in Oracle BI&DW •14 Years Experience with Oracle Technology •Regular columnist for Oracle Magazine •Author of two Oracle Press Oracle BI books •Oracle Business Intelligence Developers Guide •Oracle Exalytics Revealed •Writer for Rittman Mead Blog : http://www.rittmanmead.com/blog •Email : [email protected] •Twitter : @markrittman About the Speaker 2
Ryanair use it - famously… Everyone’s Talking About Big Data 3 chema-on-read vs schema on write real-time data ingestion agile data provisioning vs. curated data combining Hadoop, NoSQL and Oracle nnel marketing machine learning & decision engines attitudinal vs behavioural data
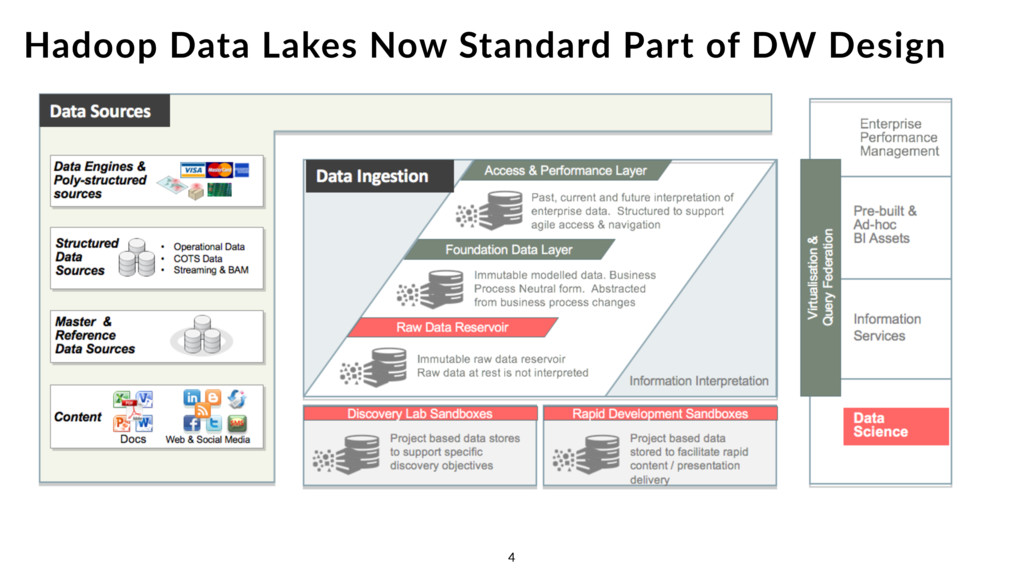
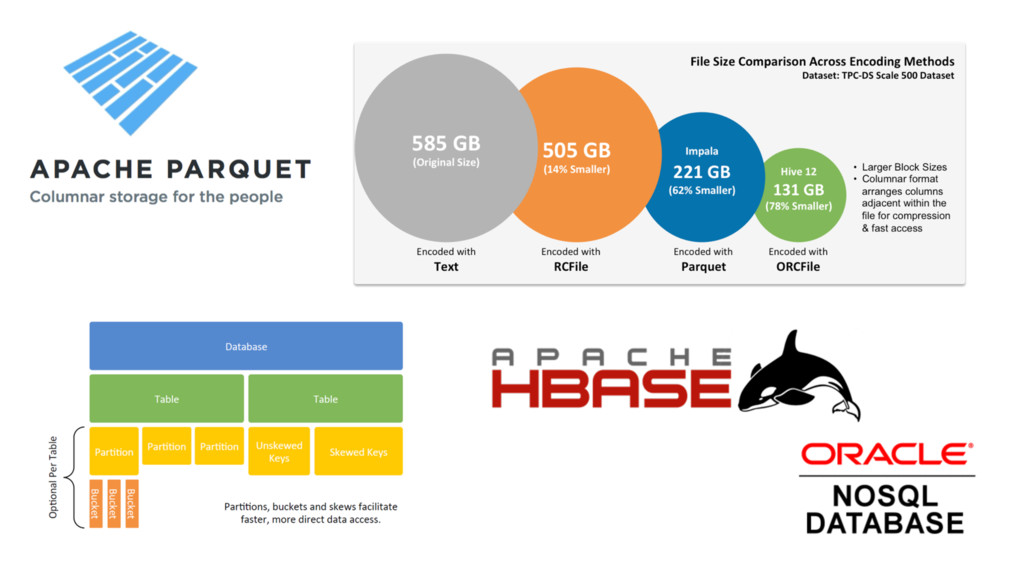
alongside Exadata •Oracle Big Data Connectors - Utility from Oracle for feeding Hadoop data into Oracle •Oracle Data Integrator EE Big Data Option - Add Spark, Pig data transforms to Oracle ODI •Oracle BI Enterprise Edition - can connect to Hive, Impala for federated queries •Oracle Big Data Discovery - data wrangling + visualization tool for Hadoop data reservoirs •Oracle Big Data SQL - extend Oracle SQL language + processing to Hadoop Oracle Software Initiatives around Big Data 5
