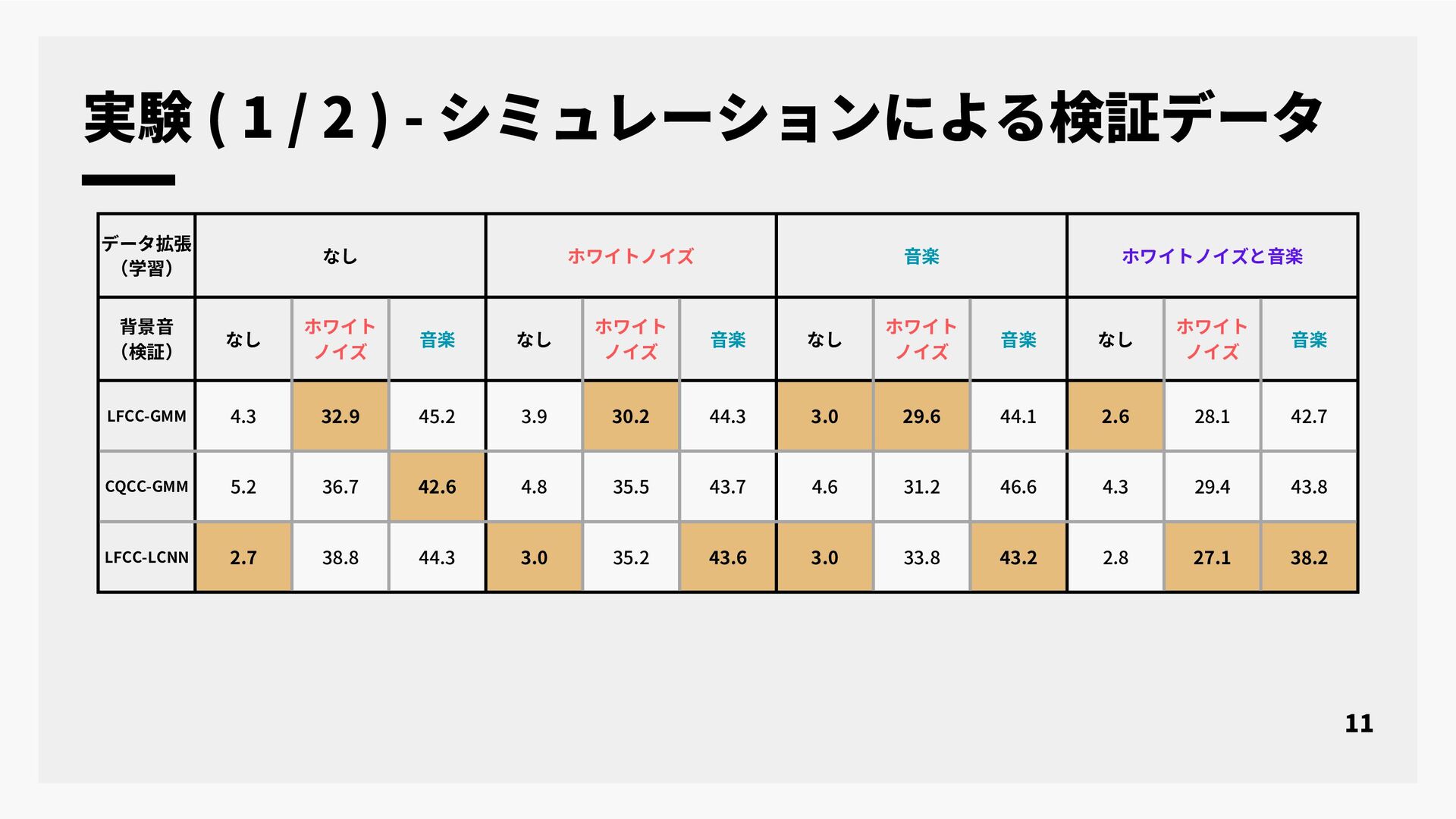
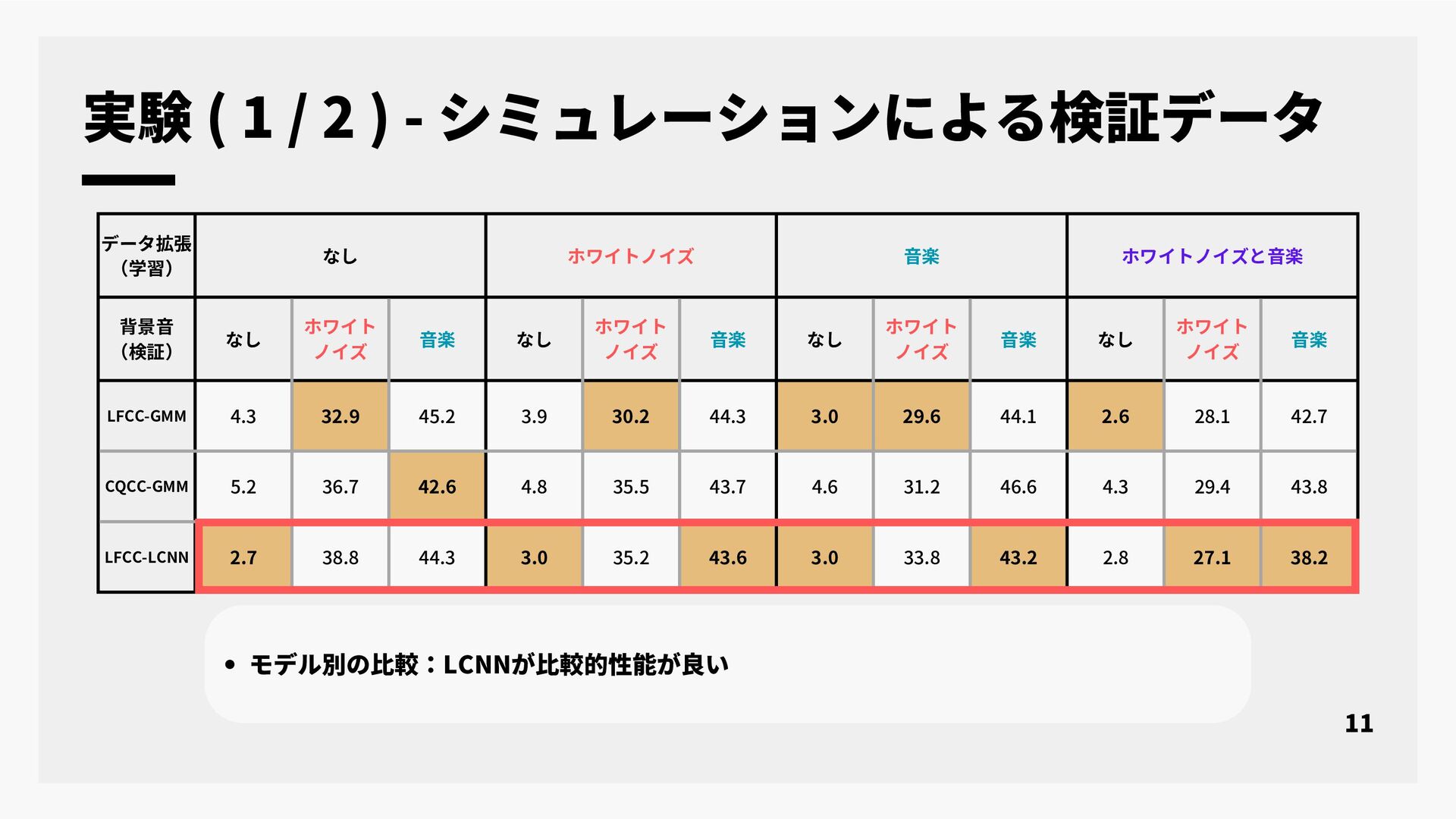
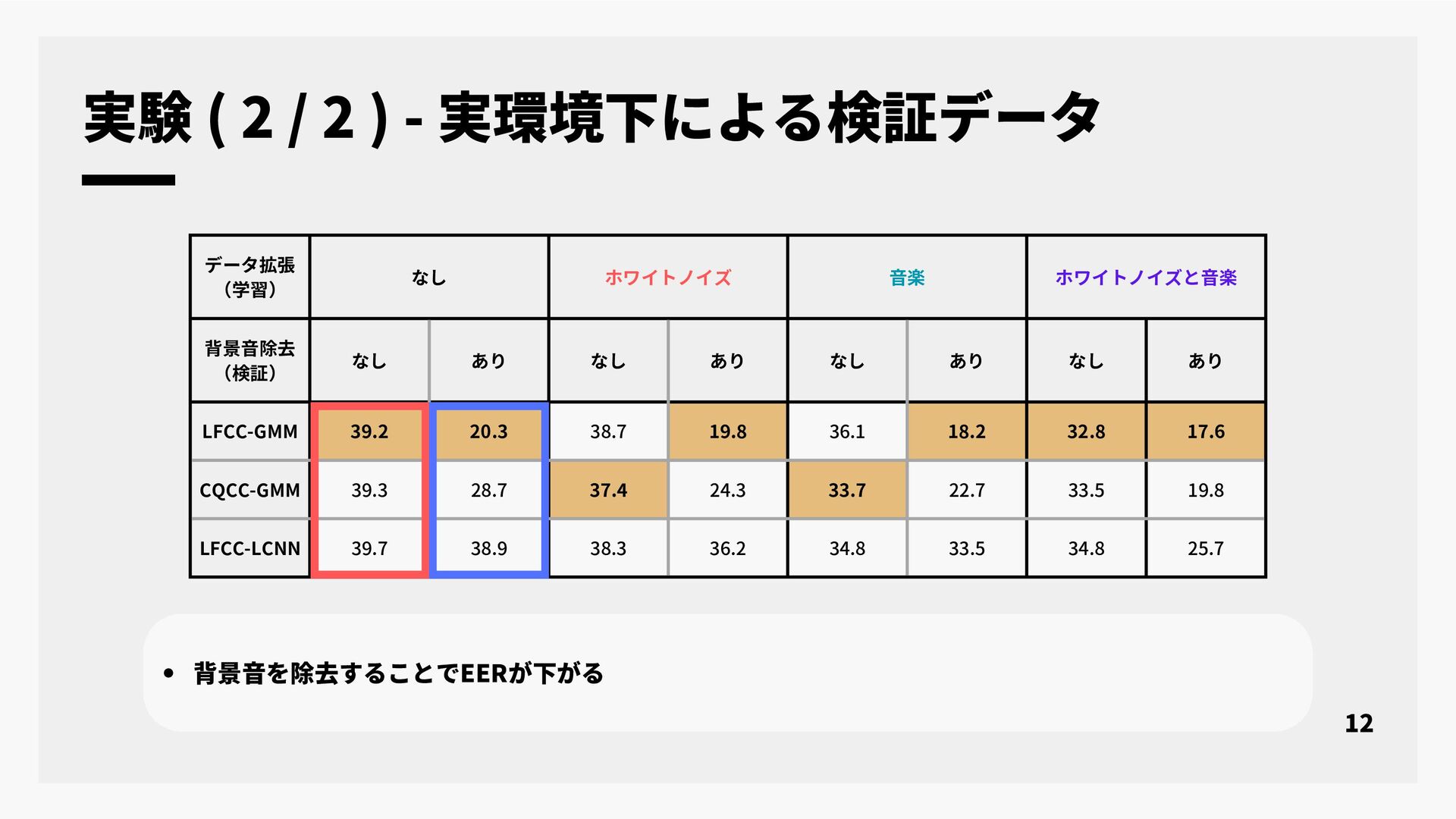
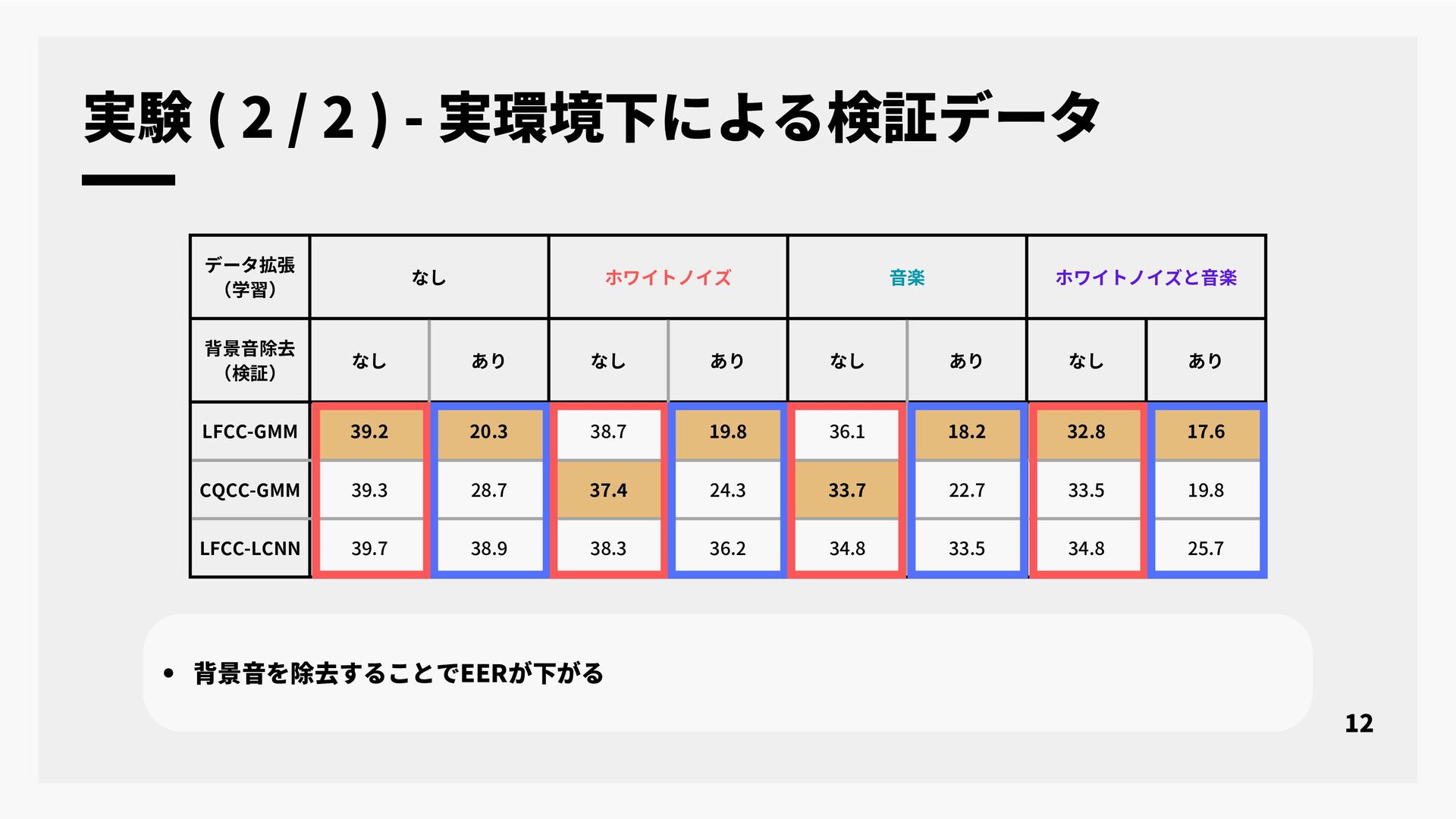
