Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Hadoop Operations
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Marc Cluet
June 09, 2013
Technology
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Hadoop Operations
Marc Cluet
June 09, 2013
More Decks by Marc Cluet
See All by Marc Cluet
FOSDEM'14 - Autoscaling Best Practices
lynxman
1
120
A metadata ocean in Chef and Puppet
lynxman
0
64
Rackspace Hack Night - Vagrant & Packer
lynxman
0
150
Innovation in the Cloud - Rackspace Zurich Event
lynxman
0
110
Introduction to DevOps - Rackspace Tech Night
lynxman
1
85
Introduction To Hadoop
lynxman
1
120
SSH That Wonderful Thing
lynxman
1
92
Networking & DNS 101
lynxman
0
100
Juju and Puppet - Rapid Harmonious Deployment
lynxman
0
110
Other Decks in Technology
See All in Technology
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
390
企業でAWS Organizationsを動かすための組織設計の考え方
nrinetcom
PRO
1
110
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
160
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
420
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
13
6.5k
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
110
Making sense of Google’s agentic dev tools
glaforge
1
280
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.5k
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
230
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
880
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.3k
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
760
Featured
See All Featured
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
310
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Writing Fast Ruby
sferik
630
63k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
970
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
We Are The Robots
honzajavorek
0
280
Raft: Consensus for Rubyists
vanstee
141
7.6k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
New Earth Scene 8
popppiees
3
2.4k
Transcript
Marc Cluet – Lynx Consultants How Hadoop Works
What we’ll cover? ¡ Understand Hadoop in detail ¡
