Universidade de Berkeley, liderado por Michael Stonebraker; • Postgres (1986): início do projeto, inspirado no Ingres, criado para superá-lo; • Em 1992 é criada a Illustra, versão comercial do Postgres, depois fundida com o Informix; • Em 1993 a universidade de Berkely encerra o projeto na versão 4.2 • Postgres95 (1994 - 1995): versão do Postgres com a linguagem SQL desenvolvido por 2 alunos de Berkeley • Em 1996 o Postgres passa a se chamar PostgreSQL e começa a ser mantido pelo PGDG: PostgreSQL Global Development Group: ◦ (1996 - 1998): Processo de estabilização do servidor ◦ (1998 - 2000): Aderência aos padrões SQL ◦ (2001 - 2011): Funcionalidades corporativas ◦ (2012 em diante): Inovação
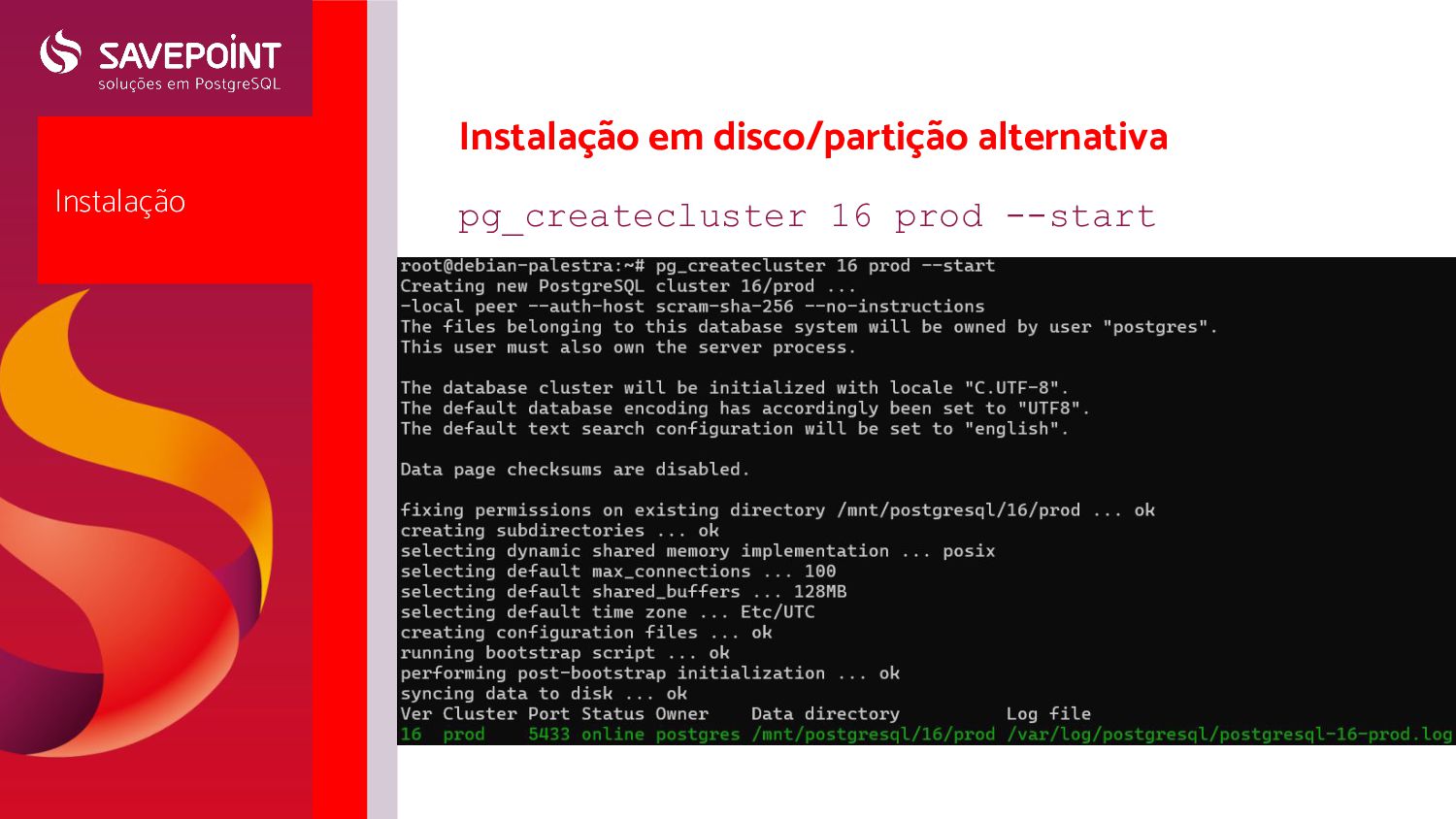
