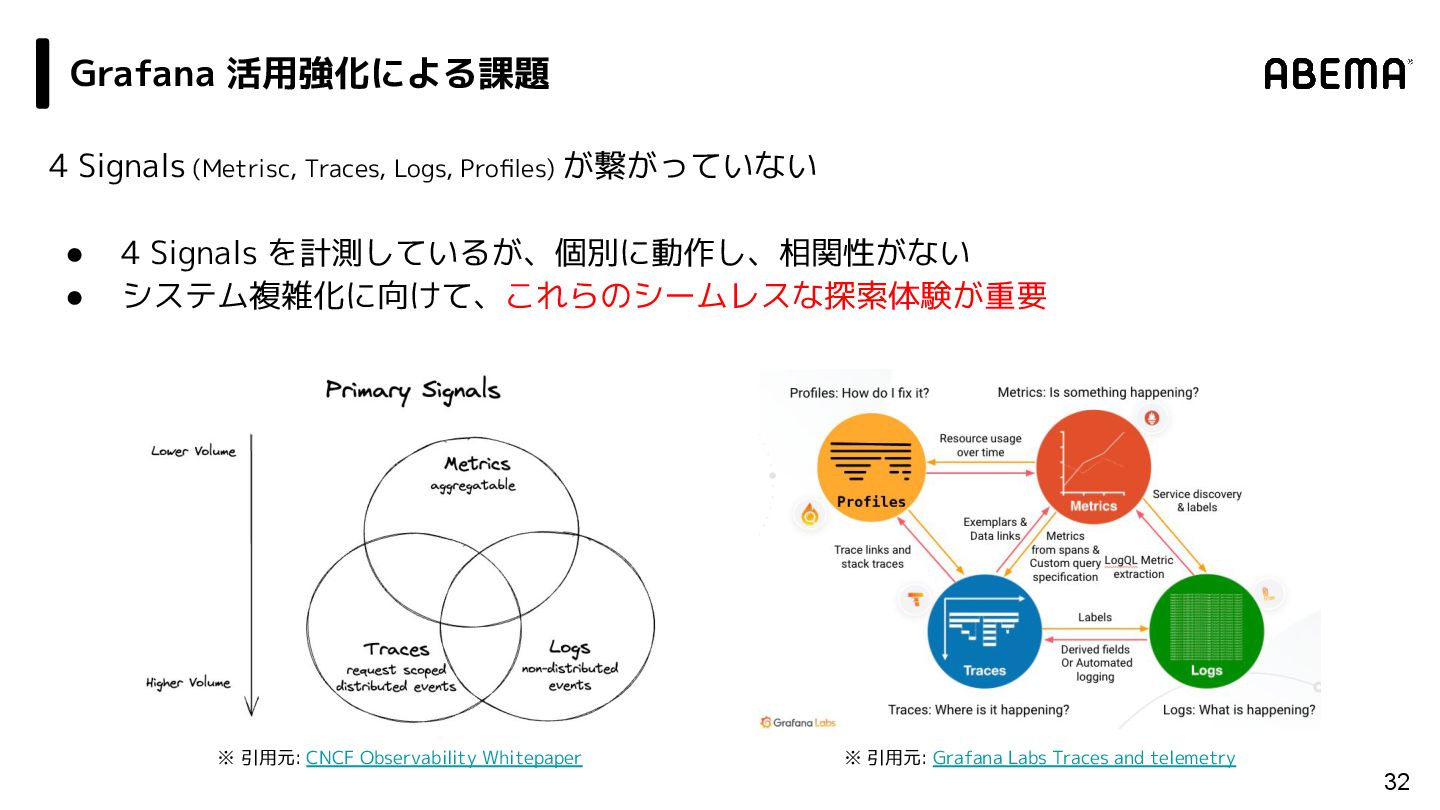
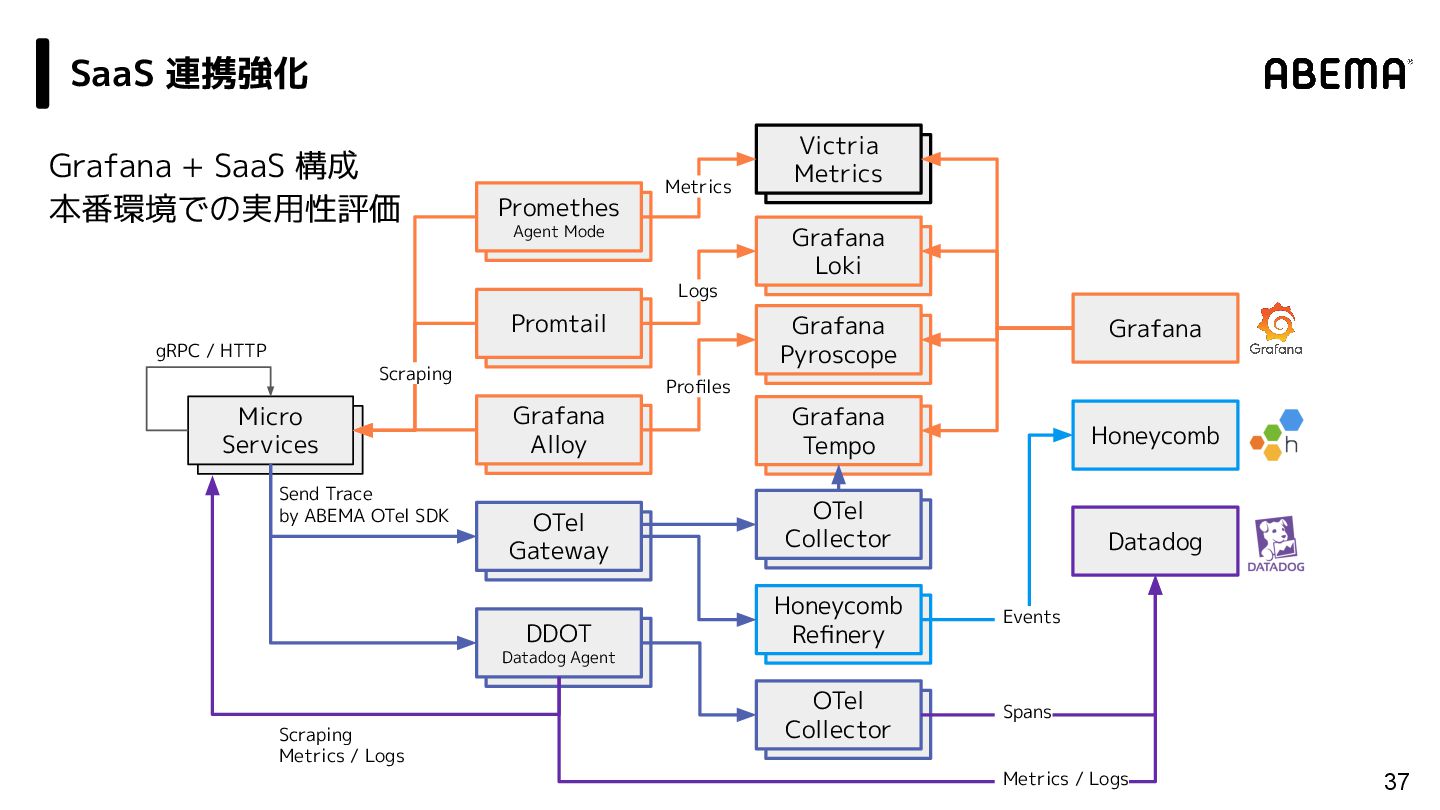
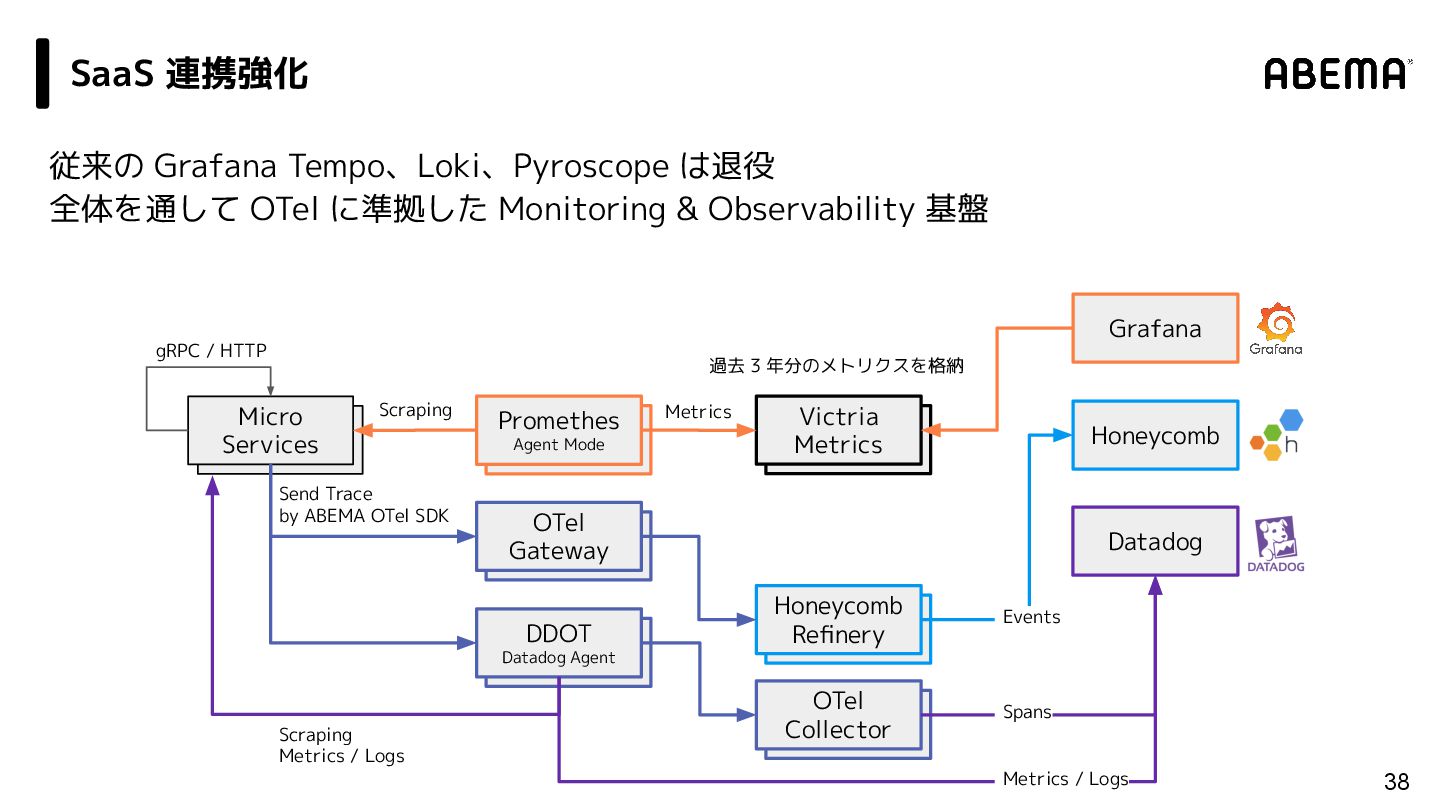
