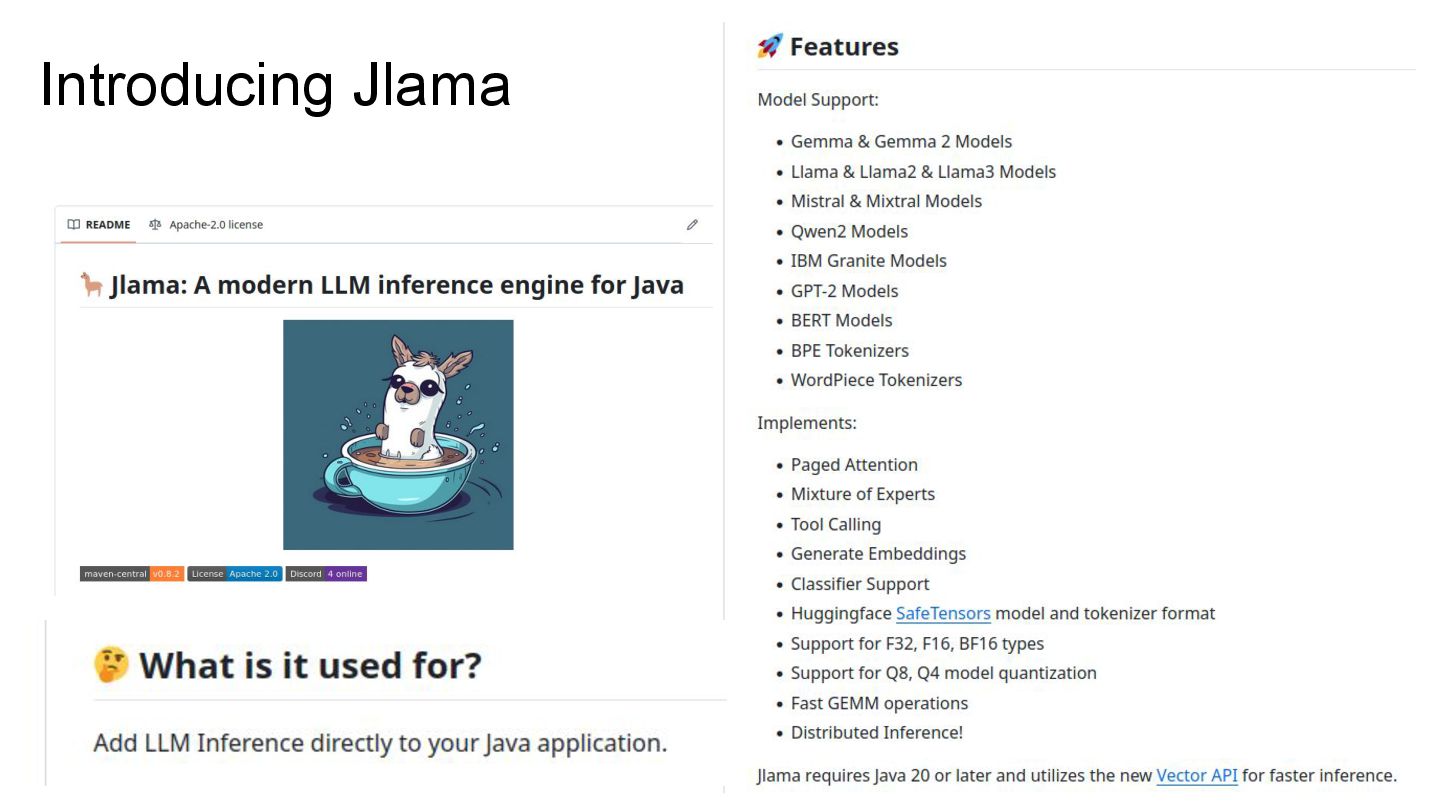
LLM inference directly embedded into your Java application ❖ Based on the Java Vector API ❖ Integrated with Quarkus and LangChain4j ❖ Jlama includes out-of-the-box ➢ Support for many different LLM families ➢ A command line tool that makes it easy to use ➢ A tool for models quantization ➢ A pure Java tokenizer ➢ Distributed inference
install, configure and interact with any external server. Security → Embedding the model inference in the same JVM instance of the application using it, eliminates the need of interacting with the LLM only through REST calls, thus preventing the leak of private data. Legacy support: Legacy users still running monolithic applications on EAP can include LLM-based capabilities in those applications without changing their architecture or platform. Monitoring and Observability: Gathering statistics on the reliability and speed of the LLM response can be done using the same tools already provided by EAP or Quarkus. Developer Experience → Debuggability will be simplified, allowing Java developers to also navigate and debug the Jlama code if necessary. Distribution → Possibility to include the model itself into the same fat jar of the application using it (even though this could probably be advisable only in very specific circumstances). Edge friendliness → Deploying a self-contained LLM-capable Java application will also make it a better fit than a client/server architecture for edge environments. Embedding of auxiliary LLMs → Apps using different LLMs, for instance a smaller one to to validate the responses of the main bigger one, can use a hybrid approach, embedding the auxiliary LLMs. Similar lifecycle between model and app →Since prompts are very dependent on the model, when it gets updated, even through fine-tuning, the prompt may need to be replaced and the app updated accordingly.
