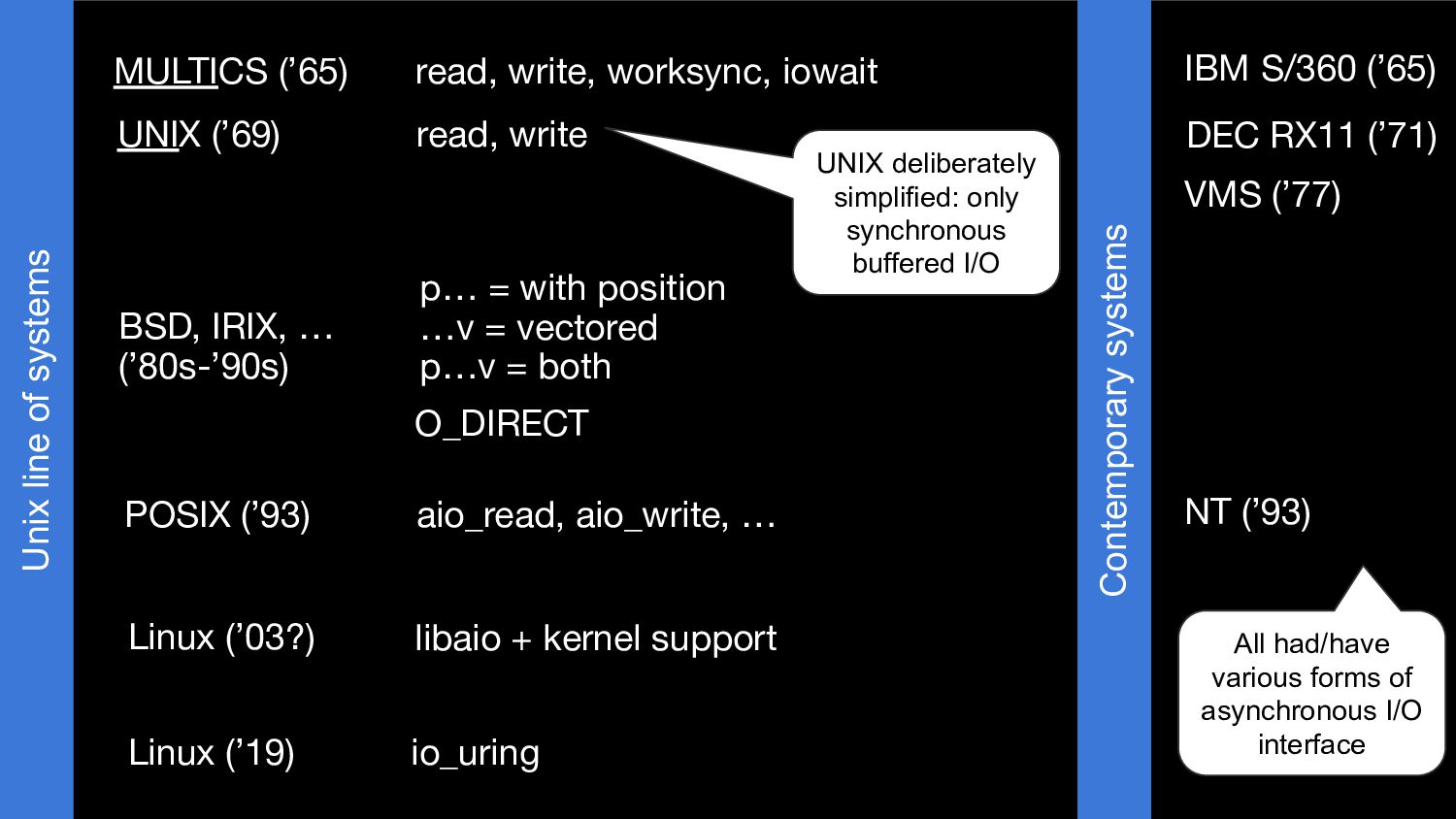
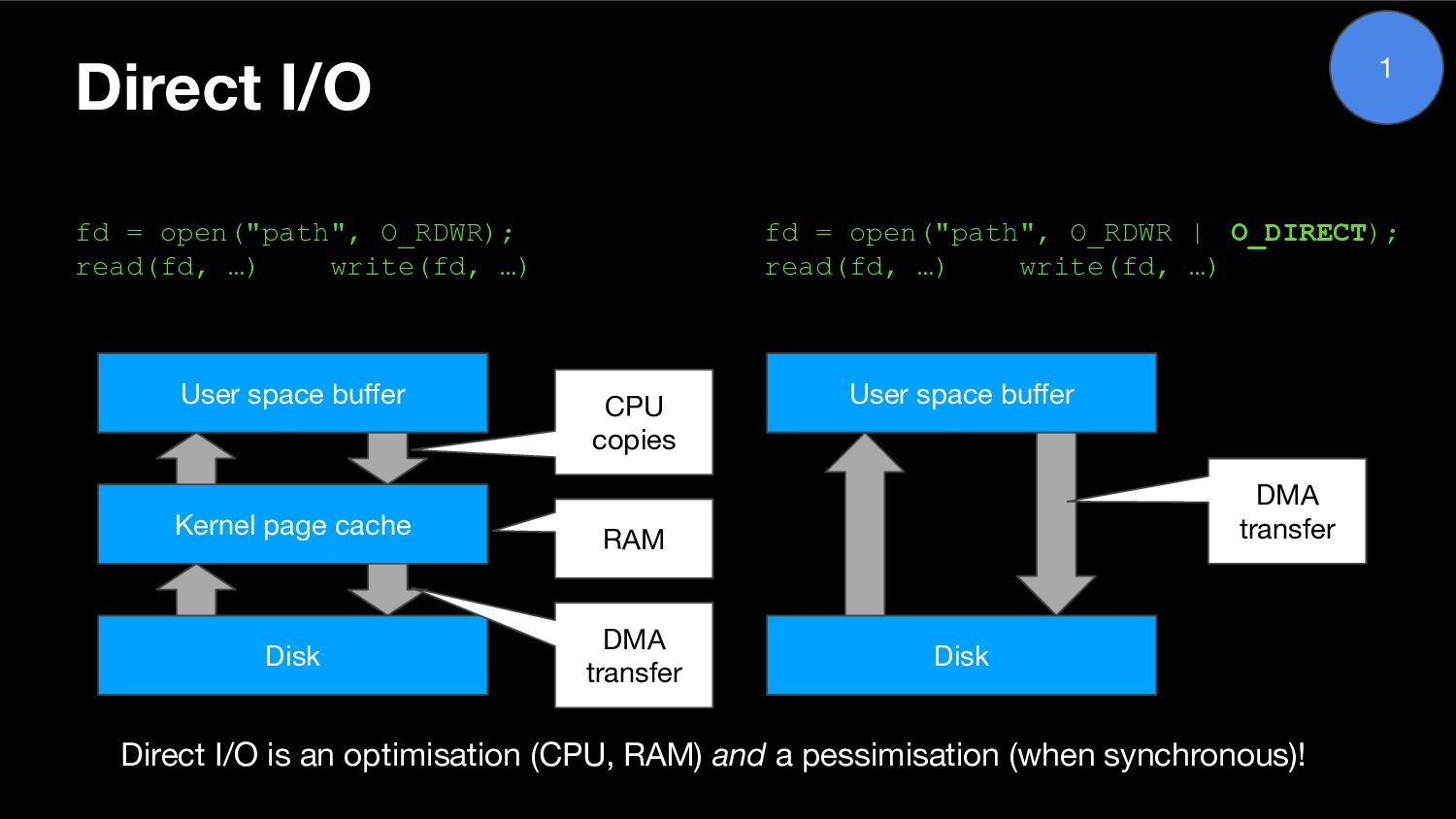
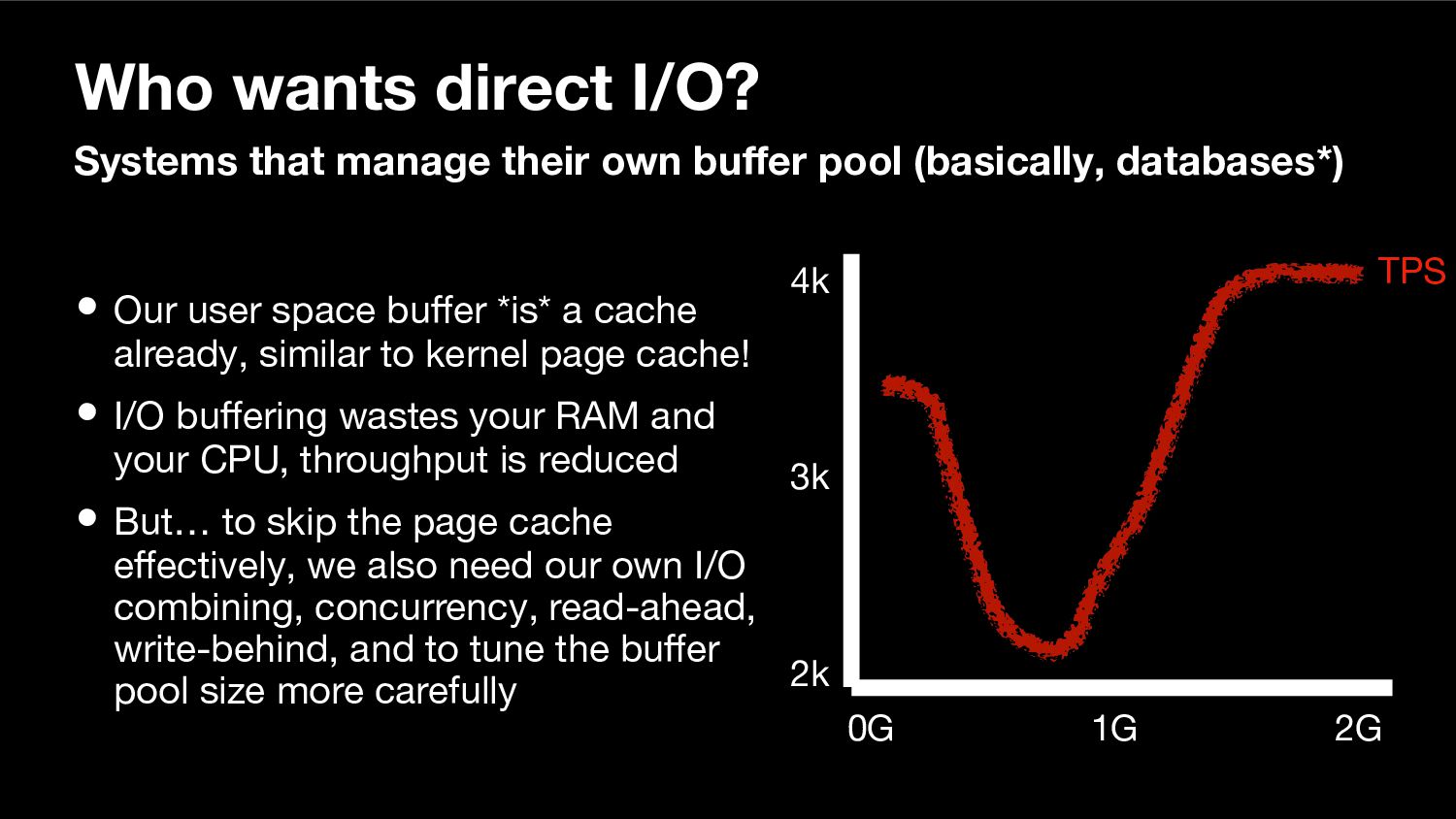
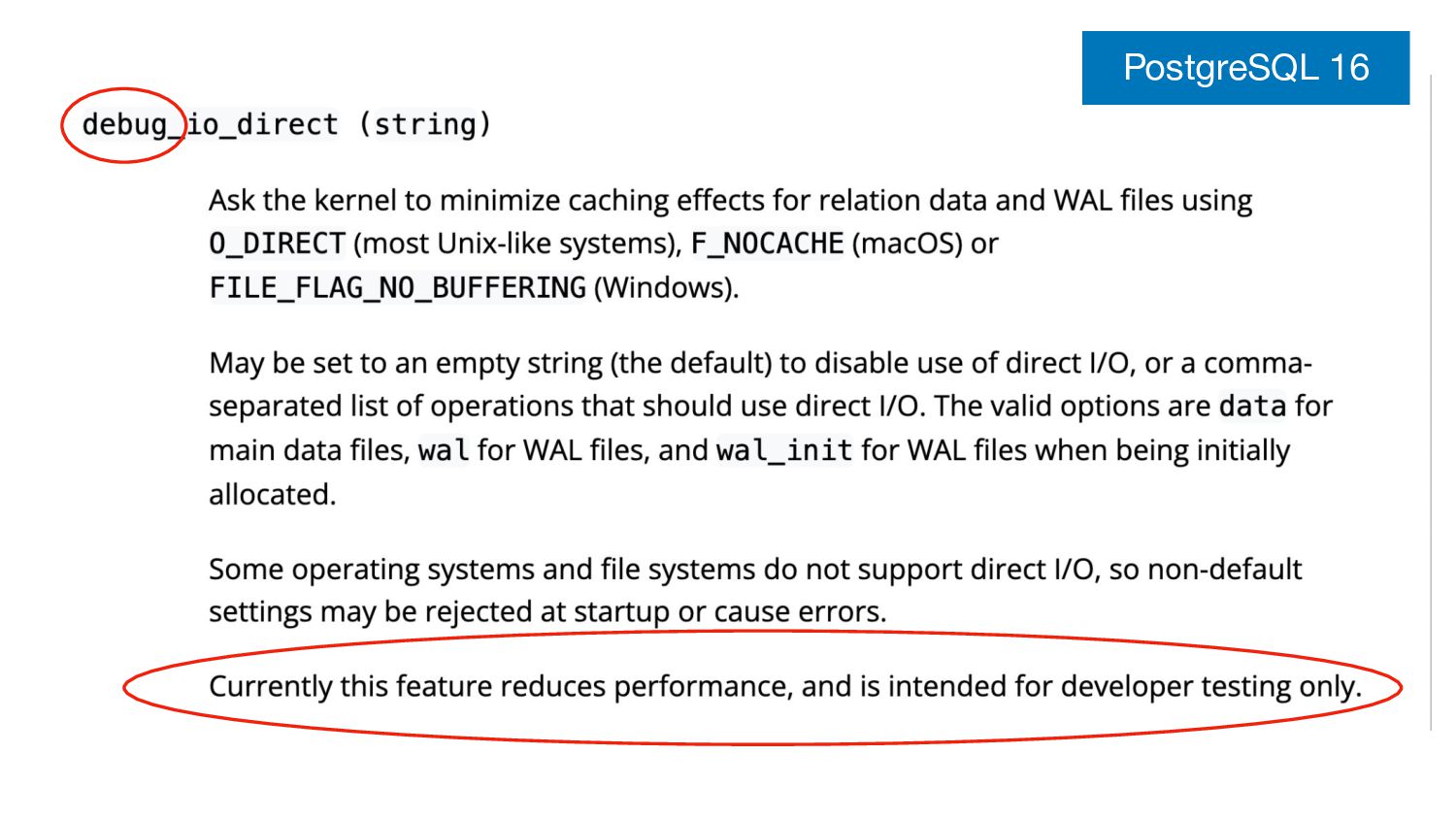
