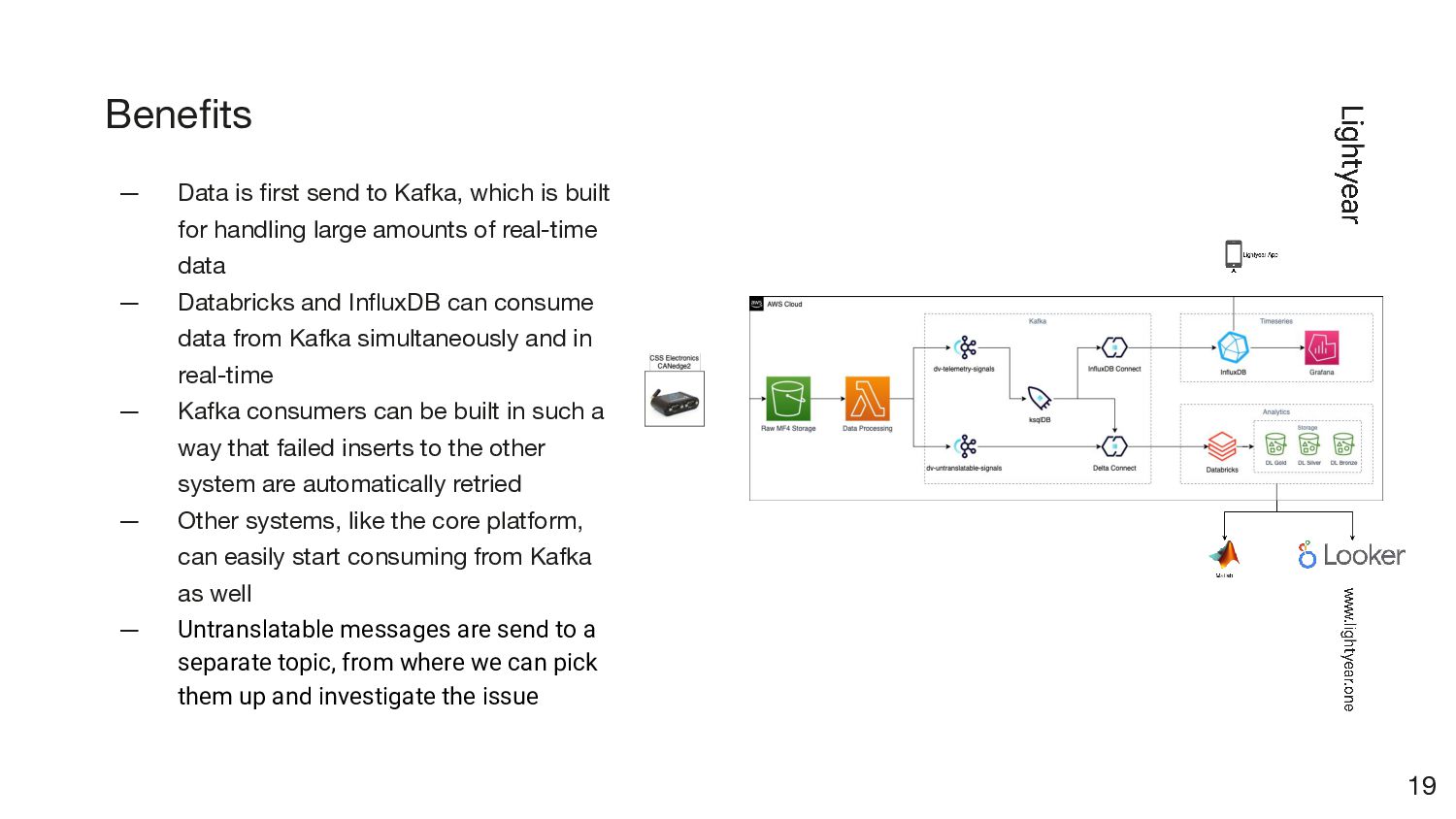
for handling large amounts of real-time data — Databricks and InfluxDB can consume data from