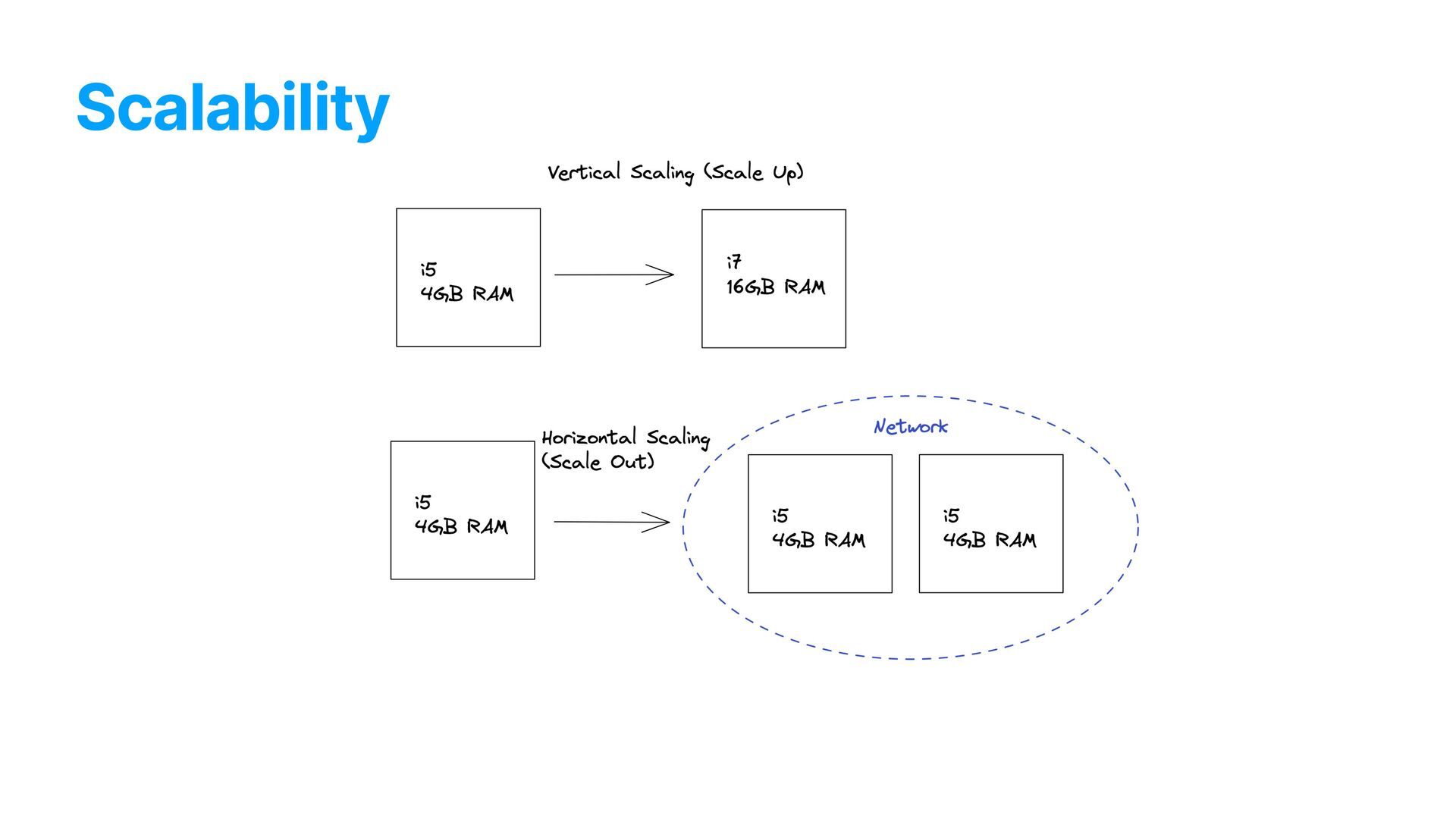
We usually worry about the infrastructure side of things, but often neglect the