Private Cloud Platform Team Lead in LINE • Experience : ◦ OSS Contribution: ▪ rancher/rancher, kubernetes/ingress-nginx, coreos/etcd-operator, openstack/neutron ◦ Presentation: ▪ Japan Container Days v18.12 Keynote (Future of LINE CaaS Platform) ▪ Japan Container Days v18.12 (How we can develop managed k8s service with Rancher) ▪ OpenStack Summit 2018 Vancouver (Excitingly simple multi-path OpenStack Network) ▪ OpenStack Summit 2016 Austin (Swift Private Endpoint) ▪ OpenStack Summit 2015 Tokyo (Automate Deployment & Benchmark) ▪ ….
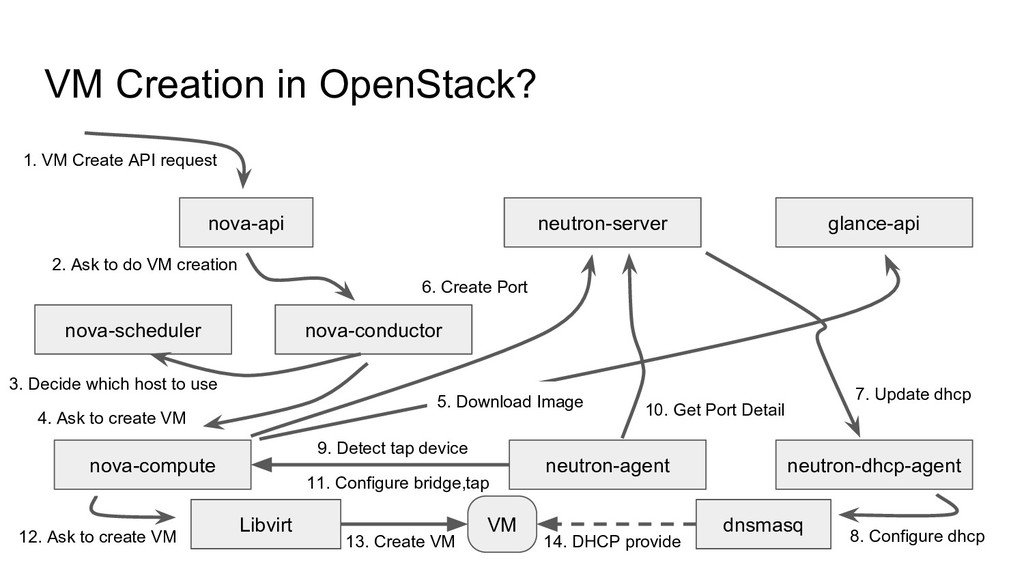
neutron-dhcp-agent glance-api Libvirt VM dnsmasq 1. VM Create API request 2. Ask to do VM creation 3. Decide which host to use 4. Ask to create VM 5. Download Image 6. Create Port 9. Detect tap device 10. Get Port Detail 7. Update dhcp 8. Configure dhcp 11. Configure bridge,tap 12. Ask to create VM 13. Create VM 14. DHCP provide
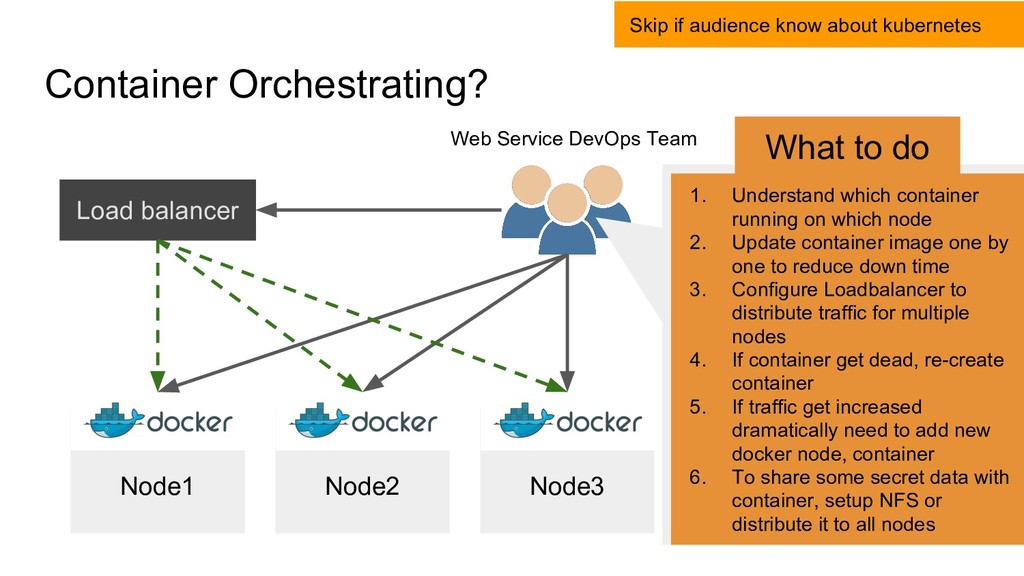
balancer 1. Understand which container running on which node 2. Update container image one by one to reduce down time 3. Configure Loadbalancer to distribute traffic for multiple nodes 4. If container get dead, re-create container 5. If traffic get increased dramatically need to add new docker node, container 6. To share some secret data with container, setup NFS or distribute it to all nodes What to do Skip if audience know about kubernetes
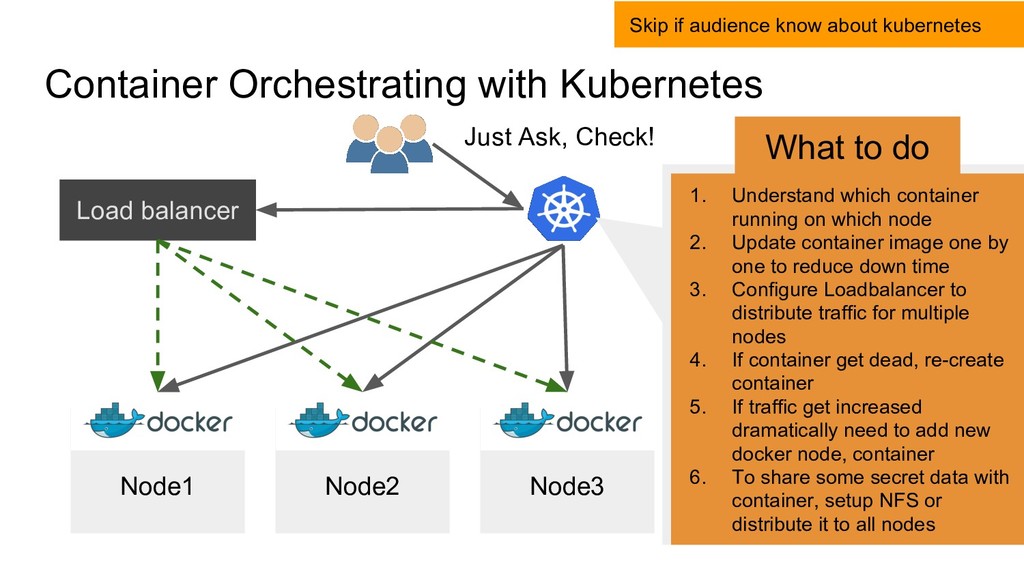
