to IU, but I have to wait for a data engineer to do it > A data engineer has to learn every schema > When the IU resource is insufficient, you cannot use any BI reports, even if it’s just the operational report
develop and use BI reports or operational reports with less dependence on the central platform > No need many data engineers to handle data ingestion. > Engineers can handle data integration with less effort (More focused on creating data facility tools) > We can fully utilize IU computing resources rather than data ingestion task
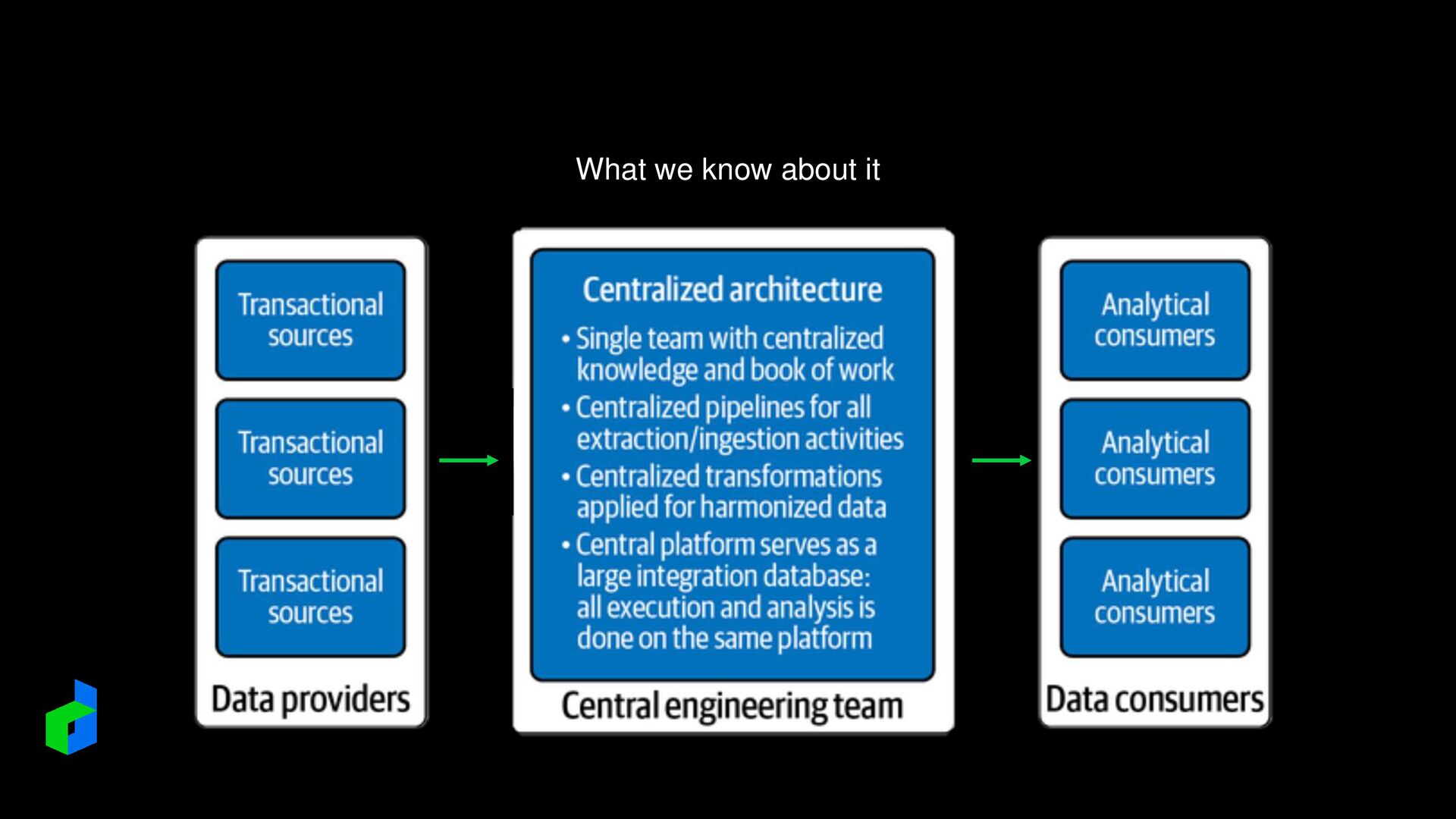
is that use cases always require reworking the data. > Data quality problems must be sorted out, transformations are required, and other data are enriched to bring the data into context. > When data is repeatedly copied and scattered throughout the organization, it becomes more difficult to find its origin and judge its quality.
single logical view of the same data that is managed in different locations. > Extensive data distribution makes controlling the data much more difficult because data can be spread even further
> Determine the correct balance between “defensive” and “offensive.” > Is full control a top priority? Or flexibility for innovation? > How does regulation impact your strategy? > These considerations will influence your initial design and the pace of federating certain responsibilities.
the existing operational processes > The analytical results need to be integrated back into the operational system’s core so that insights become relevant in the operational context.
