Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
その処理、本当に遅いですか? 〜無駄を削る達人になろう〜
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Tech Leverages
PRO
June 30, 2023
Technology
5.9k
0
Share
その処理、本当に遅いですか? 〜無駄を削る達人になろう〜
その処理、本当に遅いですか? 〜無駄を削る達人になろう〜
Tech Leverages
PRO
June 30, 2023
More Decks by Tech Leverages
See All by Tech Leverages
Engineering ManagerがAI時代に この先生きのこるには?
leveragestech
PRO
1
37
最新技術を"今は選ばない"という技術選定
leveragestech
PRO
0
420
Tableauを活かすためにTableauに制約を設けた話
leveragestech
PRO
0
57
営業支援システムと歩んだ7年半の変遷
leveragestech
PRO
0
110
DMBOKを使ってレバレジーズのデータマネジメントを評価した
leveragestech
PRO
0
750
Google ADKのSub Agentを Agentic Workflowに移行し、 遷移成功率を改善した話
leveragestech
PRO
0
9
ハッカソンから社内プロダクトへ AIエージェント ko☆shi 開発で学んだ4つの重要要素
leveragestech
PRO
0
3.5k
2025年のデザインシステムとAI 活用を振り返る
leveragestech
PRO
0
4.1k
ディメンショナルモデリングを採用してない組織がモデリング本を通じて得られたこと
leveragestech
PRO
0
3.6k
Other Decks in Technology
See All in Technology
Strands Agents超入門
kintotechdev
1
100
実践 TanStack Start ― 新規プロダクトを開発して確立した、サーバーとクライアント境界の設計パターン / Practical TanStack Start Server-Client Boundary Patterns
kaminashi
2
320
Amazon Bedrock 経由の Claude Cowork を試してみよう・MCP にも繋いでみよう
sugimomoto
0
190
Javaで学ぶSOLID原則
negima
1
140
はじめてのAI-DLC
yoshidashingo
2
550
TROCCOで始めるクラウドコストを民主化するためのFinOps
tk3fftk
1
160
Python開発環境にハーネス適用を検討する
