3. The Magic of VisuTale 4. Problem Solution 5. Backend.AI The Enabler 1. Flow diagram 6. The Orchestra of AI Models 🎩🐰 7. The Future of VisuTale 8. Setup on B.AI
Backend.AI demos – Research § Previous Experience: ESG Data Scientist, Who s Good, 2016 2019 § Education: MS from KAIST Graduate School of Knowledge Service Engineering 2016 Sergey Leksikov Alzheimer prediction in young mouse brains based on EEG recordings Airborne Infection Risk prediction based on particle spread
of VisuTale – Exploration of AI models and engines § Why You Should Care – Harnessing generative AI – Blueprint for using Backend.AI § Agenda Overview – Magic behind VisuTale – Tech powering VisuTale – Future of VisuTale
AI models generate text or images, but they work independently § The Existing Solutions – Existing multi modal AI models can not directly output the text in the form of a story or generate a story based images § The VisuTale Solution – focuses on enhanced user experience and more engaging form of media – orchestrates multiple Generative AI models to create a unified narrative experience. § Business applications – Storytellers – Marketers
that hosts and runs the VisuTale experience with Generative AI models § Why Backend.AI? – Fast time reduction from environment setup, prototyping to model inference – Scalability – Reliability – Ease of use – MLOps solutions
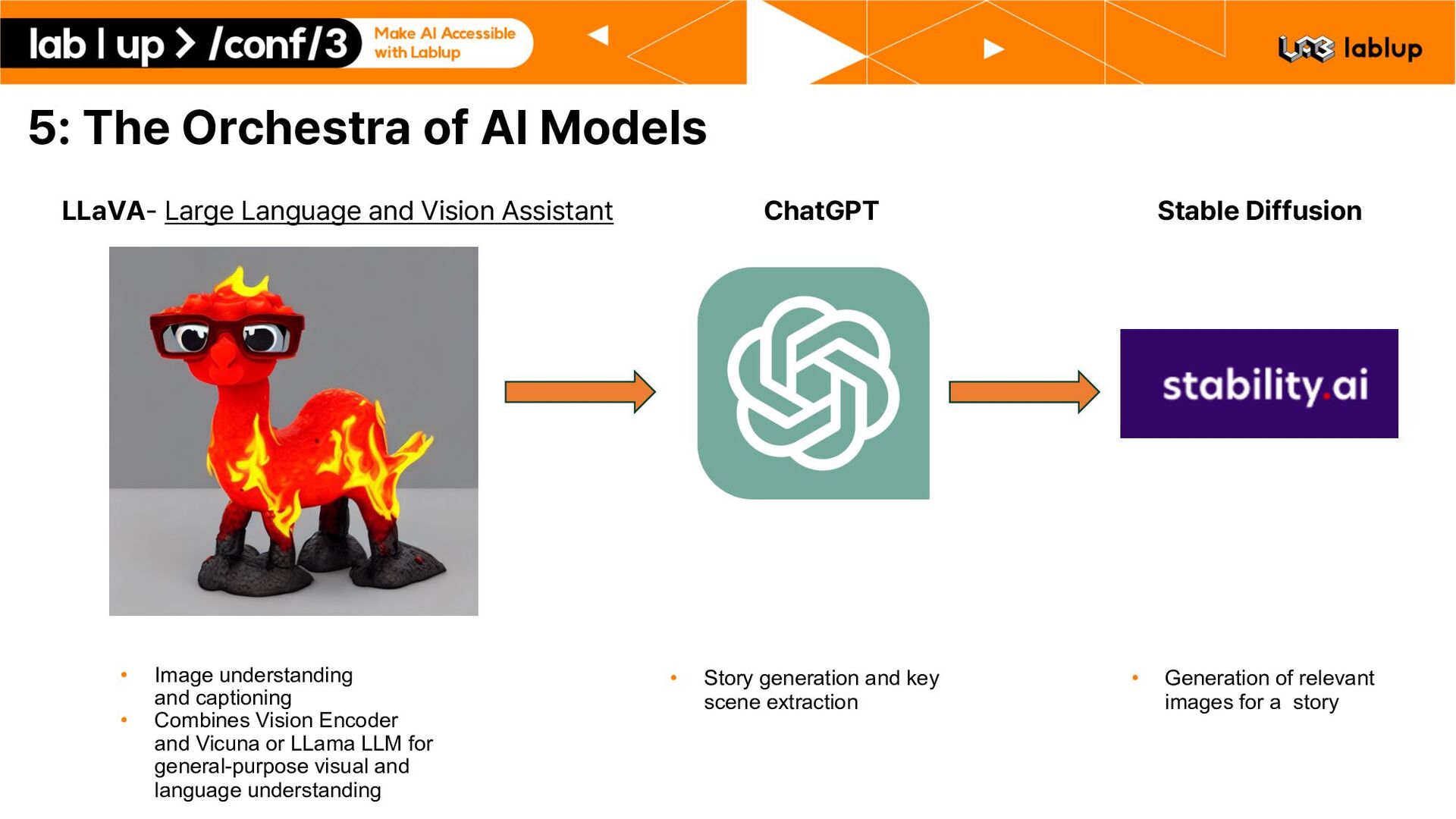
Vision Assistant Stable Diffusion ChatGPT • Story generation and key scene extraction • Image understanding and captioning • Combines Vision Encoder and Vicuna or LLama LLM for general-purpose visual and language understanding • Generation of relevant images for a story
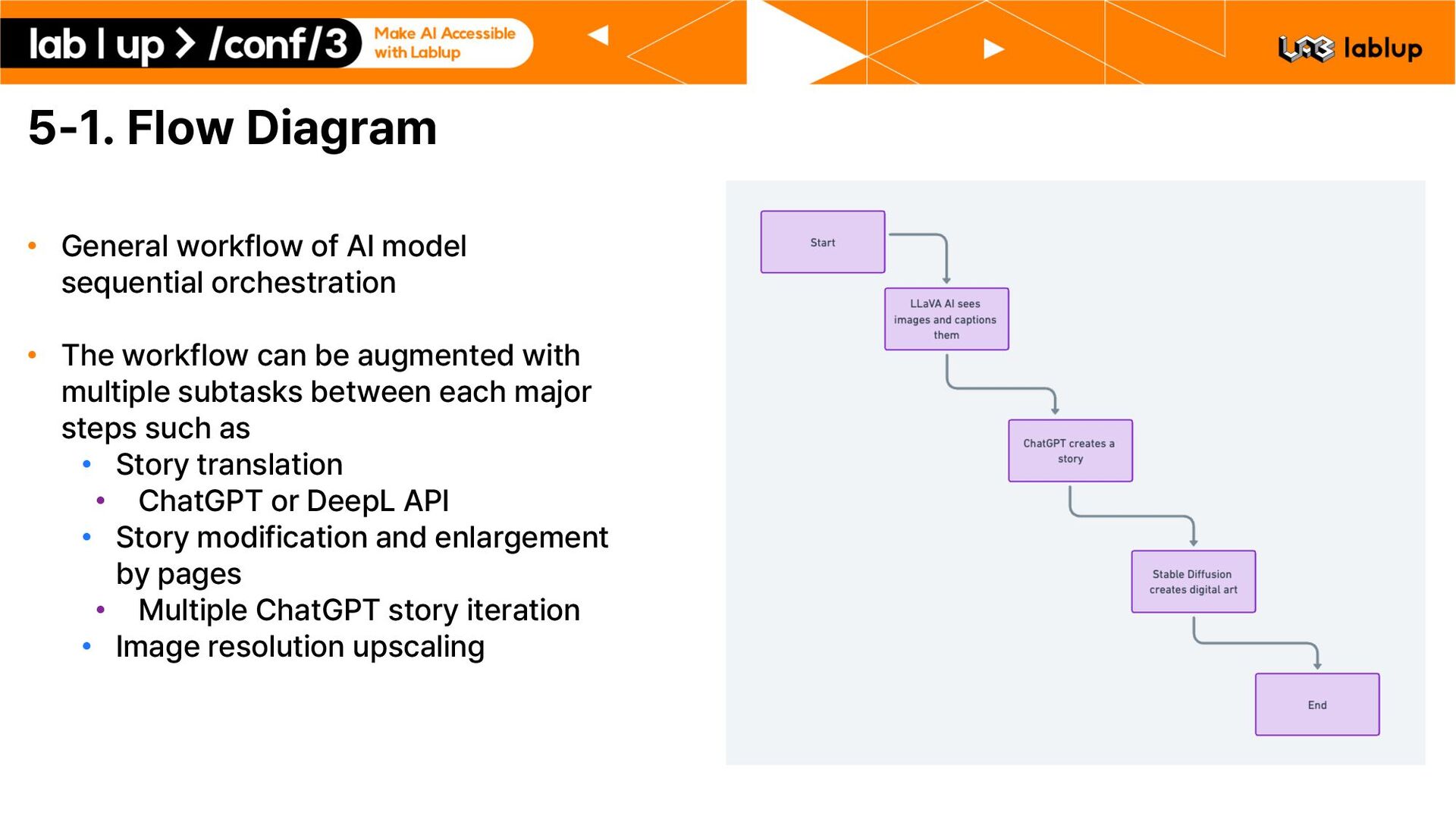
sequential orchestration • The workflow can be augmented with multiple subtasks between each major steps such as • Story translation • ChatGPT or DeepL API • Story modification and enlargement by pages • Multiple ChatGPT story iteration • Image resolution upscaling
