of study that gives computers the ability to learn without being explicitly programmed. Tom Mitchell (1998): A computer is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. 2
predict y (y ∈ {1,...,C}). Example: Given a piece of email text, predict if it is spam or not. x = [1 0 0 1 … 0 1 1], where each entry represents if the word appeared or not. y = [spam, not_spam], |y| = 2, C = 2. 13
- X is a (n x m) matrix containing the input features. - n is the number of training data. - m is the number of features. - y is a (n x 1) vector containing the target. - n is the number of training data. - Find a good function h: X → Y , where (h ∈ H) - H is the hypothesis space, and h is a single hypothesis. 15
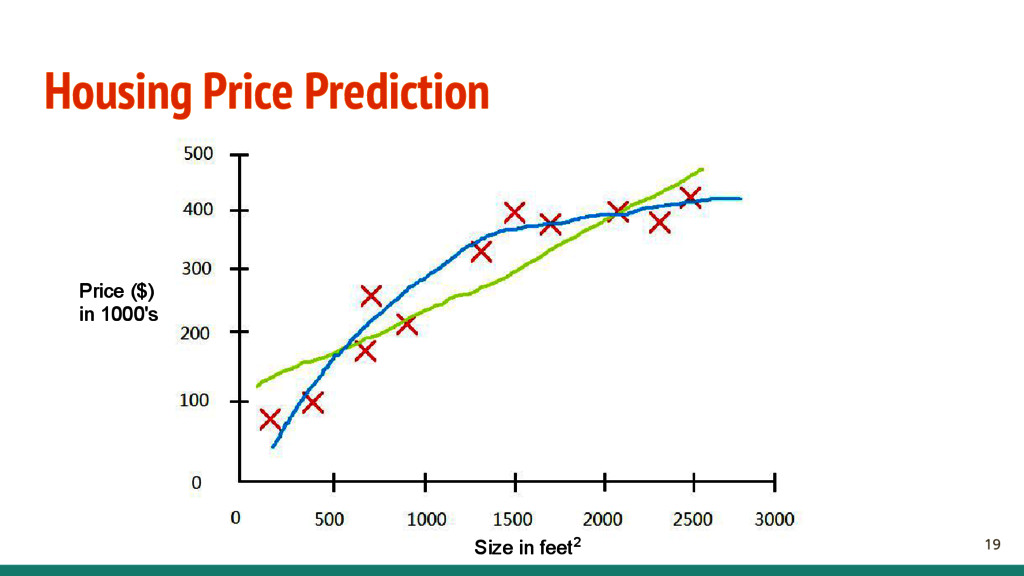
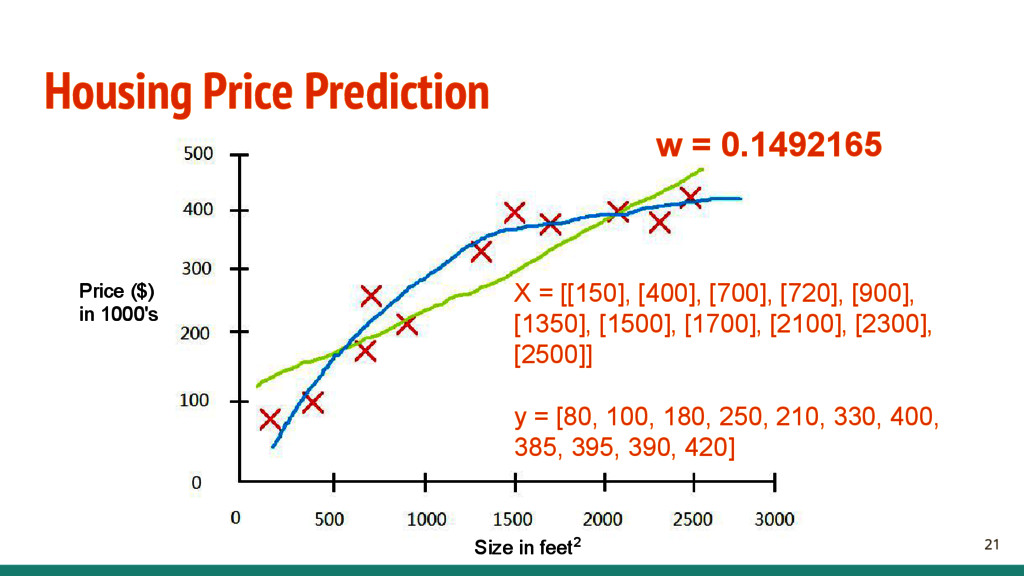
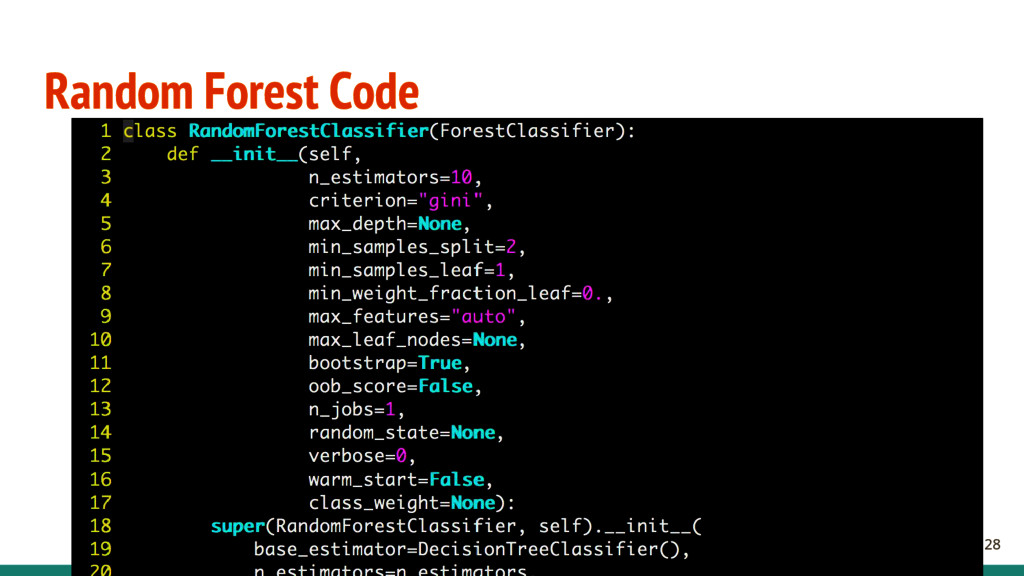
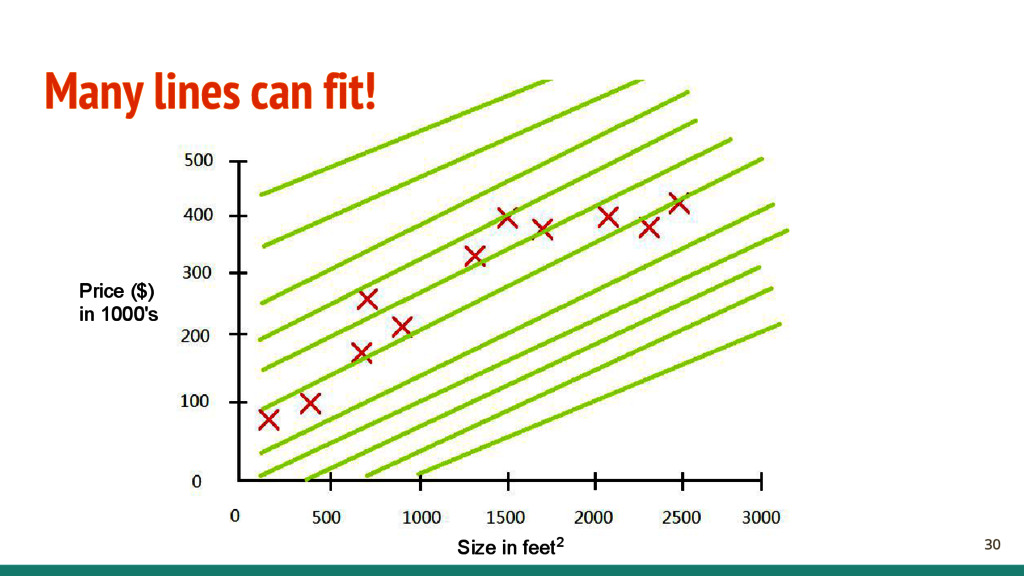
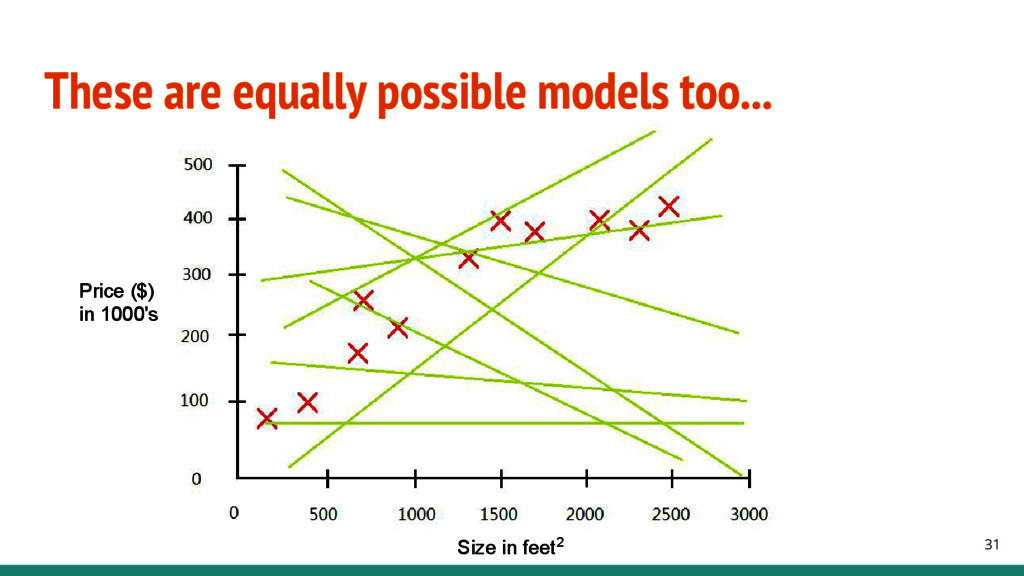
- X is a (n x m) matrix containing the input features. - n is the number of training data. - m is the number of features. - y is a (n x 1) vector contains the target. - n is the number of training data. - Find a good function h: X → Y , where (h ∈ H) - H is the hypothesis space, and h is a single hypothesis. We will be using a model