Share
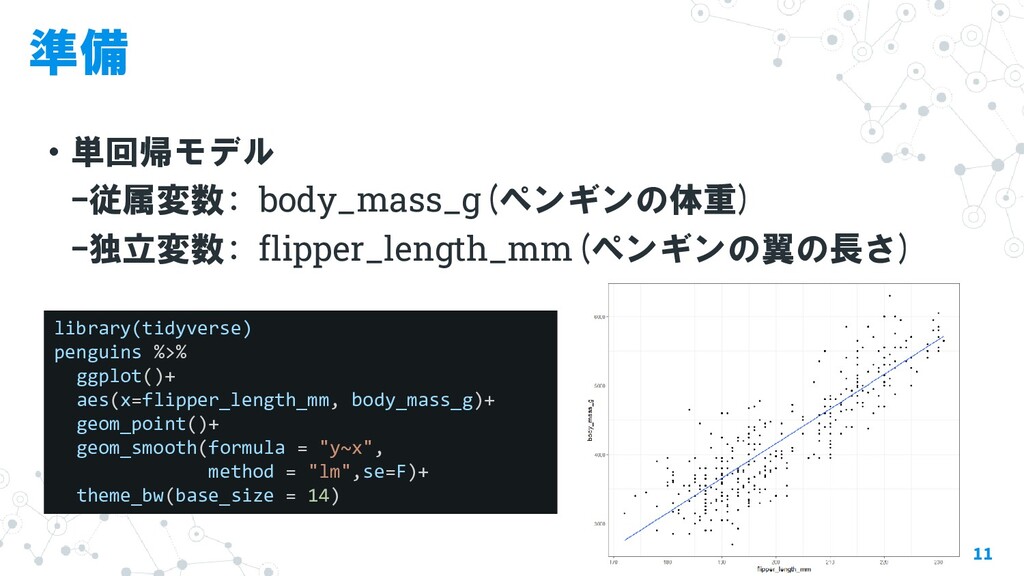
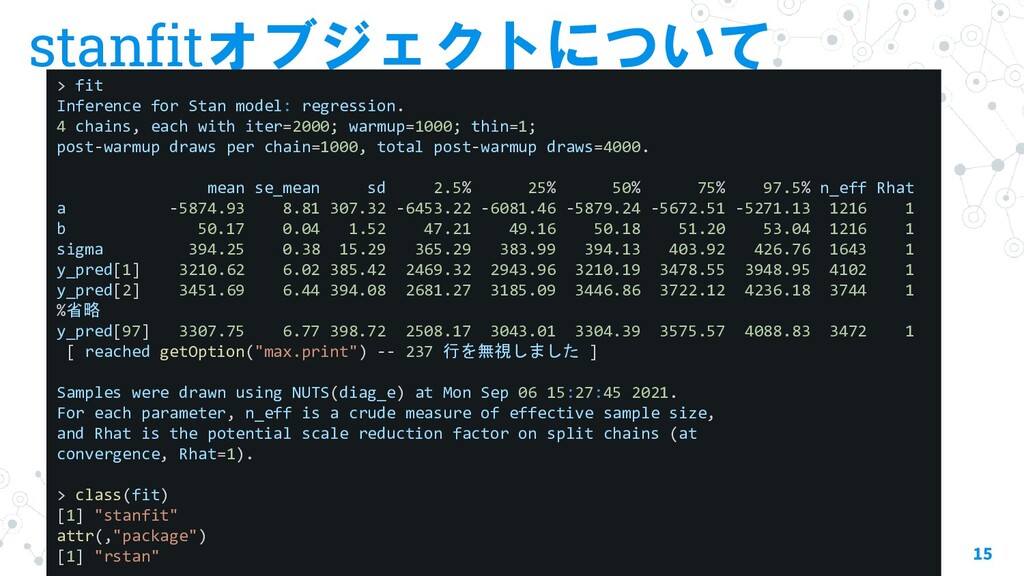
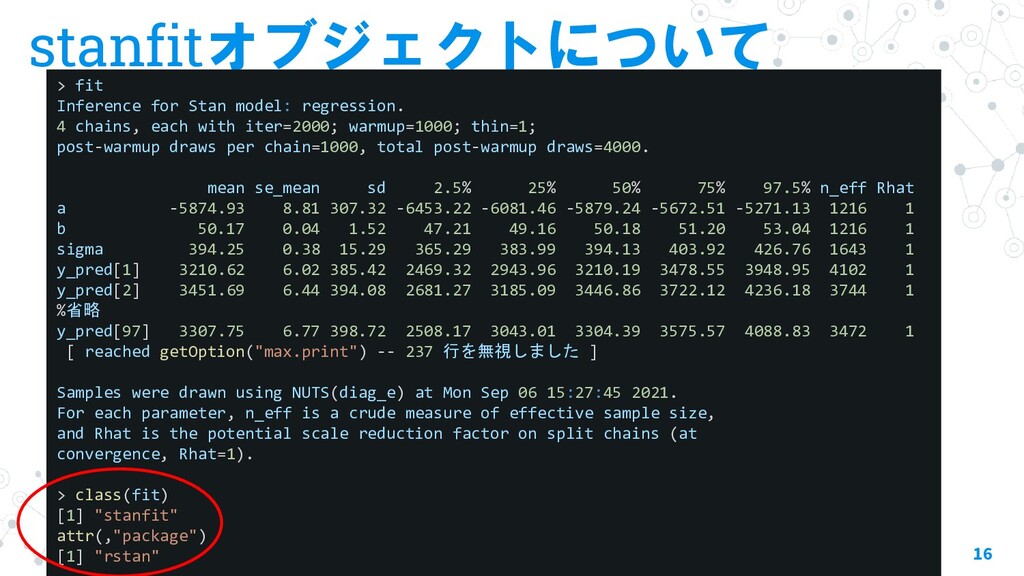
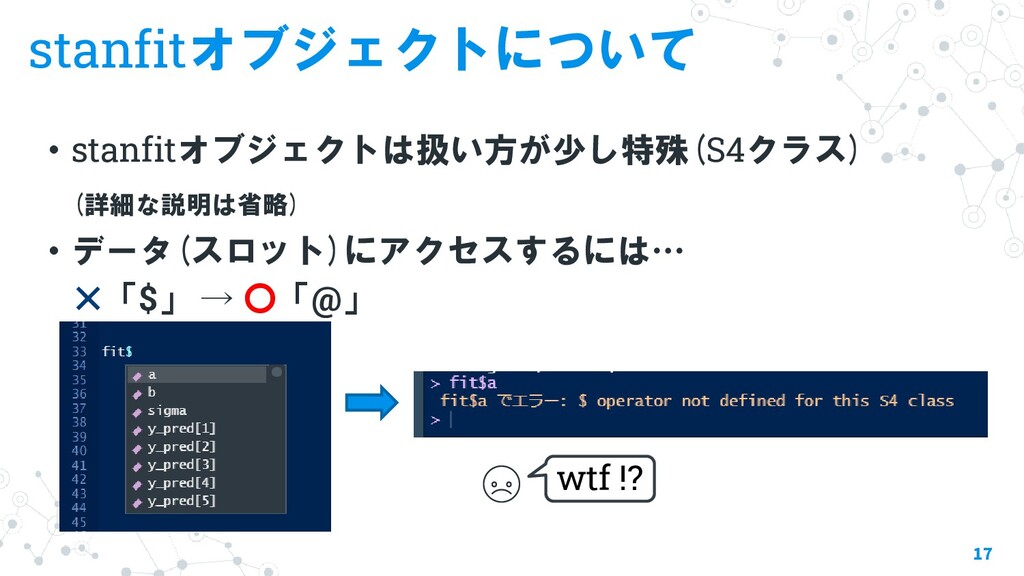
stan推定後の可視化に便利なパッケージとその関数について紹介します。 ・stanfitオブジェクトについて ・rstanパッケージの関数 ・bayesplotパッケージの関数 ・tidyverseでstanfitを扱う
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![stanコード 12 data{ int