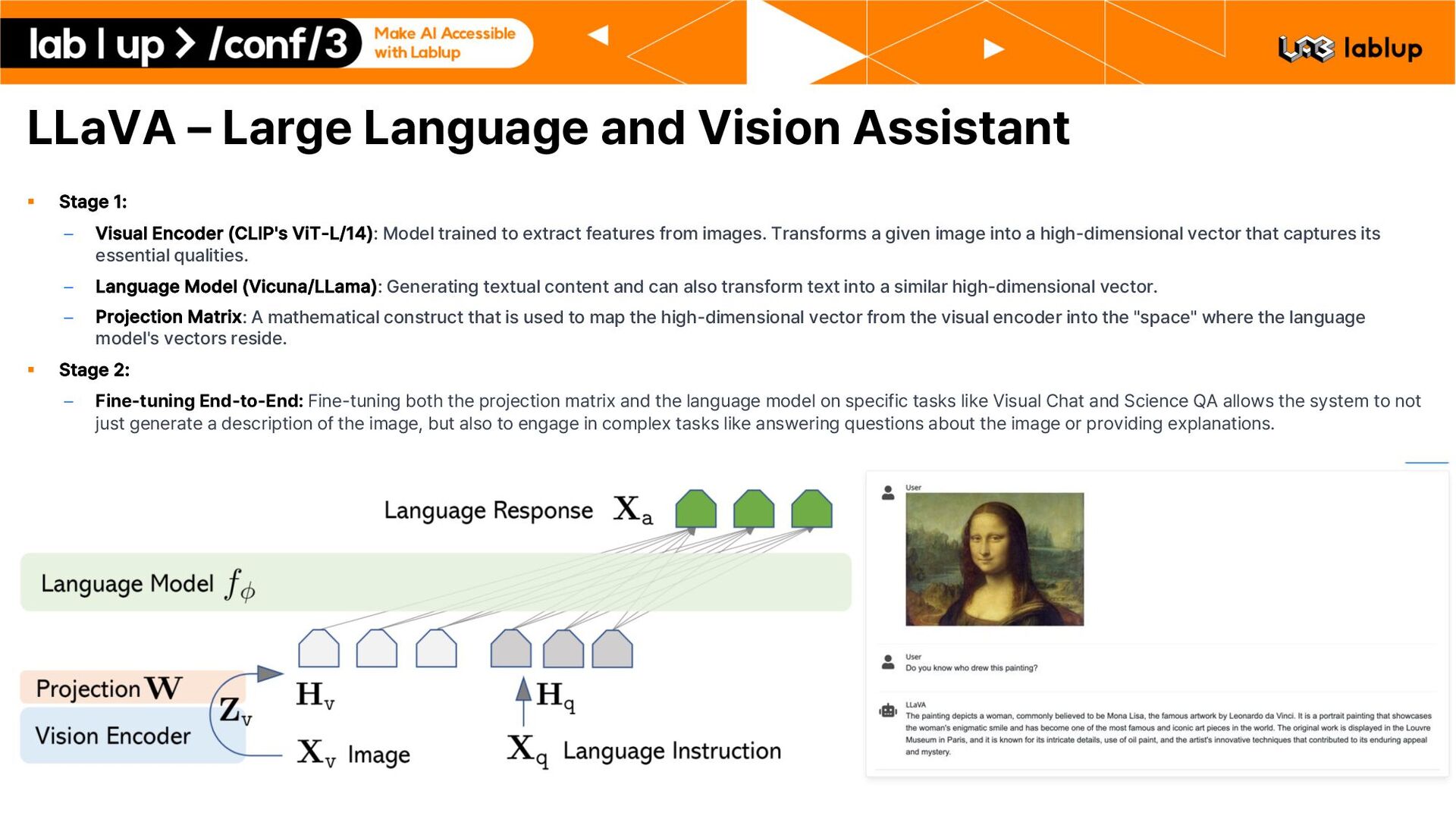
Visual Encoder CLIP s ViT L/14 : Model trained to extract features from images. Transforms a given image into a high dimensional vector that captures its essential qualities. – Language Model Vicuna/LLama : Generating textual content and can also transform text into a similar high dimensional vector. – Projection Matrix: A mathematical construct that is used to map the high dimensional vector from the visual encoder into the space where the language model s vectors reside. § Stage 2: – Fine tuning End to End: Fine tuning both the projection matrix and the language model on specific tasks like Visual Chat and Science QA allows the system to not just generate a description of the image, but also to engage in complex tasks like answering questions about the image or providing explanations.
