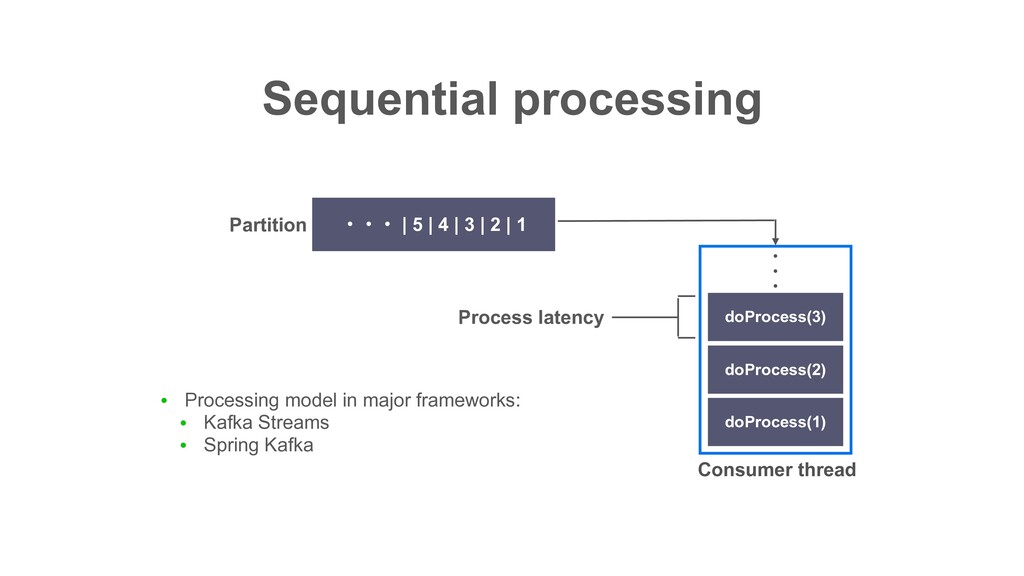
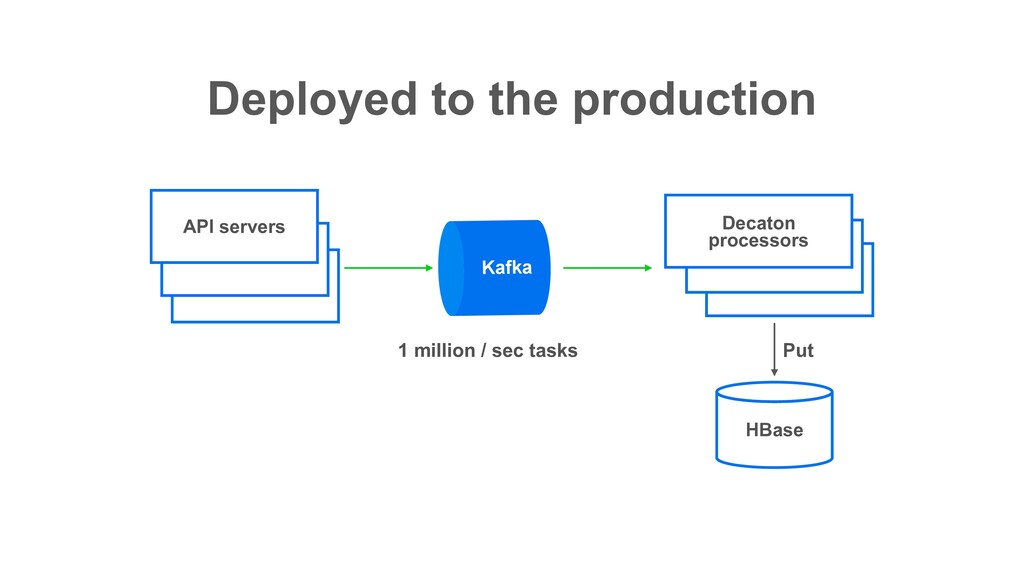
of Apache Kafka • Battle tested in various LINE services for several years • Open sourced in March, 2020 • Various features which make task processing development simple • Can process single partition in multiple threads • Contribute to improve consuming throughput especially for I/O intensive tasks What’s Decaton?