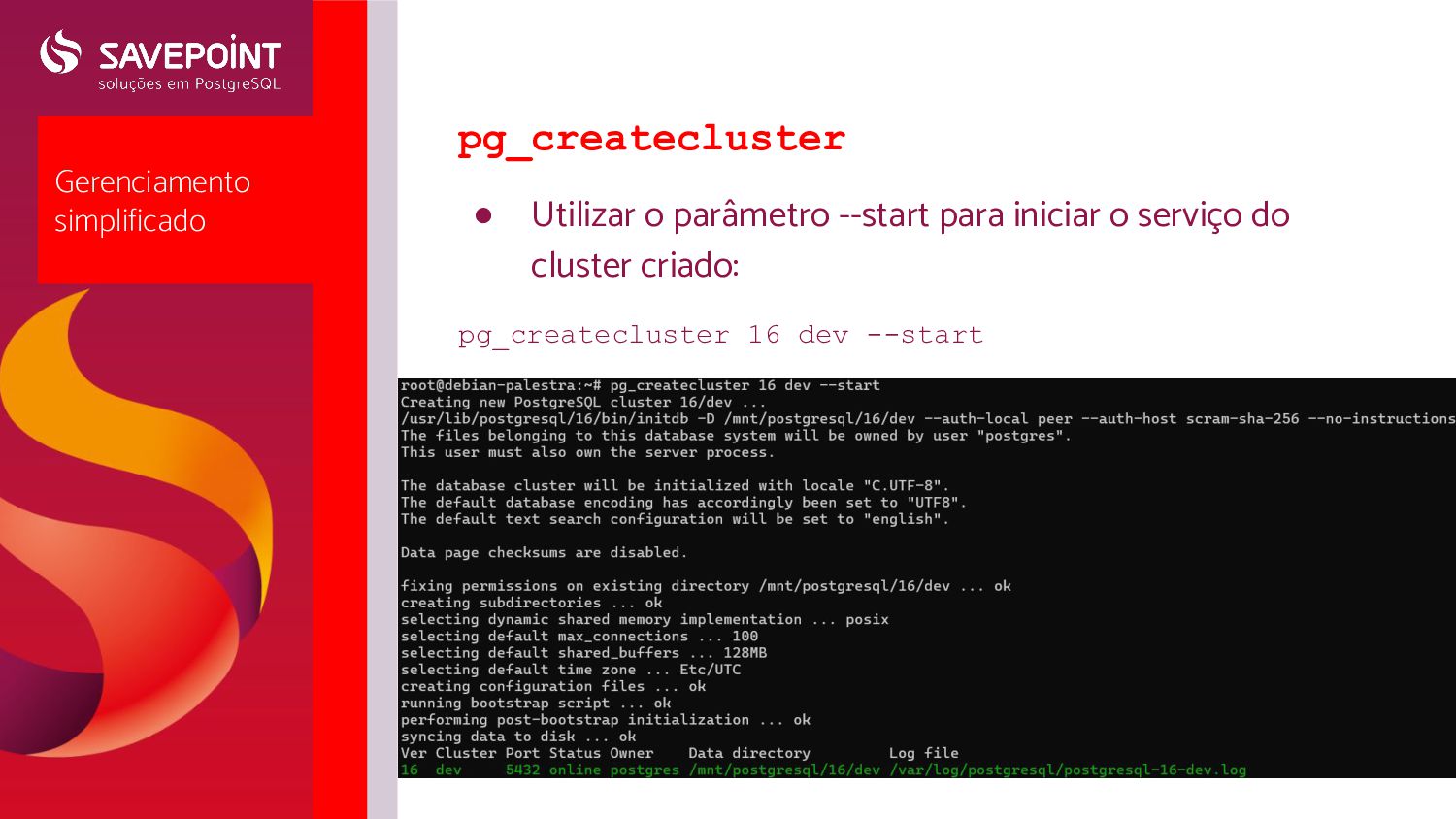
produção • Sempre utilizar uma partição separada com os dados (ext4 ou xfs) • Utilizar uma partição separada para os logs em situações de DEBUG em servidores grandes • Por padrão, o cluster fica em /var/lib/postgresql • Para alterar pós-instalação, editar o createcluster.conf (/etc/postgresql-common/), especificamente em: # Default data directory. data_directory = '/mnt/postgresql/%v/%c' • %v e %c representam a versão e o nome do cluster • Criar um novo cluster: pg_createcluster 16 <nome> --start ; • Conferir clusters com: pg_lsclusters
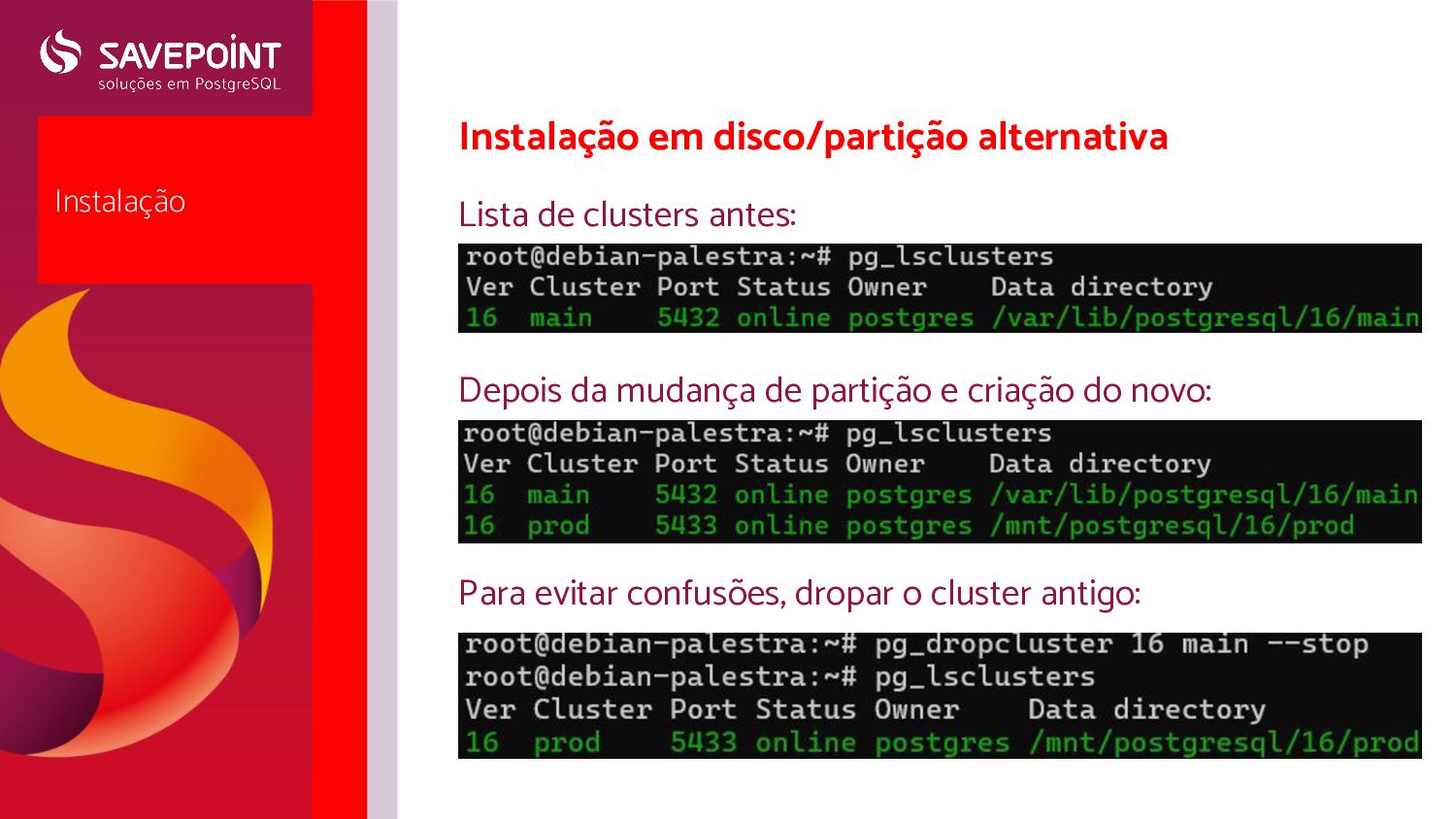
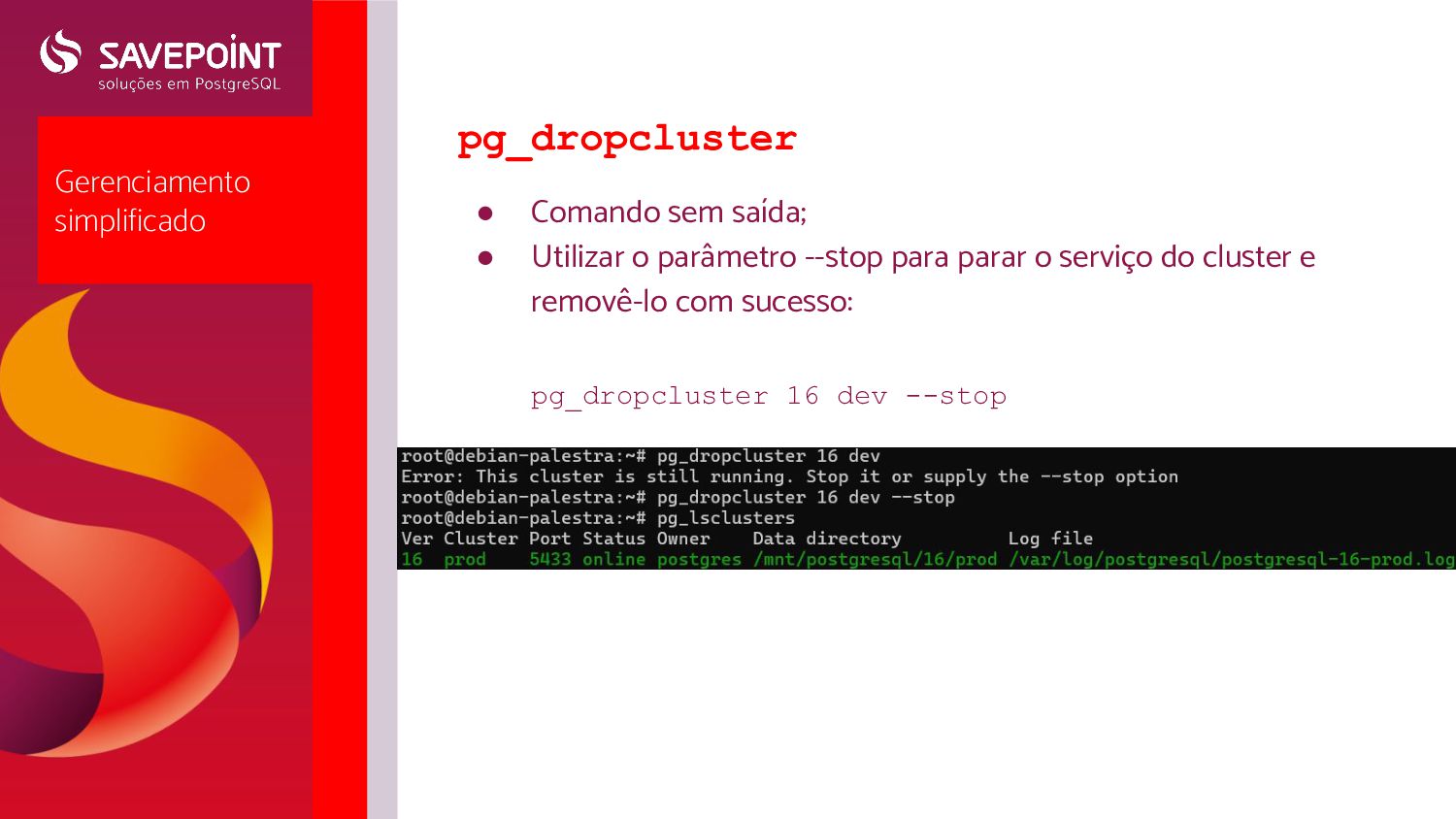
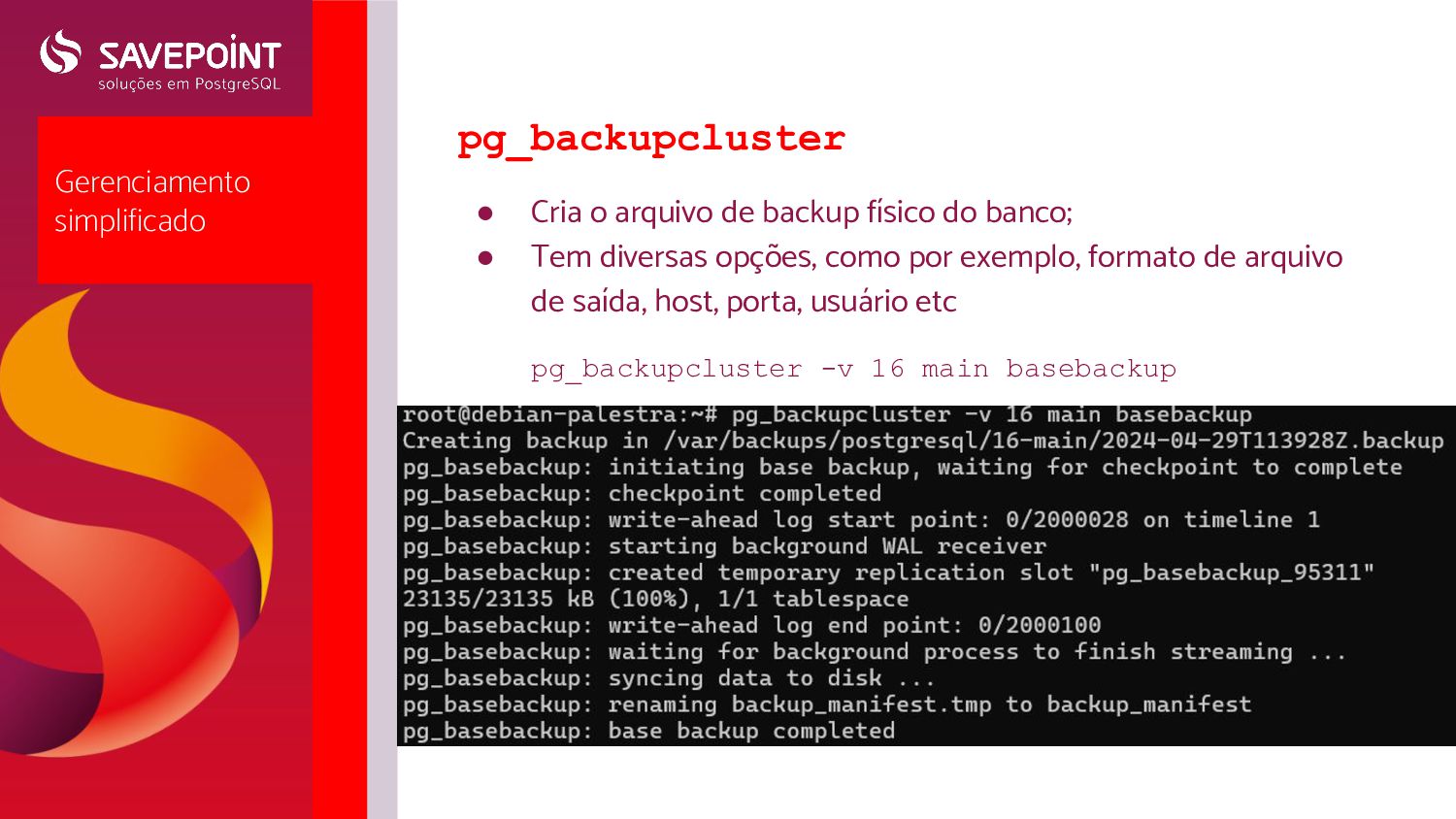
