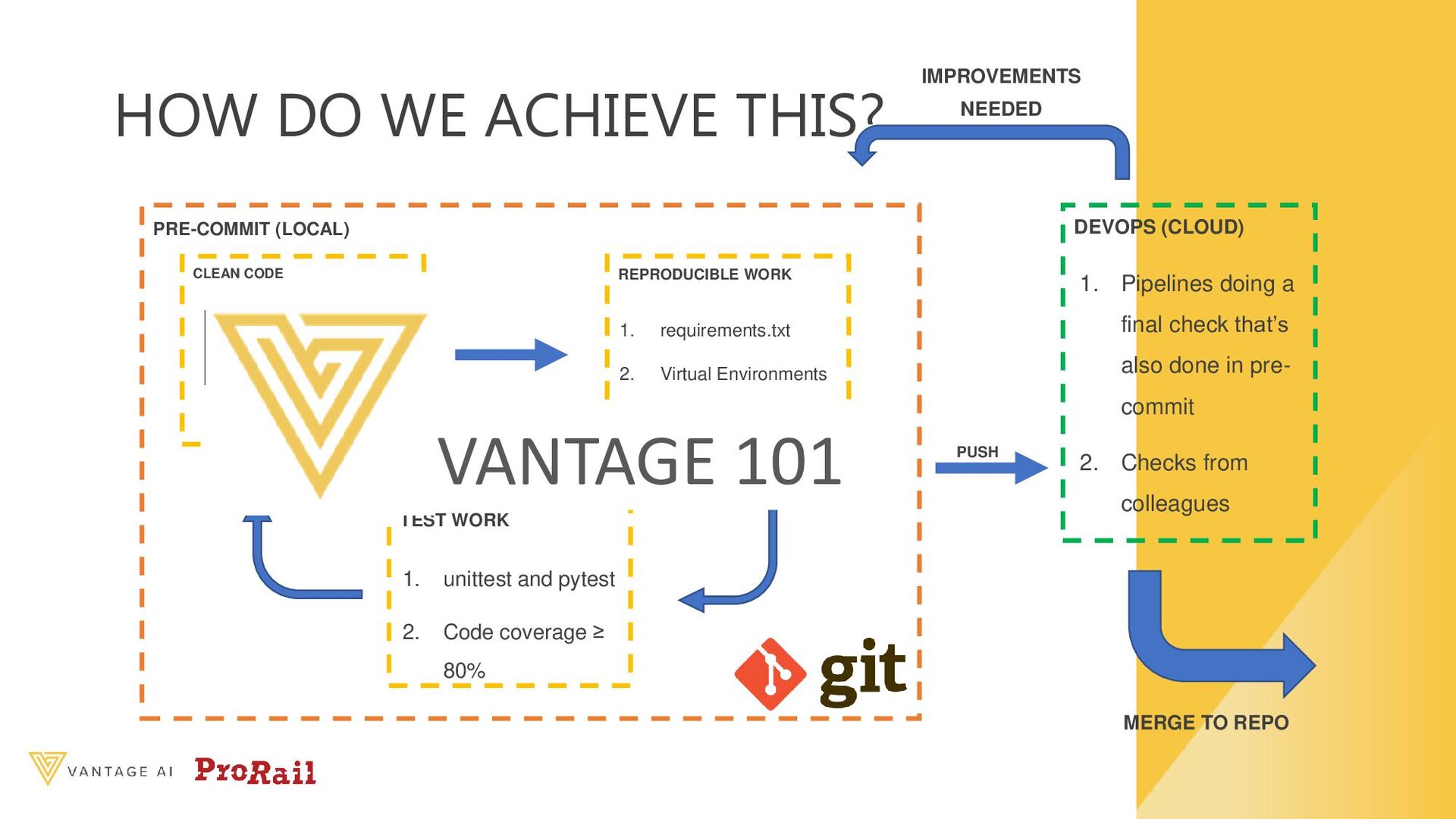
clean code --> Formatting, linting 2. Thou shalt make thy work reproducible --> Venv, dependencies in