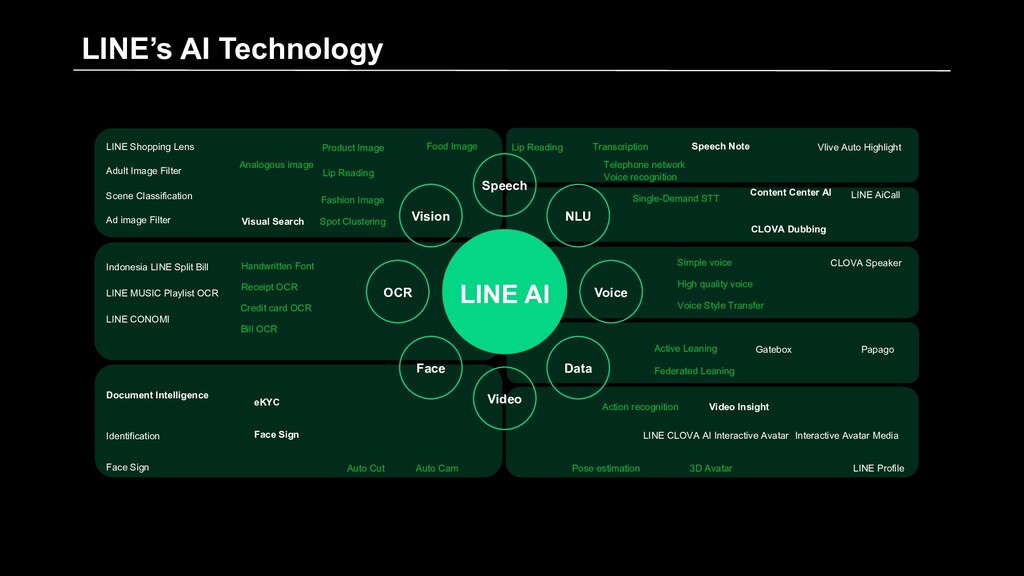
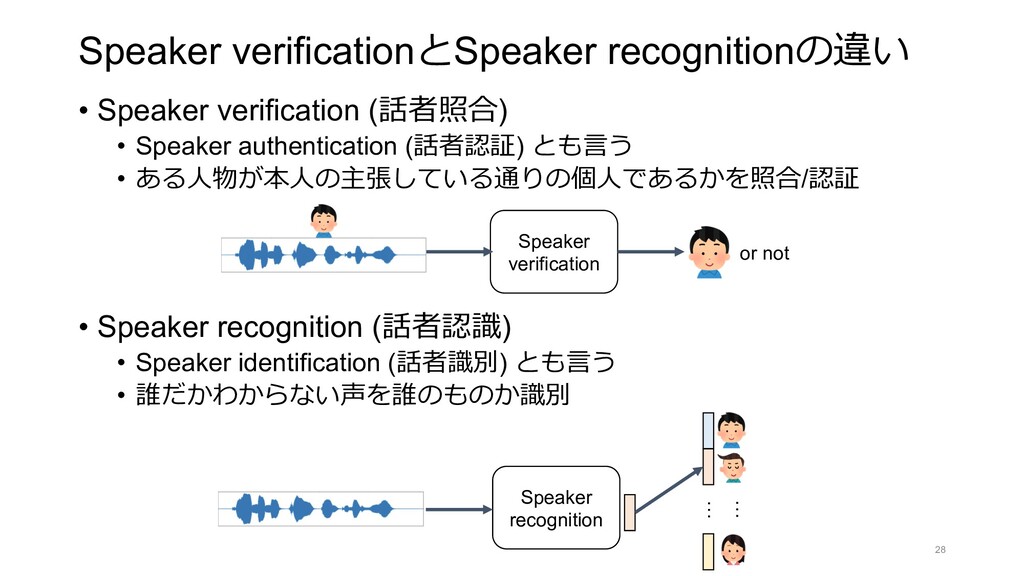
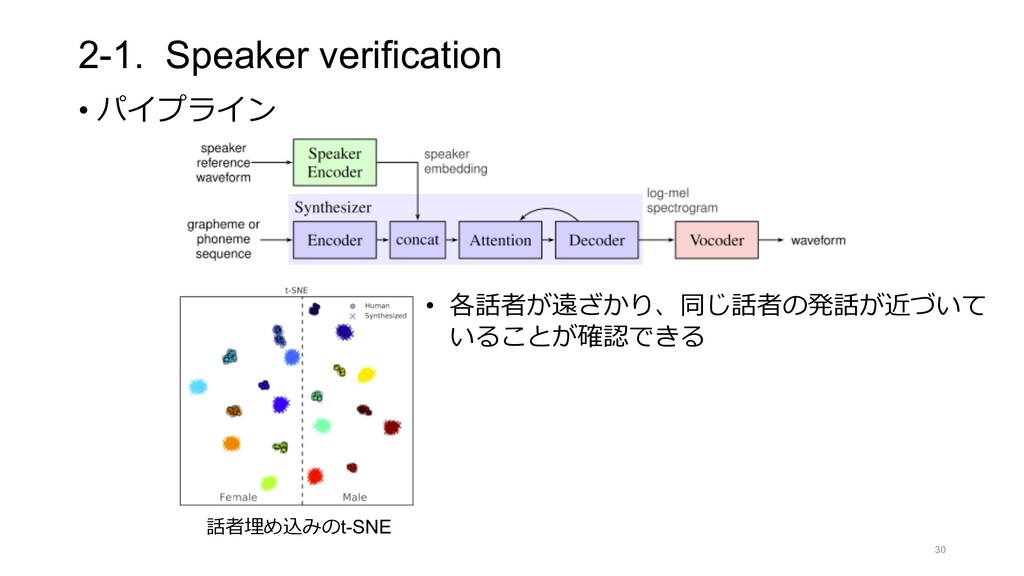
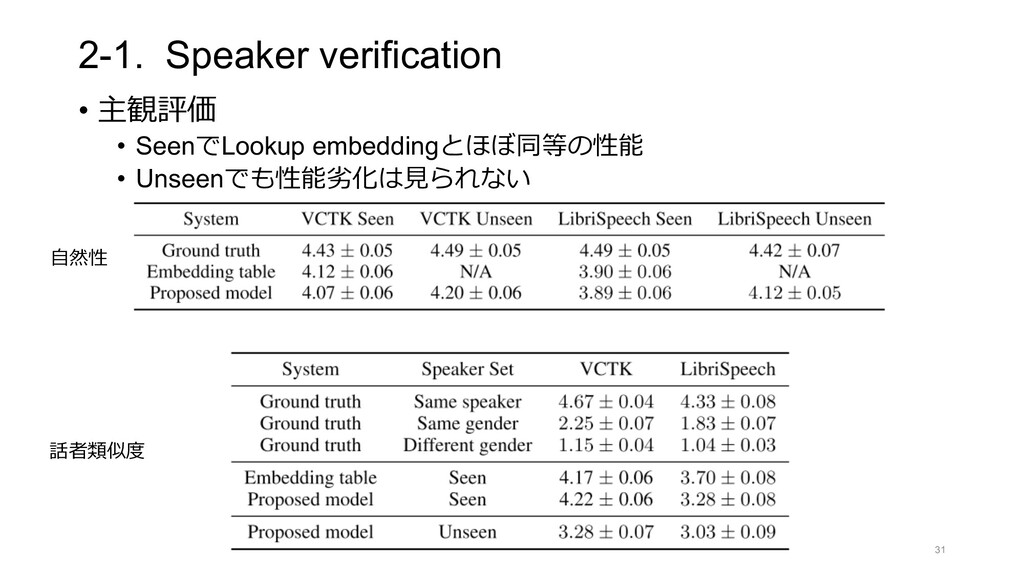
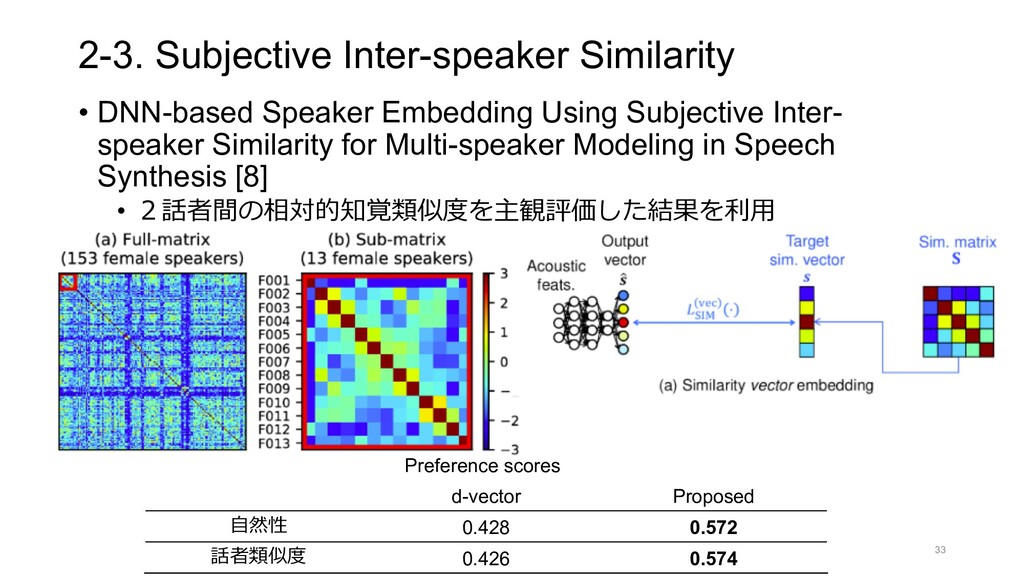
LINE Shopping Lens Adult Image Filter Scene Classification Ad image Filter Visual Search Analogous image Product Image Lip Reading