N; vector[N] Y; vector[N] X; }](https://files.speakerdeck.com/presentations/5fd8316666234cb4a6e5c9b66ee659f6/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
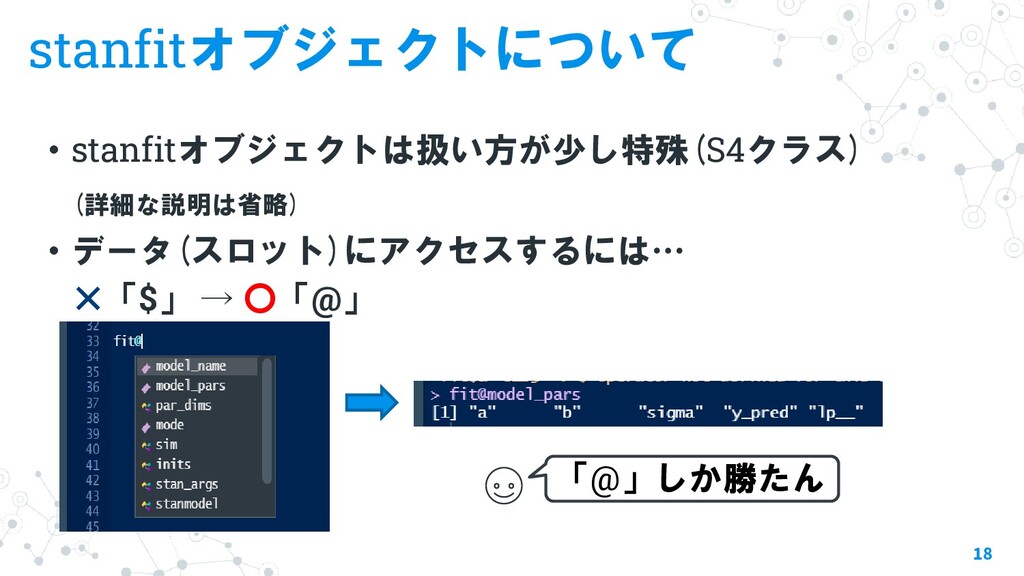{kind=link}
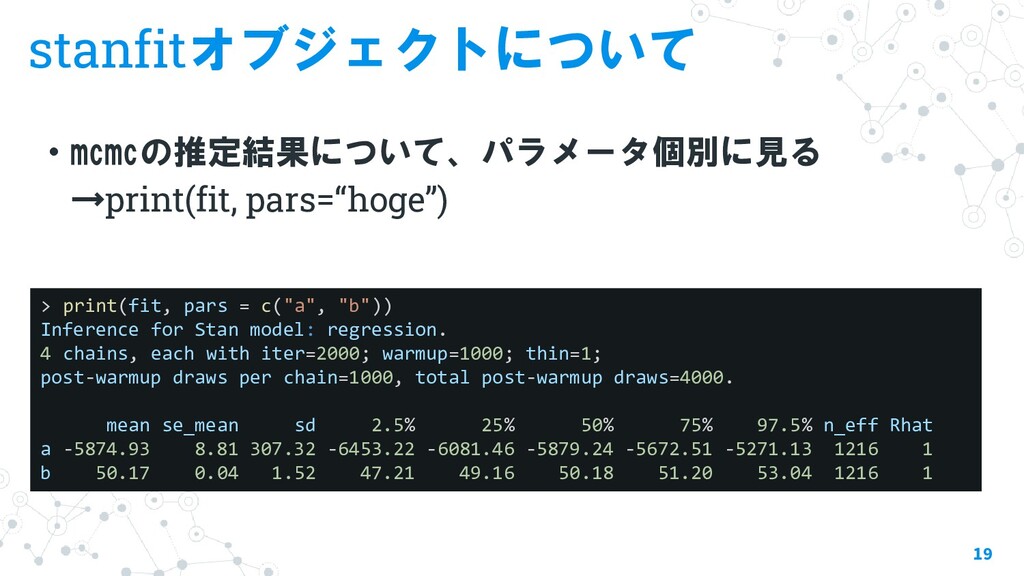{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
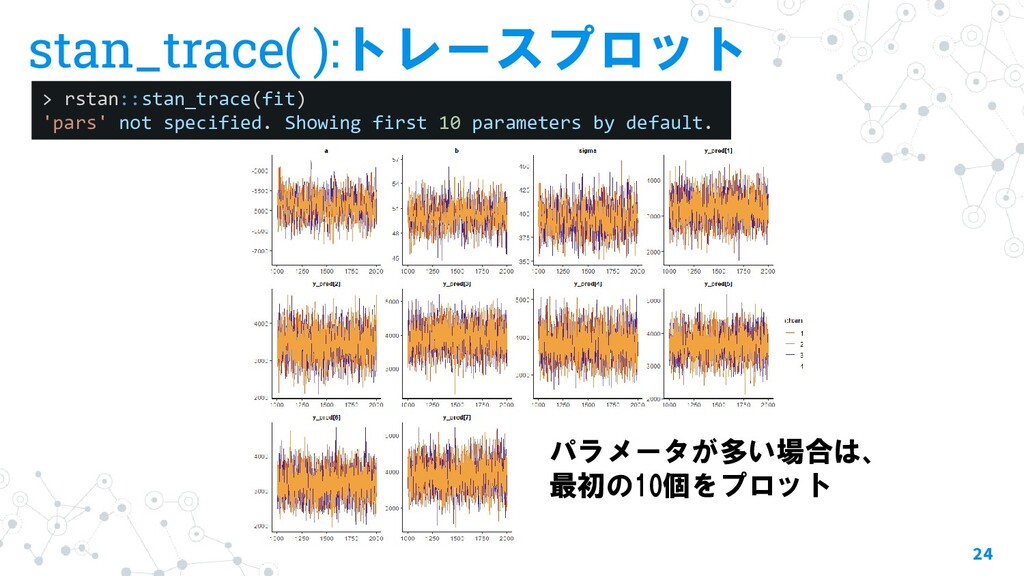{kind=link}