See how Hadoop works operationally ¡ Be able to start asking the right questions from your data Lynx Consultants © 2013
Hadoop Distributions ¡ Cloudera CDH ¡ Hortonworks ¡
MapR Lynx Consultants © 2013
Hadoop Components ¡ HDFS ¡ Hbase ¡ MapRed
¡ YARN Lynx Consultants © 2013
Hadoop Components ¡ HDFS § Hadoop Distributed File System
§ Everything sits on top of it § Has 3 copies by default of every block ¡ Hbase ¡ MapRed ¡ YARN Lynx Consultants © 2013
Hadoop Components ¡ HDFS ¡ Hbase § Hadoop
Schemaless Database § Key value Store § Sits on top of HDFS ¡ MapRed ¡ YARN Lynx Consultants © 2013
Hadoop Components ¡ HDFS ¡ Hbase ¡ MapRed
§ Hadoop Map/Reduce § Non-‐pluggable, archaic § Requires HDFS for temp storage ¡ YARN Lynx Consultants © 2013
Hadoop Components ¡ HDFS ¡ Hbase ¡ MapRed
¡ YARN § Hadoop Map/Reduce version 2.0 § Pluggable, you can add your own § Fast and not so much memory hungry Lynx Consultants © 2013
Hadoop Component Breakdown ¡ All these components divide themselves in
§ client/server § master/slave scenarios ¡ We will now check each individual component breakdown Lynx Consultants © 2013
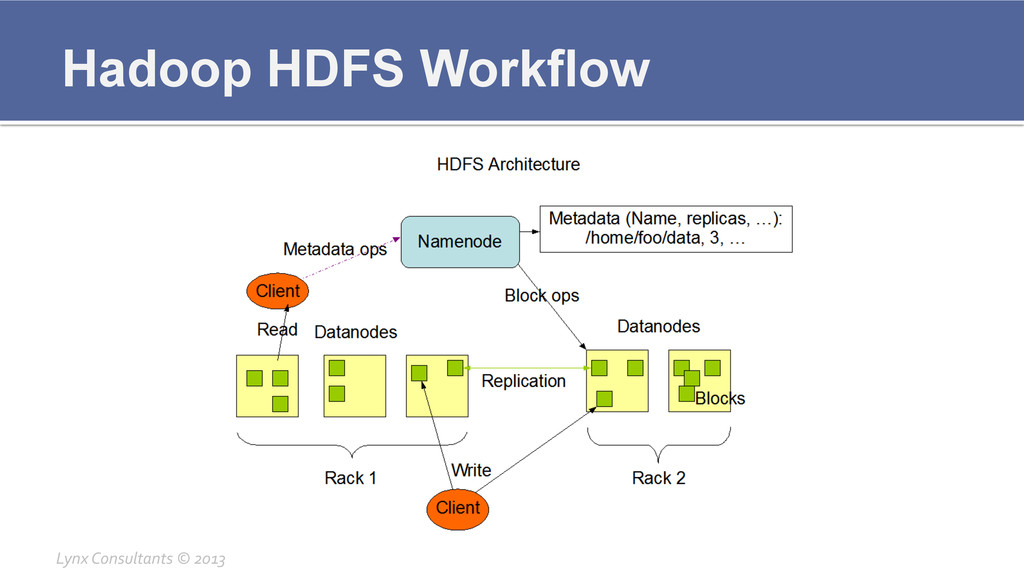
Hadoop Components Breakdown ¡ HDFS § Master Namenode
▪ Keeps track of all file allocation on Datanodes ▪ Rebalances data if one of the namenodes goes down ▪ Is Rack aware § Secondary Namenode ▪ Does cleanup services for the namenode ▪ Not necessarily two different servers § Datanode ▪ Stores the data ▪ Good to have not RAID disks for extra I/O speed Lynx Consultants © 2013
Hadoop Components Breakdown ¡ HDFS § How to access
▪ Client can connect with hadoop client to hdfs://namenode:8020 ▪ Supports all basic Unix commands § Configuration files ▪ /etc/hadoop/conf/core-‐site.xml ▪ Defines major configuration as hdfs namenode and default parameters ▪ /etc/hadoop/conf/hdfs-‐site.xml ▪ Defines configuration specific to namenode or datanode on file locations ▪ /etc/hadoop/conf/slaves ▪ Defines the list of servers that are available in this cluster Lynx Consultants © 2013
Hadoop Components Breakdown ¡ Hbase § Master ▪