order 3. Thou shalt test your code --> unittesting, code coverage 4. Thou shalt use Git to automate checks of the commandments --> pre-commit and pipelines
{kind=link}
{kind=link}
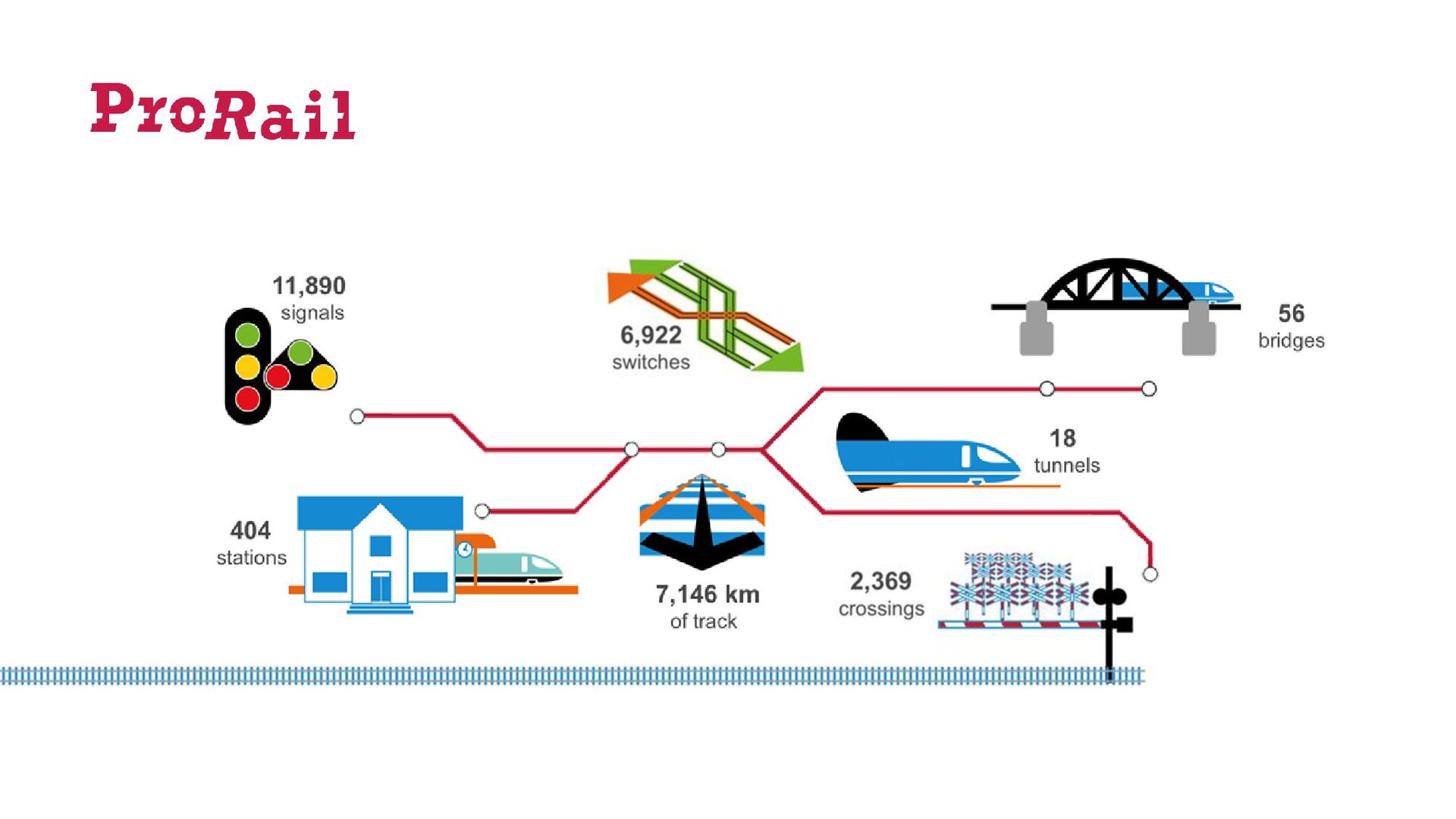{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