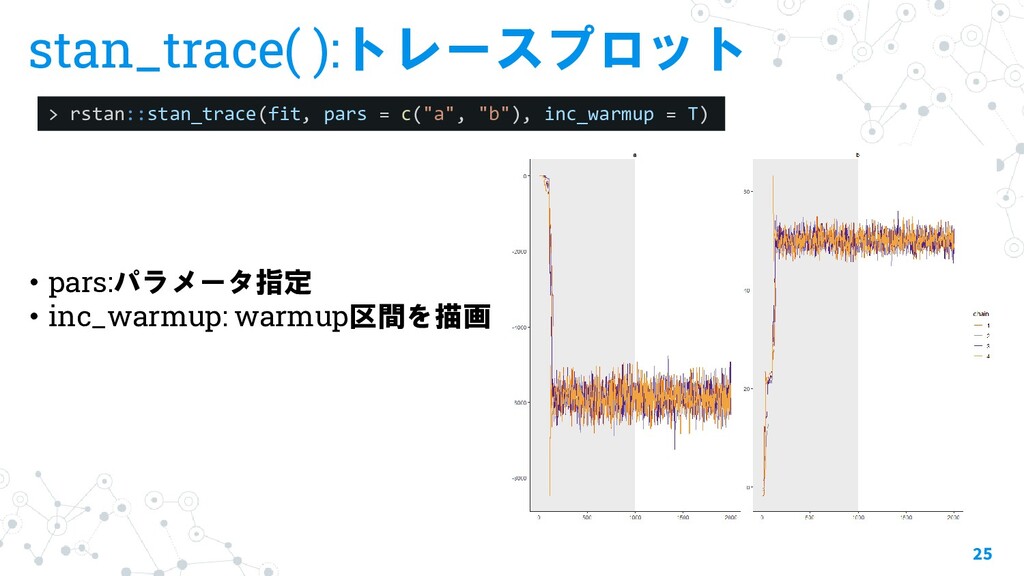{kind=link}
![上手く推定できていない時… 26 https://discourse.mc-stan.org/t/gaussian-process-on-hpc-issues-and-speeding-up/18202 [mcmcあるある] ・あるチェインだけ変な挙動 ・局所解 ※色んなトレースプロットを集めよう(?)](https://files.speakerdeck.com/presentations/5fd8316666234cb4a6e5c9b66ee659f6/slide_25.jpg){kind=link}
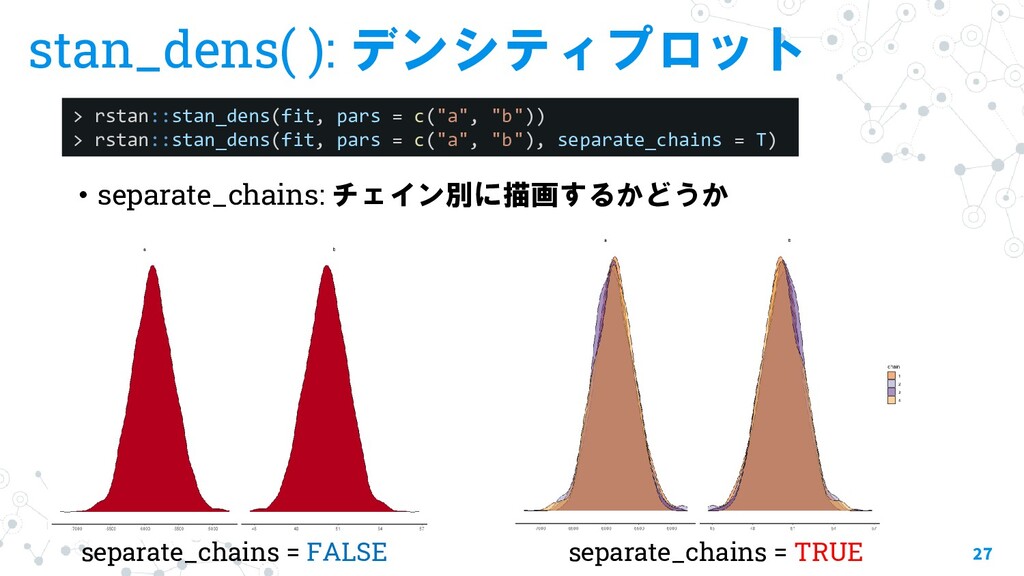{kind=link}
