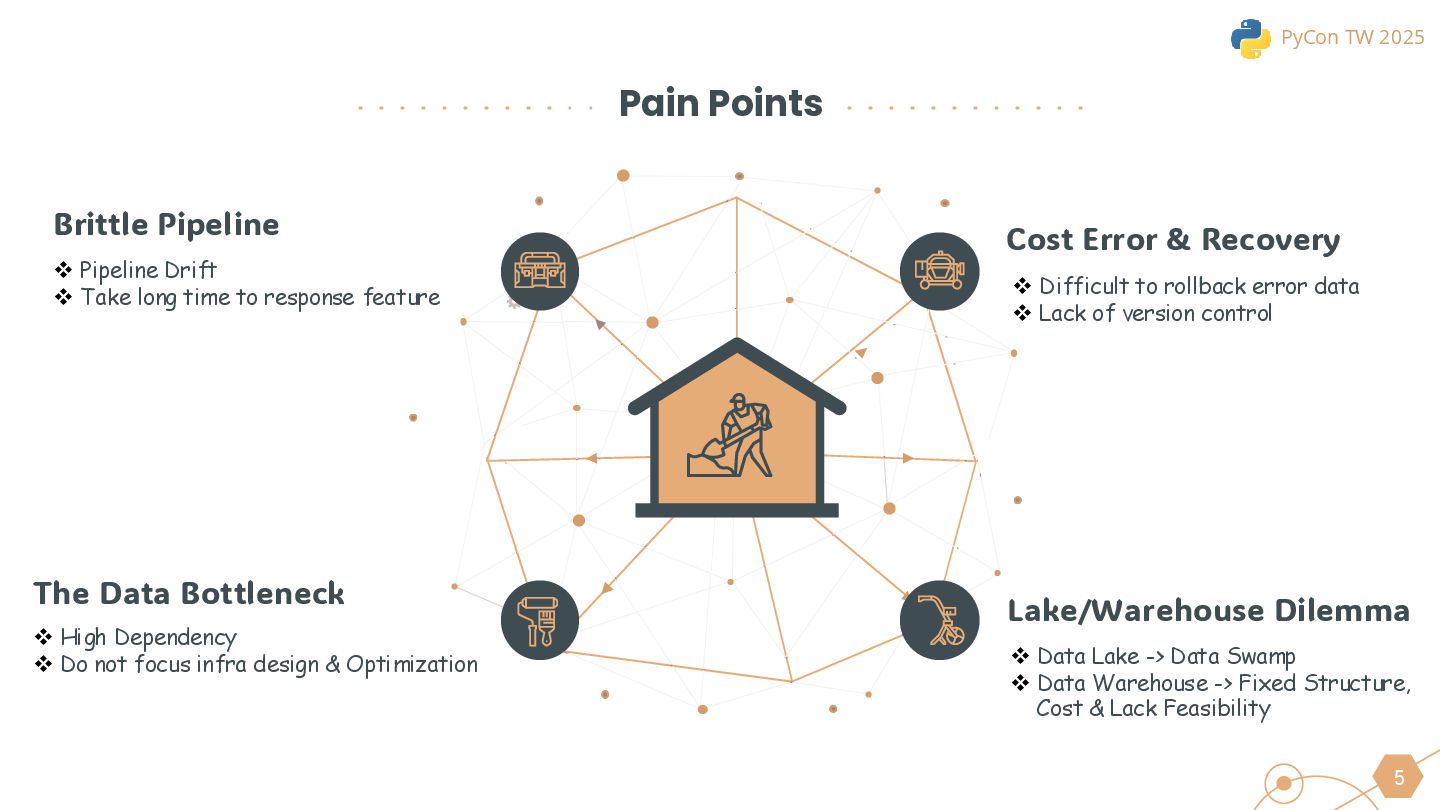
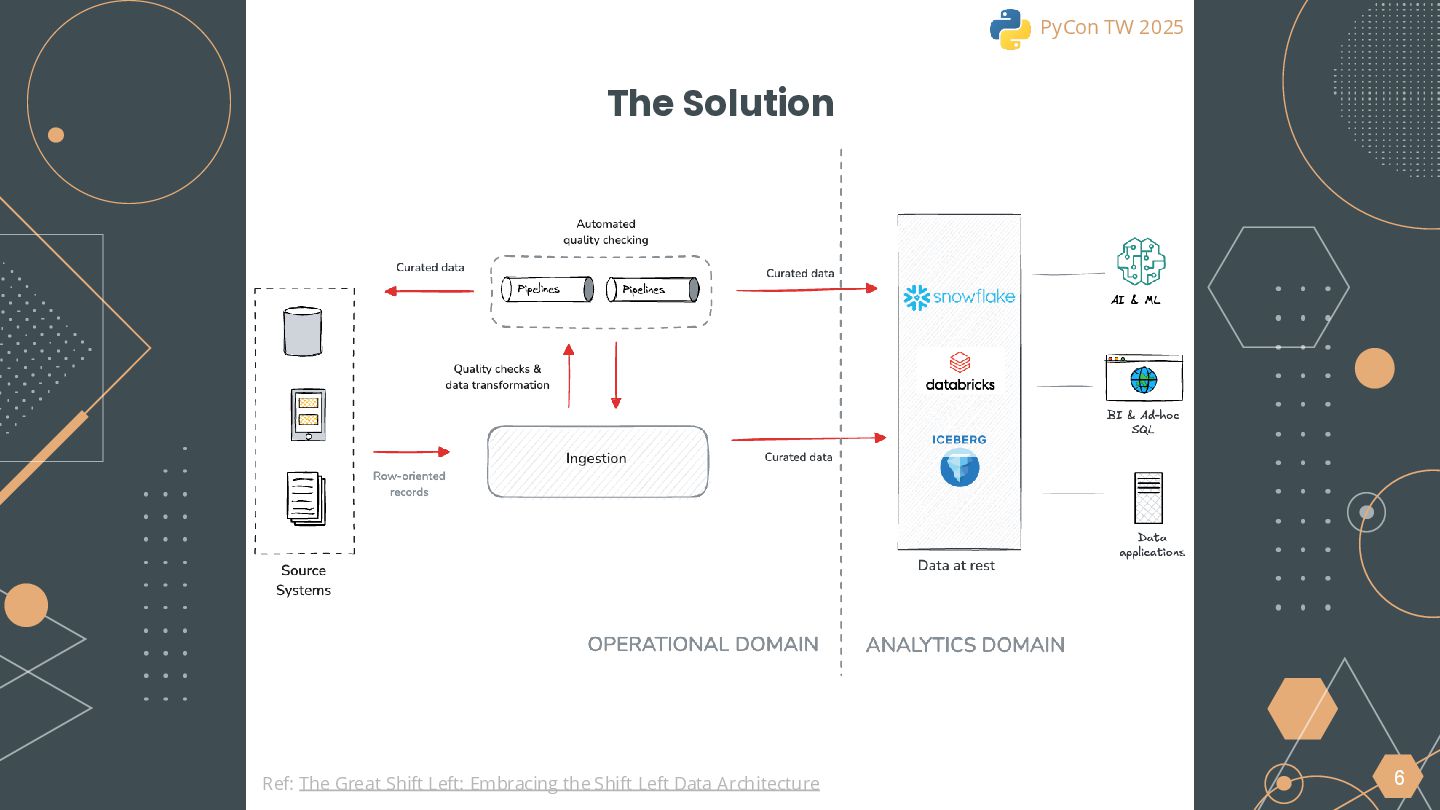
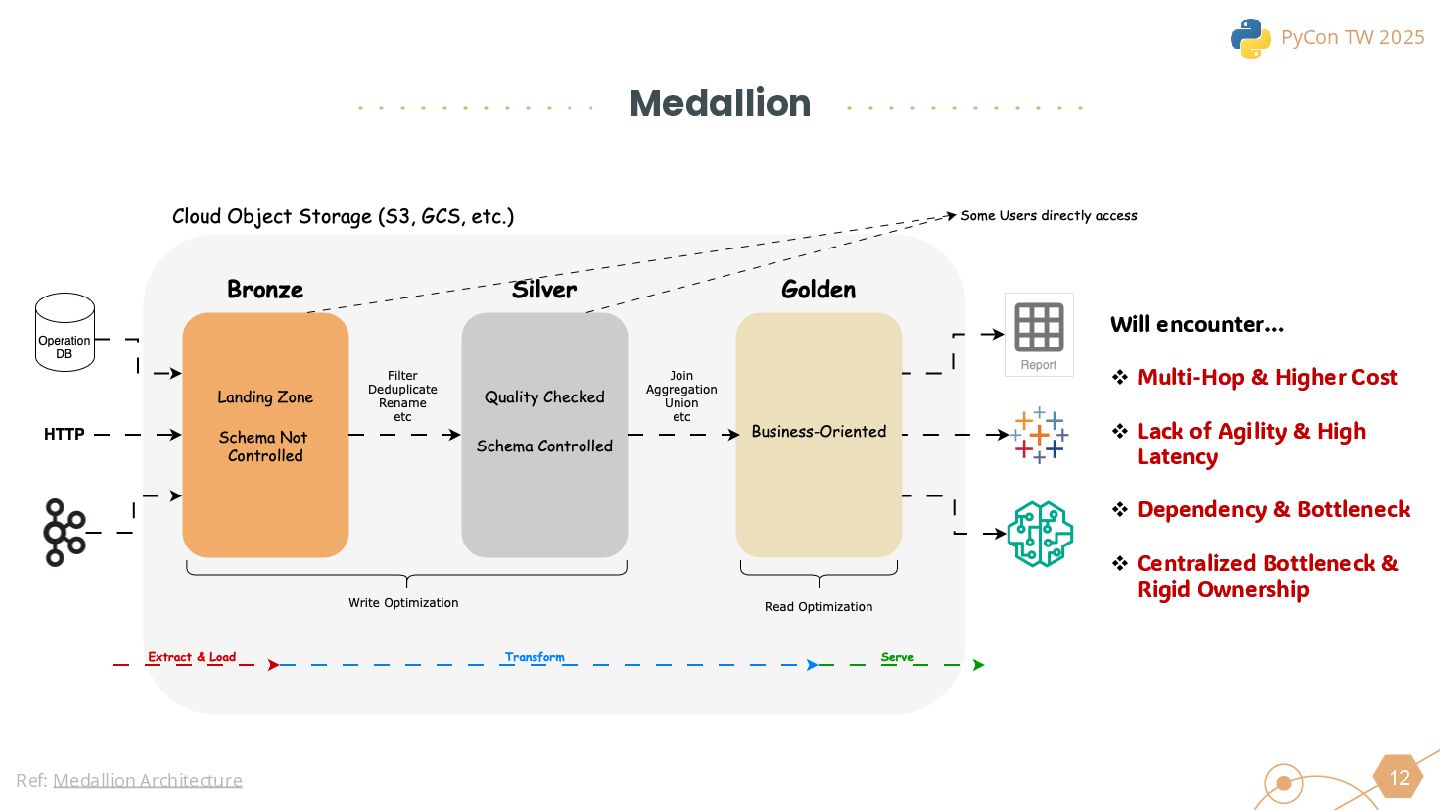
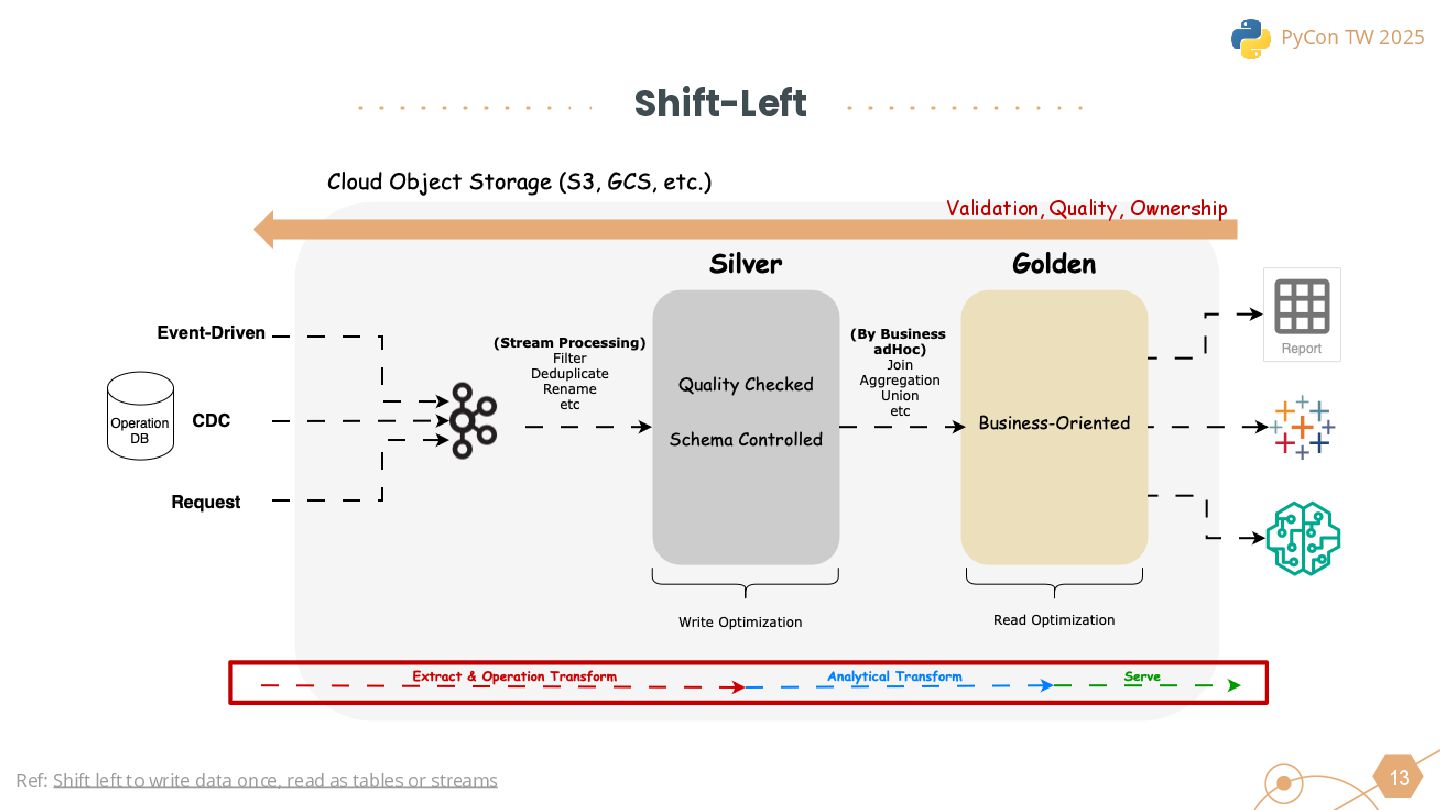
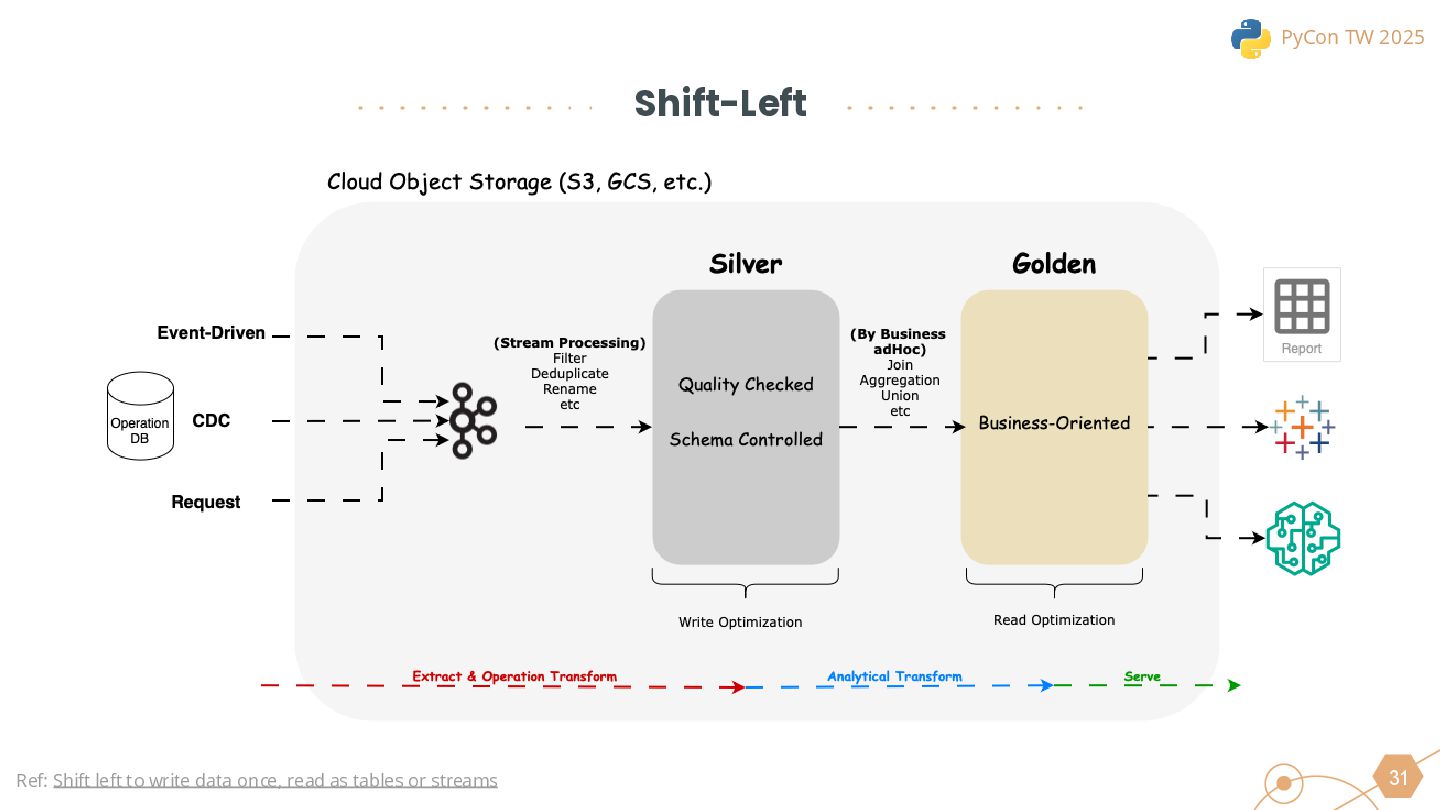
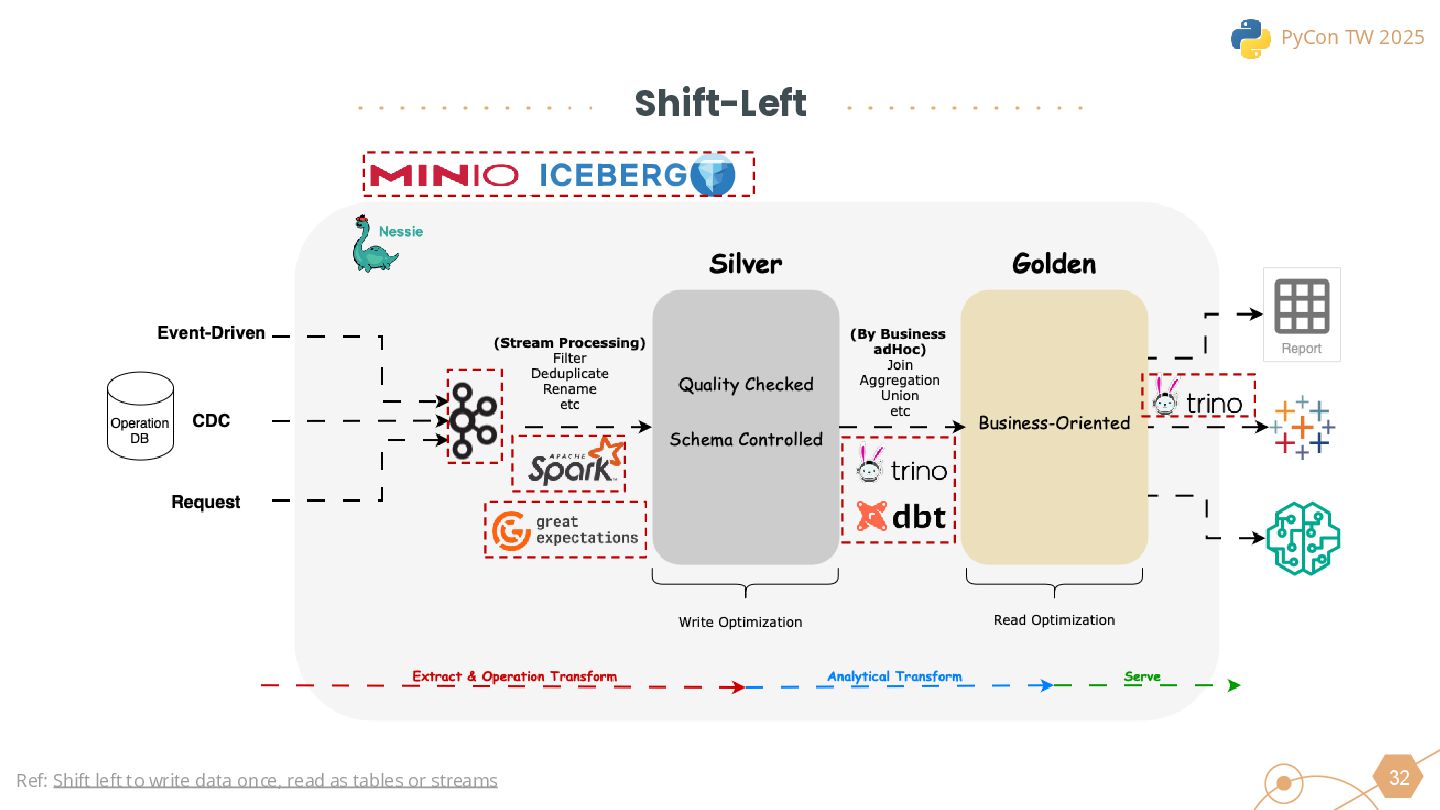
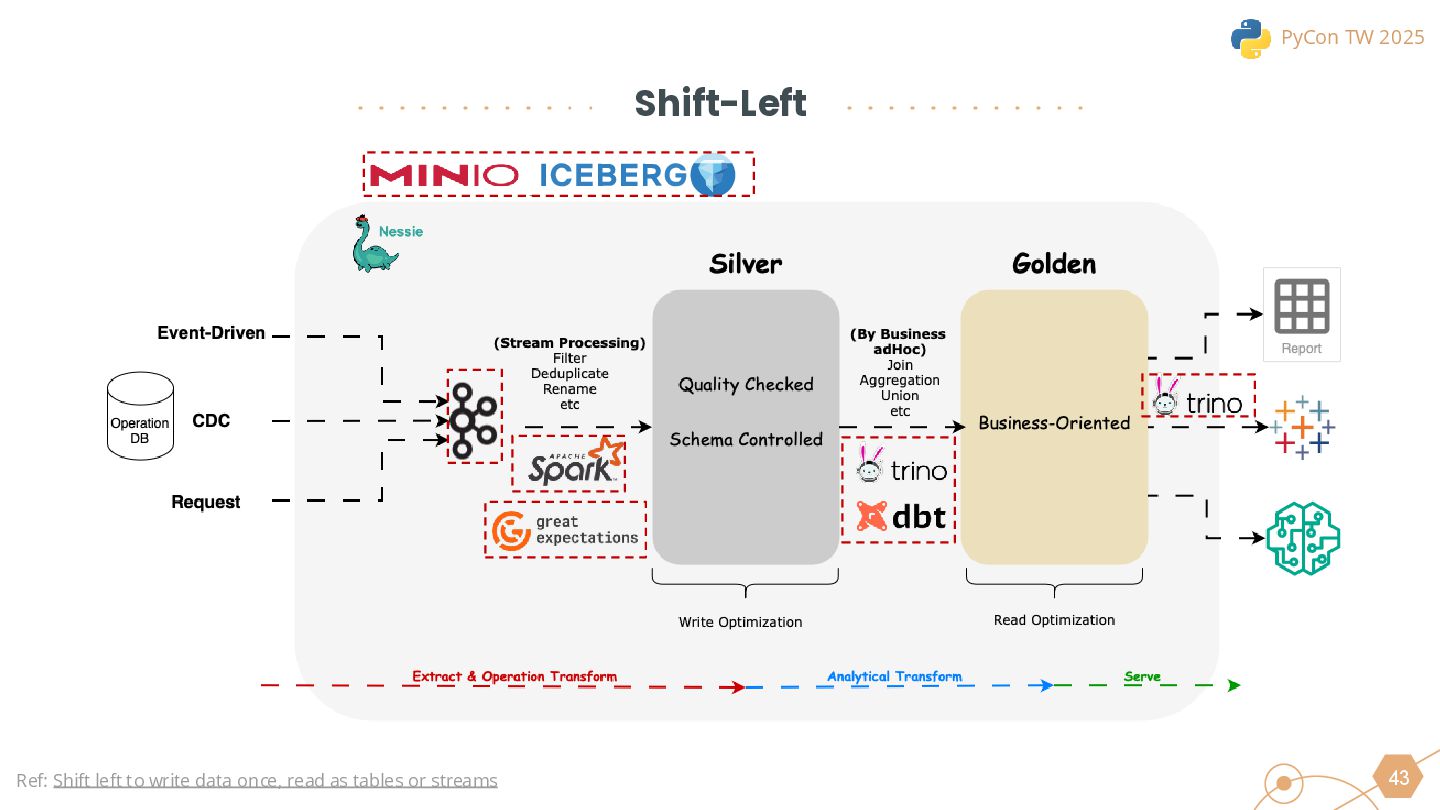