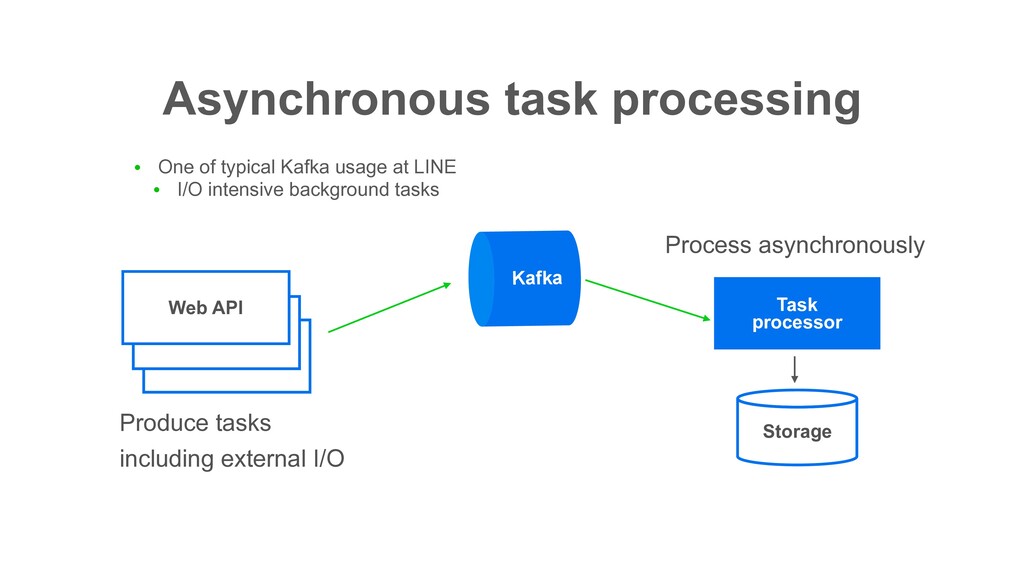
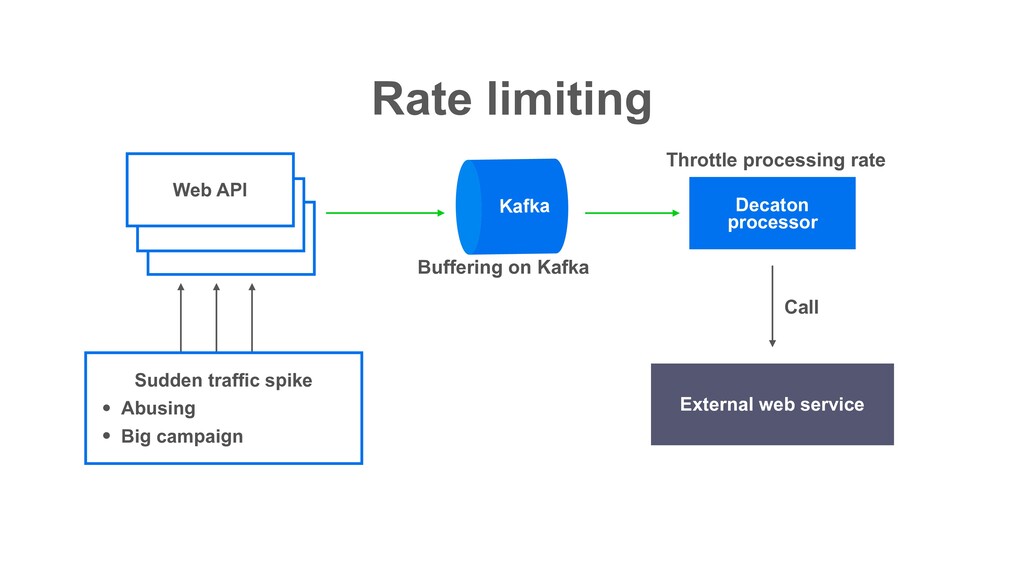
intensive background tasks Asynchronous task processing Task processor Web API Web API Kafka Produce tasks including external I/O Process asynchronously Storage
• However, • Adding partitions often requires contacting cluster administrator • Adding partitions has side effects • Message ordering breaks temporarily • More partitions tends to generate smaller producer batches • Number of open file descriptors / memory-mapped files • Not preferable in LINE circumstance • i.e. Single, multi-tenant shared Kafka cluster Why not adding more partitions?
