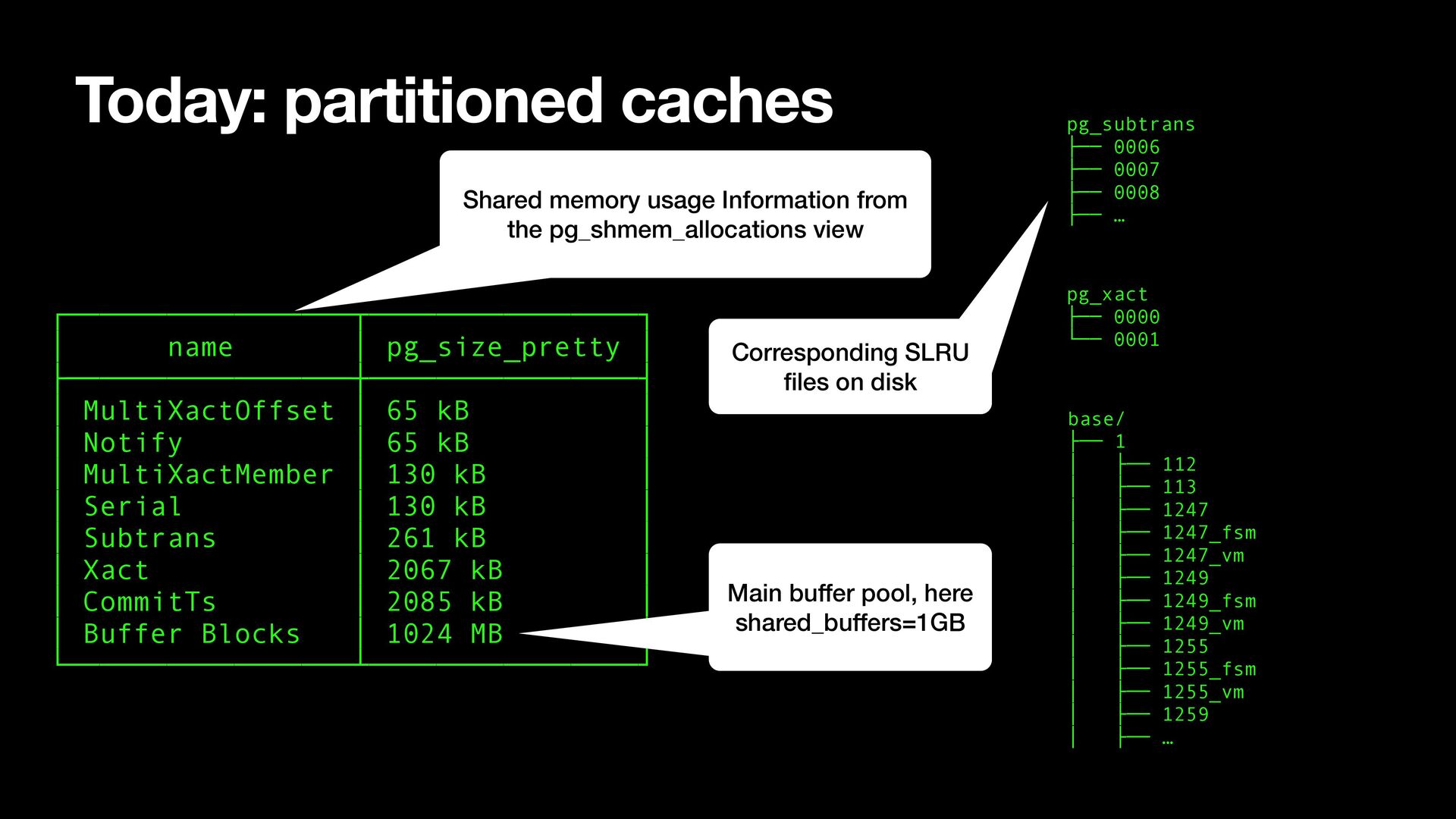
and bu ff ered access for 7 di ff erent types of critical transaction-related data • I would like to keep the fi le management part of the SLRU system unchanged, in this project • I would like to replace the separate fi xed-sized caches with ordinary bu ff ers in the main bu ff er pool • Status: work in progress!