Ask, Check! Skip if audience know about kubernetes 1. Understand which container running on which node 2. Update container image one by one to reduce down time 3. Configure Loadbalancer to distribute traffic for multiple nodes 4. If container get dead, re-create container 5. If traffic get increased dramatically need to add new docker node, container 6. To share some secret data with container, setup NFS or distribute it to all nodes What to do
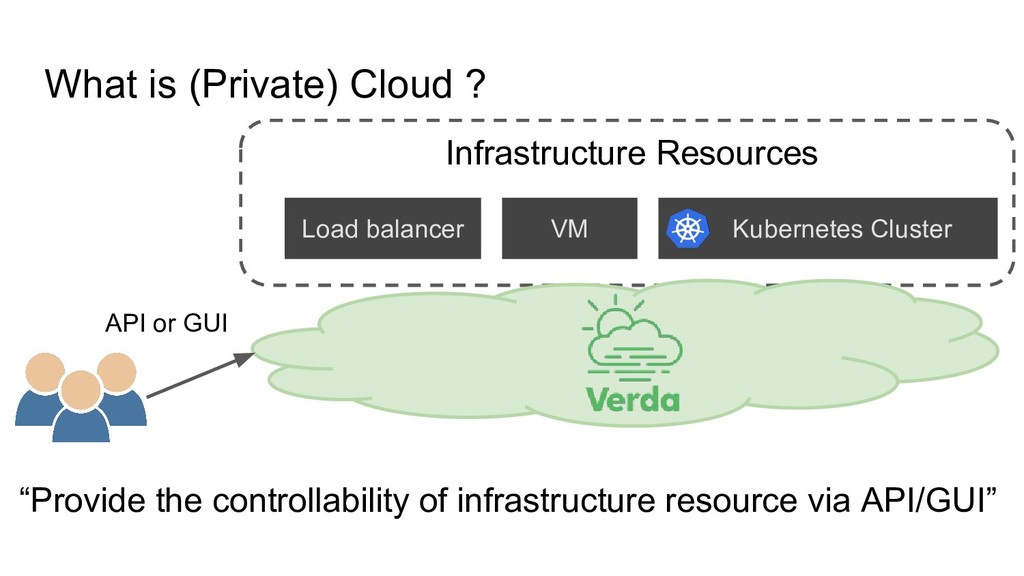
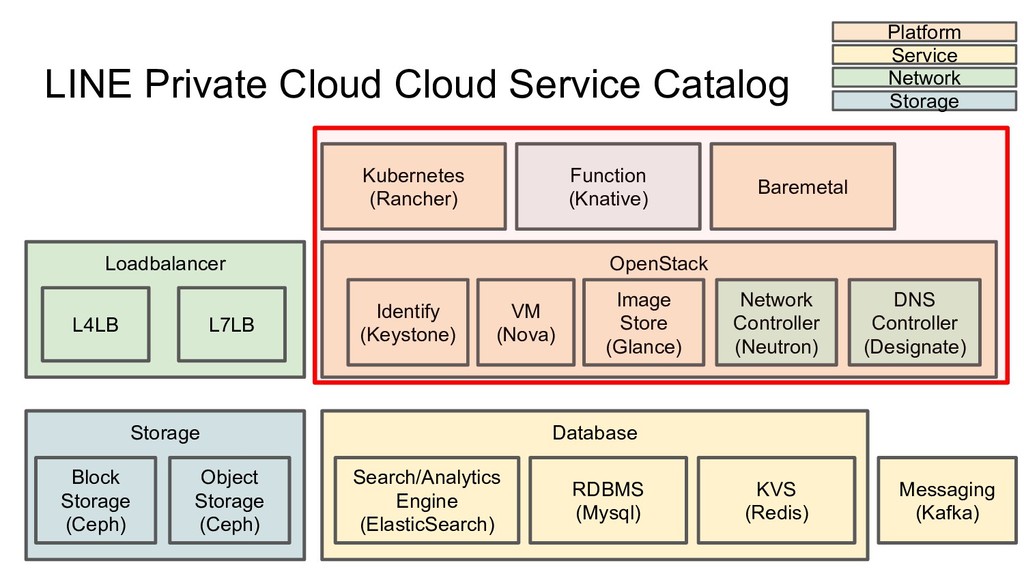
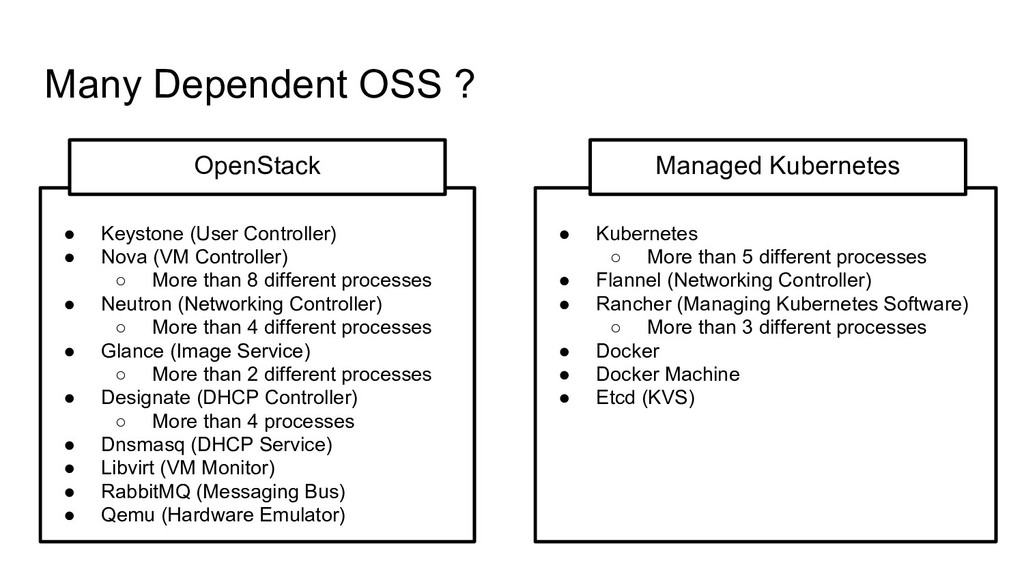
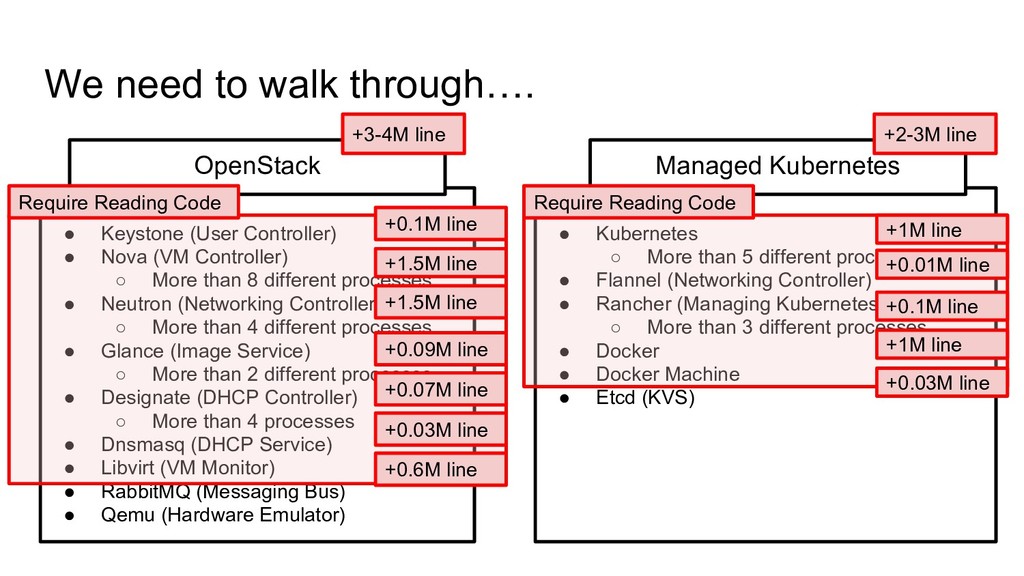
“Networking”, “Virtualization”, “Storage”.... 1. 1 Deployment include “Networking”, “Virtualization”, “Storage”.... 2. Composed of Multiple Process / Node 1. 1 Deployment include “Networking”, “Virtualization”, “Storage”.... 2. Composed of Multiple Process / Node 3. Many Dependent OSS
Nova (VM Controller) ◦ More than 8 different processes • Neutron (Networking Controller) ◦ More than 4 different processes • Glance (Image Service) ◦ More than 2 different processes • Designate (DHCP Controller) ◦ More than 4 processes • Dnsmasq (DHCP Service) • Libvirt (VM Monitor) • RabbitMQ (Messaging Bus) • Qemu (Hardware Emulator) OpenStack • Kubernetes ◦ More than 5 different processes • Flannel (Networking Controller) • Rancher (Managing Kubernetes Software) ◦ More than 3 different processes • Docker • Docker Machine • Etcd (KVS) Managed Kubernetes +0.1M line +1.5M line +1.5M line +0.09M line +0.07M line +0.03M line +0.6M line +3-4M line +1M line +0.01M line +0.1M line +2-3M line Require Reading Code Require Reading Code +1M line +0.03M line
