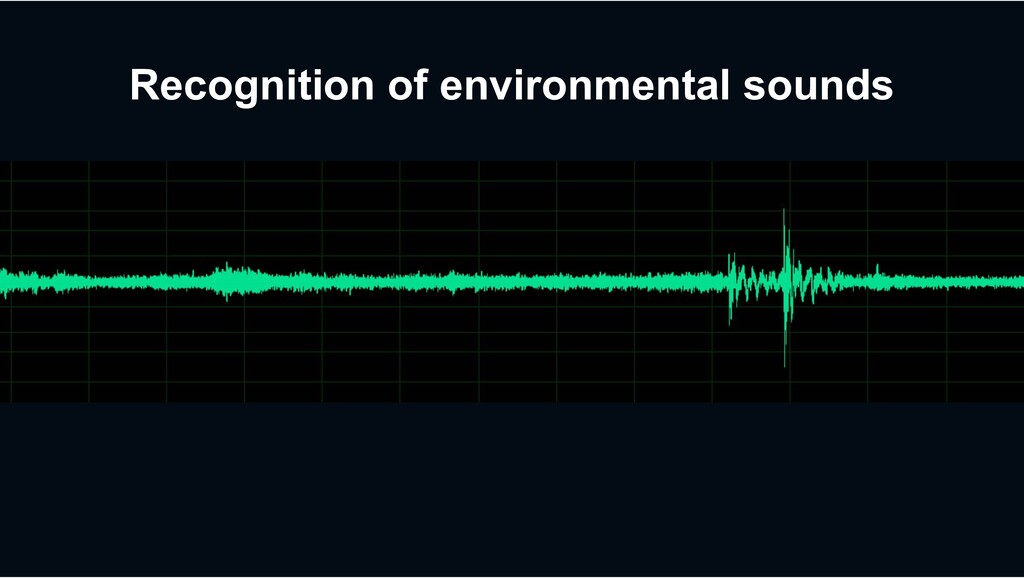
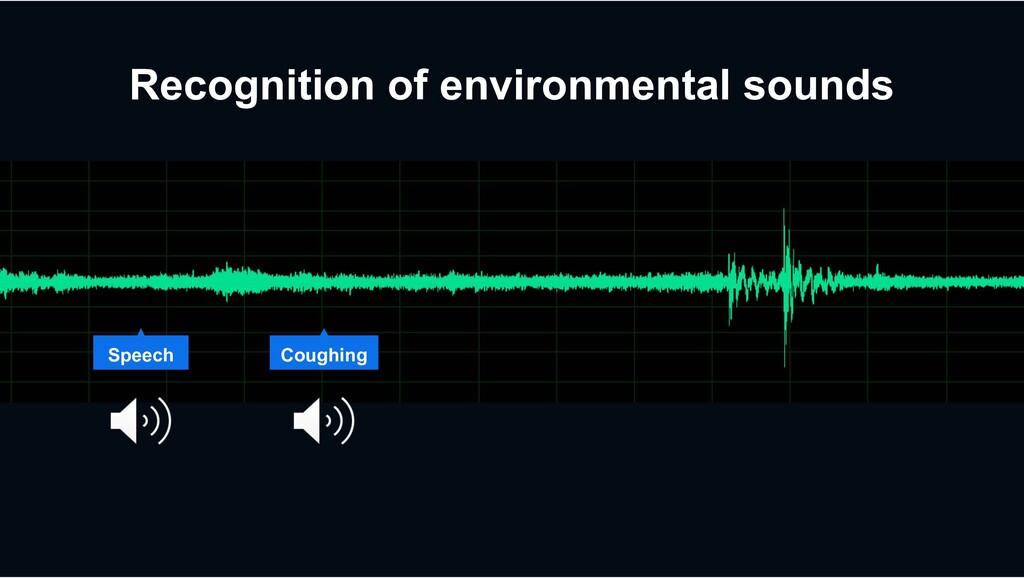
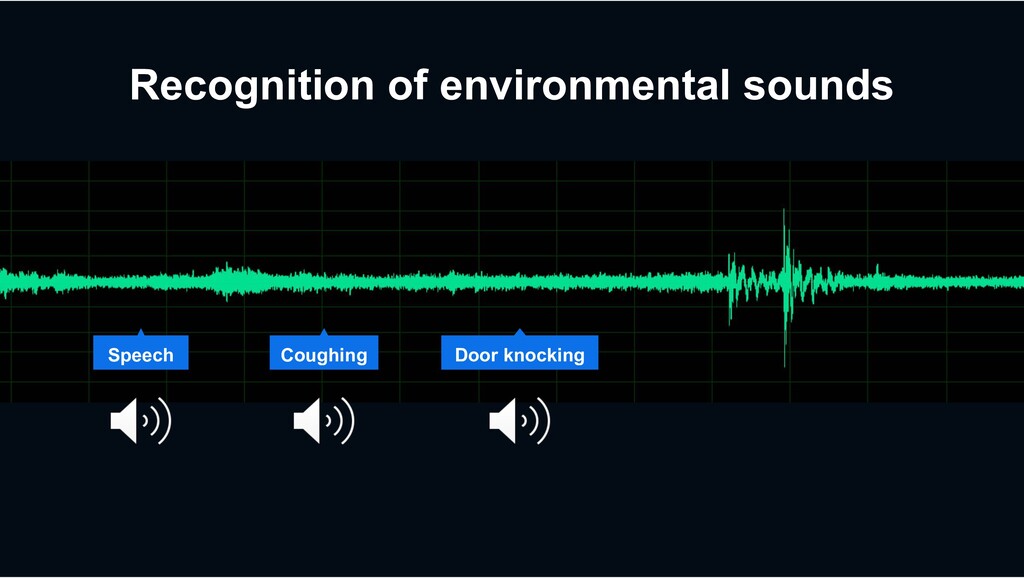
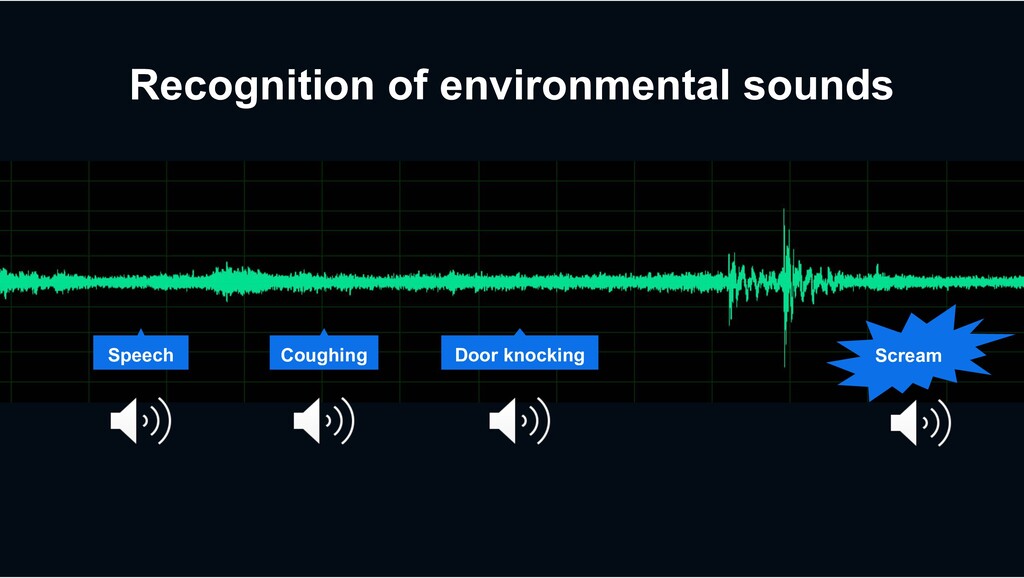
Diverse categories of environmental sounds City Surveillance › Scream › Shouting › Glass breaking Home Monitoring › Speech › Dog barking › home appliances
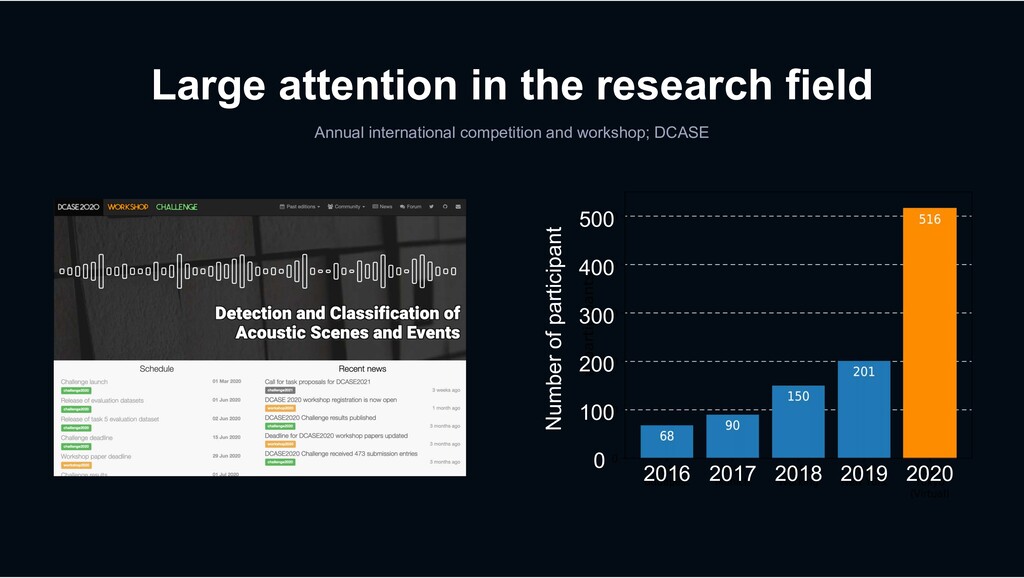
event to accelerate the development of the research field › LINE joined the challenge as the joint team with Nagoya Univ. and Johns Hopkins Univ. LINE Internship Student 2019