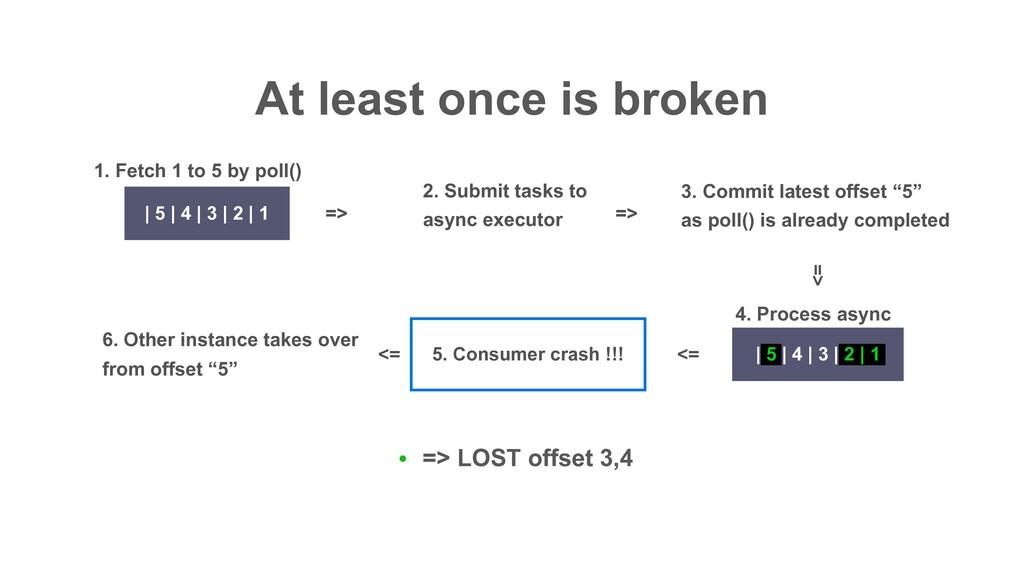
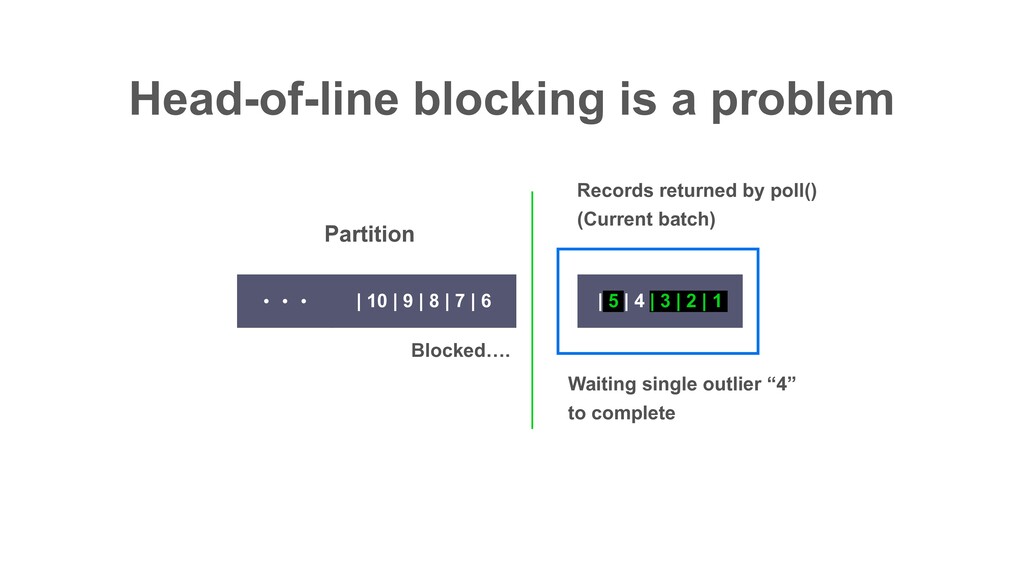
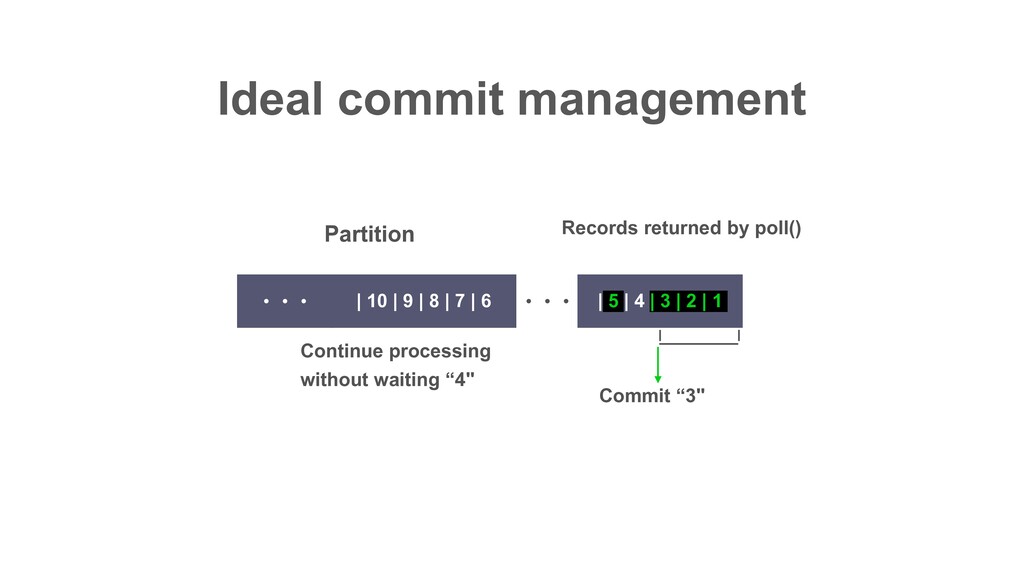
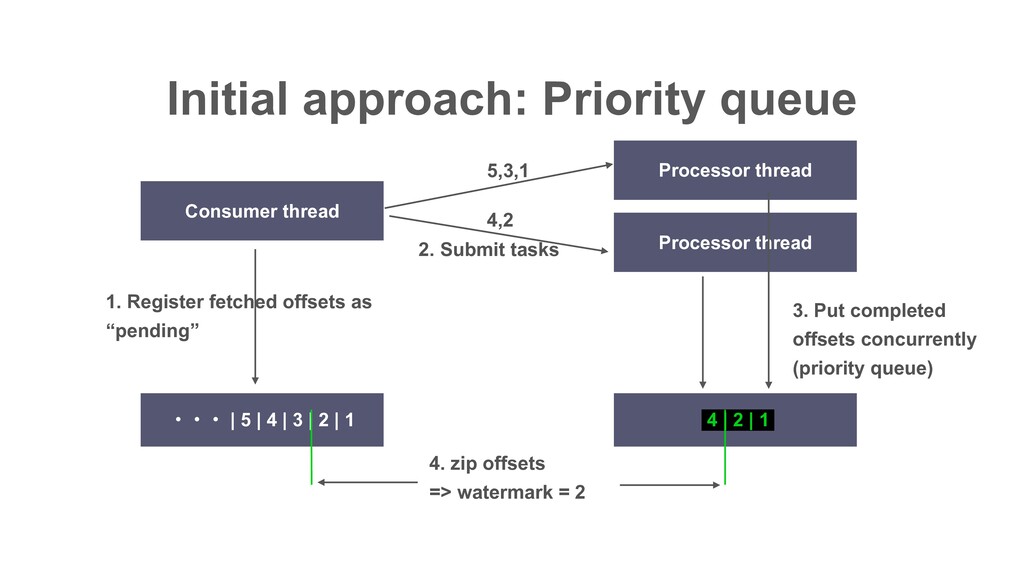
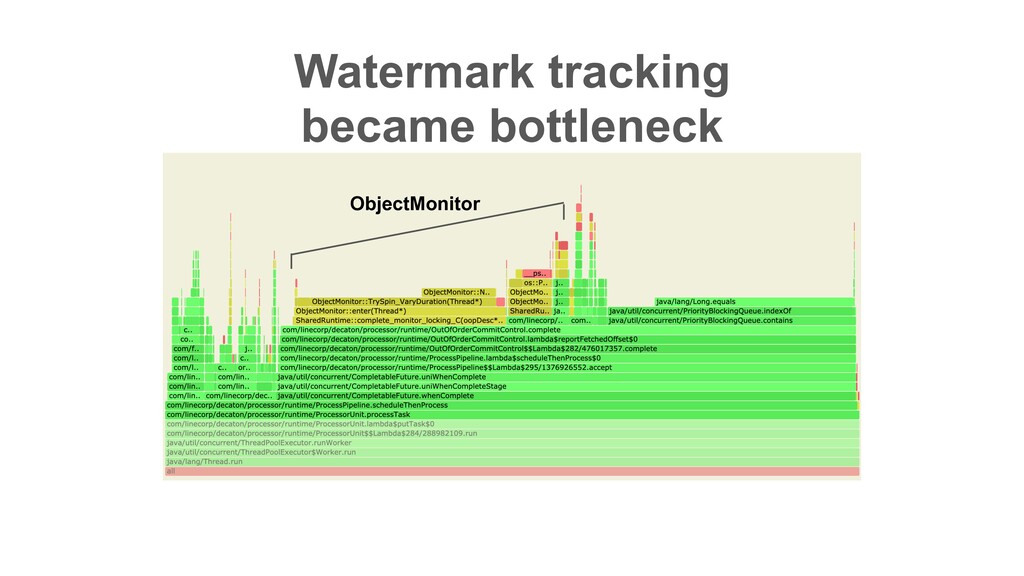
