a. 標準のSQLが使える i. テーブルの概念がほぼ RDBMSと同じ様に使える b. Googleのアカウントに紐づけて誰にどのデータを見せるかの管理ができる c. PB級のデータの格納/クエリ実行が可能 i. 価格もそれほど高くない • アクティブストレージ $0.023/GiB • クエリ(オンデマンド) $6/TiB(月額、年額固定プランも ) 18 BigQuery
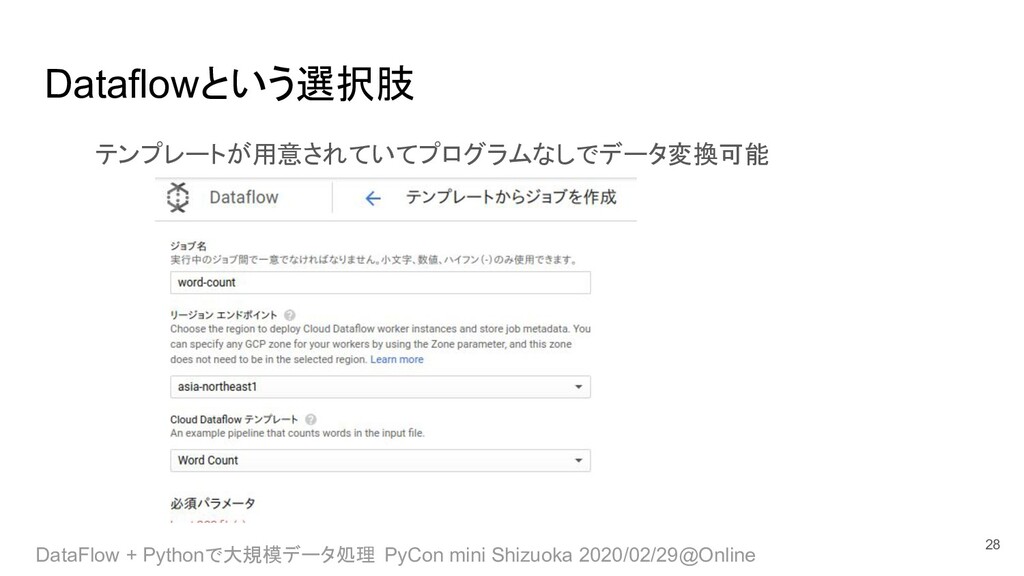
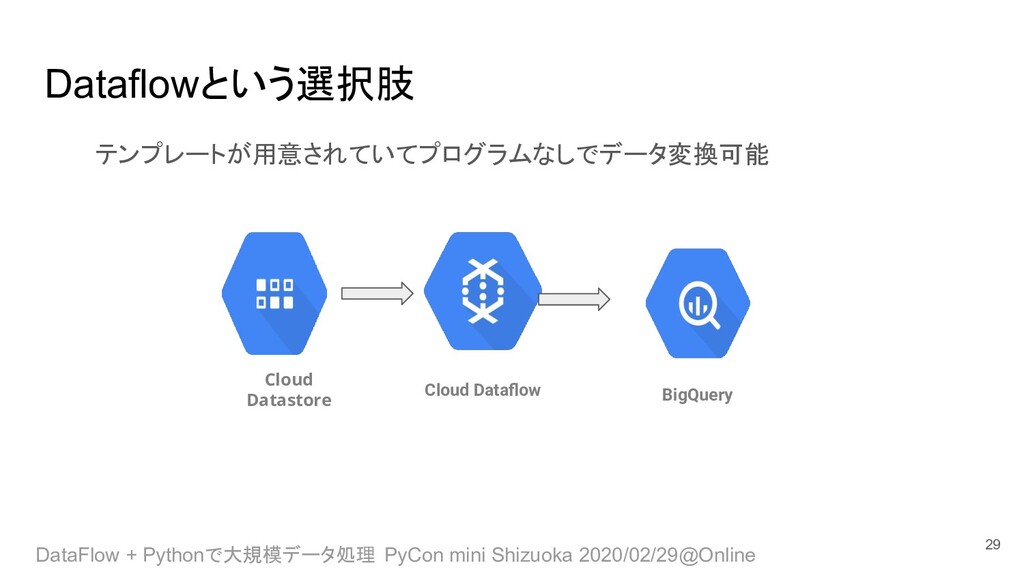
• Pub/Sub to BigQuery • JDBC to BigQuery • Cloud Storage Text to Pub/Sub • Datastore to Cloud Storage Text • Cloud Storage Text to Datastore • Bulk Compress Cloud Storage 30
Logging 41 Logging moduleからStackDriver Loggingにログを出力できる # import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower())
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}