clusters existentes • pg_createcluster/pg_dropcluster : cria e remove clusters (apaga tudo!) • pg_backupcluster/pg_restorecluster : backup / restore • pg_upgradecluster : atualiza a major version de um cluster • pg_ctlcluster : start / stop / restart / reload / promote Arquivo start.conf: • Localizado em /etc/postgresql/<versão>/<cluster>/start.conf • Define se o cluster deverá ser inicializado automaticamente durante o boot através do systemd • Opções: ◦ auto: inicia automaticamente ◦ manual: inicia manualmente ◦ disabled: não inicia nem manualmente
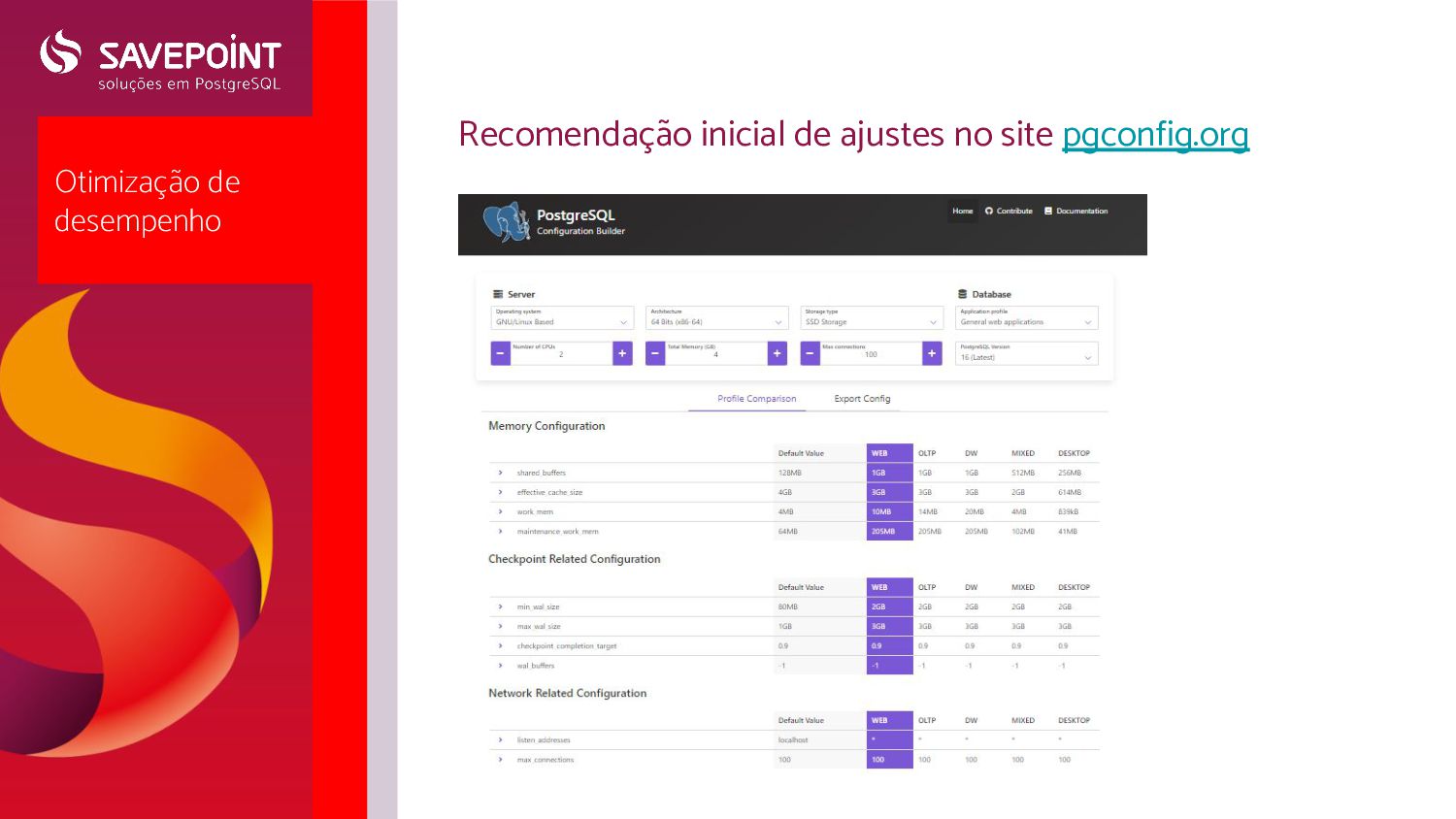
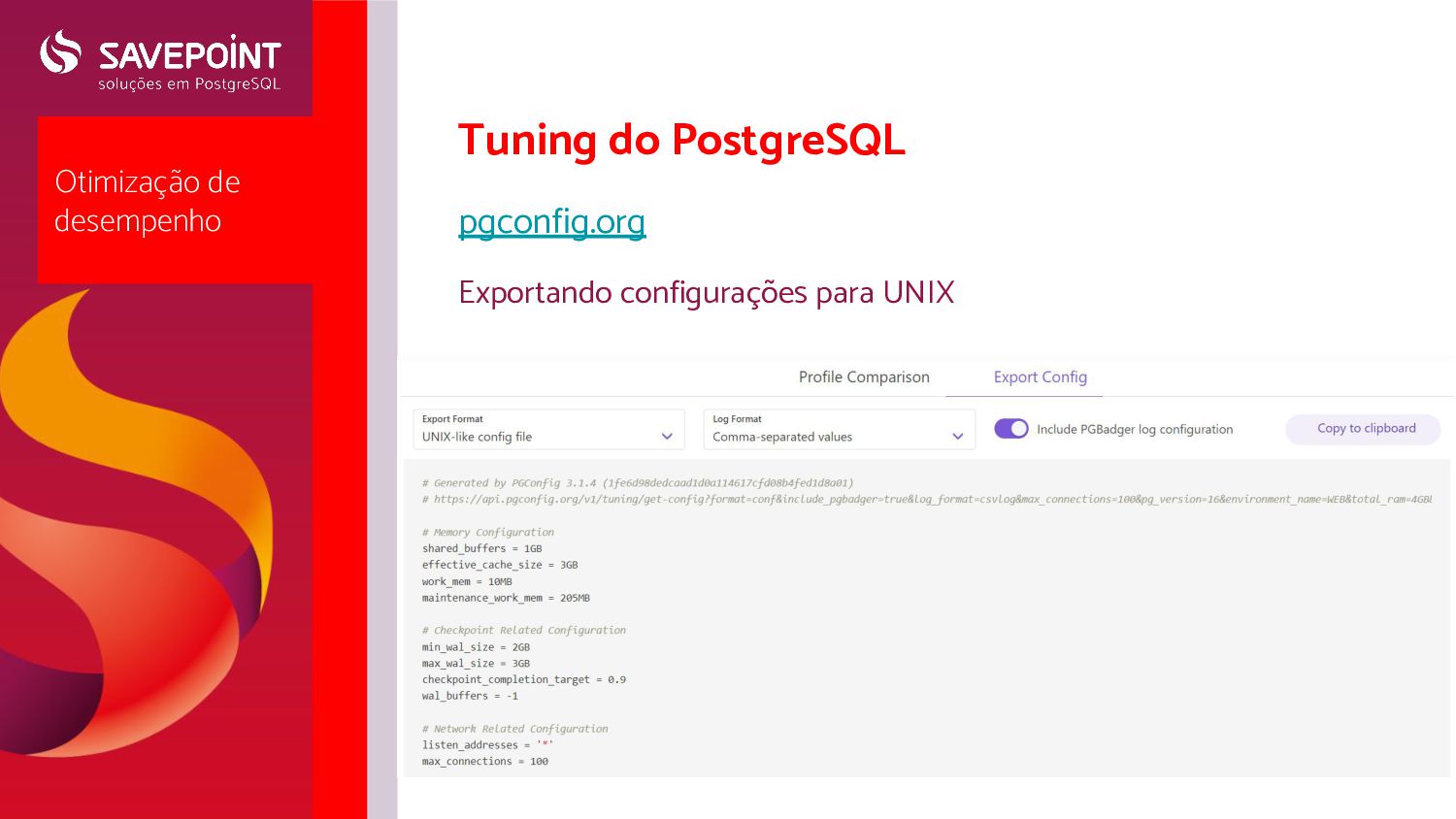
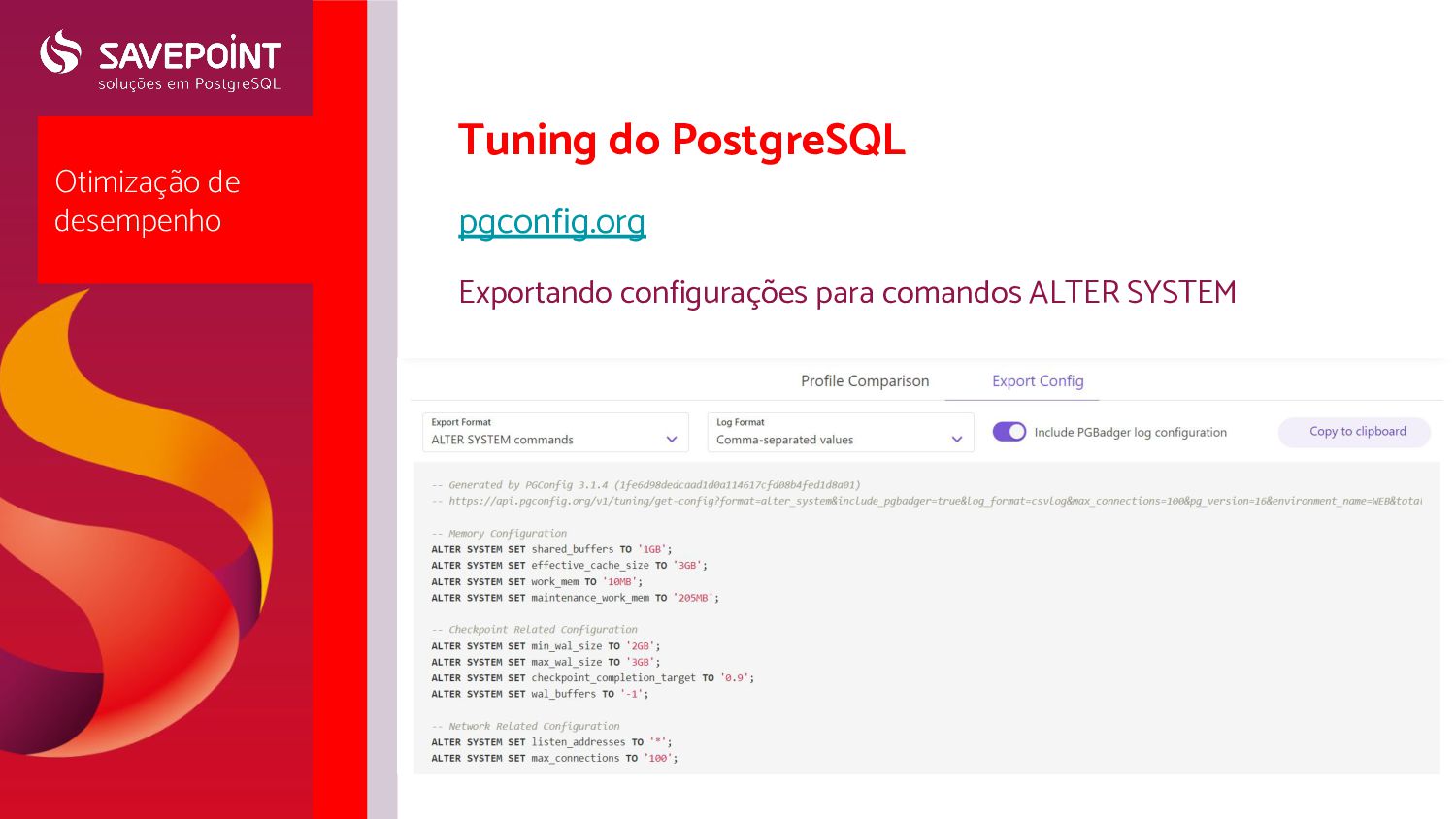