yuuka51
1
520
DI コンテナ自動生成ツールを実装してみた / intro-autodi
uhzz
0
870
情シスがMCP環境導入時に打ちのめされる認可の崖
oidfj
0
460
Kaggle未経験社員をメダリストに育てる「AIドラゴン桜」
lycorptech_jp
PRO
0
600
論文紹介:Pixal3D (SIGGRAPH 2026)
tenten0727
0
740
Javaコミュニティをもっと楽しむための9箇条
takasyou
0
140
Featured
See All Featured
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.8k
Visualization
eitanlees
151
17k
The Pragmatic Product Professional
lauravandoore
37
7.3k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
390
Music & Morning Musume
bryan
47
7.2k
How to make the Groovebox
asonas
2
2.2k
Faster Mobile Websites
deanohume
310
31k
What's in a price? How to price your products and services
michaelherold
247
13k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.2k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2k
Chasing Engaging Ingredients in Design
codingconduct
0
200
Code Reviewing Like a Champion
maltzj
528
40k
Transcript
その処理、本当に遅いですか? 〜無駄を削る達人になろう〜 HRテック事業部 桐生 直輝 2023/06/07
自己紹介 桐生直輝 (23歳) • 入社:2023年3月 • 出身:岡山県津山市 • 所属:HRテック事業部 ◦
バックエンド〜インフラ担当 • 趣味:コンピュータいじり、自宅サーバー構築 • 目標は技術力でとことん尖ることです
今回のテーマ 「動作速度」と「高速化」について • 動作速度はシステム品質の重要な柱(のはず・・・) • コード品質の話は出てきません
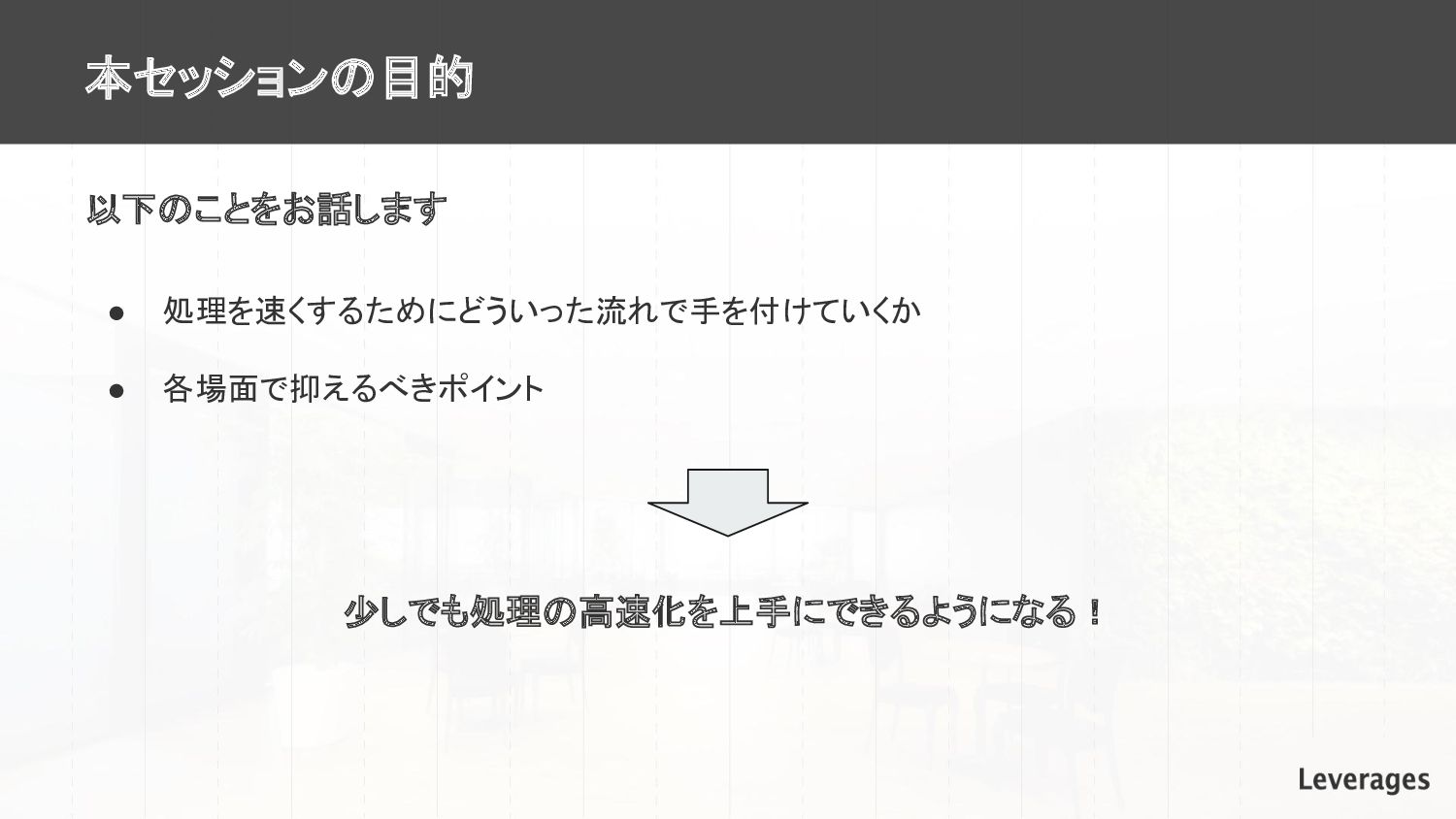
本セッションの目的 以下のことをお話します • 処理を速くするためにどういった流れで手を付けていくか • 各場面で抑えるべきポイント 少しでも処理の高速化を上手にできるようになる!