Fashion Image Spot Clustering Food Image Indonesia LINE Split Bill LINE MUSIC Playlist OCR LINE CONOMI Handwritten Font Receipt OCR Credit card OCR Bill OCR Document Intelligence Identification Face Sign eKYC Face Sign Auto Cut Auto Cam Transcription Telephone network Voice recognition Single-Demand STT Simple voice High quality voice Voice Style Transfer Active Leaning Federated Leaning Action recognition Pose estimation Speech Note Vlive Auto Highlight Content Center AI CLOVA Dubbing LINE AiCall CLOVA Speaker Gatebox Papago Video Insight LINE CLOVA AI Interactive Avatar Interactive Avatar Media 3D Avatar LINE Profile Lip Reading LINE’s AI Technology
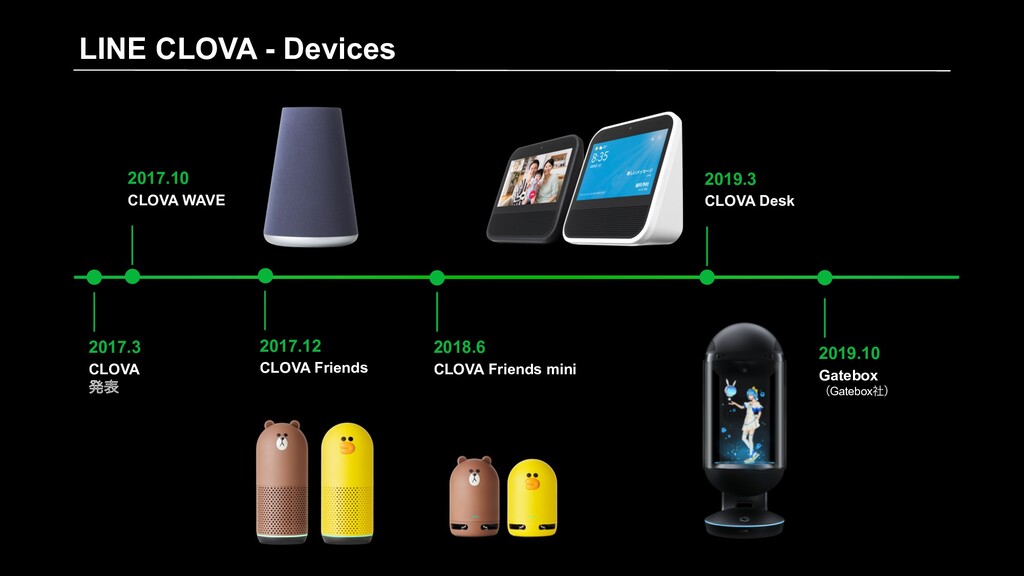
Speech CLOVA Text Analytics CLOVA Face CLOVA Assistant LINE AiCall LINE eKYC Solutions Devices CLOVA Friends CLOVA Friends mini CLOVA Desk CLOVA WAVE LINE’s AI Technology Brand
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
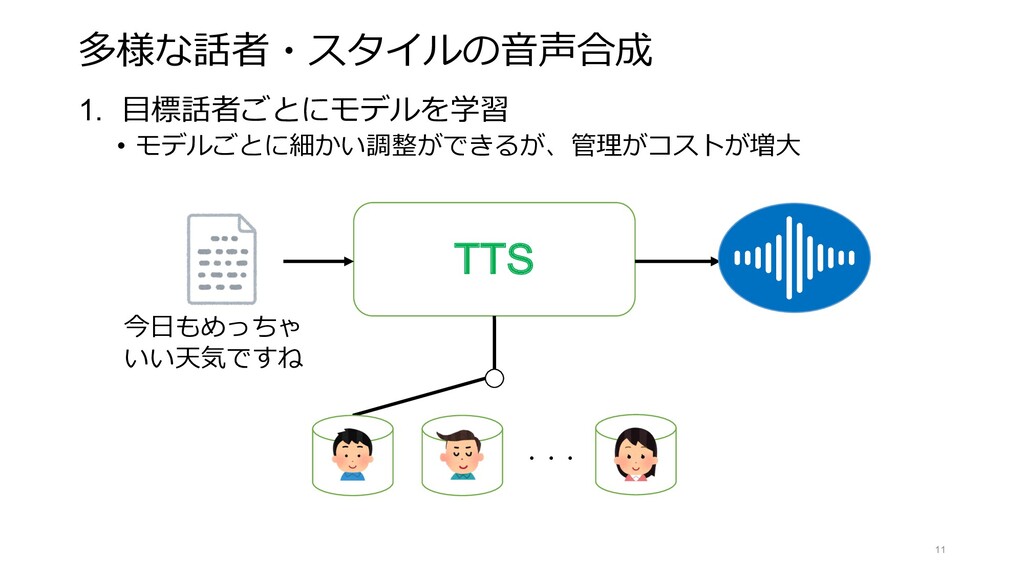{kind=link}
