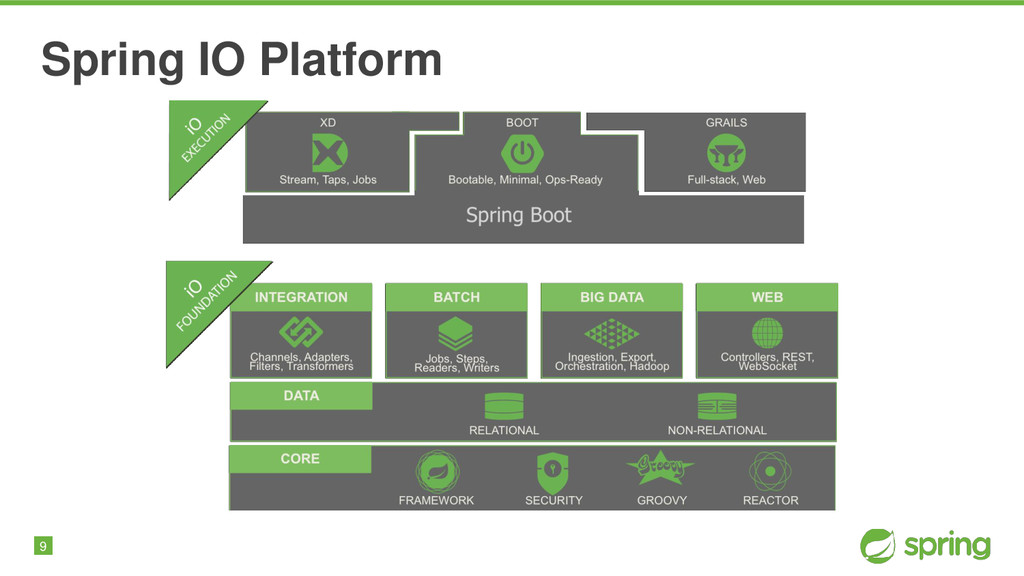
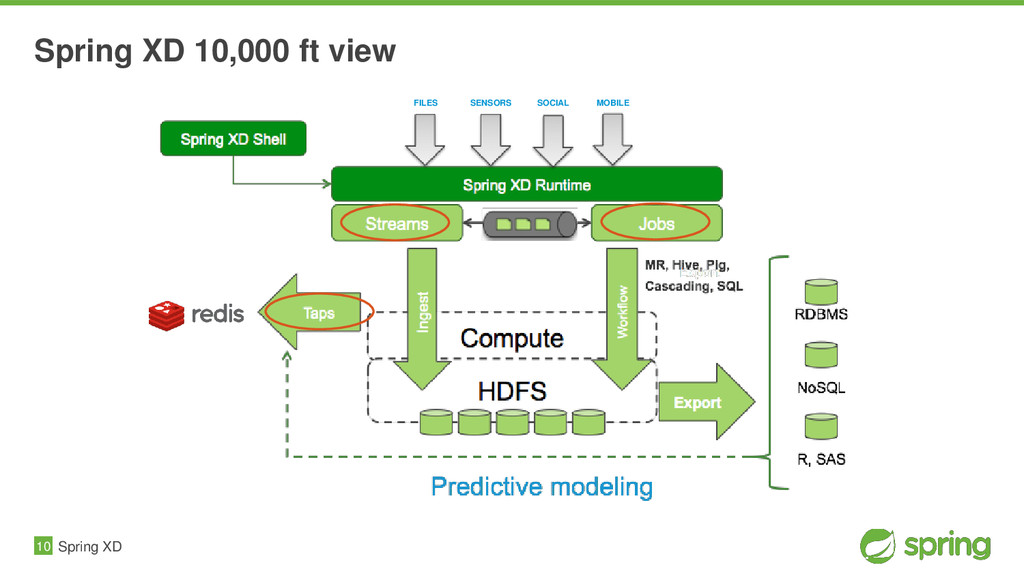
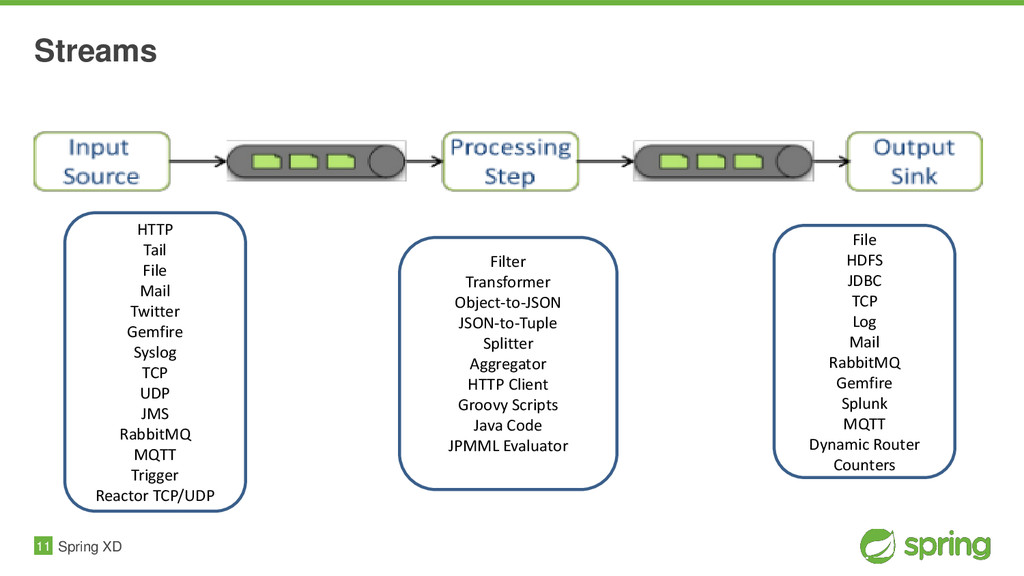
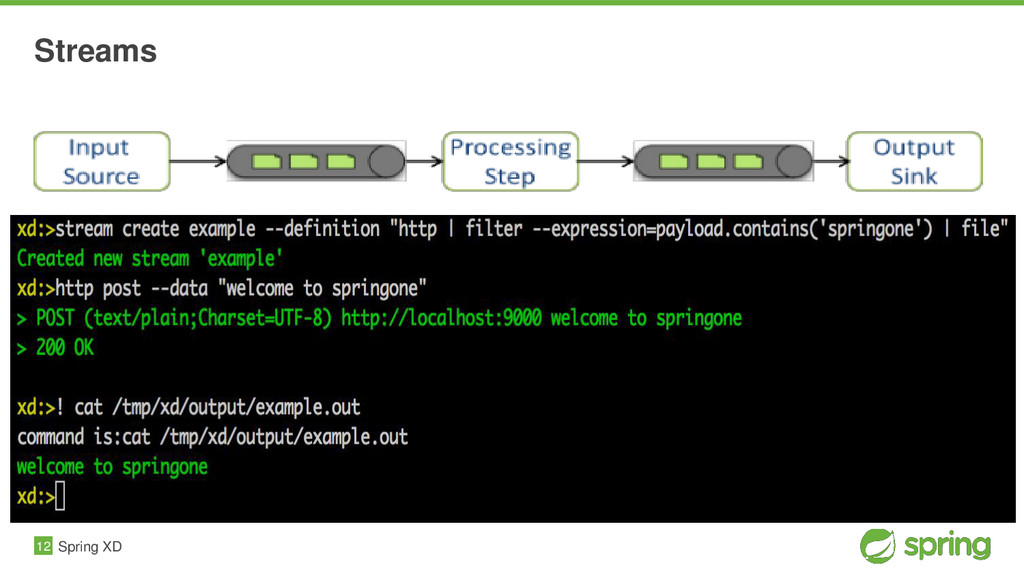
Spring XD aims to provide a one stop shop for writing and