処理高速化のアプローチ
処理高速化のアプローチ 1. 「無駄」のニオイを感じ取る 2. 処理の遅い原因を特定する(計測) 3. 高速化のための手段を考え、実装する 4. 実装した高速化の効果を測定する
処理高速化のアプローチ 1. 「無駄」のニオイを感じ取る 2. 処理の遅い原因を特定する(計測) 3. 高速化のための手段を考え、実装する 4. 実装した高速化の効果を測定する
「無駄」を感じ取るには 「無駄」のある処理とは? • 遅いからといって、全ての処理を高速化できるわけではない ◦ リソースを完全に使い切っている、本質的に重い処理 ◦ 無駄を多分に含んでいる処理 • 既に高速化の余地がない処理にいくら労力を費やしても意味がない
「無駄」を感じ取るには 「無駄」のあるなしを見分けるには? • 想定される処理時間と比較して見抜く ◦ 実際の処理時間が想定より明らかに長い =無駄を含んでいる可能性が高い • 「これくらいかかりそう」を精度良く予測できるようにする ◦
処理の性質ごとにどれくらいの時間がかかるか、感覚を掴む
「無駄」を感じ取るには 何をするのにどれくらいの時間がかかるか、感覚を掴む • 例えば、現代のCPUがどのくらい高速か知っているでしょうか?
「無駄」を感じ取るには 何をするのにどれくらいの時間がかかるか、感覚を掴む • 例えば、現代のCPUがどのくらい高速か知っているでしょうか? 例:CPU vs ストレージ vs ネットワークアクセス 1秒あたりの処理能力比較
(目安) 3,000,000,000 IPS 1,000,000 IOPS 1,000 RPS 1回のネットワーク通信の完了を待つ間に、 SSDは1000回の読み書きを実行でき、 CPUは300万回の計算を実行できる。 ※並列度=1
「無駄」を感じ取るには 処理の性質ごとに重みが大きく異なることに注意! • 計算処理が中心の場合、相応の時間がかかるのは 何百万回〜何千万回もの計算を要する 処理であるはず ◦ 大規模な文字列・データ処理や、一般的な画像処理など ◦ 業務アプリケーションでそのレベルの計算量を求められることは少ない
• 逆に、ストレージ・ネットワークアクセスが中心の場合、比較的小規模でもそれなりに時間が かかることは全然あり得る
「無駄」を感じ取るには 処理時間を概算してみる • 例:100ユーザーで、各ユーザー1000件程度のデータを集計する(合計・平均など) ◦ トータルの処理件数は 100 * 1000 =