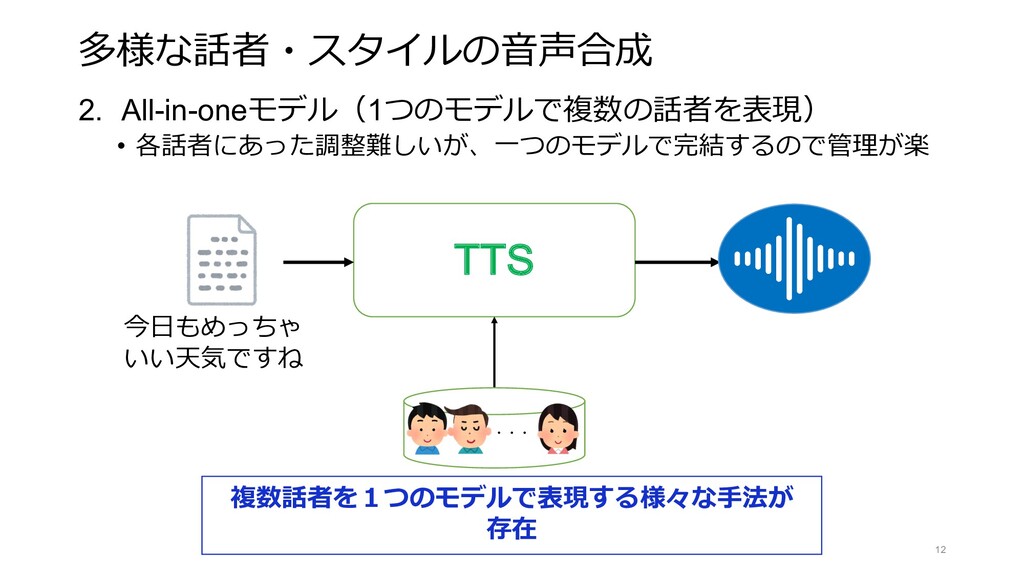{kind=link}
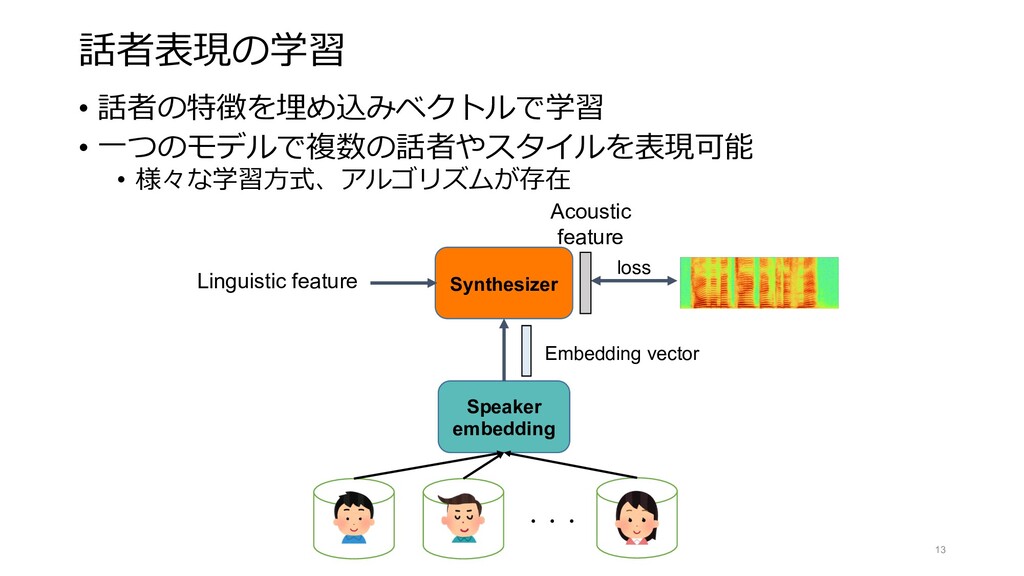{kind=link}
{kind=link}
{kind=link}
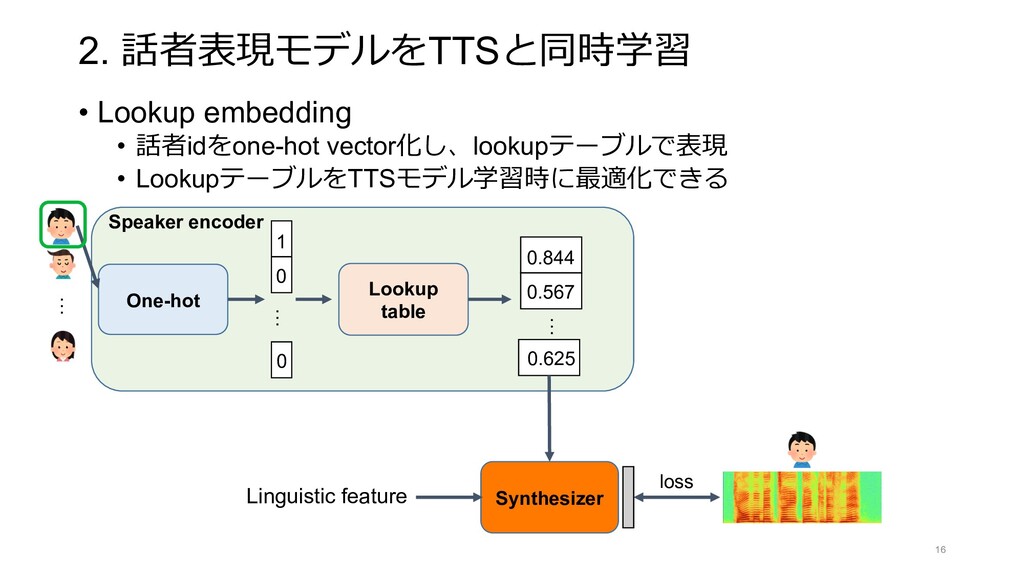{kind=link}
![Lookup embeddingの挿⼊⽅法・位置 1. Deep Voice 2 [1] 1. あらゆるモジュール・位置に挿⼊ 17](https://files.speakerdeck.com/presentations/9cdb267ea4f04813a9dae0ae2f1c757d/slide_16.jpg){kind=link}
