since batch creation at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java: 98) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:67) at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:30) at ... => Producer lost some messages 😨 One day…
continuously • e.g. NotEnoughReplicas, NotLeaderForPartition,… • => No. There’s no client log which indicates error response • Case 2: Produce request latency is too high against production rate Possible cause of batch expiration
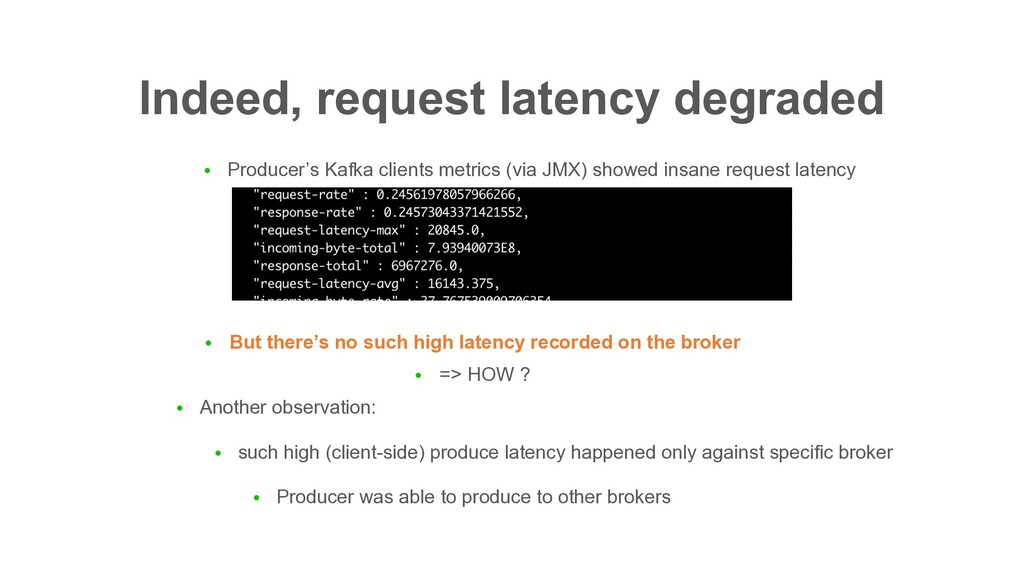
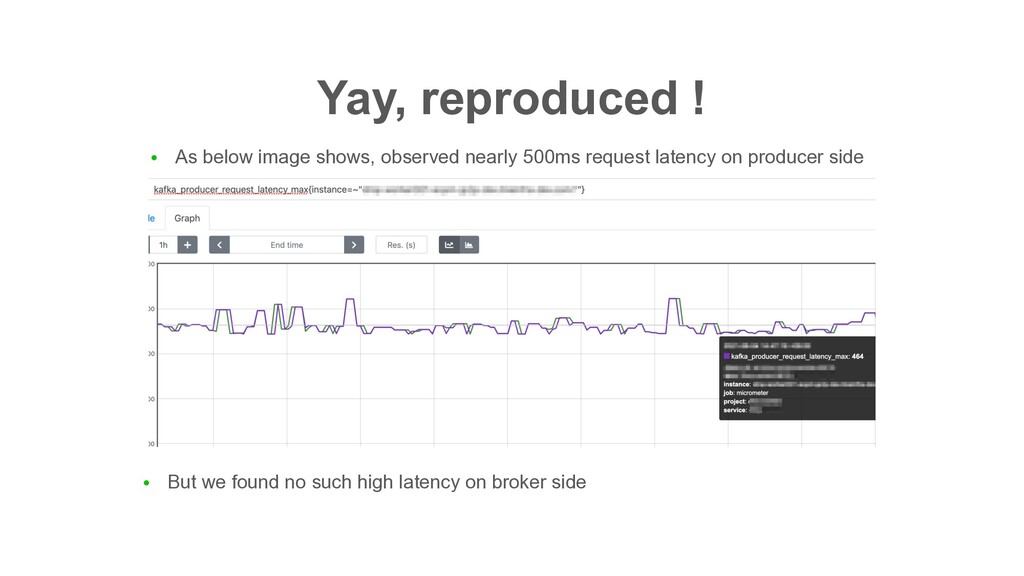
JMX) showed insane request latency • But there’s no such high latency recorded on the broker • => HOW ? • Another observation: • such high (client-side) produce latency happened only against specific broker • Producer was able to produce to other brokers
so we had to handle it ASAP • We were still not sure about the root cause, but the phenomenon started right after we restarted Kafka process on the broker • => We decided to restart the broker again. • => Hun, worked like a charm… (and lost environment for investigation)
we restarted a broker • While there’s no such slow latency observed on broker side • Possible cause: • Case 1: Producer slowed down entirely (e.g. Sender thread blocking) • => No, because the producer could produce to other brokers • Case 2: Network performance degraded Current observation
to complete sending request” only included in client-side’s latency • => Broker/Producer latency discrepancy could happen if sending-out request delays
flood attack • Attackers try to open massive TCP connections to a server from many (likely spoofed) source IPs • Server’s SYN queue will be filled up, then “innocent” clients may be refused => Denial of service • SYN cookies is a “stateless” way to handle SYN packets • In case of flood, server embeds necessary info into SYN+ACK packet by carefully choosing initial-sequence-number, then reply and forget (without storing in SYN queue) • When “innocent” clients replied “ACK”, server decodes embedded info from it
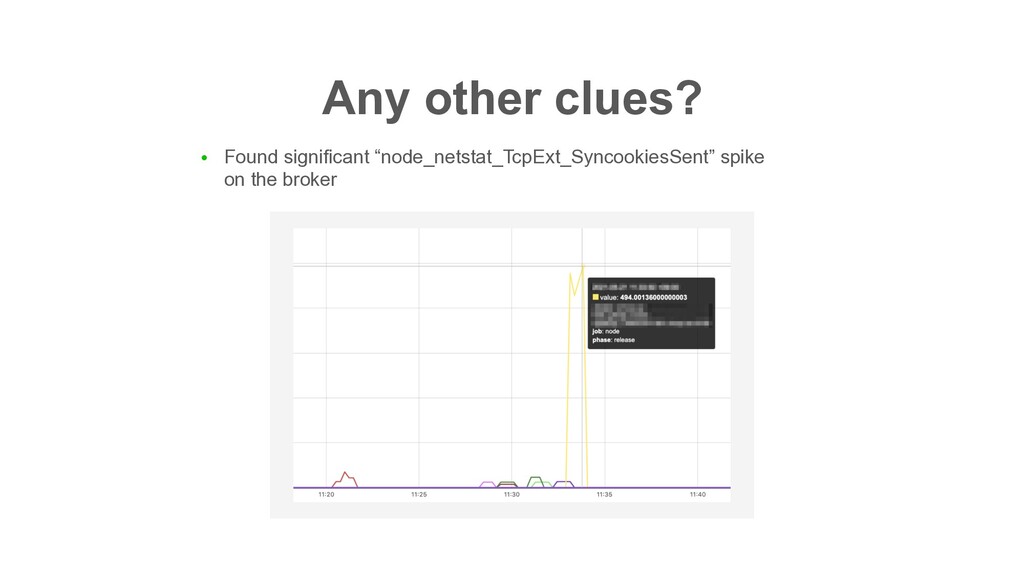
execute preferred leader election (PLE) after it became in-sync • Many clients try to open TCP connection in a short period • => Linux kernel detected “flood” 😇
options (especially window scaling-factor) can be dropped if TCP timestamp is disabled, and causes throughput degradation • Since TCP sequence-number is a 32bit field, it’s not enough to fully store encoded TCP options • But linux kernel can use TCP timestamp field additionally to store full info if it’s enabled
