Document AI kann der Schlüssel zur Erschließung wertvoller Informationen aus historischen und aktuellen Dokumentenbeständen sein. In diesem Vortrag zeigt Lukas Köhler praxisnahe Ansätze für die Verarbeitung von PDFs mit und ohne Text-Layer sowie die Generierung belastbarer Zitate mit präzisen Bounding-Boxen. Wichtige Konzepte wie Annotation-Workflows, der Einsatz spezialisierter Modelle wie Mistral Document AI und DeepSeek OCR sowie Matching-Strategien werden anhand eines Proof of Concept demonstriert. Entwickler und Architekten erhalten einen pragmatischen Überblick über die mögliche Implementierung nachvollziehbarer Datenextraktion in eigenen Projekten.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
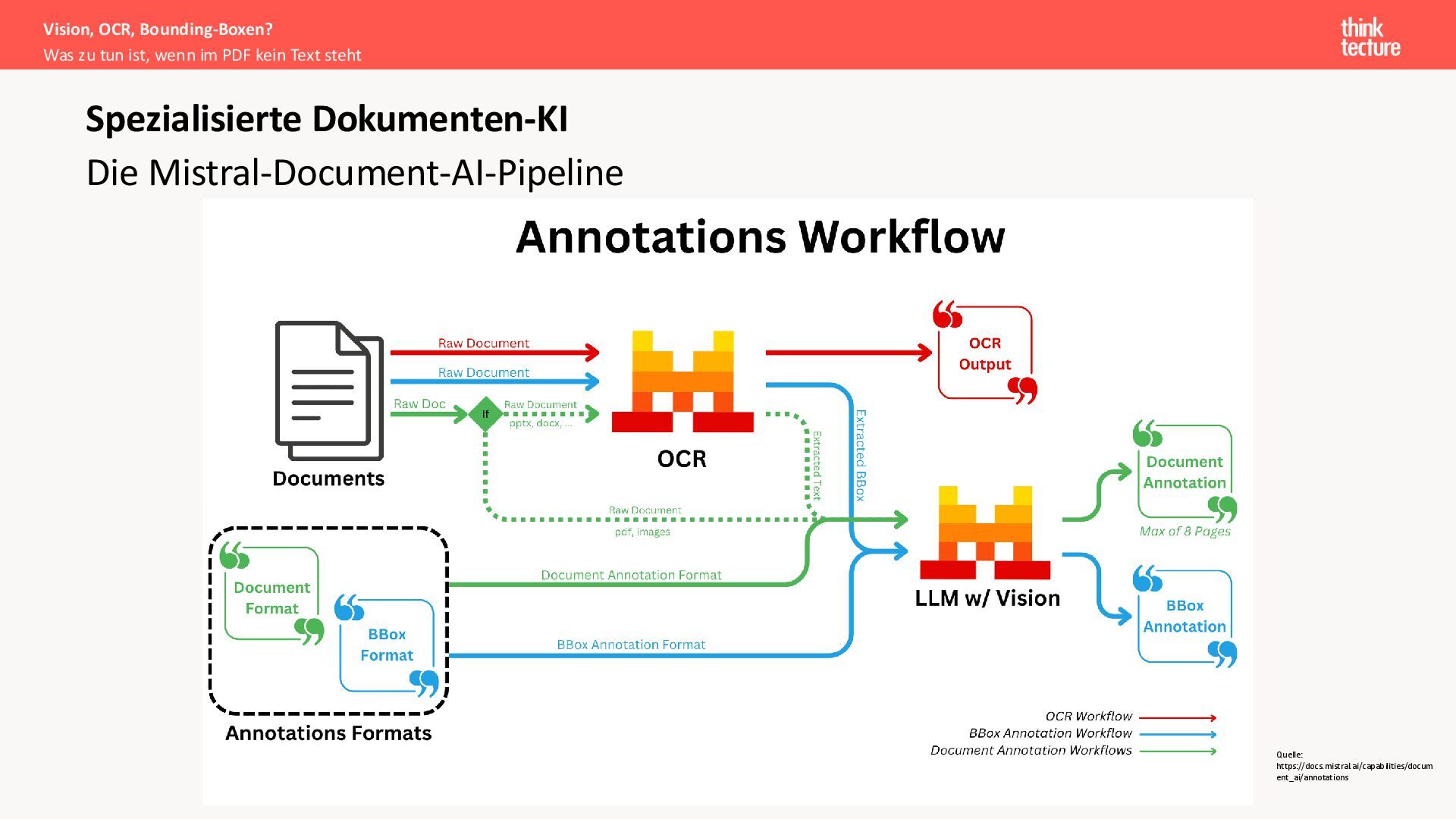{kind=link}
{kind=link}
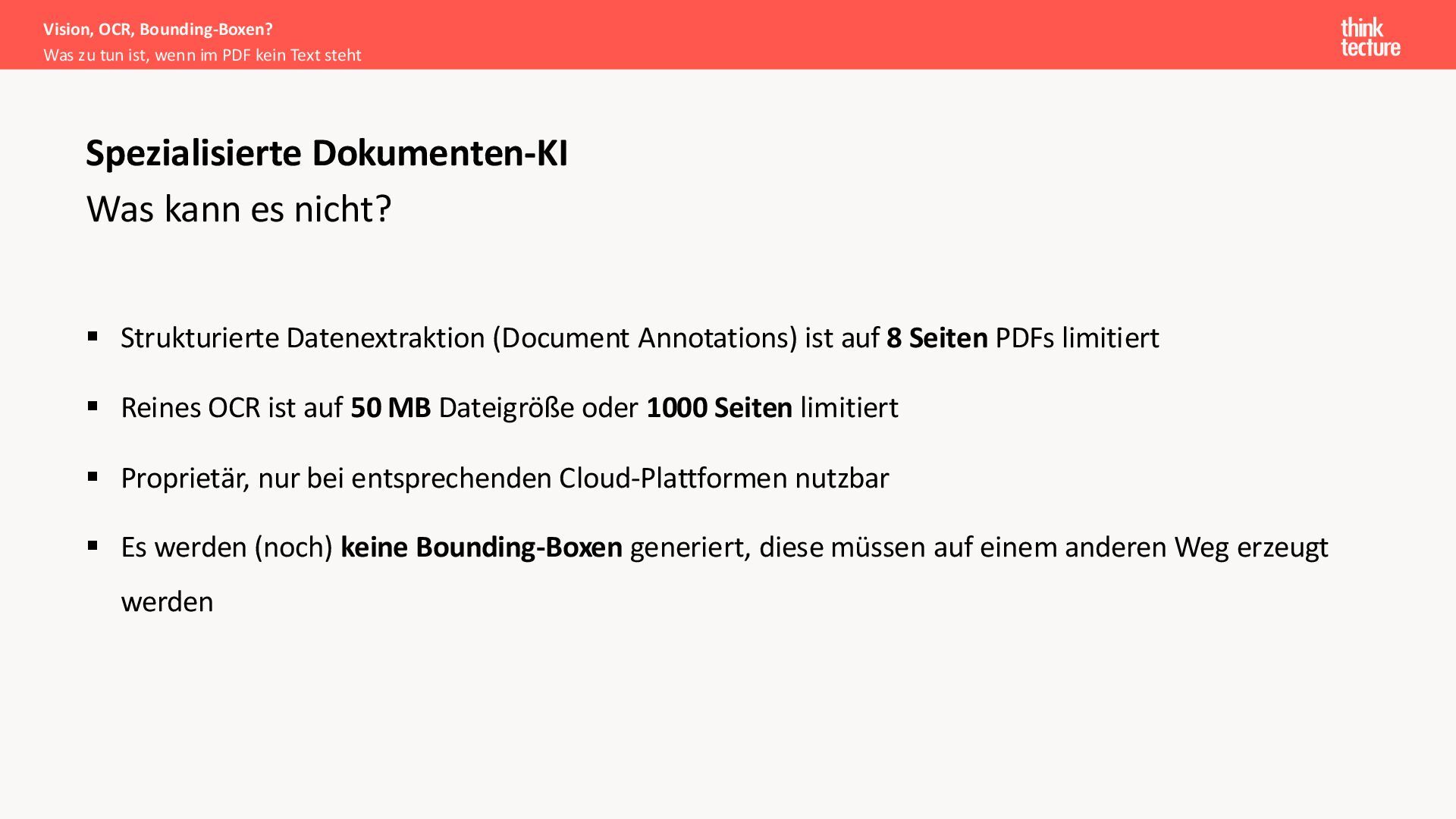{kind=link}
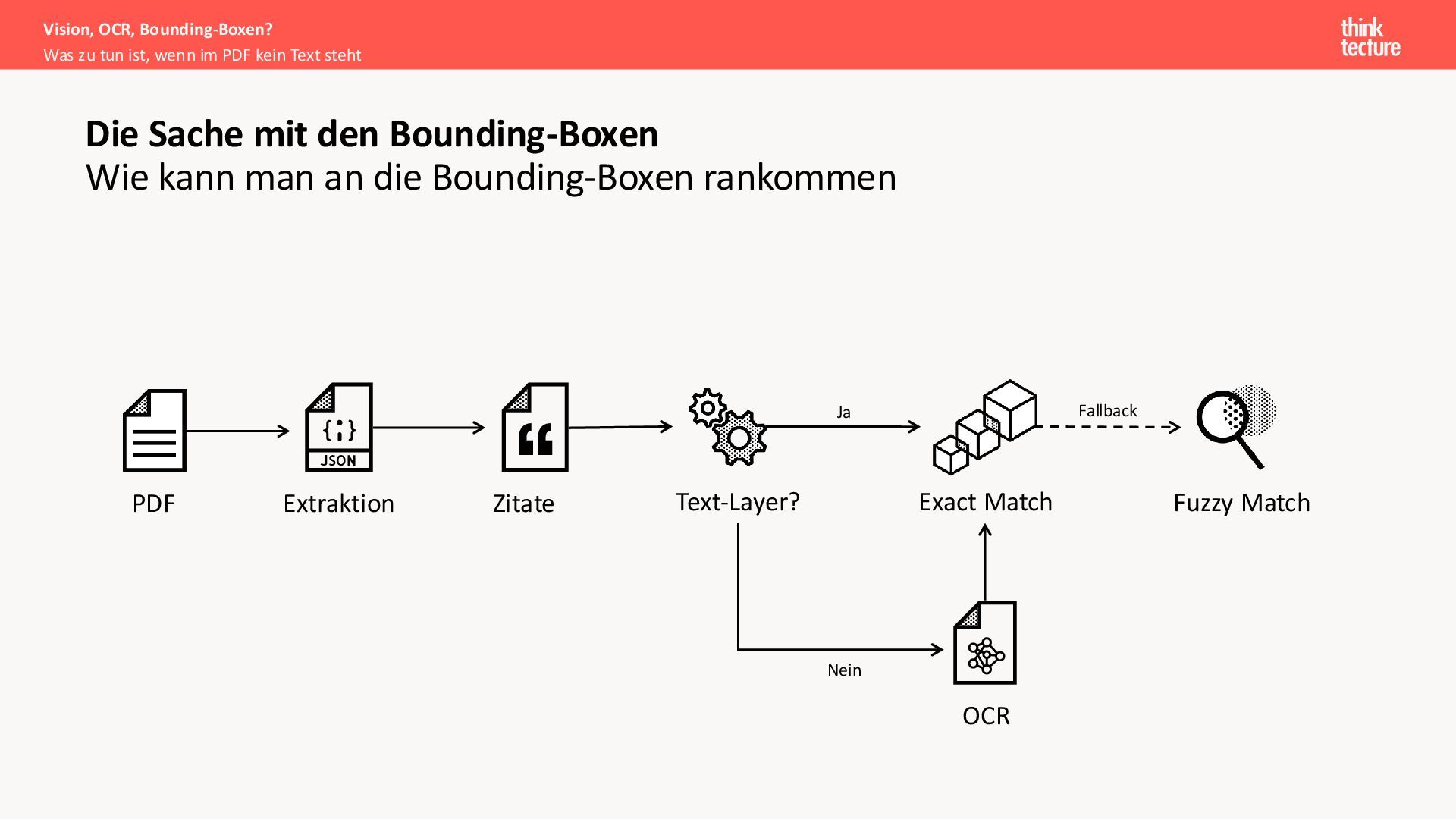{kind=link}