10万件程度 ◦ 単純な集計なら1件あたり数十ステップで処理可能 →実時間では数ミリ秒程度 ◦ DBからのデータの取得も 10万件程度なら最大で数秒程度しかかからないはず • ここで概算した時間(数秒)を大きく上回る場合、無駄が存在することになる
「無駄」を感じ取るには 結論:処理時間の予測精度を上げる! • 「これそんなに遅くある必要ないのでは?」と思えることが大事 • センスを磨くには・・・ ◦ 計算量について学ぶ ◦ より細かい内部の仕組みを学ぶ
処理高速化のアプローチ 1. 「無駄」のニオイを感じ取る 2. 処理の遅い原因を特定する(計測) 3. 高速化のための手段を考え、実装する 4. 実装した高速化の効果を測定する
高速化の第一歩 高速化できそうな処理は見つけた。 次にやるべきことは?
計測
計測せよ 「これが原因で遅い」という証拠を手に入れる • 何が原因で遅くなっているかは、計測してみなければわからない • さっきのステップでわかったのは「本来は遅いはずがない」ということだけ
ロブ・パイクのプログラミング5カ条 ロバート・C・パイク 引用元: https://www.flickr.com/photos/shockeyk/4833152910/in/photostream/ 「Goの父」と呼ばれる人物 ベル研究所でUNIX開発に携わり、 Cプログラミングに精通
ロブ・パイクのプログラミング5カ条 ルール1 プログラムがどこで時間を消費することになるか知ることはできない。ボトルネックは驚くべき箇所 で起こるものである。したがって、どこがボトルネックなのかをはっきりさせるまでは、推測を行った り、スピードハックをしてはならない。 引用元: http://www.lysator.liu.se/c/pikestyle.html ルール2 計測すべし。計測するまでは速度のための調整をしてはならない。コードの一部が残りを圧倒し ないのであれば、なおさらである。
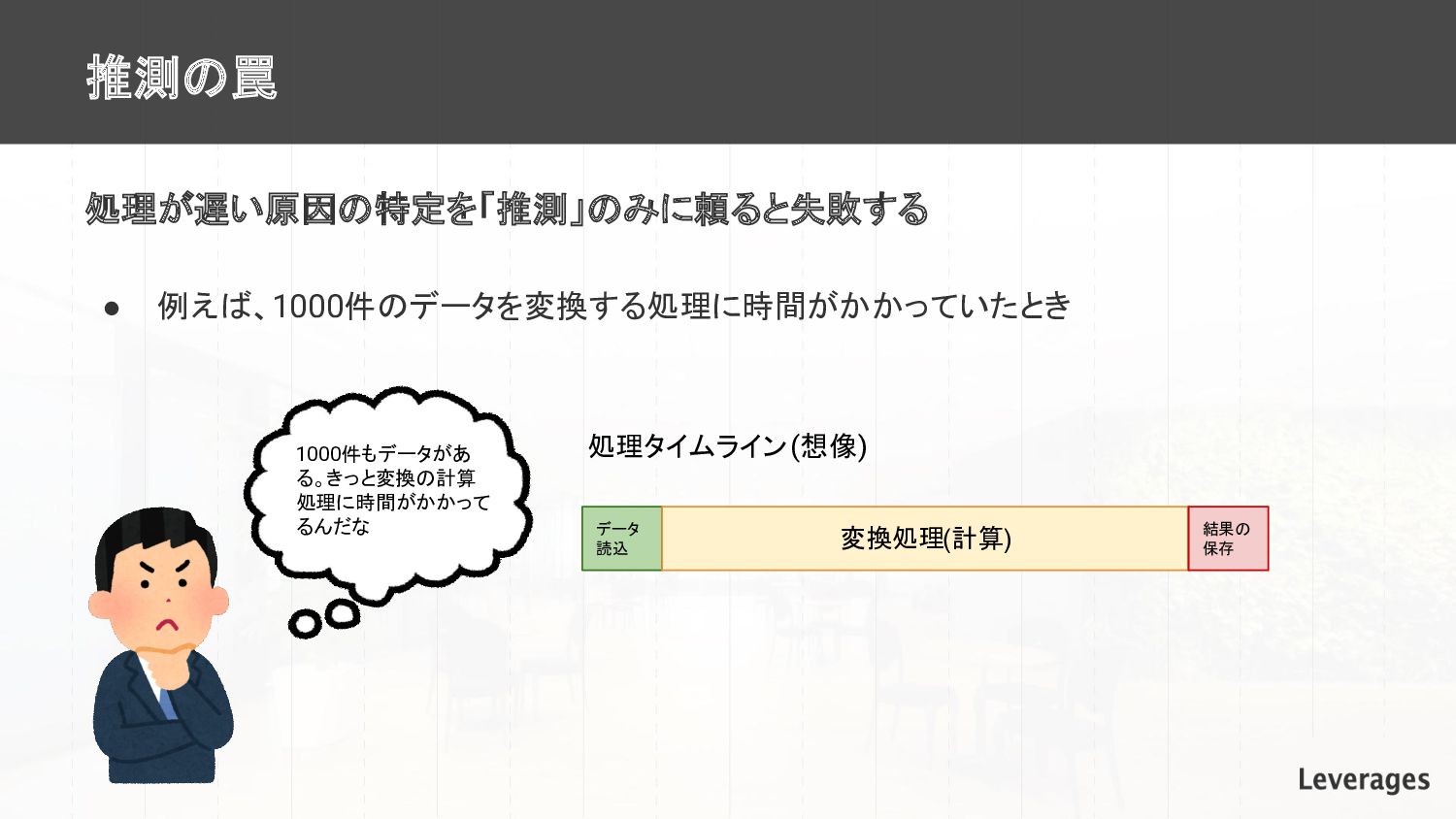
推測の罠 処理が遅い原因の特定を「推測」のみに頼ると失敗する • 例えば、1000件のデータを変換する処理に時間がかかっていたとき 1000件もデータがあ る。きっと変換の計算 処理に時間がかかって るんだな 処理タイムライン(想像) データ
読込 変換処理(計算) 結果の 保存
推測の罠 処理が遅い原因の特定を「推測」のみに頼ると失敗する • 実際は・・・ 処理タイムライン(実際) データ 読込 変換 処理 結果の保存
↑ここを改善しないと意味がない!
