Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLMでAI-OCR、実際どうなの? / llm_ai_ocr_layerx_bet_ai_d...
Search
sbrf248
July 30, 2025
Technology
10k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLMでAI-OCR、実際どうなの? / llm_ai_ocr_layerx_bet_ai_day_lt
sbrf248
July 30, 2025
More Decks by sbrf248
See All by sbrf248
自社開発SaaSバクラクのAI技術とそれに向き合うエンジニアのやりがい / layerx-ai-engineer-dataconference20240601
sbrf248
0
440
バクラクのアノテーション基盤の伸びしろを考えてみた
sbrf248
1
240
Other Decks in Technology
See All in Technology
基調講演:人とAIをつなぐIoTの今と未来 ー 「フィジカル」と「デジタル」が出会うその先へ【SORACOM Discovery 2026】
soracom
PRO
0
360
WEBフロントエンド研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
820
toio・myCobotでフィジカルAIっぽいことを行うための検討(とりあえず調査) / フィジカルAI LT(IoTLTによる開催)
you
PRO
0
150
信頼できるテスティングAIをどう育てるか?
odan611
0
170
書籍セキュアAPIについて
riiimparm
0
390
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
1k
AI時代の強いチームの作り方
yuukiyo
16
8.8k
20260801_スクフェス大阪
kgnkhkr
0
130
運用を犠牲にせずコストを制御し事業成長を支える B2B SaaS ID管理基盤におけるS3 Tableのログストレージ活用
kaminashi
1
120
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
2.9k
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
1.4k
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
780
Featured
See All Featured
Agile that works and the tools we love
rasmusluckow
331
22k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
HDC tutorial
michielstock
2
760
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
750
The Curious Case for Waylosing
cassininazir
1
440
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.7k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Transcript