deploying Big Data Applications. It provides a scalable, fault tolerant, distributed runtime for Data Ingestion, Analytics, and Workflow Orchestration using a single programming, configuration and extensibility model. By not requiring developers to rationalize all of this themselves across the many different solutions available today, Spring XD greatly reduces the inherent complexity of Big Data development. It's all built on proven projects like Spring Integration, and Spring Batch. You'll see for yourself how this heritage combines to provide a scalable runtime environment, that is easily configured and assembled via a simple DSL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
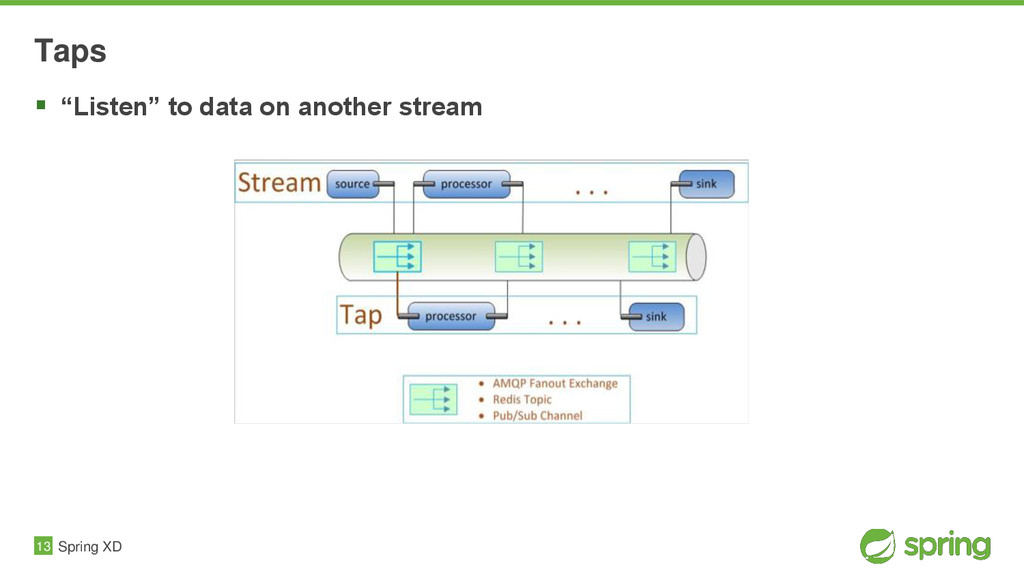{kind=link}
{kind=link}
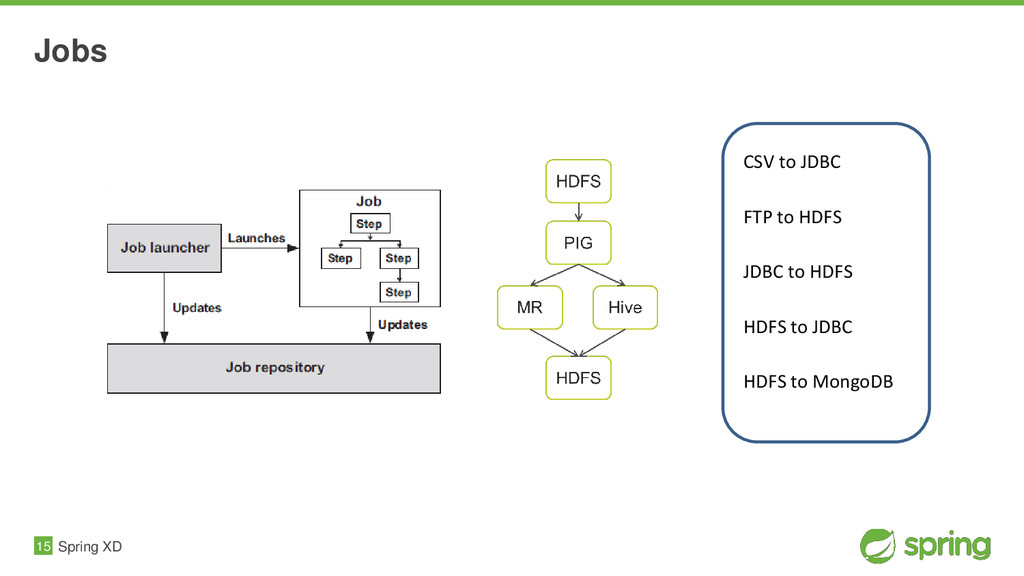{kind=link}
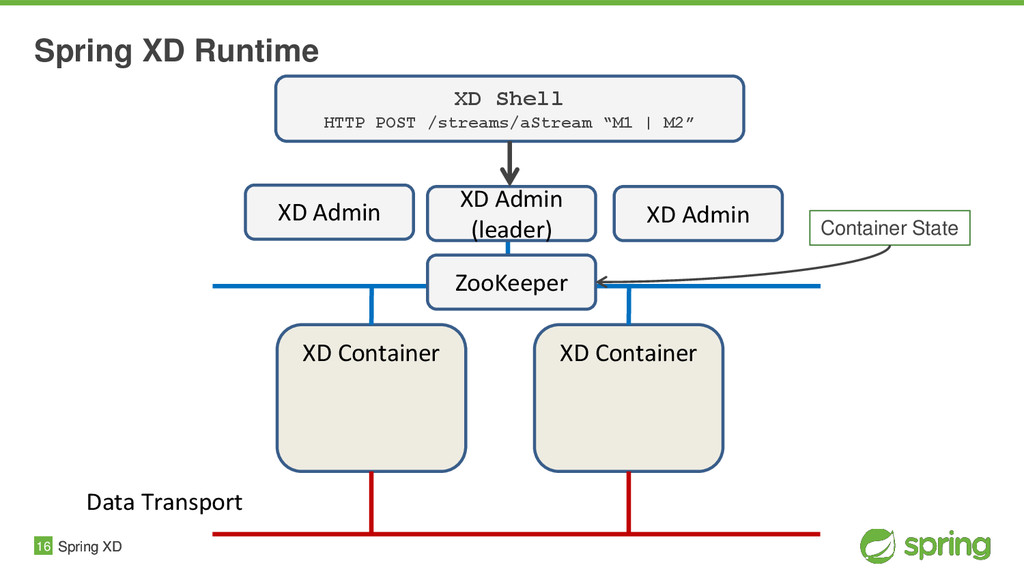{kind=link}
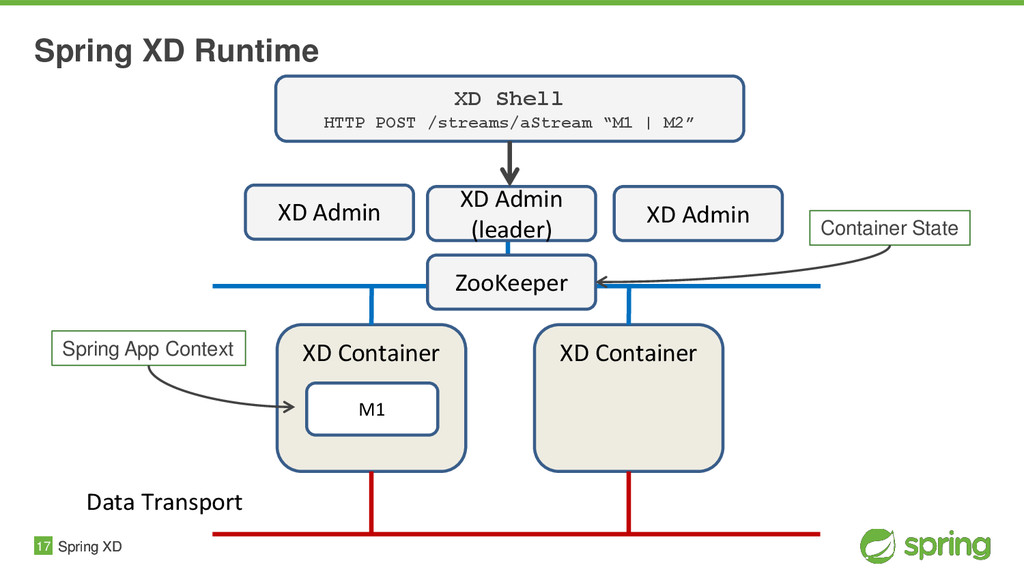{kind=link}