- don’t use it like this •But adding SQL processing and abstraction can help in many scenarios: •Query access to data stored in Hadoop as an archive •Aggregating, sorting, filtering and transforming data •Set-based transformation capabilities for other frameworks (e.g. Spark) •Ad-hoc analysis and data discovery in-real time •Providing tabular abstractions over complex datatypes Why SQL on Hadoop? 8 SQL! Though SQL isn’t actually relational According to Chris Date SQL is just mappings Tedd Codd used Predicate Calculus and there’s never been a mainstream relational DBMS but it is the standard language for RDBMSs and it’s great for set-based transforms & queries so Yes SQL!
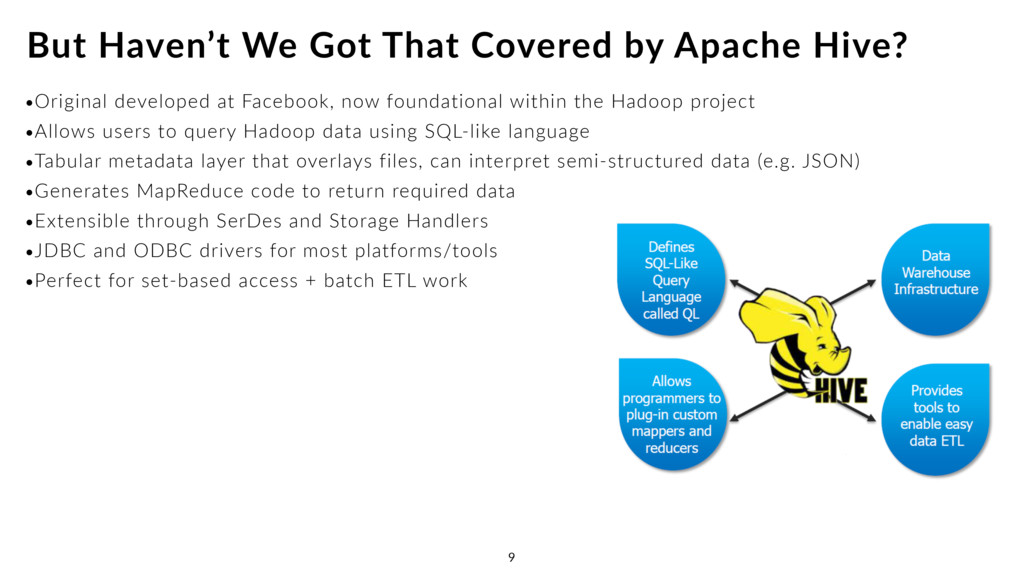
•Allows users to query Hadoop data using SQL-like language •Tabular metadata layer that overlays files, can interpret semi-structured data (e.g. JSON) •Generates MapReduce code to return required data •Extensible through SerDes and Storage Handlers •JDBC and ODBC drivers for most platforms/tools •Perfect for set-based access + batch ETL work But Haven’t We Got That Covered by Apache Hive? 9