operacional ◦ Ajustes comuns ◦ Ajustes sob demanda ◦ Erros comuns ◦ Ajustes no Huge Pages e THP ◦ Sistemas de Arquivos e particionamento • Tuning do PostgreSQL (pgconfig.org) • Pgbench- para teste de ajustes de parâmetros
Memory: Killed process 12345 (postgres) ◦ Ajustar os parâmetros: vm.overcommit_memory vm.overcommit_ratio vm.swappiness • FATAL: could not create shared memory segment: Invalid argument DETAIL: Failed system call was shmget ◦ Ajustar os parâmetros: kernel.shmmax kernel.shmall • FATAL: could not create semaphores: No space left on device DETAIL: Failed system call was semget(5440126, 17, 03600). ◦ Ajustar o parâmetro: kernel.sem
of file descriptors: Too many open files in system; release and retry PANIC: could not open file (...): Too many open files in system ◦ Ajustar o parâmetro: nofile • LOG: could not fork new process for connection: Resource temporarily unavailable ◦ Ajustar os parâmetros: fs.file-max fs.aio-max-nr • could not connect to server: Resource temporarily unavailable ◦ Ajustar o parâmetro: net.core.somaxconn
Pages e THP (servidores com RAM >= 32GB) • Desligar o THP (Transparent Huge Pages) ◦ Adicionar o script em /etc/rc.local: if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag
>= 32GB • Configurar o Huge Pages: ◦ O número de páginas deve ser o valor do shared_buffers + 10%, dividido pelo tamanho da página. O valor do huge pages deve ser = (shared_buffers(em MB) * 1,1)/ 2. Ex: shared_buffers = 16GB hugepages = (16 * 1024 *1,1) / 2 = 9011 ◦ Editar a linha GRUB_CMDLINE_LINUX no