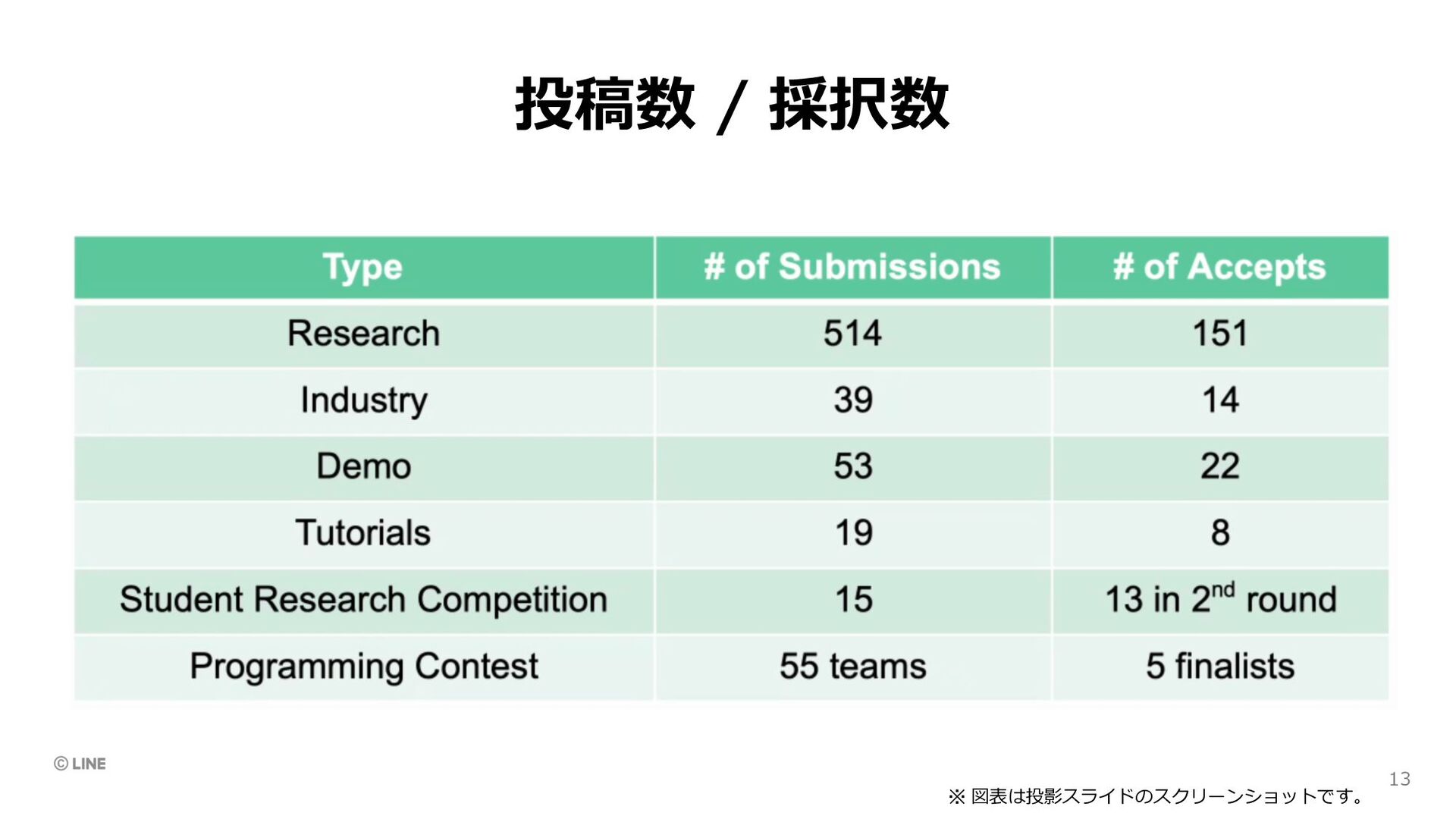
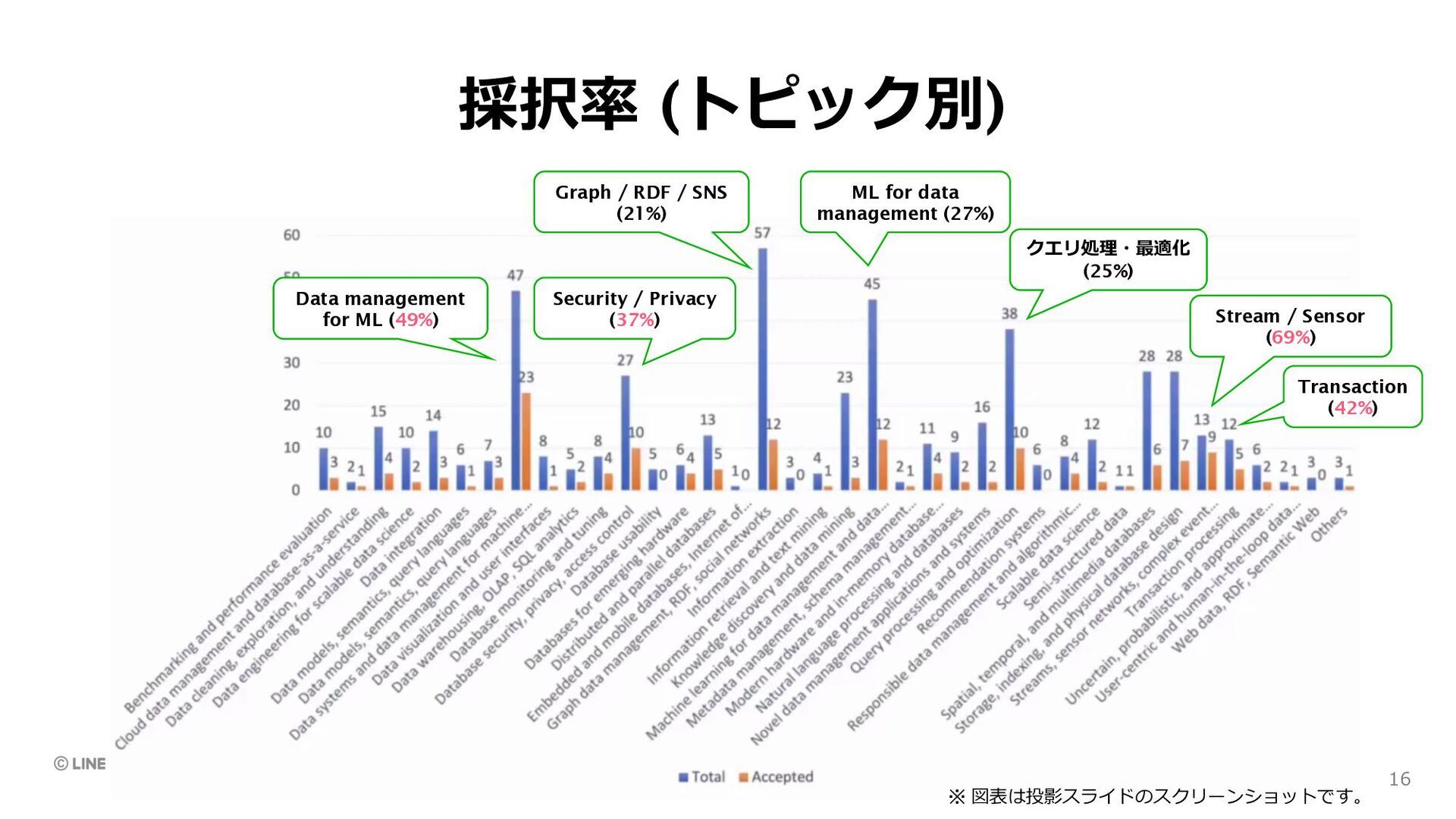
management for ML (49%) ML for data management (27%) Security / Privacy (37%) クエリ処理・最適化 (25%) Stream / Sensor (69%) Transaction (42%) ※ 図表は投影スライドのスクリーンショットです。
to the environment, health, and society: innovation engine, plumber, or bystander? • Organizer: • Magdalena Balazinska (Univ. of Washington) • Panelists: • Anastasia Ailamaki (EPFL) • Leilani Battle (Univ. of Washington) • Johannes Gehrke (Microsoft Research) • Masaru Kitsuregawa (NII, Univ. of Tokyo) • David Maier (Portland State Univ.) • Christopher Re (Stanford) • Meihui Zhang (Beijing Institute of Technology) 24 環境・健康・社会のグランドチャレンジに相対するDBコミュニティ イノベーションエンジンか︖配管⼯か︖傍観者か︖