called linear regression. - Find y = WTX, W is a (1 x m) vector containing the weights to the model. 16
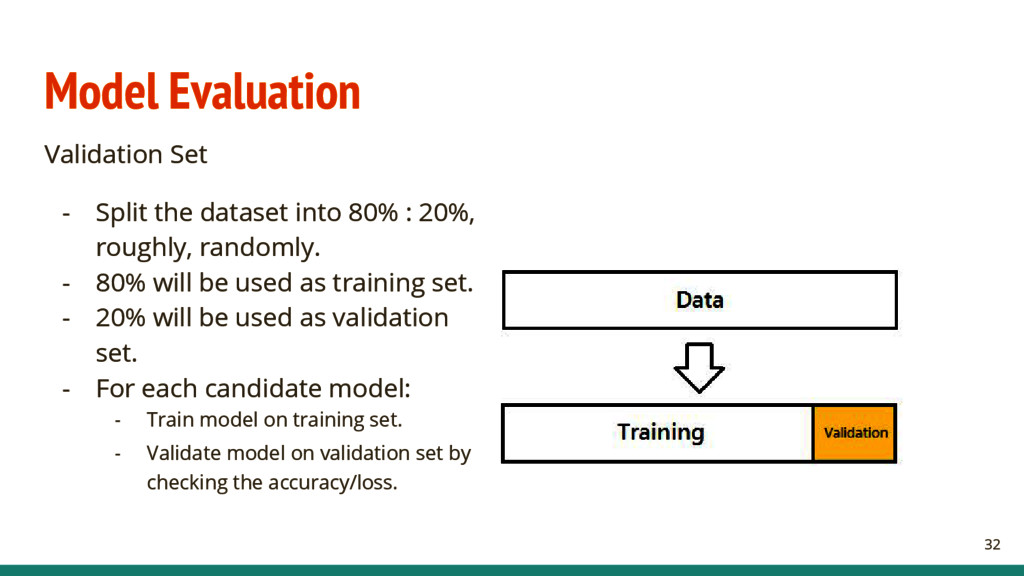
: 20%, roughly, randomly. - 80% will be used as training set. - 20% will be used as validation set. - For each candidate model: - Train model on training set. - Validate model on validation set by checking the accuracy/loss. 32
Train on fold 1, 2, 3, 4, validate on fold 5 - Train on fold 1, 2, 3, 5, validate on fold 4 - ... - Take the average of the errors (optionally, also standard deviation, variance, ...) 37
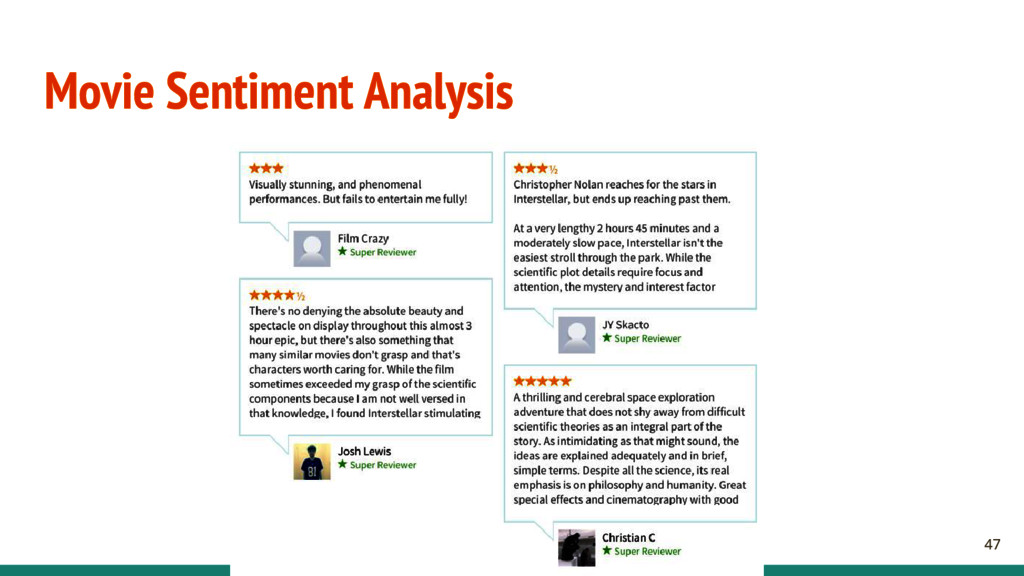