© LayerX Inc. LLMでAI-OCR、実際どうなの? バクラク事業部 AI・機械学習部 AI-OCRグループ 伊藤 駿 ITO,
Shun DAY06 topic Deep into AI Speaker
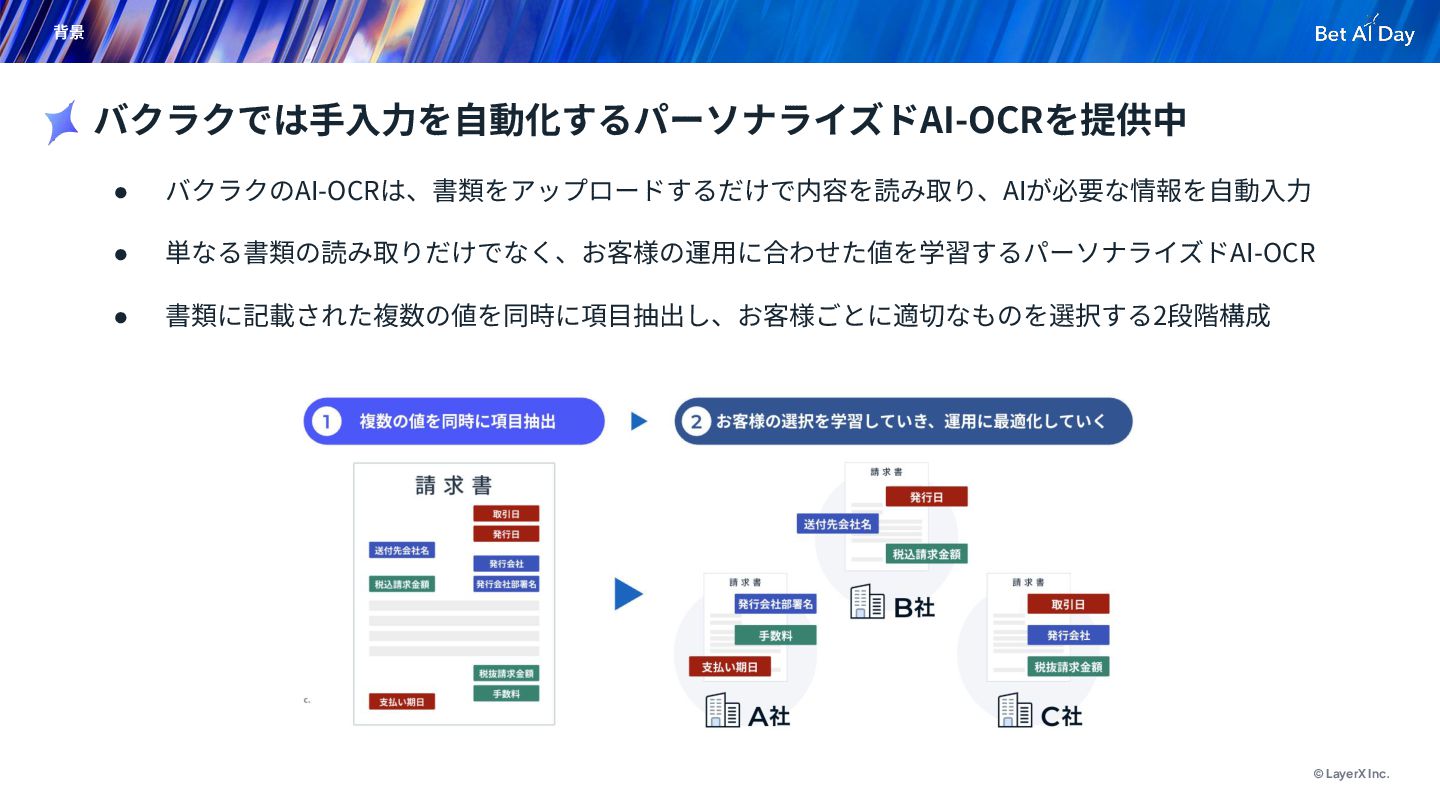
© LayerX Inc. 背景 • バクラクのAI-OCRは、書類をアップロードするだけで内容を読み取り、AIが必要な情報を⾃動⼊⼒ • 単なる書類の読み取りだけでなく、お客様の運⽤に合わせた値を学習するパーソナライズドAI-OCR • 書類に記載された複数の値を同時に項⽬抽出し、お客様ごとに適切なものを選択する2段階構成
バクラクでは⼿⼊⼒を⾃動化するパーソナライズドAI-OCRを提供中
© LayerX Inc. 背景 • パーソナライズドAI-OCRは、LLMではなく⾃社NLPモデル + 推薦モデルで実装 ◦ 問題設定が明確で、⾃社ドメインの⼤量データを使った学習によって
⾼い精度を出せる ◦ In-Context Learningより推薦モデルの⽅がシンプルで解釈しやすい ◦ AI-UX観点での組み込みやすさ、推論速度の速さ • LLMの画像‧⾔語処理能⼒の進歩は著しく、⾼精度なOCRが現実的に ◦ ChatGPTやGeminiなどにレシートを渡すと、⾼精度で内容を 読み取ってくれる Why not LLM? ⼀⽅で、LLMの性能が上がってきているのも事実
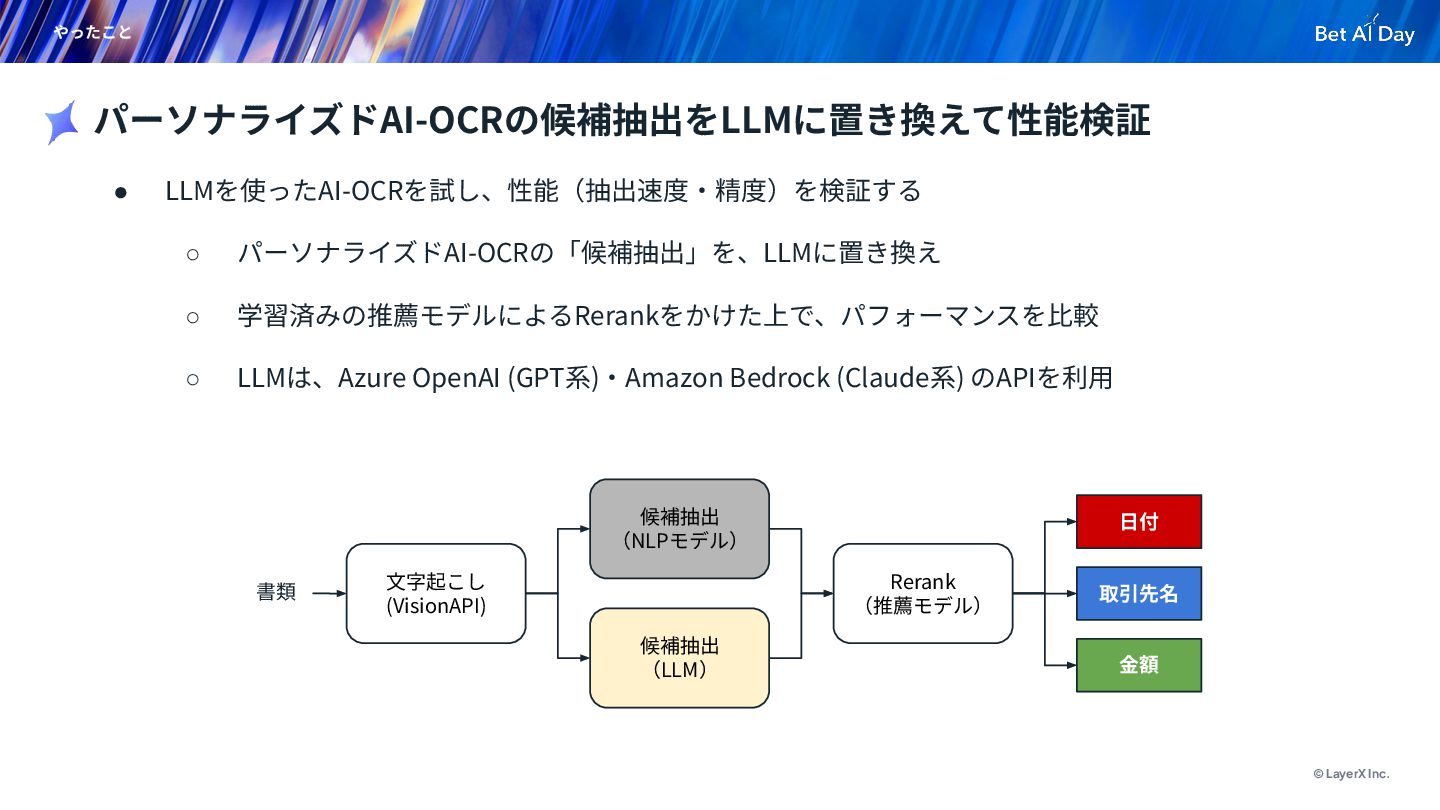
© LayerX Inc. やったこと • LLMを使ったAI-OCRを試し、性能(抽出速度‧精度)を検証する ◦ パーソナライズドAI-OCRの「候補抽出」を、LLMに置き換え ◦ 学習済みの推薦モデルによるRerankをかけた上で、パフォーマンスを⽐較