quality and our code’s ability to grow — in functionalities, modi fi cations or processing power. Well-tested, properly designed code = easier to grow and to modify
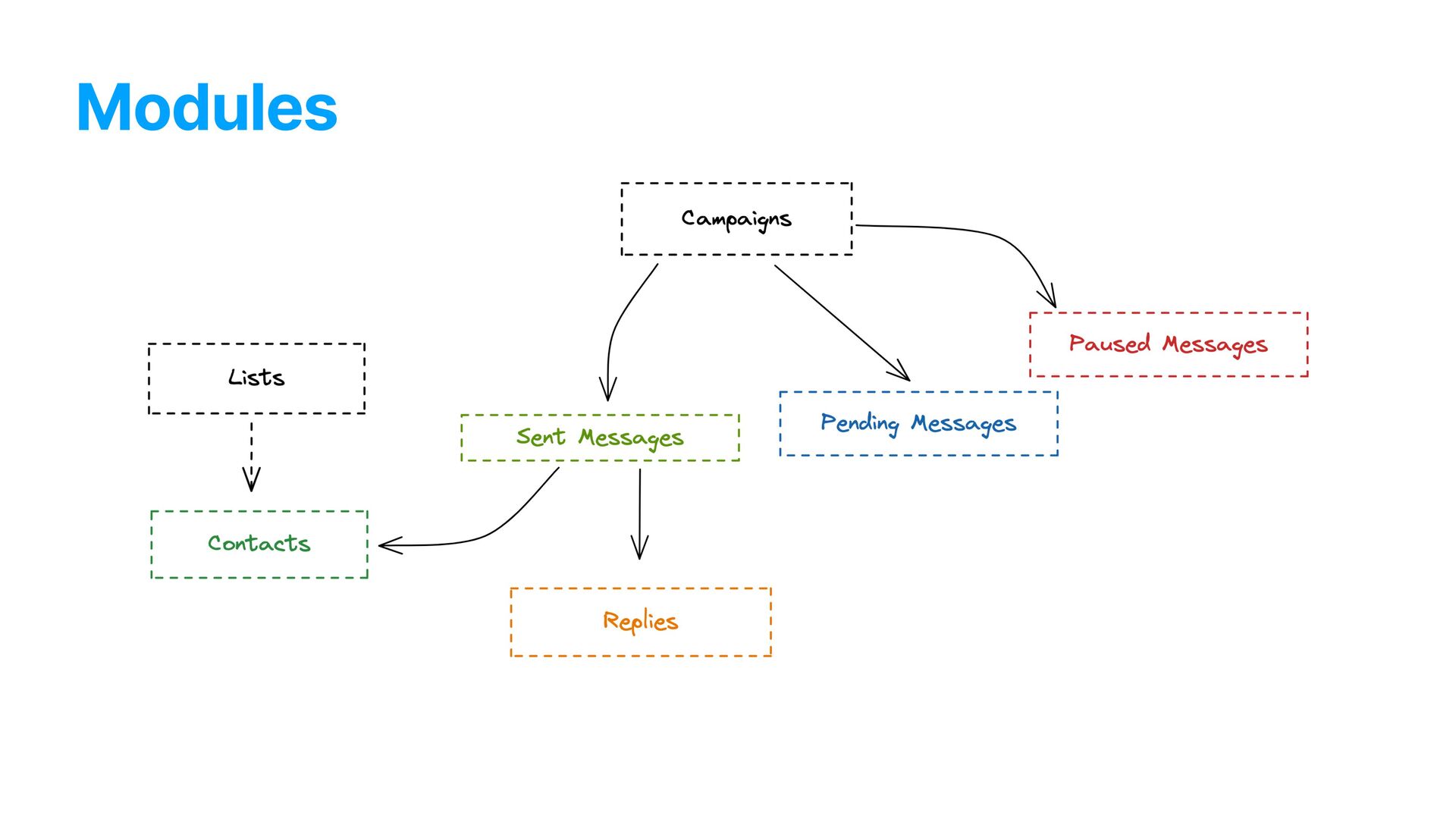
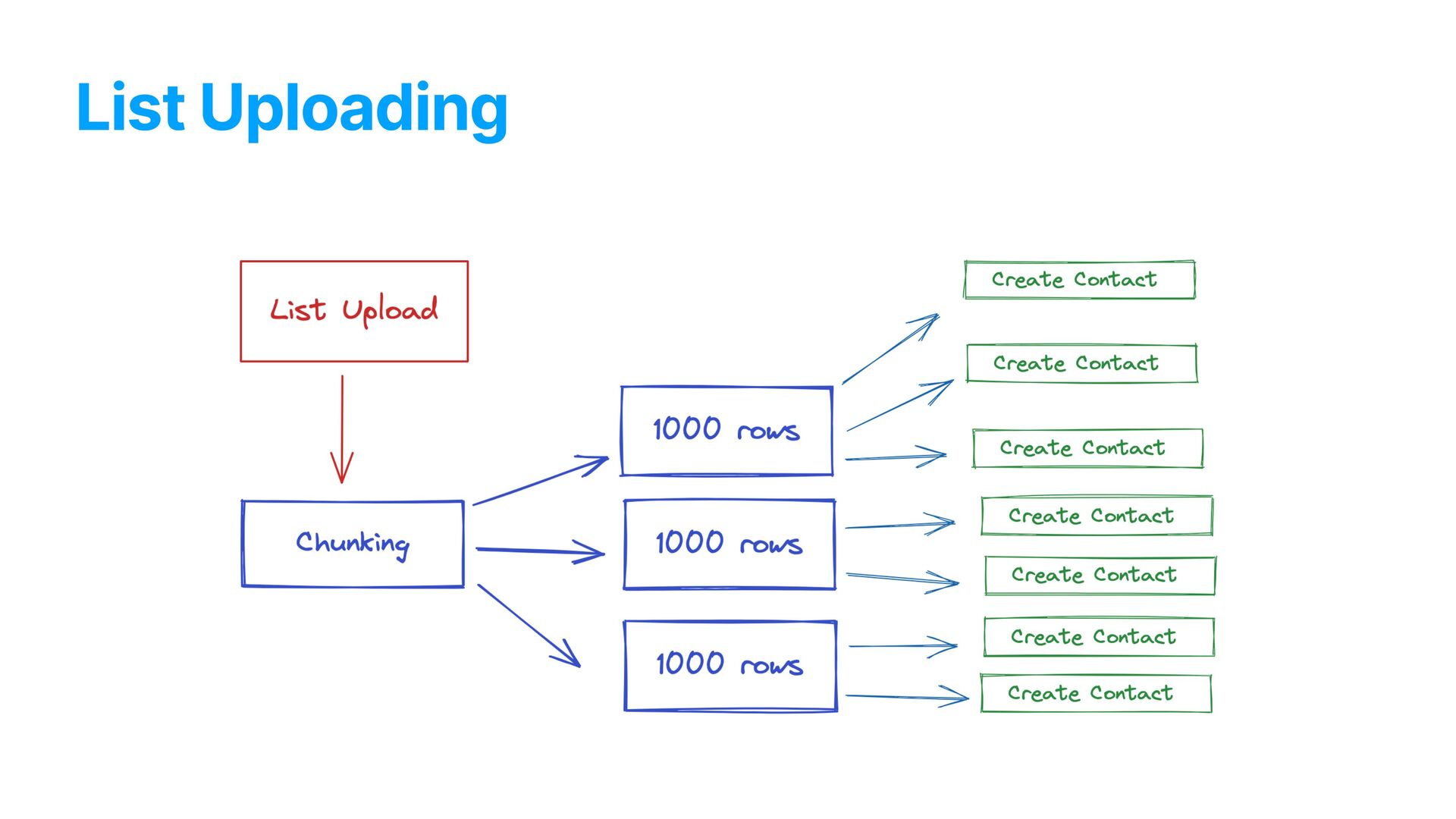
