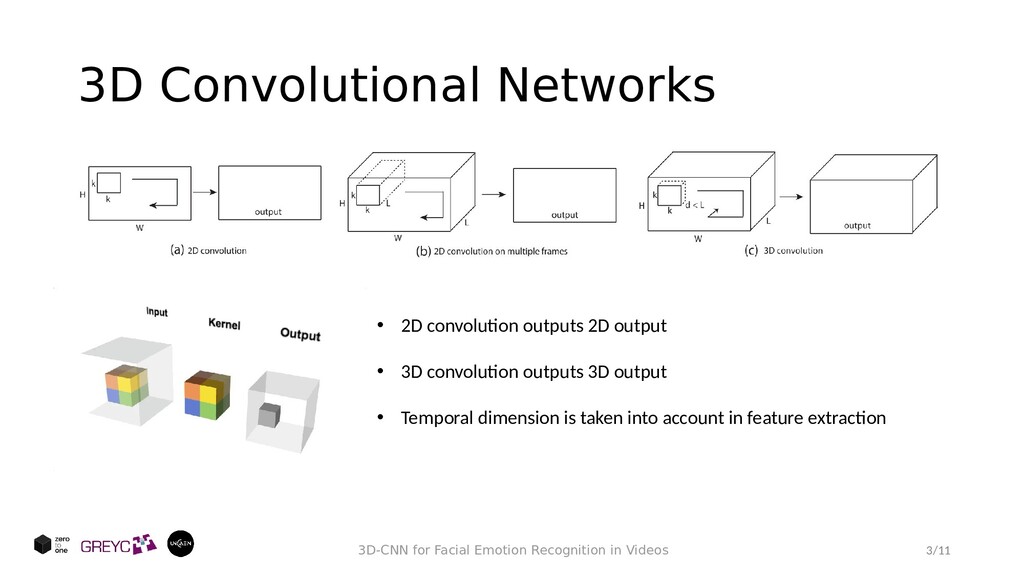
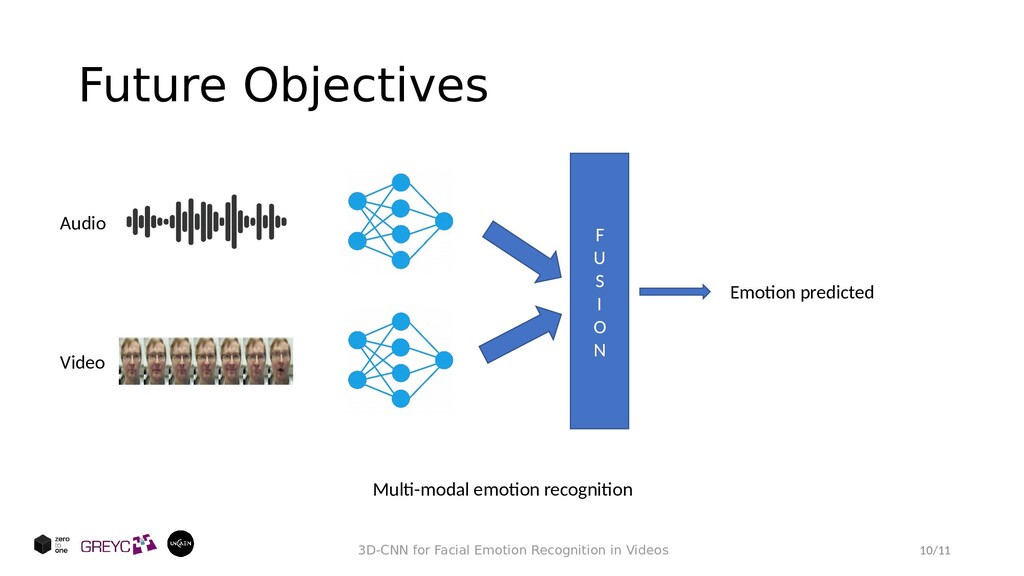
: • Develop a neural network architecture that can be applied on videos, therefore, the temporal aspect of the emotion is important • Our model should be light in terms of computational power Our approach: • A 3D Convolutional Neural Network
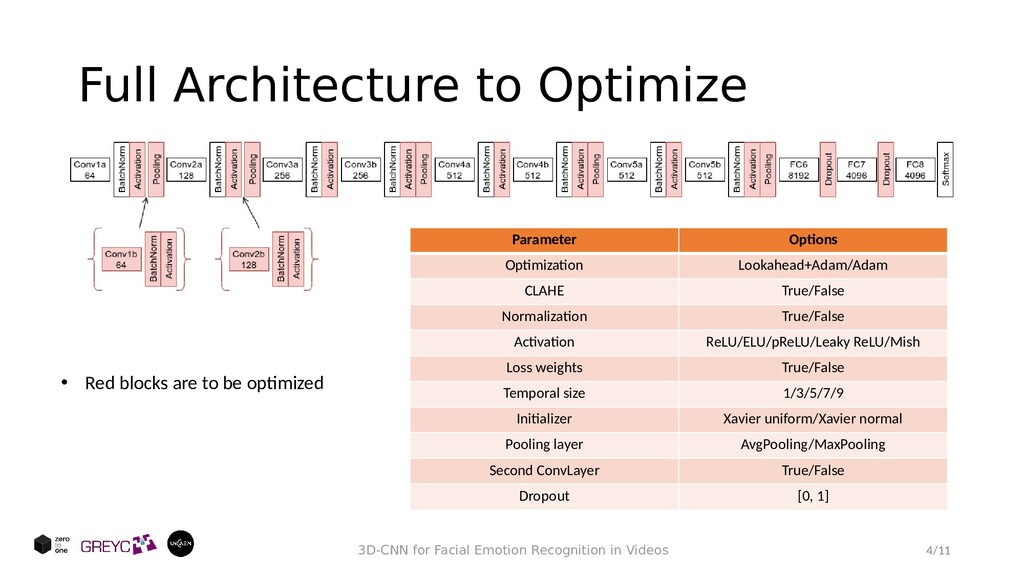
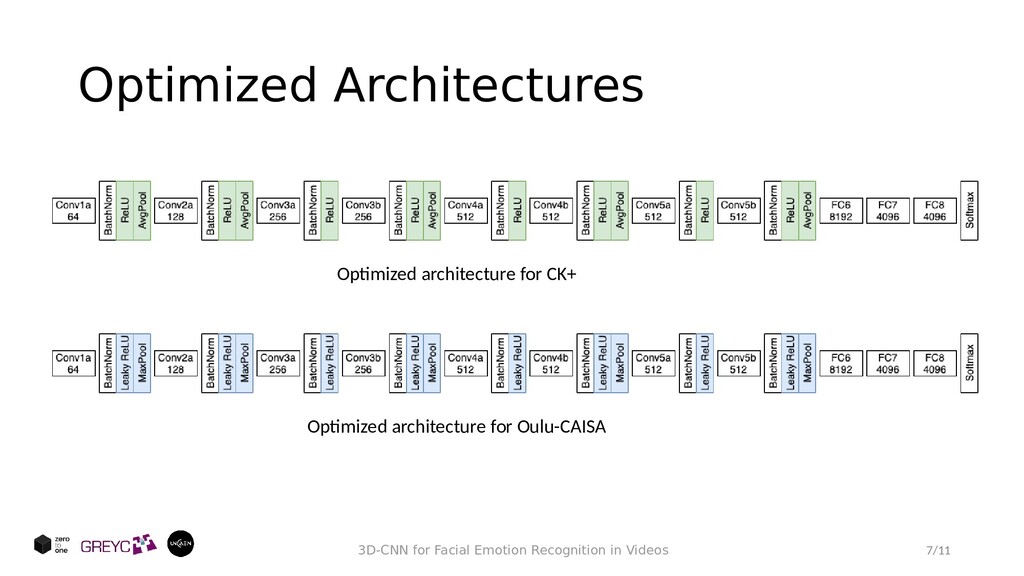
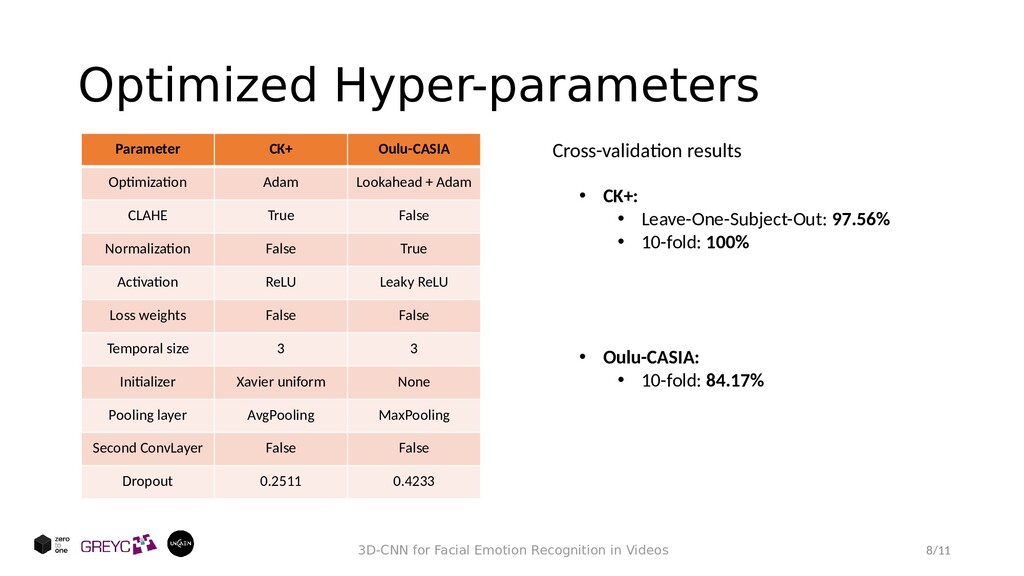