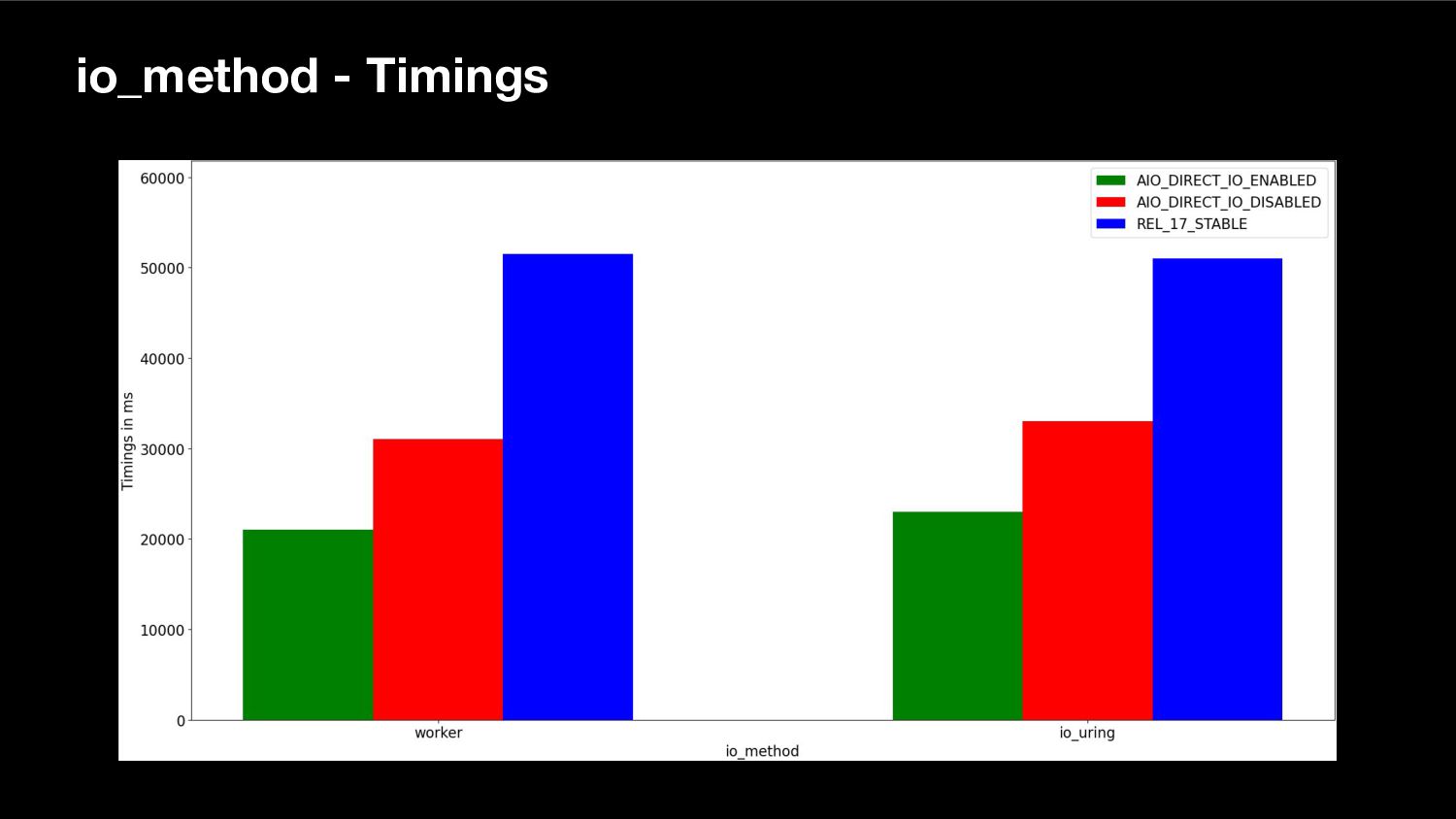
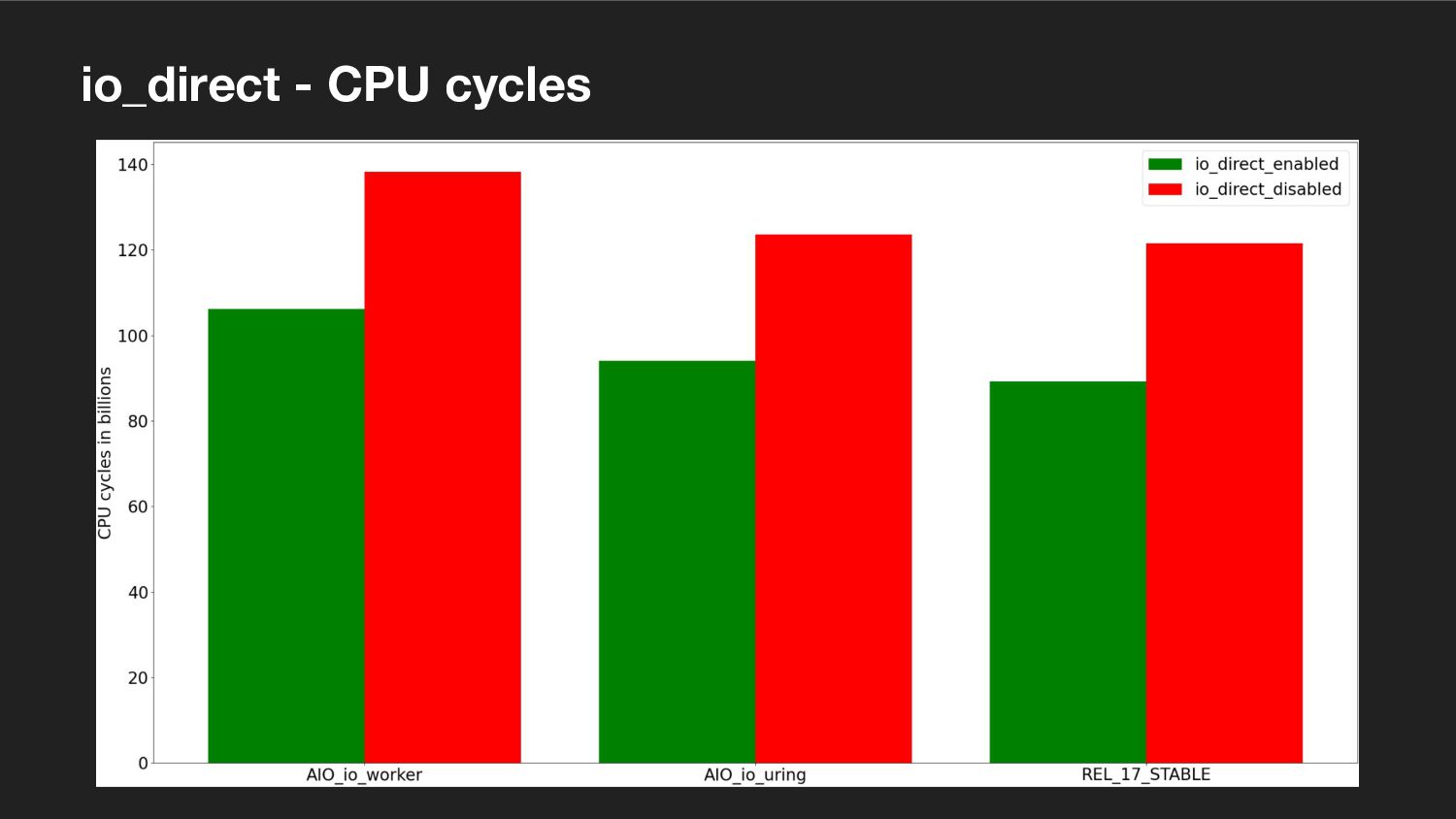
Another talk about streaming I/O, or more specifically about direct I/O, vectored I/O and