› Noisy, diverse characteristics and low-quality sound labels DCASE2020 Challenge task4 Domestic-Environment-Sound Recognition Golden Retriever Dog Luke sings with piano music https://www.youtube.com/watch?v=-hDuDDv0lbQ crying baby https://www.youtube.com/watch?v=-3UBJIEYKVg
system submission › 14.6 % higher than Baseline system › 3.3 % higher than 2nd place team submission Our team http://dcase.community/challenge2020/task-sound-event-detection-and-separation-in-domestic-environments-results
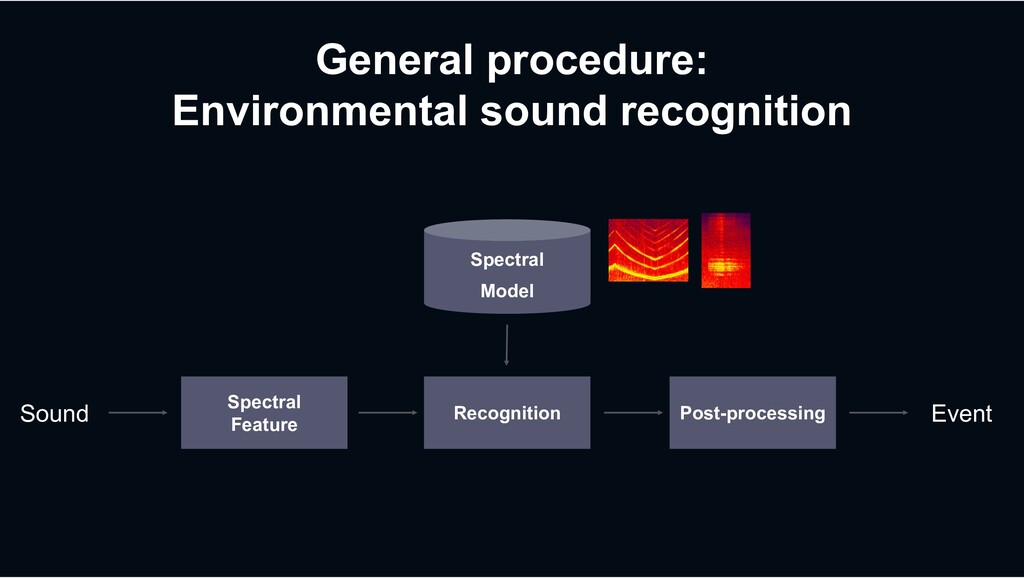