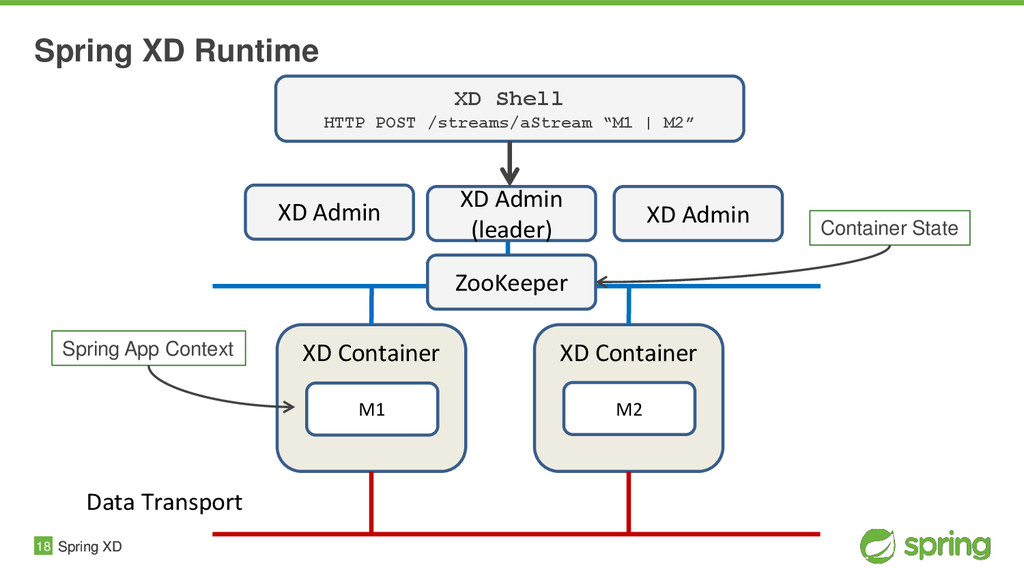{kind=link}
{kind=link}
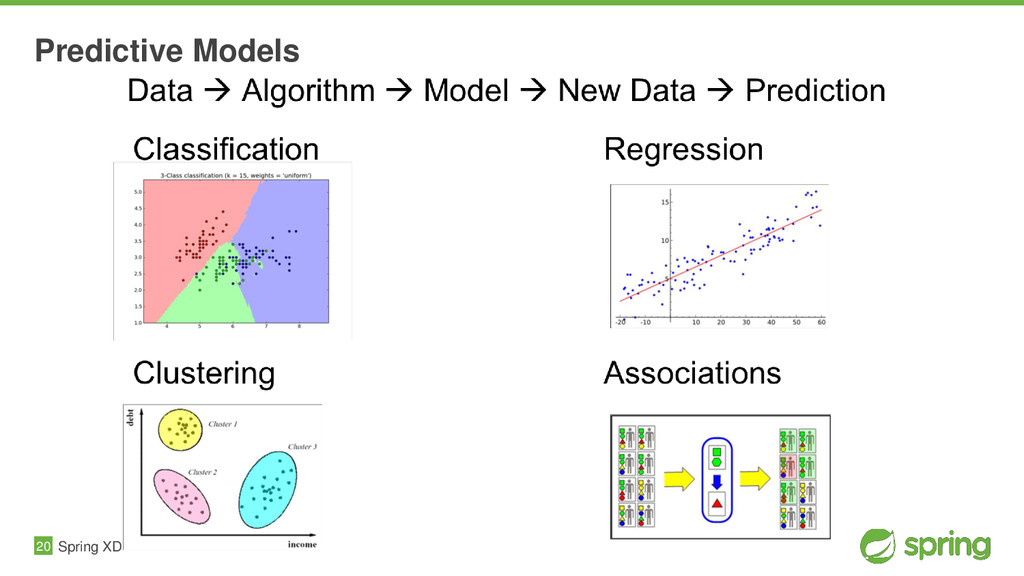{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
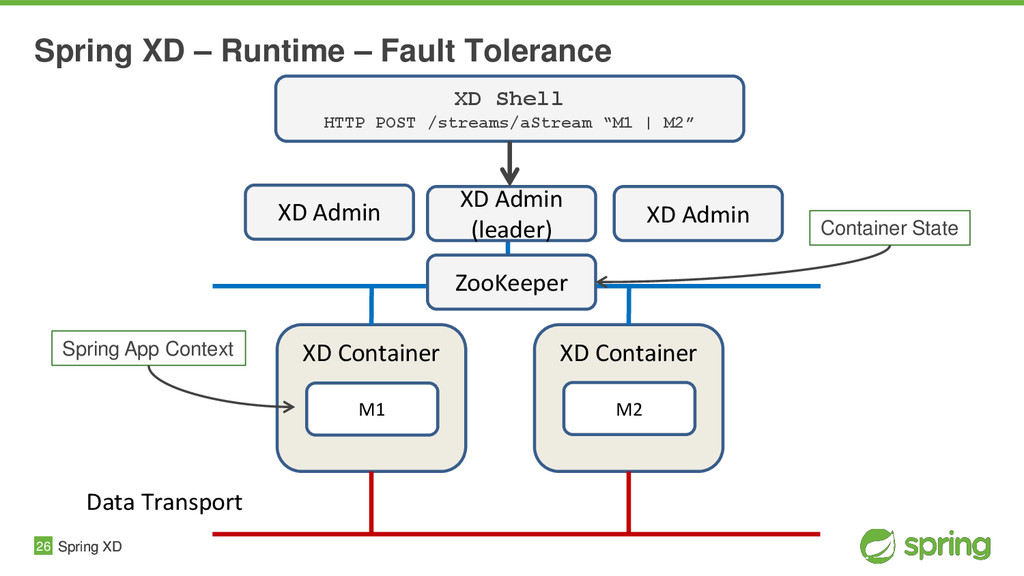{kind=link}