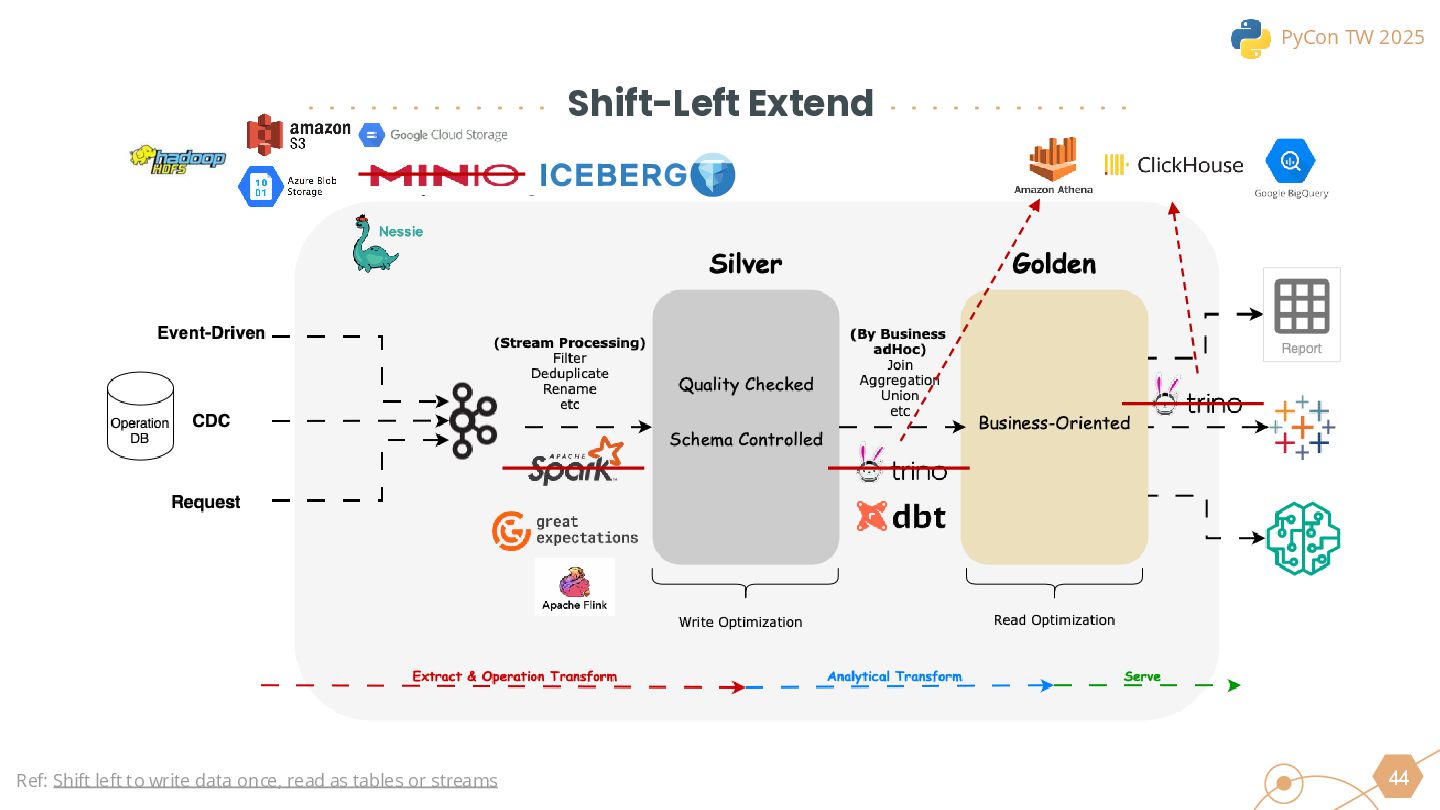
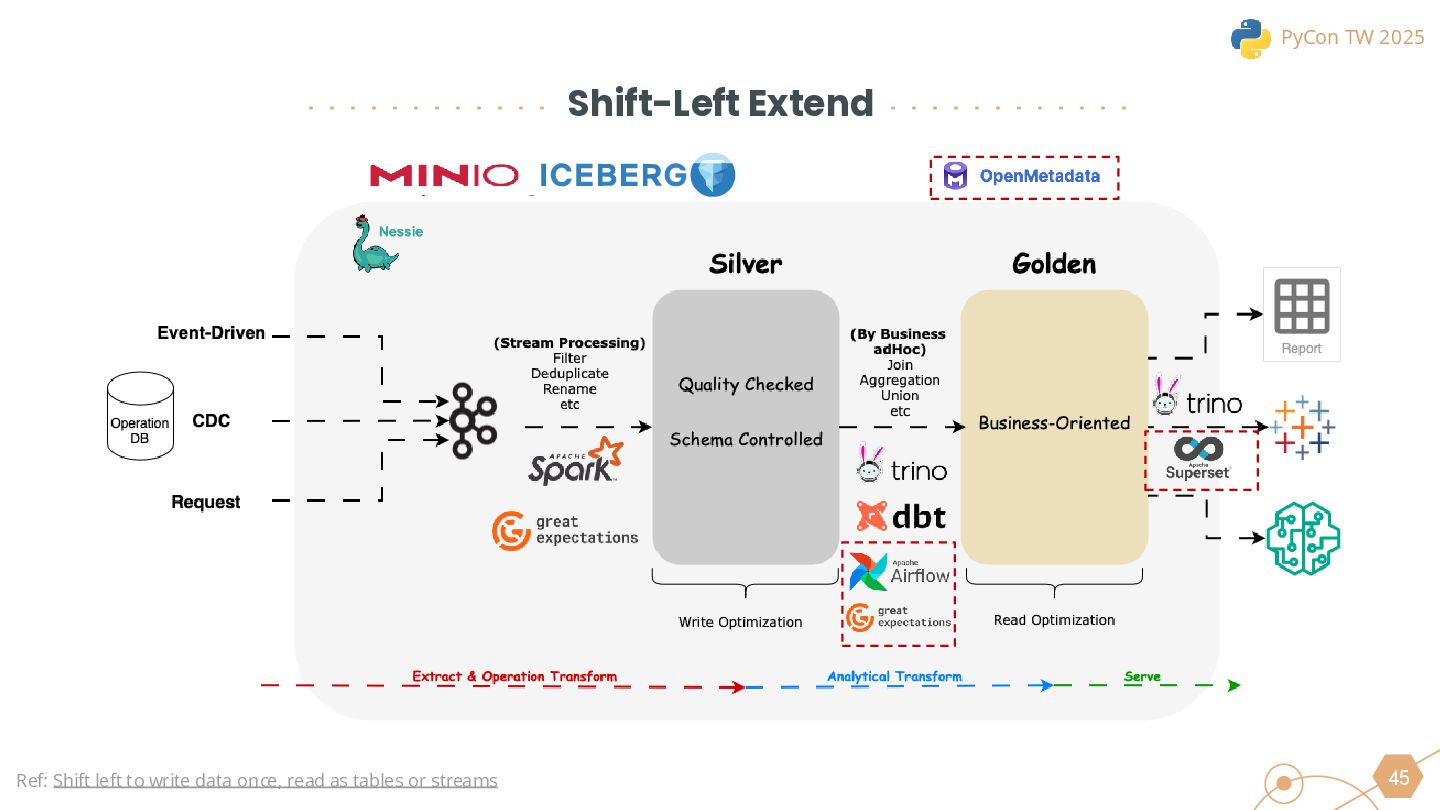
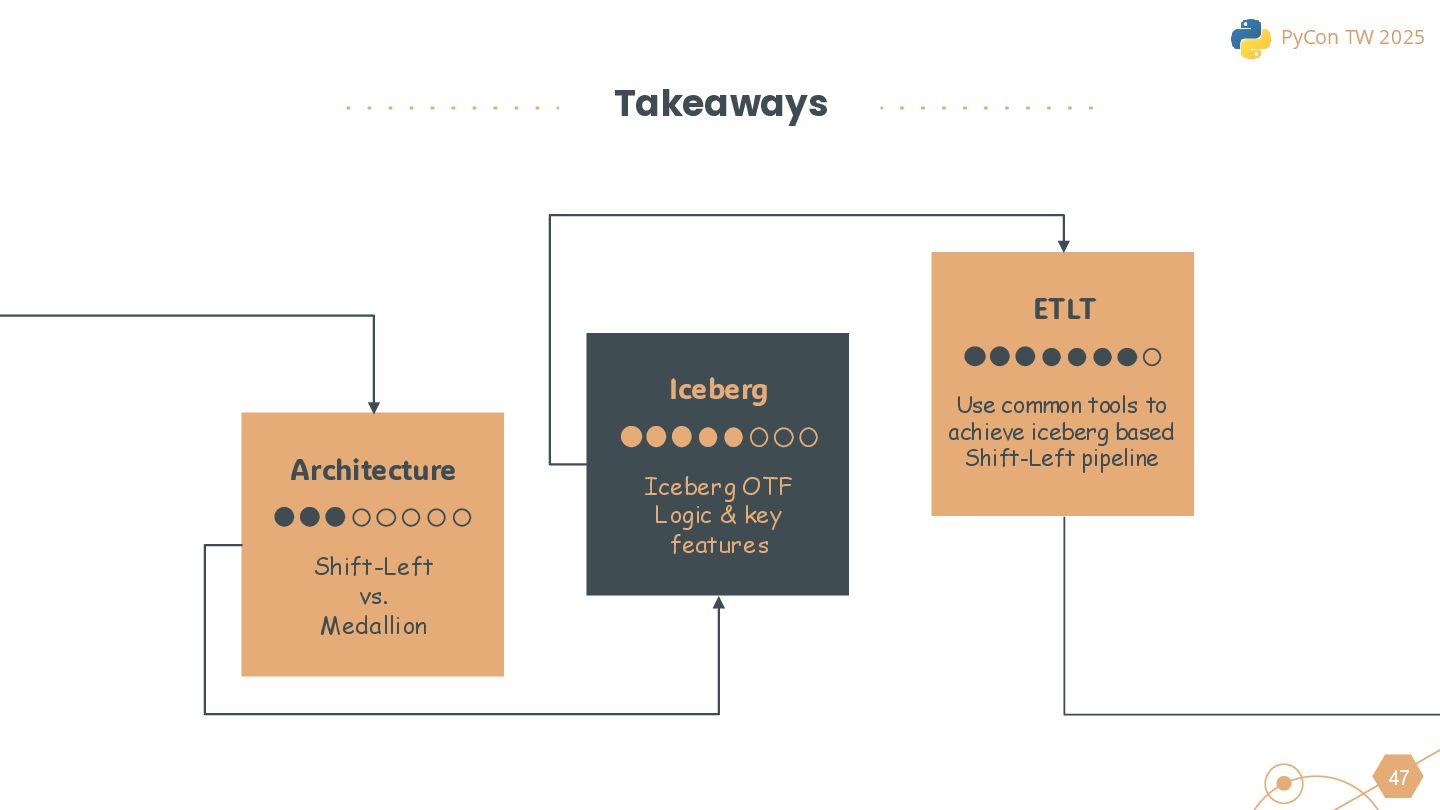
This session will begin by exploring why the industry is increasingly moving toward the lakehouse architecture, highlighting the core challenges it addresses in modern data processing. Using this as a foundation, we will introduce the ETLT pattern and compare two architectural approaches: the Shift-Left Architecture and the Medallion Architecture, outlining their key differences and applicable scenarios.
