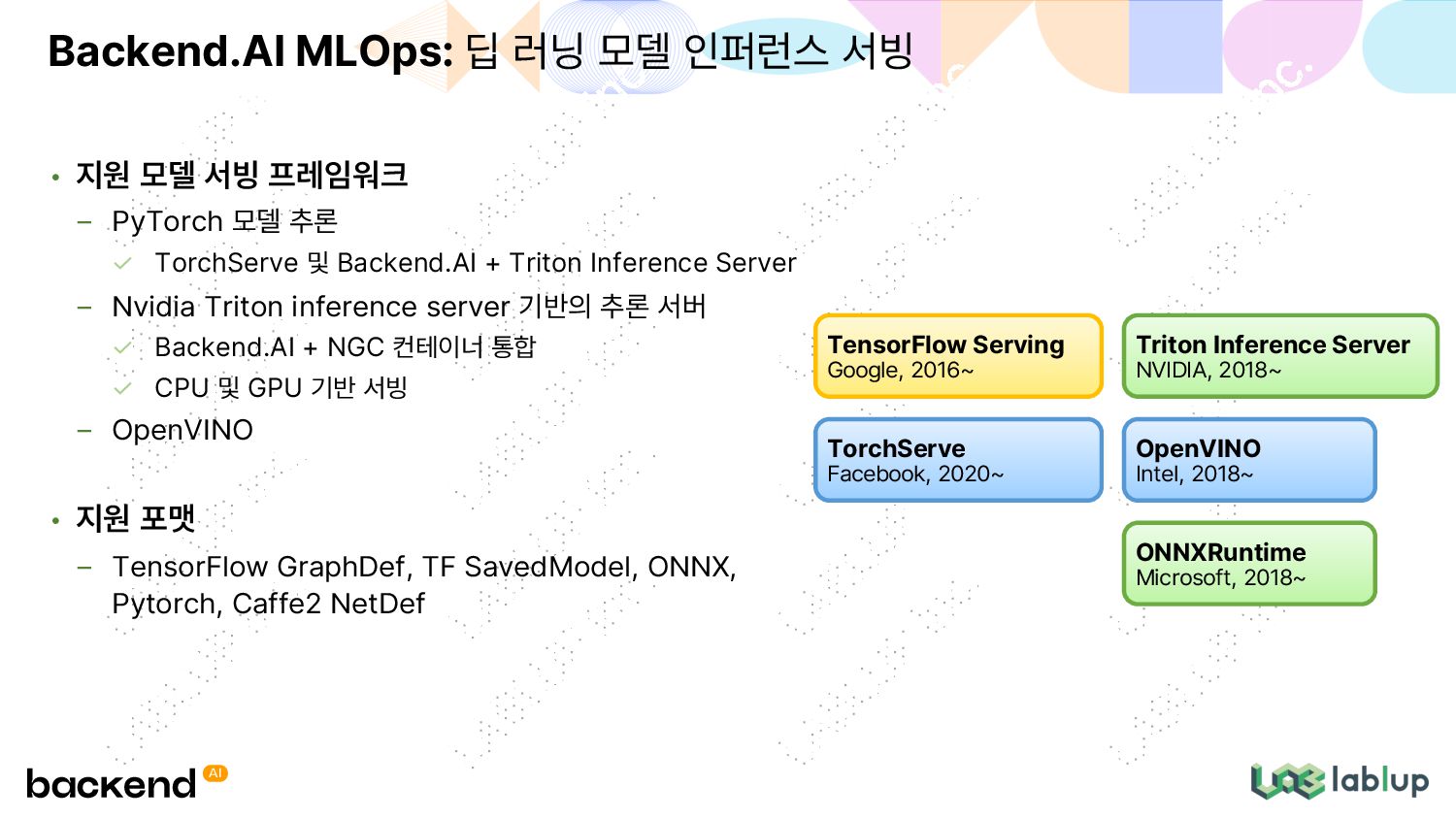
Backend.AI + Triton Inference Server Nvidia Triton inference server 기반의 추론 서버 Backend.AI + NGC 컨테이너 통합 CPU 및 GPU 기반 서빙 OpenVINO • 지원 포맷 TensorFlow GraphDef, TF SavedModel, ONNX, Pytorch, Caffe2 NetDef Backend.AI MLOps: 딥 러닝 모델 인퍼런스 서빙 TensorFlow Serving Google, 2016~ Triton Inference Server NVIDIA, 2018~ OpenVINO Intel, 2018~ ONNXRuntime Microsoft, 2018~ TorchServe Facebook, 2020~
인퍼런스 오토스케일링 • App Proxy의 미인증 모드 기반 서비스 추론 컨테이너의 auto-scaling 추론 워크로드를 위한 전용 Resource Group 설정 • 모델 서빙 스케일링 매니저의 프록싱 부담 없이 바로 모델 서비스 전체 시스템 부하를 최소화한 인퍼런스 구현 API 부하에 따른 인퍼런스 서비스 자동 추가 실행 및 버퍼링 Backend.AI MLOps: 딥 러닝 모델 서비스 스케일링
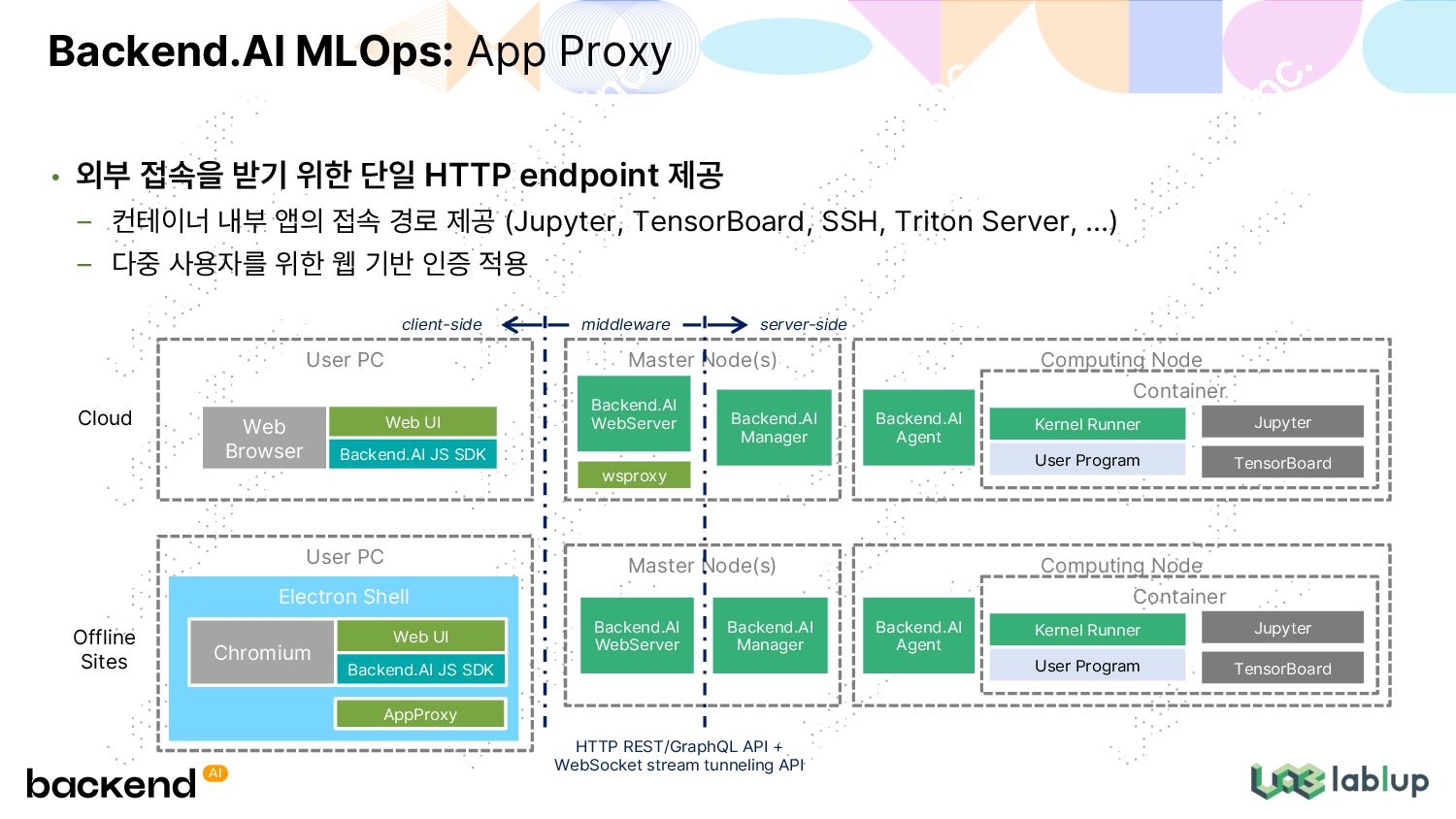
내부 앱의 접속 경로 제공 (Jupyter, TensorBoard, SSH, Triton Server, ...) 다중 사용자를 위한 웹 기반 인증 적용 Backend.AI MLOps: App Proxy User PC Web Browser Computing Node Backend.AI Agent Container Kernel Runner User Program Jupyter TensorBoard Master Node(s) Web UI wsproxy Backend.AI JS SDK client-side User PC Electron Shell Chromium Computing Node Backend.AI Agent Container Kernel Runner User Program Jupyter TensorBoard