and temporal (global) information are important › Sounds occur simultaneously, i.e. Overlapping → One of the key solution = Source separation Global information Local information Next Session
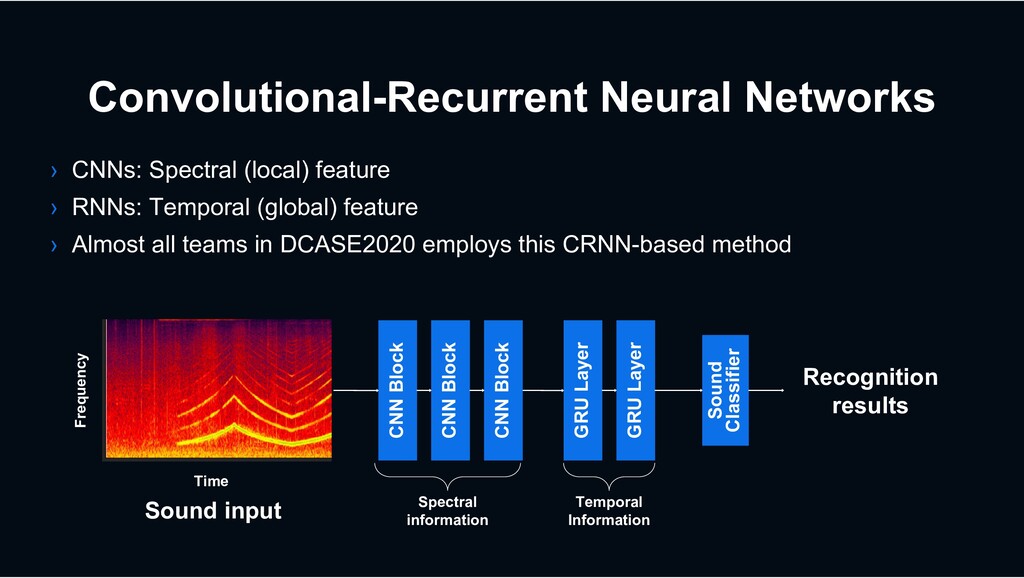
Temporal (global) feature › Almost all teams in DCASE2020 employs this CRNN-based method GRU Layer GRU Layer Sound input Time Frequency CNN Block CNN Block CNN Block Sound Classifier Recognition results Spectral information Temporal Information
› Noisy, diverse characteristics and low-quality sound labels DCASE2020 Challenge task4 Domestic-Environment-Sound Recognition Golden Retriever Dog Luke sings with piano music