asynchronous I/O and the streaming abstraction being developed over several PostgreSQL releases to enable efficient use of them. This talk was extended and co-presented with my colleague Nazir "Bilal" Yavuz.
https://www.postgresql.eu/events/pgconfeu2024/schedule/session/5720-streaming-io-and-vectored-io/
https://www.youtube.com/watch?v=8d6YrSByNew&t=2157s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
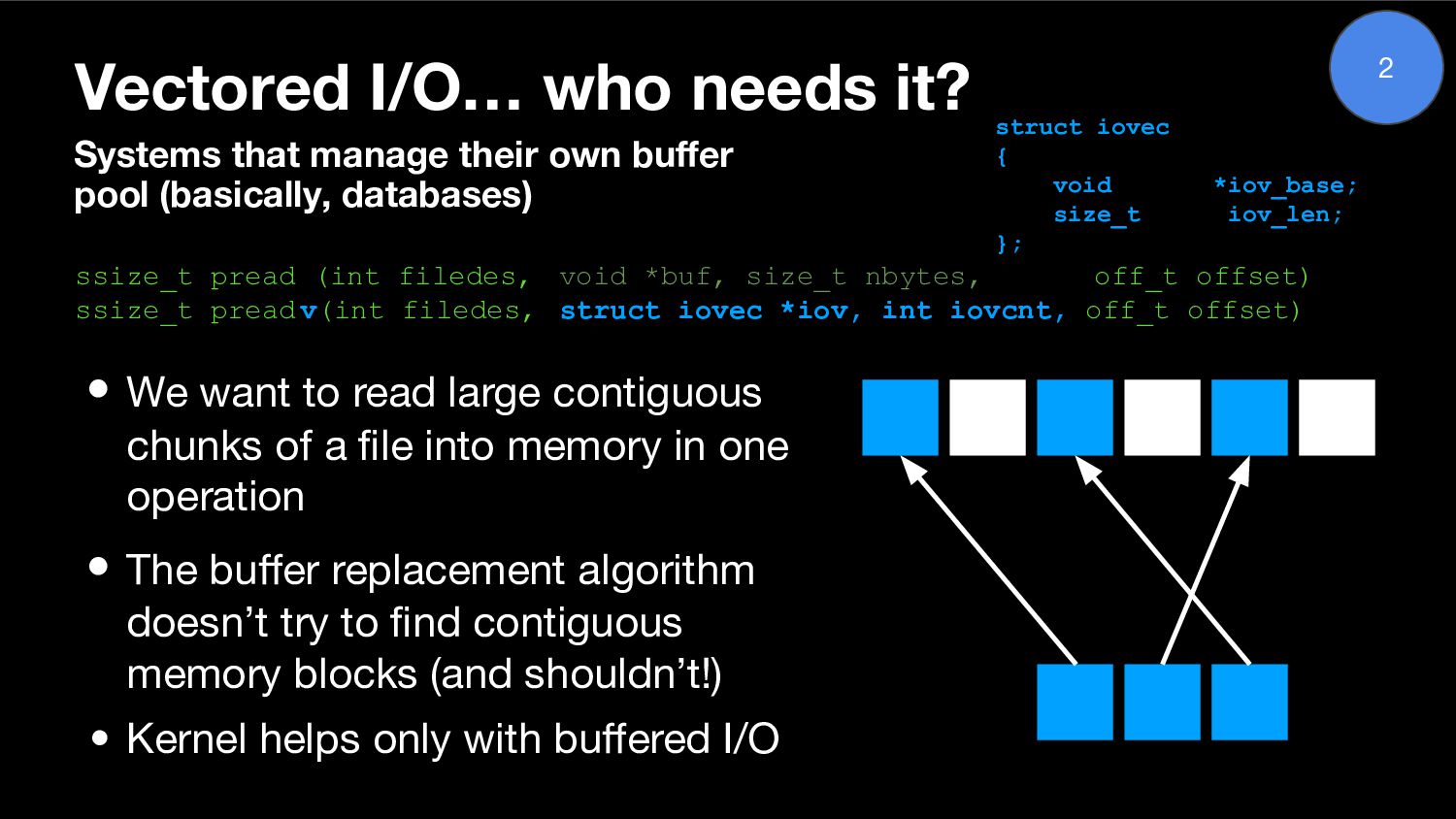{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
