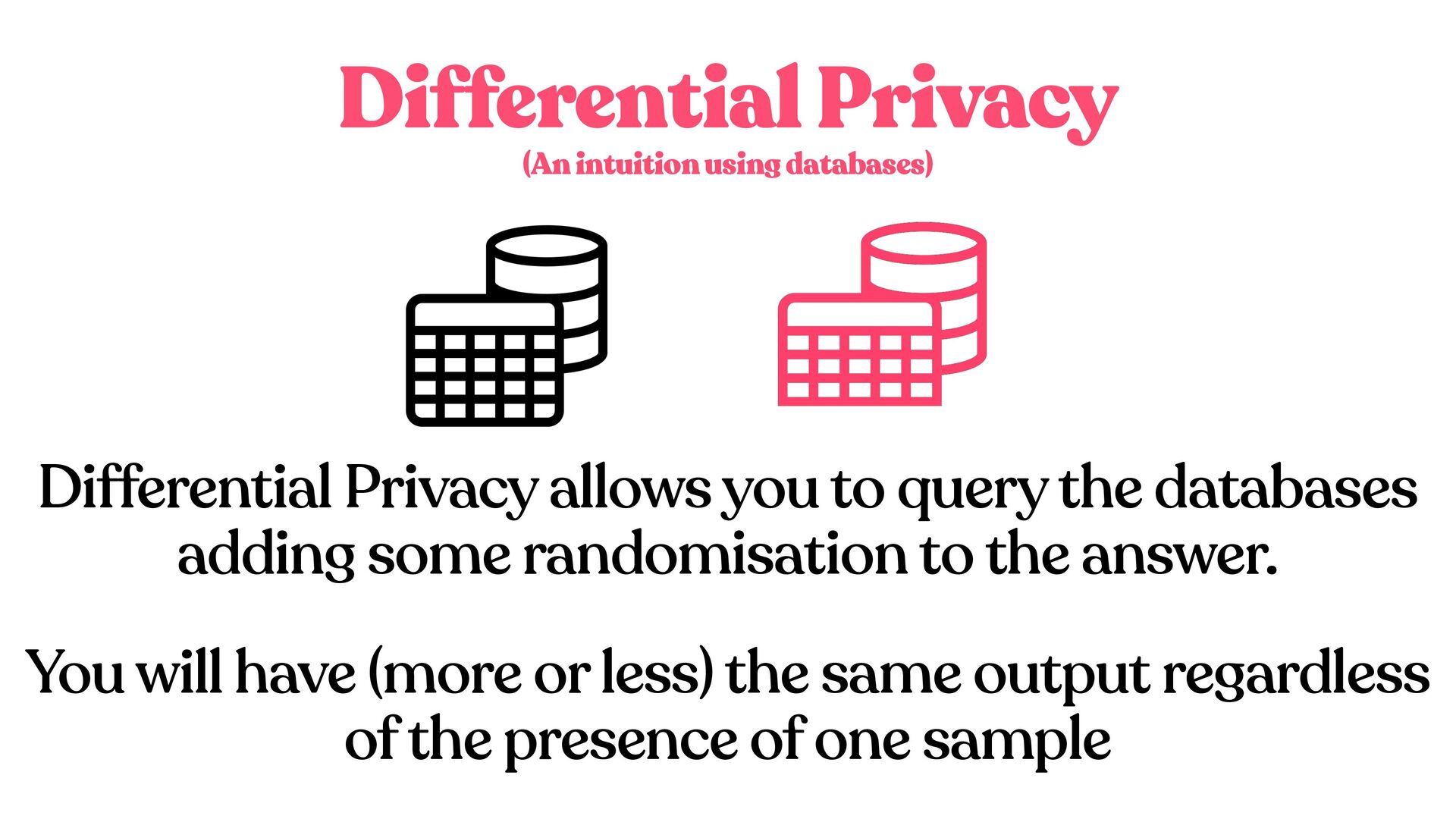
adding some randomisation to the answer. (An intuition using databases) You will have (more or less) the same output regardless of the presence of one sample
tells us how much these two probabilities are similar eϵ is called “privacy budget” and represents an upper bound on how much we can leak information ϵ How to interpret the ϵ Given two databases which differ in only one instance:
≤ P[A( ) = O] +δ eϵ The parameter quantifies the probability that something goes wrong. The algorithm will be differentially private with probability 1 -δ δ Given two databases which differ in only one instance:
sample x_i in the batch: g_t(x_i) = compute_gradient(M, x_i) g_t = average of gradients M = M - lr * g_t Return M def sgd(): for each batch L_t: for each sample x_i: g_t(x_i) = compute_gradient(M, x_i) g_t = average of gradients M = M - lr * g_t Return M
sample x_i: g_t(x_i) = compute_gradient(M, x_i) g_t(x_i) = clip_gradient() g_t = average of clipped gradients + Noise M = M - lr * g_t Return M def sgd(): for each batch L_t: for each sample x_i in the batch: g_t(x_i) = compute_gradient(M, x_i) g_t = average of gradients M = M - lr * g_t Return M
sample x_i: g_t(x_i) = compute_gradient(M, x_i) g_t(x_i) = clip_gradient(C) g_t = average of clipped gradients + Noise M = M - lr * g_t Return M def sgd(): for each batch L_t: for each sample x_i in the batch: g_t(x_i) = compute_gradient(M, x_i) g_t = average of gradients M = M - lr * g_t Return M This can be Gaussian Noise 𝒩(0, σ2C2I)
if you carefully choose your privacy parameters model, optimizer, train_loader = privacy_engine.make_private_with_epsilon( module=model, # the model you want to train with DP optimizer=optimizer, data_loader=train_loader, epochs=EPOCHS, target_epsilon=EPSILON, # privacy budget target_delta=DELTA, max_grad_norm=MAX_GRAD_NORM, # clipping value )