Kafka simultaneously and in real-time — Kafka consumers can be built in such a way that failed inserts to the other system are automatically retried — Other systems, like the core platform, can easily start consuming from Kafka as well — Untranslatable messages are send to a separate topic, from where we can pick them up and investigate the issue Benefits 19
{kind=link}
{kind=link}
{kind=link}
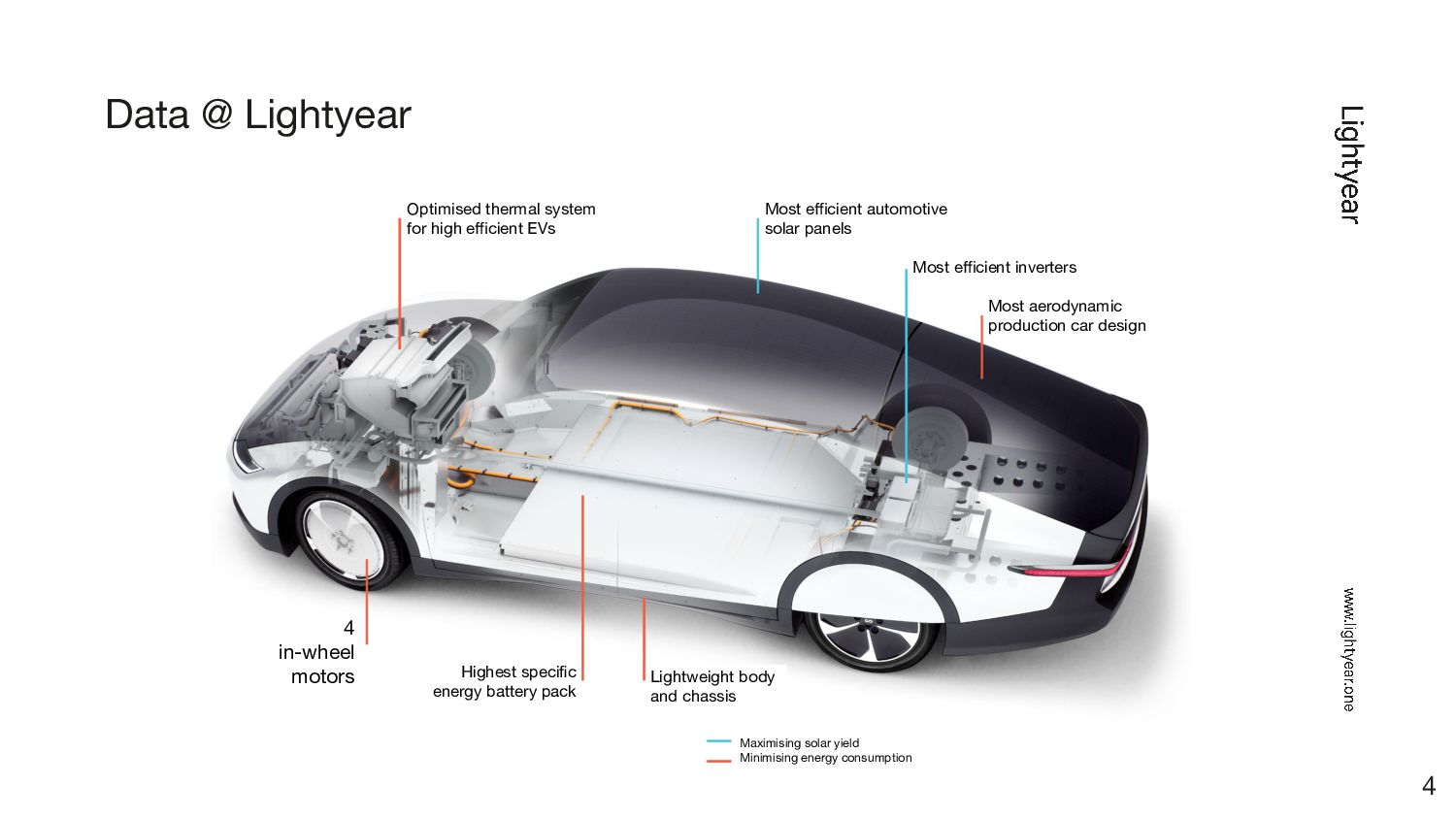{kind=link}
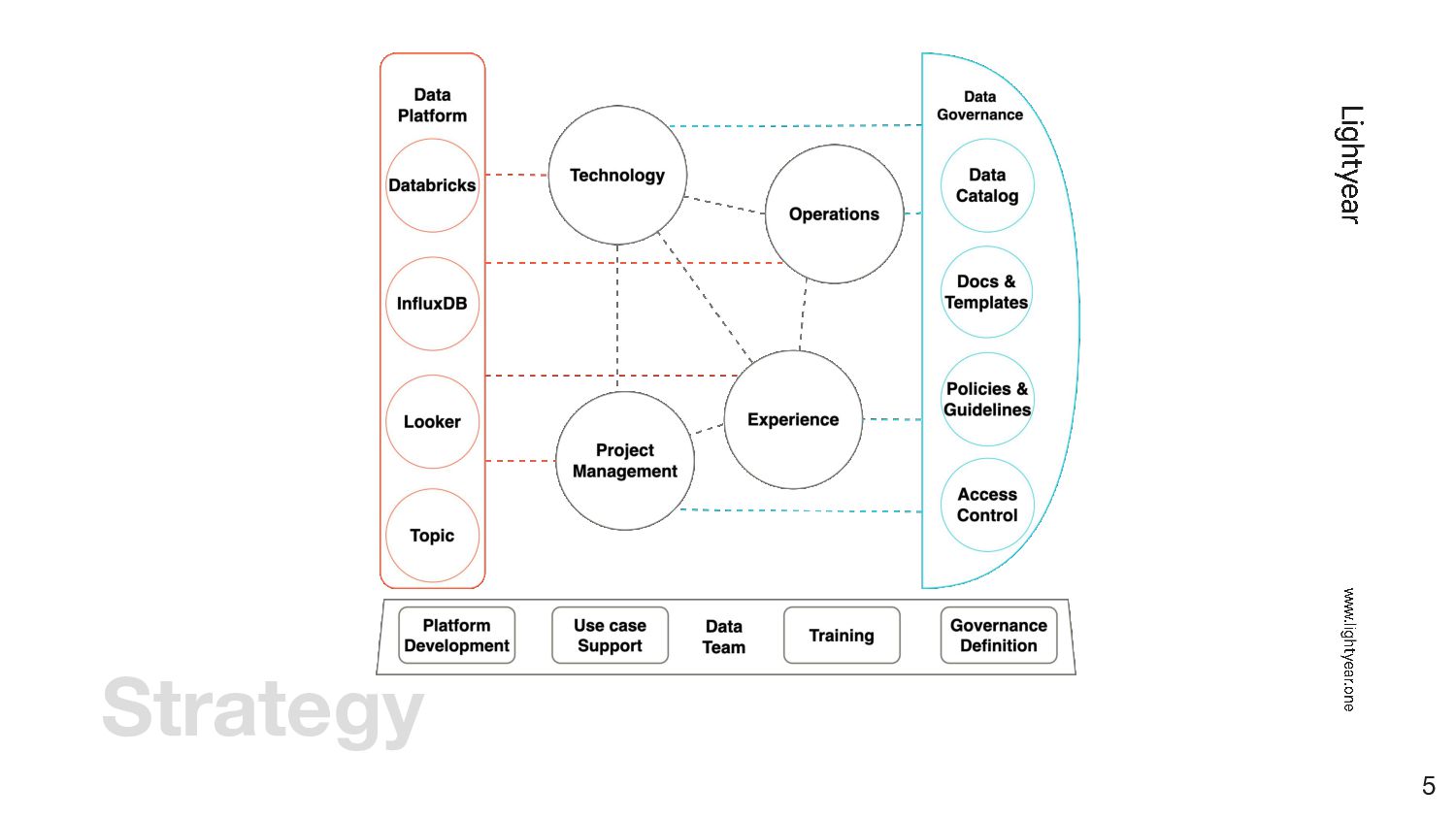{kind=link}
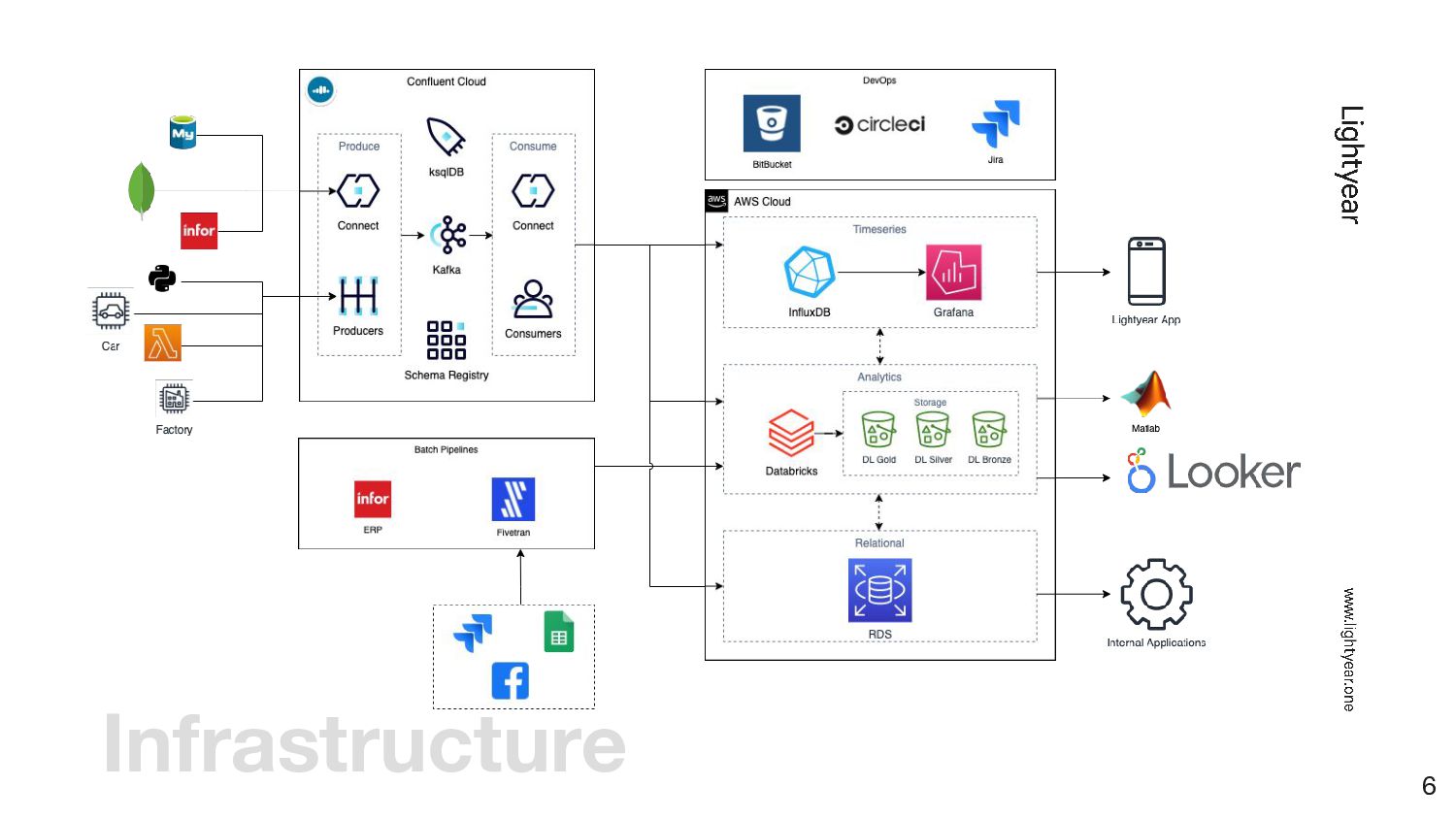