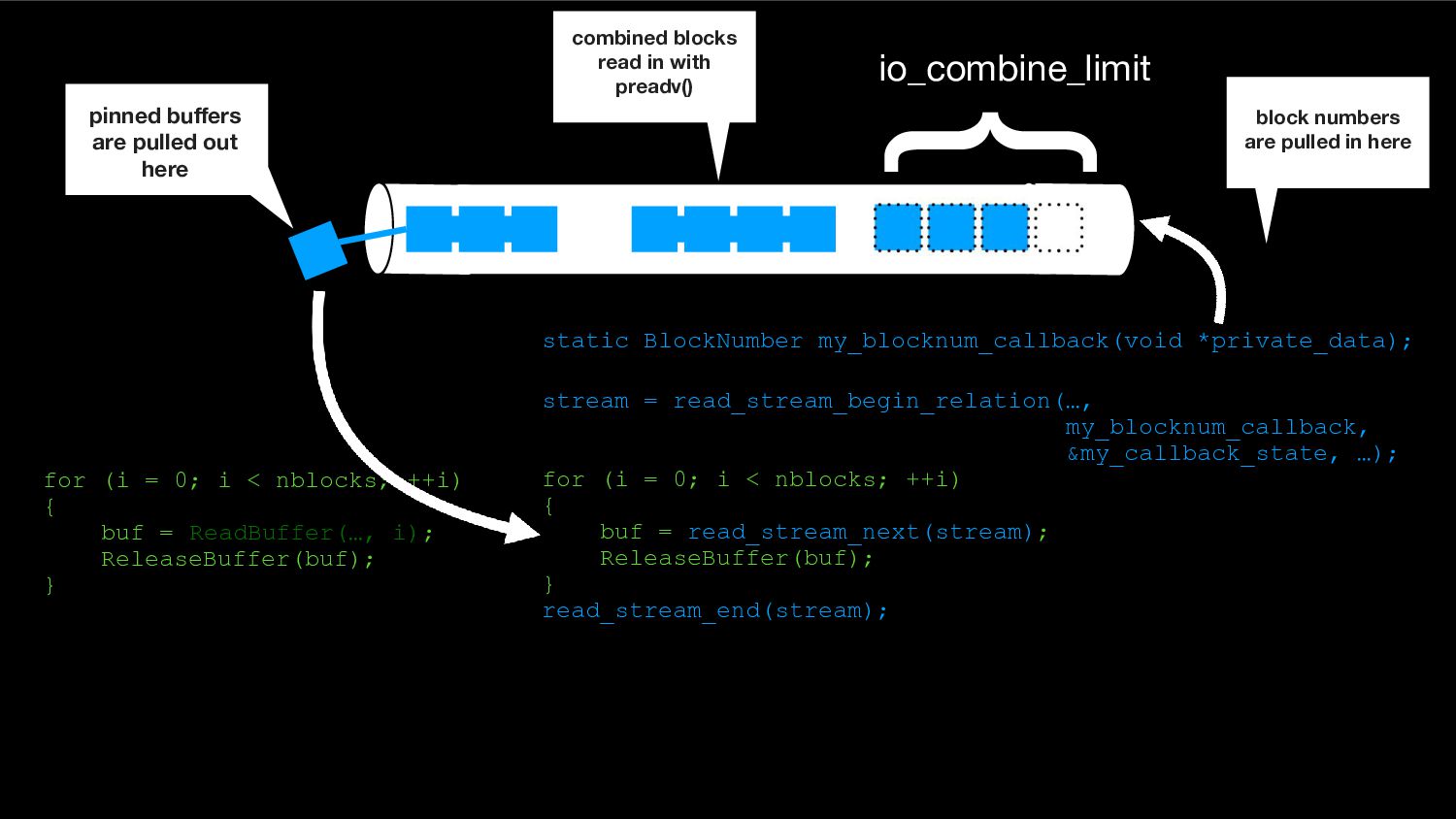{kind=link}
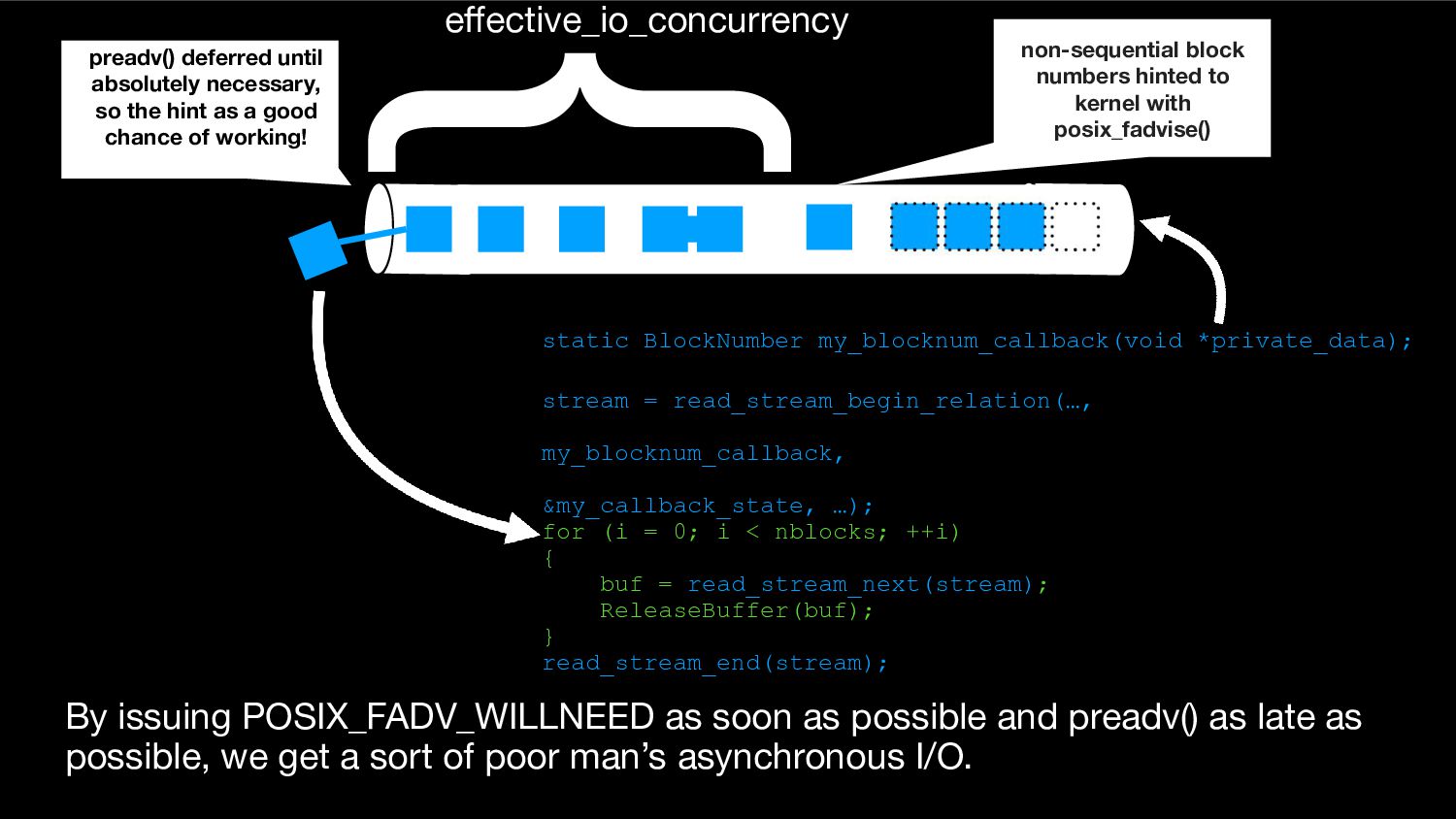{kind=link}
{kind=link}
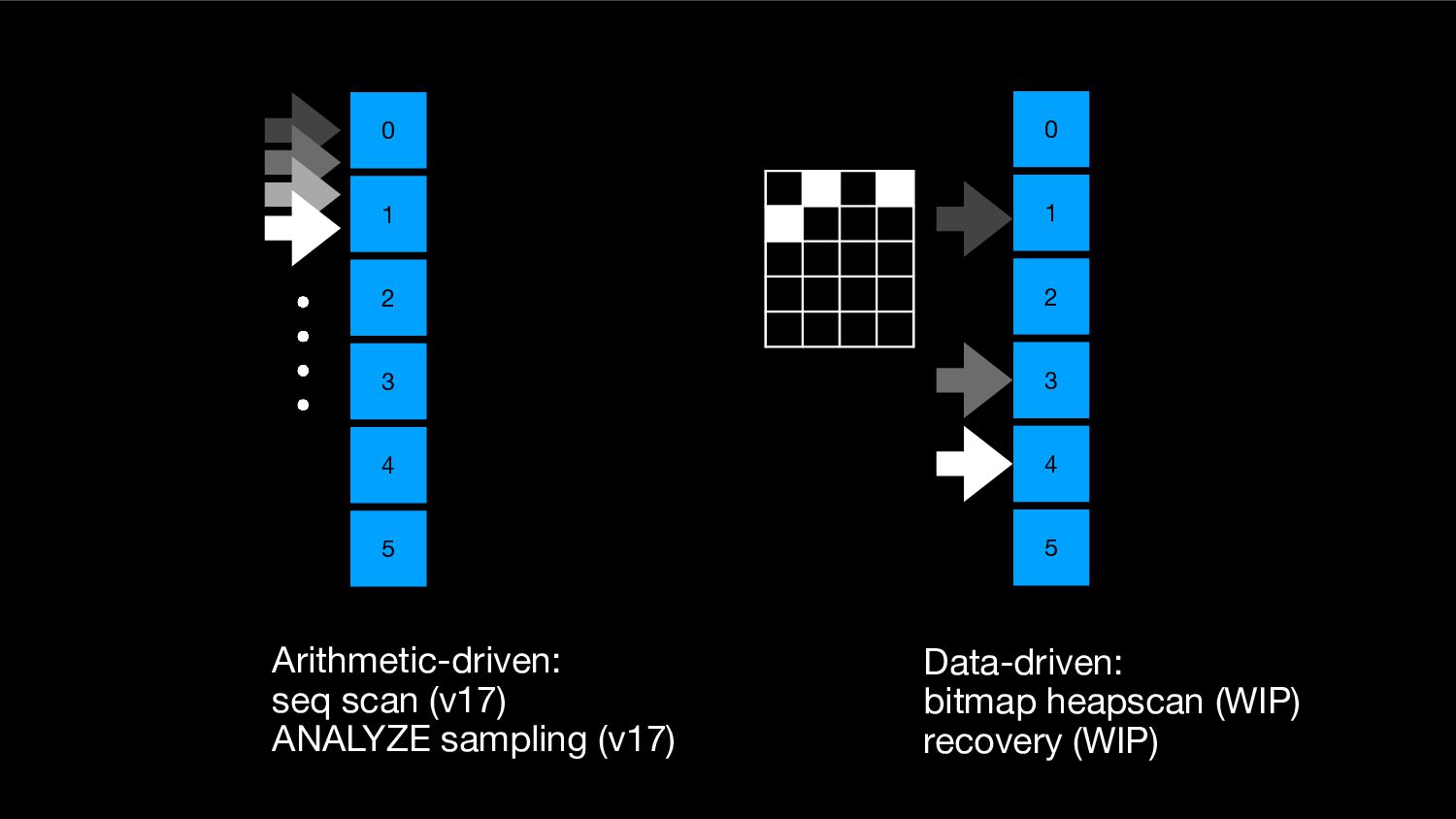{