Controls the Hbase cluster, knows where the data is allocated and provides a client listening socket using Thrift and/or a RESTful API § Regionserver ▪ Hbase node, stores some of the information in one of the regions, it’d be equivalent to sharding § Thrift / REST ▪ Interface to connect to HBase Lynx Consultants © 2013
Hadoop Components Breakdown ¡ Hbase § How to access
▪ Through the Hbase client (using Thrift) ▪ Through the RESTful API § Configuration files ▪ /etc/hbase/conf/hbase-‐site.xml ▪ Defines all the basic configuration for accessing hbase ▪ /etc/hbase/conf/hbase-‐policy.xml ▪ Defines all the security (ACL) and all the hbase memory tweaks ▪ /etc/hbase/conf/regionservers ▪ List all the regionservers available to this cluster Lynx Consultants © 2013
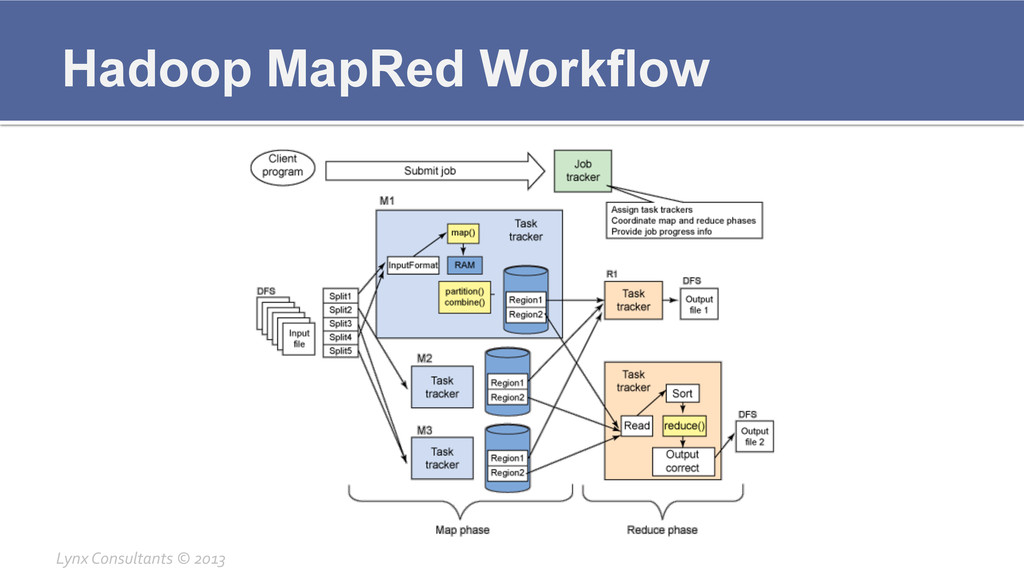
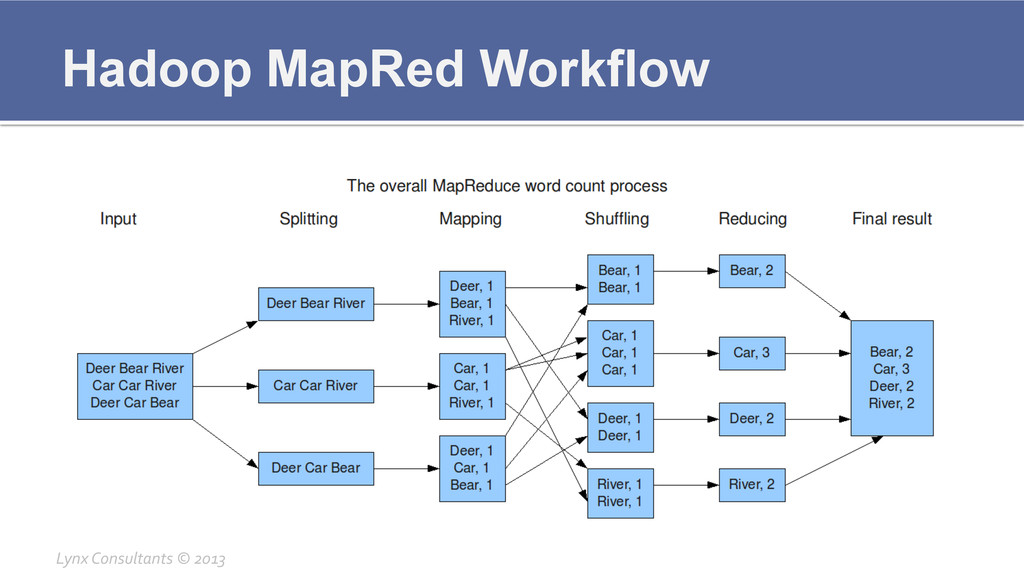
Hadoop Components Breakdown ¡ MapRed § JobTracker ▪
Creates the Map/Reduce jobs ▪ Stores all the intermediate data ▪ Keeps track of all the previous results through the HistoryServer § TaskTracker ▪ Executed Tasks related to the Map/Reduce job ▪ Very CPU and memory intensive ▪ Stores intermediate results which then are pushed to JobTracker Lynx Consultants © 2013
Hadoop Components Breakdown ¡ MapRed § How to access
▪ Through the Hadoop Client ▪ Through any MapRed client like Pig or Hive ▪ Own Java code § Configuration files ▪ /etc/hadoop/conf/mapred-‐site.xml ▪ Defines how to contact this MapRed Cluster ▪ /etc/hadoop/conf/mapred-‐queue-‐acls.xml ▪ Defines ACL structure for accessing MapRed, normally not necessary ▪ /etc/hadoop/conf/slaves ▪ Defines the list of TaskTrackers in this cluster Lynx Consultants © 2013
Hadoop Components Breakdown ¡ YARN § Same structure as
MapRed (lives on top of it) § Configuration files ▪ /etc/hadoop/conf/yarn-‐site.xml ▪ All required configuration for YARN Lynx Consultants © 2013
Hadoop Cluster Breakdown ¡ Namenode Server § HDFS Namenode
§ Hbase Master ¡ Secondary Namenode Server § HDFS Secondary Namenode ¡ JobTracker Server § MapRed JobTracker § MapRed History Server Lynx Consultants © 2013
Hadoop Cluster Breakdown ¡ Datanode Server § HDFS Datanode
§ Hbase RegionServer § MapRed TaskTracker Lynx Consultants © 2013