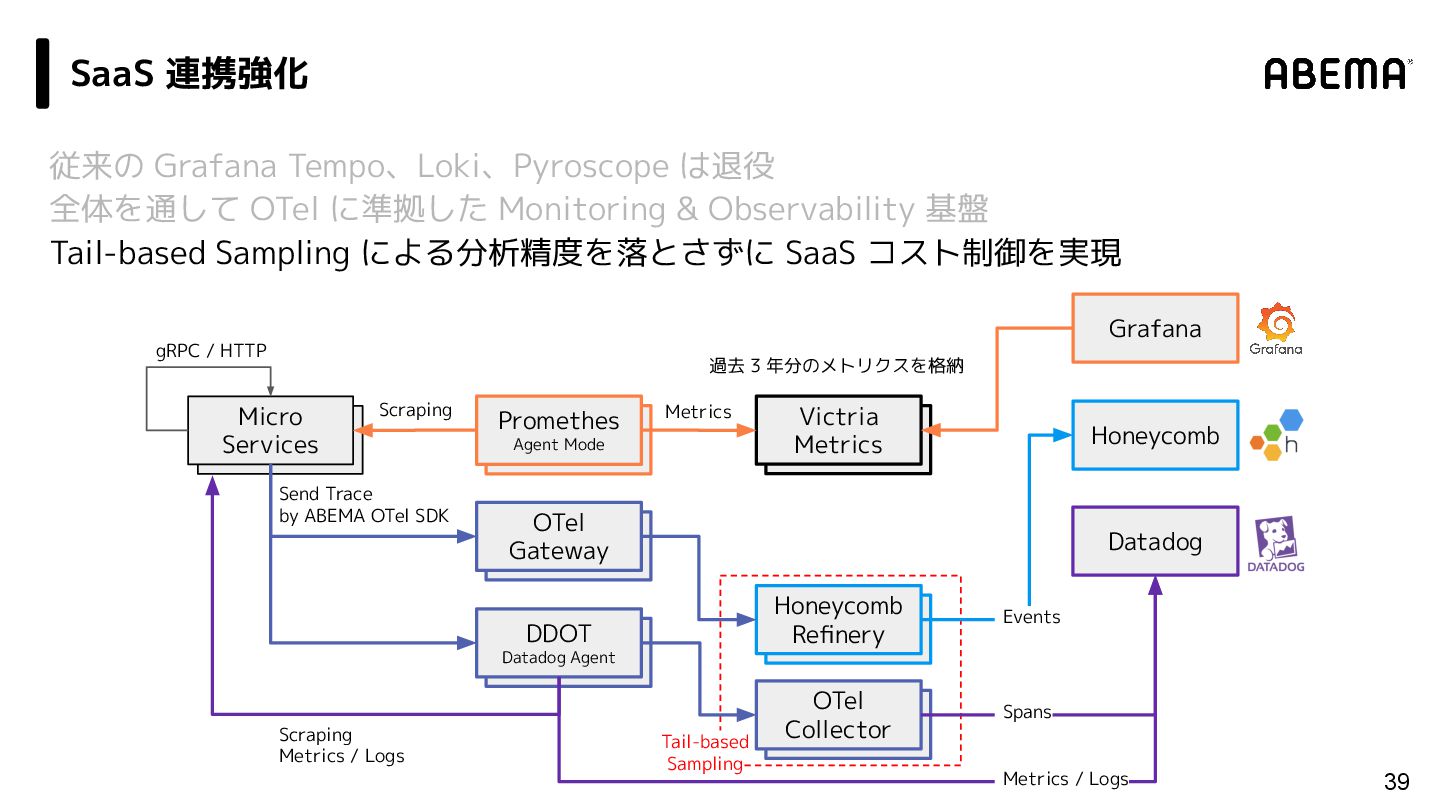
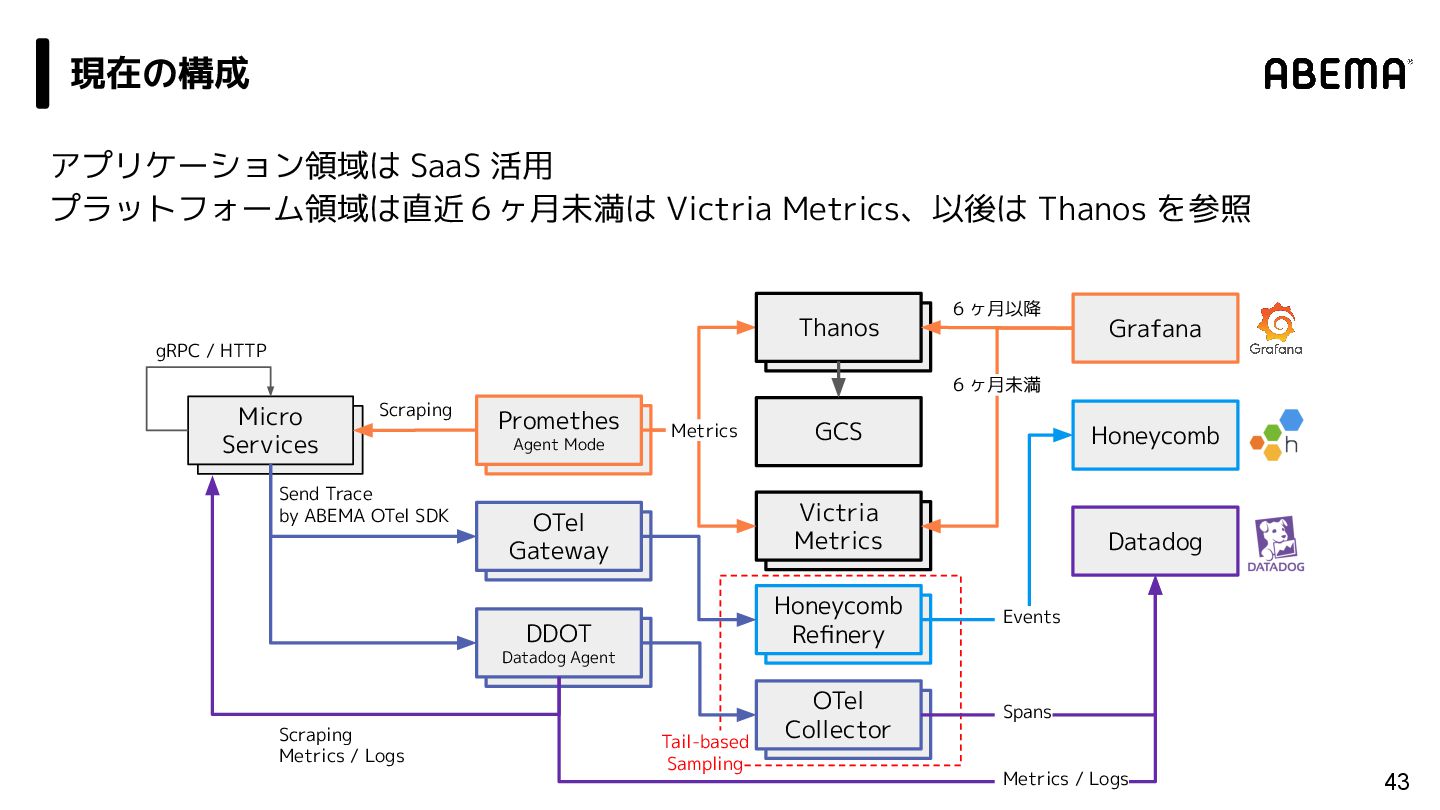
/ Grafana Alloy 31 vm