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
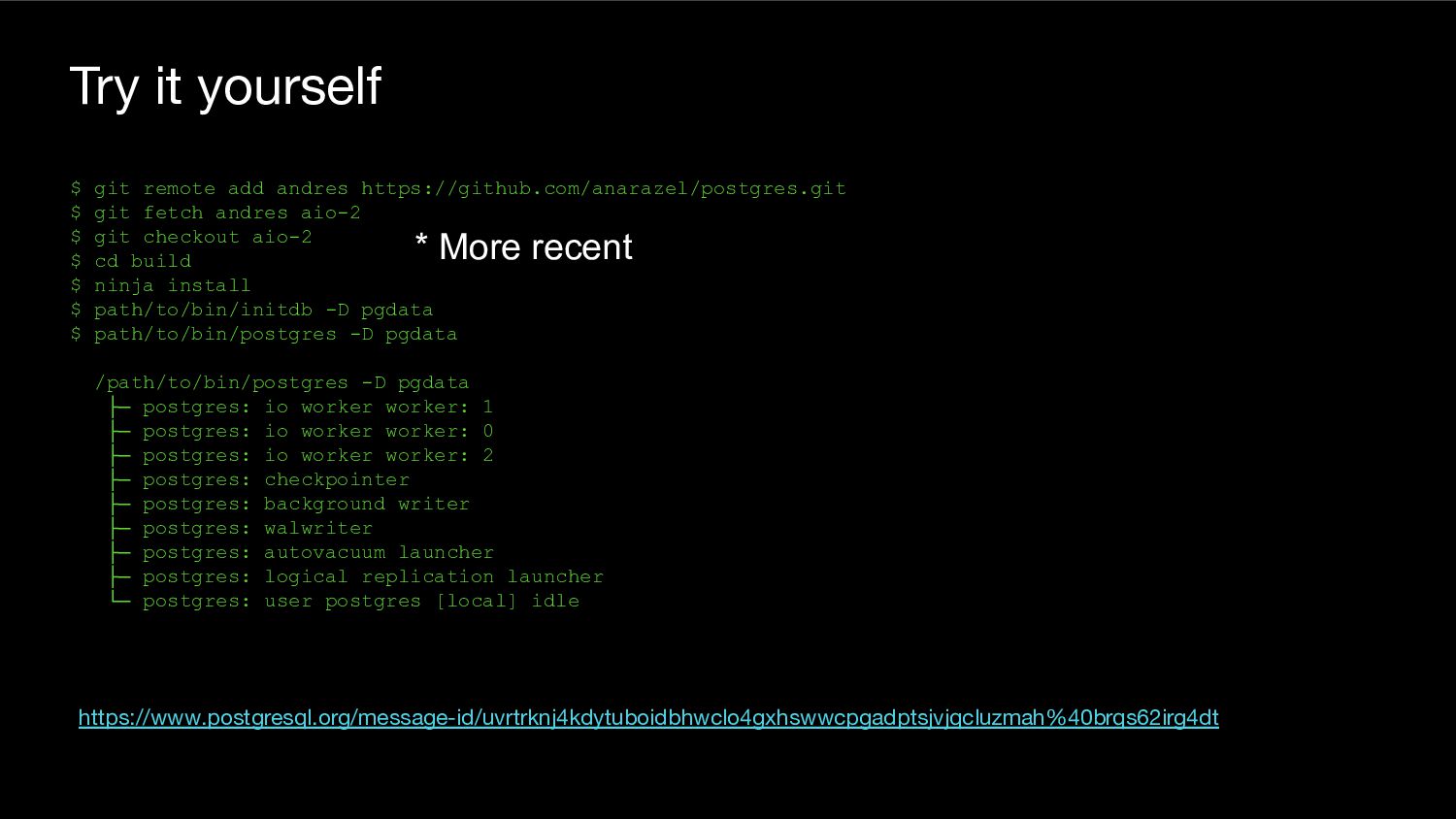{kind=link}
{kind=link}
{kind=link}
{kind=link}
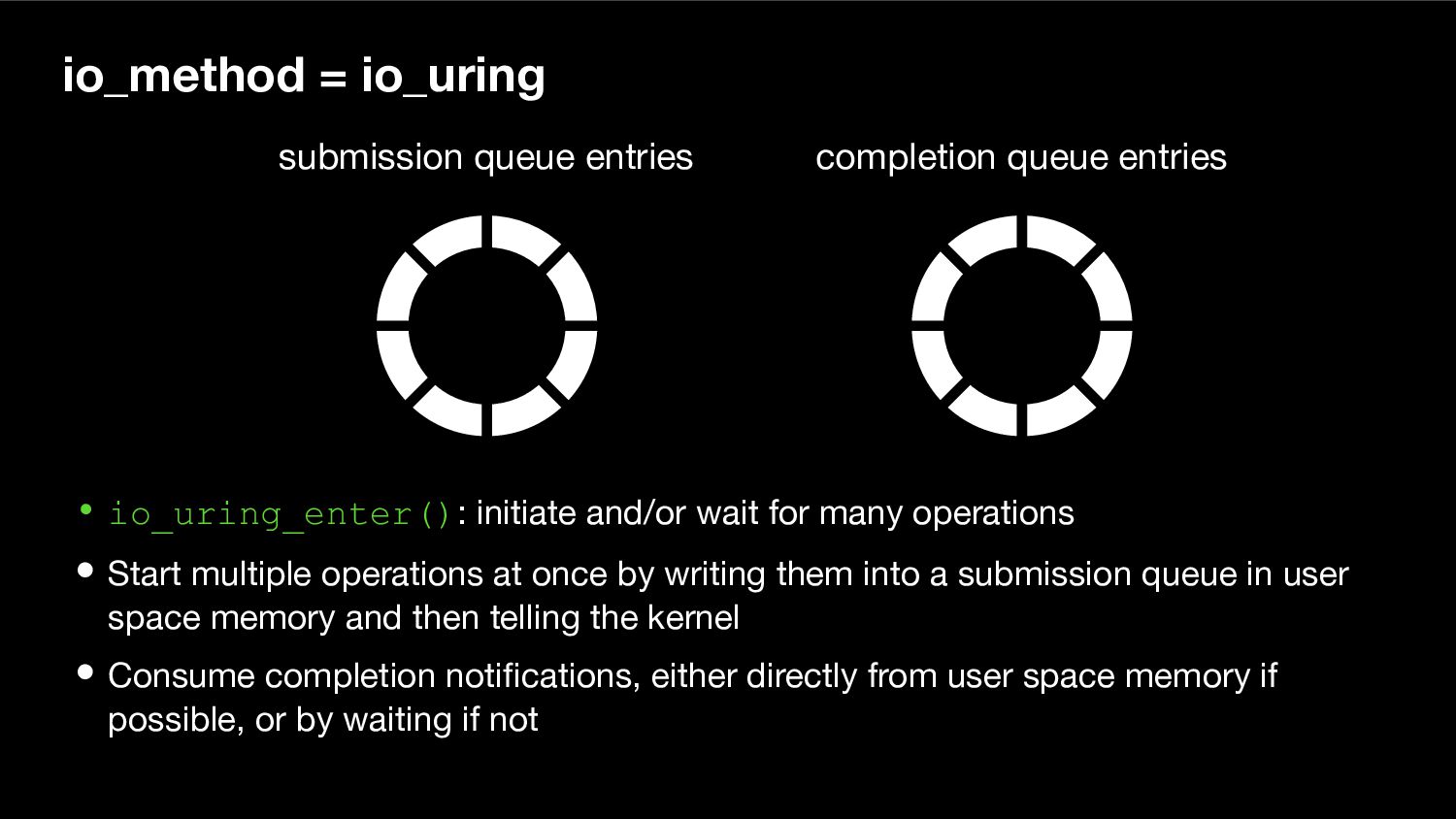{kind=link}