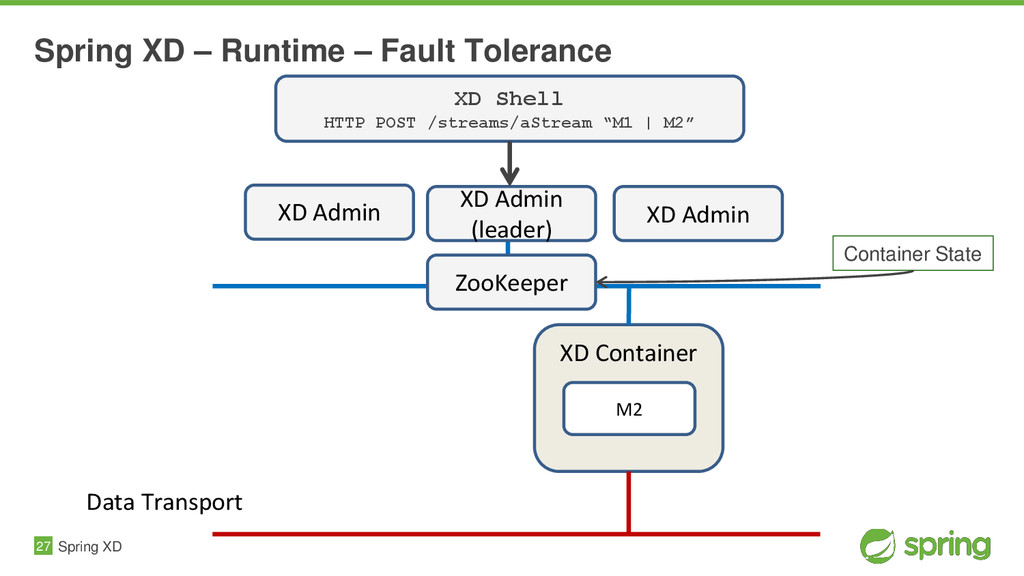{kind=link}
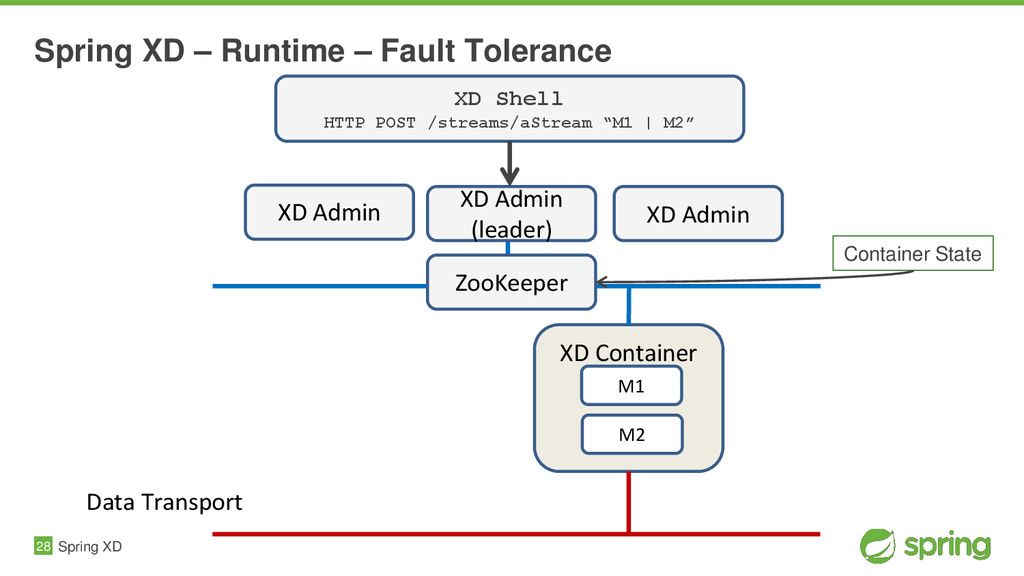{kind=link}
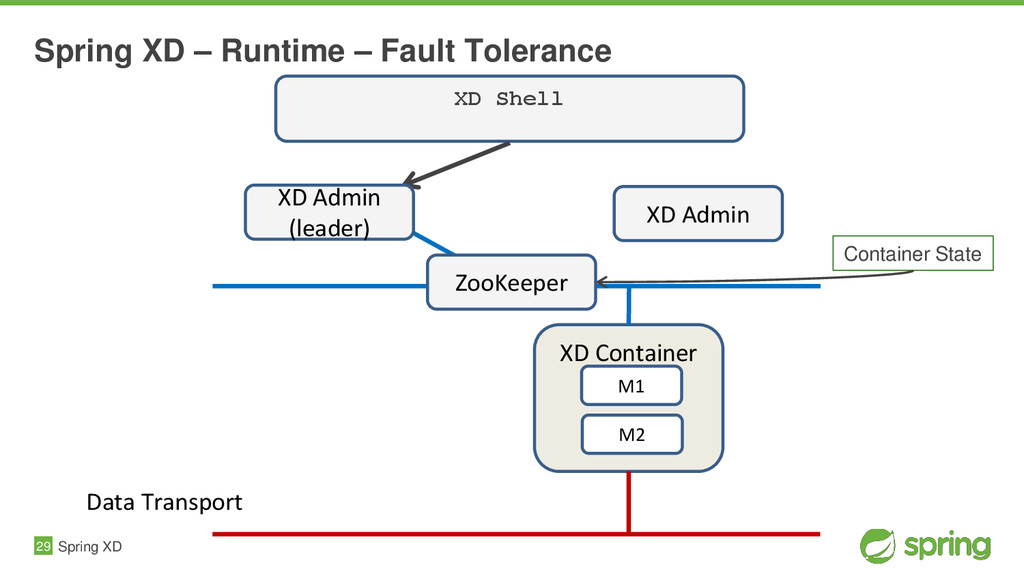{kind=link}
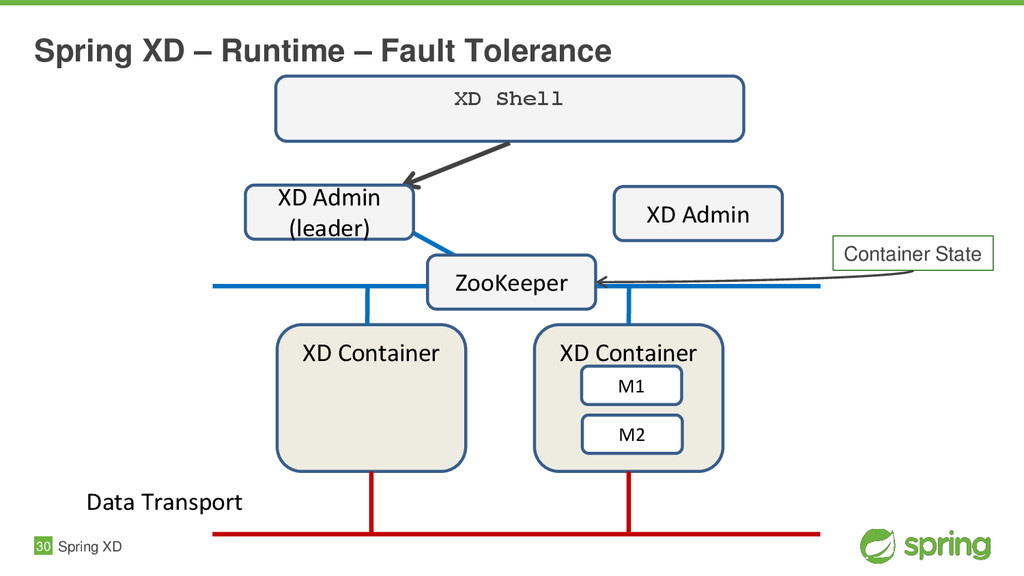{kind=link}
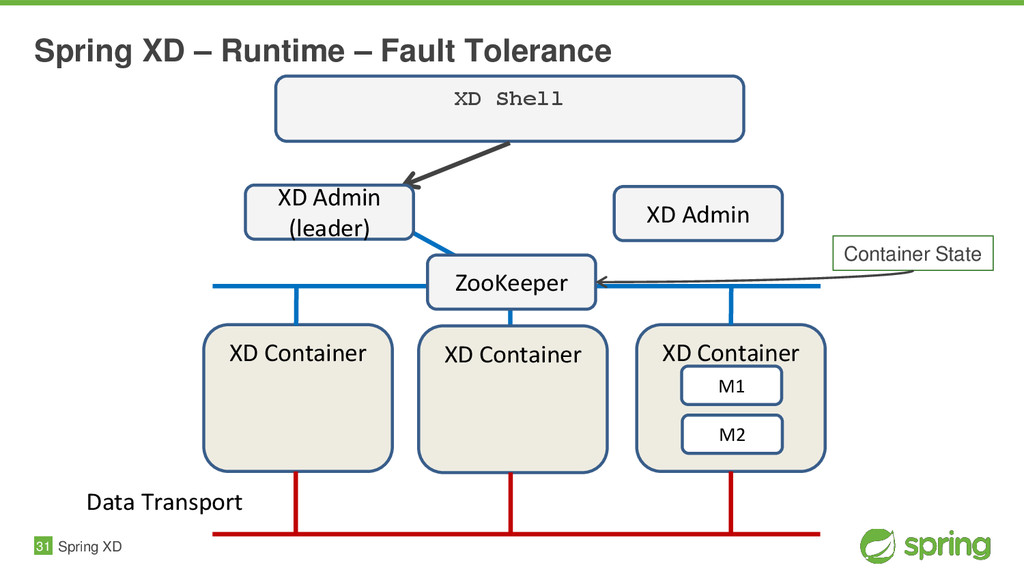{kind=link}