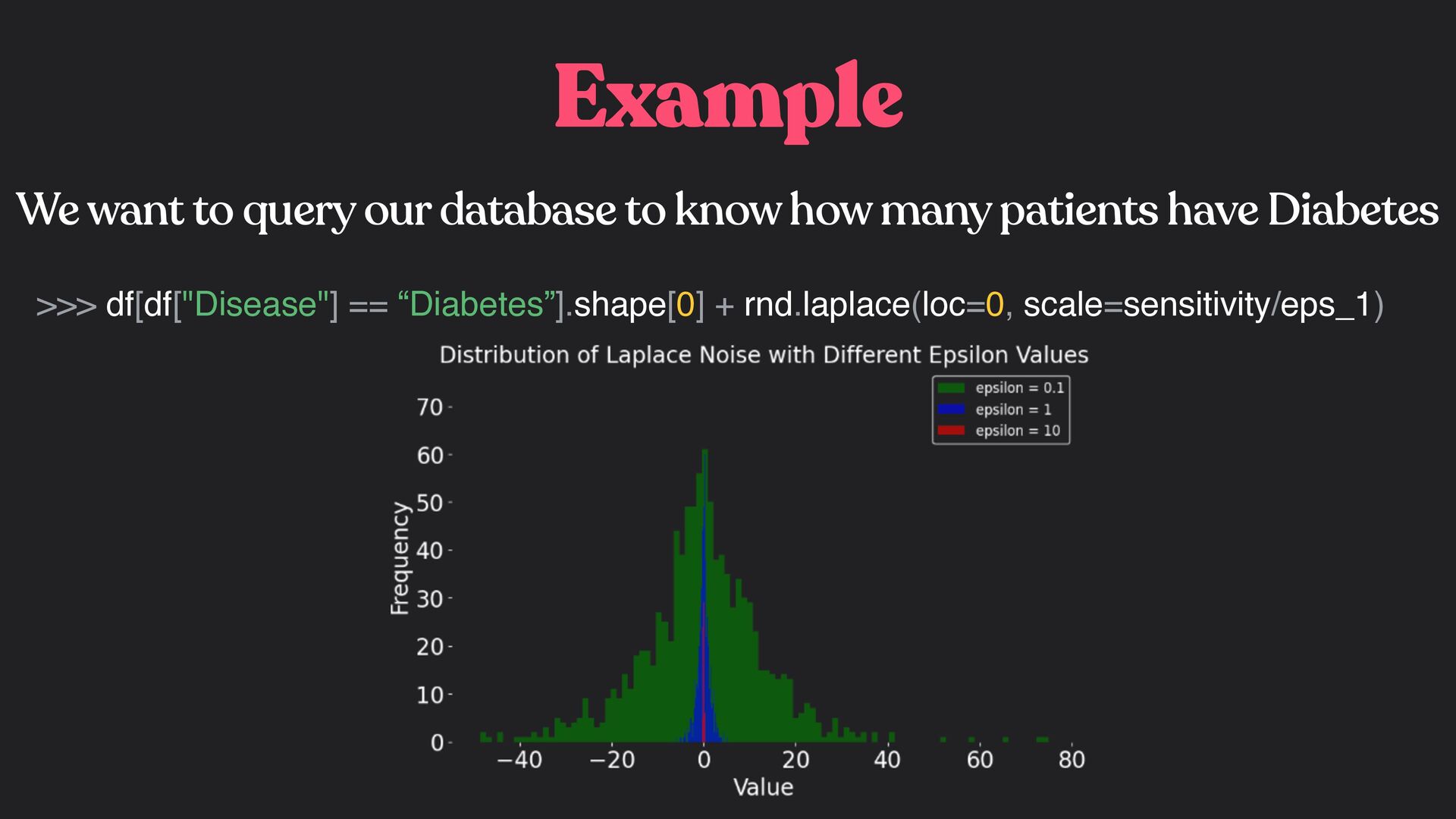
a low we will need to introduce a lot of noise during the training Choosing the is a tradeoff between the utility of the model and the privacy we want to guarantee ϵ ϵ
a low we will need to introduce a lot of noise during the training This will degrade the model performances! Choosing the is a tradeoff between the utility of the model and the privacy we want to guarantee ϵ ϵ
https:// bair.berkeley.edu/blog/2019/08/13/memorization/ 2) Scalable Extraction of Training Data from (Production) Language Models https://arxiv.org/pdf/2311.17035 3) Membership Inference Attacks against Machine Learning Models https:// arxiv.org/abs/1610.05820 4) A friendly, non-technical introduction to differential privacy https:// desfontain.es/blog/friendly-intro-to-differential-privacy.html 5) Deep Learning with Differential Privacy https://arxiv.org/abs/1607.00133 6) Opacus https://opacus.ai/ 7) Tensorflow Privacy https://github.com/tensorflow/privacy
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![P[A( ) = O] ≤ P[A( ) = O] eϵ](https://files.speakerdeck.com/presentations/46b782eb5b1b4f77ad857b7ac8f545aa/slide_22.jpg){kind=link}
![Differential Privacy (A more relaxed definition) P[A( ) = O]](https://files.speakerdeck.com/presentations/46b782eb5b1b4f77ad857b7ac8f545aa/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Differential Privacy P[A( ) = ] ≤ P[A( ) =](https://files.speakerdeck.com/presentations/46b782eb5b1b4f77ad857b7ac8f545aa/slide_35.jpg){kind=link}
![Differential Privacy P[A( ) = ] ≤ P[A( ) =](https://files.speakerdeck.com/presentations/46b782eb5b1b4f77ad857b7ac8f545aa/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}