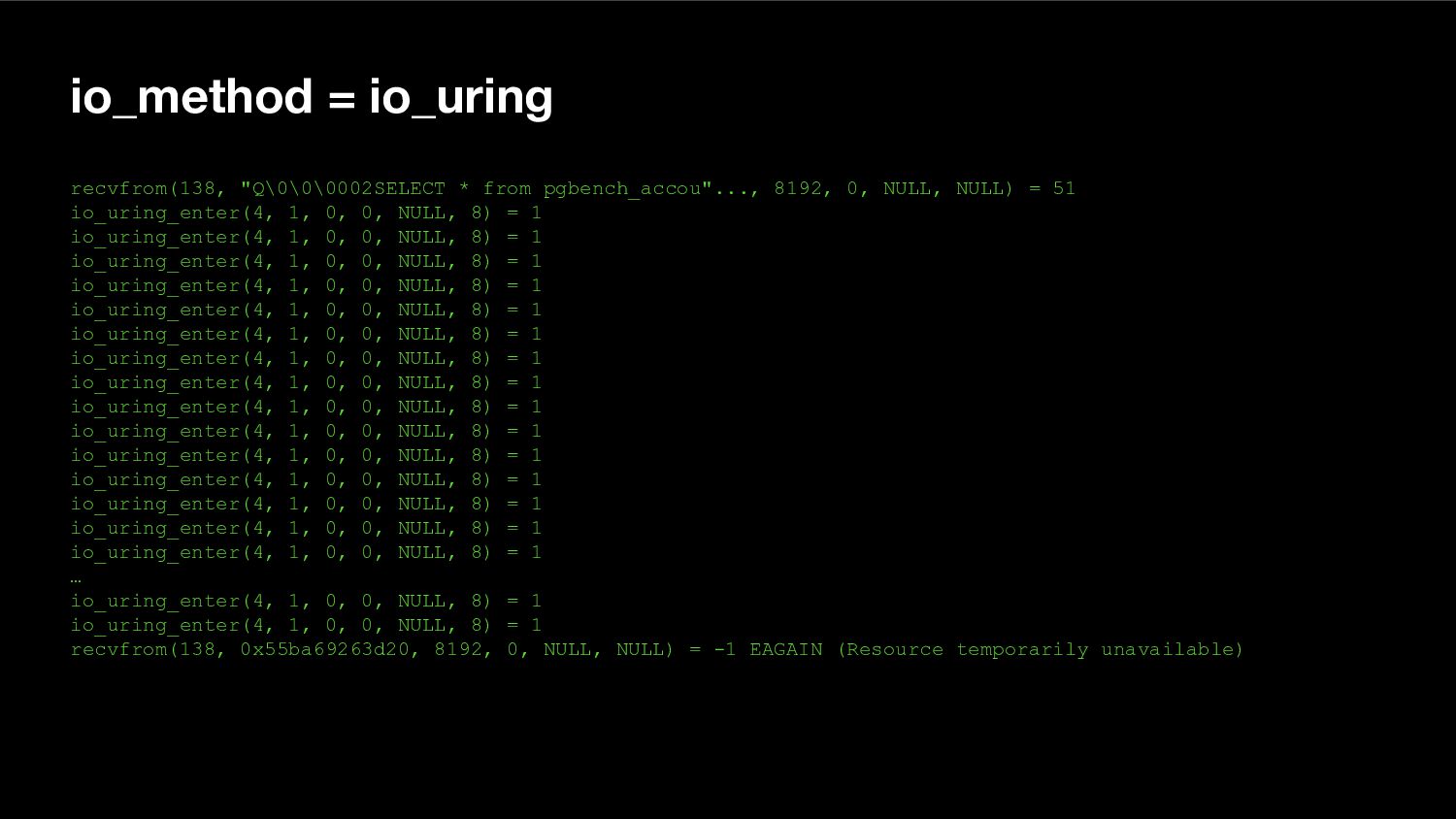{kind=link}
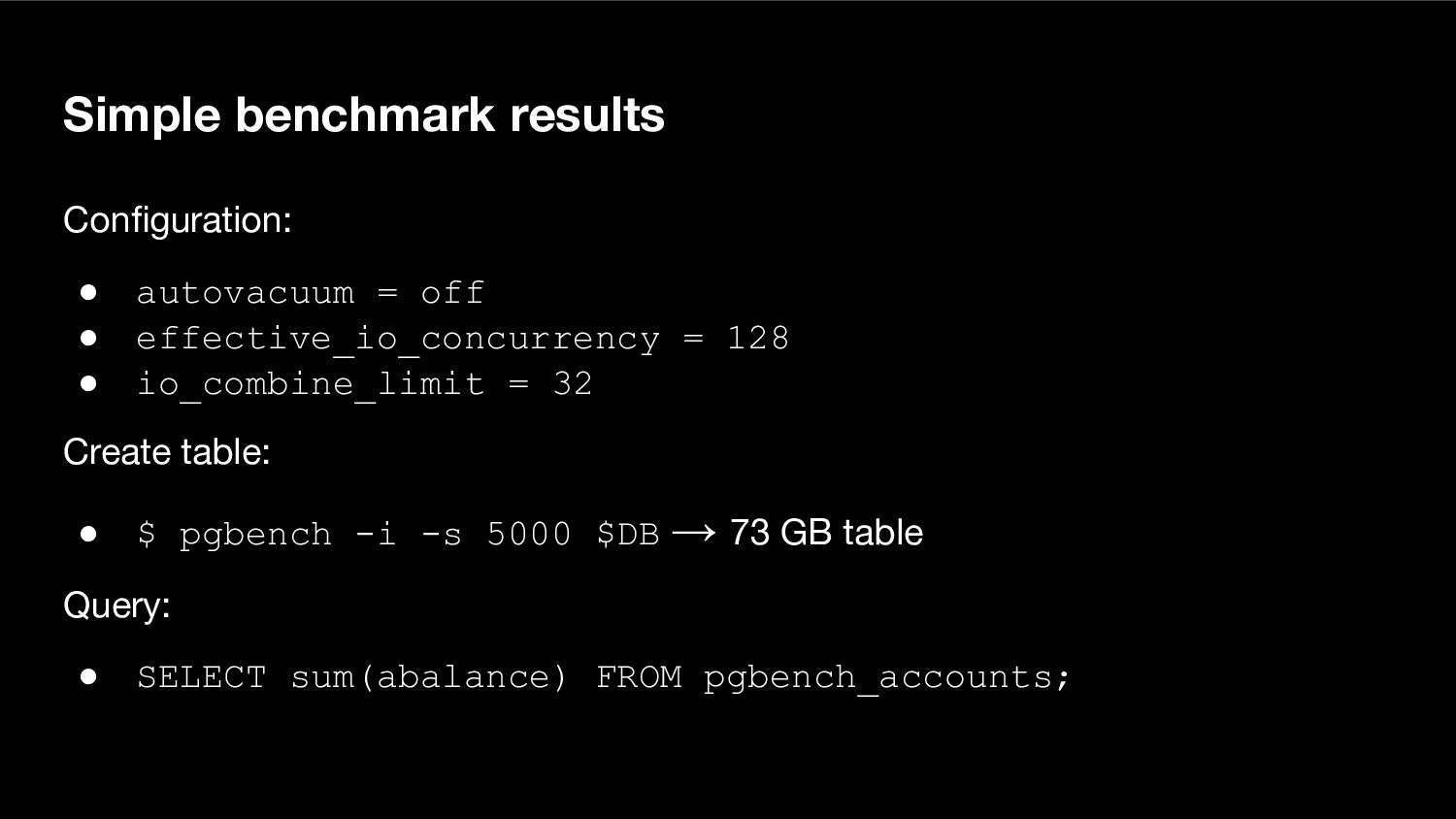{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}