on data governance and artificial intelligence > Force large companies to be transparent about what data is collected and purchased, what data is combined, how data is used within analytical models, and what data is distributed (sold)
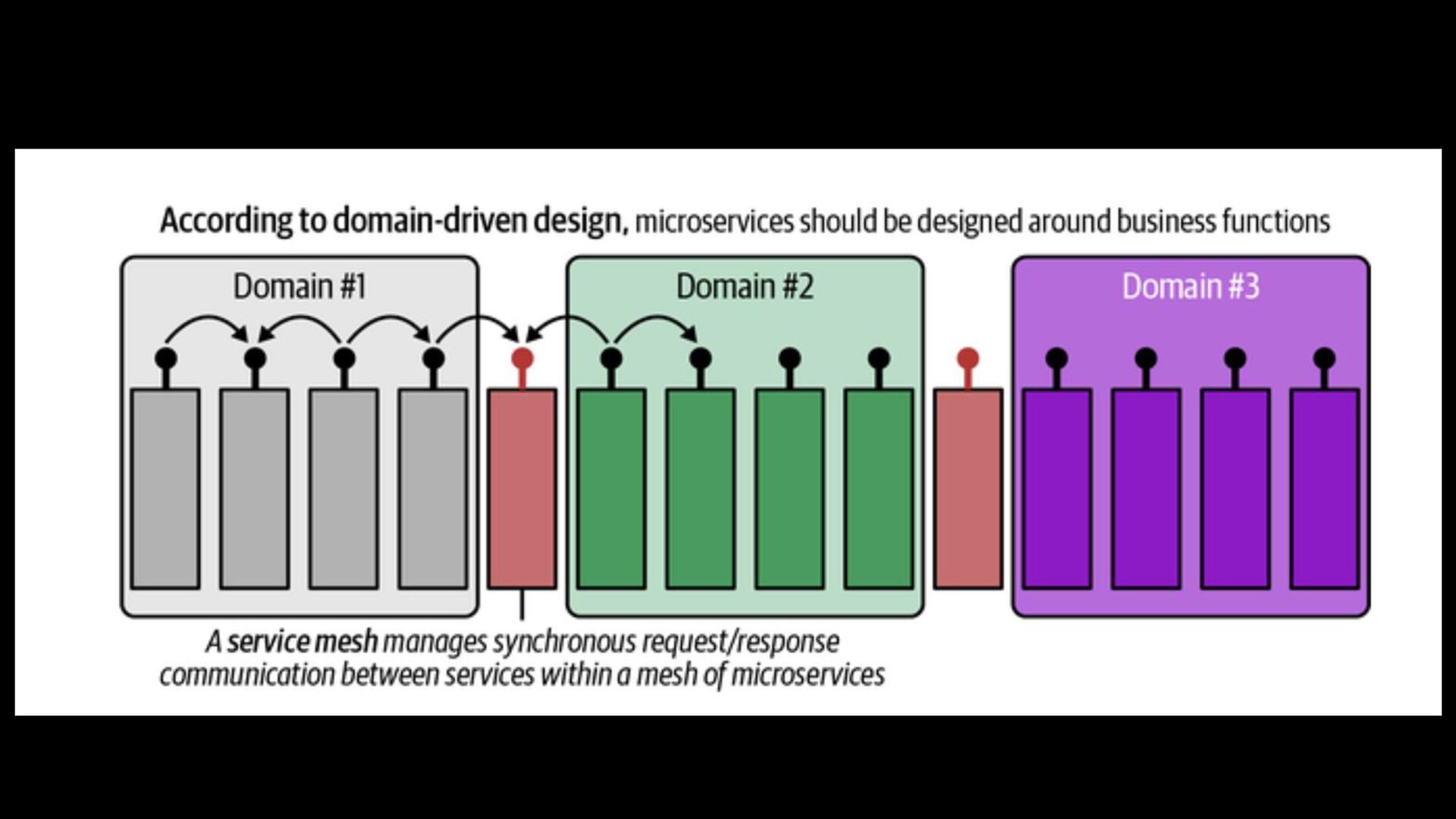
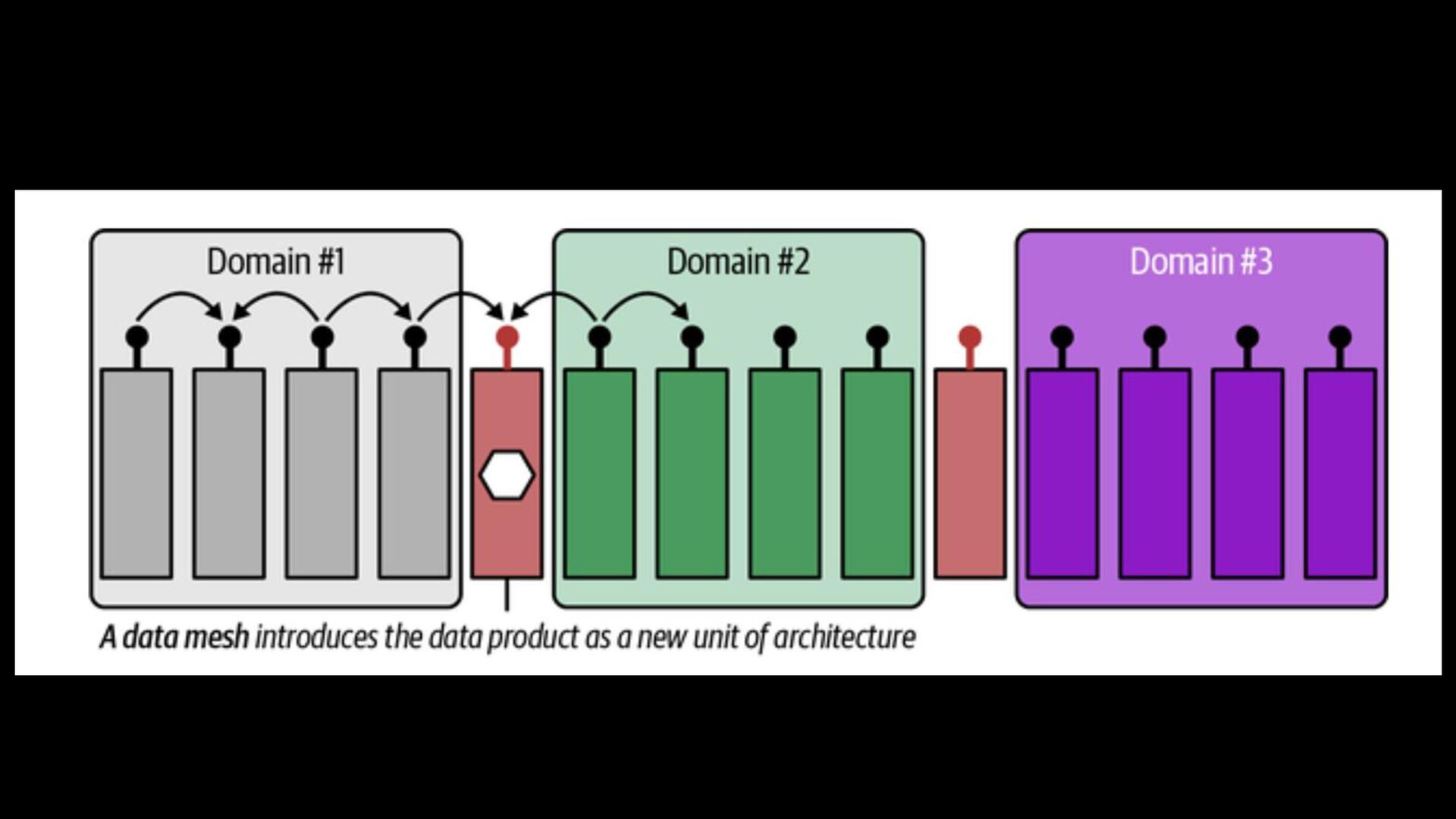
Architecture Balance the centralized and decentralized data