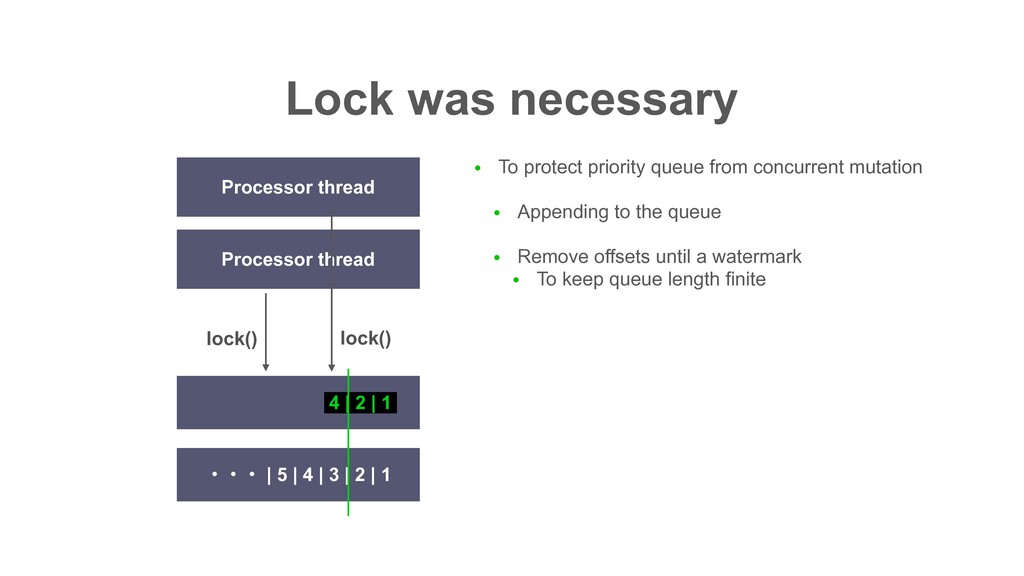
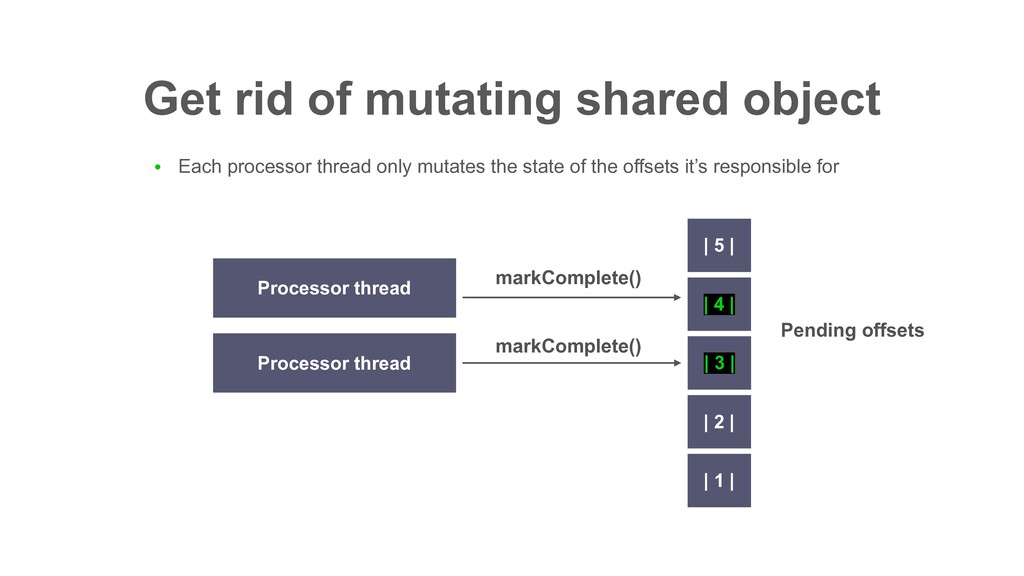
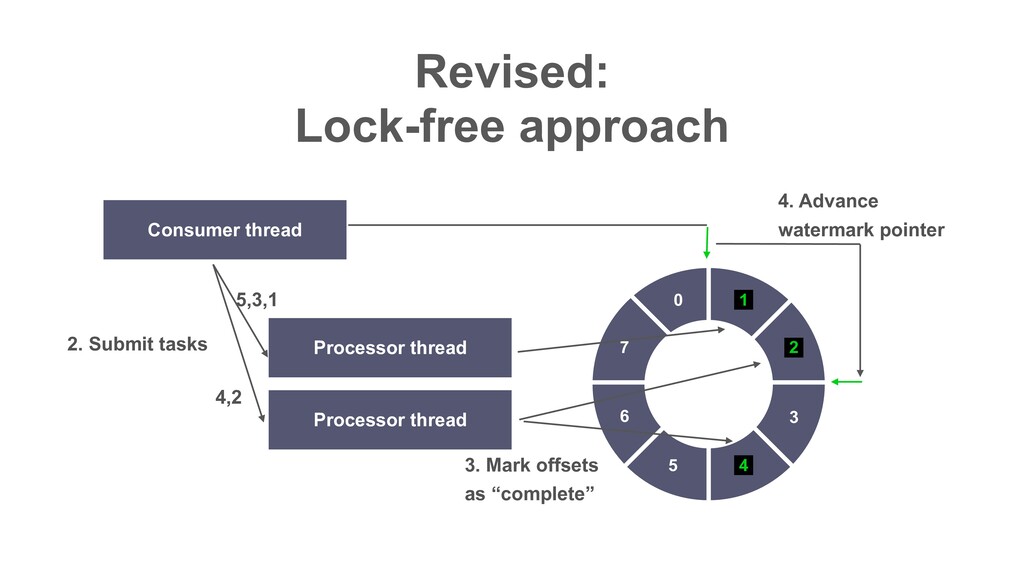
| 2 | 1 | 10 | 9 | 8 | 7 | 6 ɾɾɾ Partition Records returned by poll() ɾɾɾ In Decaton, this offset is called “Watermark” i.e. The