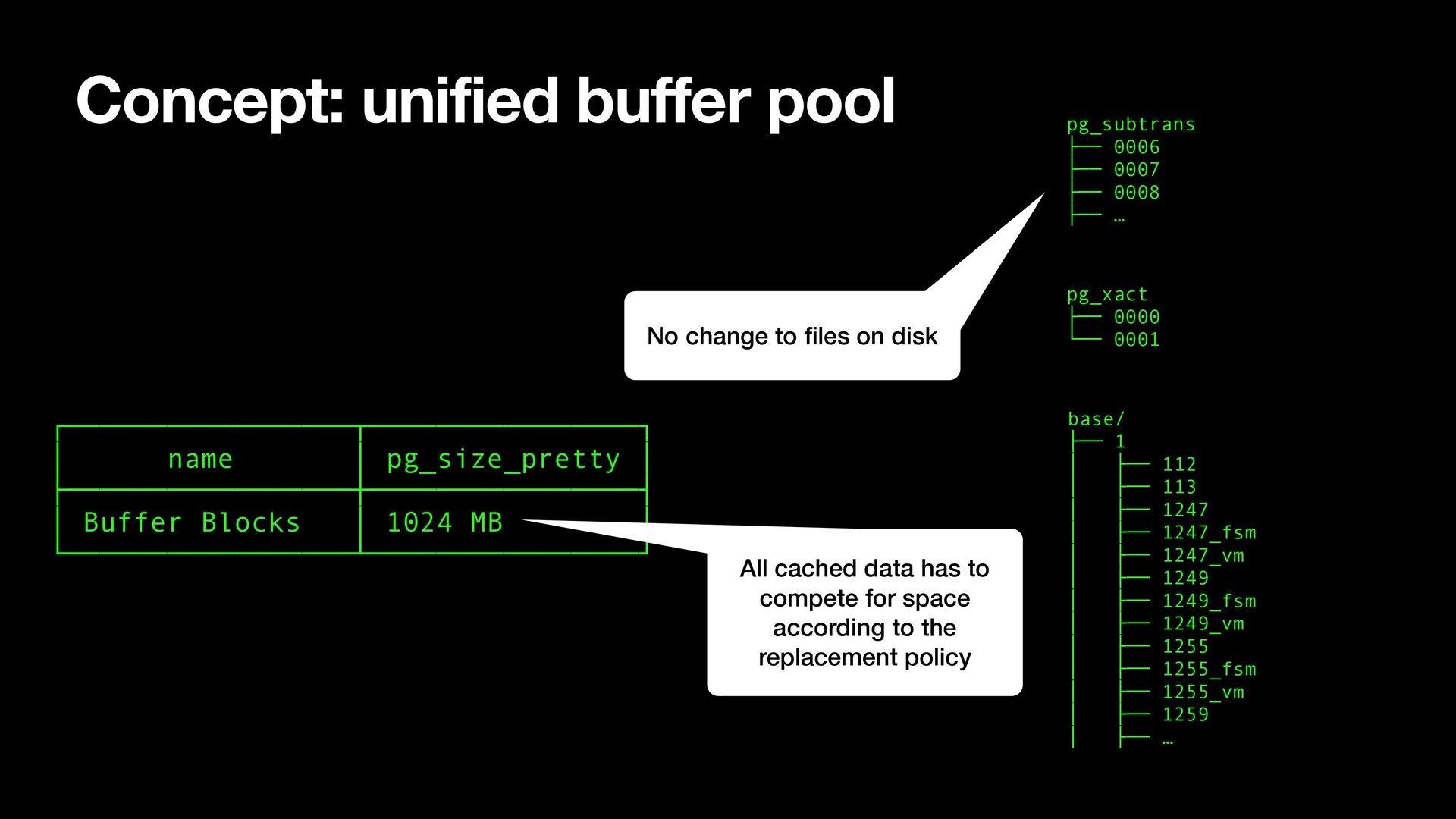
├── 1247 │ ├── 1247_fsm │ ├── 1247_vm │ ├── 1249 │ ├── 1249_fsm │ ├── 1249_vm │ ├── 1255 │ ├── 1255_fsm │ ├── 1255_vm │ ├── 1259 │ ├── … pg_xact ├── 0000 └── 0001 pg_subtrans ├── 0006 ├── 0007 ├── 0008 ├── … ┌─────────────────┬────────────────┐ │ name │ pg_size_pretty │ ├─────────────────┼────────────────┤ │ Buffer Blocks │ 1024 MB │ └─────────────────┴────────────────┘ Concept: unified buffer pool All cached data has to compete for space according to the replacement policy No change to fi les on disk
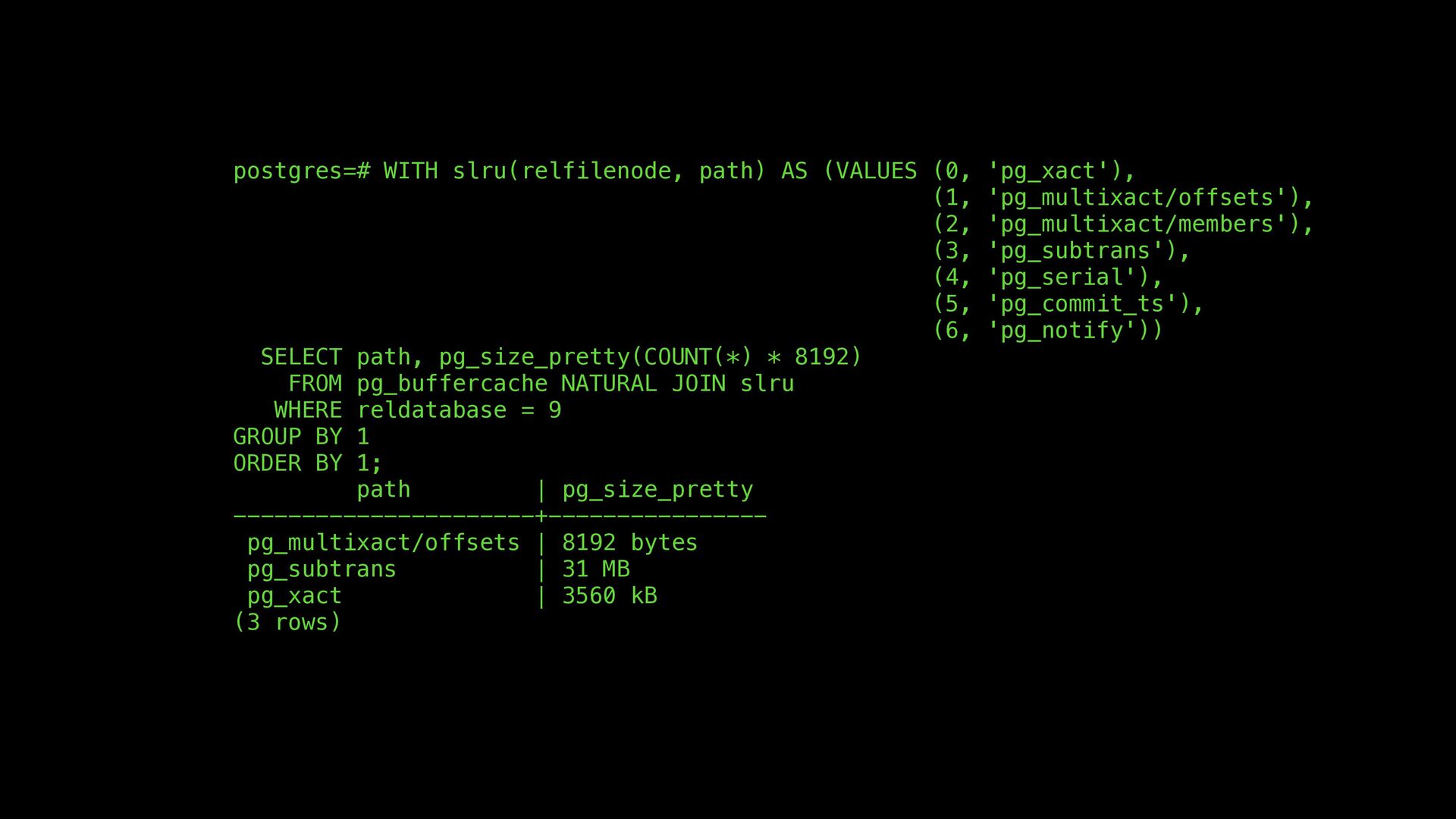
some speci fi c workloads produce a lot of SLRU cache misses and can be improved by resizing. So far we have resisted the urge to add 7 hard-to-tune settings for manual size control • The main bu ff er pool also has better scalability, asynchronous write back, checksums, …, and plans for more feature like encryption, smart block storage and many more potential innovations
Instead it had a minimalist log to record which transactions committed and aborted, with two bits per transaction • Most other systems use locking and undo-on-rollback to make uncommitted data invisible, or they used undo-based MVCC