in Videos Parameter Options Optimization Lookahead+Adam/Adam CLAHE True/False Normalization True/False Activation ReLU/ELU/pReLU/Leaky ReLU/Mish Loss weights True/False Temporal size 1/3/5/7/9 Initializer Xavier uniform/Xavier normal Pooling layer AvgPooling/MaxPooling Second ConvLayer True/False Dropout [0, 1] • Red blocks are to be optimized
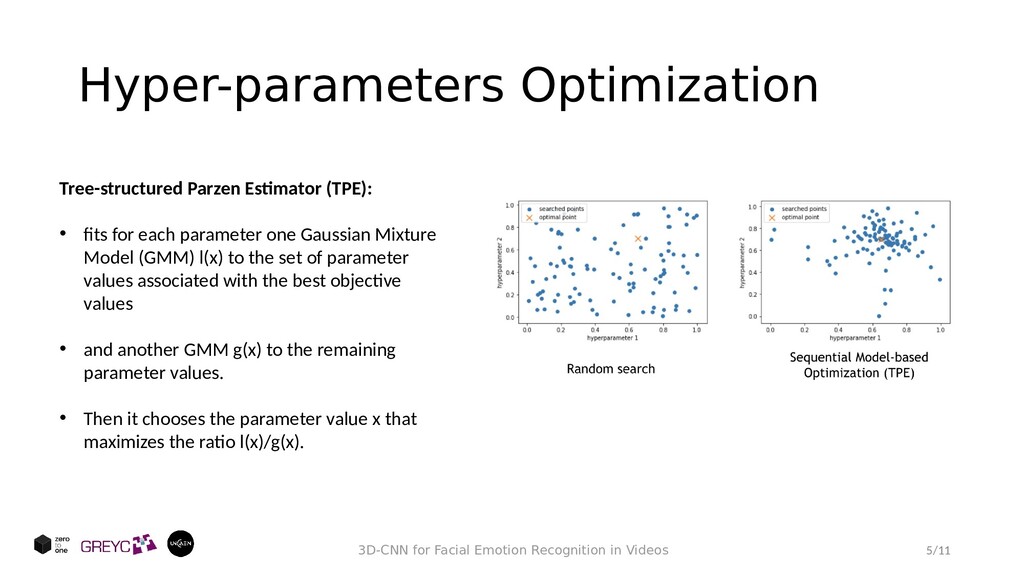
Tree-structured Parzen Estimator (TPE): • fits for each parameter one Gaussian Mixture Model (GMM) l(x) to the set of parameter values associated with the best objective values • and another GMM g(x) to the