data discovery •Inspired by Google Dremel, innovation is querying raw data with schema optional •Automatically infers and detects schema from semi-structured datasets and NoSQL DBs •Join across different silos of data e.g. JSON records, Hive tables and HBase database •Aimed at different use-cases than Hive - low-latency queries, discovery (think Endeca vs OBIEE) And Isn’t the Future of SQL-on-Hadoop Apache Drill? 10
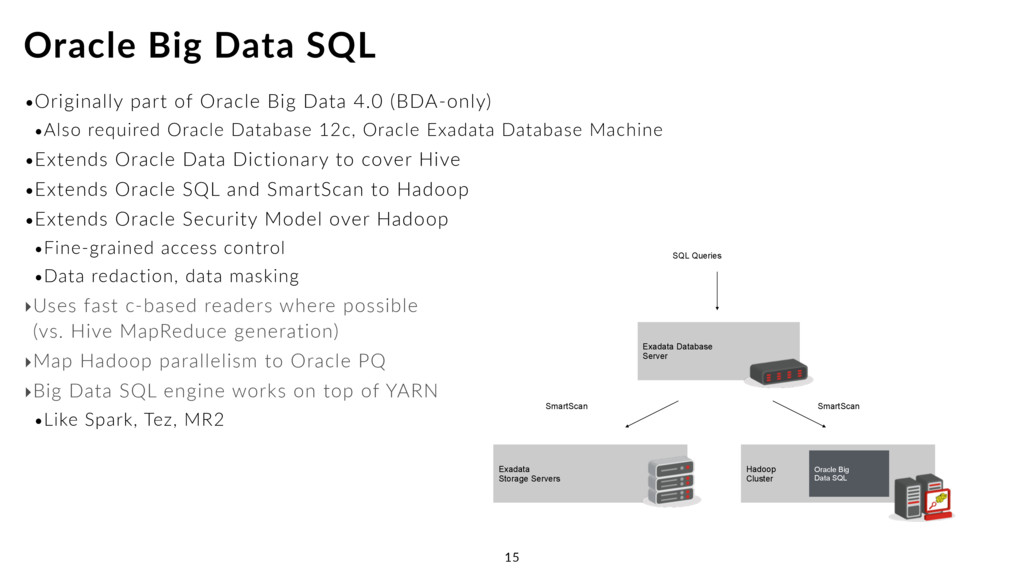
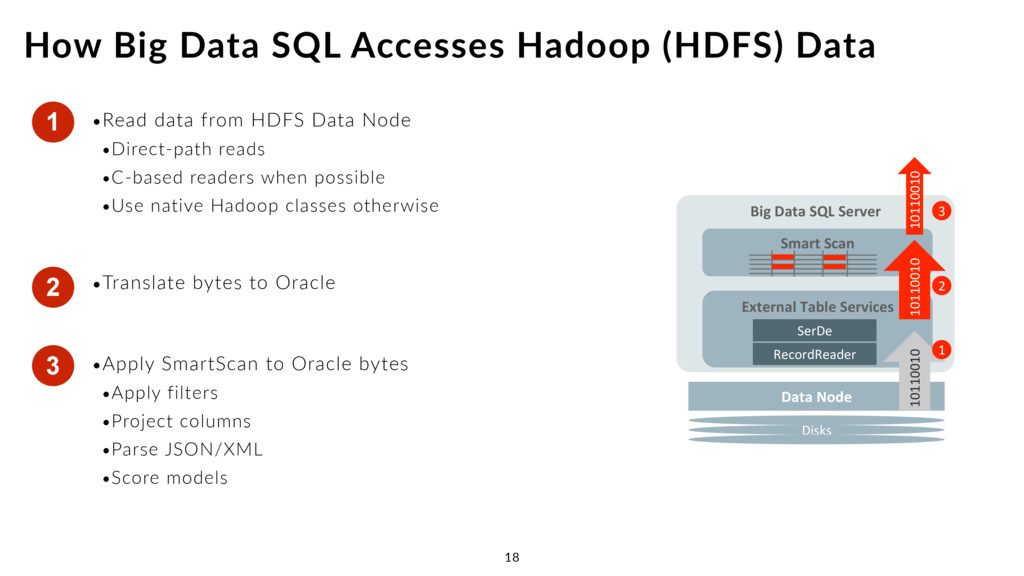
Oracle Database 12c, Oracle Exadata Database Machine •Extends Oracle Data Dictionary to cover Hive •Extends Oracle SQL and SmartScan to Hadoop •Extends Oracle Security Model over Hadoop •Fine-grained access control •Data redaction, data masking ‣Uses fast c-based readers where possible (vs. Hive MapReduce generation) ‣Map Hadoop parallelism to Oracle PQ ‣Big Data SQL engine works on top of YARN •Like Spark, Tez, MR2 Oracle Big Data SQL 15 Exadata Storage Servers Hadoop Cluster Exadata Database Server Oracle Big Data SQL SQL Queries SmartScan SmartScan