main bu ff er pool using a special pseudo-relation called “pg_log”. Problems: • It kept growing and was kept forever on disk • When 32 bit transaction IDs ran out you had to dump and restore • In 7.2, it was kicked out into its own mini bu ff er pool to support changes: • Data was cut into 256K fi les so that old fi les could be unlinked • The xid was allowed to wrap around • Renamed to pg_clog (and later in 10, renamed again to pg_xact)
8.0 to implement SQL SAVEPOINT, and needed a spillable place to store the parent for each transaction ID • Multixacts arrived in 8.1 to implement shared locks, so that foreign key checks didn’t block other sessions. This required storage for sets of transactions that hold a FOR SHARE lock on a tuple, and uses two SLRUs • NOTIFY (since reimplementation) and SERIALIZABLE also added SLRUs • Special mention for commit timestamps, which are much like “pg_time” from university POSTGRES; similar to pg_log this was bu ff ered as a relation
made sense for small numbers of bu ff ers on small machines, but begins to burn too much CPU above hundreds of bu ff ers. • One big LWLock for lookup and access. • The bu ff er pool has partitioned hash table for fast scalable bu ff er lookup. • Bu ff ers have pins, various atomic fl ags and content locks. (Which of these do we need?) Lookup: SLRU vs buffer pool