{kind=link}
{kind=link}
{kind=link}
{kind=link}
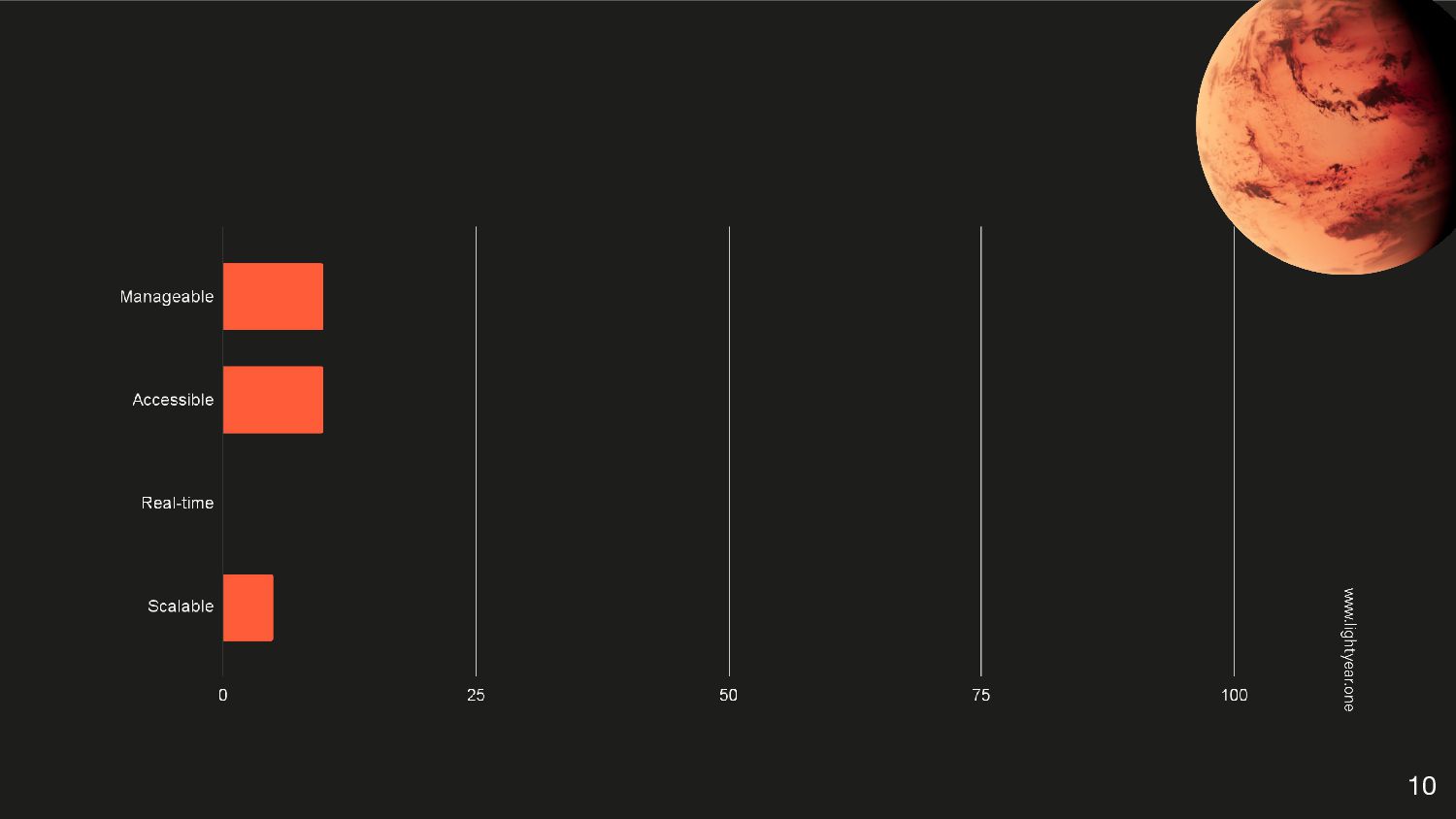{kind=link}
{kind=link}
{kind=link}