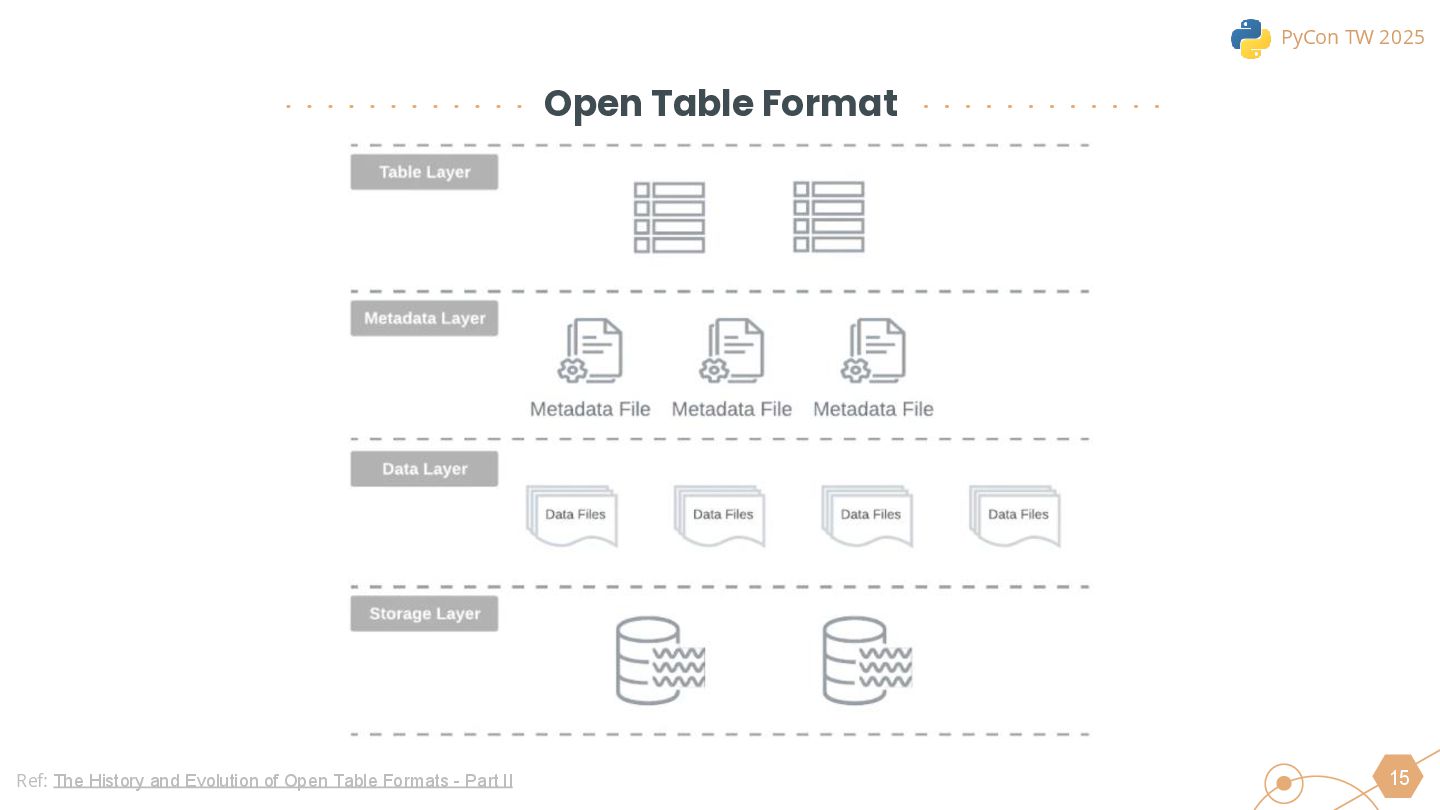
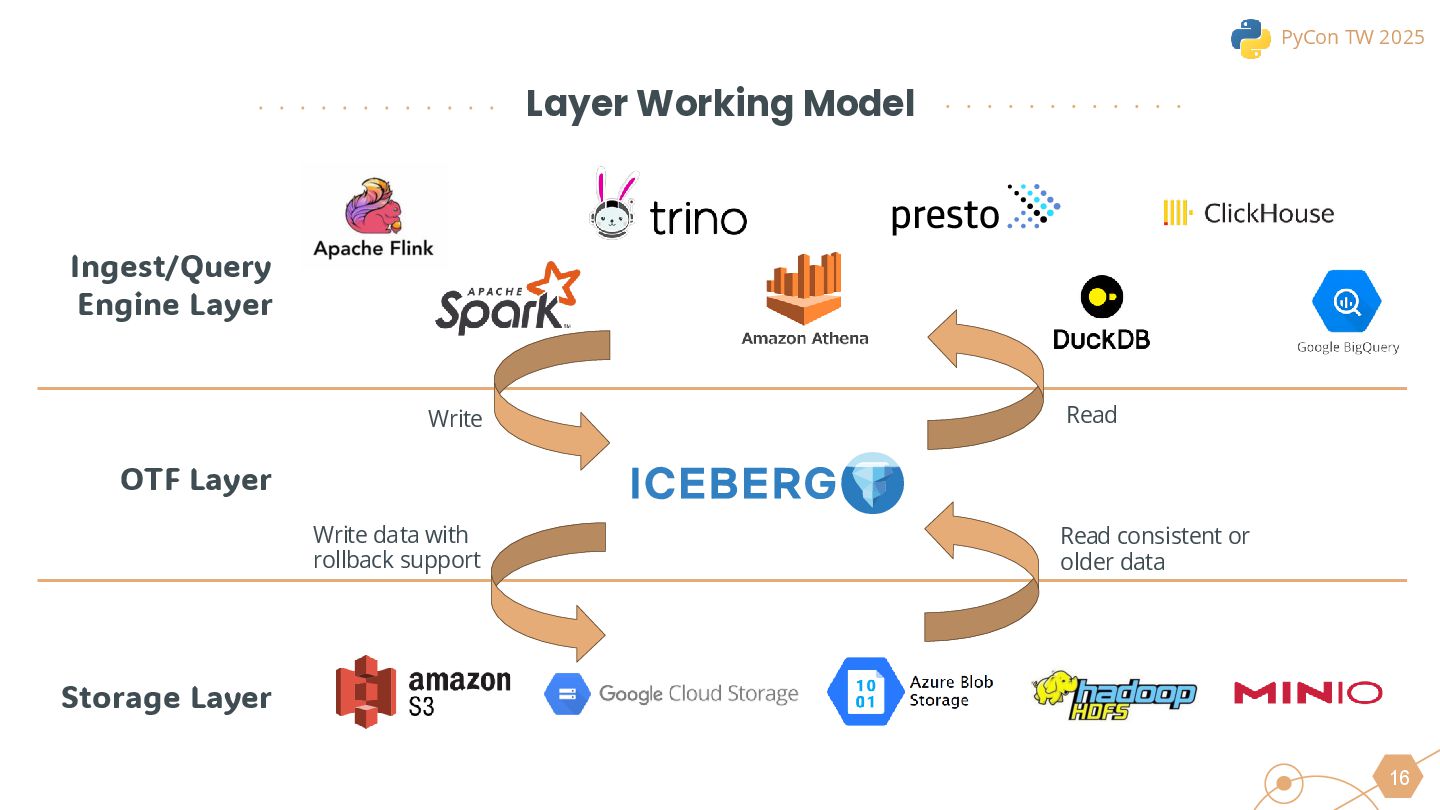
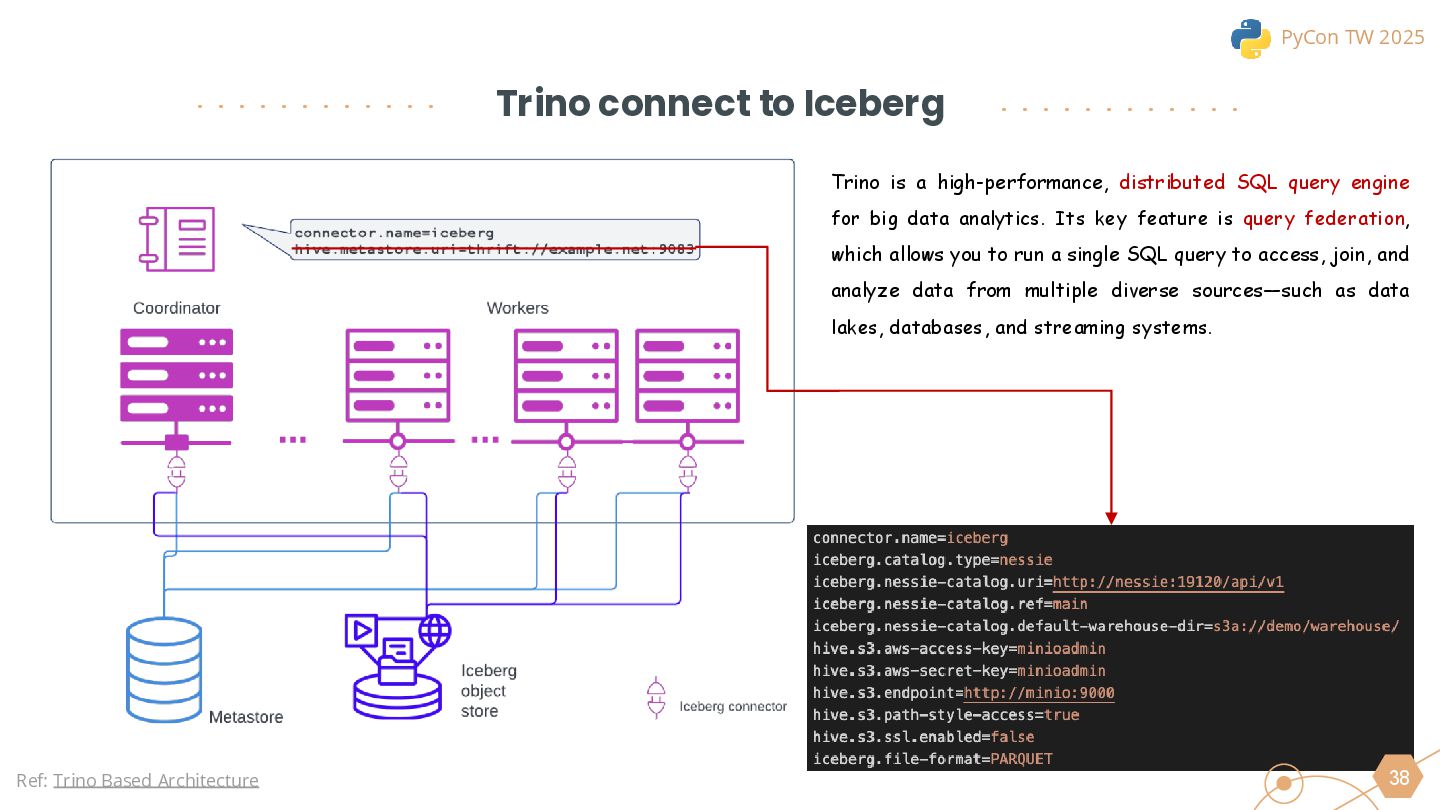
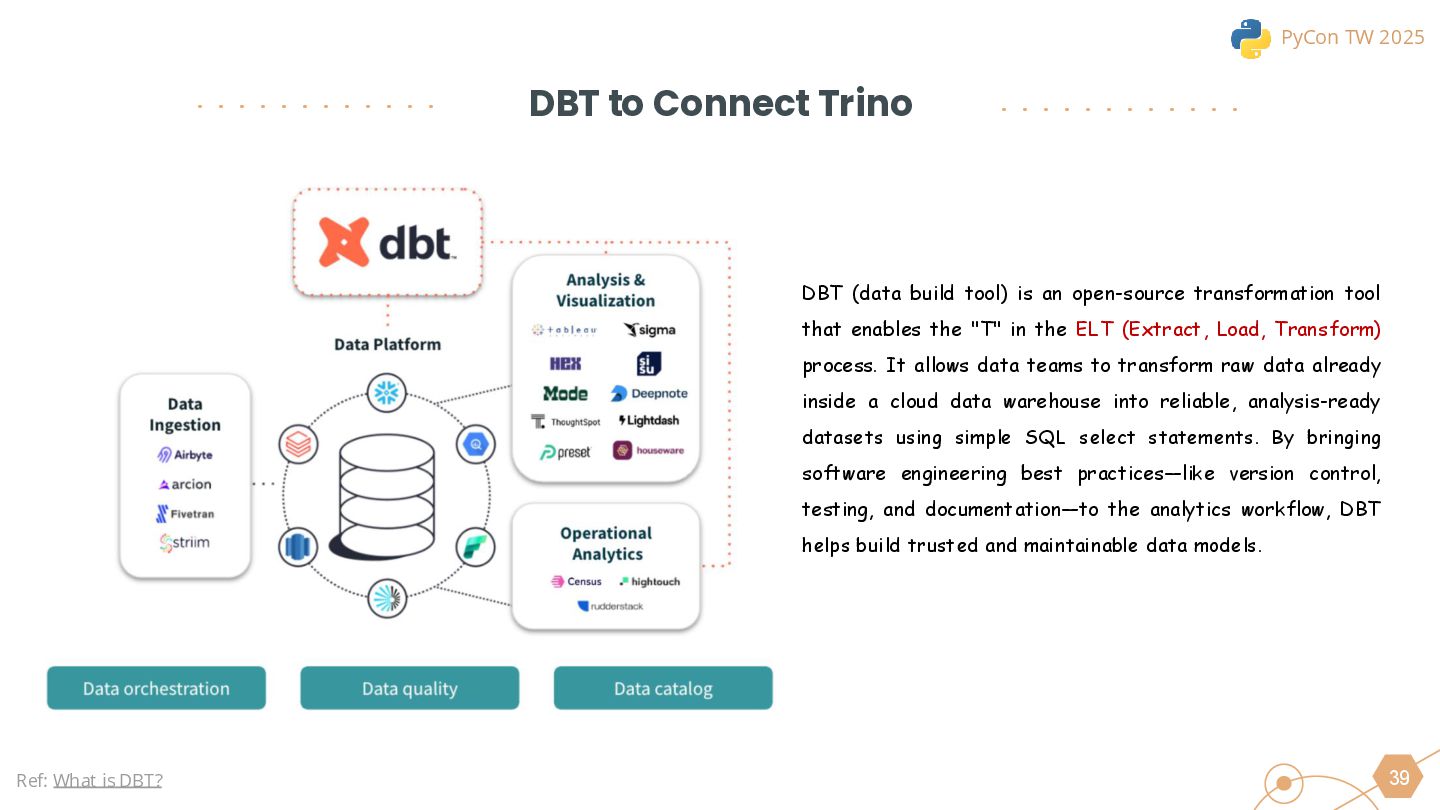
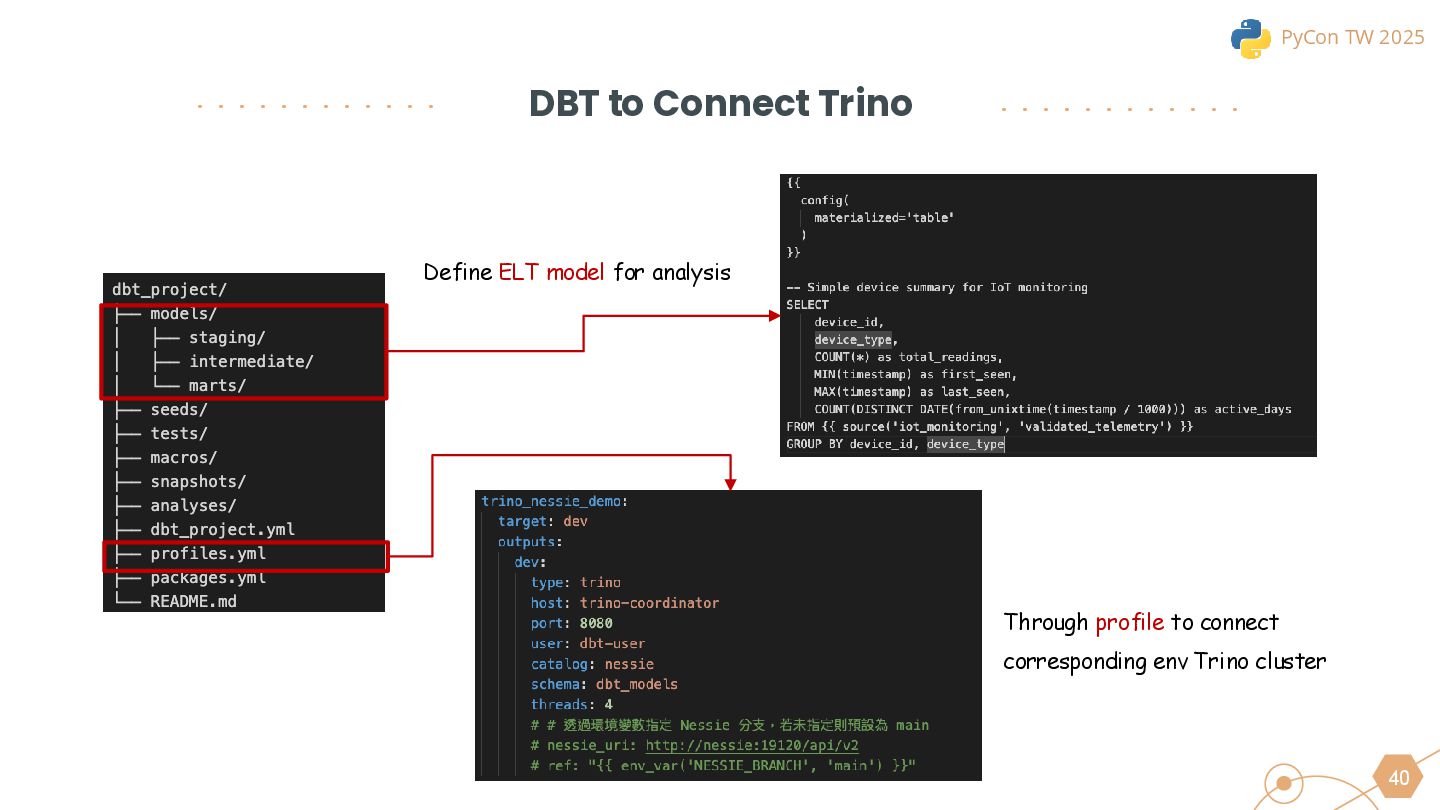
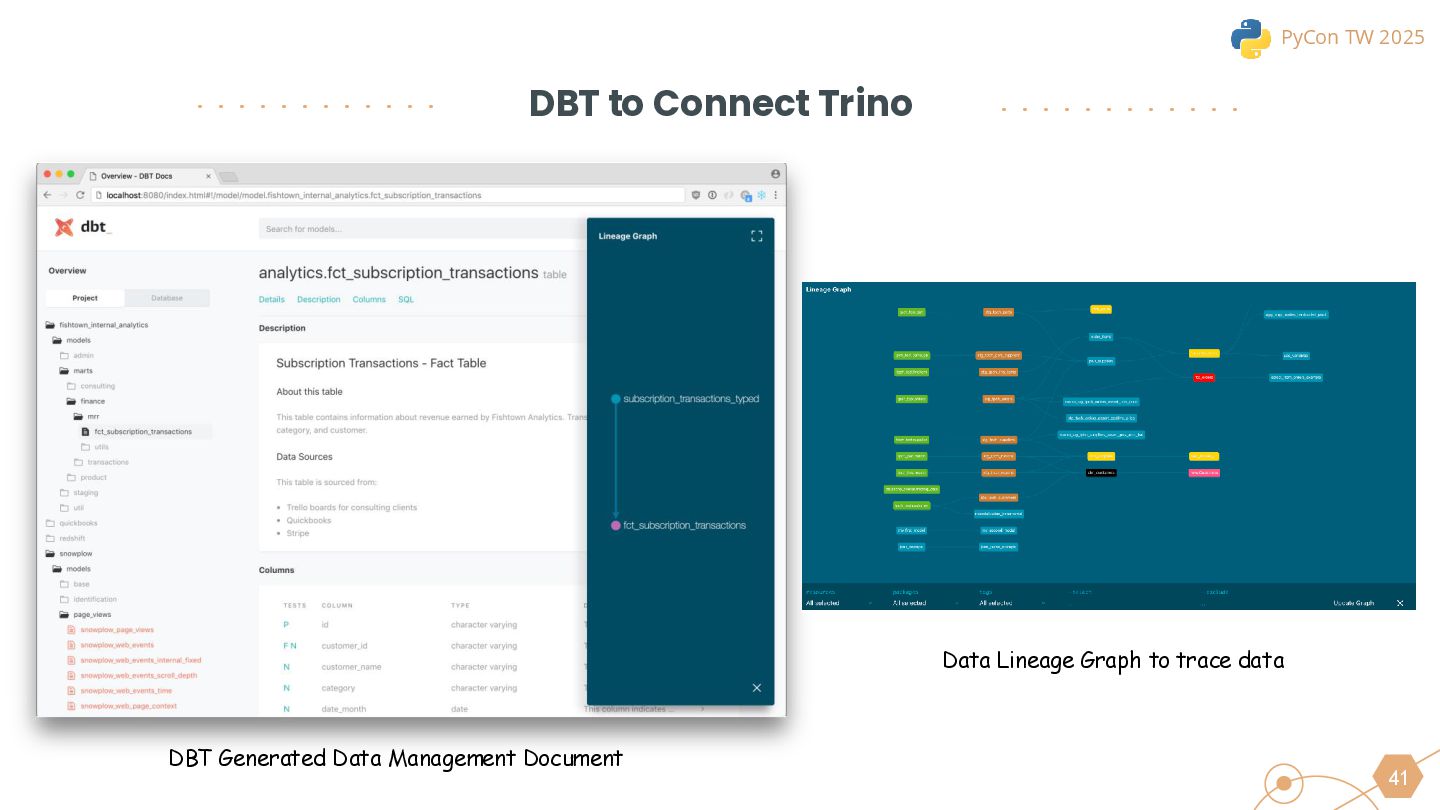
We will also cover the essential technologies used throughout the data pipeline, including