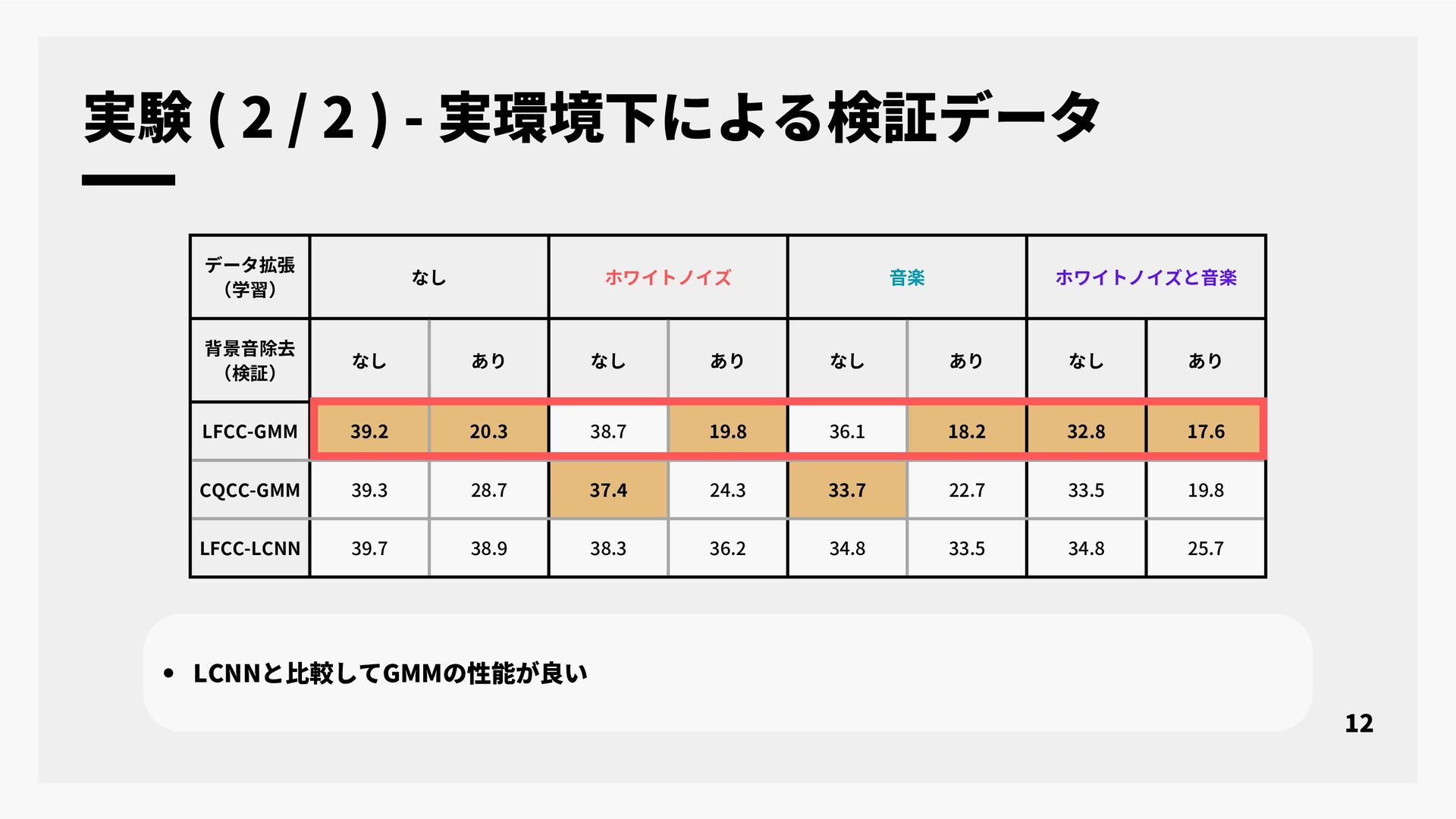
本研究では, なりすまし音声検出として提案されている合成音検出を実環境で収録された音声データのクレンジング技術に応用することについて検討する. 近年, 大規模な音声コーパスを構築する手段として, インターネット上の様々な音声データを自動収集する手段が広く用いられている. インターネット上の音声データは背景雑音や音楽など様々な音が重畳されており, 単純な音声区間検出などでは目的の音声コーパスを作成することは難しい. そのため, 収集目的に対して適切な動画だけを選択して音声コーパスを構築するための様々なデータクレンジング技術が適用されている. 話者照合のための音声コーパス構築に必要なデータクレンジング技術として, 単一話者による実発声であることの判定がある. しかし, 従来法では合成音声と単一話者において分類精度が不十分であった. そこで本研究では, なりすまし音声検出を合成音声と実発話の分類を行うデータクレンジング技術の一つとして応用することを検討した. 実験では, シミュレーションによる合成音声と実発話の音声データ及び, 実環境下で収集された音声データの二つを評価データとして用い合成音検出の評価を行った. 実験結果より, なりすまし音声検出のデータクレンジング技術としての性能と今後の課題について報告する.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}