bu ff er to replace. Replacement has to perform a linear scan to fi nd the least recently used bu ff er, while locking the whole SLRU. • The bu ff er pool uses a generalisation of the CLOCK algorithm from traditional Unix (originally Multics, 1969) bu ff er caches. It tries to account for recency and frequency of use. • It is not the state of the art, and does degrade to scanning linearly for replaceable bu ff ers in the worst case, but it is likely to be improved over time. (CAR?) Replacement: SLRU vs buffer pool
evicted to make room to read in a new bu ff er, it must be done synchronously. • Before 13, we used to fsync synchronously too when that happened. Handing that part o ff was a stepping stone for this work (collaboration with Shawn Debnath). • The main bu ff er pool has a “background writer” process that tries to make sure that clean bu ff ers are always available. • sync_ fi le_range() is used to start write back before fsync(), for extra I/O concurrency • The background writer may not always succeed in that goal, but improvements are possible. Write-back: SLRU vs buffer pool
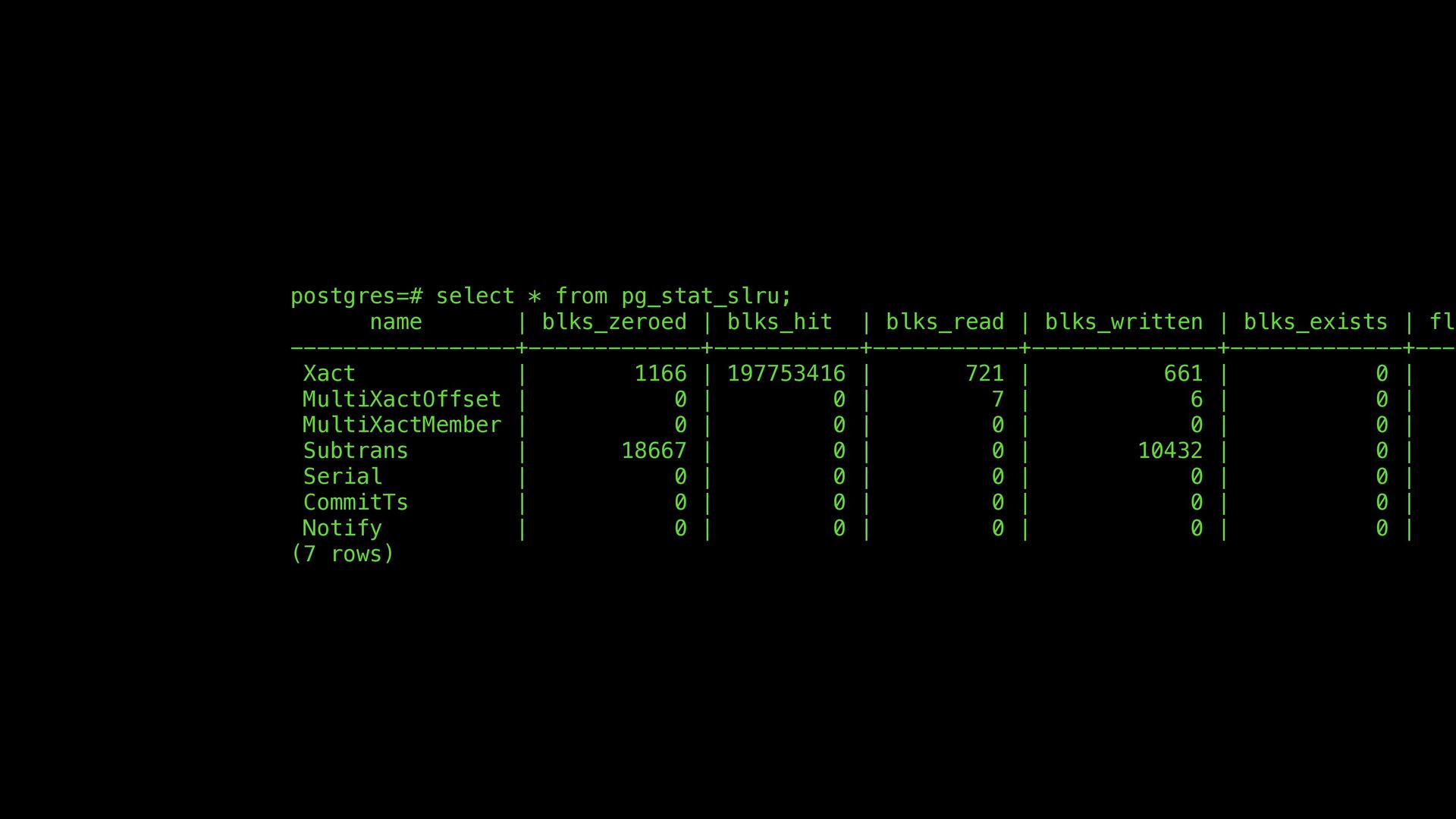