◦ LLMは、Azure OpenAI (GPT系)‧Amazon Bedrock (Claude系) のAPIを利⽤ パーソナライズドAI-OCRの候補抽出をLLMに置き換えて性能検証 候補抽出 (NLPモデル) 候補抽出 (LLM) Rerank (推薦モデル) ⽇付 取引先名 ⾦額 ⽂字起こし (VisionAPI) 書類
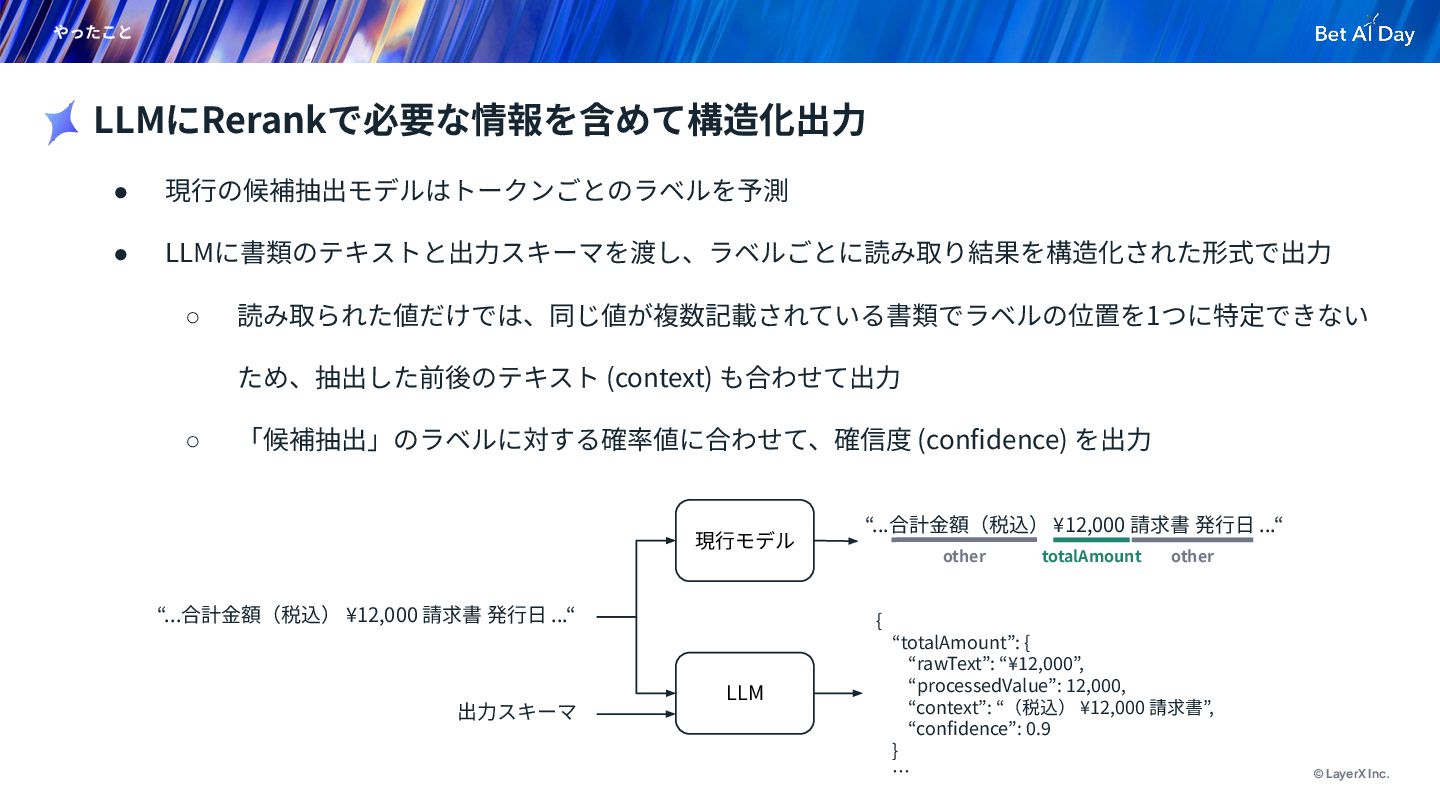
© LayerX Inc. やったこと • 現⾏の候補抽出モデルはトークンごとのラベルを予測 • LLMに書類のテキストと出⼒スキーマを渡し、ラベルごとに読み取り結果を構造化された形式で出⼒ ◦ 読み取られた値だけでは、同じ値が複数記載されている書類でラベルの位置を1つに特定できない
ため、抽出した前後のテキスト (context) も合わせて出⼒ ◦ 「候補抽出」のラベルに対する確率値に合わせて、確信度 (confidence) を出⼒ LLMにRerankで必要な情報を含めて構造化出⼒ “...合計⾦額(税込) ¥12,000 請求書 発⾏⽇ ...“ 現⾏モデル LLM 出⼒スキーマ { “totalAmount”: { “rawText”: “¥12,000”, “processedValue”: 12,000, “context”: “(税込) ¥12,000 請求書”, “confidence”: 0.9 } … totalAmount “...合計⾦額(税込) ¥12,000 請求書 発⾏⽇ ...“ other other
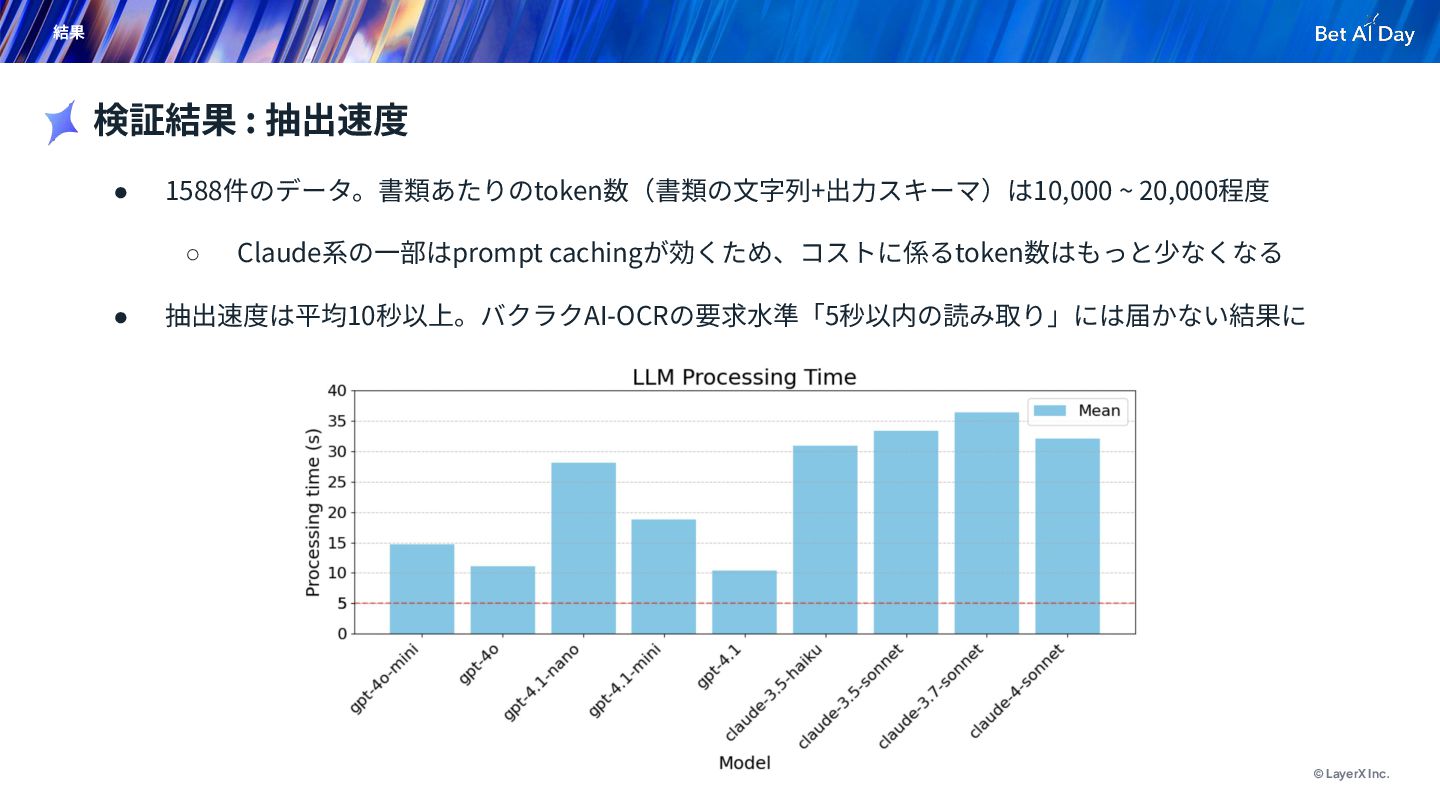
© LayerX Inc. 結果 • 1588件のデータ。書類あたりのtoken数(書類の⽂字列+出⼒スキーマ)は10,000 ~ 20,000程度 ◦ Claude系の⼀部はprompt