![上手く推定できていない時 28 http://www.eeso.ges.kyoto-u.ac.jp/emm/materials/bayesian/stan_step1 [mcmcあるある] ・多峰性 ・チェインでばらばら ※色んなデンシティプロットを集めよう(?)](https://files.speakerdeck.com/presentations/5fd8316666234cb4a6e5c9b66ee659f6/slide_27.jpg){kind=link}
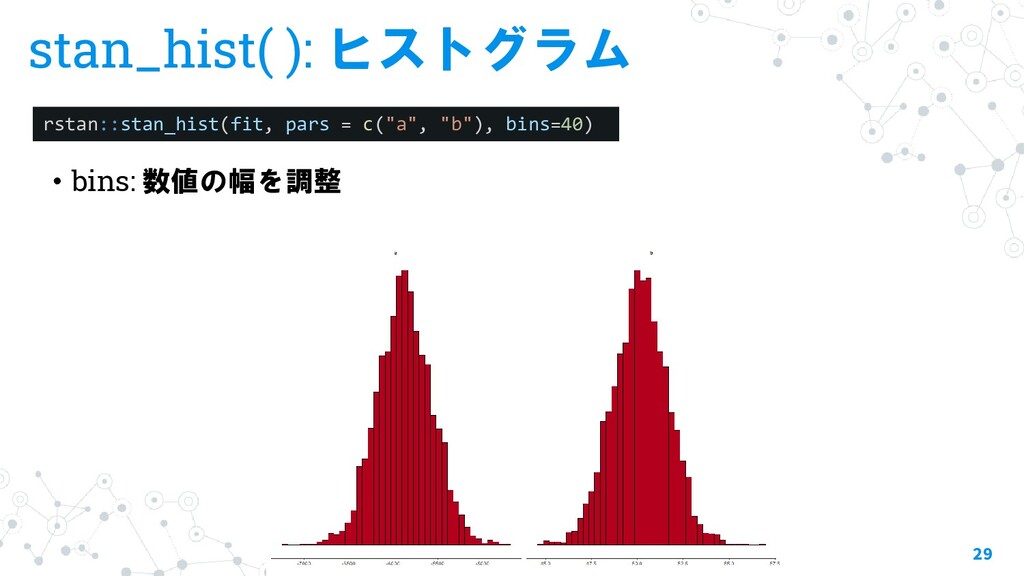{kind=link}
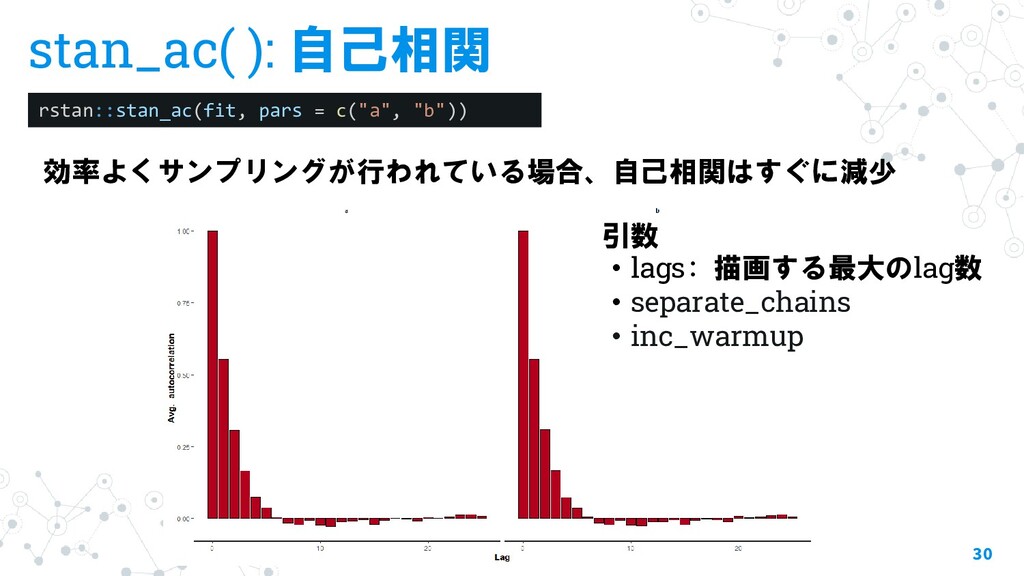{kind=link}
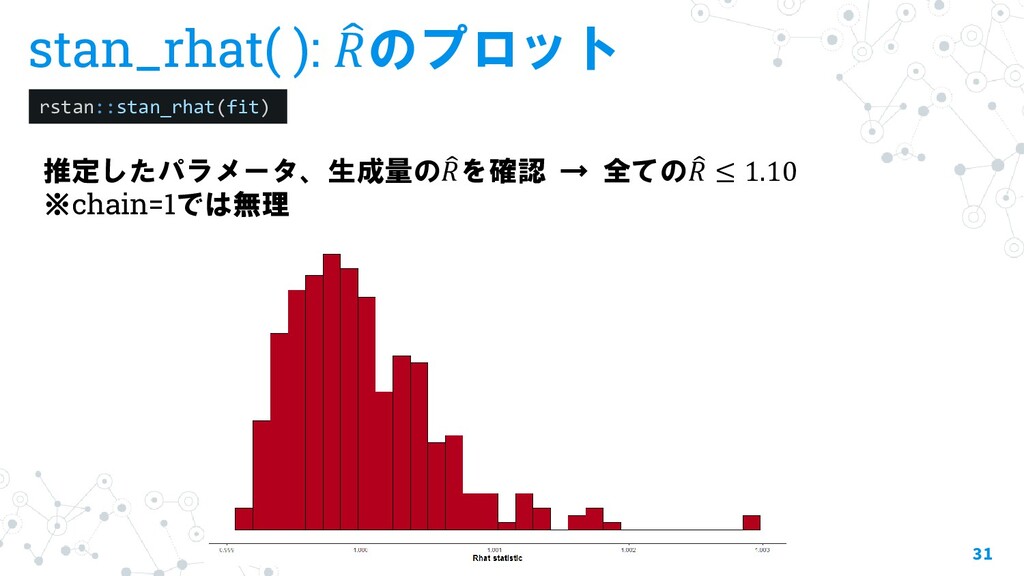{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