are currently no checksums to detect that • The main bu ff er pool supports optional per-page checksums that are computed at write time and veri fi ed at read time Corruption detection: SLRU vs buffer pool Note: current prototype is not attempting to implement this part for SLRU data (more on that soon). One step at a time…
to AWS Aurora Postgres”, see nearby talk) are working on distributed WAL- aware block storage systems that integrate at the bu ff er pool level It must eventually help if all relevant data for a cluster is managed through one bu ff er pool with standardised LSN placement…? • The AIO proposal for PostgreSQL adds optional direct IO, asynchronous IO, IO merging, scatter/gather, and is integrated with the bu ff er pool. • In progress work to add TDE (transparent data encryption) probably integrates with the bu ff er pool a bit like checksums. • A better replacement policy? Future buffer pool innovations This slide is pure conjecture!
represent SLRU data, and then relation ID selects the particular SLRU • Other schemes are possible! People have suggested stealing fork number bits or special table space IDs. • spc = DEFAULTTABLESPC_OID db = SLRU_DB_ID rel = SLRU_CLOG_REL_ID fork = MAIN_FORKNUM block = ? Buffer tags Hash table keys for fi nding bu ff ers db rel fork block spc
unchanged, that is, without any header: • No checksums: for those to be powerloss crash safe, we’d need to implement full page writes and register all modi fi ed pages in the WAL. Out of scope. • No LSN: fi le format change vs pg_upgrade. Out of scope. • External LSNs: we still need a place to track the last LSN to modify each page, so we need a new array to hold them (may be able to chisel some space out of padding in Bu ff erDescriptor) • These could all be fi xed, removing the need to handle raw pages Rough edge: raw pages
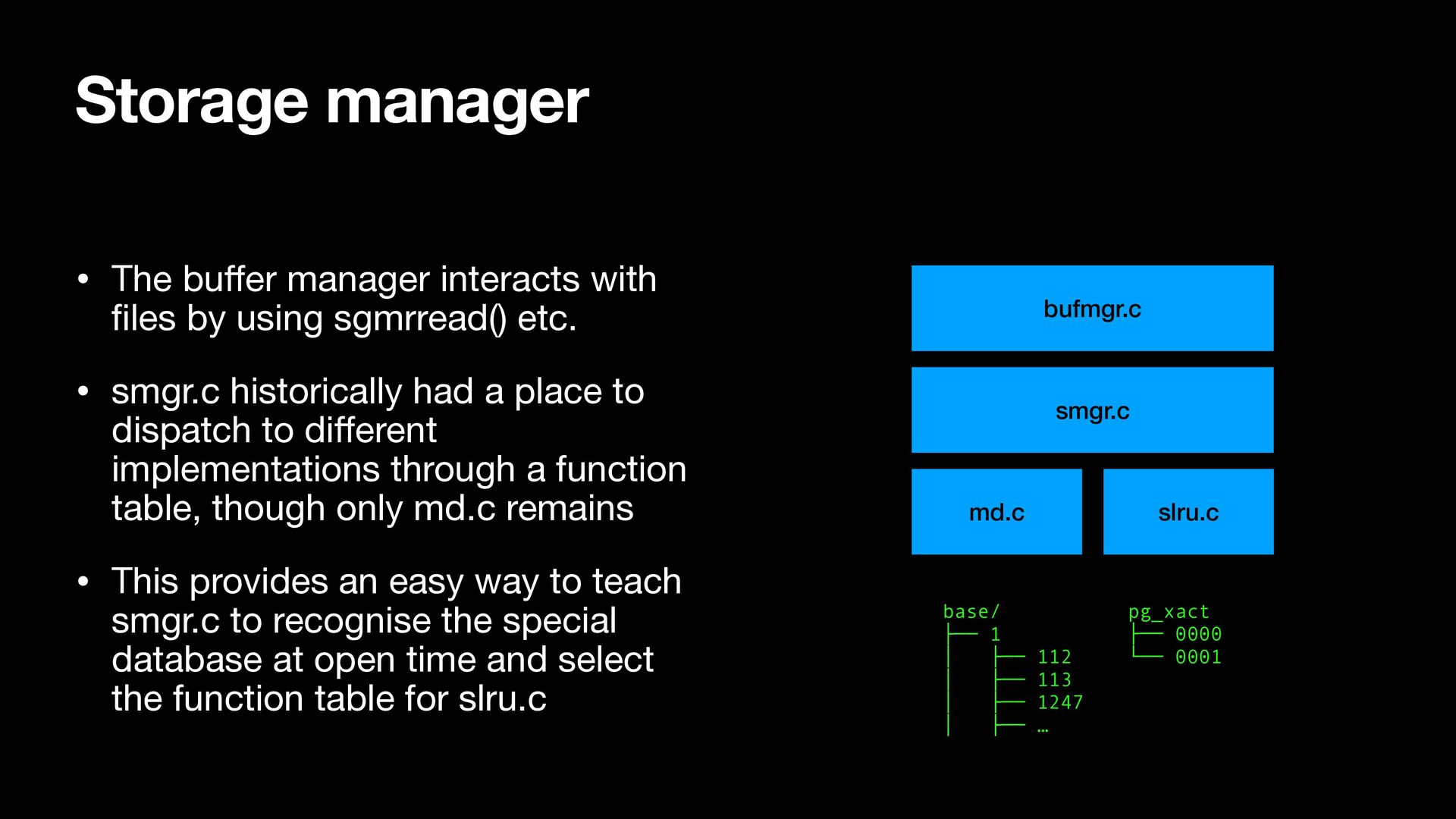
by using sgmrread() etc. • smgr.c historically had a place to dispatch to di ff erent implementations through a function table, though only md.c remains • This provides an easy way to teach smgr.c to recognise the special database at open time and select the function table for slru.c Storage manager bufmgr.c smgr.c md.c slru.c pg_xact ├── 0000 └── 0001 base/ ├── 1 │ ├── 112 │ ├── 113 │ ├── 1247 │ ├── …
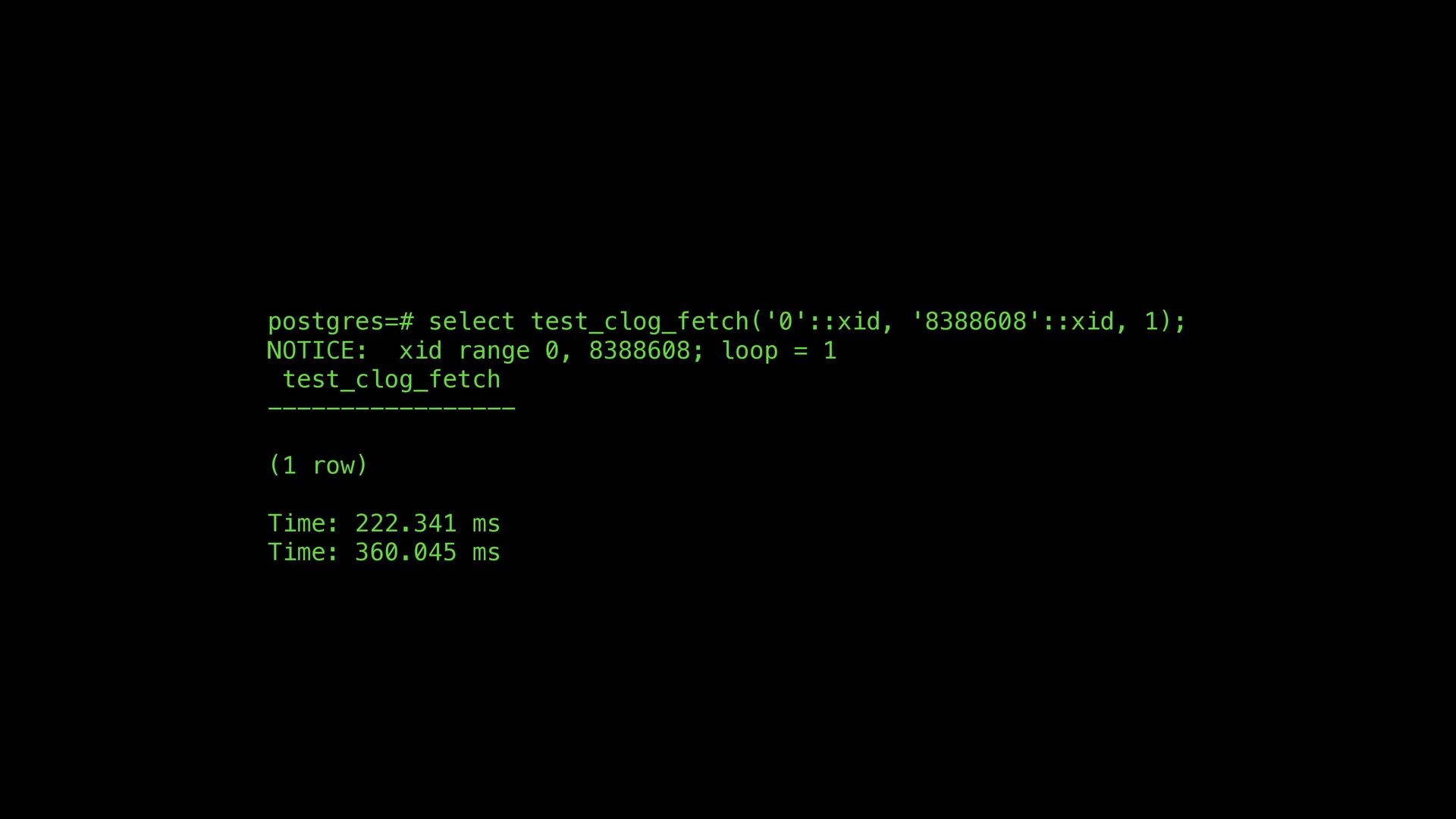
perform a linear search for a page number and then access the data, which is pretty fast if the cache is small and the it’s a cache hit • A naive implementation using the bu ff er pool would build a bu ff er tag, compute a hash, acquire/release an LWLock for a partition of the lookup table to fi nd a bu ff er, pin the bu ff er, and then share lock the page while reading the bits it needs. Ouch. • Current theory: we can avoid the bu ff er mapping table in common cases with a small cache of recent bu ff ers and Bu ff erReadRecent() • Current theory: in many interesting cases we only need a pin to read Lookup, pinning and locking overheads
for blocks to discard, when truncating old data • In the main bu ff er cache, we must loop over the block range probing the bu ff er mapping table looking for blocks to discard — a bit more work! • Hopefully this’ll be OK because it all happens in background jobs: pg_xact and pg_multixact are trimmed during vacuuming, and pg_subtrans during checkpoints Discarding/truncating
updates works by with extra state per CLOG bu ff er. If the CLOG page can’t be locked immediately, the update joins a queue and sleeps, and then updates are consolidated. • But… going o ff CPU when you’re trying to commit is bad? • Idea: Abandon the whole schmozzle. Invent a lock-free update protocol. We only need a pinned page, and we can use pg_atomic_fetch_or_u8() to set the bits without clobbering current writes. Use CAS to update the page LSN while making sure it doesn’t go backwards. • Is LSN contention and false sharing tra ff i c worse than the sleeping? Rough edge: grouped CLOG updates
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}