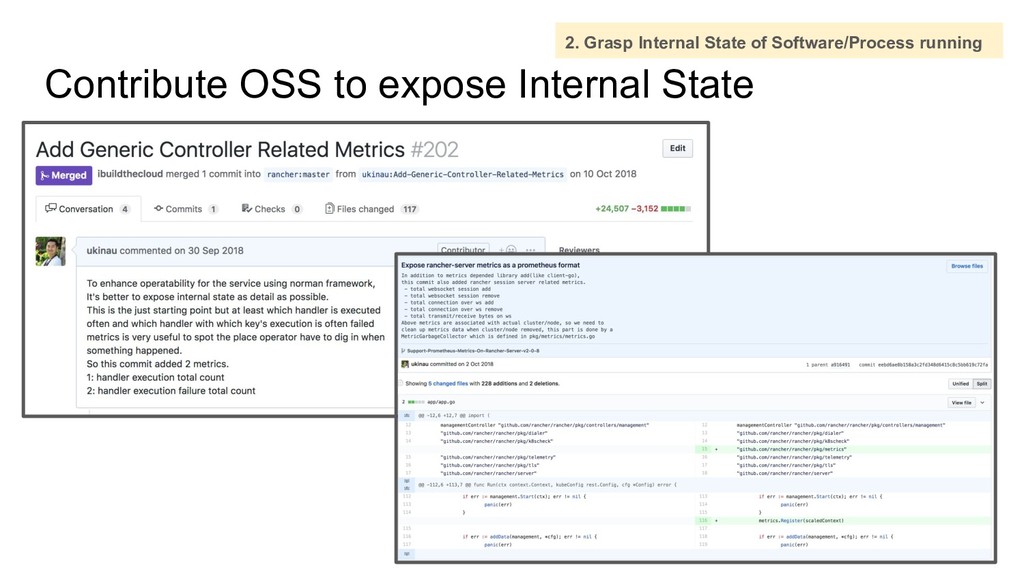
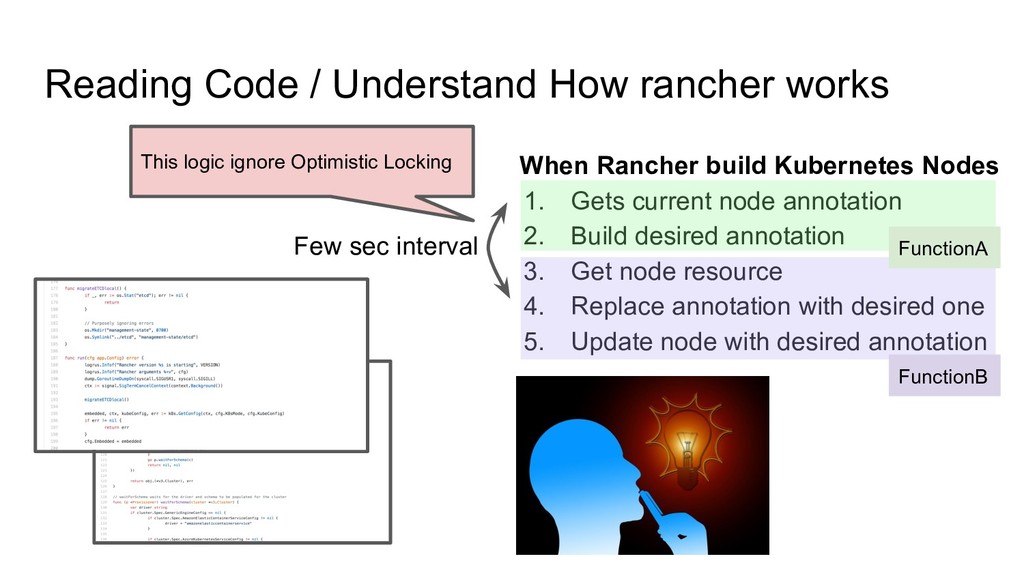
Code until you understood, Don’t believe just document, bug report. 1. Read Code until you understood, Don’t believe just document, bug report. 2. Grasp internal state of software/process running 1. Read Code until you understood, Don’t believe just document, bug report. 2. Grasp internal state of software/process running 3. Understand where problem happened is not always where there is root cause. 1. Read Code until you understood, Don’t believe just document, bug report. 2. Grasp internal state of software/process running 3. Understand where problem happened is not always where there is root cause. 4. Understand which software have what responsibility 1. Read Code until you understood, Don’t believe just document, bug report. 2. Grasp internal state of software/process running 3. Understand where problem happened is not always where there is root cause. 4. Understand which software have what responsibility 5. Don’t stop to investigate/dive into problem until you understood root cause
Code until you understood, Don’t believe just document Architecture/Design Understanding - Documenting is not catching up with Coding - To know more about risk in operation - To improve OSS (not always perfect to us) Bug or Weird Behaviour - Don’t rely on just google, Do effort to solve it by ourselves - Discussion/Communication inside team is based on code.