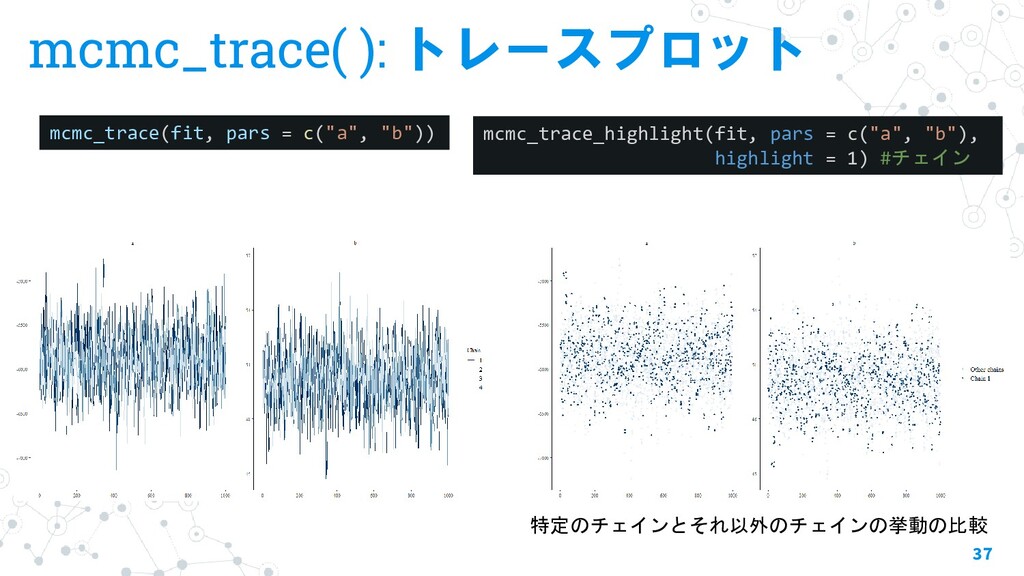{kind=link}
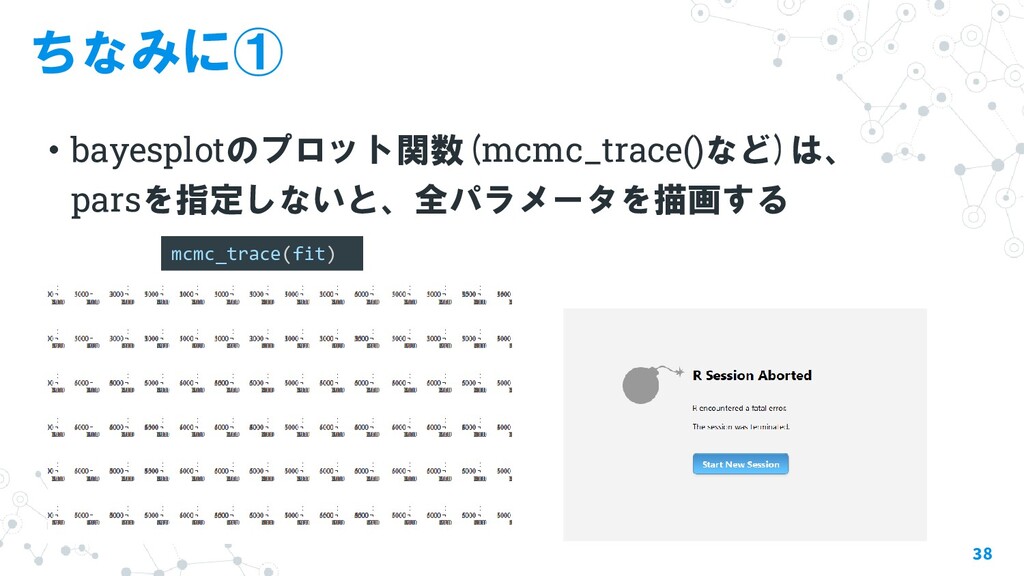{kind=link}
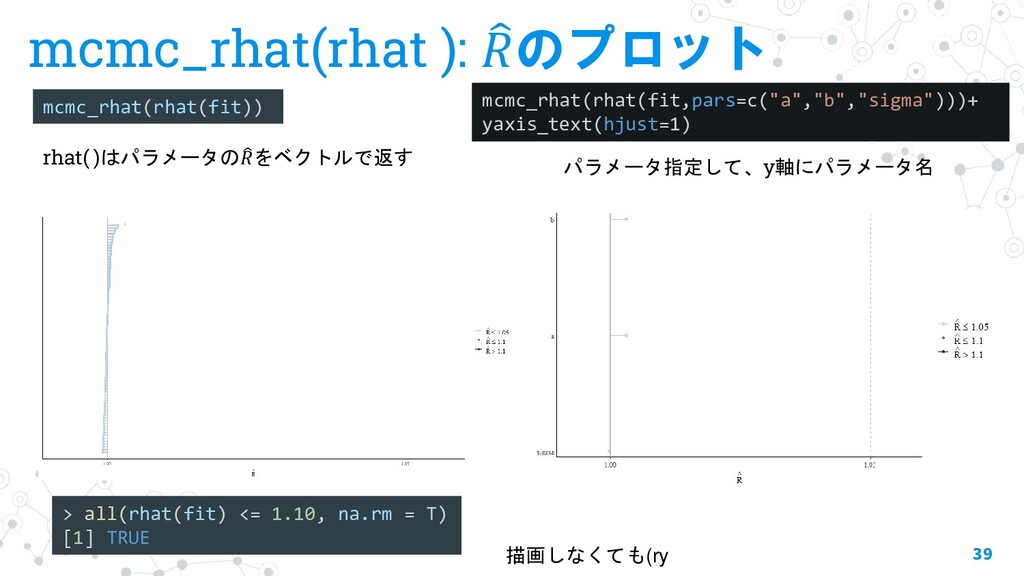{kind=link}
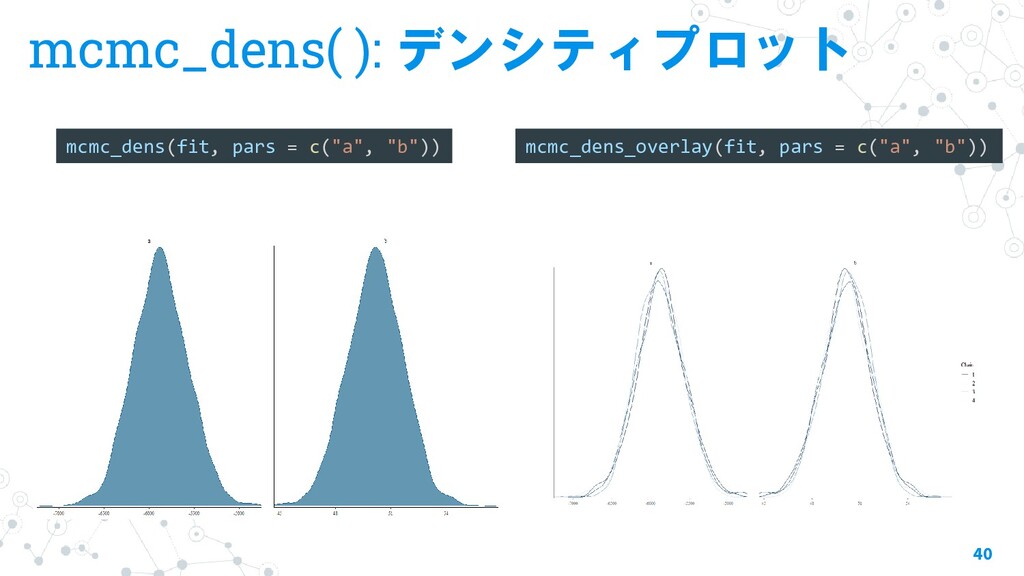{kind=link}
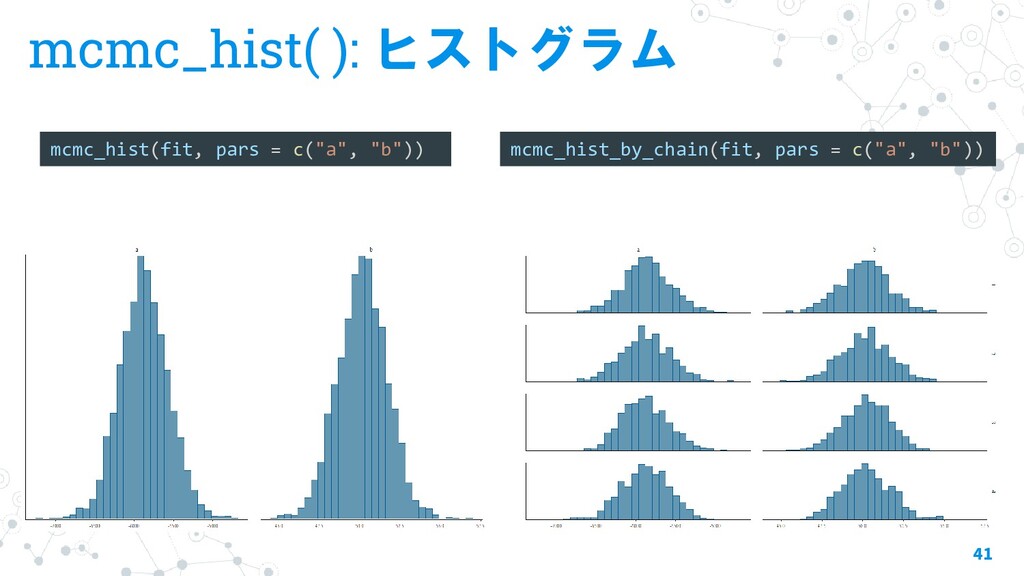{kind=link}
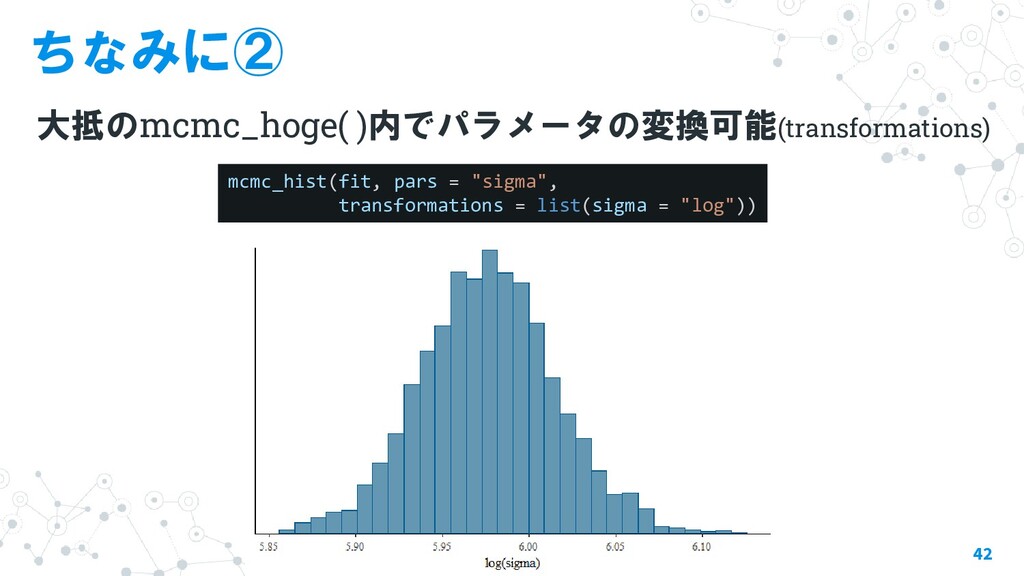{kind=link}