https://www.youtube.com/watch?v=-hDuDDv0lbQ crying baby https://www.youtube.com/watch?v=-3UBJIEYKVg
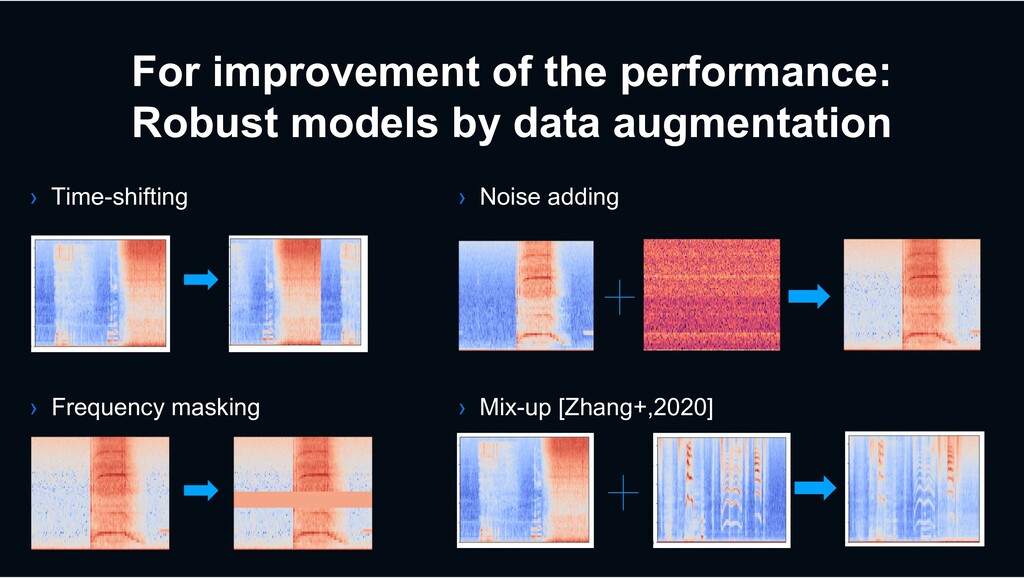
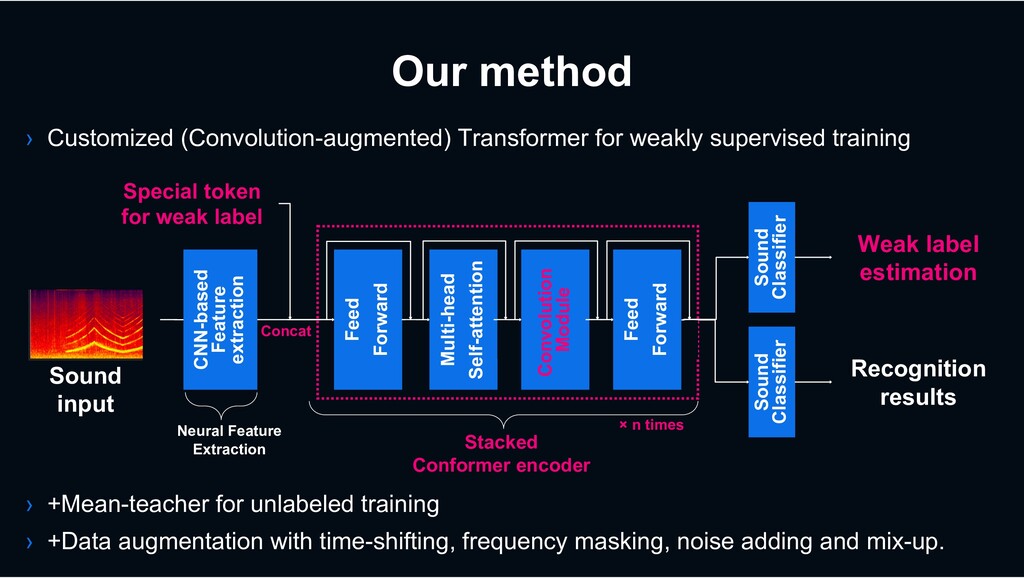
the ``wild’’ › Unlabeled data training for effective use of huge amounts of data on the web › Robust model to handle sounds with diverse characteristics Baby crying Music People speech
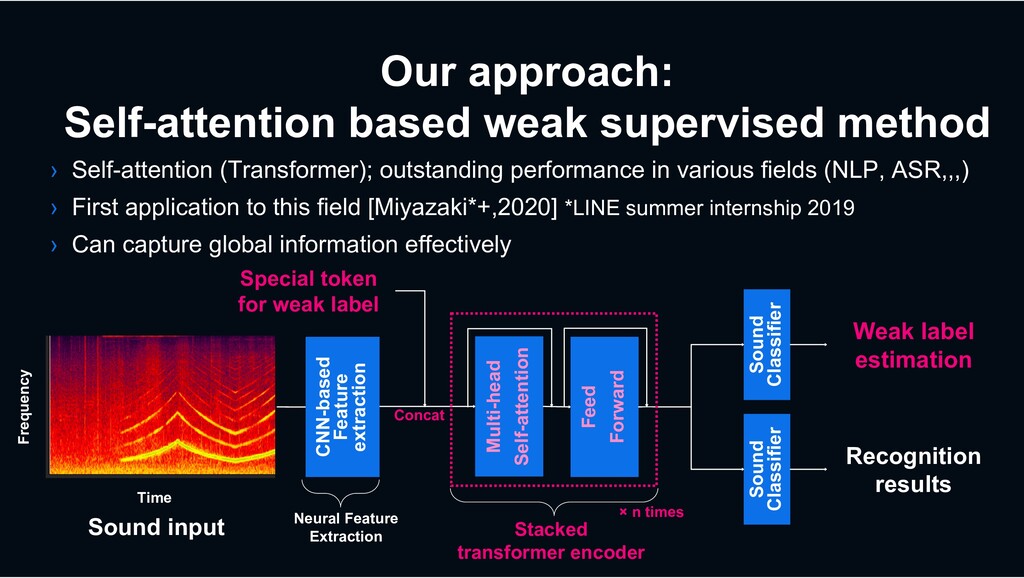
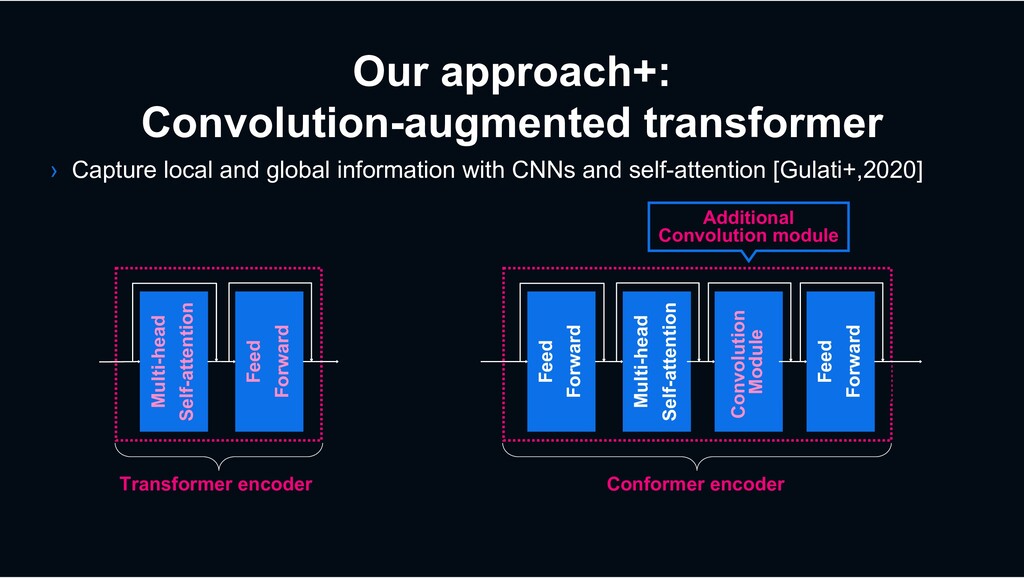
outstanding performance in various fields (NLP, ASR,,,) › First application to this field [Miyazaki*+,2020] *LINE summer internship 2019 › Can