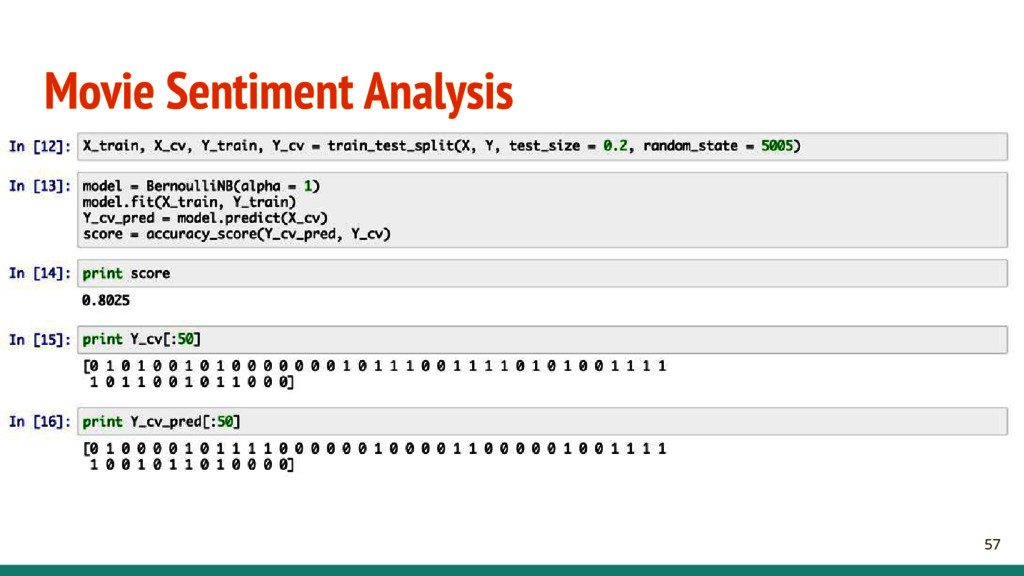
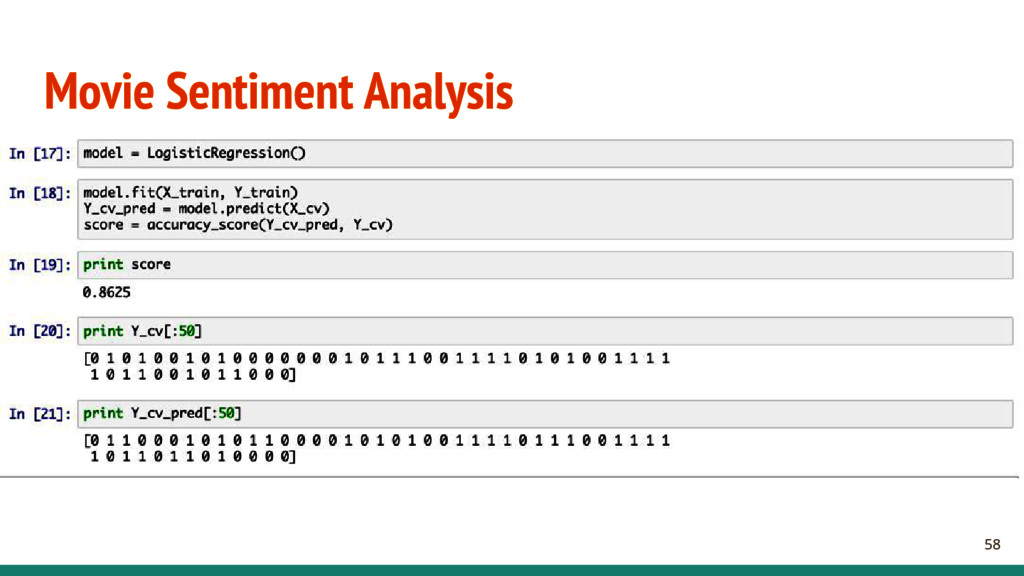
Collection - Extract from Rotten Tomatoes, IMDB, etc. - Label data - Data Cleaning - Check that the data is correctly labeled - The data is valid and not a bunch of invalid HTML
- What kind of features? - Bag of words? Word counter? - K Best words? - Any preprocessing? - Stopwords? - How to find the best model? - How to construct the validation set?
first. - Move onto more sophisticated features and models later. - Occam's Razor - Among competing hypotheses, the one with the fewest assumptions should be selected. 70