◦ openstack/neutron (1) • Kubernetes Related ◦ coreos/etcd-operator (1) ◦ kubernetes/ingress-controller (1) ◦ rancher/norman (3) ◦ rancher/types (1) ◦ docker/machine (1) Code Reading Document • https://github.com/ukinau/rancher-analyse • https://www.slideshare.net/linecorp/lets-unbox-rancher-20-v200 We are user for OSS But at the same time, We are developer for OSS 1. Read Code until you understood, Don’t believe just document
Software have internal states like... • Dnsmasq-dhcp (DHCP Server) ◦ The number of DHCP entry ◦ How many times DHCP NACK to be issued ◦ ... • Nginx (WEB Server) ◦ Average Request Processing Time ◦ Average Number of Request ◦ How many requests are pending ◦ …. Dnsmasq-dhcp • 3 entries of dhcp • 1000 times DHCP NACK issued Nginx • 30msec average req processing time • 10k req in min • 200 req are pending (backlog queue) 2. Grasp Internal State of Software/Process running
3 entries of dhcp • 1000 times DHCP NACK issued Nginx • 30msec average req processing time • 10k req in min • 200 req are pending (backlog queue) There seems be client to send unexpected DHCP REQUEST. => Need to review configuration / troubleshoot The number of worker is not enough for actual requests. => Need to run more nginx or Increase worker 2. Grasp Internal State of Software/Process running
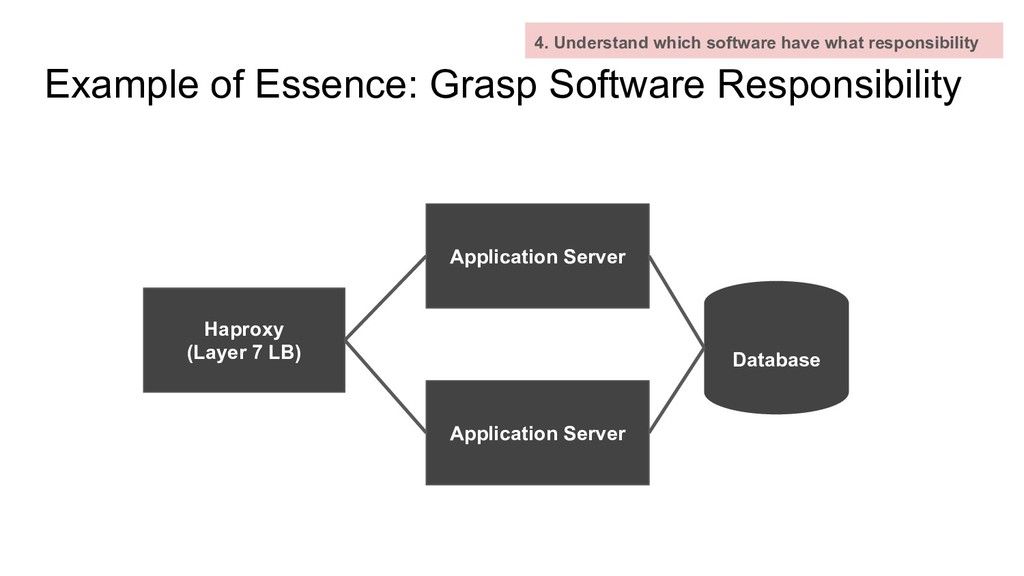
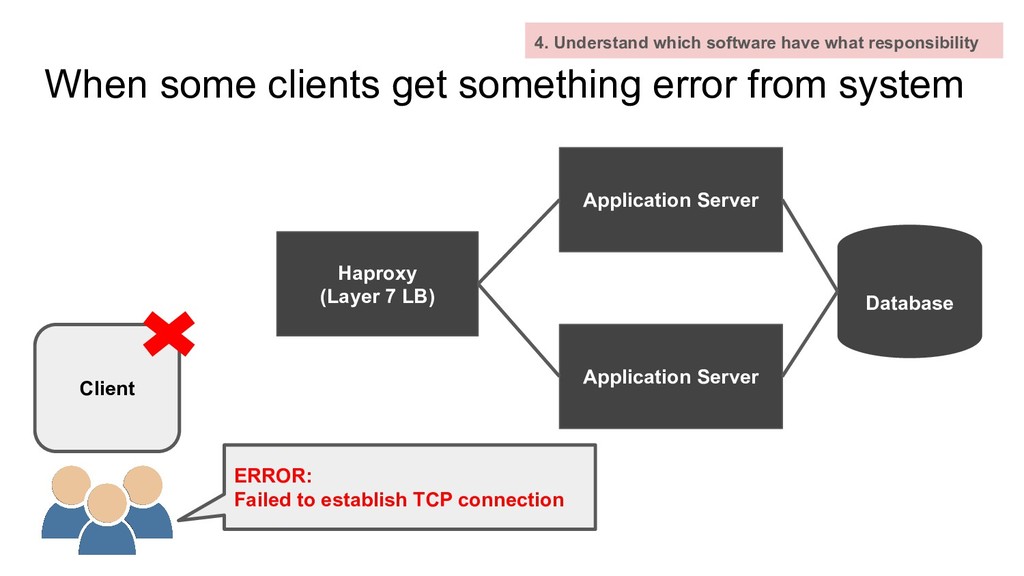
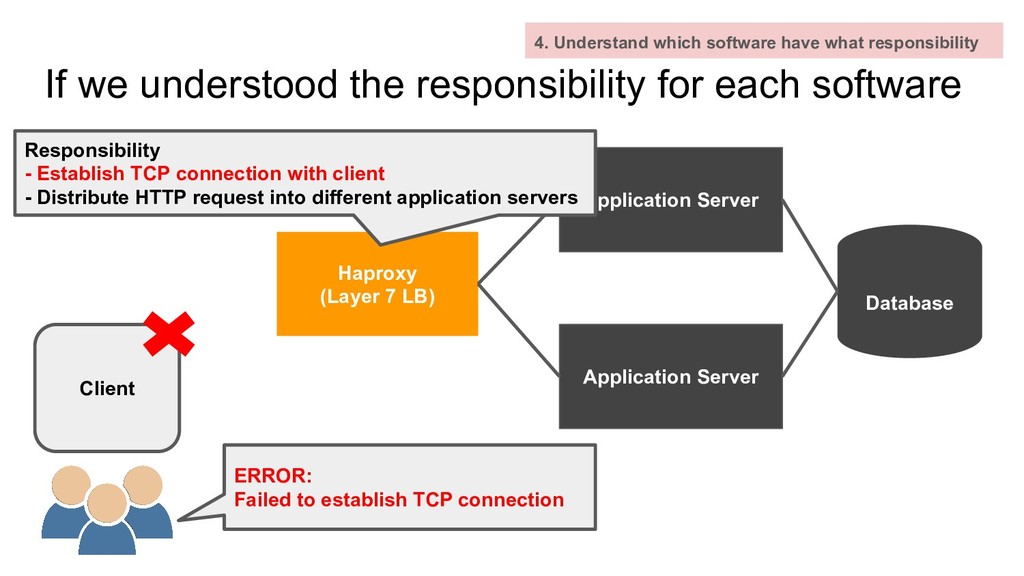
which software have what responsibility Haproxy (Layer 7 LB) Application Server Application Server Database Client ERROR: Failed to establish TCP connection
which software have what responsibility Haproxy (Layer 7 LB) Application Server Application Server Database Client ERROR: Failed to establish TCP connection Responsibility - Establish TCP connection with client - Distribute HTTP request into different application servers
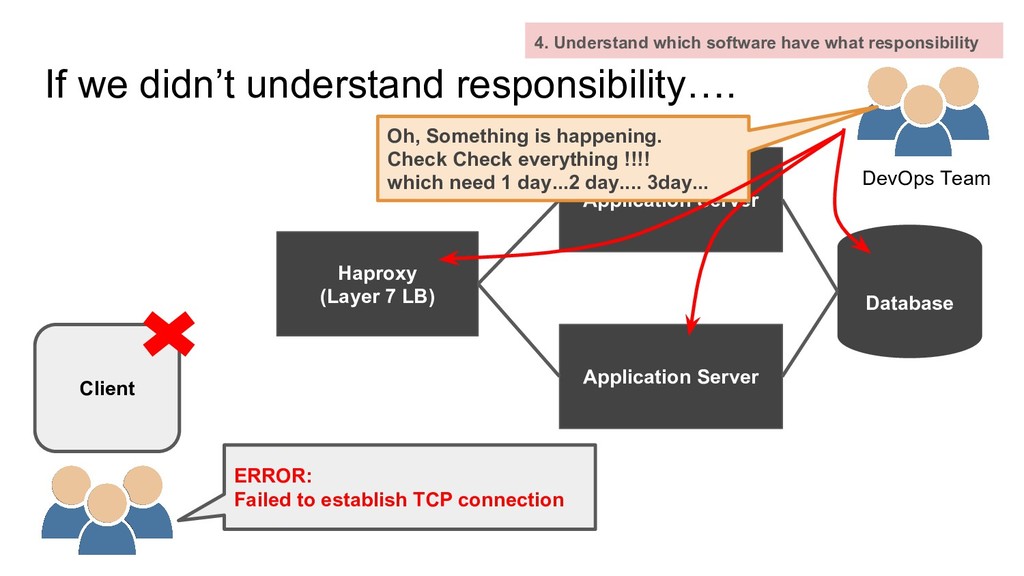