capture global information effectively Multi-head Self-attention Sound input Time Frequency Sound Classifier Weak label estimation Neural Feature Extraction Stacked transformer encoder Feed Forward Sound Classifier Recognition results Special token for weak label × n times Concat CNN-based Feature extraction
The implementation to reproduce the competition results will be public › ESPnet: end-to-end speech processing toolkit [https://espnet.github.io/espnet/] › 14.6 % higher than Baseline system › 3.3 % higher than 2nd place team submission Our team
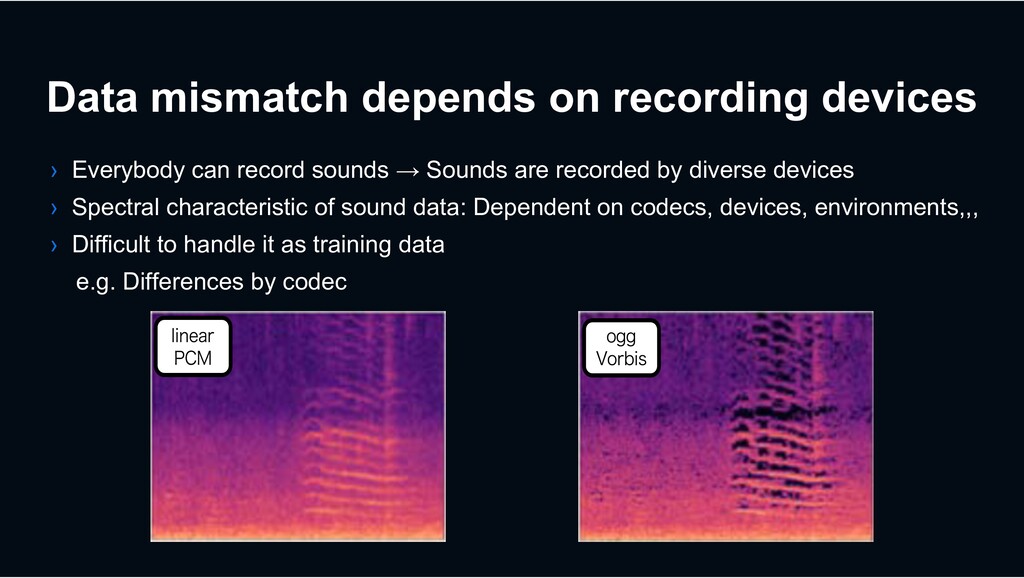