seriously … why not Python? What we do is integrating existing models Do you really want to do • Transactions • Security • Scalability • Observability • … you name it in Python??? into enterprise- grade systems and applications
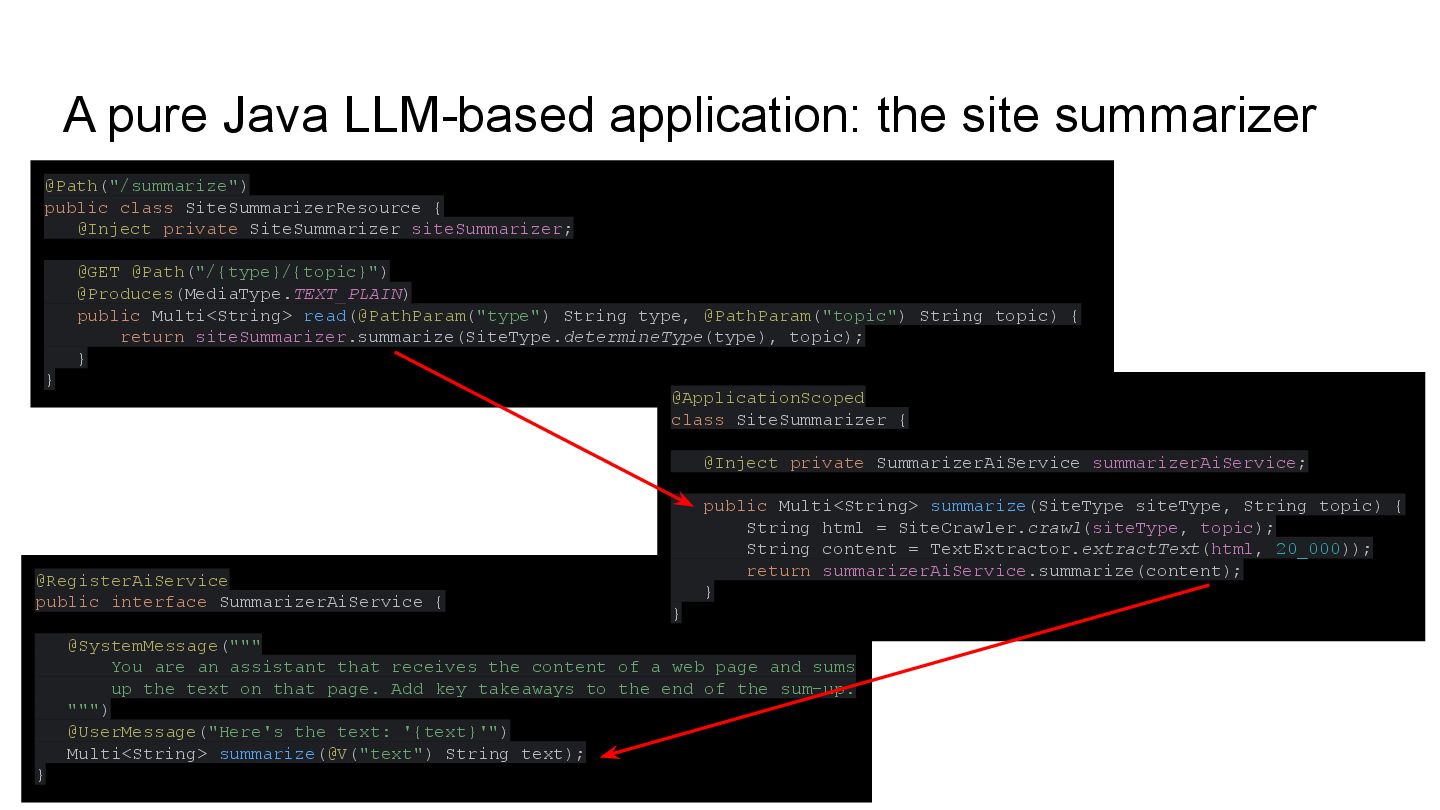
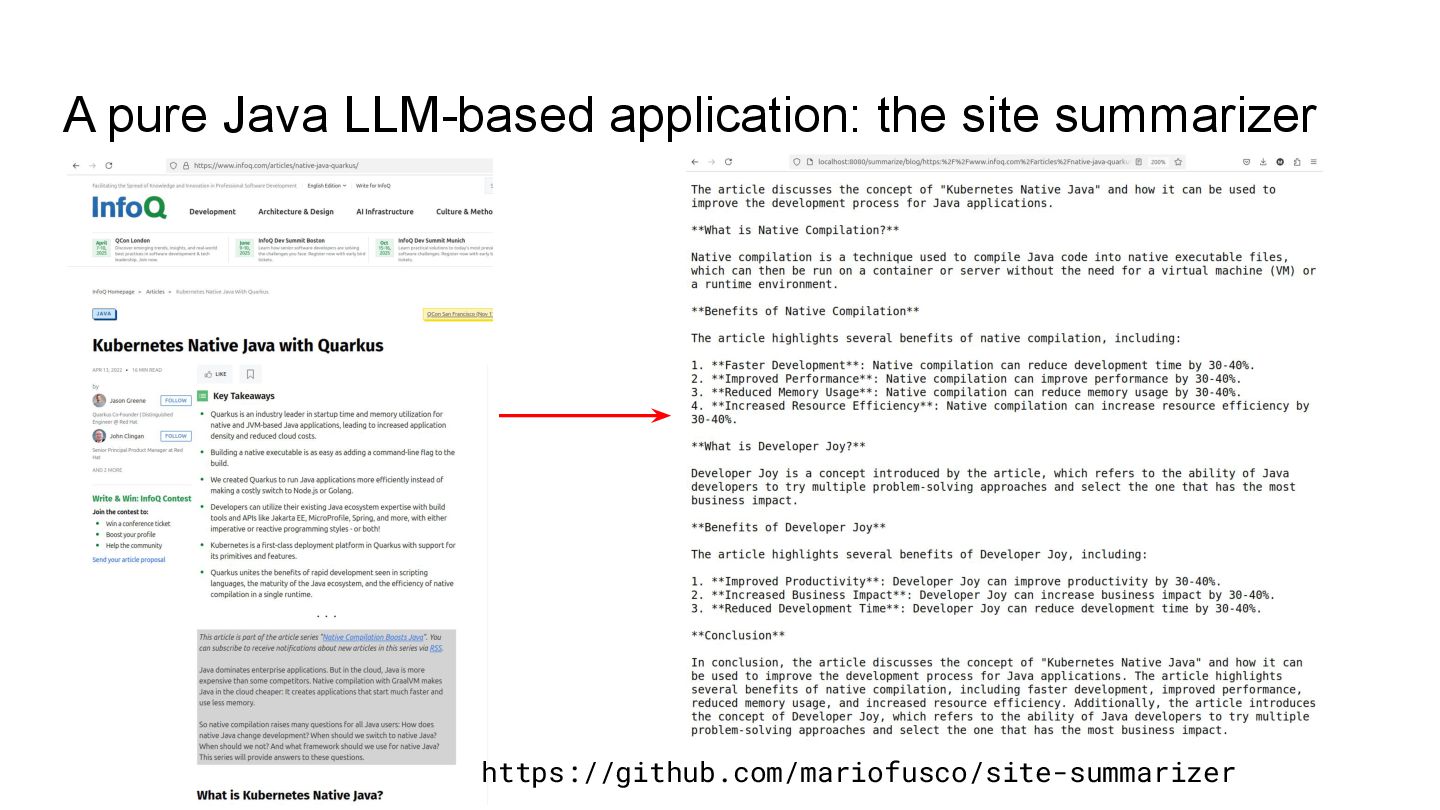
class SiteSummarizerResource { @Inject private SiteSummarizer siteSummarizer; @GET @Path("/{type}/{topic}") @Produces(MediaType.TEXT_PLAIN) public Multi<String> read(@PathParam("type") String type, @PathParam("topic") String topic) { return siteSummarizer.summarize(SiteType.determineType(type), topic); } } @RegisterAiService public interface SummarizerAiService { @SystemMessage(""" You are an assistant that receives the content of a web page and sums up the text on that page. Add key takeaways to the end of the sum-up. """) @UserMessage("Here's the text: '{text}'") Multi<String> summarize(@V("text") String text); } @ApplicationScoped class SiteSummarizer { @Inject private SummarizerAiService summarizerAiService; public Multi<String> summarize(SiteType siteType, String topic) { String html = SiteCrawler.crawl(siteType, topic); String content = TextExtractor.extractText(html, 20_000)); return summarizerAiService.summarize(content); } }
will be great! But when… 202X? • TornadoVM ◦ Requires bespoke wrapper around jdk to compile/run applications (with all driver dependencies) • What else is multi-platform, portable runtime for the GPU?