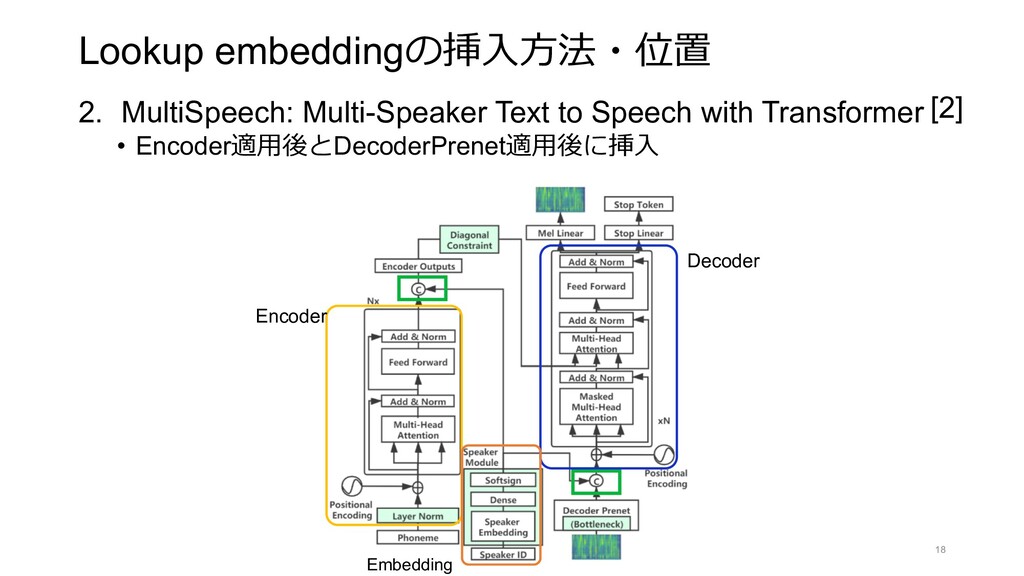{kind=link}
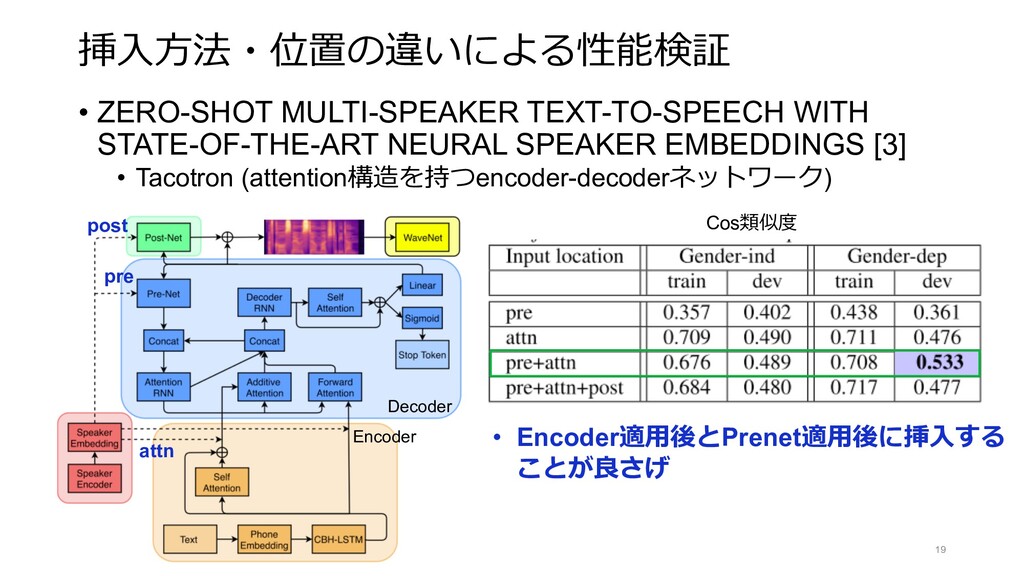{kind=link}
{kind=link}
![Lookup embedding + fine-tuning • SAMPLE EFFICIENT ADAPTIVE TEXT-TO-SPEECH [4]](https://files.speakerdeck.com/presentations/9cdb267ea4f04813a9dae0ae2f1c757d/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