Server Application Server Database Client ERROR: Failed to establish TCP connection DevOps Team Oh, Something is happening. Check Check everything !!!! which need 1 day...2 day.... 3day... 4. Understand which software have what responsibility
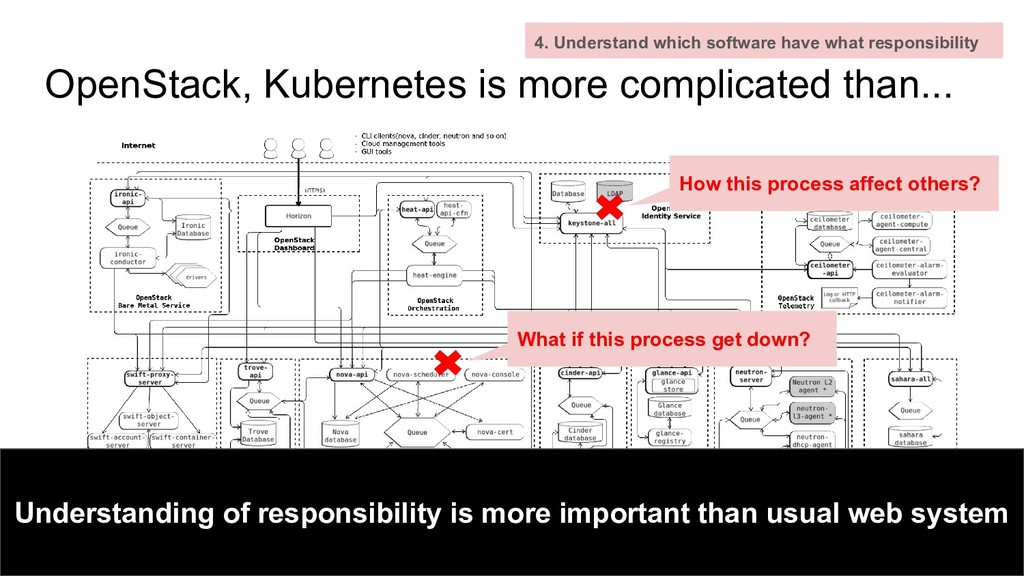
have what responsibility What if this process get down? How this process affect others? Understanding of responsibility is more important than usual web system
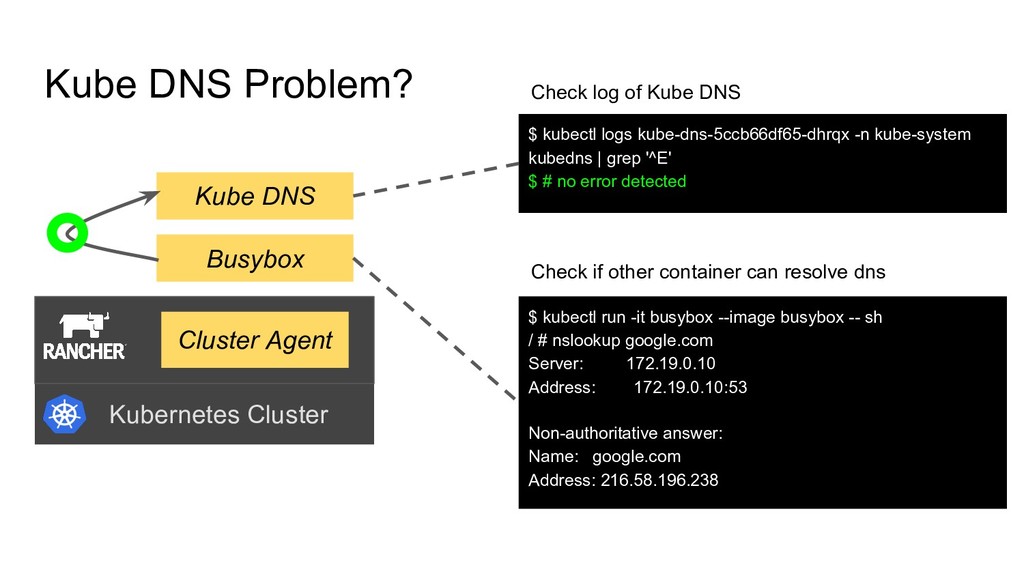
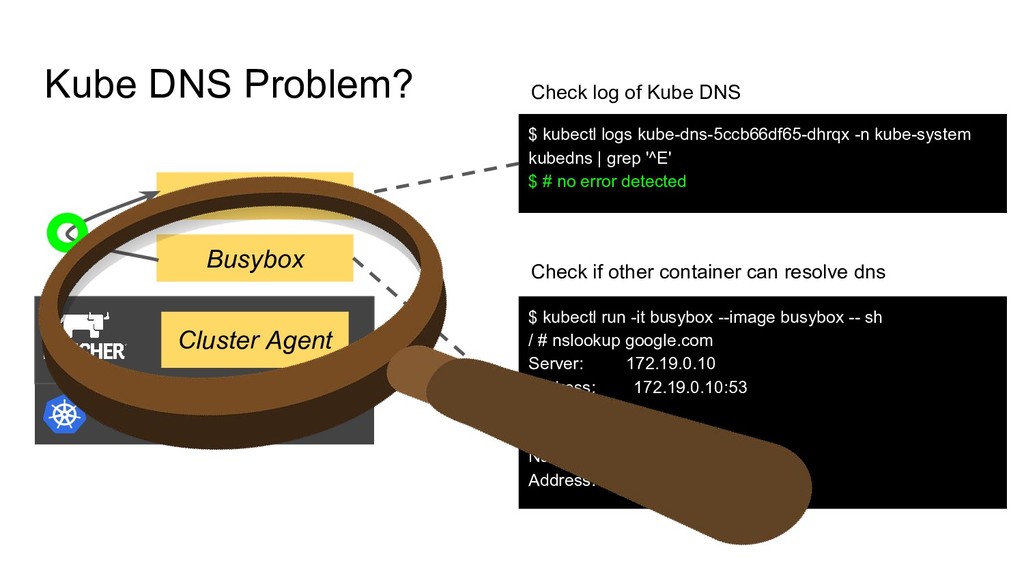
| grep '^E' $ # no error detected Kubernetes Cluster Cluster Agent Kube DNS Busybox $ kubectl run -it busybox --image busybox -- sh / # nslookup google.com Server: 172.19.0.10 Address: 172.19.0.10:53 Non-authoritative answer: Name: google.com Address: 216.58.196.238 Check log of Kube DNS Check if other container can resolve dns
| grep '^E' $ # no error detected Kubernetes Cluster Cluster Agent Kube DNS Busybox $ kubectl run -it busybox --image busybox -- sh / # nslookup google.com Server: 172.19.0.10 Address: 172.19.0.10:53 Non-authoritative answer: Name: google.com Address: 216.58.196.238 Check log of Kube DNS Check if other container can resolve dns
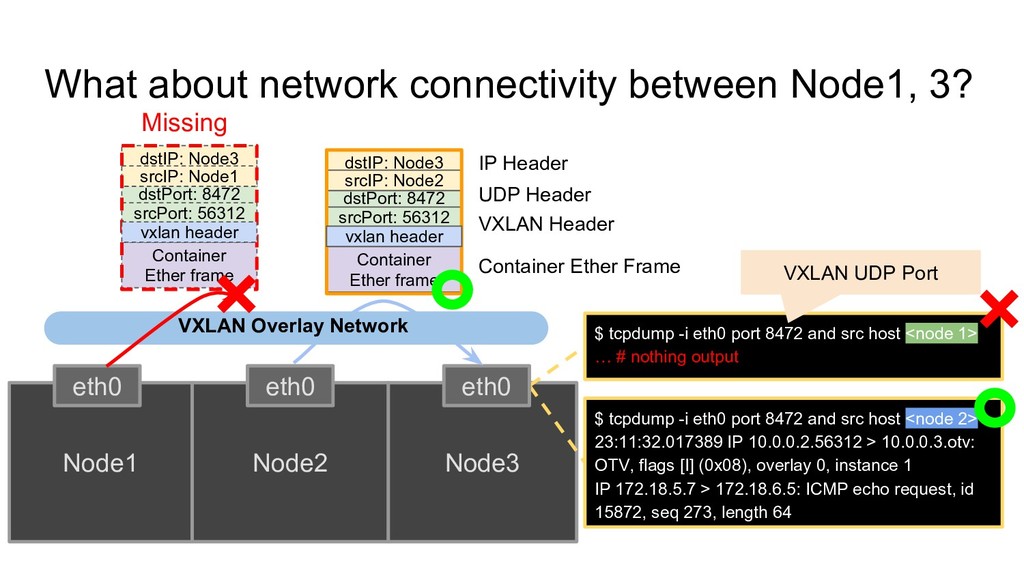
used to connect Linux Containers • Flannel support multiple backends like vxlan, ipip…. Responsibility of Flannel in our case? • Configure Linux kernel to create termination device of overlay network • Configure Linux kernel to route, bridge, related sub-system
flannel.1 172.17.2.0/24 dev cni 172.17.3.0/24 via 172.17.3.0 dev flannel.1 ARP cache 172.17.1.0 flannel.1 lladdr aa:aa:aa:aa:aa:aa 172.17.3.0 flannel.1 lladdr cc:cc:cc:cc:cc:cc FDB aa.aa.aa.aa.aa.aa dev flannel.1 dst 10.0.0.1 cc.cc.cc.cc.cc.cc dev flannel.1 dst 10.0.0.3 Routing table 172.17.2.0/24 via 172.17.2.0 dev flannel.1 172.17.3.0/24 dev cni ARP cache 172.17.2.0 flannel.1 lladdr bb.bb.bb.bb.bb.bb FDB bb.bb.bb.bb.bb.bb dev flannel.1 dst 10.0.0.2 Routing table 172.17.1.0/24 dev cni 172.17.2.0/24 via 172.17.2.0 dev flannel.1 172.17.3.0/24 via 172.17.3.0 dev flannel.1 ARP