推測の罠 でもこれ、あるあるです • 真面目に計測すると面倒くさいので、つい推測で済ませてしまいがち • 結果、時間のかかってないところを高速化 →ほとんど成果が得られなかったりとか
計測の手法 代表的なもの • 経過時間を計測し、ログ出力 • プロファイラの活用
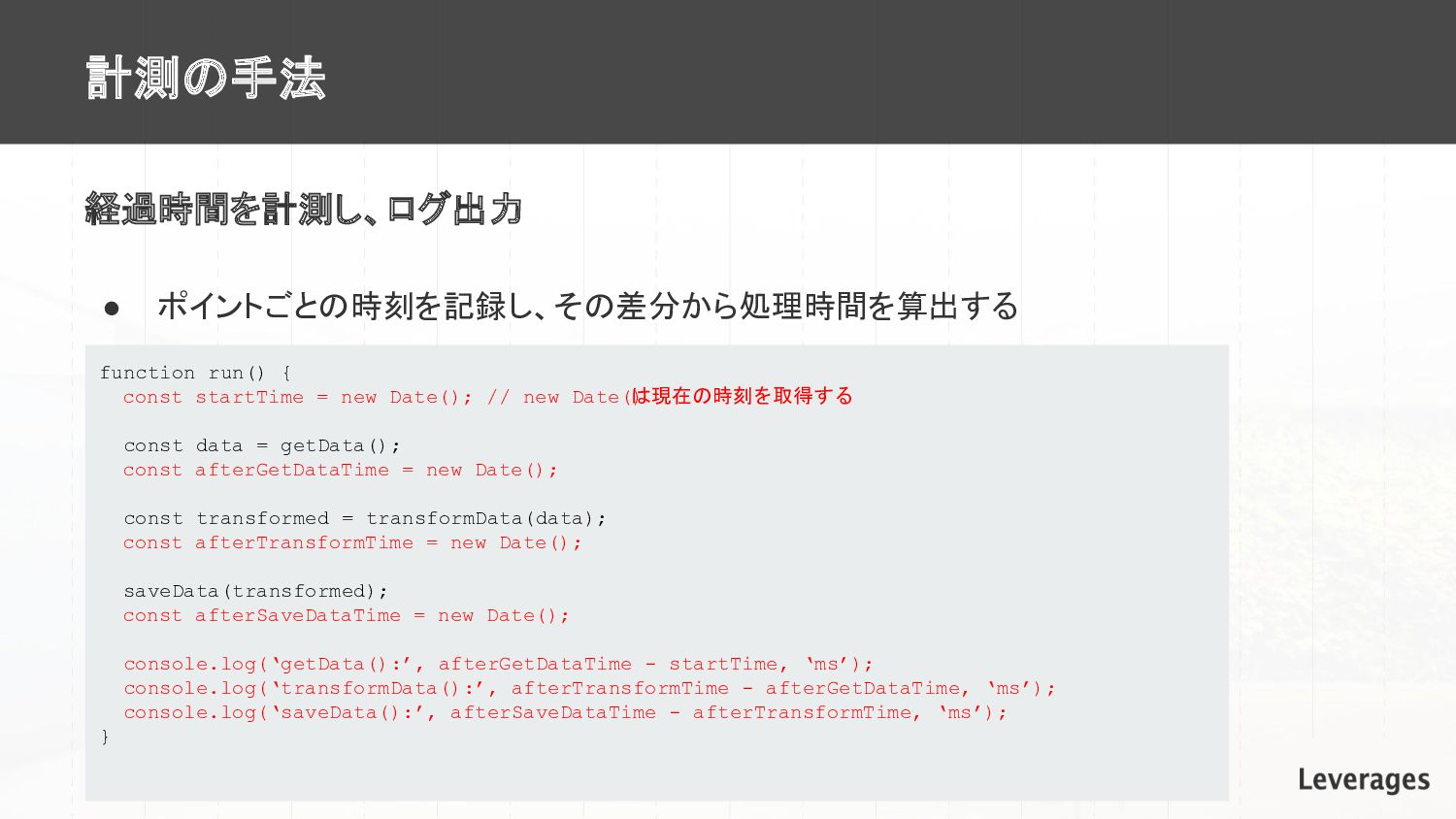
計測の手法 経過時間を計測し、ログ出力 • ポイントごとの時刻を記録し、その差分から処理時間を算出する function run() { const startTime =
new Date(); // new Date() は現在の時刻を取得する const data = getData(); const afterGetDataTime = new Date(); const transformed = transformData(data); const afterTransformTime = new Date(); saveData(transformed); const afterSaveDataTime = new Date(); console.log(‘getData():’, afterGetDataTime - startTime, ‘ms’); console.log(‘transformData():’, afterTransformTime - afterGetDataTime, ‘ms’); console.log(‘saveData():’, afterSaveDataTime - afterTransformTime, ‘ms’); }
計測の手法 経過時間を計測し、ログ出力 • ポイントごとの時刻を記録し、その差分から処理時間を算出する getData(): 105 ms transformData(): 92ms saveData():
4870ms コンソール出力
計測の手法 プロファイラの活用 • 各関数にかかっている処理時間を可視化できるツール • 各ポイントでの時刻の記録を関数呼び出し時に自動的に行うことで実現 • プロファイラの例 ◦ ChromeのPerformanceタブ