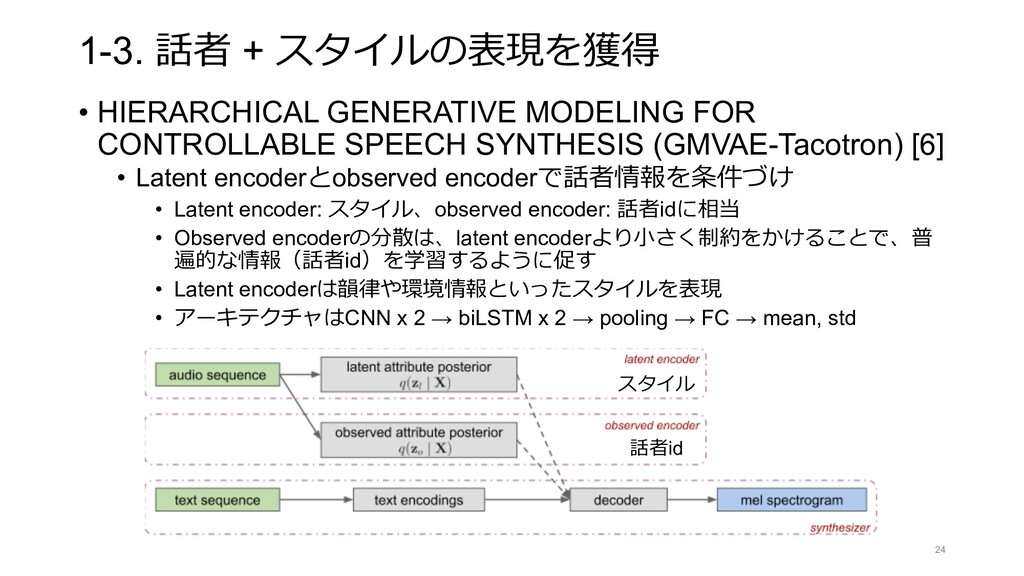{kind=link}
{kind=link}
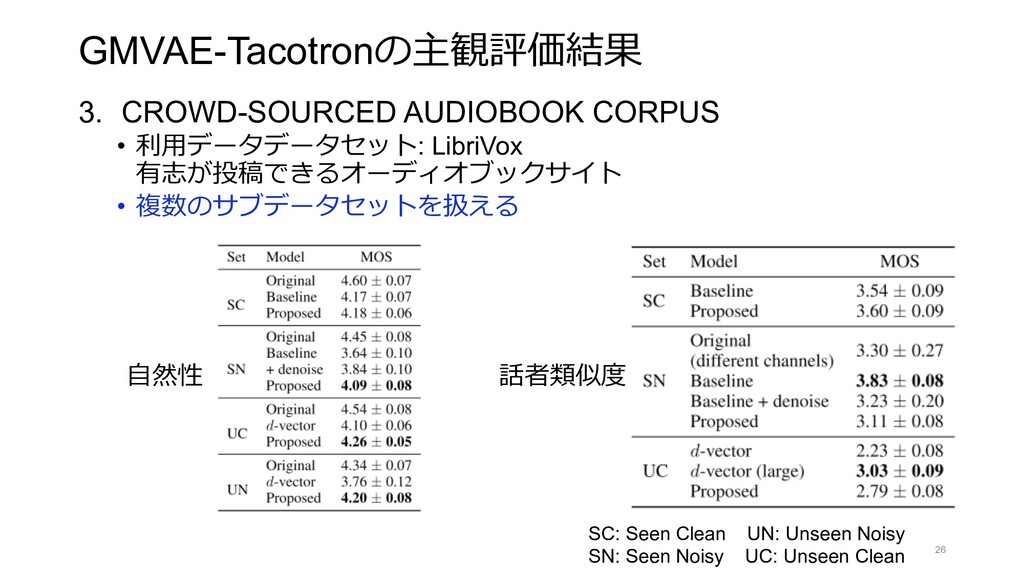{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• ZERO-SHOT MULTI-SPEAKER TEXT-TO-SPEECH WITH STATE-OF-THE-ART NEURAL SPEAKER EMBEDDINGS [3]](https://files.speakerdeck.com/presentations/9cdb267ea4f04813a9dae0ae2f1c757d/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