cache 172.17.2.0 flannel.1 lladdr bb:bb:bb:bb:bb:bb 172.17.3.0 flannel.1 lladdr cc:cc:cc:cc:cc:cc FDB bb.bb.bb.bb.bb.bb dev flannel.1 dst 10.0.0.2 cc.cc.cc.cc.cc.cc dev flannel.1 dst 10.0.0.3 Node1 Node2 Node3 Node1 related information has been missing • 172.17.1.0/24 via 172.17.1.0 dev flannel.1 • 172.17.1.0 flannel.1 lladdr aa:aa:aa:aa:aa:aa • Aa.aa.aa.aa.aa.aa dev flannel.1 dst 10.0.0.1
node specific metadata into k8s node annotation when flannel start • flannel setup route, fdb, arp cache if there is a node with flannel annotation Flannel Agent will $ kubectl get node yuki-testc1 -o yaml apiVersion: v1 kind: Node Metadata: Annotations: flannel.alpha.coreos.com/backend-data: '{"VtepMAC":"9a:4f:ef:9c:2e:2f"}' flannel.alpha.coreos.com/backend-type: vxlan flannel.alpha.coreos.com/kube-subnet-manager: "true" flannel.alpha.coreos.com/public-ip: 10.0.0.1 All Nodes should have these annotation
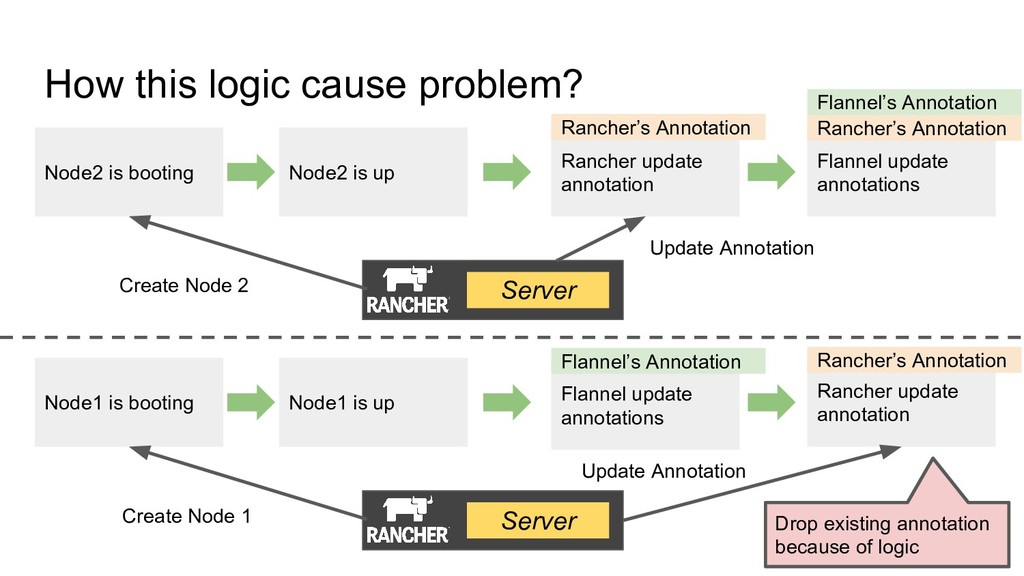
is up Node2 is booting Flannel update annotations Rancher update annotation Server Node1 is up Node1 is booting Flannel update annotations Create Node 2 Update Annotation Rancher’s Annotation Rancher’s Annotation Flannel’s Annotation Flannel’s Annotation Rancher’s Annotation Update Annotation Create Node 1 Drop existing annotation because of logic
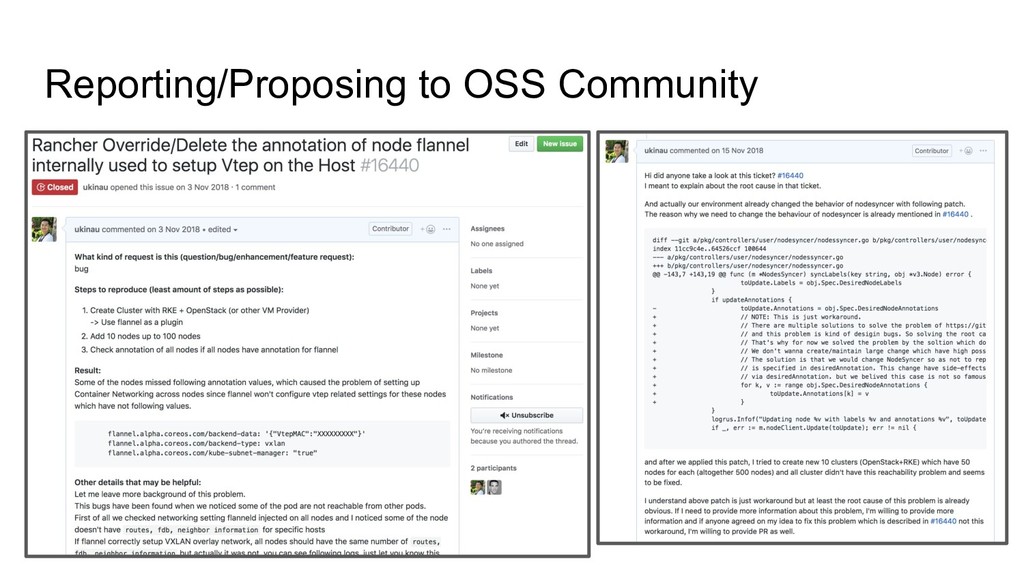
index 11cc9c4e..64526ccf 100644 --- a/pkg/controllers/user/nodesyncer/nodessyncer.go +++ b/pkg/controllers/user/nodesyncer/nodessyncer.go @@ -143,7 +143,19 @@ func (m *NodesSyncer) syncLabels(key string, obj *v3.Node) error { toUpdate.Labels = obj.Spec.DesiredNodeLabels } if updateAnnotations { - toUpdate.Annotations = obj.Spec.DesiredNodeAnnotations + // NOTE: This is just workaround. + // There are multiple solutions to solve the problem of https://github.com/rancher/rancher/issues/13644 + // and this problem is kind of desigin bugs. So solving the root cause of problem need design decistions. + // That's why for now we solved the problem