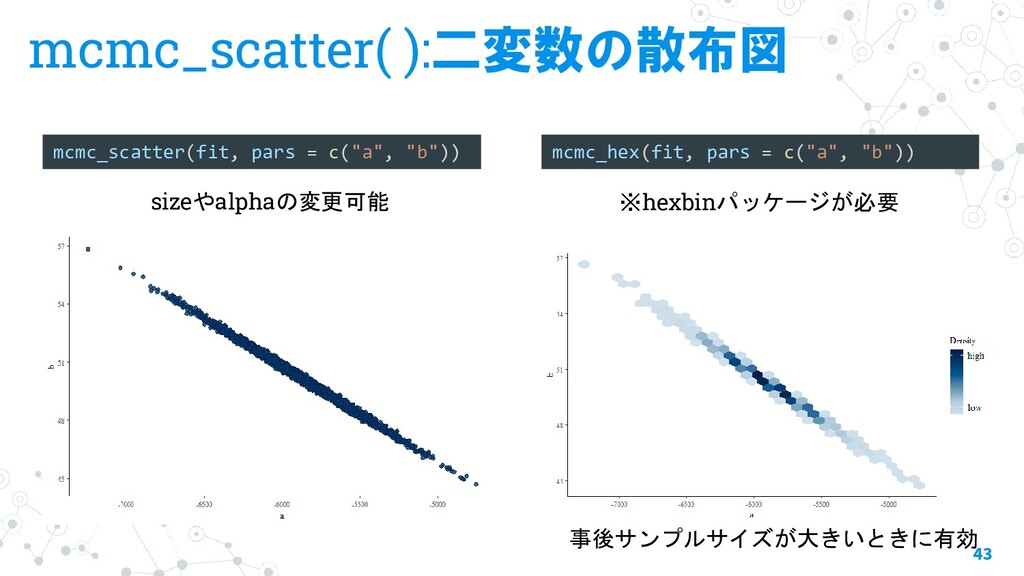{kind=link}
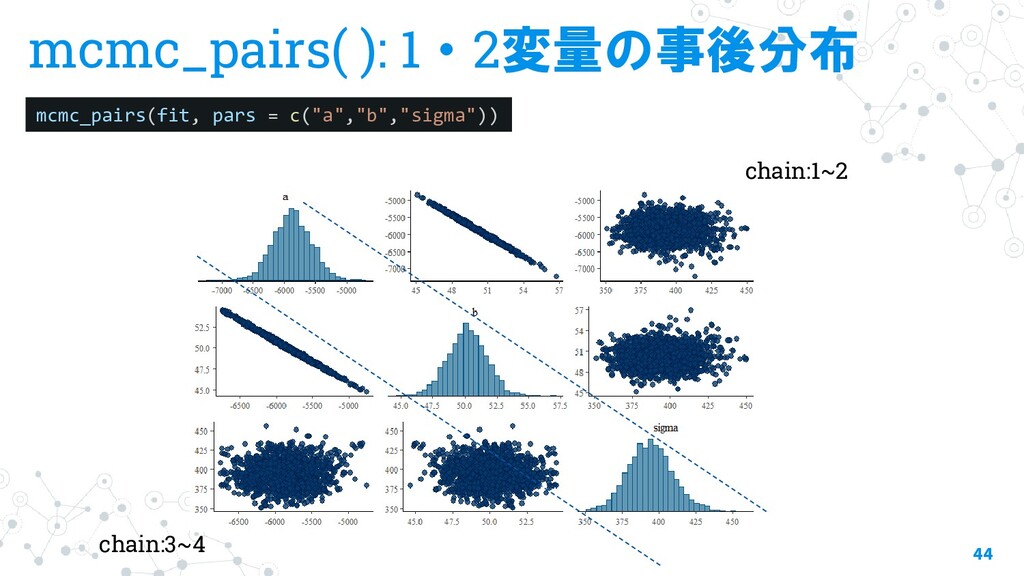{kind=link}
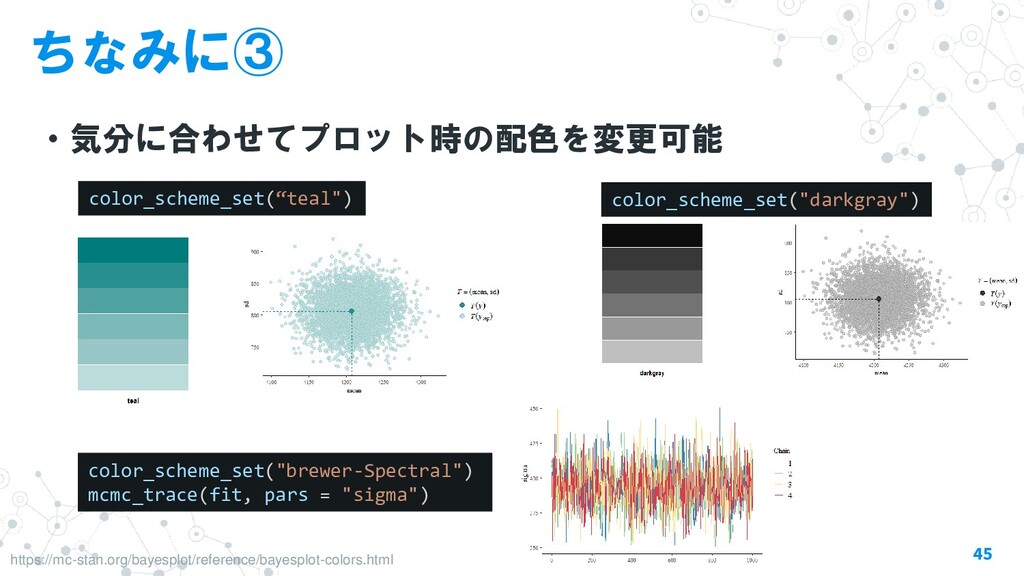{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ppc_dens_overlay( ):データと予測値の密度分布比較 50 ppc_dens_overlay(y = y, yrep = yrep[sample(nrow(yrep), 10),])](https://files.speakerdeck.com/presentations/5fd8316666234cb4a6e5c9b66ee659f6/slide_49.jpg){kind=link}