sounds → Sounds are recorded by diverse devices › Spectral characteristic of sound data: Dependent on codecs, devices, environments,,, › Difficult to handle it as training data e.g. Differences by codec Airport - London 0 1 5 2 3 4 Frequency [kHz] 10 5 0 MJOFBS 1$. Airport - London 0 1 5 2 3 4 Frequency [kHz] 10 5 0 0 1 5 2 3 4 Time [sec] Frequency [kHz] 10 5 0 MJOFBS 1$. PHH 7PSCJT
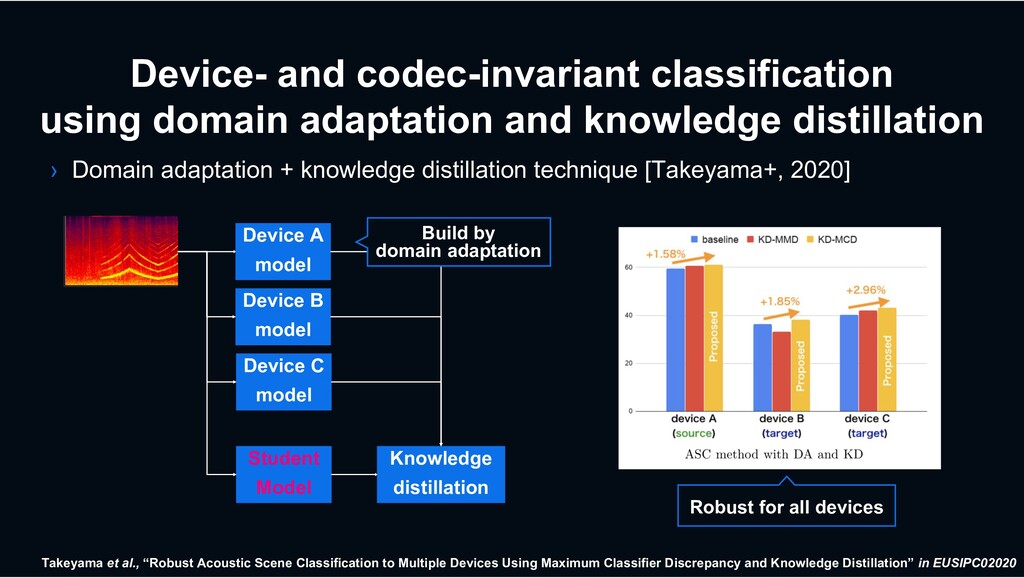
› Domain adaptation + knowledge distillation technique [Takeyama+, 2020] Takeyama et al., “Robust Acoustic Scene Classification to Multiple Devices Using Maximum Classifier Discrepancy and Knowledge Distillation” in EUSIPC02020 Device A model Device C model Device B model Student Model Knowledge distillation Robust for all devices Build by domain adaptation
and scene classification [Komatsu+,2020] › Condition event classifier using the estimated scene Multi-task network 58% lower error rate Komatsu et al., “SCENE-DEPENDENT ACOUSTIC EVENT DETECTION WITH SCENE CONDITIONING AND FAKE-SCENE-CONDITIONED LOSS” in ICASSP 2020 Shared feature Scene estimation Recognition Scene estimation Recognition results Condition!!