strategy, which includes customer-focused, business functions, legal, finance, compliance, and company-wide data governance.
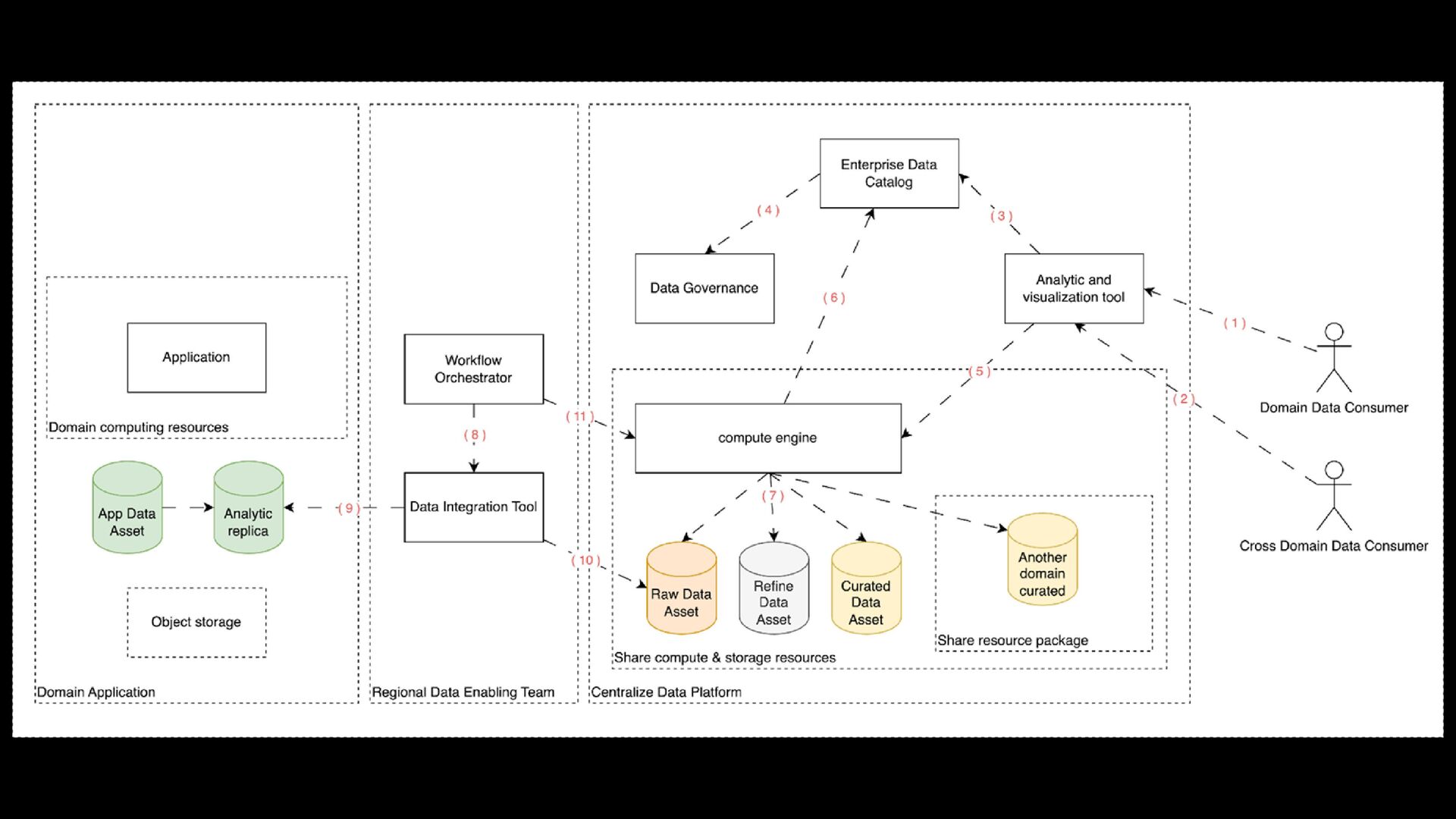
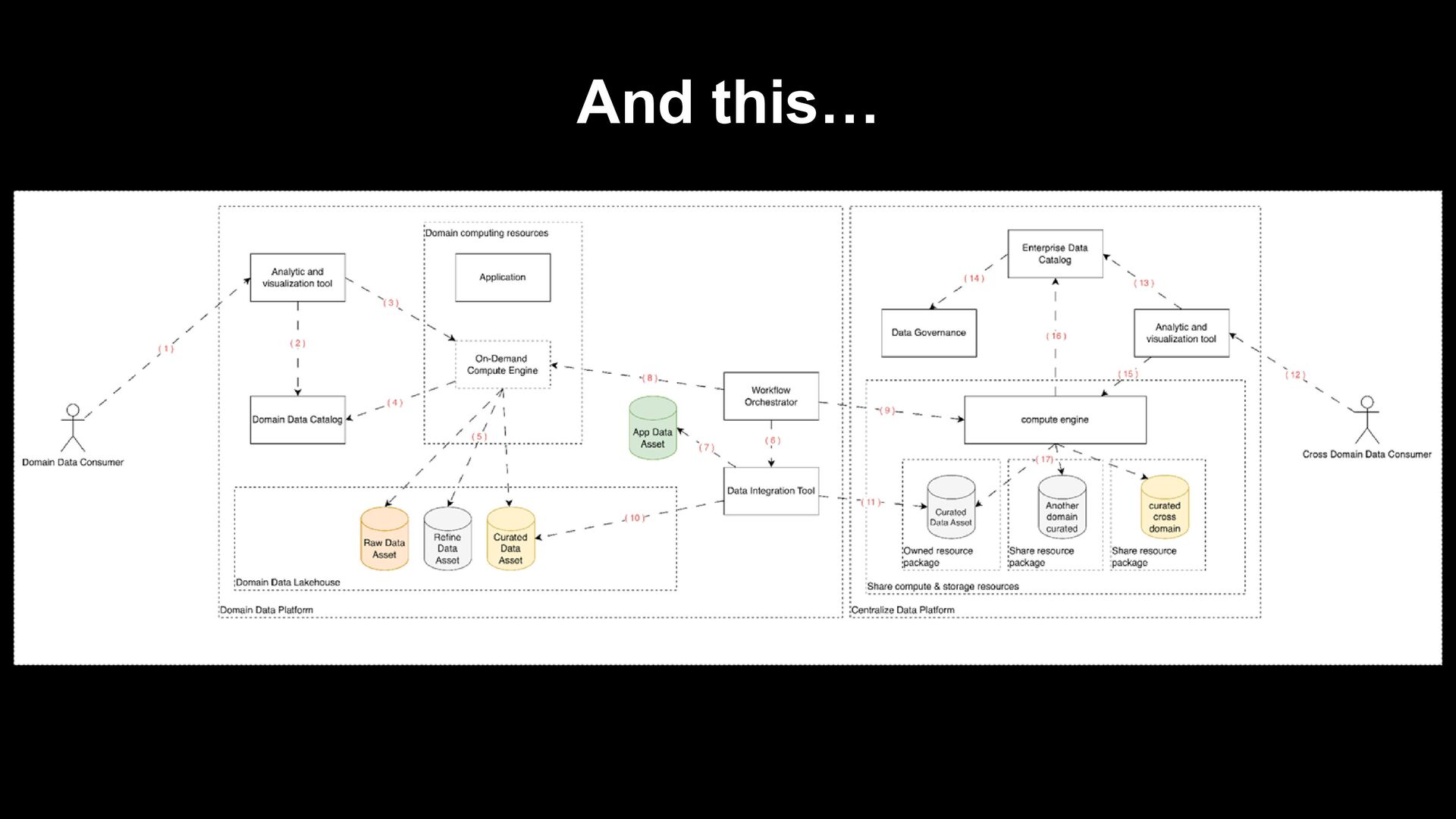
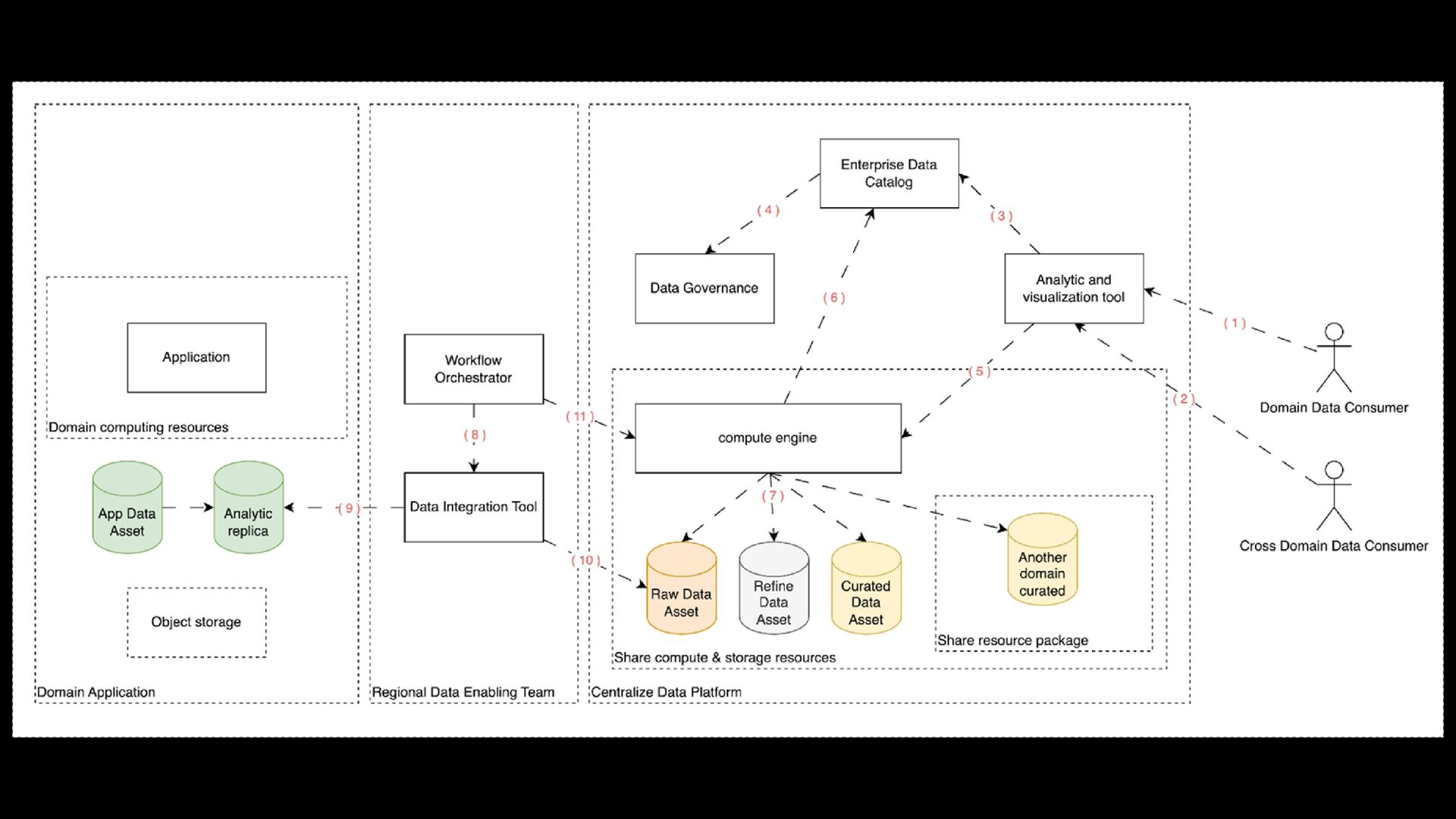
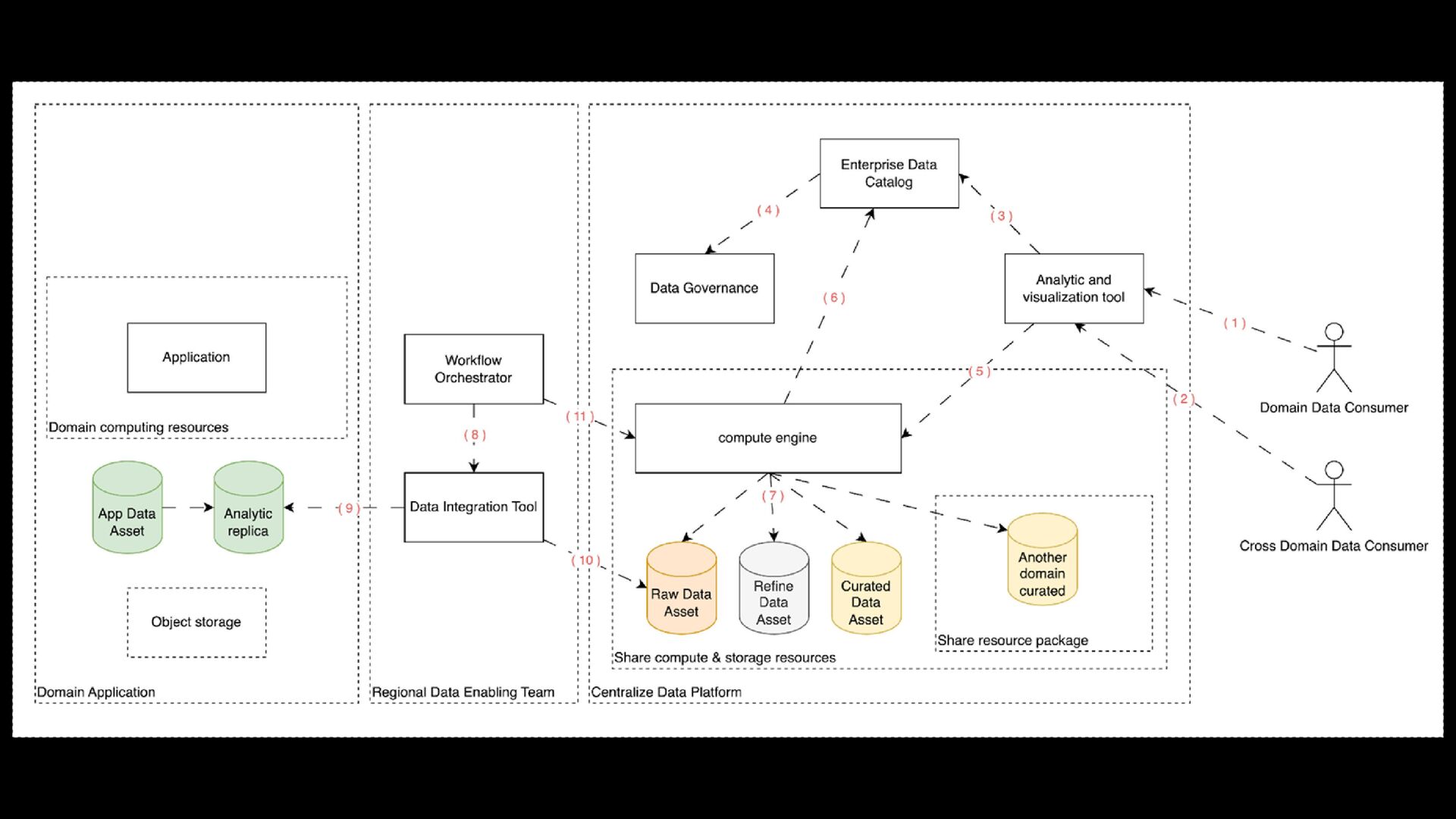
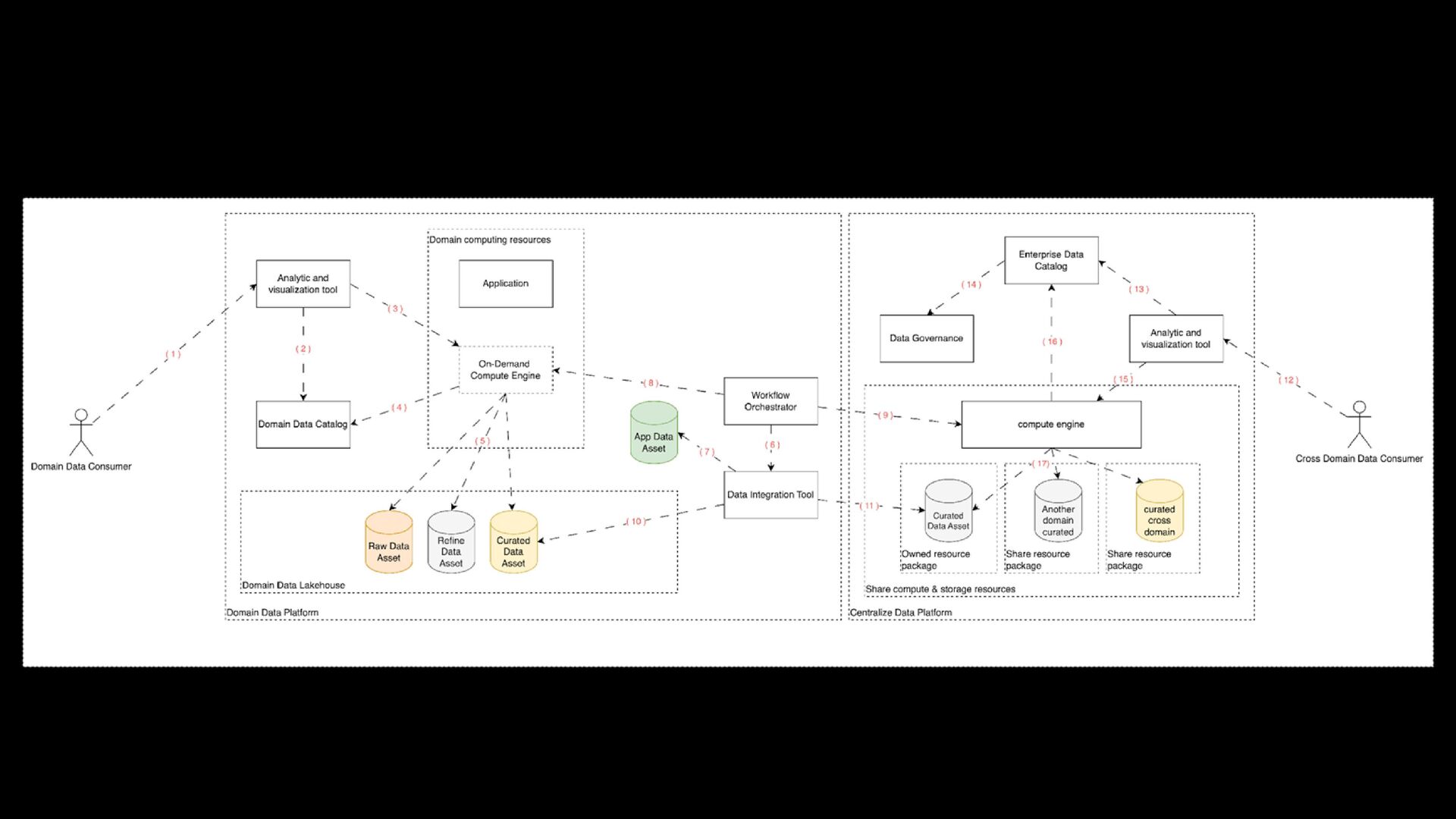
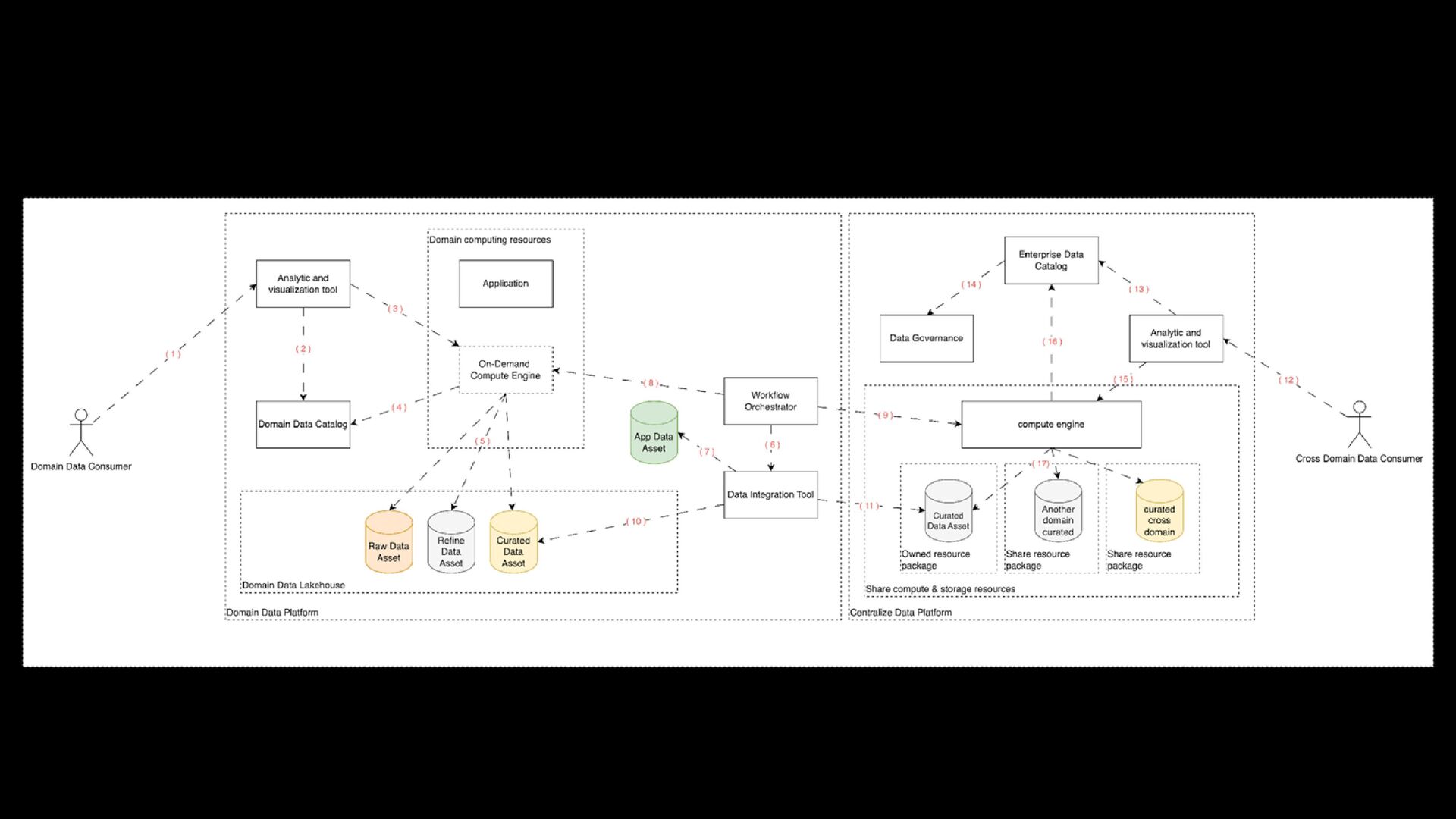