{kind=link}
![ppc_hist( ), ppc_boxplot( ) ・ヒストグラムやボックスプロットでの比較 52 ppc_hist(y, yrep[sample(nrow(yrep), 5),]) ppc_boxplot(y,](https://files.speakerdeck.com/presentations/5fd8316666234cb4a6e5c9b66ee659f6/slide_51.jpg){kind=link}
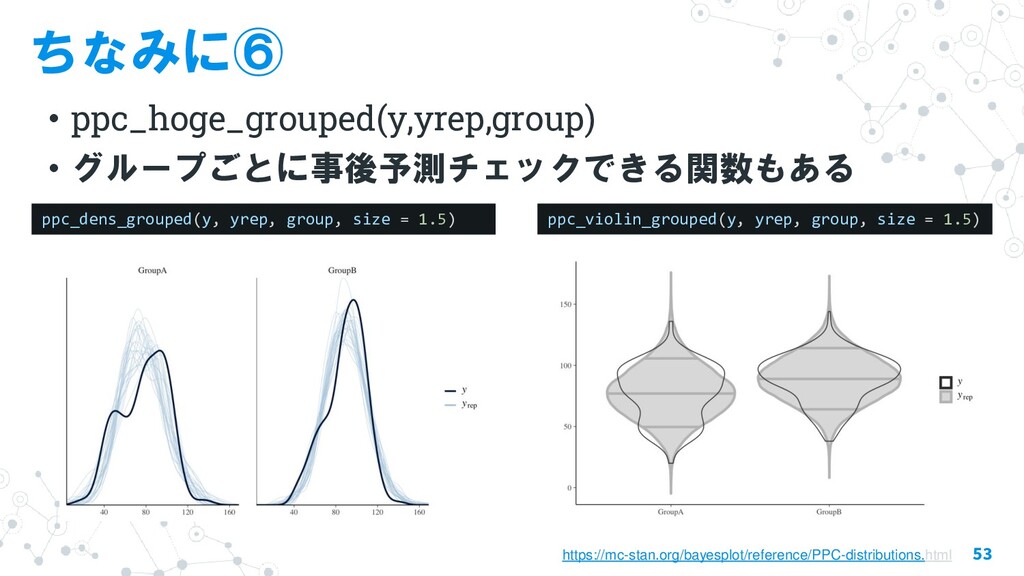{kind=link}
![ppc_error_hoge( ): 予測誤差のプロット データと予測値の誤差(y - yrep)をヒストグラムや散布図で可視化 54 