Hadoop Hardware Requirements ¡ Namenode Server § Redundant power
supplies § RAID1 Drives § Enough memory (16Gb) ¡ Secondary Namenode Server § Almost none Lynx Consultants © 2013
Hadoop Hardware Requirements ¡ Jobtracker Server § Redundant power
supplies § RAID1 Drives § Enough memory (16Gb) ¡ Datanode Server § Lots of cheap disk (no RAID) § Lots of memory (32Gb) § Lots of CPU Lynx Consultants © 2013
Hadoop Default Ports ¡ HDFS § 8020: HDFS Namenode
§ 50010: HDFS Datanode FS transfer ¡ MapRed § No defaults ¡ Hbase § 60010: Master § 60020: Regionserver Lynx Consultants © 2013
Hadoop HDFS Workflow Lynx Consultants © 2013
Hadoop MapRed Workflow Lynx Consultants © 2013
Hadoop MapRed Workflow Lynx Consultants © 2013
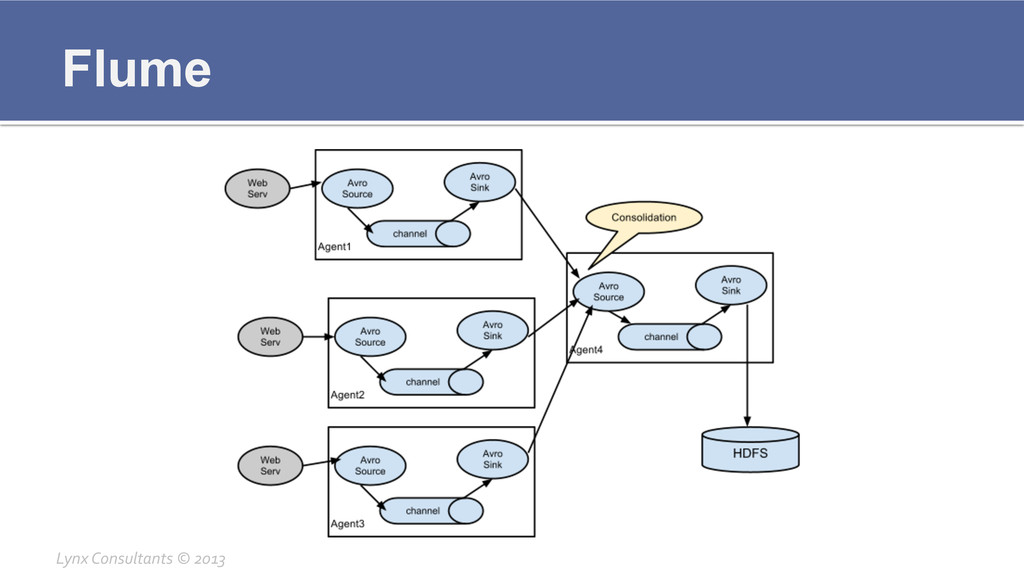
Flume ¡ Transports streams of data from point A to
point B ¡ Source § Where the data is read from ¡ Channel § How the data is buffered ¡ Sink § Where the data is written Lynx Consultants © 2013
Flume ¡ Flume is fault tolerant ¡ Sources are
pointer kept § With some exceptions, but most sources are in a known state ¡ Channels can be fault tolerant § Channel written to disk can recover from where it left ¡ Sinks can be redundant § More than one sink for the same data § Data is serialised and deduplicated using AVRO Lynx Consultants © 2013
Flume Lynx Consultants © 2013
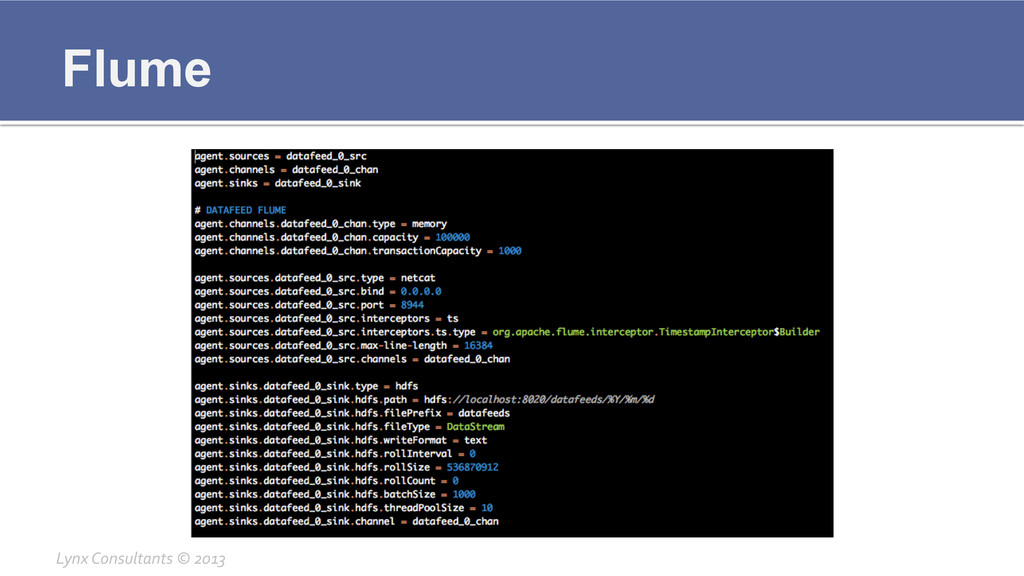
Flume ¡ Configuration files § /etc/flume-‐ng/conf/flume.conf ▪ Defines
the agent configuration with source, channel, sink Lynx Consultants © 2013
Flume Lynx Consultants © 2013
Hadoop Recommended Reads Lynx Consultants © 2013
Hadoop References ¡ Hadoop § http://hadoop.apache.org/docs/stable/cluster_setup.html § http://rc.cloudera.com/cdh/4/hadoop/hadoop-‐yarn/hadoop-‐yarn-‐site/
ClusterSetup.html § http://pig.apache.org/docs/r0.7.0/setup.html § http://wiki.apache.org/hadoop/NameNodeFailover ¡ Hbase § http://hbase.apache.org/book/book.html ¡ Flume § http://archive.cloudera.com/cdh4/cdh/4/flume-‐ng/ FlumeUserGuide.html Lynx Consultants © 2013
Questions? Lynx Consultants © 2013
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}