it Works: – Image feature vector x from the visual encoder and a text feature vector y from the language model – The projection matrix W is trained to minimize the distance between Wx and y for corresponding pairs of image and text in the dataset. § Training Process: – Initialize W : the matrix W could be initialized randomly – Compute Wx : For each image text pair, transform the image feature x using W. – Loss Calculation: A loss function, such as cosine similarity or mean squared error, measures the distance between Wx and y. – Optimization: Backpropagation and optimization techniques like SGD or Adam are used to update the elements of W to minimize this loss. – Not a Neural Network: The projection matrix W is not a neural network. While neural networks might have activation functions, multiple layers, etc., W is just a matrix that performs a linear transformation. – Not PCA: While Principal Component Analysis PCA also involves linear transformation it is unsupervised. The training of W is supervised and aims to align the feature spaces of the visual encoder and language model based on paired image text data.
generation for a story § Creating a Multi Modal model which can directly create a stories and images from given input – Separate multi modal will help for scale in terms of reduction number of physical GPUs currently needed for each model
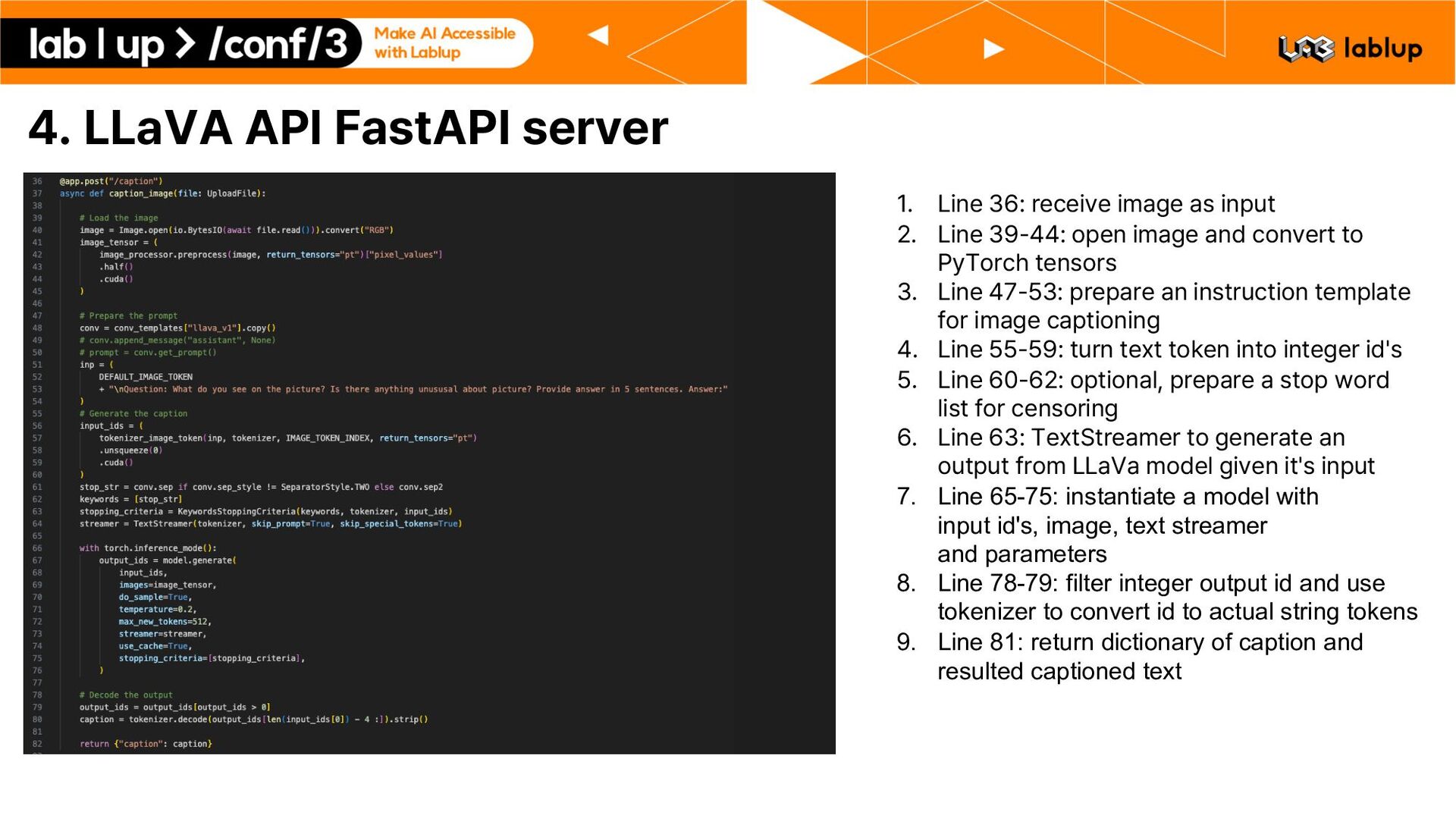
as input 2. Line 39 44: open image and convert to PyTorch tensors 3. Line 47 53: prepare an instruction template for image captioning 4. Line 55 59: turn text token into integer id s 5. Line 60 62: optional, prepare a stop word list for censoring 6. Line 63: TextStreamer to generate an output from LLaVa model given it s input 7. Line 65-75: instantiate a model with input id's, image, text streamer and parameters 8. Line 78-79: filter integer output id and use tokenizer to convert id to actual string tokens 9. Line 81: return dictionary of caption and resulted captioned text