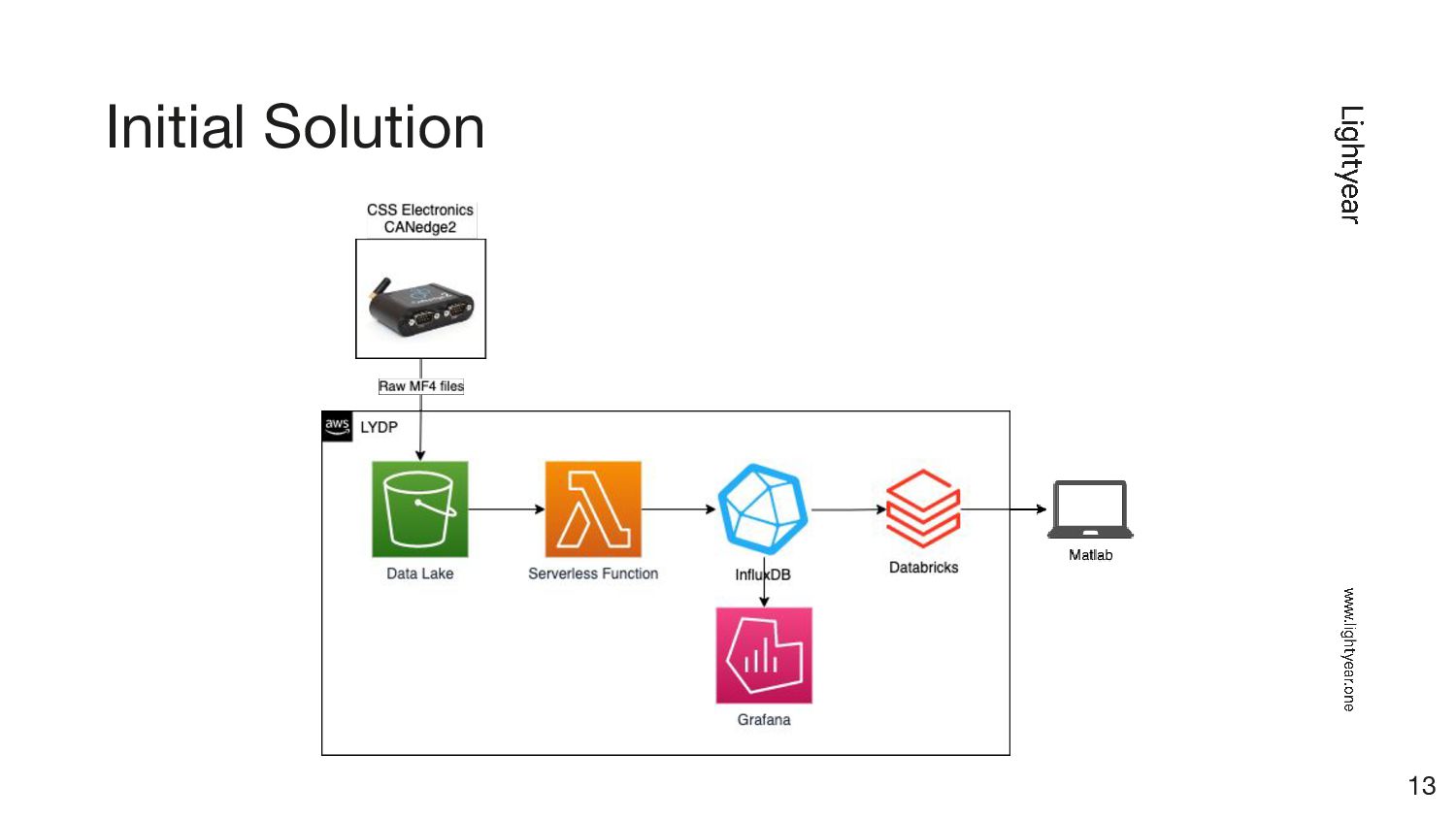{kind=link}
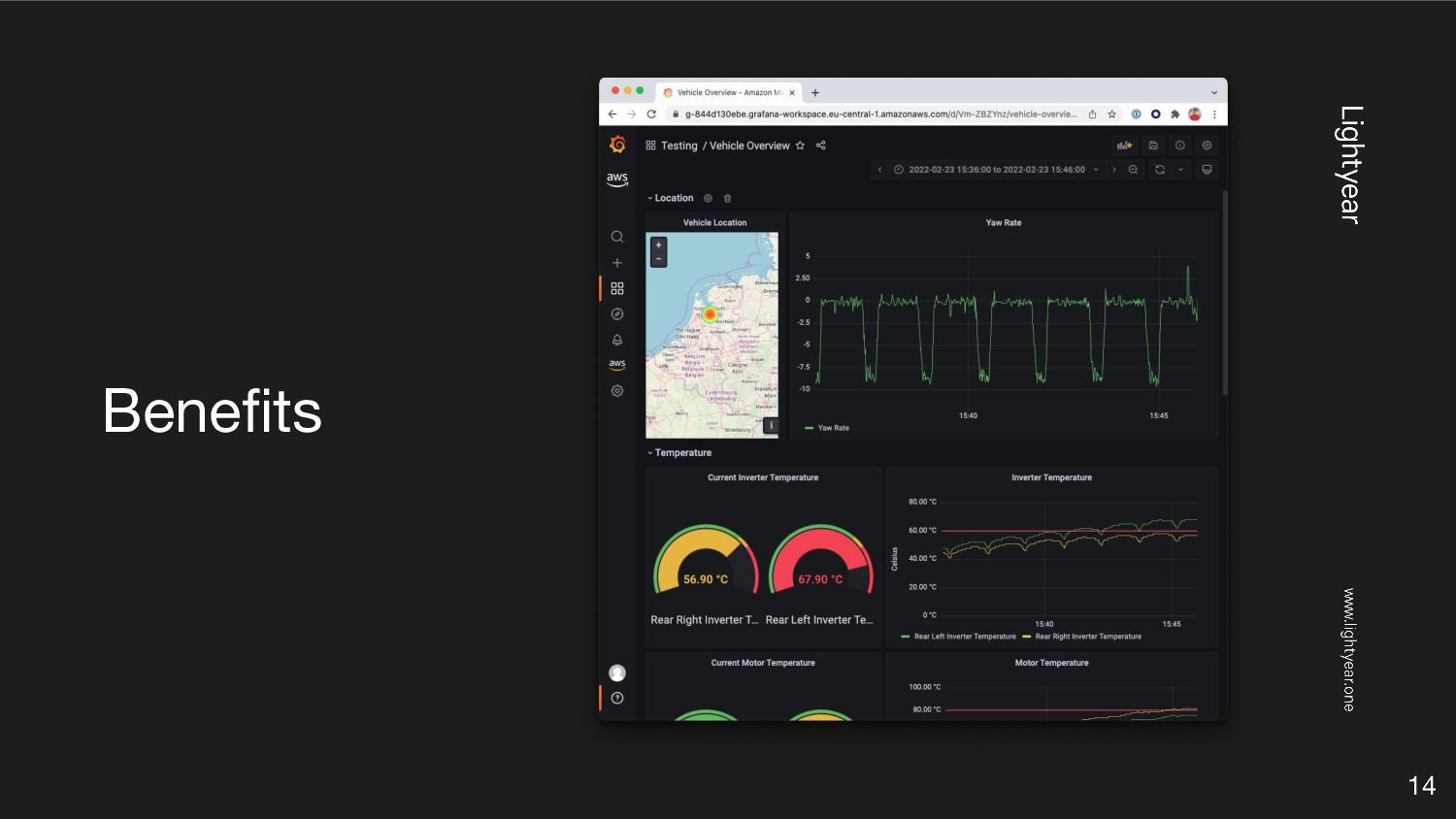{kind=link}
{kind=link}