insert Victria Metrics vm insert Grafana Pyroscope vm insert Grafana Loki Grafana vm insert Grafana Tempo vm insert Promtail vm insert OTel Gateway vm insert Promethes Agent Mode vm insert Grafana Alloy vm insert OTel Collector vm insert Micro Services Scraping Profiles Logs Metrics gRPC / HTTP Grafana 活用強化 Send Trace by ABEMA OTel SDK
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
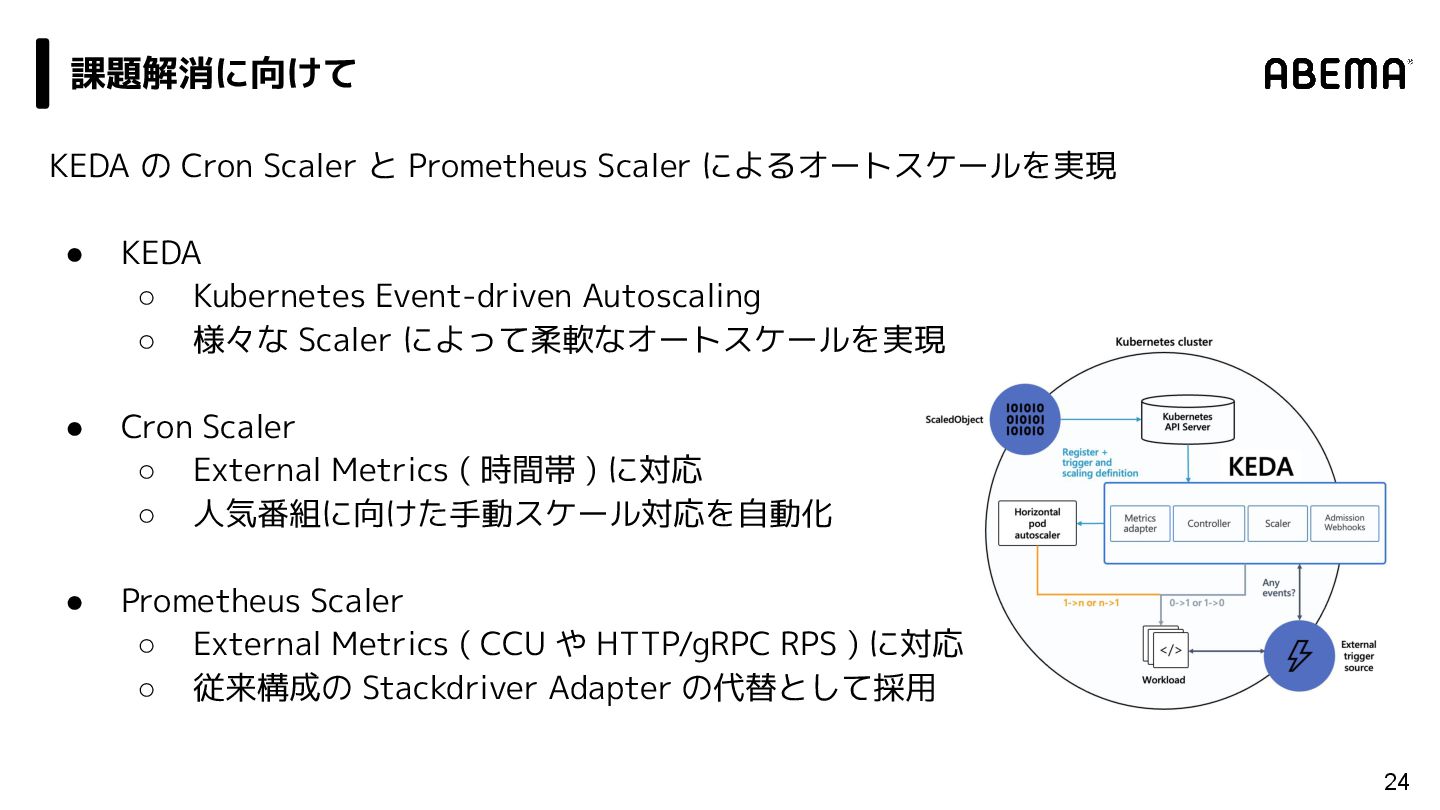{kind=link}