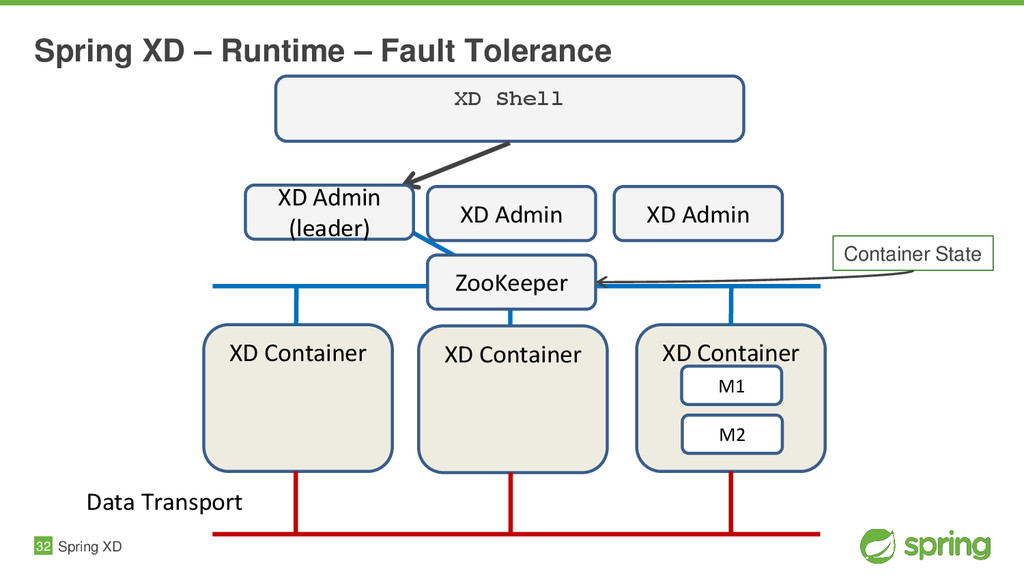{kind=link}
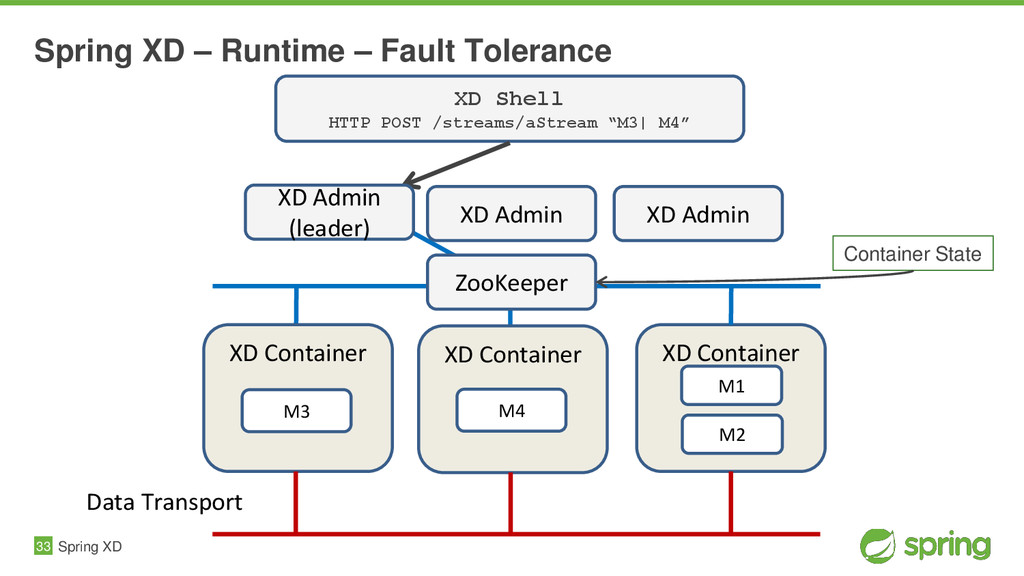{kind=link}
{kind=link}
{kind=link}
{kind=link}
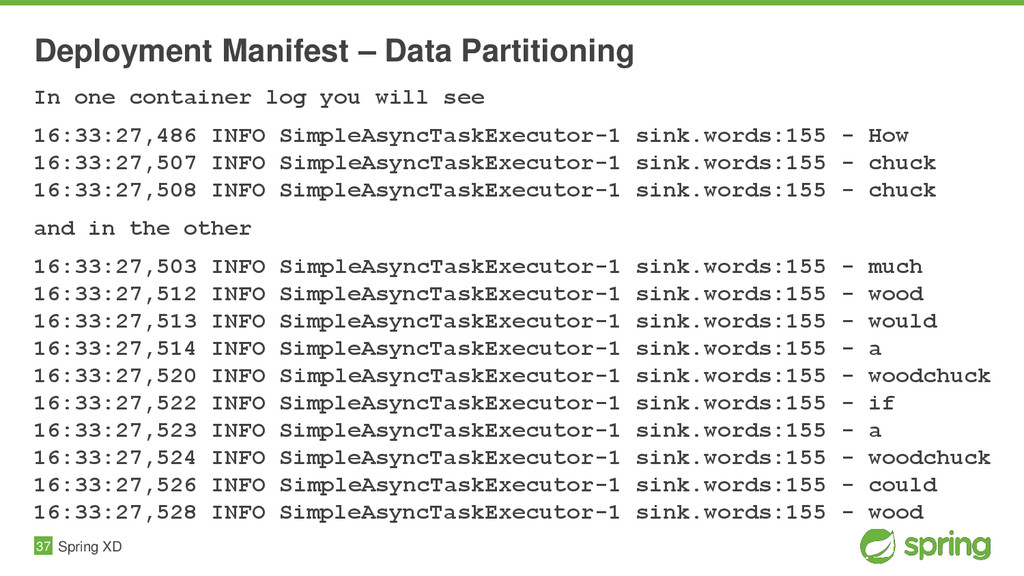{kind=link}
{kind=link}