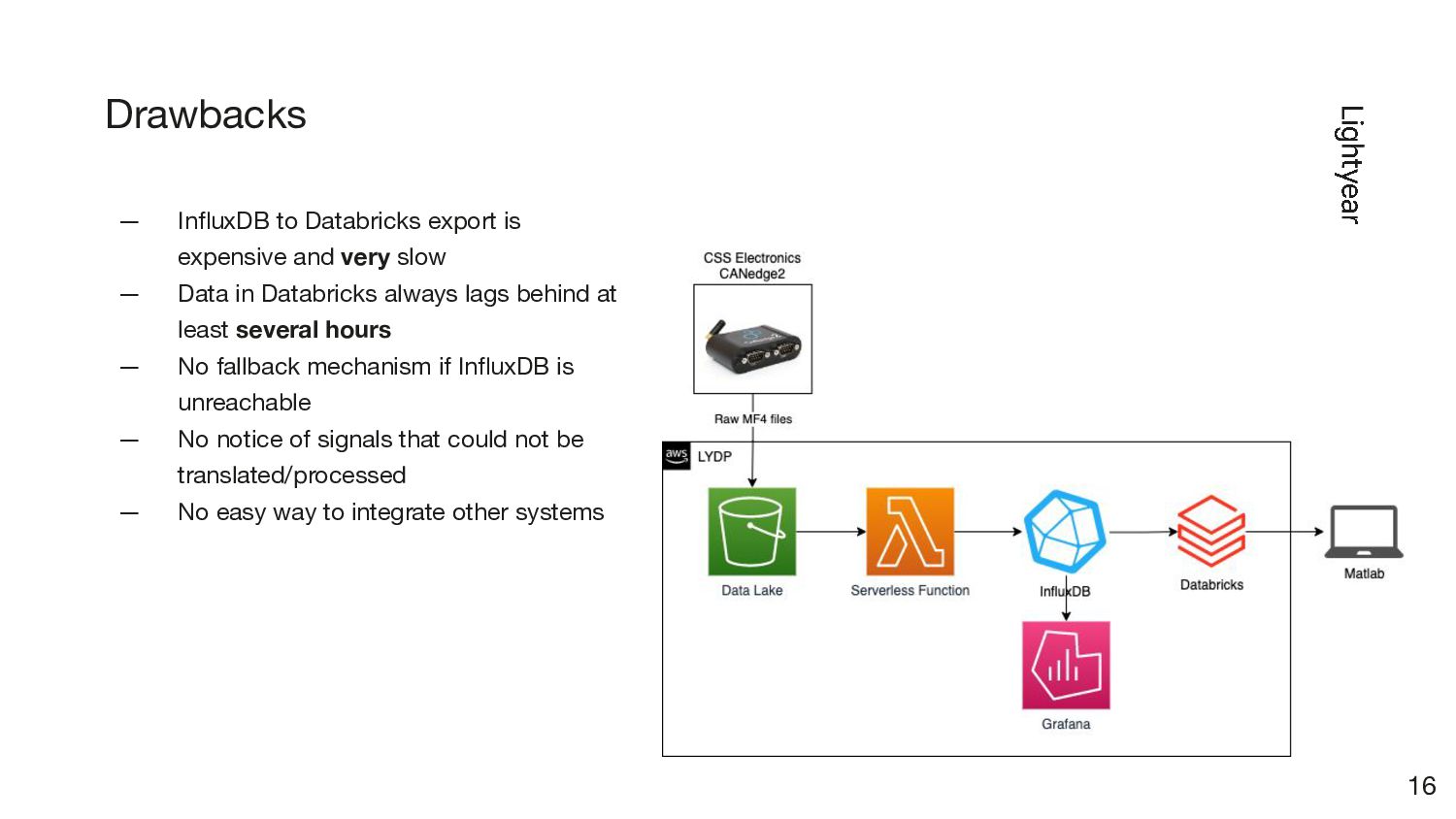{kind=link}
{kind=link}
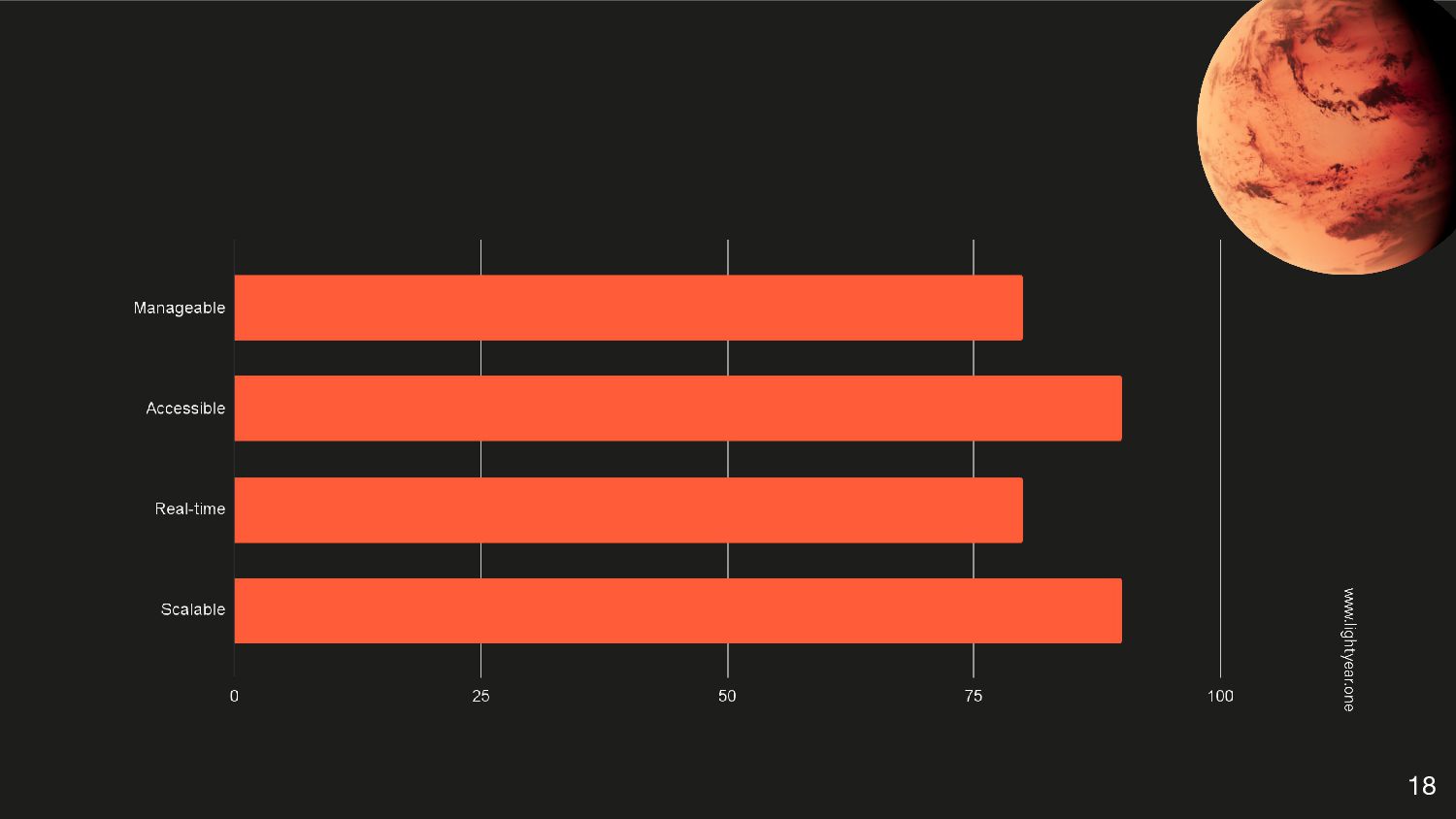{kind=link}
{kind=link}
{kind=link}
{kind=link}