environment by default • SYN cookies should not drop any TCP options • Also, even if window-scaling option is dropped, it should not cause such significant throughput degradation • Window-scaling is a way to extend TCP window size beyond 2^16 (uint16-max) by multiplying window size by 2^scaling_factor • Effective on large-latency connection (like internet) by reducing acks • But 2^16 should be sufficient on our env (i.e. network latency is < 1ms)
cookies can be the cause at that moment, digging into it sounds somewhat worthwhile at least • Experiment: Force SYN cookies to be used for every incoming TCP connections • Can be done by setting `net.ipv4.tcp_syncookies = 2`
tcpdump this time • Surprisingly, tcpdump shows: • producer is waiting ack from broker for every packets • Also, every acks from broker delayed for 40ms • Likely because producer is generating too small packets (TCP delayed ack)
Compiler Collection) script to dump “actual” window scaling factor that broker uses by attaching kprobe for `__tcp_select_window` function • https://github.com/ocadaruma/mybcc/blob/main/tools/tcp_wnd.py • As the result, we found broker actually uses `7` for scaling-factor to calculate window size, while advertised scaling-factor (to producer) is `1`
https://github.com/torvalds/linux/commit/909172a149749242990a6e64cb55d55460d4e417 • Kernel calculated initial window differently when a connection is established through SYN cookies • It caused inconsistency in advertised scaling-factor and actual one after establishment
upon broker-restart causes many clients to open connection in a short period, then SYN queue filled up • => 2. Meanwhile, some producer connections fall-back to be established through SYN cookies • => 3. Due to kernel bug, window scaling-factor became inconsistent between broker/producer. Broker: `advertised_window = window >> 7`, Producer: `window = advertised_window << 1` • => 4. Producer waits ack from broker too frequently due to small window size. At the same time, broker delayed acks because sufficient data isn’t received. • => 5. Producer starts to take insanely long time to complete sending out request.
are dropped when SYN queue full, clients will reconnect soon (SYN retries) • Drawback: • Extra delay will be added until successful connection • (Additionally) Increase listen socket’s backlog size • As of Kafka 2.8.1, backlog size is hardcoded value (50) so we can’t configure it • Reported and discussing in KIP-764: Configurable backlog size for creating Acceptor
may cause significant network throughput degradation due to inconsistent window scaling factor • In a large scale Kafka platform that handles many connections, we might face kernel’s network stack issue • tcpdump, ss, bcc (BPF) greatly help us to investigate network’s problem
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}