Kafka, PySpark, Trino, and DBT for Left-Shit Architecture. For Python developers, we’ll demonstrate how to efficiently read and interact with Iceberg-formatted data, showcasing code snippets and configuration examples to provide practical guidance.
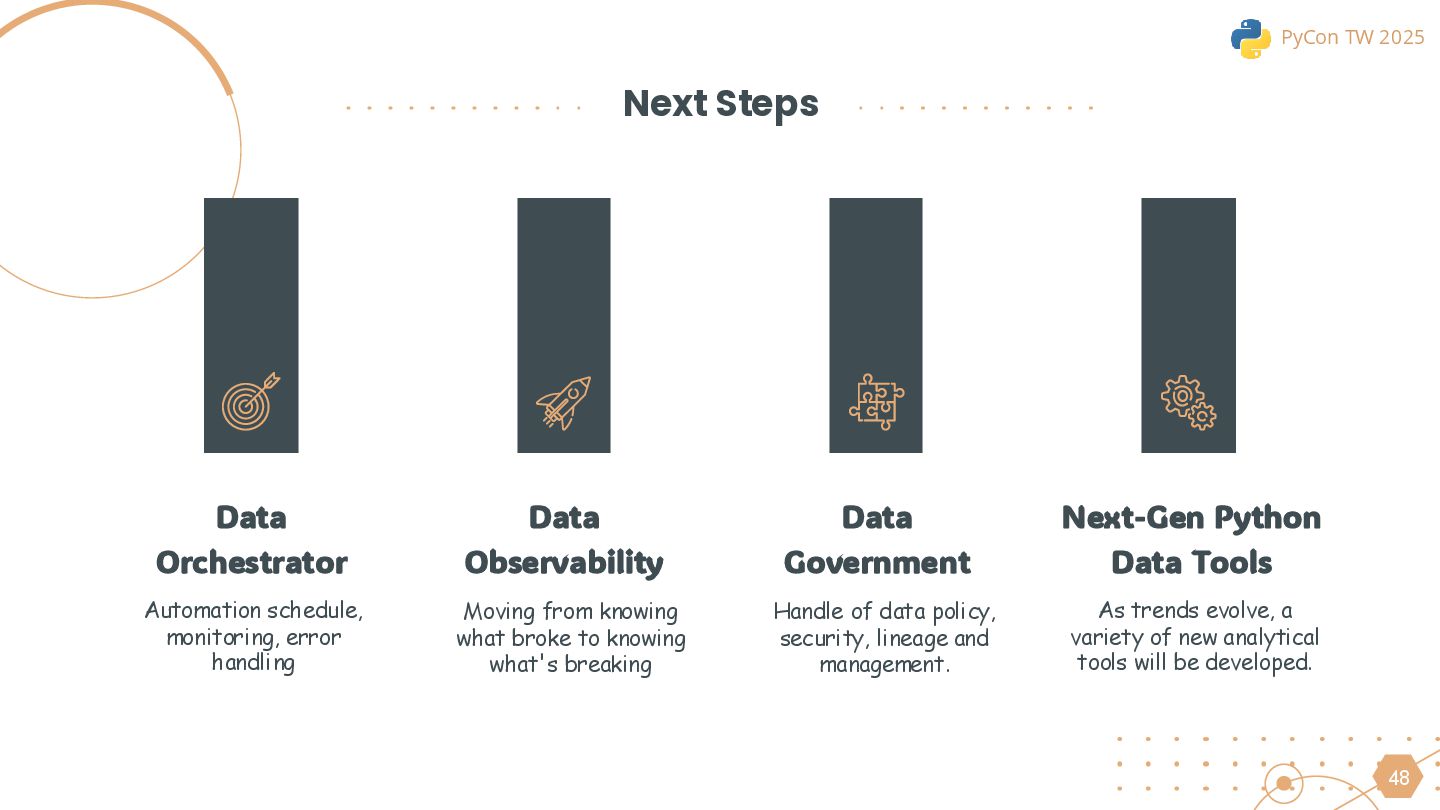