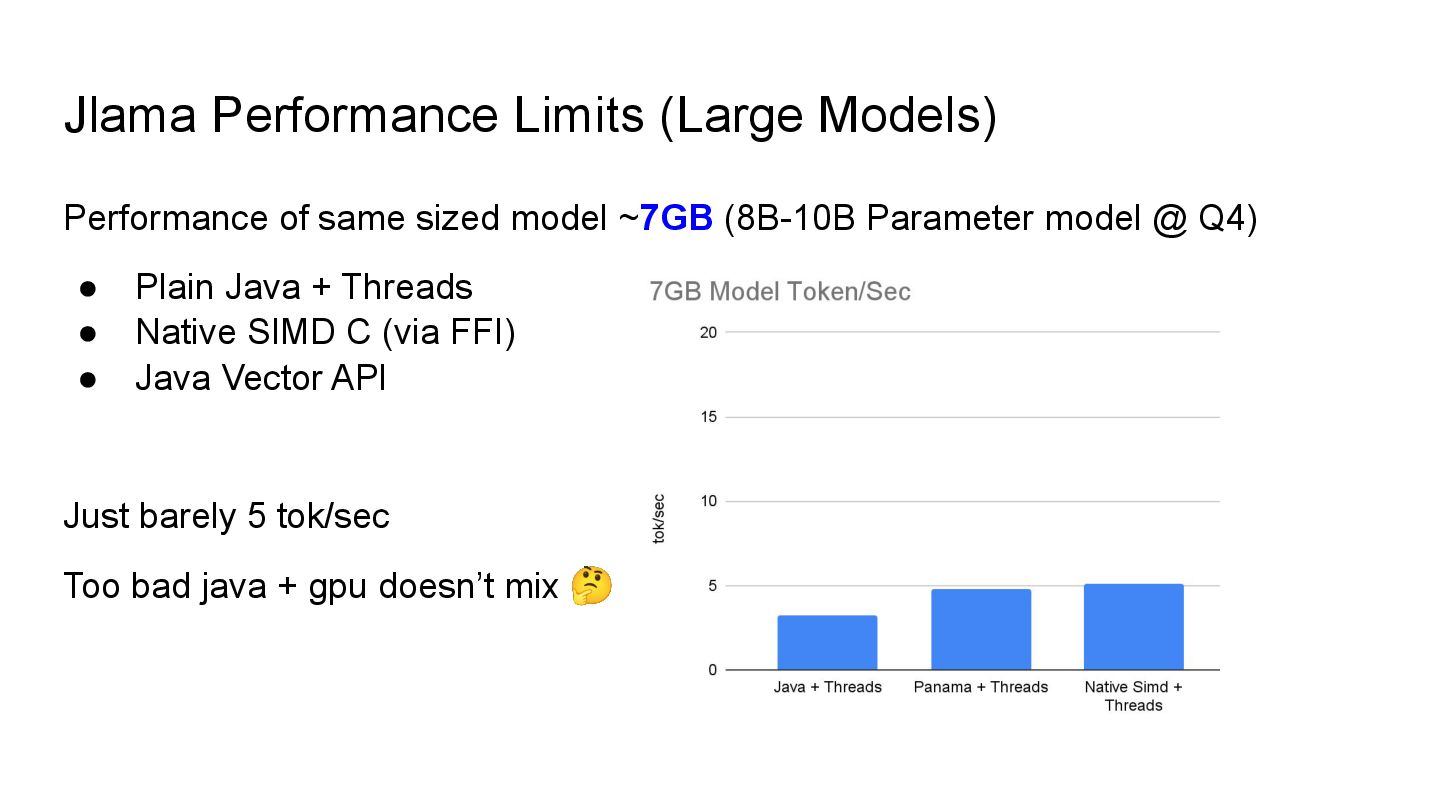
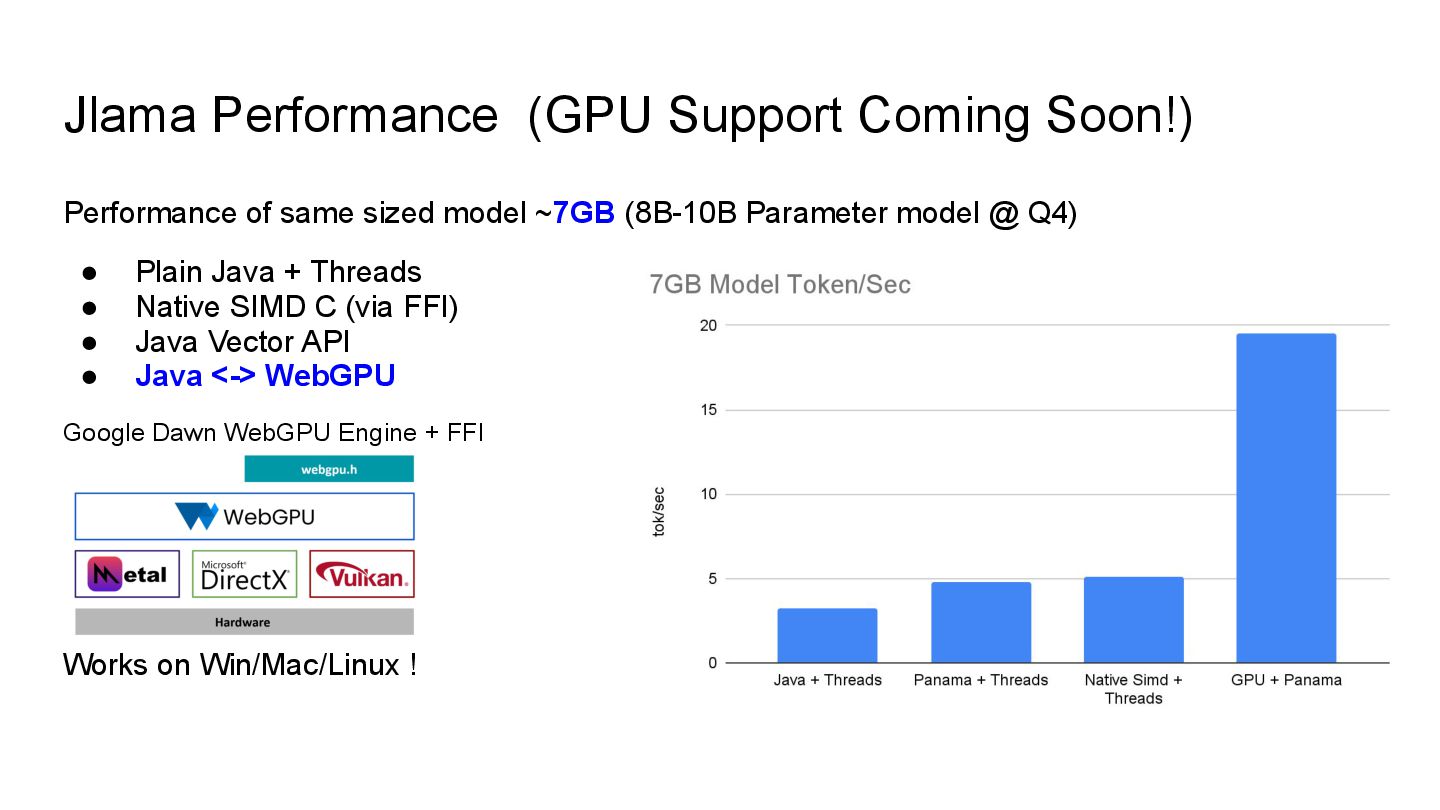
model ~7GB (8B-10B Parameter model @ Q4) • Plain Java + Threads • Native SIMD C (via FFI) • Java Vector API • Java <-> WebGPU Google Dawn WebGPU Engine + FFI Works on Win/Mac/Linux !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}