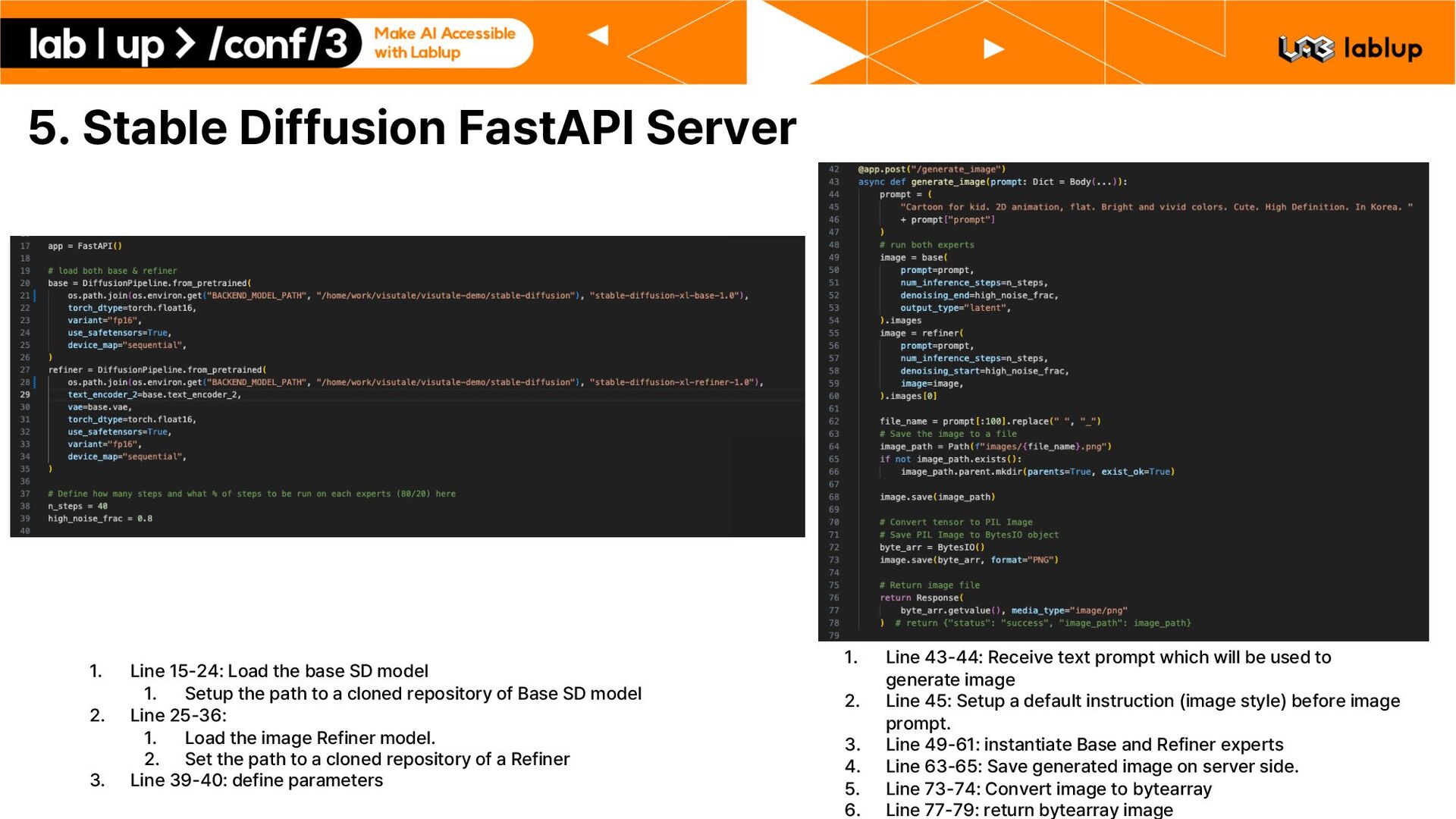
the base SD model 1. Setup the path to a cloned repository of Base SD model 2. Line 25 36: 1. Load the image Refiner model. 2. Set the path to a cloned repository of a Refiner 3. Line 39 40: define parameters 1. Line 43 44: Receive text prompt which will be used to generate image 2. Line 45: Setup a default instruction image style before image prompt. 3. Line 49 61: instantiate Base and Refiner experts 4. Line 63 65: Save generated image on server side. 5. Line 73 74: Convert image to bytearray 6. Line 77 79: return bytearray image
various frameworks to make an interface to facilitate image upload and display § JavaScript frameworks such as React JS § Python frameworks Gradio Streamlit § In addition, the role of Web Server is to manage data transfer between different api endpoints in sequence.