The talk will conclude with real-world best practices to help data professionals evaluate whether this architecture fits their use cases and how it can be leveraged to improve existing data workflows.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
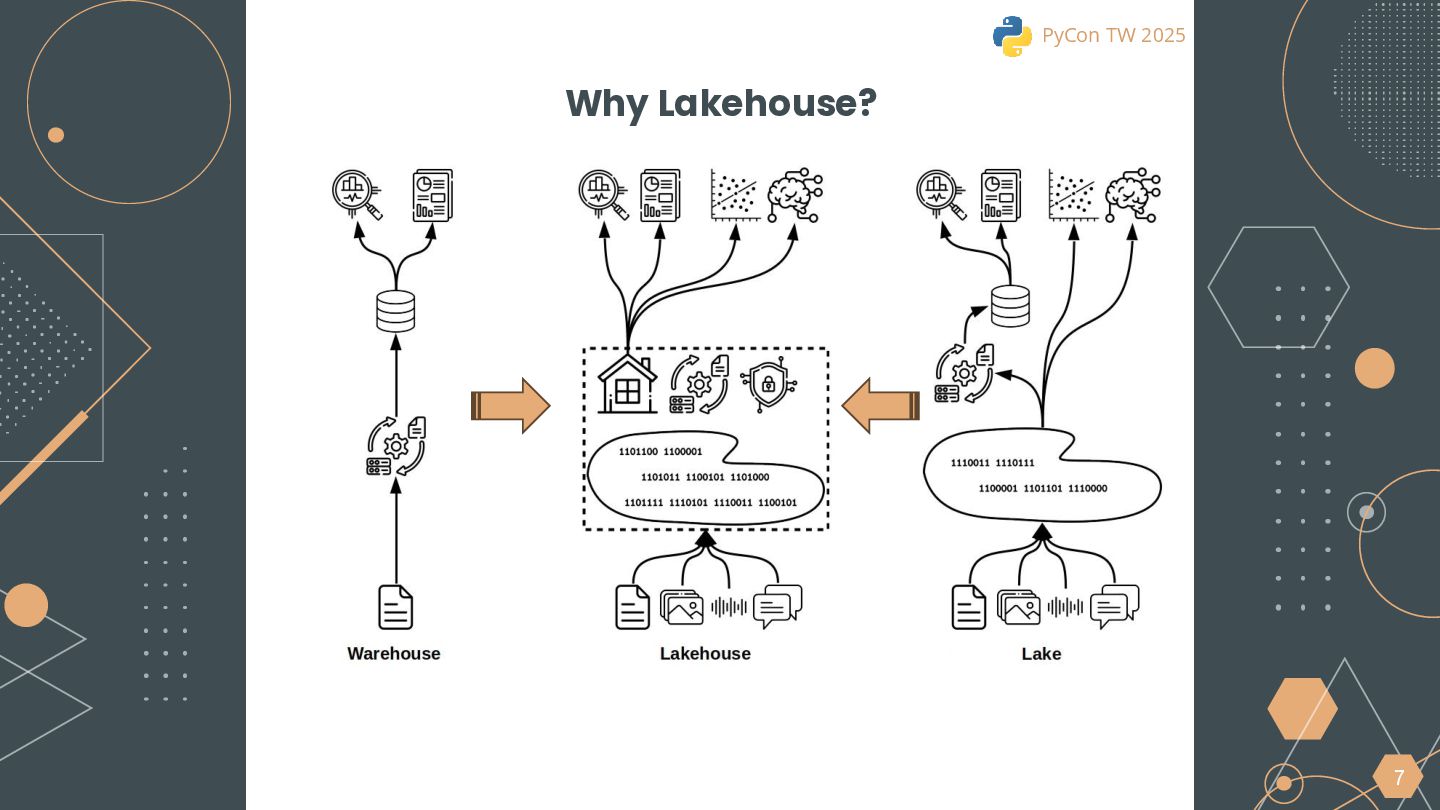{kind=link}
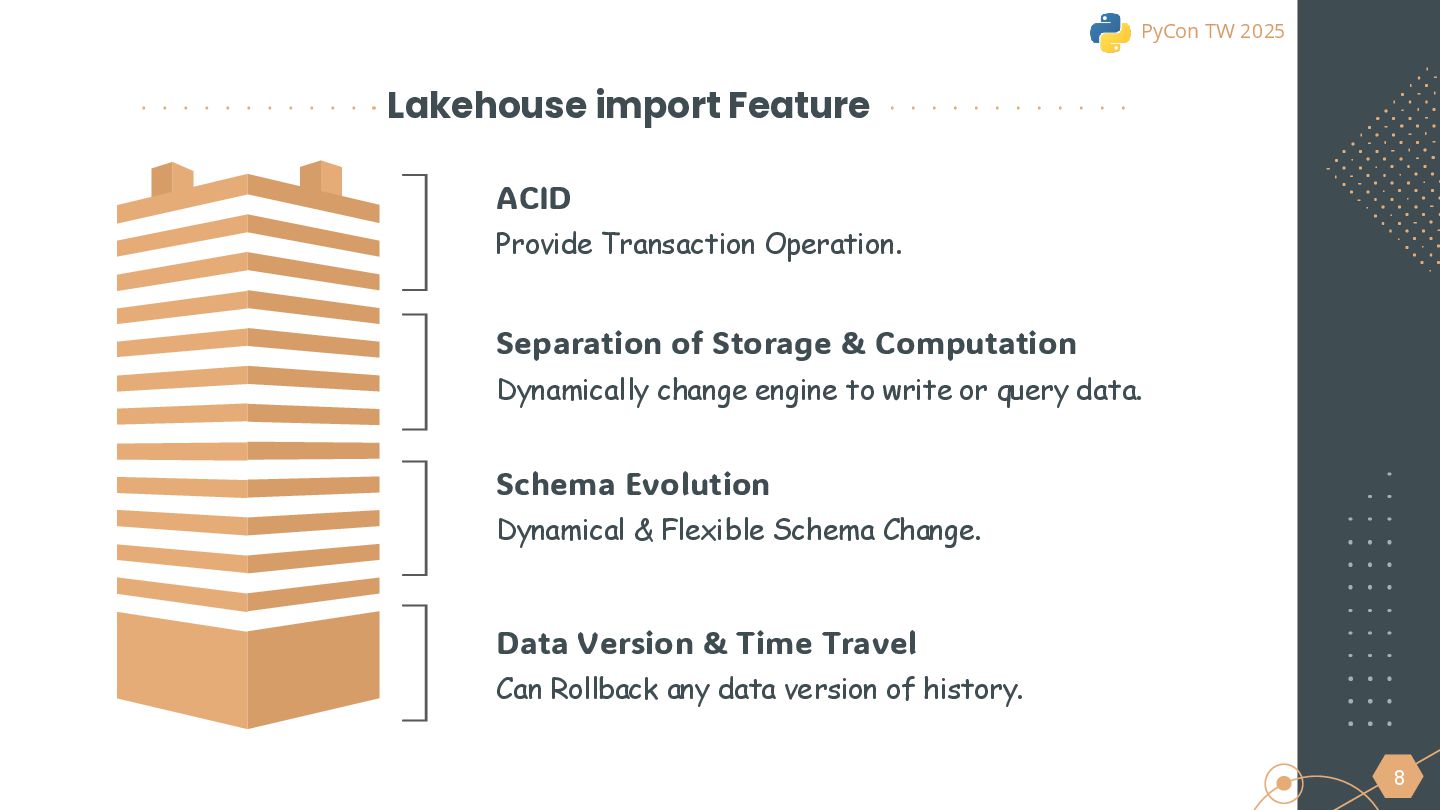{kind=link}