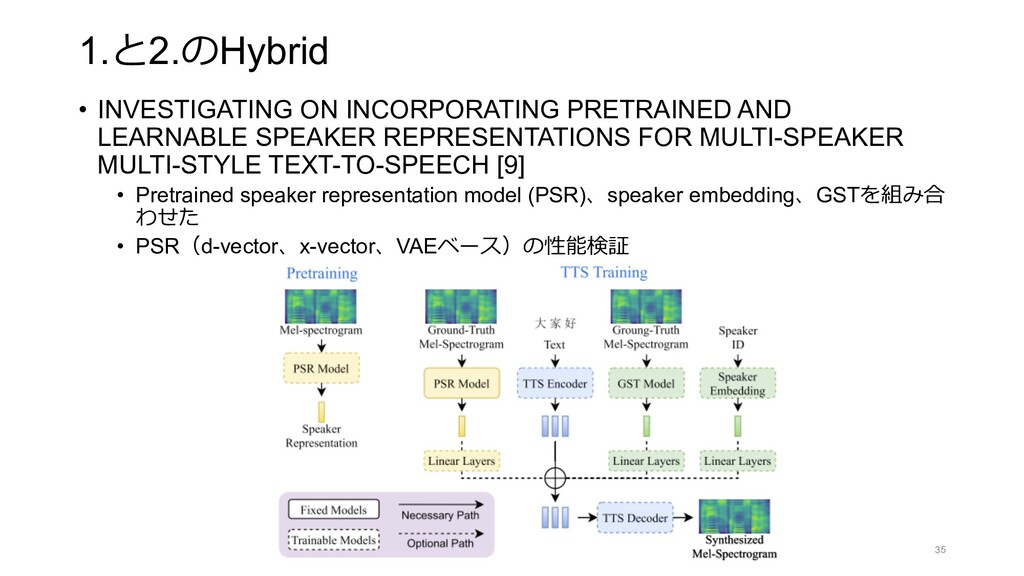{kind=link}
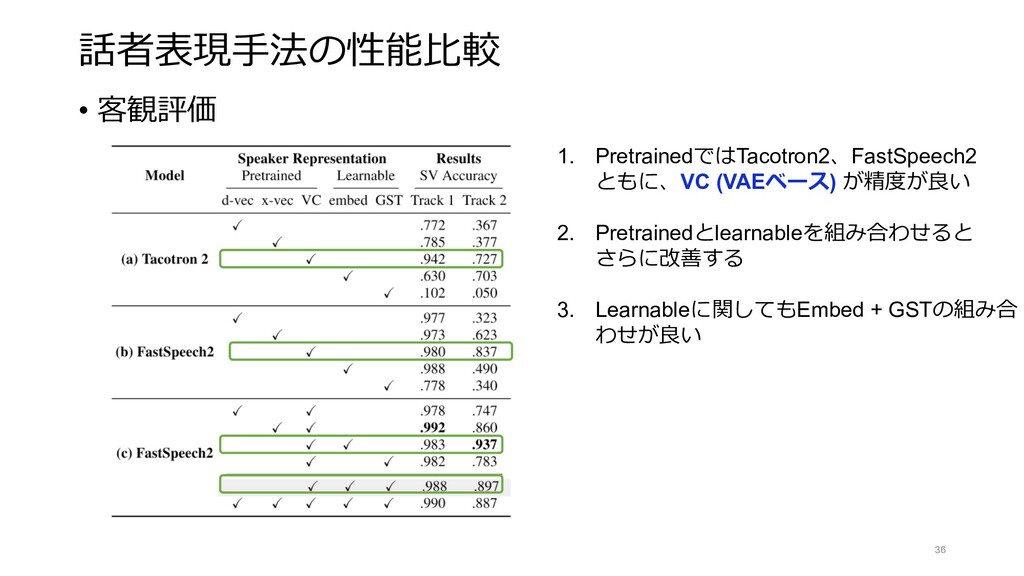{kind=link}
{kind=link}
{kind=link}
![参考⽂献 [1] Arik, Sercan, et al. "Deep voice 2: Multi-speaker](https://files.speakerdeck.com/presentations/9cdb267ea4f04813a9dae0ae2f1c757d/slide_38.jpg){kind=link}