collaborators? • Q2: Should we build prototypes, open systems, hire teams? • Q3: Should we collaborate with other researchers or practitioners? • Q4: Should the database community organize ourselves to facilitate and recognize work that solves real world problems and have practical impact? 25
• Helping people requires a meaningful connection and active dialogue. • David Maier (Portland State U.) • Take care with people who think you will be gratified to help out simply because they have "interesting data". • Anastasia Ailamaki (EPFL) • Talking to scientists an endless source of inspiration. • Be patient with peer reviewers. • Open mind toward building bridges across sciences. 26
Keep your eye on the prize (変化を注視しつづける) • Find a real problem instance • Select the right collaborators • Don’t underestimate indirect influence (AIの発展はデータに基づいている) • Invest into People • Christopher Ré (Stanford) • The point of the projects is to develop people. • Students lead to new directions –and end bad ones. 27
• Most researchers rushed to develop their own models, rather than working together. The world produced hundreds of mediocre tools, rather than a handful of properly trained and tested ones. • Database researchers' role is to show the importance of data and importance of data sharing by solving real world problem with Databased approach in addition to writing papers. • Meihui Zhang (Beijing Institute of Technology) • Working with non-computer scientists require: • A lot of patience and understanding • Data collection and cleaning • Involvement in non-CS writing for subject matter experts to publish in their domain 28