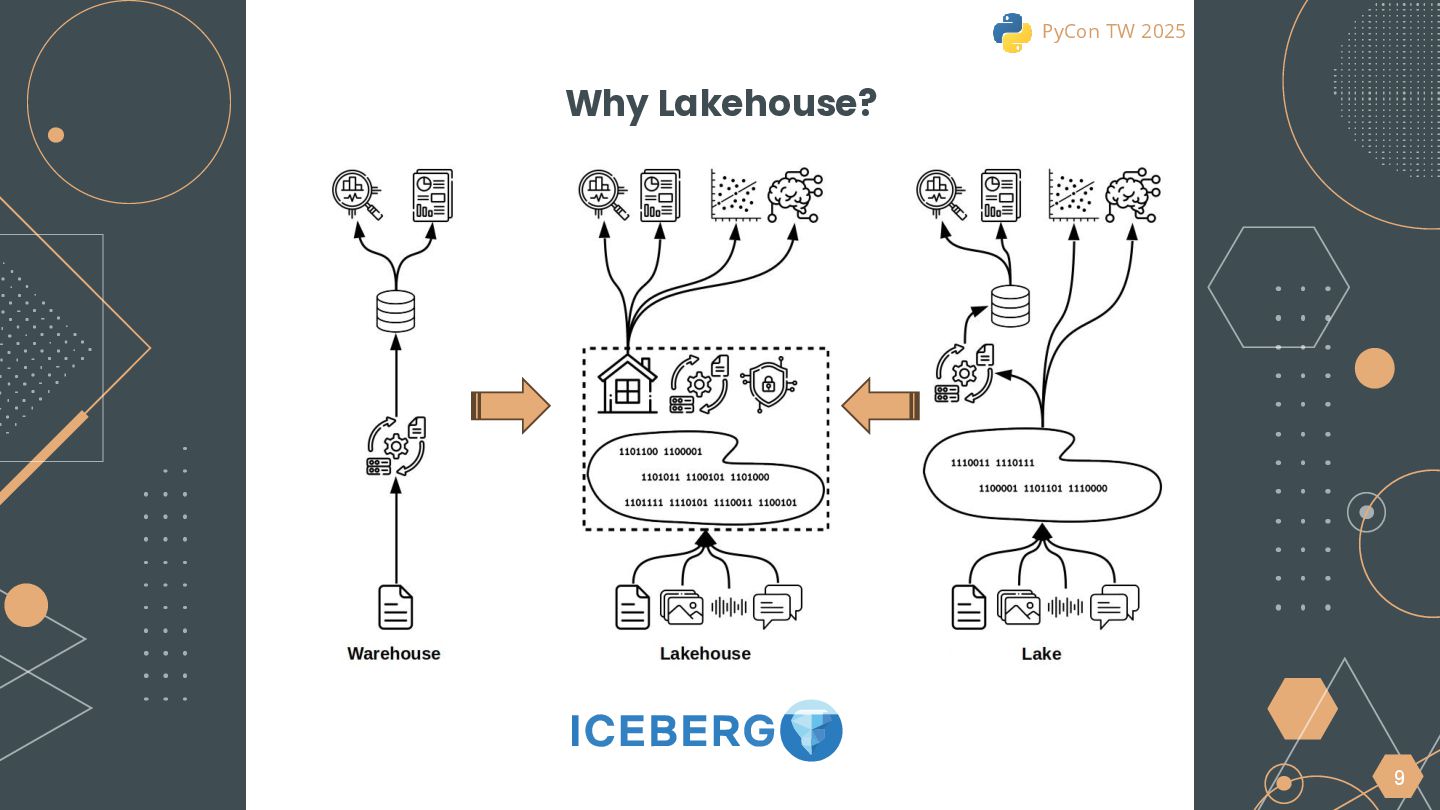{kind=link}
{kind=link}
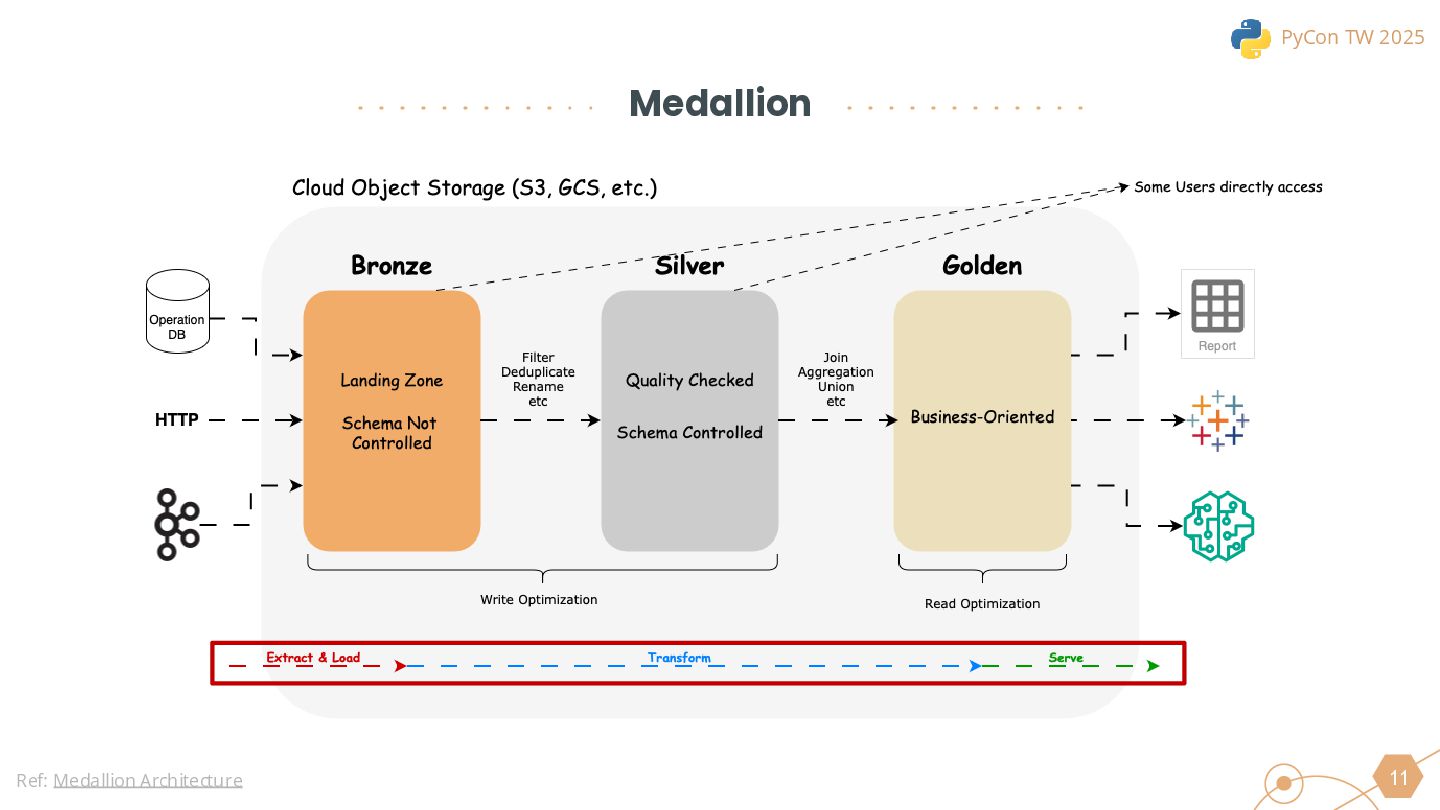{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
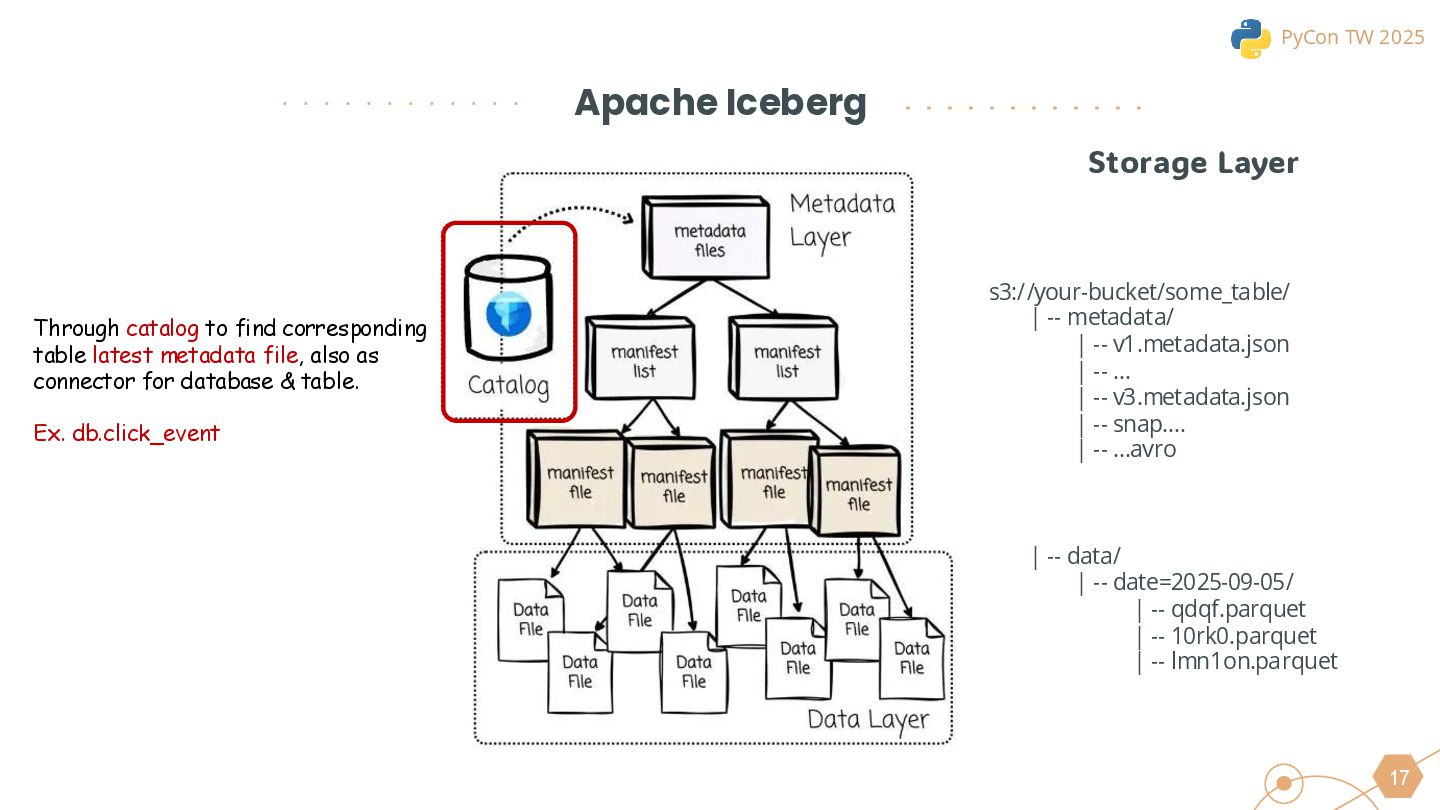{kind=link}
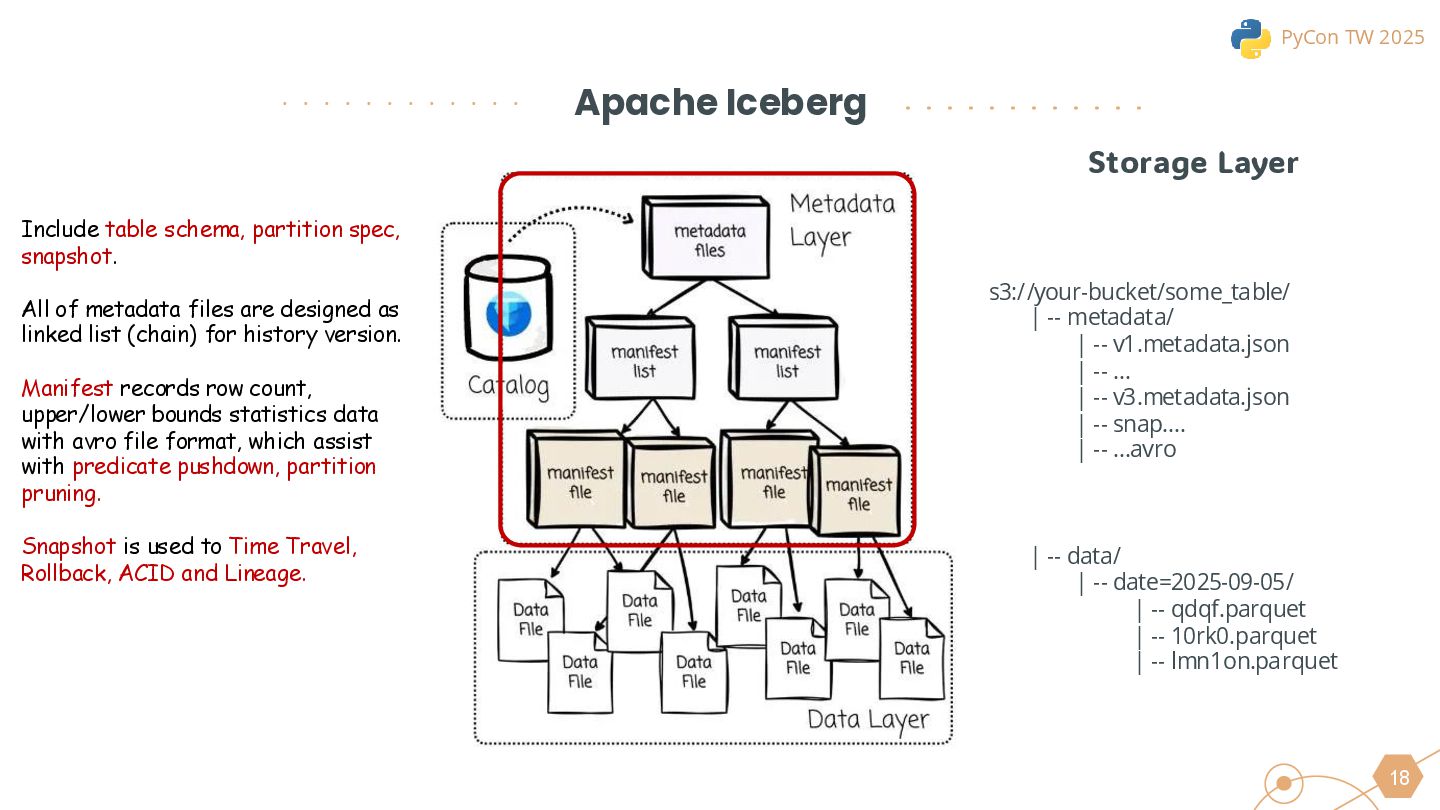{kind=link}
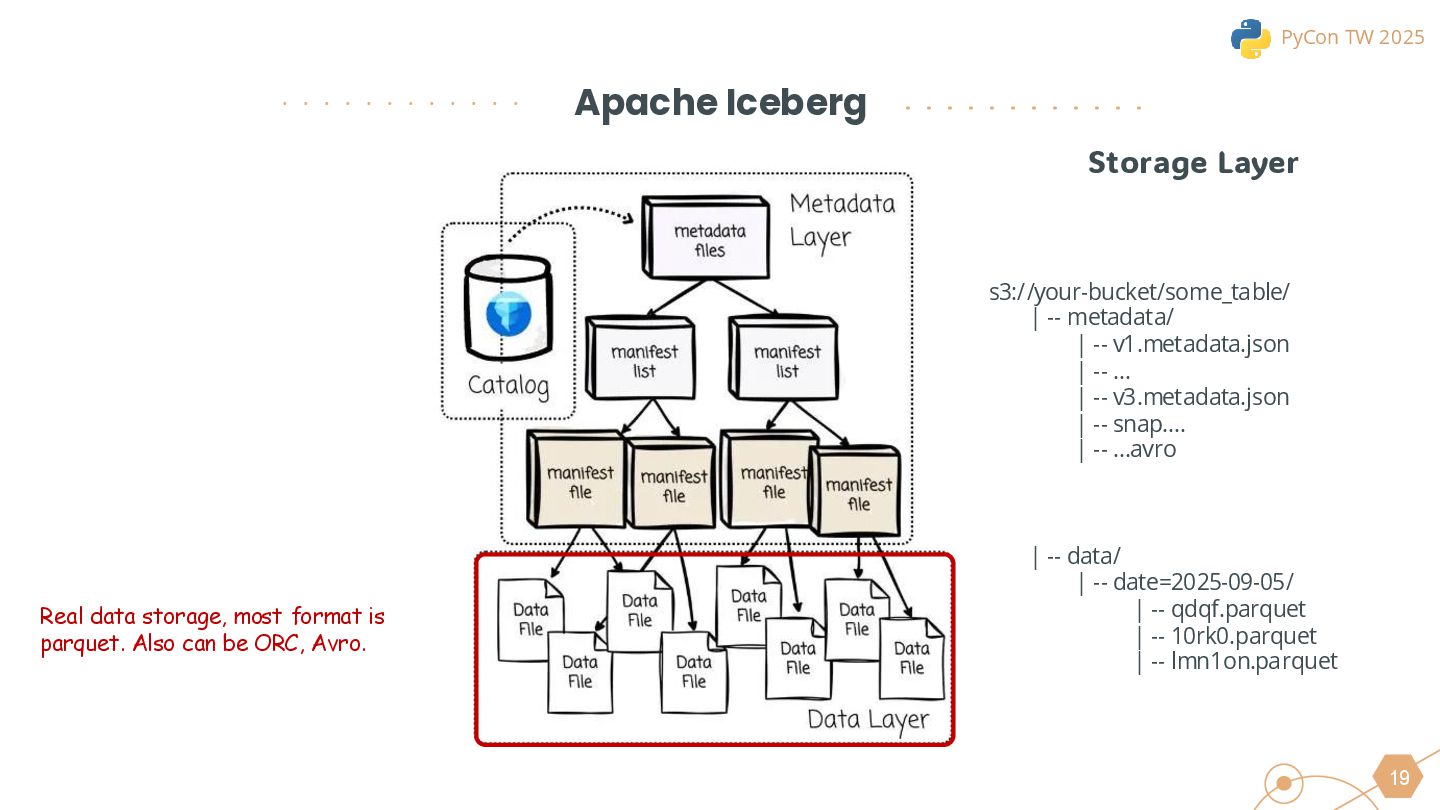{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