by the soltion which don't have to change many places. Because + // We don't wanna create/maintain large change which have high possibility not to be merged in upstream + // Rancher Community tend to hesitate to merge big change created by engineer not from Rancher Lab + + // The solution is to change NodeSyncer so as not to replace annotation with desiredAnnotations but just update annotations which + // is specified in desiredAnnotation. This change have side-effects that disable for user to delete exisiting annotation + // via desiredAnnotation. but we belived this case is not so famous so we chose this solution + for k, v := range obj.Spec.DesiredNodeAnnotations { + toUpdate.Annotations[k] = v
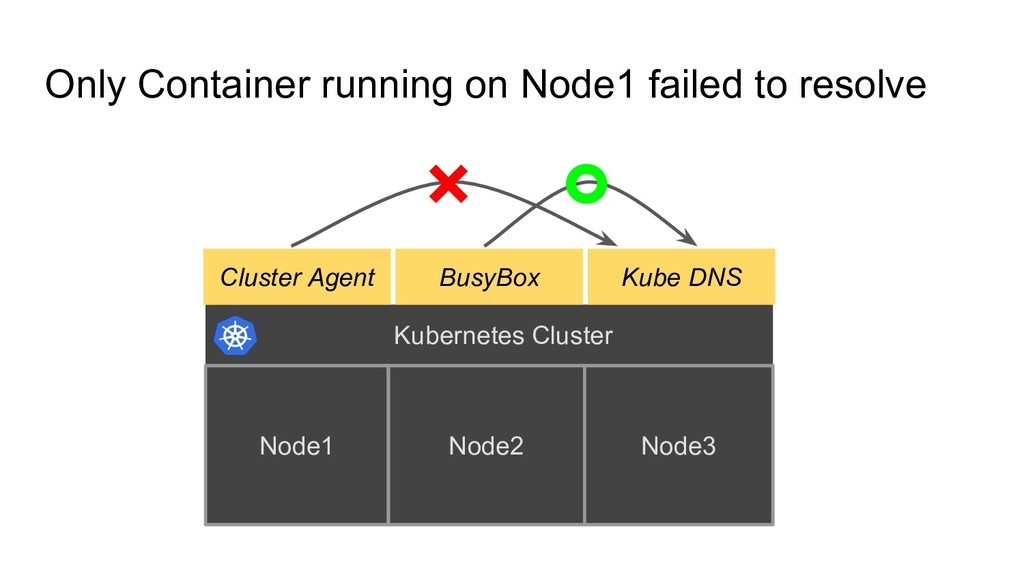
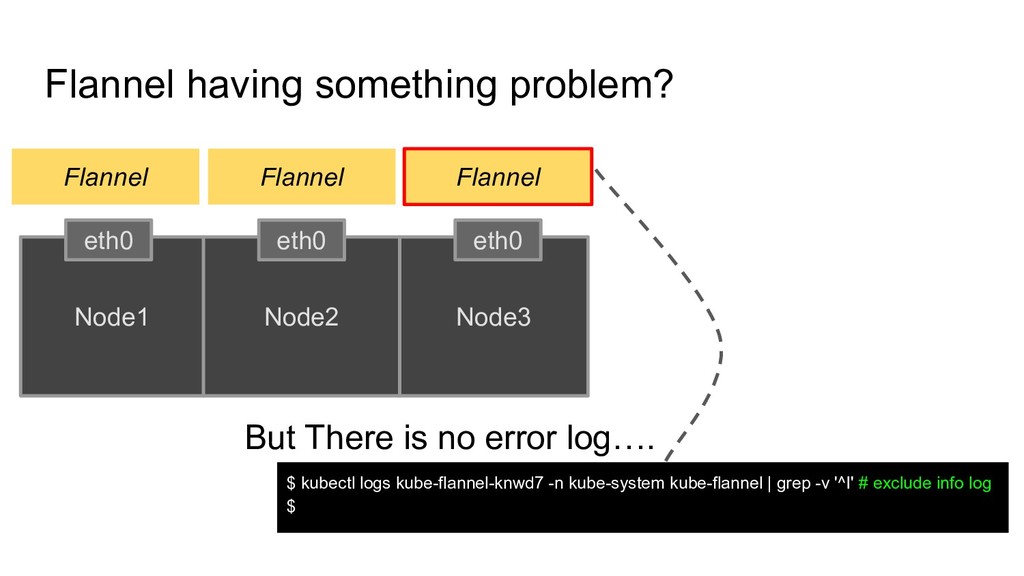
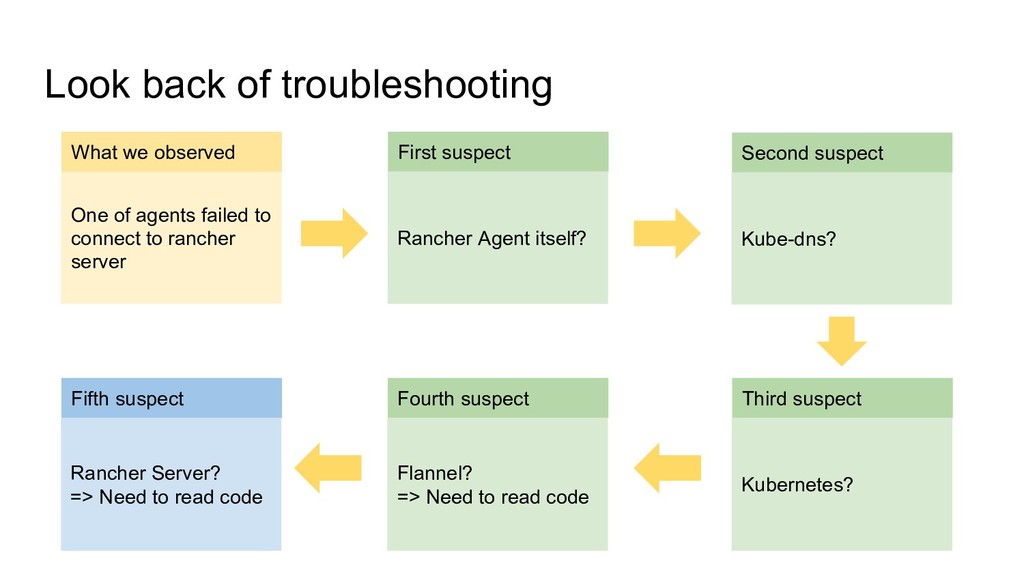
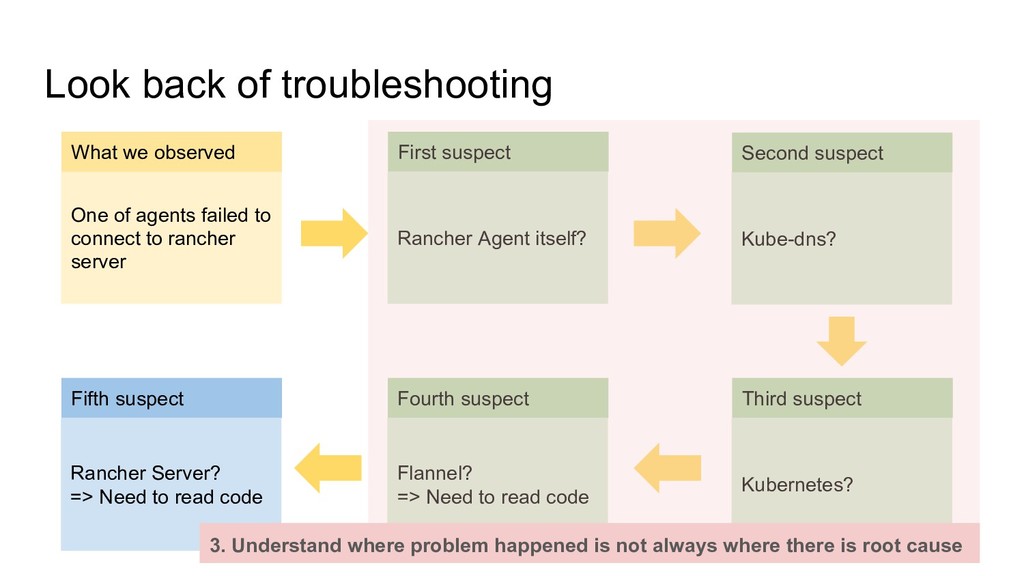
to rancher server First suspect Rancher Agent itself? Second suspect Kube-dns? Third suspect Kubernetes? Fifth suspect Rancher Server? => Need to read code Fourth suspect Flannel? => Need to read code What we observed
to rancher server First suspect Rancher Agent itself? Second suspect Kube-dns? Third suspect Kubernetes? Fifth suspect Rancher Server? => Need to read code Fourth suspect Flannel? => Need to read code What we observed 3. Understand where problem happened is not always where there is root cause
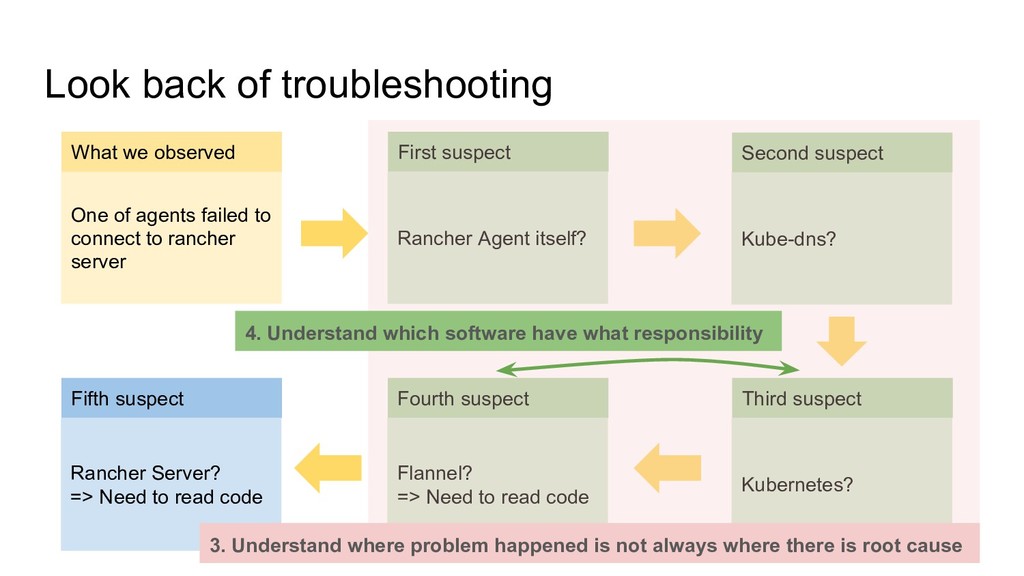
to rancher server First suspect Rancher Agent itself? Second suspect Kube-dns? Third suspect Kubernetes? Fifth suspect Rancher Server? => Need to read code Fourth suspect Flannel? => Need to read code What we observed 3. Understand where problem happened is not always where there is root cause 4. Understand which software have what responsibility