Management Community: An Open Discussion • タイトル • Publication Culture and Review Processes in the Data Management Community: An Open Discussion • パネリスト • Sihem Amer-Yahia (CNRS LIG and Univ. Grenoble Alpes) • Sourav S. Bhowmick (NTU Singapore) • Xin Luna Dong (Meta) • Stratos Idreos (Harvard) • Wolfgang Lehner (TU Dresden) • オーガナイザー • Divesh Srivastava 30 ※ 図表は投影スライドのスクリーンショットです。
of the paper? • citation numbers / h-index • How many of ideas are either pushing new ideas come up or generating practical impact in industry in changing people’ life • Ex. Booking airline ticket • Database communityの貢献 • 良い論⽂とは何か︖ • worth well for readers’ time • Paper should • have good idea • Well written • Easy to understood • Inspiring 32
Computer Science • Barbara Liskov (MIT) • Keynote 2 • On A Quest for Combating Filter Bubbles and Misinformation • Laks V.S. Lakshmanan (University of British Columbia) • Keynote 3 • Is Data Management the Beating Heart of AI Systems? • Christopher Ré (Stanford) 37 (引⽤) https://2022.sigmod.org/
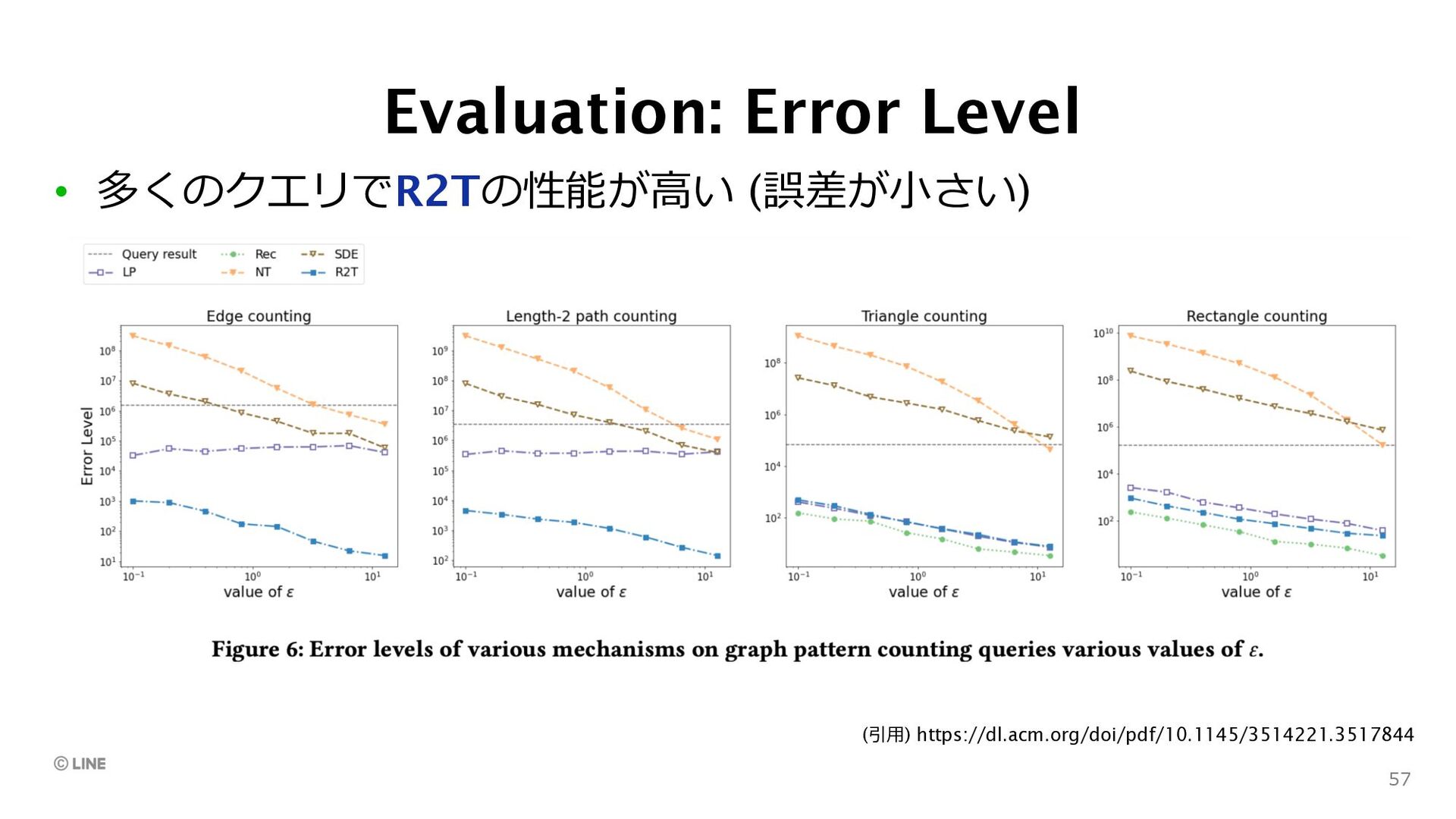
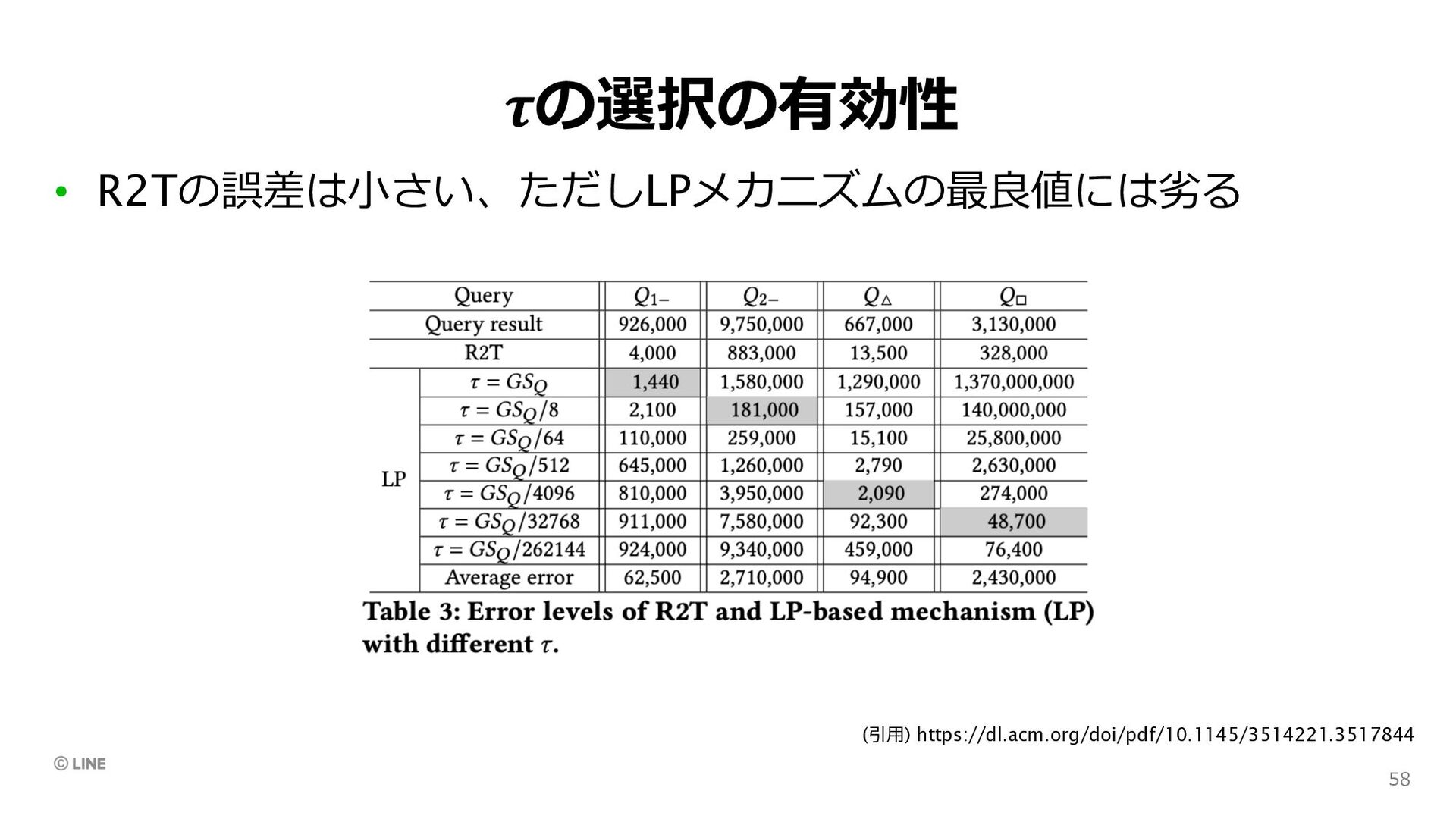
• LINEの採択論⽂「Network Shuffling」 • Best Paper Award受賞論⽂「R2T」 • VLDB 2022 (9/5~9, @Sydney) で以下の論⽂を発表予定 • HDPView: Differentially Private Materialized View for Exploring High Dimensional Relational Data F. Kato, T. Takahashi, S. Takagi, Y. Cao, S.P. Liew, M. Yoshikawa 61
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}