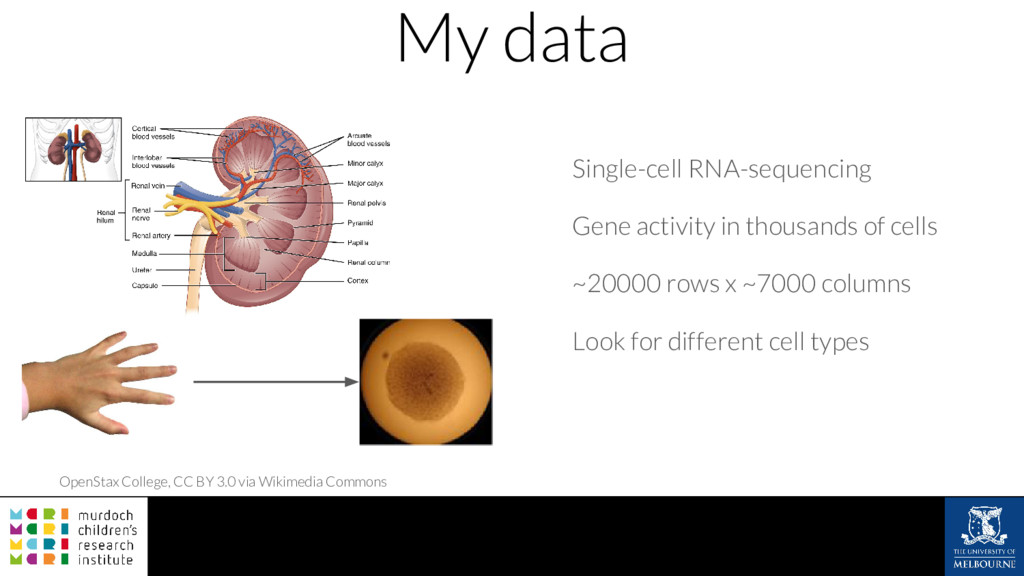
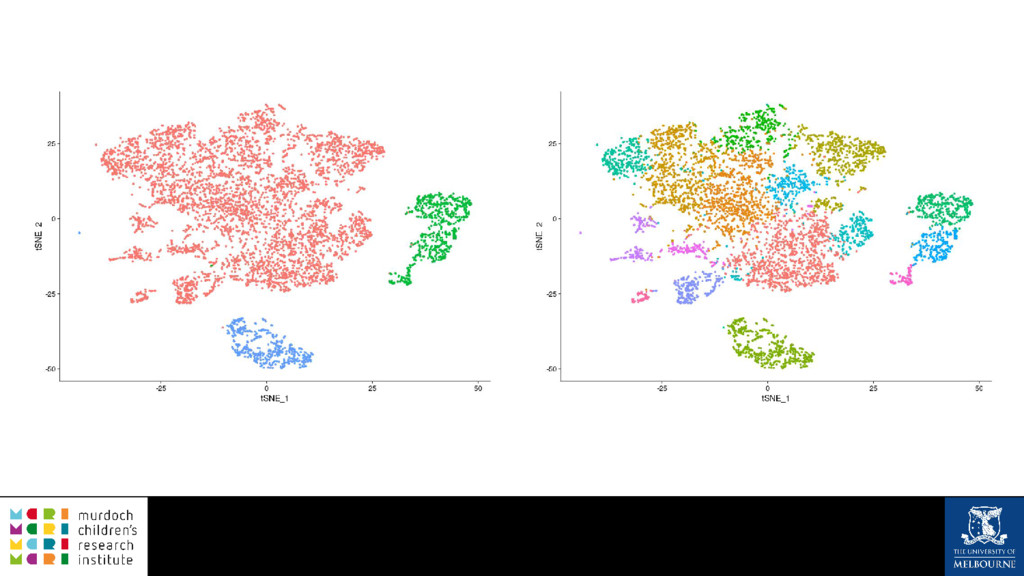
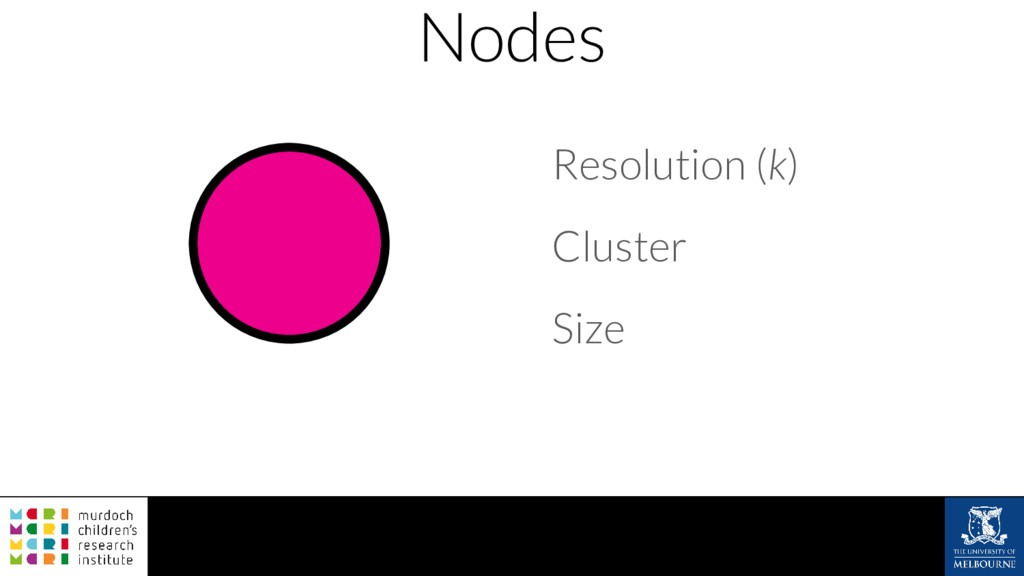
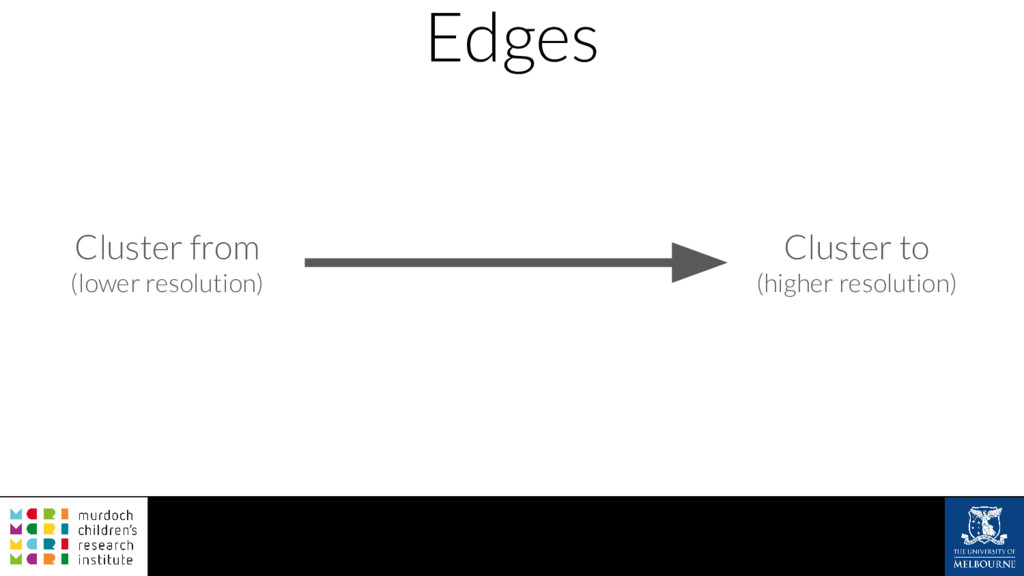
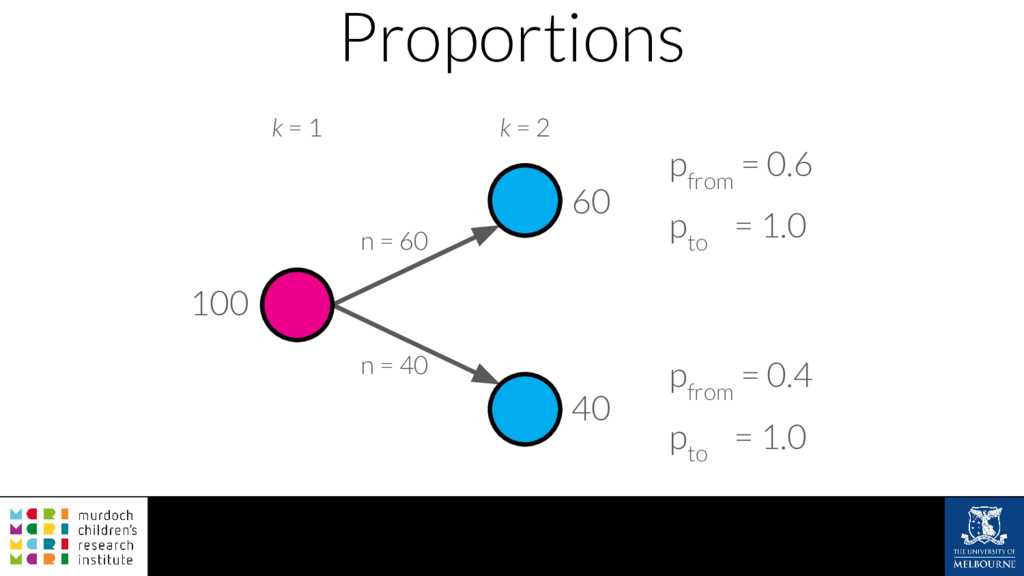
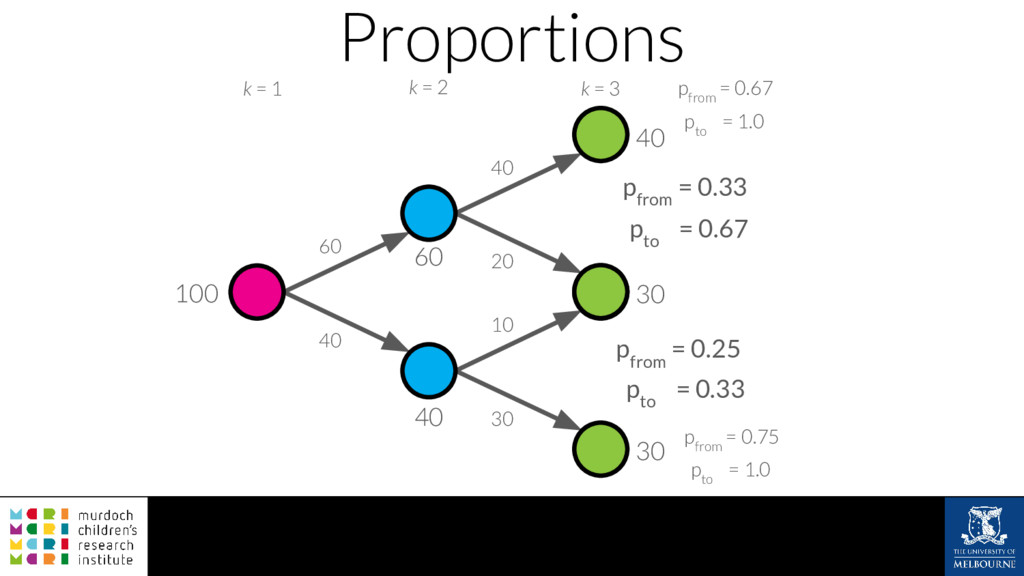
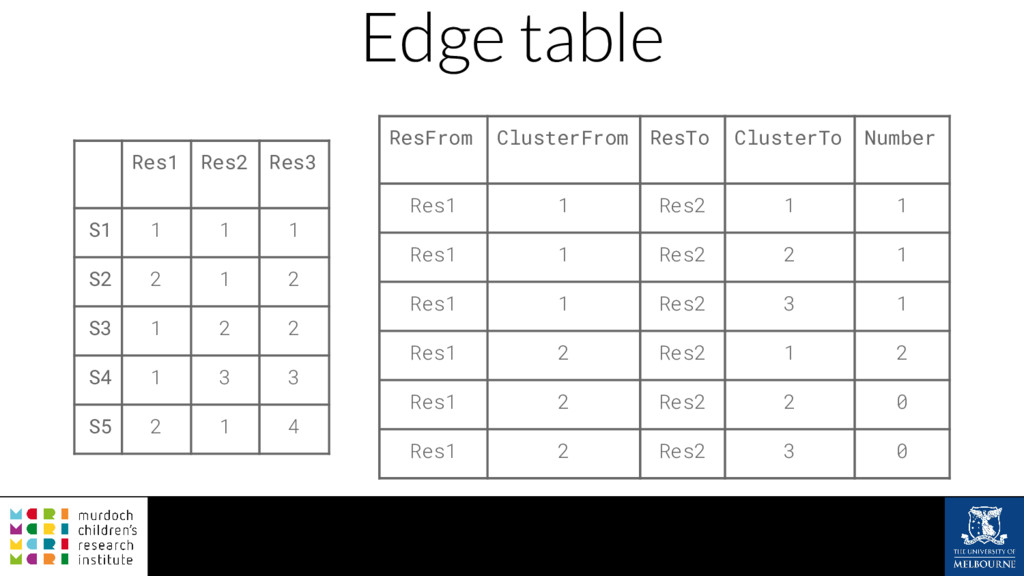
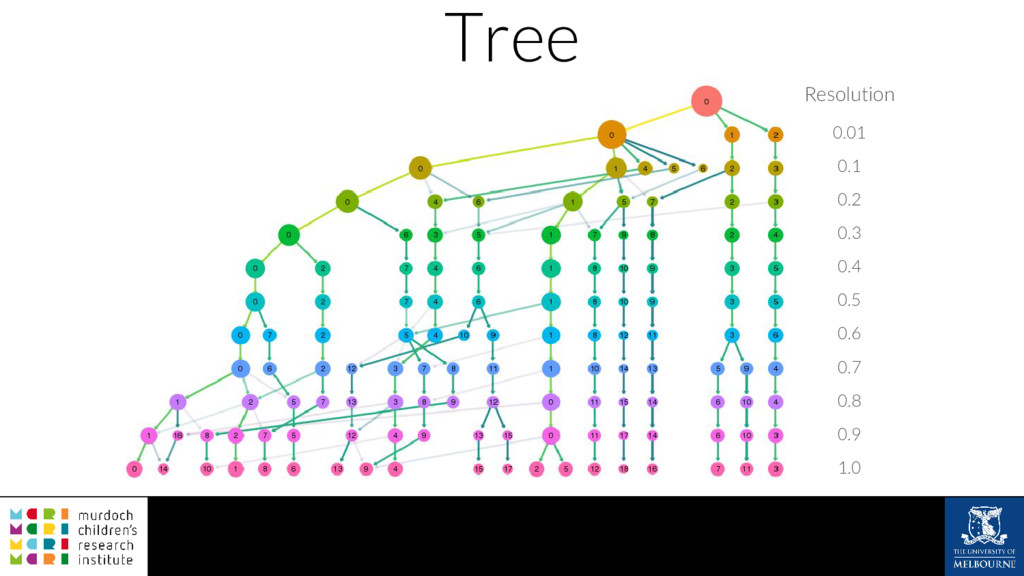