first. - Move onto more sophisticated features and models later. - Occam's Razor - Among competing hypotheses, the one with the fewest assumptions should be selected. => Sometimes simple models work effectively well, and more sophisticated models may not yield much better gains. This is especially the case in deep features (images, audio) vs shallow features (text). 71
Ng, Stanford, Coursera) ◦ Learning From Data (by Yaser S. Abu-Mustafa, Caltech) ◦ Neural Network for Machine Learning (by Geoff Hinton, University of Toronto) • Books ◦ Machine Learning : A Probabilistic Perspective, by Kevin Murphy ◦ The Elements of Statistical Learning 76
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Classification Given an input features vector x (x[i] ∈ R),](https://files.speakerdeck.com/presentations/4ec6620e0e4e444dbbe8683b11320f1e/slide_12.jpg){kind=link}
![Regression Given an input features vector x (x[i] ∈ R),](https://files.speakerdeck.com/presentations/4ec6620e0e4e444dbbe8683b11320f1e/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
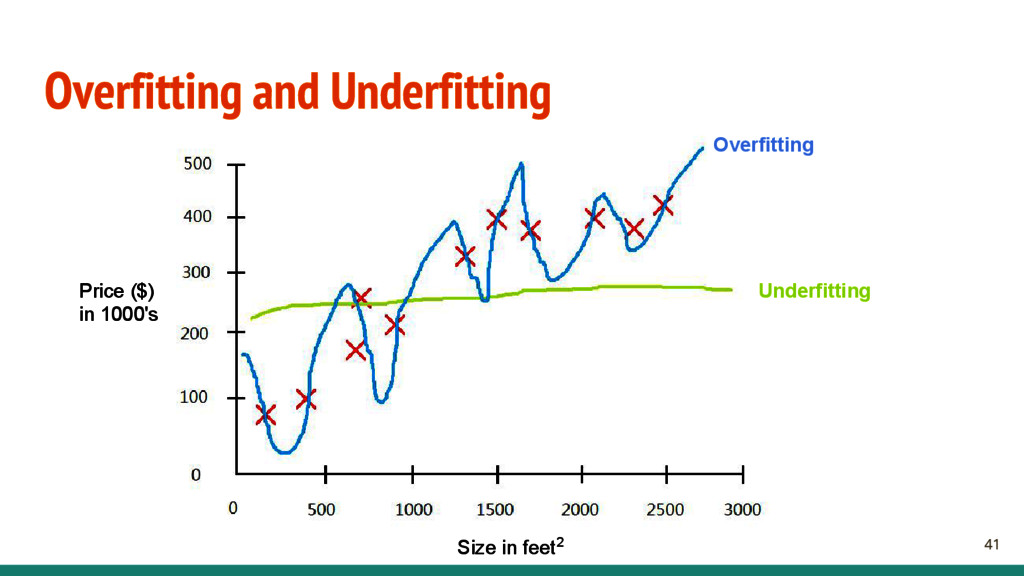{kind=link}
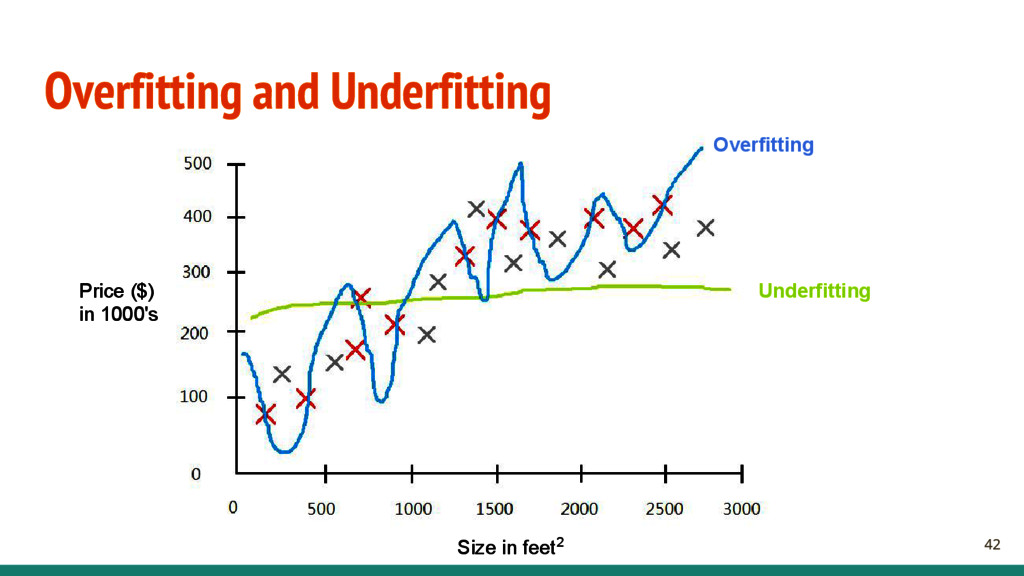{kind=link}
{kind=link}
{kind=link}
{kind=link}
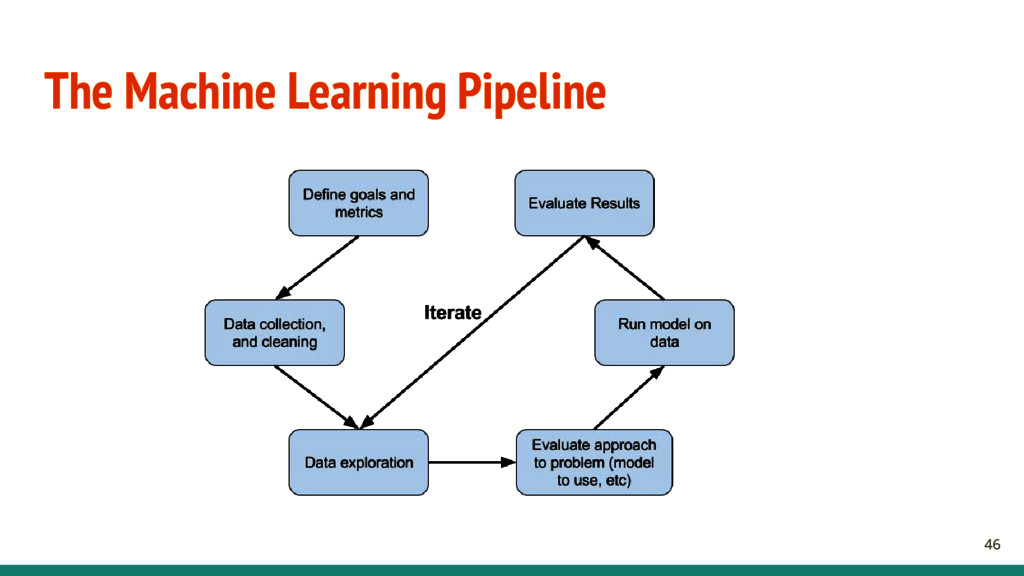{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}