to rancher server First suspect Rancher Agent itself? Second suspect Kube-dns? Third suspect Kubernetes? Fifth suspect Rancher Server? => Need to read code Fourth suspect Flannel? => Need to read code What we observed 3. Understand where problem happened is not always where there is root cause 4. Understand which software have what responsibility 5. Don’t stop to investigate/dive into problem until you understood root cause => There was chance to stop to dive into and Do just workaround for now • Second Suspect (Kube DNS): As some internet information described, If we deployed kube dns on all nodes, this problem seems be hidden • Fourth Suspect (Flannel): If we just thought flannel annotation get disappeared for trivial reason and manually fixed annotation, this problem seems be hidden.
Code until you understood, Don’t believe just document, bug report. 2. Grasp internal state of software/process running 3. Understand where problem happened is not always where there is root cause. 4. Understand which software have what responsibility 5. Don’t stop to investigate/dive into problem until you understood root cause Remind:
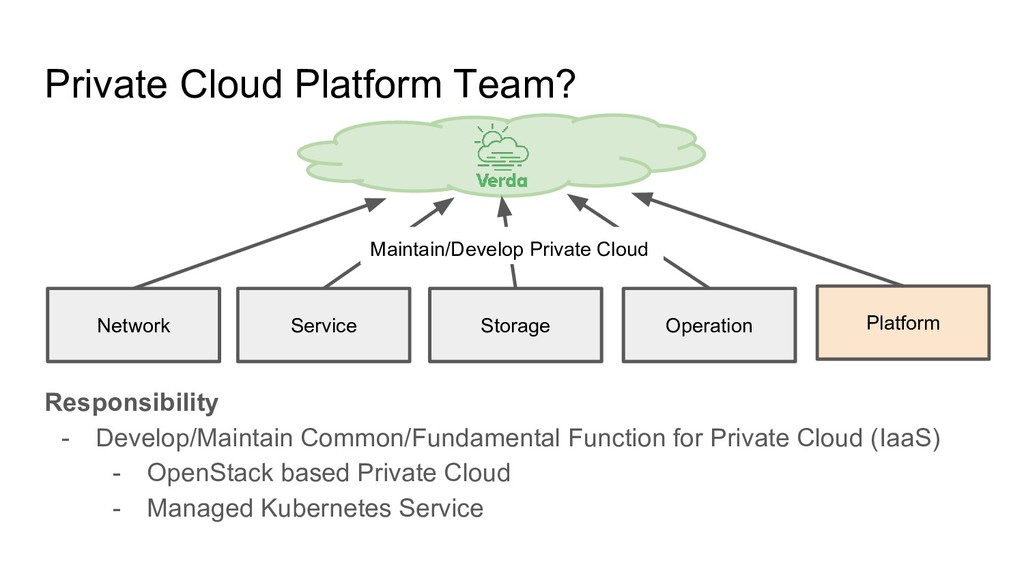
stack of technology ◦ Microservice/Distributed System Operation Knowledge ◦ Reading Large Amount of Code ◦ Many Dependent OSS e.g. OpenStack, Kubernetes, Rancher, Docker…. ◦ Networking e.g. OS Networking, Overlay Network ◦ Virtualization e.g. Container, Libvirt/KVM • Strong problem solving skill ◦ Troubleshooting tend to be complicated like cascade disaster • Mind to communicate/contribute to OSS Community ◦ As much as possible, we want to follow upstream development to reduce costs • Continuously learning new tech deeply ◦ Don’t finish just playing for new tech! There are many chances to improve ourselves
getting bigger ◦ More Region (Current: 3 Regions) ◦ More Hypervisors (Current: +1000 HV) ◦ More Cluster for Specific Use Case • Enhance Operation (Making Operation Easy) ◦ To be able to Operate Large Scale of Cloud with small team • Make Cloud Native Related Component Production Ready ◦ Managed Kubernetes Service is not production ready yet...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}