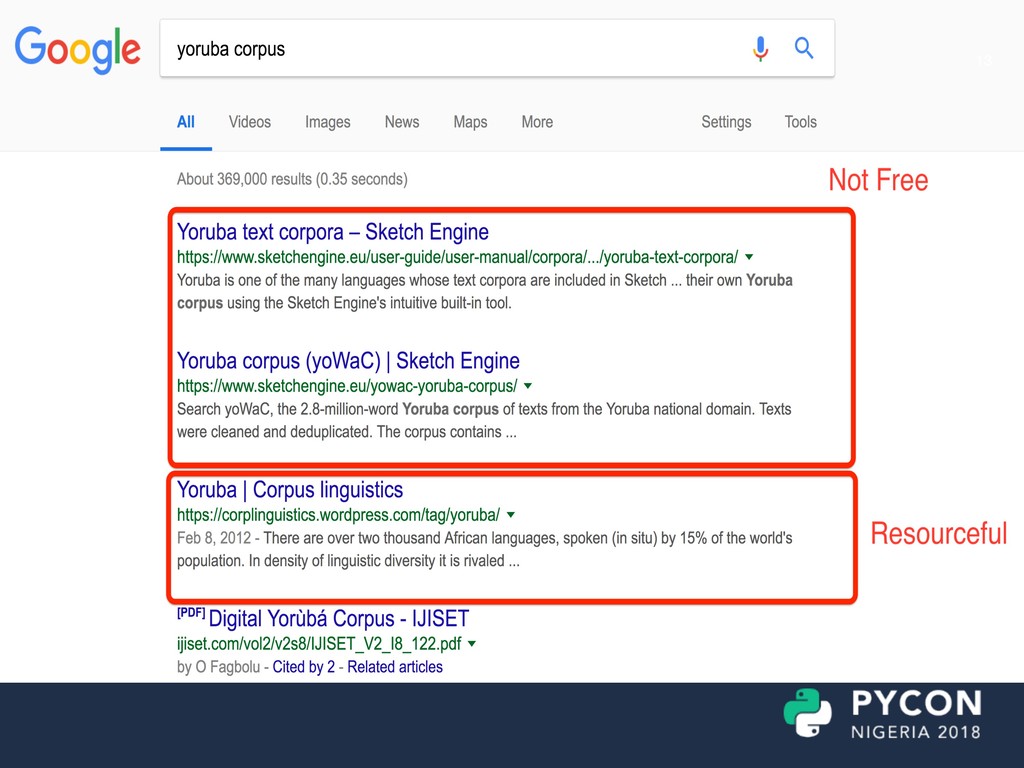
Natural Language Processing : The need for a Yoruba Corpus
Natural language powered platforms have one big problem;Supporting indigenous African languages.This talk analyses some of the problems with these platforms and the work being done to introduce support for more African languages especially Yoruba
Contributor Machine Learning Engineer and Aspiring Machine Learning Researcher Huge fan of Saheed Osupa Advocate for Open Machine Learning www.openml.org
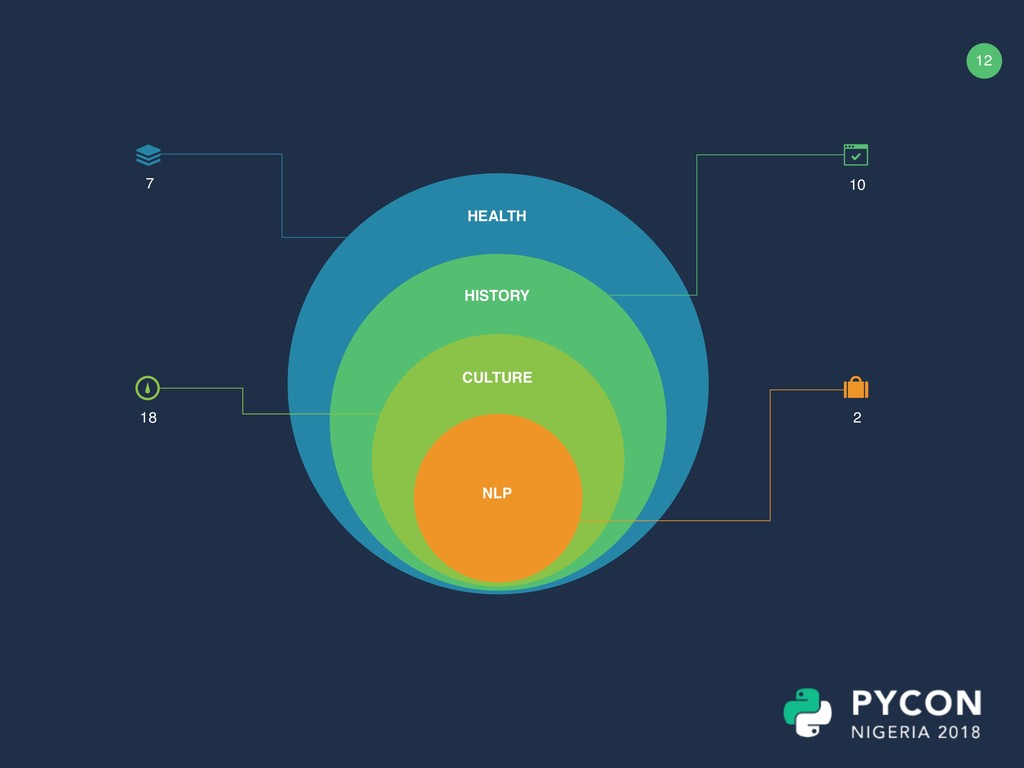
usage of Yo r u b a i n d i f f e r e n t contexts. Ife, Ibadan and Ede Manual translations of orikis of my home town (Ede), Ibadan and Ijebu Ode Yoruba names Scrapped Yoruba names from Kola Tubosun’s project. Saheed Osupa, Pasuma Collaborated with kiosk disc sellers to work on getting some songs by SO and Pasuma written and manually translated to English. Bible Oriki Yoruba Names Fuji Music KJV A combination of manually translated and scrapped b i b l e v e r s e s o f t h e Pentateuch chapters. ASP Corpus Lexicology A database containing lexical and morphological usage of the Yoruba language LDC Lexical Database What We Have Done
advise and generally go more into academia for a solution. 1 Do more for open source. Try to bring more interested developers into the work and generally be more open. 2 Look more into existing (new) solutions. 3 More language support 4
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}