arquivo /etc/default/grub GRUB_CMDLINE_LINUX="... hugepages= 9011 hugepagesz=2M transparent_hugepage=never" ◦ Executar como root ou sudo: update-grub ◦ Reiniciar o servidor: reboot
e particionamento • Utilizar uma partição separada para os logs em situações de DEBUG em servidores grandes ◦ Ajustar o parâmetro log_directory no postgresql.conf • Utilizar uma partição separada para os arquivos temporários em servidores com bases grandes e consultas muito pesadas (Data Warehouse, Data Lake, etc). ◦ Ajustar o parâmetro temp_tablespaces no postgresql.conf • Utilizar uma partição separada para os logs de transação em servidores OLTP com alto volume de transações. ◦ Criar um link simbólico para $PGDATA/pg_wal
e particionamento • Tablespaces: ◦ Criar novos tablespaces para separar dados de discos rápidos de discos lentos (geralmente utilizados para dados históricos) ◦ Quando lidar com vários discos idênticos, ao invés de utilizar vários tablespaces, crie um RAID com mais discos. • Utilizar ext4 ou xfs para os dados: ◦ Sempre montar os discos com UUID no /etc/fstab ◦ Utilizar a opção noatime com ext4 • Ajustar o Read-Ahead para o discos dos dados entre 4096 e 16384: ◦ Ajustar no /etc/rc.local: blockdev --setra 4096 /dev/sda1
ajustar dezenas de parâmetros ◦ Ajustes direto em /etc/postgresql/<version>/<cluster>/postgresql.conf ◦ Ajustes estilo system.d (com o parâmetro include_dir) em /etc/postgresql/<version>/<cluster>/conf.d/<nome_arquivo>.conf ◦ Ajustes em arquivo aleatório com o parâmetro include ◦ Ajustes com comando SQL ALTER SYSTEM, armazenados em /var/lib/postgresql/<version>/<cluster>/postg resql.auto.conf (não editar este arquivo manualmente) ◦ Utilize um e apenas um método ◦ Recomendamos ajustar via comandos SQL
◦ Não instalar interface gráfica ◦ Instale apenas o mínimo necessário • Não utilizar IPs públicos • Restringir ao máximo as conexões no pg_hba.conf ◦ Não use autenticação TRUST ◦ Não utilize o intervalo de redes 0.0.0.0/0 ◦ Utilize conexões encriptadas com hostssl • Crie usuários separados no banco para funções separadas: ◦ DBAs / administradores ◦ Deploy / owner de objetos ◦ Replicação / Backup ◦ Aplicações
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}