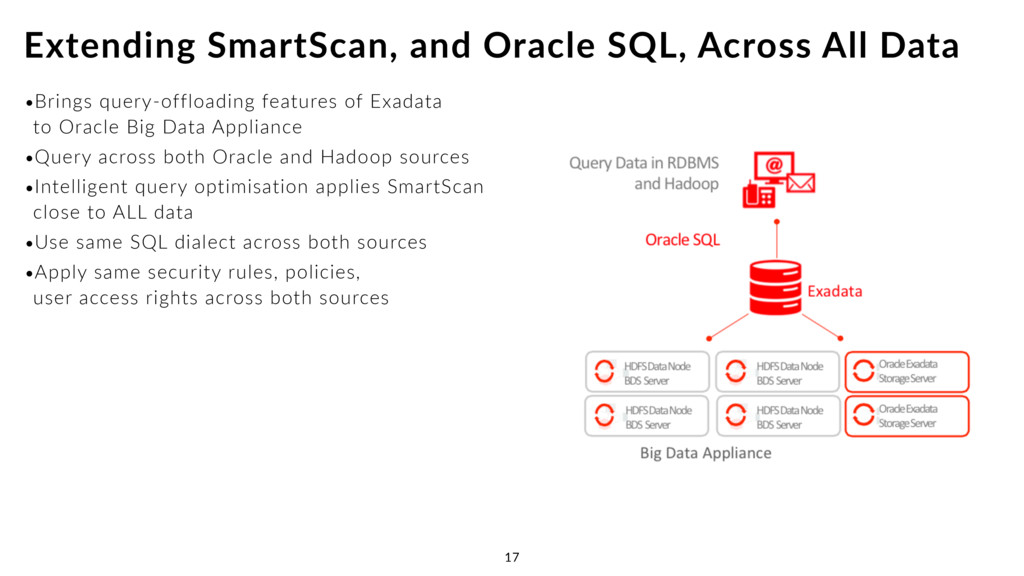
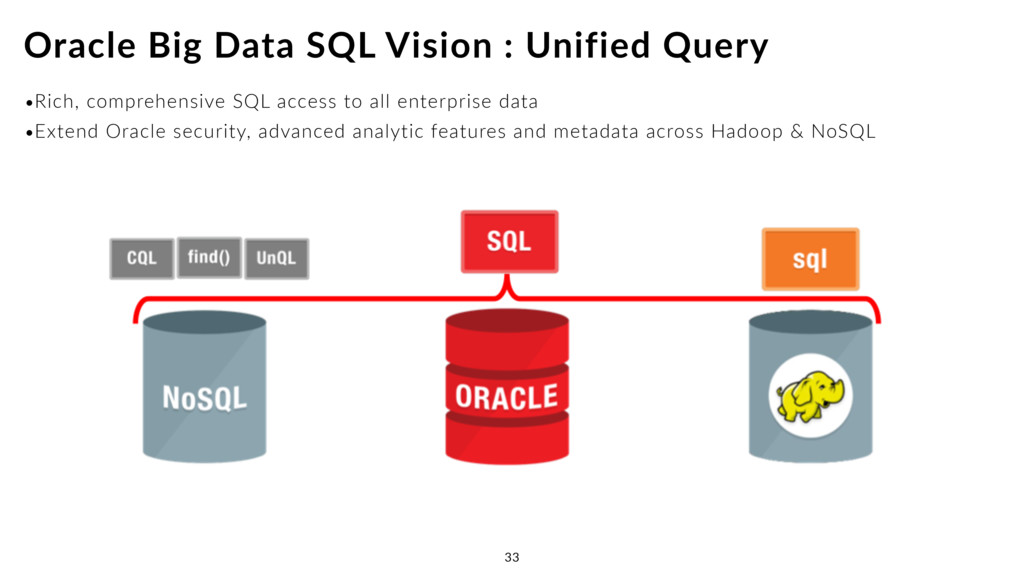
•Query across both Oracle and Hadoop sources •Intelligent query optimisation applies SmartScan close to ALL data •Use same SQL dialect across both sources •Apply same security rules, policies, user access rights across both sources Extending SmartScan, and Oracle SQL, Across All Data 17
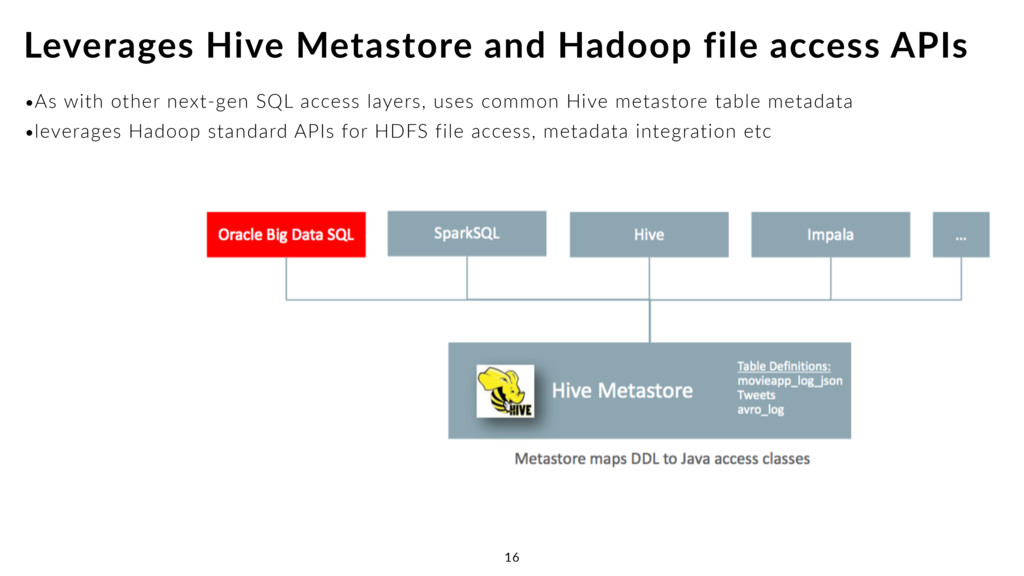
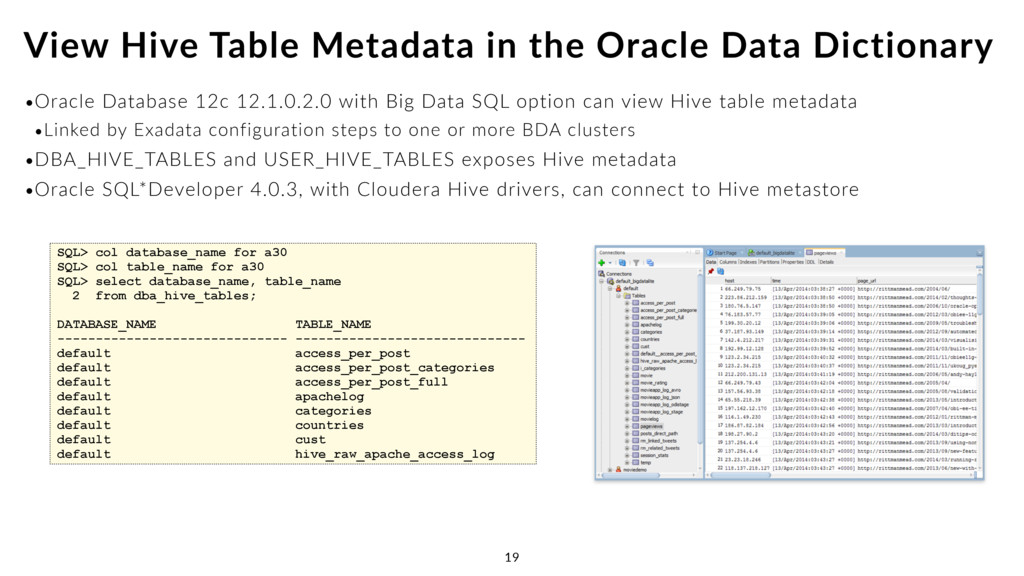
view Hive table metadata •Linked by Exadata configuration steps to one or more BDA clusters •DBA_HIVE_TABLES and USER_HIVE_TABLES exposes Hive metadata •Oracle SQL*Developer 4.0.3, with Cloudera Hive drivers, can connect to Hive metastore View Hive Table Metadata in the Oracle Data Dictionary 19 SQL> col database_name for a30 SQL> col table_name for a30 SQL> select database_name, table_name 2 from dba_hive_tables; DATABASE_NAME TABLE_NAME ------------------------------ ------------------------------ default access_per_post default access_per_post_categories default access_per_post_full default apachelog default categories default countries default cust default hive_raw_apache_access_log