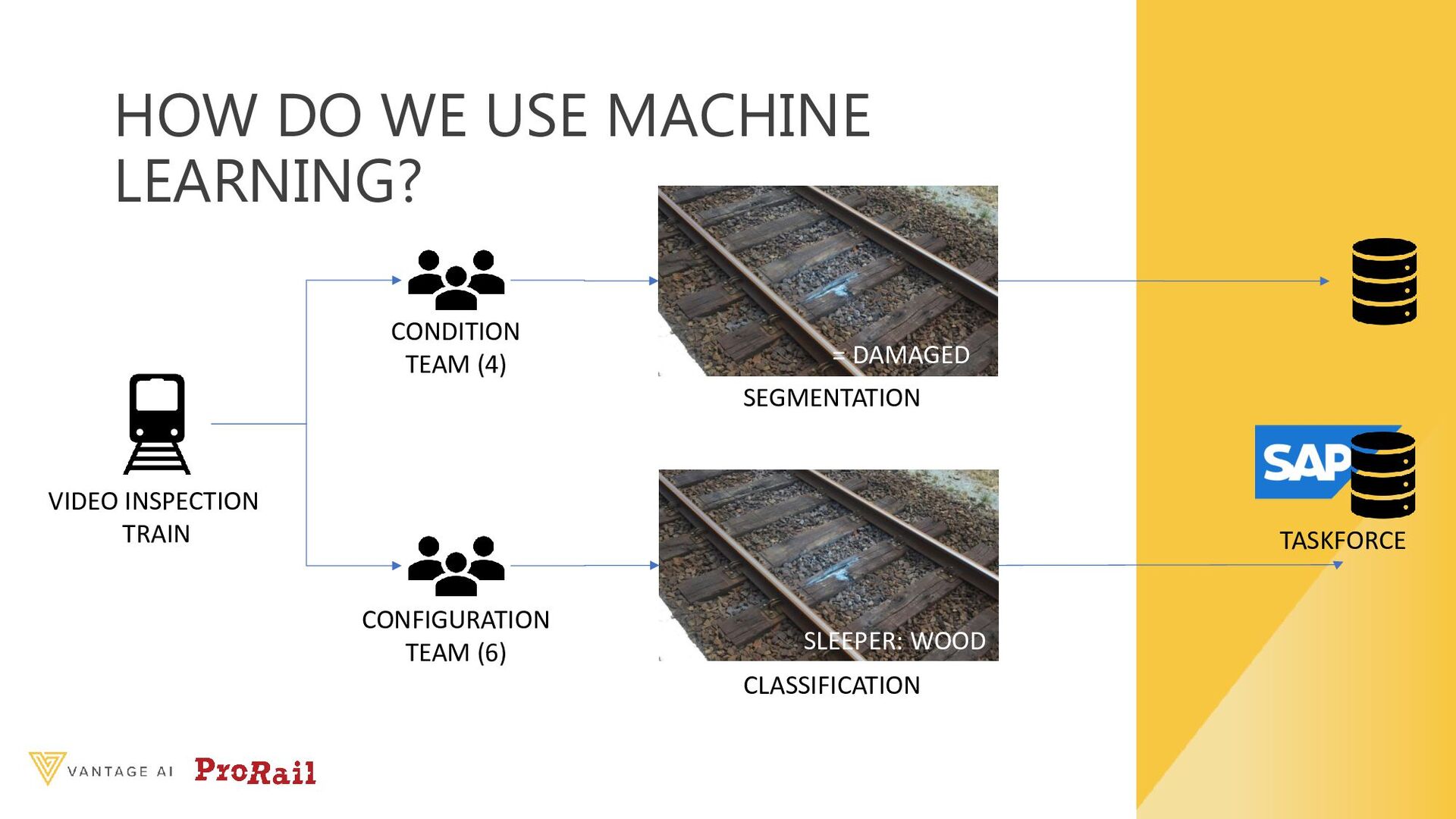{kind=link}
{kind=link}
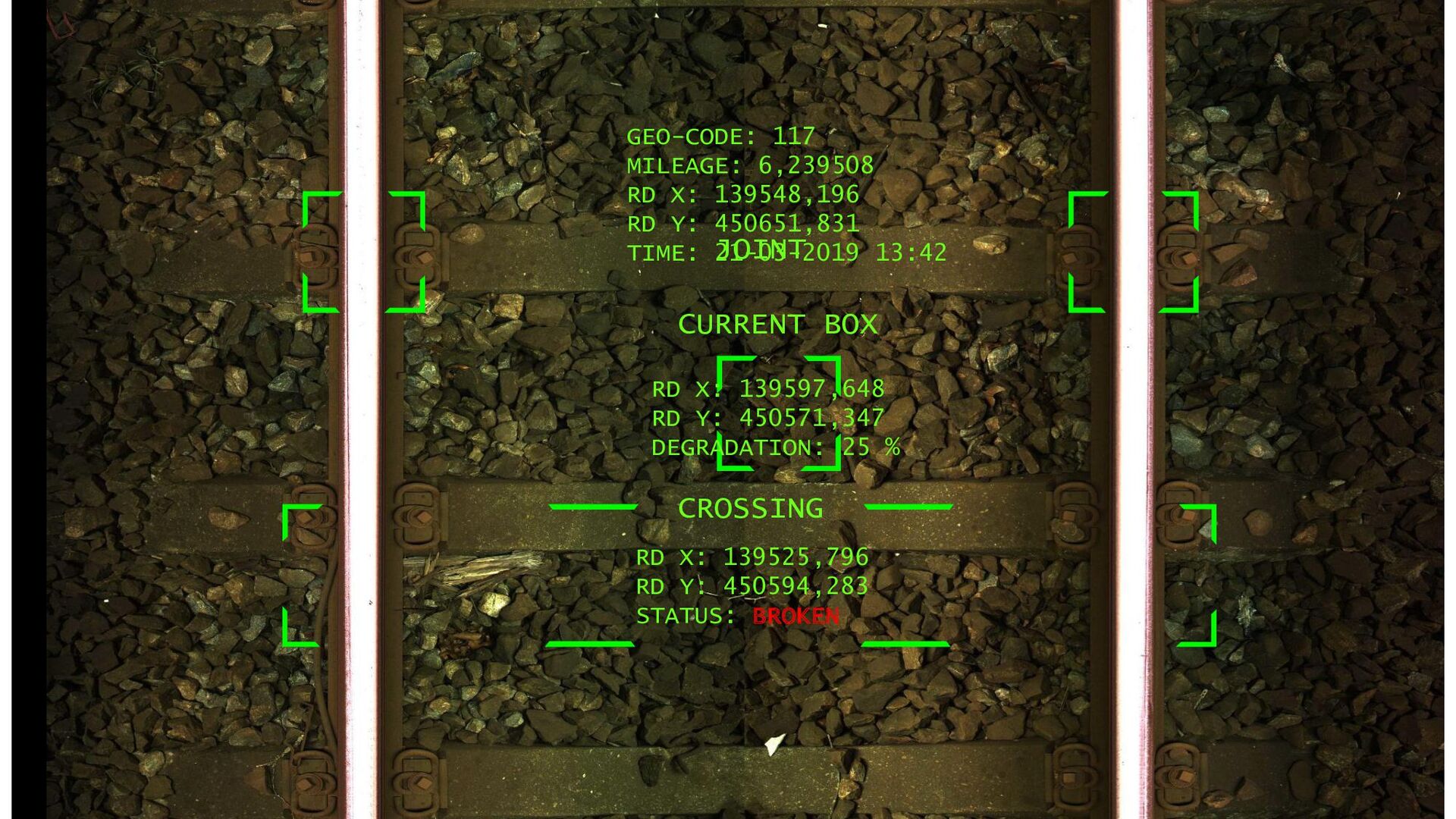{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}