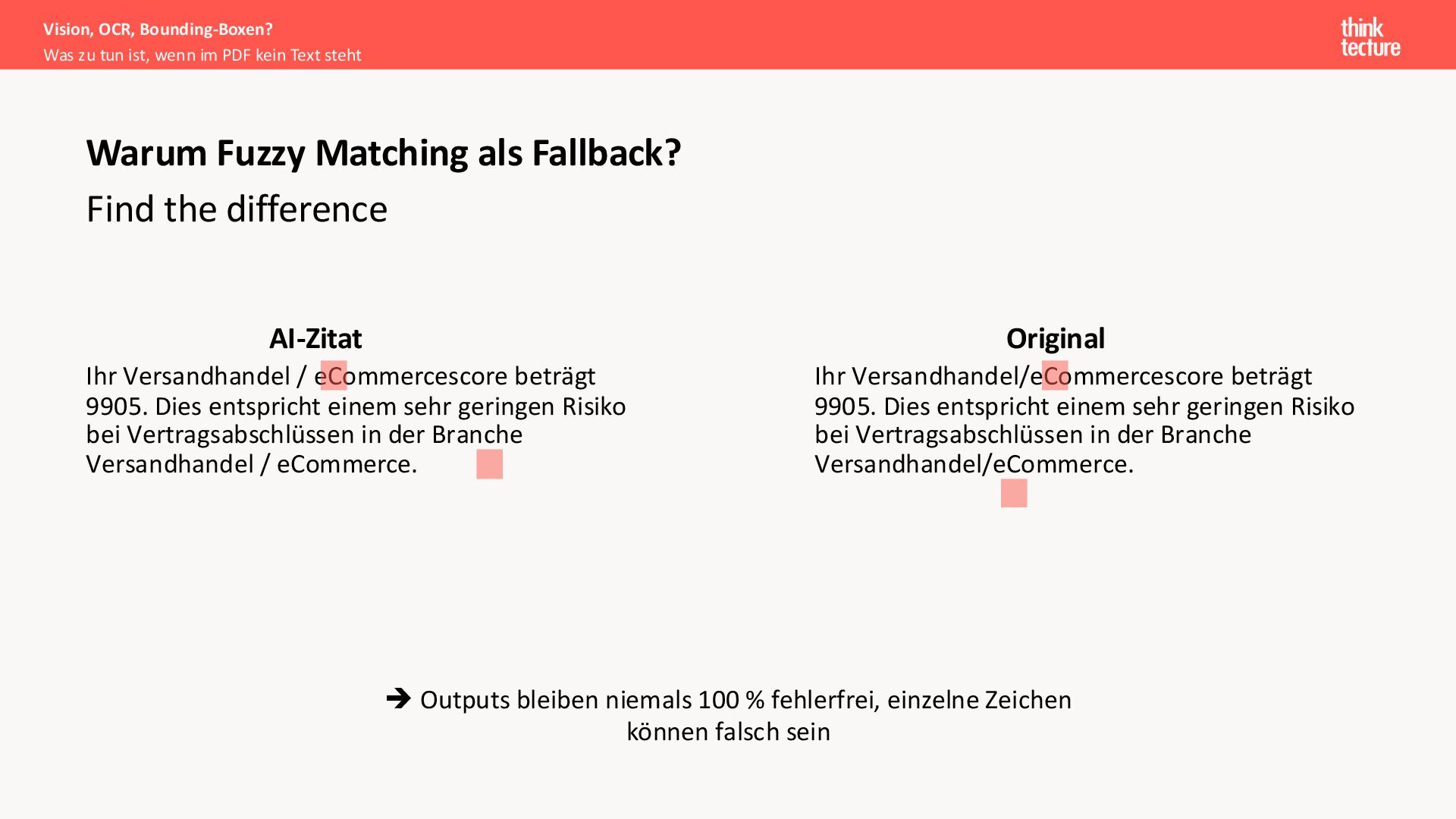{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Vielen Dank für eure Aufmerksamkeit! Lukas Köhler @lukkoeh [email protected]](https://files.speakerdeck.com/presentations/4c722bbf4ba44d528dbb0a4fece771cc/slide_28.jpg){kind=link}