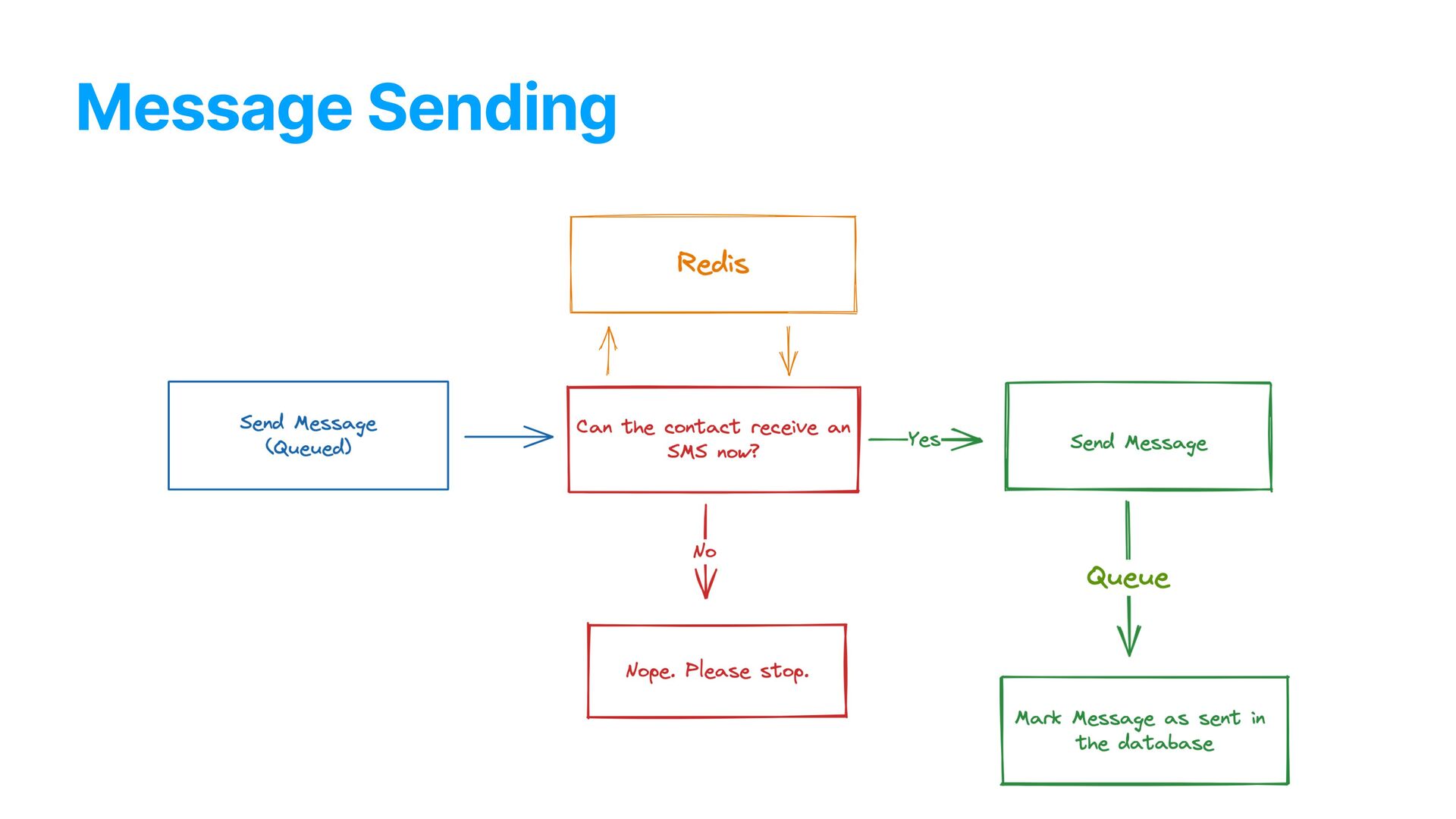
app. In short: • Clients uploaded huge lists of customers • Campaigns were