highest offset that all preceding offsets are already processed
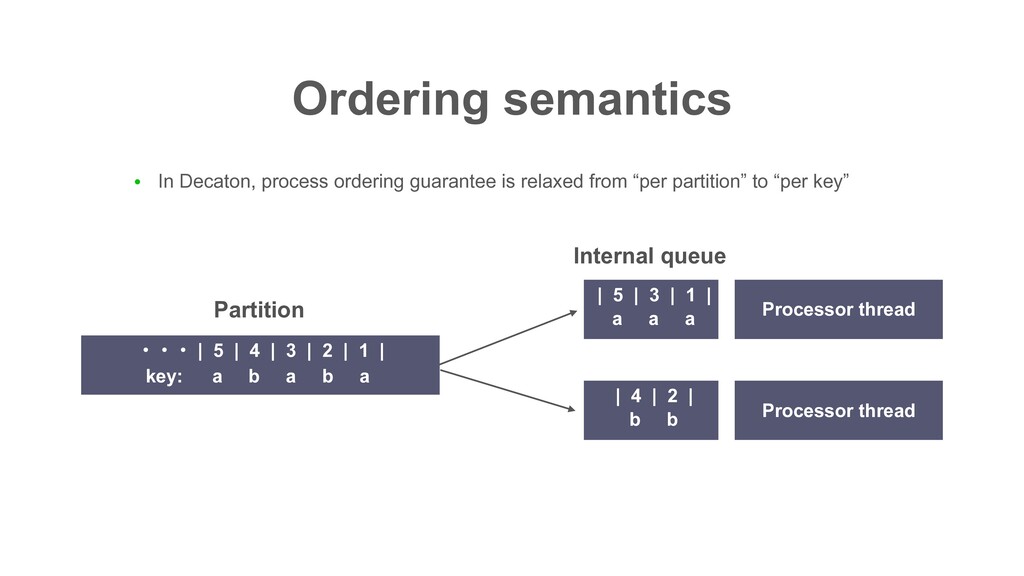
partition” to “per key” Ordering semantics Processor thread Processor thread ɾɾɾ | 5 | 4 | 3 | 2 | 1 | a b a b a