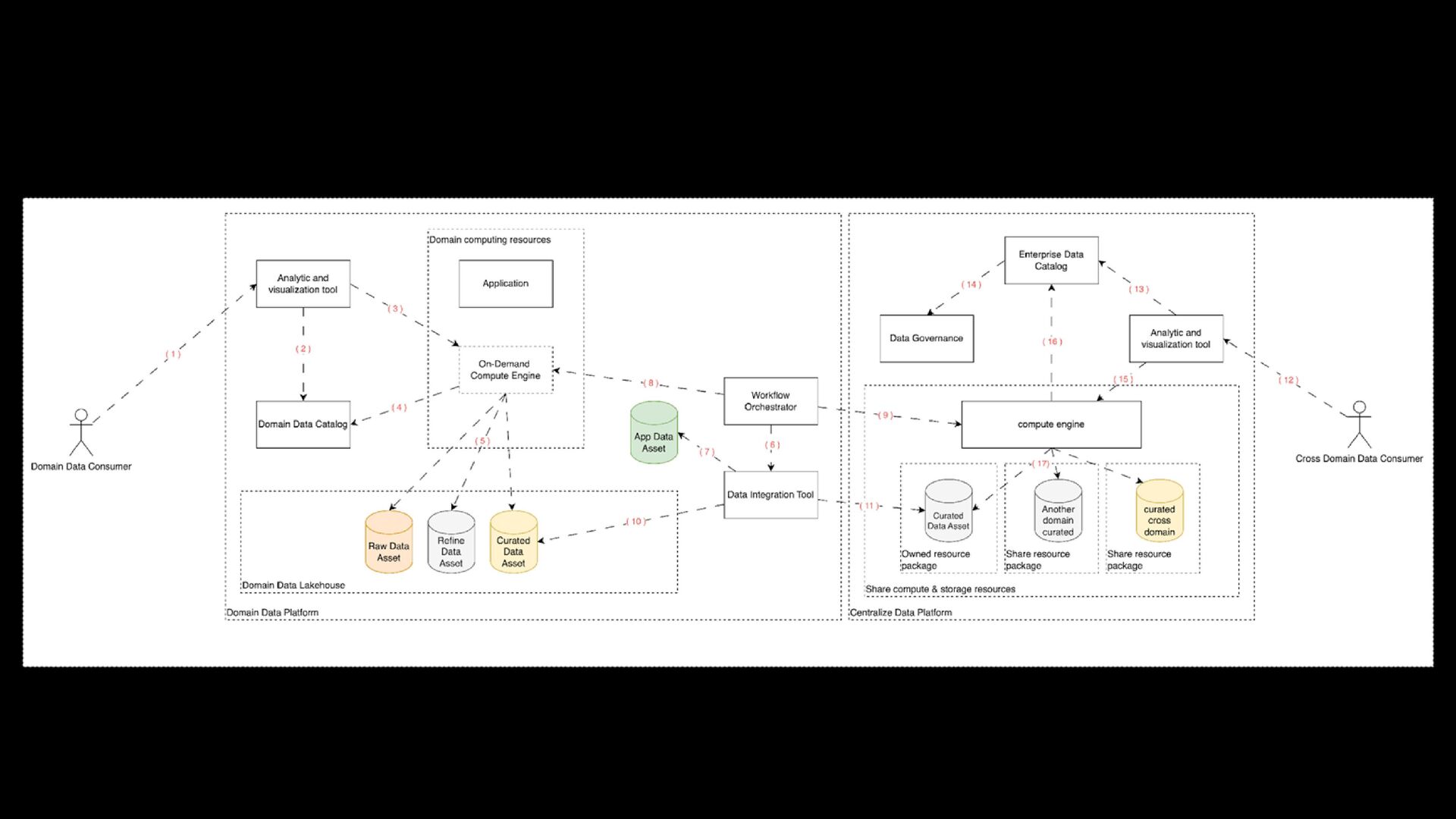
within the Domain data platform > Empowering the domain to self-managed its data and authorizing Self-served domain analytics > Cost-effective utilization of On-Demand computation resources > Reduce Time to consume data
to a Central Data Platform for Cross-Domain Analysis. > Mitigate spoiled data assets, which were prematurely ingested in a centralized data platform from domain raw data assets. > Minimizing Premature Data Governance Efforts
influences the design of the application and finds its way into the data > Unique business problems require unique thinking, unique data, and optimized technology to provide the best solution
data at large. > The concept foresees an architecture in which data is highly distributed and a future in which scalability is achieved by federating responsibilities. > It puts an emphasis on the human factor and addresses the challenges of managing the increasing complexity of data architectures.
as ingesting, cleaning, and transforming data, to serve as many data customers’ needs as possible > Improving data quality and respecting service level agreements (SLAs) and quality measures set by data consumers > Encapsulating metadata or using reserved column names for fine-grained row/column-level filtering and dynamic data masking
and source system schema registration > Providing metadata for improved discoverability > Observing versioning rules > Linking data attributes and business terms > Ensuring the integrity of metadata information to allow better integration between domains
protocols, data formats, and data types > Providing lineage, either manually or by linking source systems and integration services to scanners > Completing data-sharing tasks, including identity and access management reviews and data contract creation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}