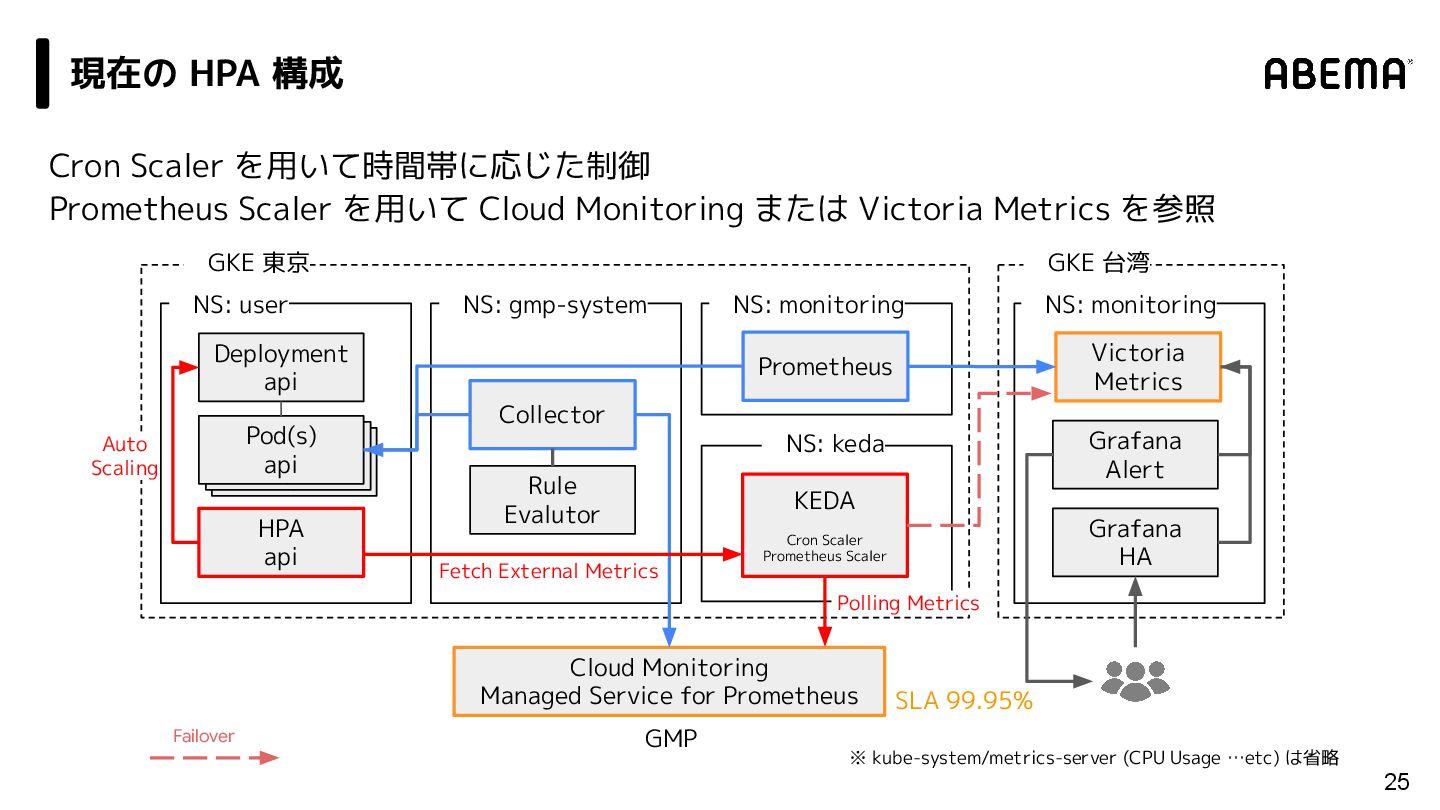{kind=link}
{kind=link}
{kind=link}
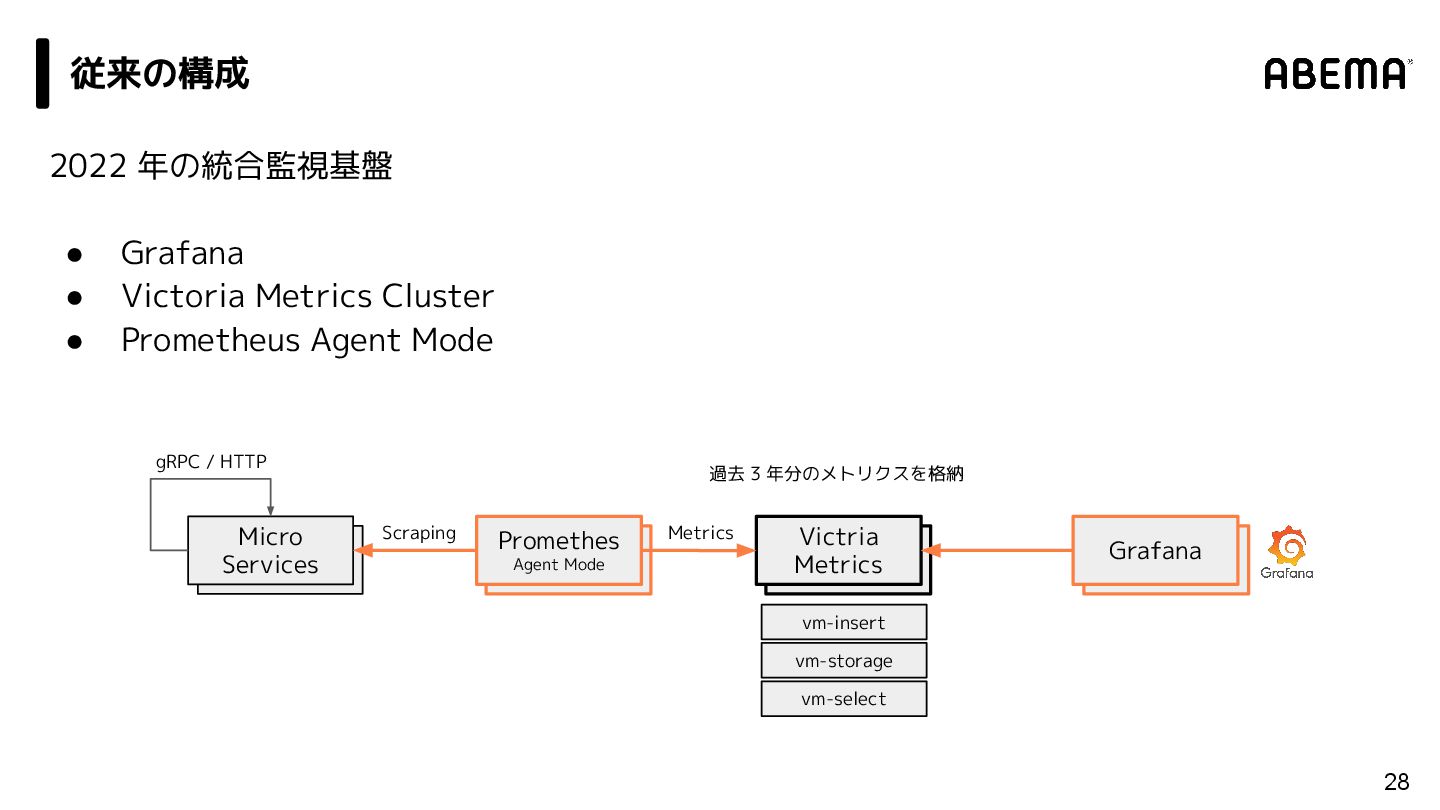{kind=link}