key: Partition | 5 | 3 | 1 | a a a Internal queue | 4 | 2 | b b
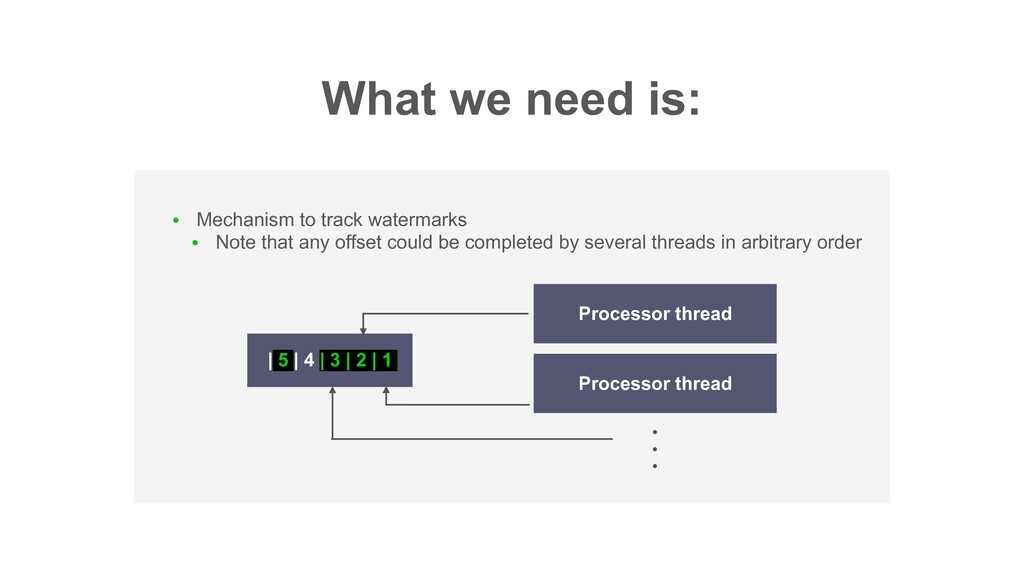
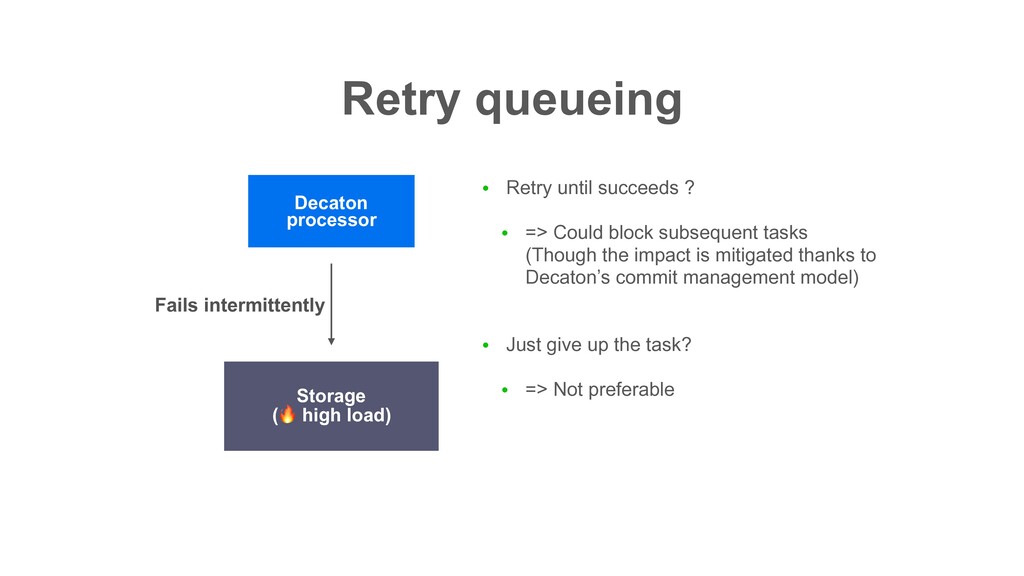
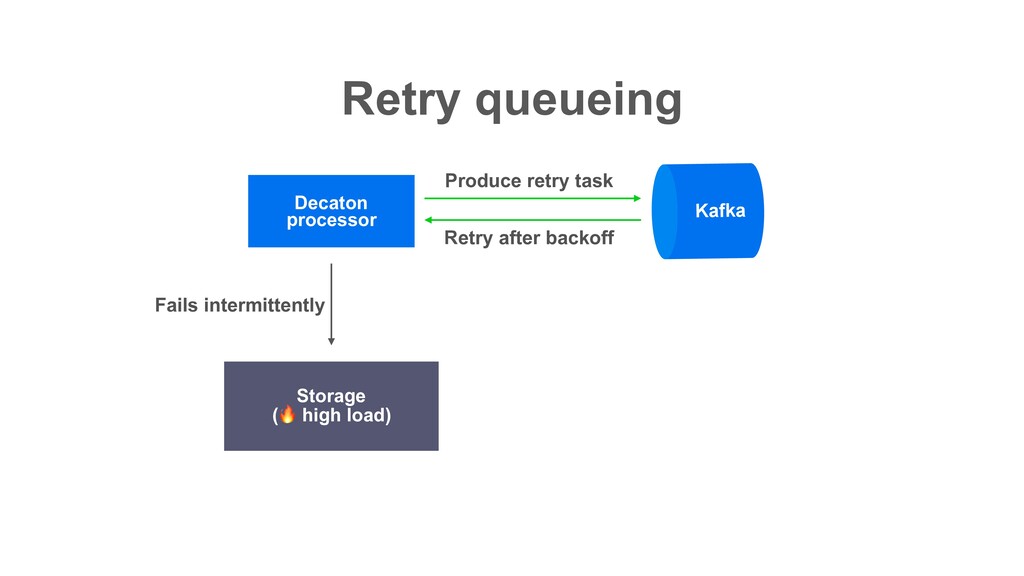
block subsequent tasks (Though the impact