remaining parameter values. • Then it chooses the parameter value x that maximizes the ratio l(x)/g(x).
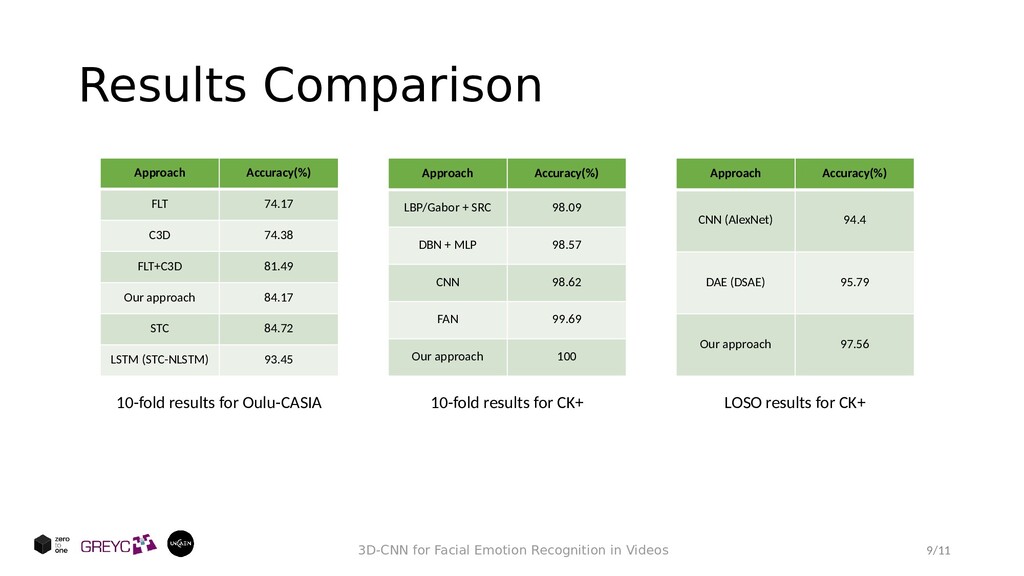
• 593 video sequences from 123 subjects • anger, contempt, disgust, fear, happiness, sadness, and surprise • Leave-One-Subject-Out (LOSO) and 10-fold cross- validation Oulu-CASIA: • 480 video sequences from 80 people between 23 to 58 years old • anger, disgust, fear, happiness, sadness, and surprise • 10-fold cross-validation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}