/ Node.jsの標準プロファイラ (--inspect) ◦ PHPのxhprof ◦ Datadog APMのContinuous Profiler
計測の手法 Node.jsプロファイラの例 • どこの処理にどのくらいの時間を使ったかが可視化可能
計測の手法 Node.jsプロファイラの例 • どこの処理にどのくらいの時間を使ったかが可視化可能
計測の手法 プロファイラの注意点 • 非同期処理を追うのは難しい(Node.jsの場合) • 関数呼び出しに一定のオーバーヘッドが課されるようになる ◦ 何万〜何十万回と呼ばれる関数は実際よりも処理時間が多く出てしまうことも
計測の手法 まとめ • 一度も計測せずに憶測だけで高速化に着手するのは危険 • 一方、計測も完全ではないので、範囲をある程度絞るくらいで良い ◦ 真因に関しては高速化を実施する中で判明していくことも多い
処理高速化のアプローチ 1. 「無駄」のニオイを感じ取る 2. 処理の遅い原因を特定する(計測) 3. 高速化のための手段を考え、実装する 4. 実装した高速化の効果を測定する
高速化の実施 高速化の普遍的な手法は存在しない • 遅い原因は処理によって千差万別 • その対策も状況に合わせて泥臭くやっていく必要がある • 今回は自分が関わったいくつかの高速化事例をご紹介
高速化の実施 例:月次の勤怠締め操作 (給与計算ソフト) • 1ヶ月分の勤怠データを締めて給与額を算出する処理 • 300人分のデータで7分以上かかる • 処理量が多いためであると諦められていたが、計算内容と処理時間が乖離していると感じ 高速化に着手
◦ 300人 * 30日 = 9000個の勤怠データの集計 + 過去の有給使用データ (300人 * 数十件 = 数 千〜1万件) の集計 ◦ データの取得等含めて考えても何十秒もかかるのですらおかしい
高速化の実施 例:月次の勤怠締め操作 (給与計算ソフト) • ログを吐いて計測した結果、DBのデータ読み書きに大半の時間を費やしていた • 詳しくコードを調査した結果、以下の 2つの原因が判明 ◦ 特定のテーブル(大きめ)にインデックスが張られていなかった