ppc_error_hist(y, yrep[sample(nrow(yrep), 3),])+](https://files.speakerdeck.com/presentations/5fd8316666234cb4a6e5c9b66ee659f6/slide_53.jpg){kind=link}
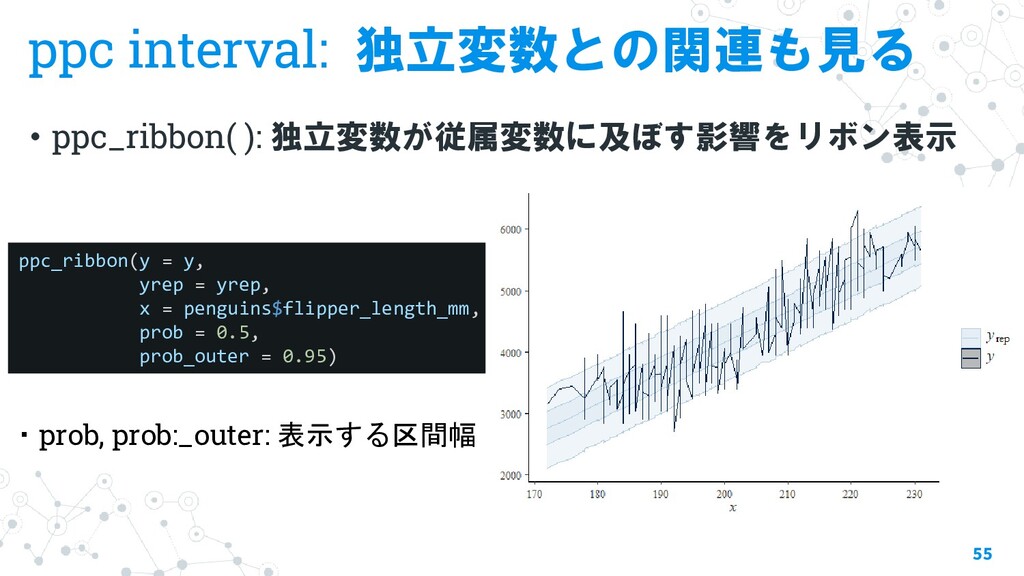{kind=link}
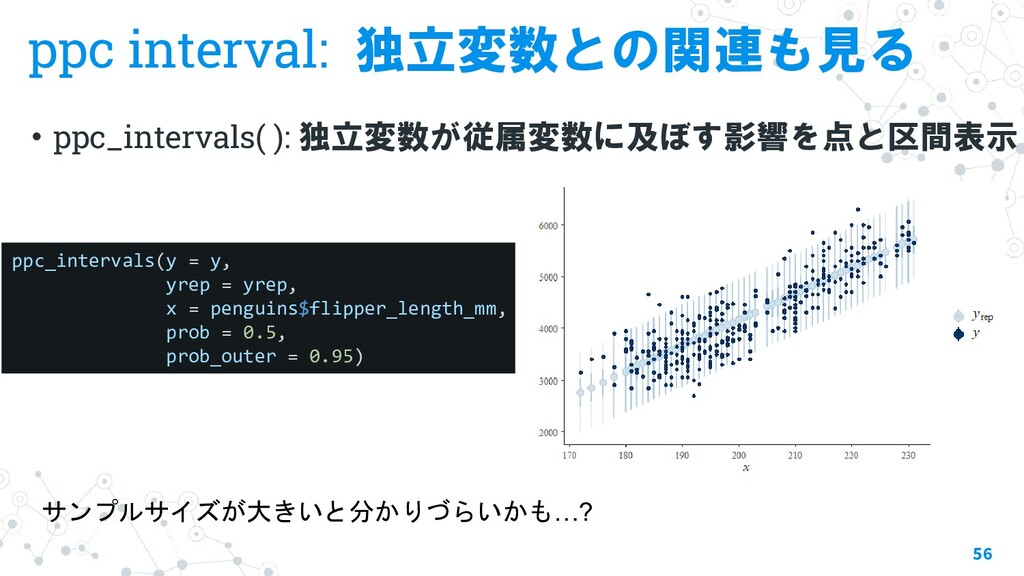{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
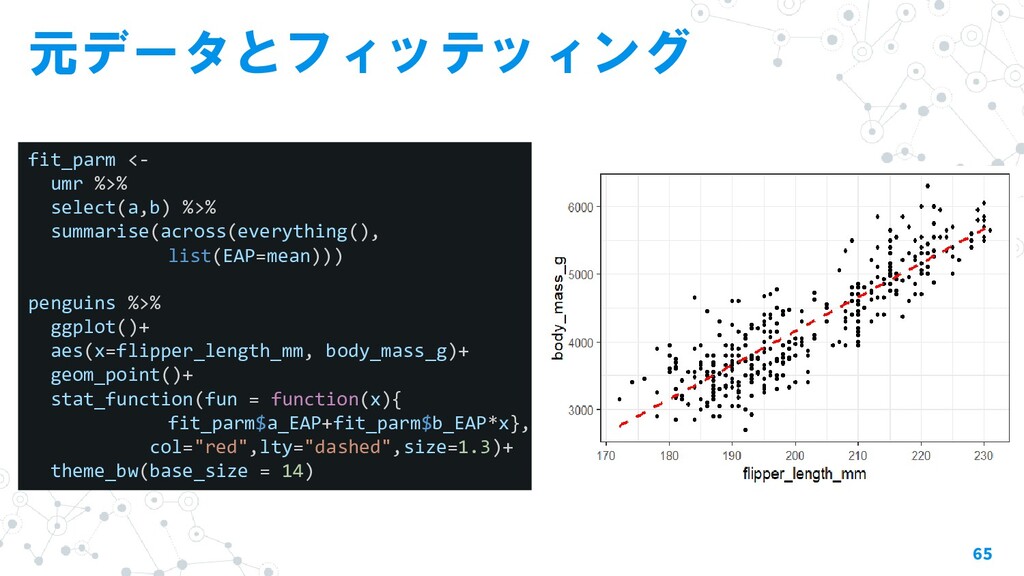{kind=link}
{kind=link}
{kind=link}
{kind=link}