Master Node(s) HTTP REST/GraphQL API + WebSocket stream tunneling API Backend.AI Manager Backend.AI WebServer Backend.AI Manager Backend.AI WebServer Web UI Backend.AI JS SDK AppProxy server-side middleware Cloud Offline Sites
+ 템플릿 기반 앱 추가 다양한 사전 지원 앱 Dockerfile 생성 및 다운로드 지원 이미지 저장소로 자동 push 기능 설치된 이미지 관리 이미지 메타데이터 확인 및 삭제 실행 중인 컨테이너 조회 및 커밋 기능 • 원하는 연구 / 개발 환경을 직접 손쉽게 만들고 배포 Backend.AI Forklift: 편의성 중심의 컨테이너 이미지 제작도구
도전 과제들 증가하는 딥 러닝 소프트웨어 레거시 엔터프라이즈 AI/ML과 신기술 등장의 속도 차 Arm / RISC-V 등 멀티 아키텍처 플랫폼의 등장 인간계의 한계: 발열과 전력 소모 문제 전력 대 성능비의 중요성 – 더이상 데이터센터에 집적이 힘들다 AI 훈련 및 서비스 가속 ASIC의 춘추전국시대 도래 CPU 대비 상대적으로 간단한 구조 특화 기능 대응의 용이함을 살릴 수 있을 것인지? 거대 언어 모델 및 생성 모델 서비스의 증가 고비용 AI 모델의 상용화 급증 Edge Intelligence / distributed intelligence 모바일 단에서의 모델 서빙 – 일반 IoT 기기들로 확장 딥 러닝 엣지 소프트웨어 플랫폼들의 보급
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![감사합니다! [email protected] https://www.facebook.com/lablupinc Lablup Inc. https://www.lablup.com Backend.AI https://www.backend.ai Backend.AI GitHub](https://files.speakerdeck.com/presentations/8b1e3650edb244f99d13aaa0fc4a7a0d/slide_29.jpg){kind=link}