cachingが効くため、コストに係るtoken数はもっと少なくなる • 抽出速度は平均10秒以上。バクラクAI-OCRの要求⽔準「5秒以内の読み取り」には届かない結果に 検証結果 : 抽出速度
© LayerX Inc. 結果 • パーソナライズドAI-OCRを1.0としてLLMの項⽬ごとにRerankした後の精度(Top1 Accuracy)を⽐較 ◦ ⾦額(PaymentAmount)‧取引先名(ClientName)‧⽇付(DocumentDate)について評価 •
GPT系のモデルよりも、Claude系のモデルが全体的にやや⾼精度 • いずれのモデル‧項⽬についても 1.0 を下回り、⾼いものは 0.9 前後の精度に ◦ 軽量なモデルほど、取引先名となる名前の⼀部しか取れていないような間違いが⽬⽴つ 検証結果 : 項⽬別の読み取り精度
© LayerX Inc. 結論 • 今回は、パーソナライズドAI-OCRの「候補抽出」をそのままLLMに置き換えるだけの性能は確認できず ◦ パーソナライズドAI-OCRを基準に0.9程度の精度はでているものの、より⾼める⼯夫が必要 ◦ 抽出速度は特にボトルネックになりそう
• とはいえ、LLMによるAI-OCRはまだまだ別の可能性が考えられる ◦ コンテキストに過去の⼊⼒履歴に関する情報を加え、LLMでRerankも含めたE2Eの推論 ◦ 主要項⽬(⾦額‧取引先名‧⽇付)以外の読み取り項⽬への拡張 • 既存の機械学習技術だけに囚われず、状況に応じて適切な技術を使い分け、お客様の様々な 課題を解決していきます! まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}