◦ 1ユーザーの処理ごとに多数のクエリを発行していた
高速化の実施 テーブルにインデックスが張られていなかった • ただの凡ミス • 取得に使うカラムにインデックスを張って対応 補足:データベースのインデックスとは • 特定の属性(ユーザーID等)に基づいてデータの索引を作る機能 •
レコードの検索処理の計算量が O(n) から O(log n)に減少する(巨大 なテーブルだと、ほぼ定数時間) インデックスに使うB-treeの構造
高速化の実施 1ユーザーごとに多数のクエリを発行していた • ループ内でクエリを発行していた &同じデータを何回も取ってきていた ◦ 何万回ものクエリ発行 ◦ ネットワーク通信待ち +
クエリ実行のオーバーヘッドで結構時間を取られる • 全ユーザーのデータを予め一括で取得するようにして解決 ◦ 1件SELECTを10000回やるより10000件SELECTを1回の方が圧倒的に速い
高速化の実施 結果 • 計算処理には一切手を入れなかったが、 10秒程度まで短縮
高速化の実施 例2:TypeORM マイグレーションの高速化 • マイグレーション = DBスキーマ変更クエリの実行 • マイグレーションコマンドが立ち上がるまでに 10分弱かかっていた
• どう考えても時間のかかり方が異常で、無駄がありそう ◦ ただマイグレーションのクエリ実行を準備するのに 10分もかからないはずなので
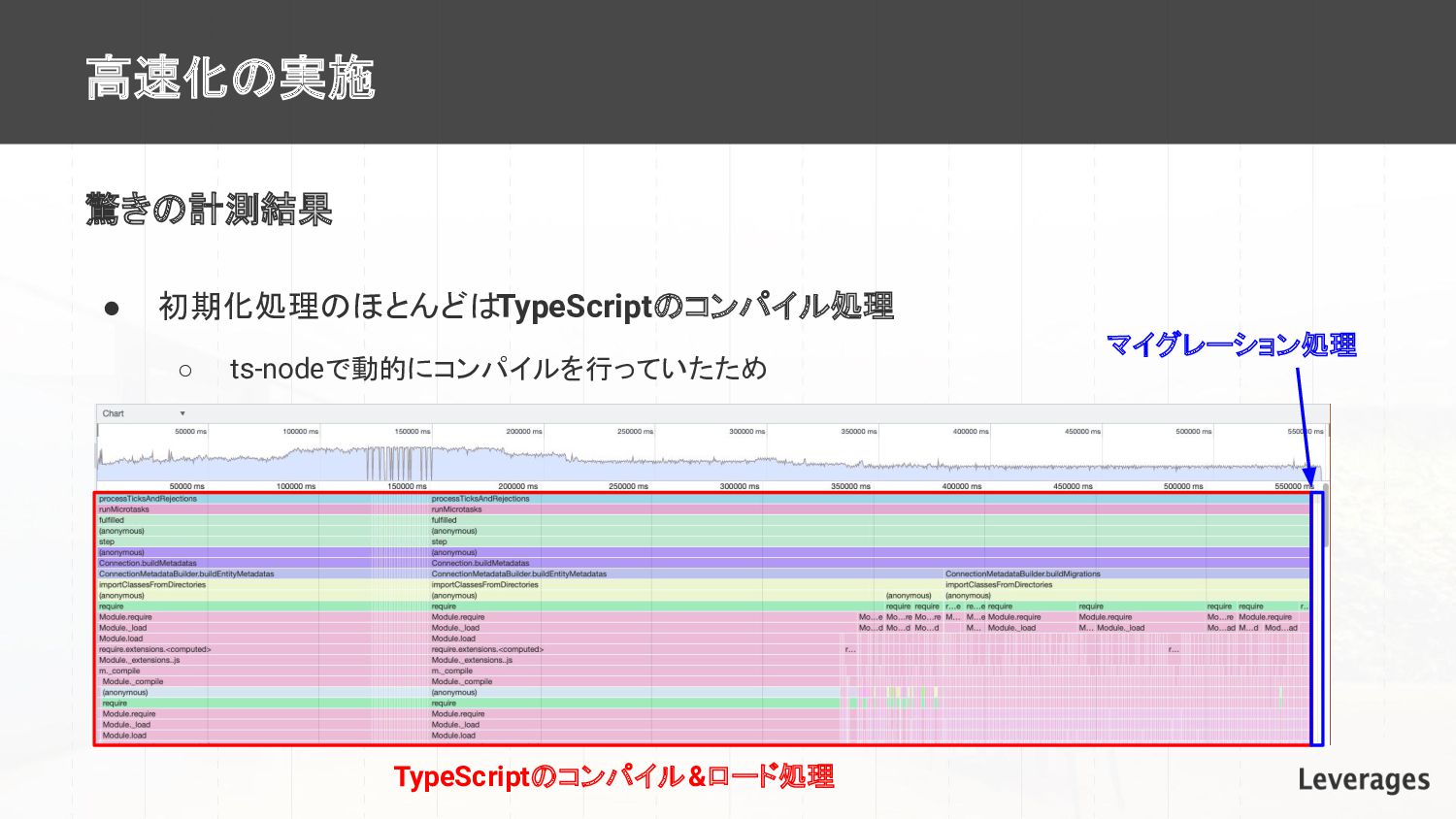
高速化の実施 驚きの計測結果 • 初期化処理のほとんどはTypeScriptのコンパイル処理 ◦ ts-nodeで動的にコンパイルを行っていたため TypeScriptのコンパイル&ロード処理 マイグレーション処理
高速化の実施 TypeScriptのコンパイルがそんなに重いはずがない • 確かにtsファイル数は多い(2000ファイル弱) • しかし、プロジェクトのビルド(npm run build)には10秒くらいしかかからない • 仮説:
ts-nodeが1ファイルずつビルドしているのでオーバーヘッドが大きく、重い? ◦ 同じファイルを何度もコンパイルしている可能性?