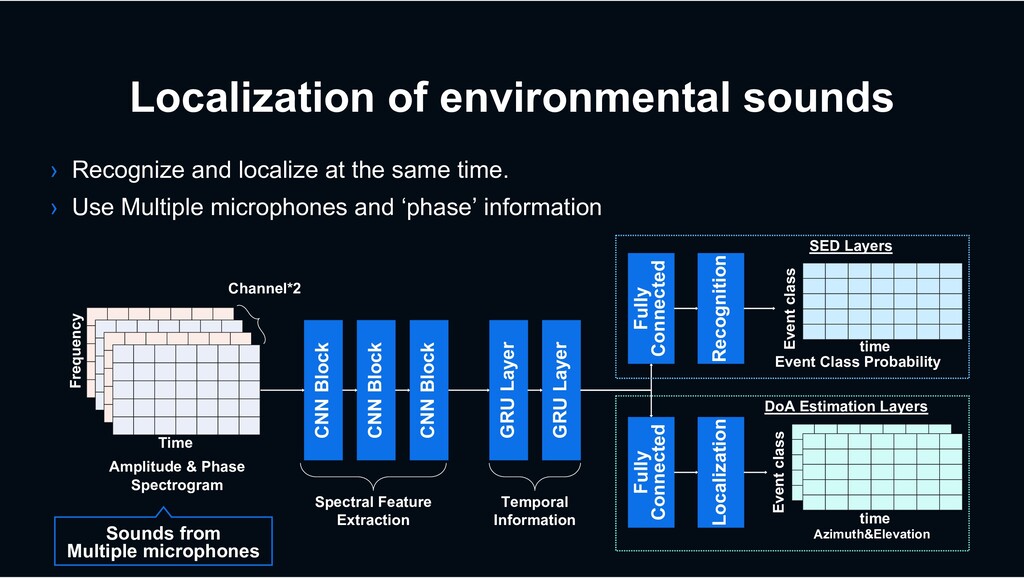
same time. › Use Multiple microphones and ‘phase’ information Sounds from Multiple microphones GRU Layer GRU Layer Amplitude & Phase Spectrogram Time Frequency Channel*2 CNN Block CNN Block CNN Block Fully Connected time Event class Event class time Recognition Fully Connected Localization Azimuth&Elevation Event Class Probability SED Layers DoA Estimation Layers Spectral Feature Extraction Temporal Information
Focus on the differences in information required for classification and localization › New mechanism to automatically control input information by GLUs [Komatsu+, 2020] Komatsu et al., “Sound Event Localization and Detection using a Recurrent Convolutional Neural Network and Gated Linear Unit” in EUSIPC02020 Improved performance for both Batch norm Max pooling Drop out Sigmoid Batch norm Linear input GLU block Control information to be used Proposed feature extraction
field of sounds › 1st place in the DCASE2020 Challenge with the joint team of Nagoya University, Johns Hopkins University and LINE › More advanced research activities in LINE › Codec-invariant environmental sound analysis › Scene-aware environmental sound recognition › Recognition and localization of environmental sounds
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}