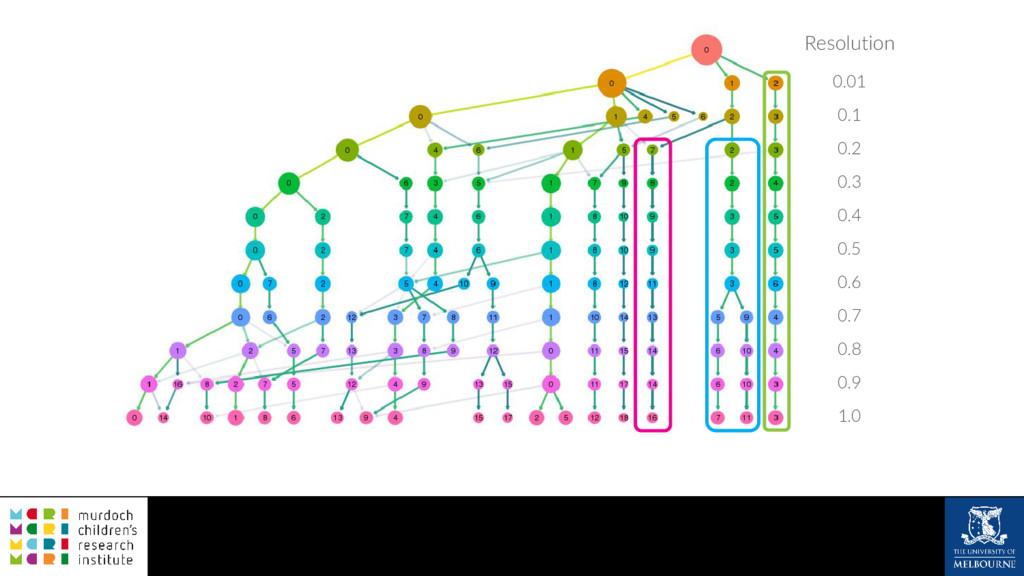
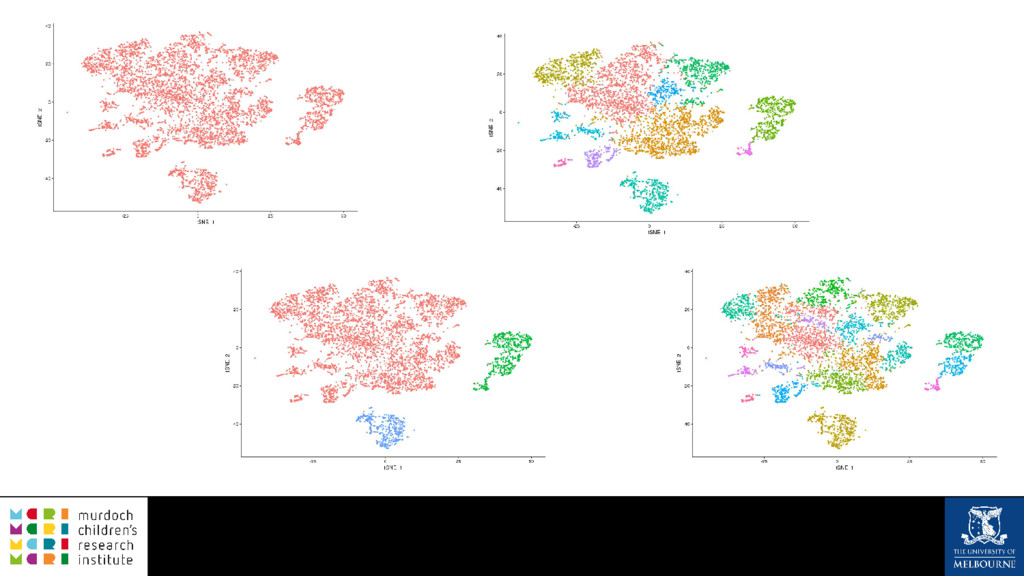
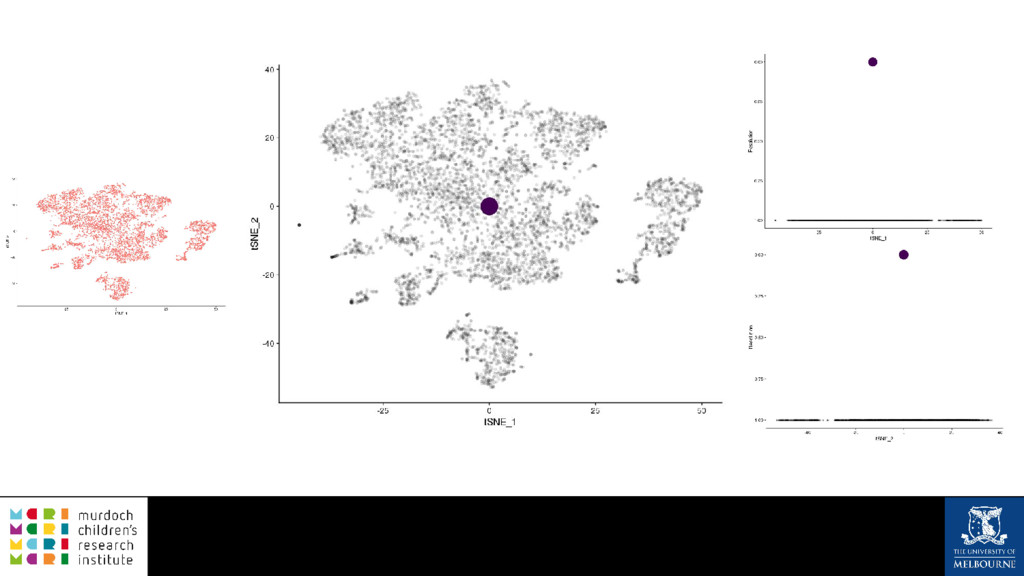
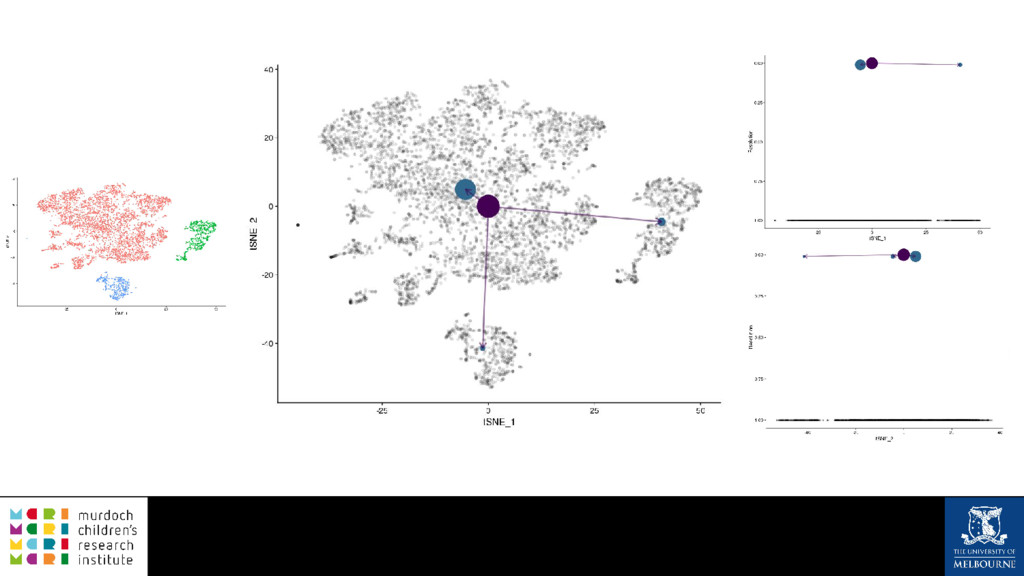
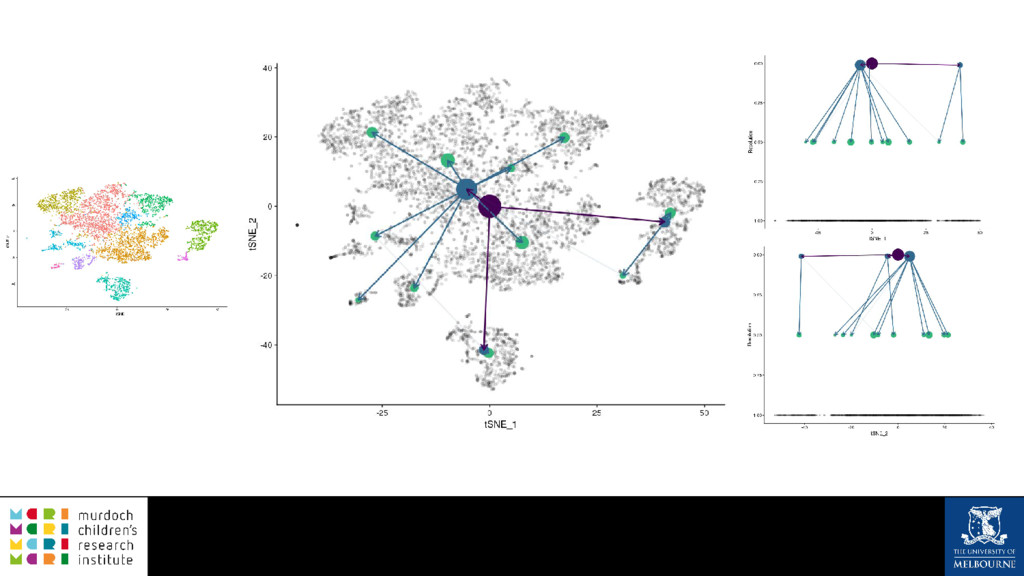
A common task in many fields is to group objects or samples based on their characteristics such that objects in one group are more similar to each other than to objects in other groups. This unsupervised process is known as clustering. Many clustering algorithms exist but all of them require some sort of user input to decide how many groups to produce. For example k-means clustering requires a value for k, the number of clusters, and graph-based clustering methods can include a resolution parameter. How do we know what the correct number of clusters is and what are the relationships between clusters at different resolutions? I will show how to construct a clustering tree to help answer these questions. While I will use a single-cell RNA sequencing dataset as an example this approach could be used for any discipline or clustering method. A clustering tree combines information from multiple clusterings with different resolutions and shows the relationships between them. This visualisation can be used to see which clusters are distinct, where new clusters come from and how many samples change clusters as the number of clusters increases. Building a clustering tree provides an alternative way of looking at clusterings, giving extra insight into the clustering process and helping to determine the correct number of clusters to use in further analysis.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}