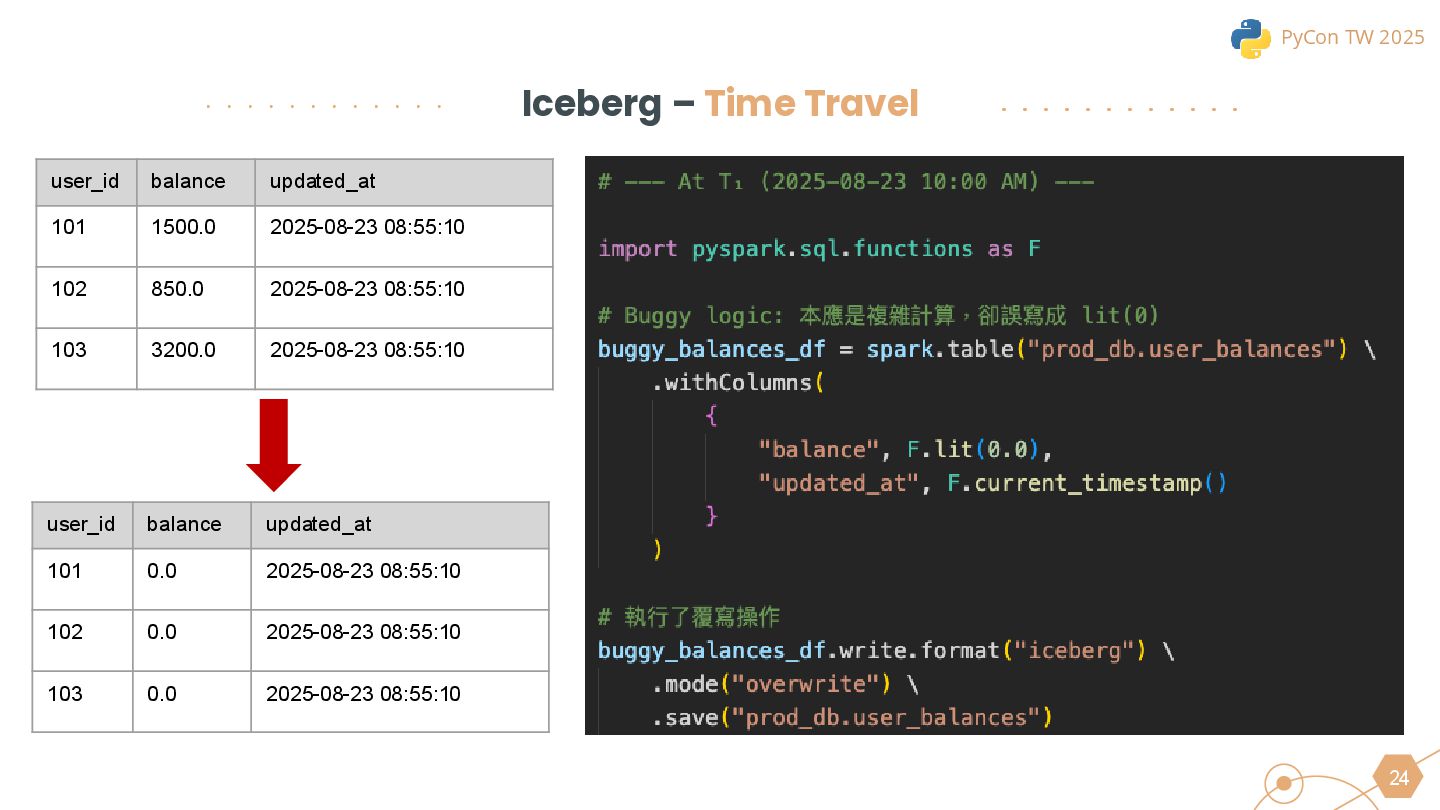{kind=link}
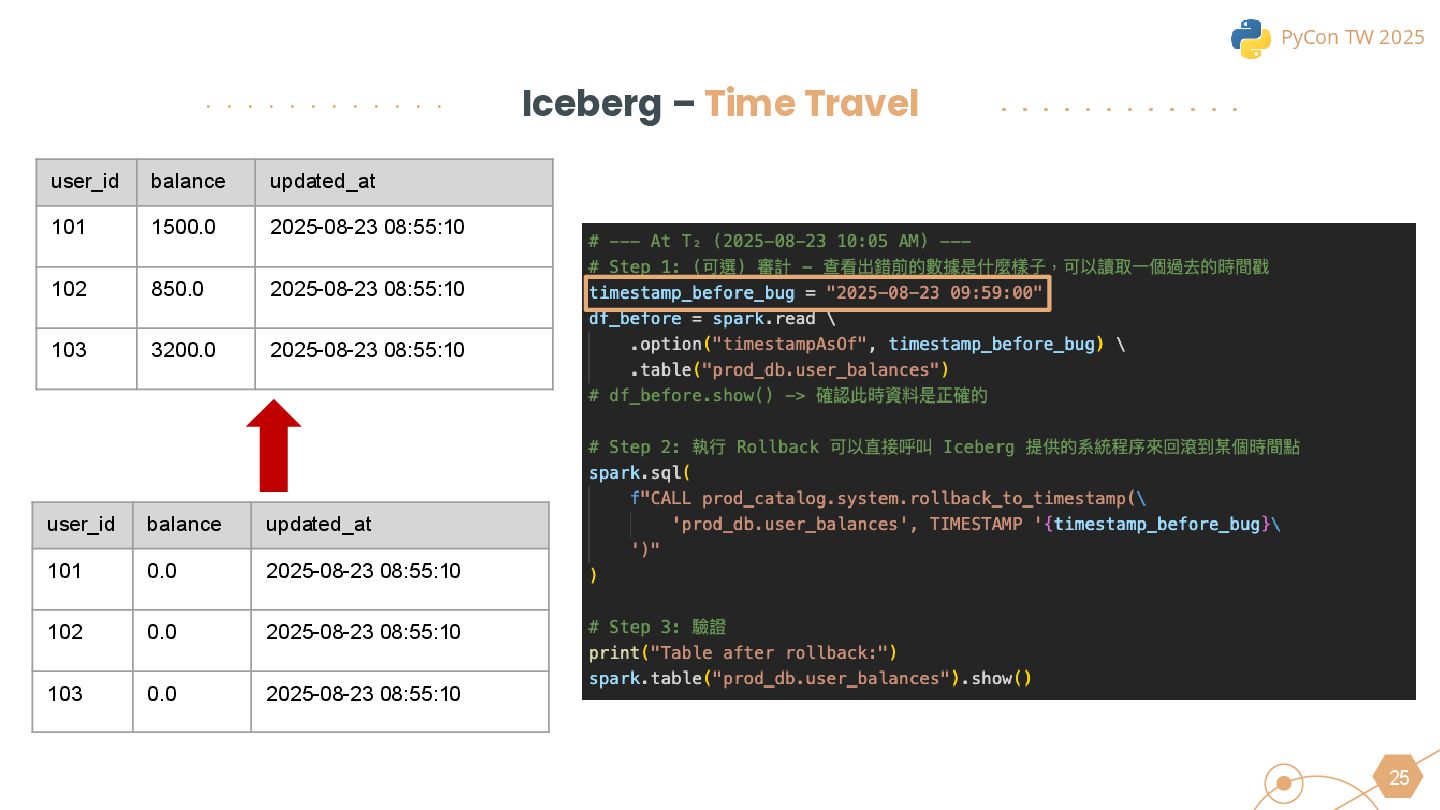{kind=link}
{kind=link}
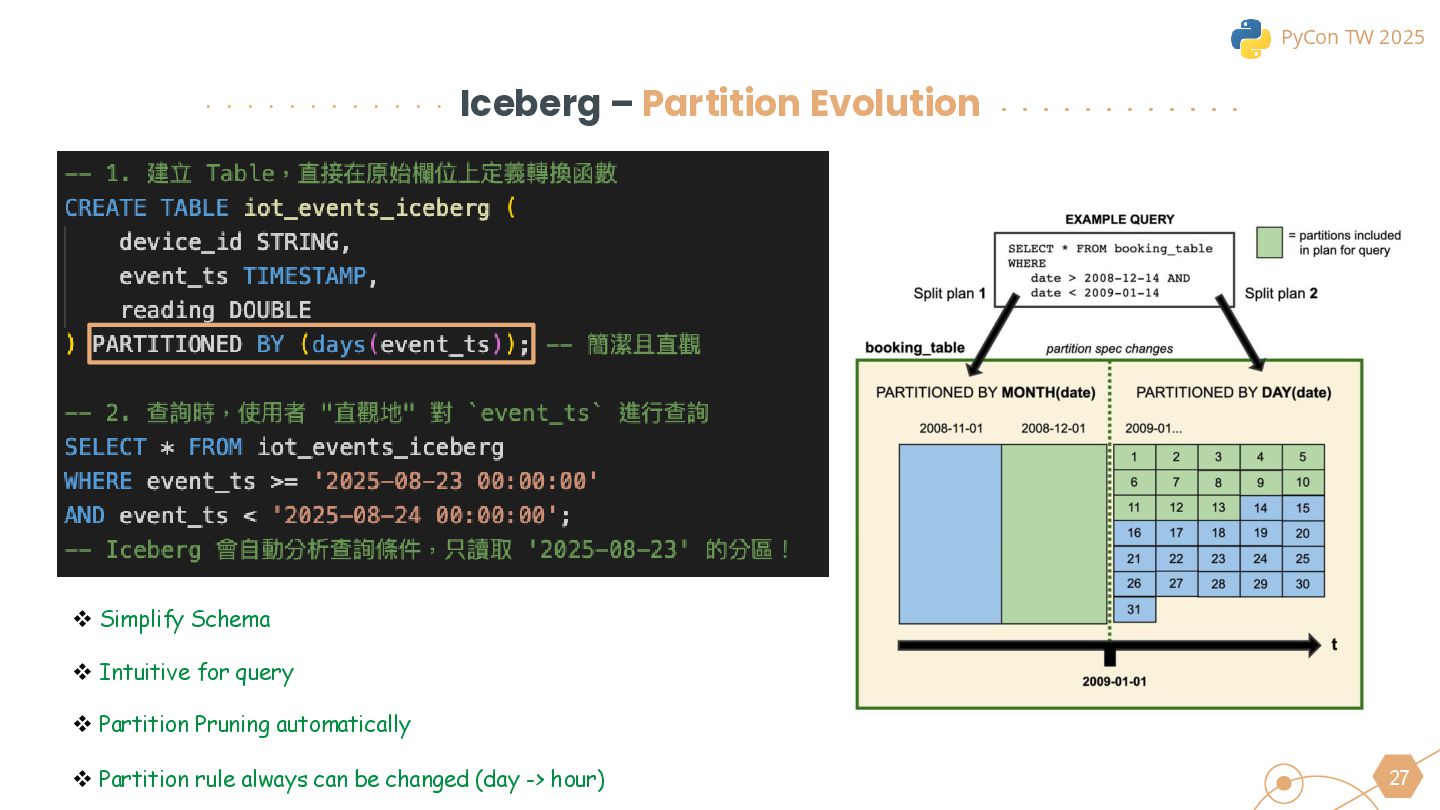{kind=link}
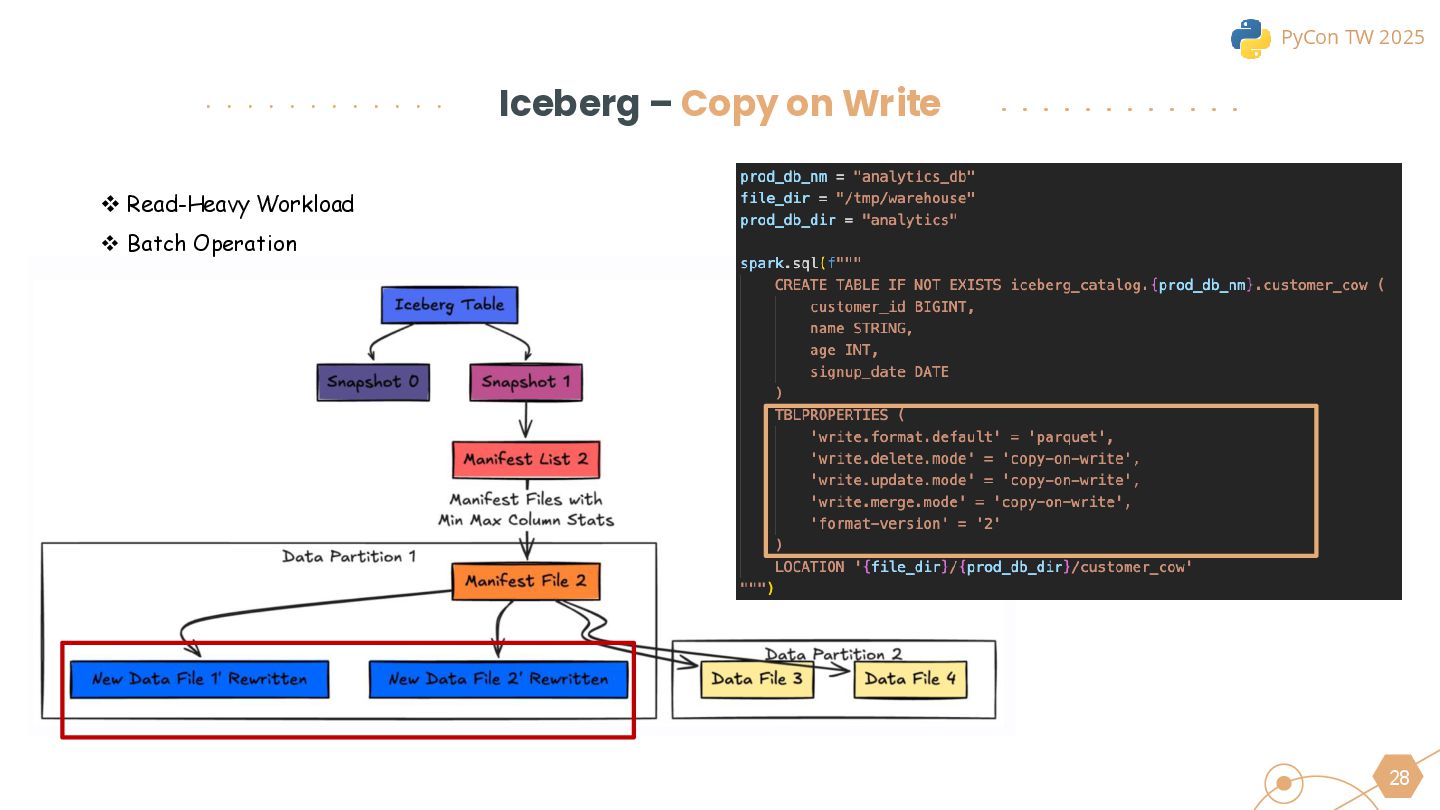{kind=link}
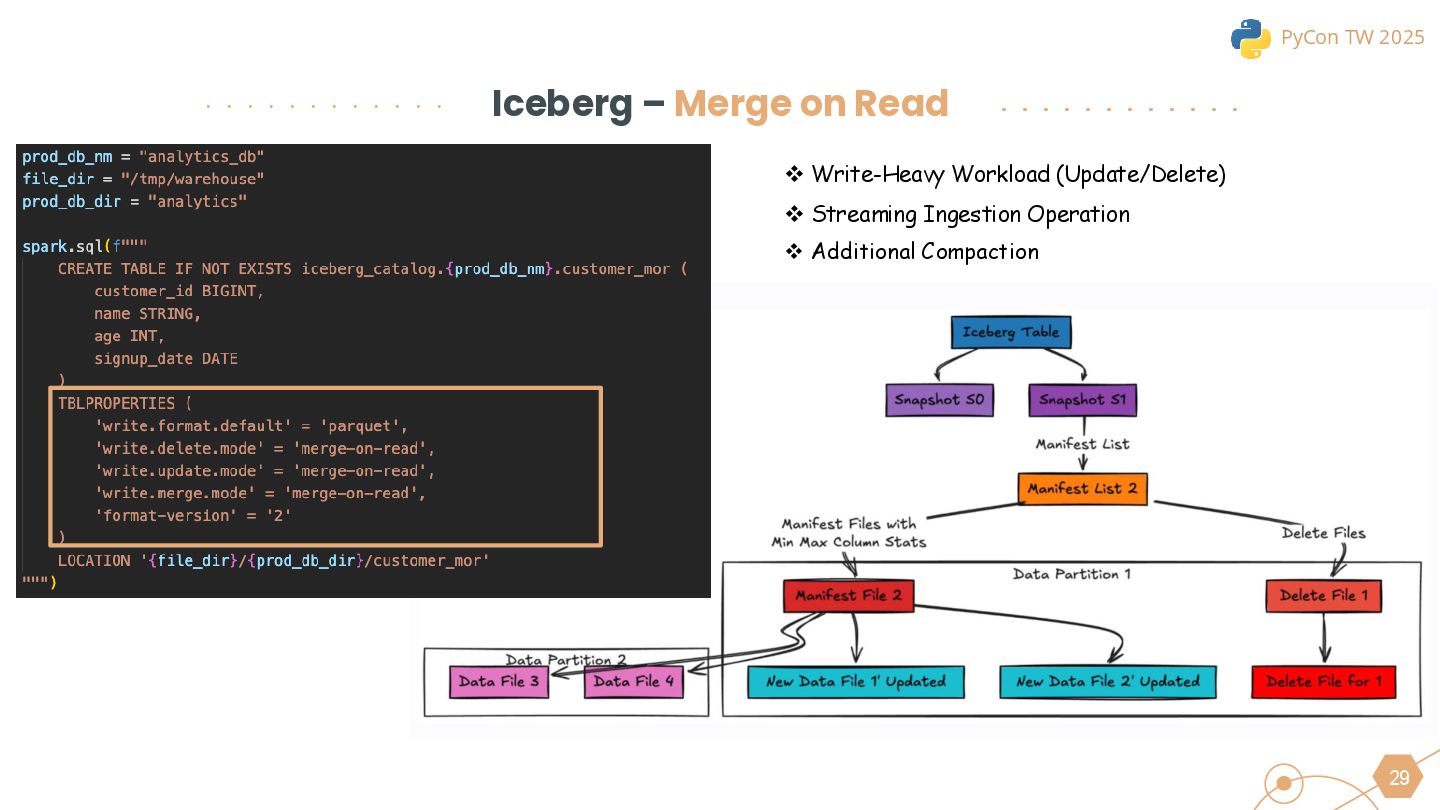{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}