10⼈おきに選ぶなど⼀定の決まりをもって選ぶ n 層化抽出 n ⼤きな⺟集団を反映した、⼩さな⺟集団を作成する n たとえば、男⼥⽐1:1、65歳以上の⼈は20%など、各々のプロダクトのユーザ層に 合わせたり。 n 便宜的抽出 n 募集に対して来たユーザを対象とする⽅法。 n バイアスがかかる可能性を把握しておくことが重要
平均値、標準偏差、信頼区間が表現することができる n 同じユーザの平均値の変化においての有意差を調べるにはt検定(対応のある標本同⼠) n 異なるユーザでの⽐較にはt検定(独⽴標本同⼠) n 3セット以上のデータでの有意差⽐較には分散分析(ANOVA)を⽤いることができる n ⽐データ(⽐例尺度) n 間隔データとほぼ同じだけれど、0がある。タスク時間、⾝⻑、体重など n 間隔データに適応できる統計と同じものが使⽤できる データのタイプ
2値による成功率(成功 or 失敗) 27 タスク成功率 n 3/4で80%というより、16/20で80%としたほうが⾃⾝を持って⾔える n 調整ワルド法を⽤いて信頼区間を計算するのがベスト n https://measuringu.com/wald/ で計算してくれる 2値による成功率の信頼区間の計測
バタフライ投票⽤紙 n エラーデータの収集 n 正しいアクションは何かを明確にしておくと良い n エラーの数を単純に記録する、0=エラーなし、1=エラー1回 n エラーの頻度をタスクごとに求めると、どのタスクがエラーを起こしやすいかわかる n エラーは重複にカウントできないようする(⾃動で取得する際に注意) 33 エラー
n エラーを招くもの n 気づくべきことに気付かない状況 n 正しくないことを正しいと思いこんでる状況 n タスクが完了していないのに完了したと思いこんでいる状況 n 正しくないアクションを取ってしまう状況 n コンテンツのどこかを誤解してしまう状況 n ナビゲーションが理解できない状況 ユーザビリティの問題とは何か
n 中:タスクの失敗に寄与するが、直接的な原因とはならない問題。ユーザーは迂回策を みつけて⽬標に到達できることが多い。このタイプの問題は、有効性に影響し、効率を 下げる可能性がある。 n ⾼:タスクの失敗を直接的に起こす問題。この問題に直⾯しながら、主なタスクを完了 する⽅法は、基本的に存在しない。このタイプの問題は、有効性、効率、満⾜度に⼤き な影響を及ぼす。 n 深刻度についての定義に誰もが賛同しているものはまだ無い。
31% の問題が観測されると発表 n 10つ問題があったとき、1⼈30%の発⾒率だと、 5⼈で 10(1-((1-0.3)^5)) = 8.3193つの問題が発⾒できる(83%) n ⼀概に上記のとおりではないと⾔われている研究もある n 本書では ユーザグループ(年齢層、男⼥等)ごとに5⼈程度が良いといっている
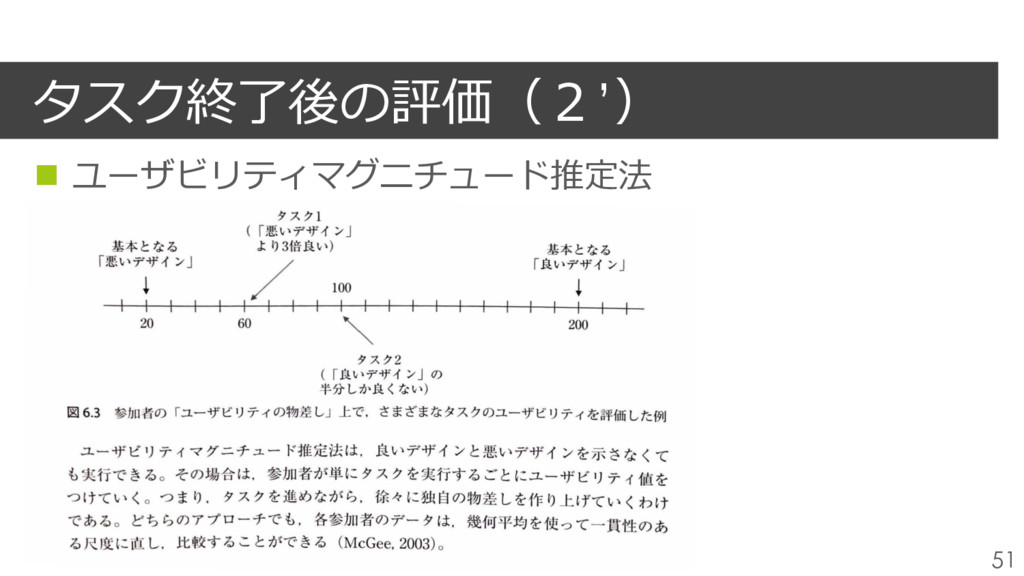
光源をみせて、明るさといった属性に値をつける、 次に新しい光源をみせて最初に⾒た光源との⽐較で値をつけてもらう n 重要なのは、度合いを数値の⽐率でつけるということ n McGeeは良いWebサイトと悪いWebサイトを⾒せて値をつけ、 テストしているWebサイトがどの程度か値をつけてもらう n 実際は良い例/悪い例がなくてもいい、 ユーザがタスクを進めながらユーザ⾃⾝の物差しを作っていければよい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}