is mitigated thanks to Decaton’s commit management model) • Just give up the task? • => Not preferable Decaton processor Storage ( high load) Fails intermittently
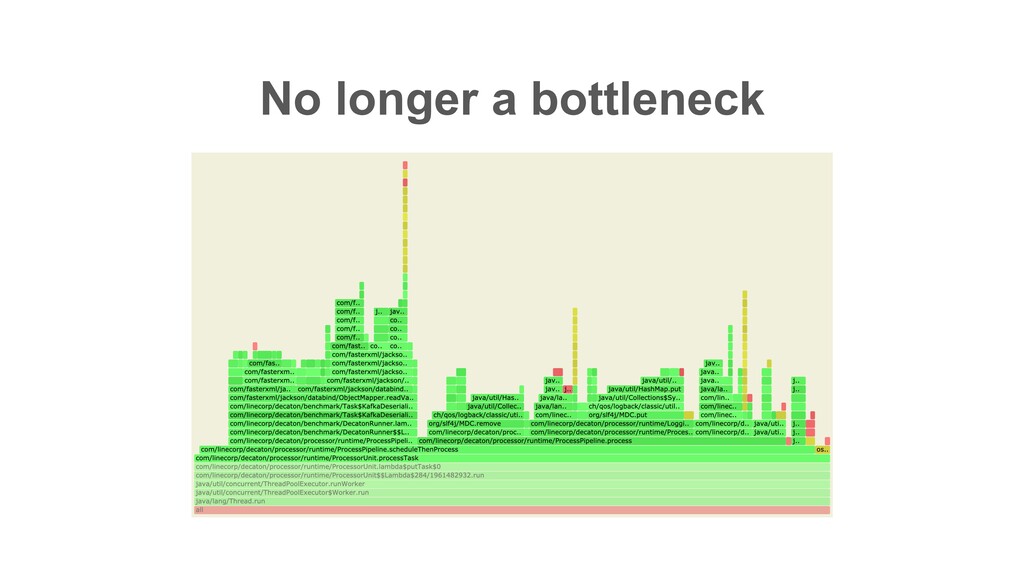
Suites for I/O intensive workload the most • Provides various features which suit for many situations in task processing • Give it a try! • Feedbacks and contributions are welcome Conclusion
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}