高速化の実施 解決策:事前に全てコンパイル • マイグレーションに必要なtsファイルのみを事前コンパイル(一瞬) • 初期化の時間がほぼなくなり、すぐにマイグレーションが走るように • 必要時間は9分→数秒に改善
高速化の実施 まとめ • 基本的には状況に合わせて愚直に無駄を削るしかない
処理高速化のアプローチ 1. 「無駄」のニオイを感じ取る 2. 処理の遅い原因を特定する(計測) 3. 高速化のための手段を考え、実装する 4. 実装した高速化の効果を測定する
高速化の効果を確認する 高速化で処理時間を短縮できた!めでたしめでたし • ・・・本当でしょうか? • 狙った通りに高速化できているか、立ち返って確認しましょう
ロブ・パイクのプログラミング5カ条 ルール3 凝ったアルゴリズムはnが小さいときには遅く、nはしばしば小さい。凝ったアルゴリズムは大きな 定数を持っている。nが頻繁に大きくなることがわかっていないなら、凝ってはいけない 引用元: http://www.lysator.liu.se/c/pikestyle.html ルール4 凝ったアルゴリズムはシンプルなそれよりバグを含みやすく、実装するのも難しい。シンプルなア ルゴリズムとシンプルなデータ構造を使うべし。
高速化の効果を確認する 高速化は実装の複雑化とのトレードオフ • 実装の複雑さに見合うほどの効果が得られたか • 高速化したと思ったのに逆に遅くしてしまっていないか(?!) ◦ 複数の高速化策を同時に適用したが、実際には一部が逆効果だったというパターン
高速化の効果を確認する 実例:キャッシュ入れて高速化したと思ったら遅くなってた件 • Jest(Node.js テストフレームワーク)によるテスト実行が遅かった(何十分も要する) • 例によってTypeScriptの動的コンパイルを行っていた • Jestのコンパイルキャッシュ機能を有効化して高速化した気になっていたが・・・
高速化の効果を確認する 実例:キャッシュ入れて高速化したと思ったら遅くなってた件 • 本件ではそもそもTypeScriptの動的コンパイルの占める処理時間は小さかった ◦ そもそもts-node自身がコンパイル結果をメモリに保持するのでほぼ効果なし • 逆に、キャッシュが最新のソースを反映しているかの確認処理の方が重かった • 結果、キャッシュ導入前よりも実行時間が伸びる
高速化の効果を確認する 敗因 • 時間がかかっているのがどこかきちんと計測していなかった ◦ ちなみに遅くなっている原因は全く別の場所だった • 複数の高速化を同時に行っており、個々の策についての効果を測定していなかった → 測定した上で、効果のあるものだけを残すべき
高速化の効果を確認する まとめ • 高速化技法が本当に効果をもたらすかは、測ってみなければわからない • 意味のない実装はきちんとコードベースから排除する
まとめ
まとめ • 処理に潜む無駄を見抜けるようになる ◦ 低レベルな部分まで興味を持つ! • 当てずっぽうで高速化を試すのはやめる • 高速化の効果と釣り合わない実装は排除する
ご清聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}