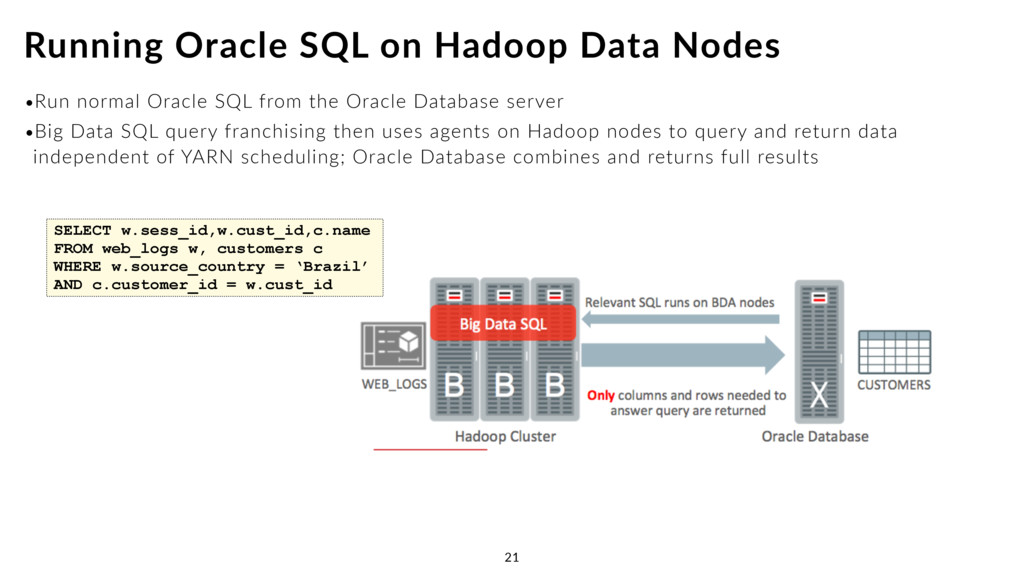
Data SQL query franchising then uses agents on Hadoop nodes to query and return data independent of YARN scheduling; Oracle Database combines and returns full results Running Oracle SQL on Hadoop Data Nodes 21 SELECT w.sess_id,w.cust_id,c.name FROM web_logs w, customers c WHERE w.source_country = ‘Brazil’ AND c.customer_id = w.cust_id
for non-offloadable operations Big Data SQL will perform column pruning and datatype conversion (which saves a lot of resources) •Other operations (non-offloadable) will be done on the database side •Requires Oracle Database 12.1.0.2 + patchset, and per-disk licensing for Big Data SQL •You need and Oracle Big Data Appliance, and Oracle Exadata, to use Big Data SQL Restrictions when using Oracle Big Data SQL 22 SELECT NAME FROM v$sqlfn_metadata WHERE offloadable ='YES'
instead of BDA and Exadata •Oracle Database 12.1.0.2 on x86_64 with Jan/Apr Proactive Bundle Patches •Cloudera CDH 5.5 or Hortonworks HDP 2.3 on RHEL/OEL6 •See MOS Doc ID 2119369.1 - note cannot mix Engineered/Non-Engineered platforms Running Big Data SQL on Commodity Hardware 23