{kind=link}
{kind=link}
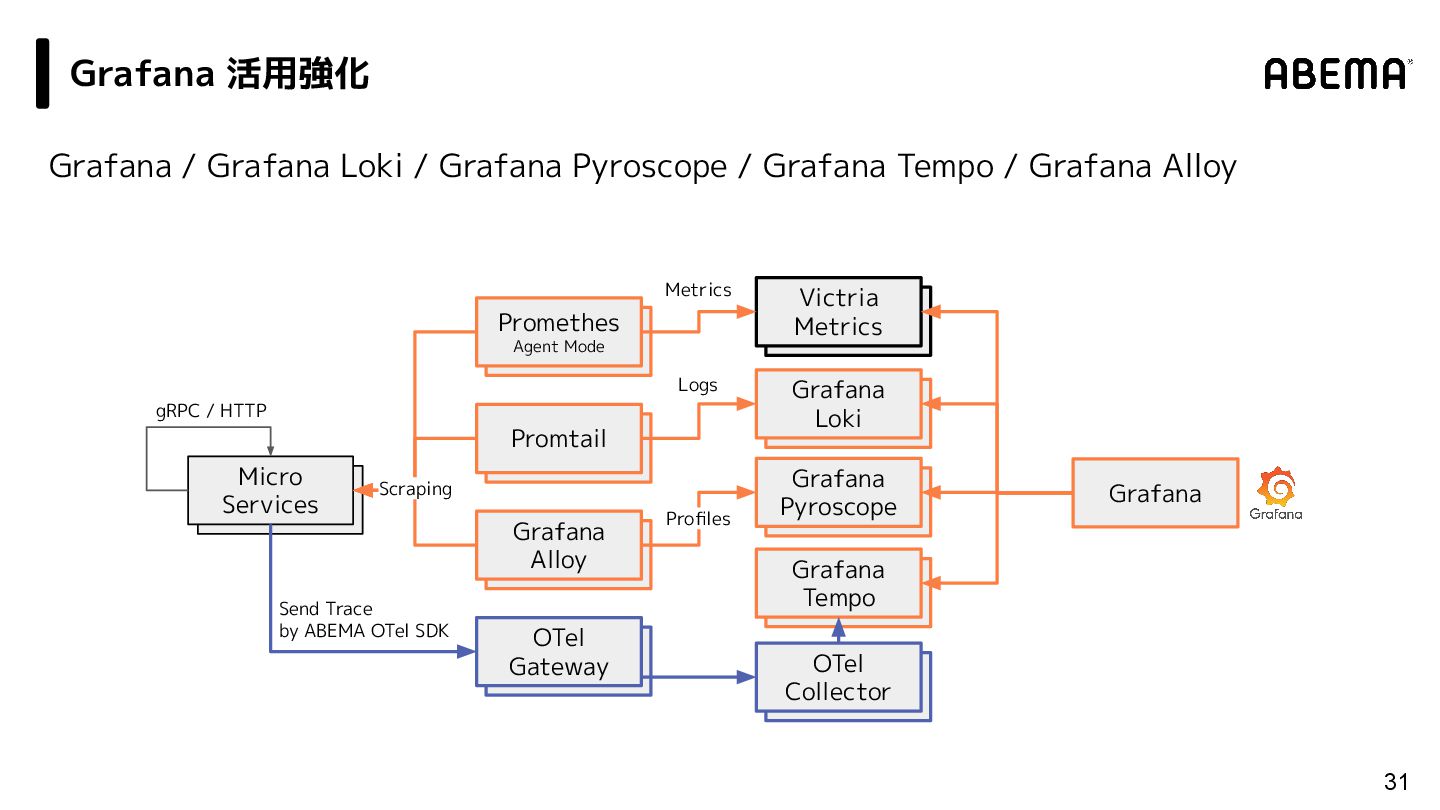{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}