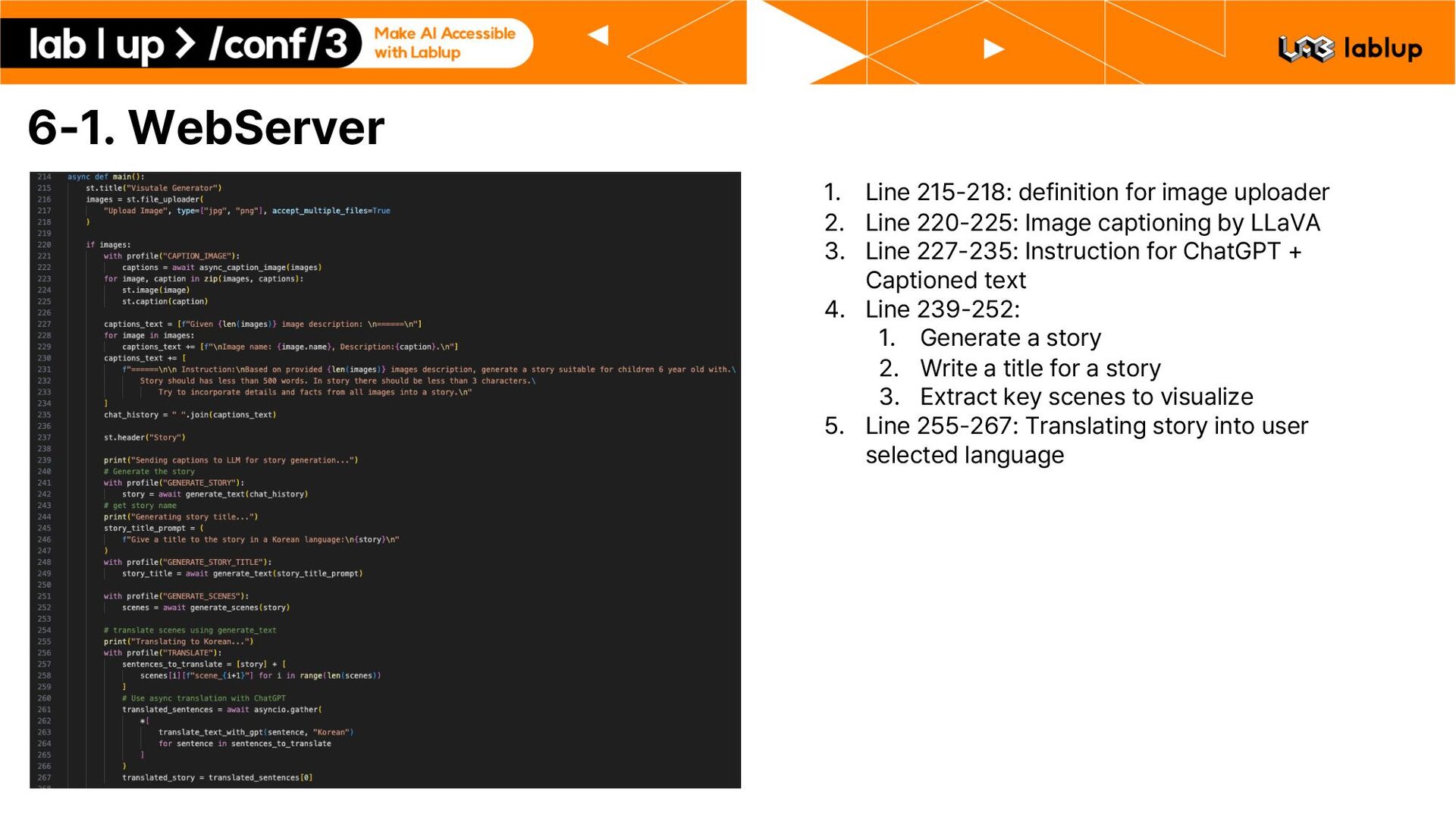
uploader 2. Line 220 225: Image captioning by LLaVA 3. Line 227 235: Instruction for ChatGPT Captioned text 4. Line 239 252: 1. Generate a story 2. Write a title for a story 3. Extract key scenes to visualize 5. Line 255 267: Translating story into user selected language
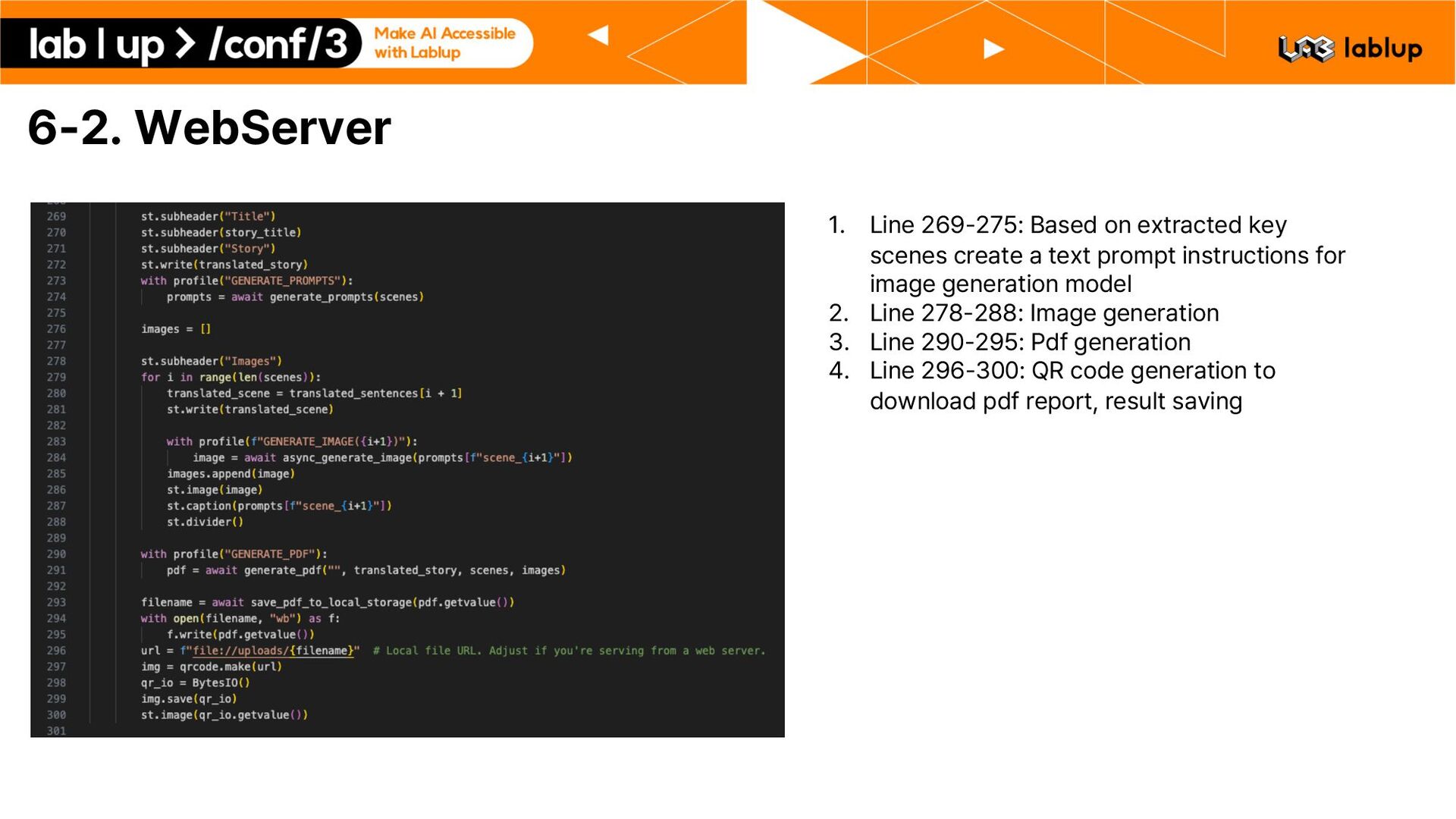
key scenes create a text prompt instructions for image generation model 2. Line 278 288: Image generation 3. Line 290 295: Pdf generation 4. Line 296 300: QR code generation to download pdf report, result saving
used in VisuTale § Described the feature alignment in LLaVA § Talked about Backend.AI role and its advantages § Mentioned of possible future of VisuTale service § Had session about how to setup the models in B.AI Cloud
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}