hardware •External table capability lives with the database, and the performance functionality with the BDS cell software. •All BDS features (SmartScan, offloading, storage indexes etc still available) •But hardware can be a factor now, as we’re pushing processing down and data up the wire •1GB ethernet can be too slow, 10Gb is a minimum (i.e. no InfiniBand) •If you run on an undersized system you may see bottlenecks on the DB side. Big Data SQL on Commodity Hardware Considerations 24
from non-HDFS sources •MongoDB, HBase, Oracle NoSQL database •Run HiveQL queries against NoSQL DBs •From BDS1.1, Hive storage handlers can be used with Big Data SQL •Only MongoDB, HBase and NoSQL currently “supported” •Others should work but not tested Big Data SQL and Hive Storage Handlers 28
in Big Data SQL agents •Check index before reading blocks – Skip unnecessary I/Os •An average of 65% faster than BDS 1.x •Up to 100x faster for highly selective queries •Columns in SQL mapped to fields in HDFS file via External Table Definitions •Min / max value is recorded for each HDFS Block in a storage index Big Data SQL Storage Indexes 30
pruning etc) •Original BDS 1.0 supported Hive predicate push-down as part of SmartScan •BDS 3.0 extends this by pushing SARGable (Search ARGument ABLE) predicates •Into Parquet and ORCFile to reduce I/O when reading files from disk •Into HBAse and Oracle NoSQL database to drive subscans of data from remote DB •Oracle Database 12.2 will add more optimisations •Columnar-caching •Big Data-Aware Query Optimizer, •Managed Hadoop partitions •Dense Bloom Filters Extending Predicate Push-Down Beyond Hive 31
results delivered through Oracle •What if you want to load data into Hadoop, update data, do Hadoop>Hadoop transforms? •Still requires formal Hive metadata, whereas direction is towards Drill & schema-free queries •What if you have other RDBMSs as well as Oracle RDBMS? •Trend is towards moving all high-end analytic workloads into Hadoop - BDS is Oracle-only •Requires Oracle 12c database, no 11g support •And cost … BDS is $3k/Hadoop disk drive •Can cost more than an Oracle BDA •High-end, high-cost Oracle-centric solution •of course! … So What’s the Catch? 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}