created targeting segmented people based on those lists • The platform would then automatically send SMS messages, respecting the limits of each number provider, etc
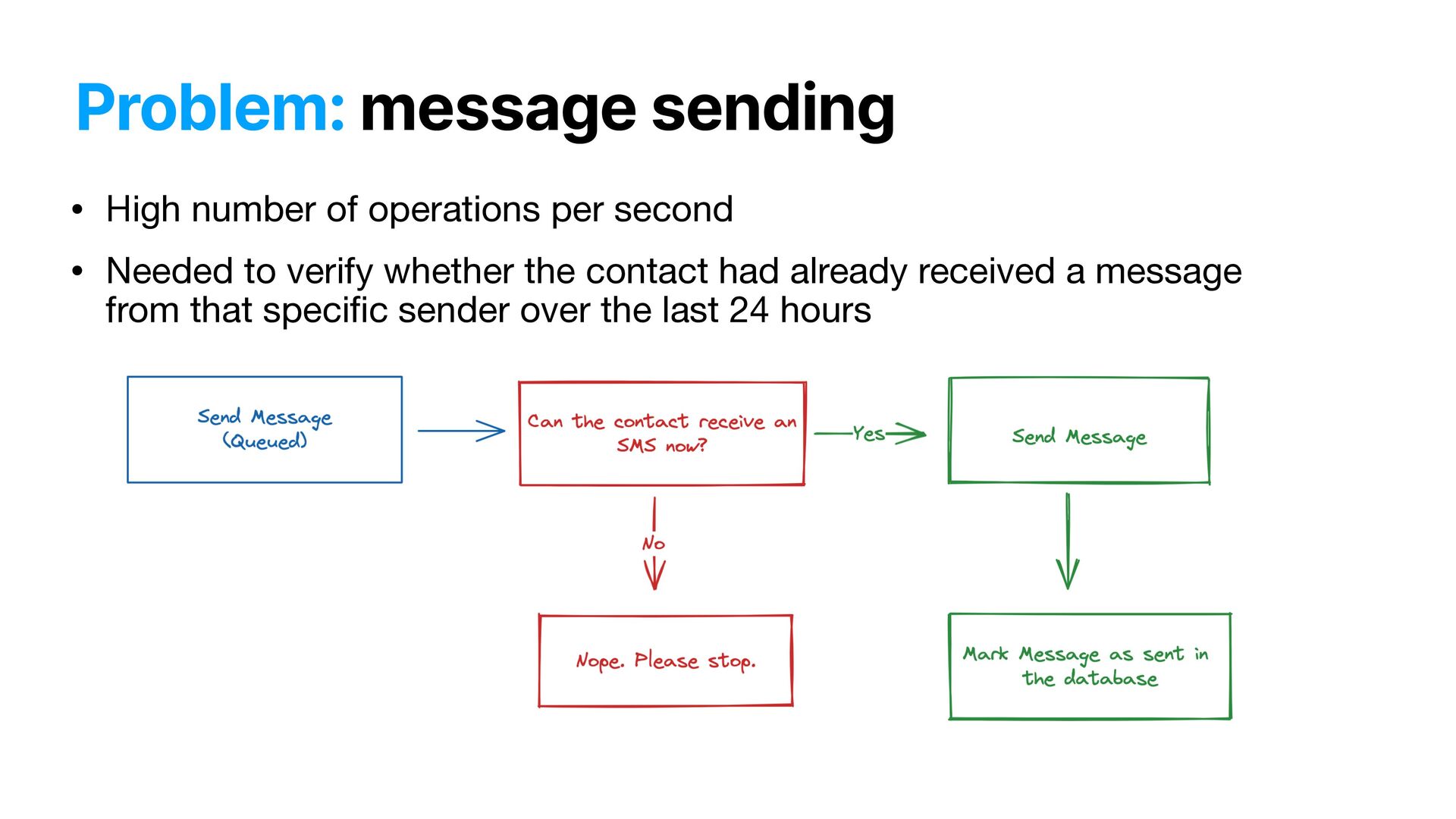
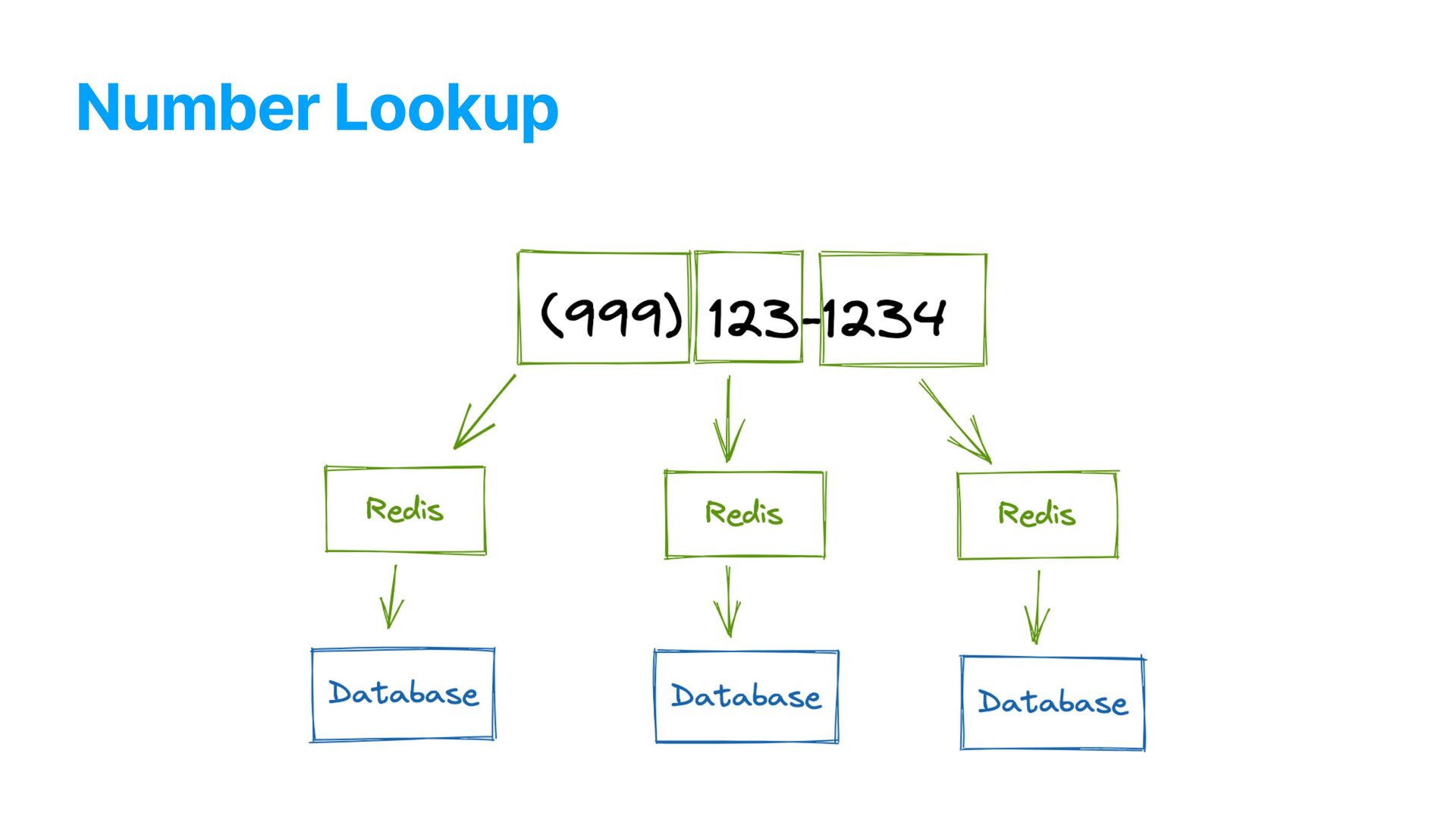
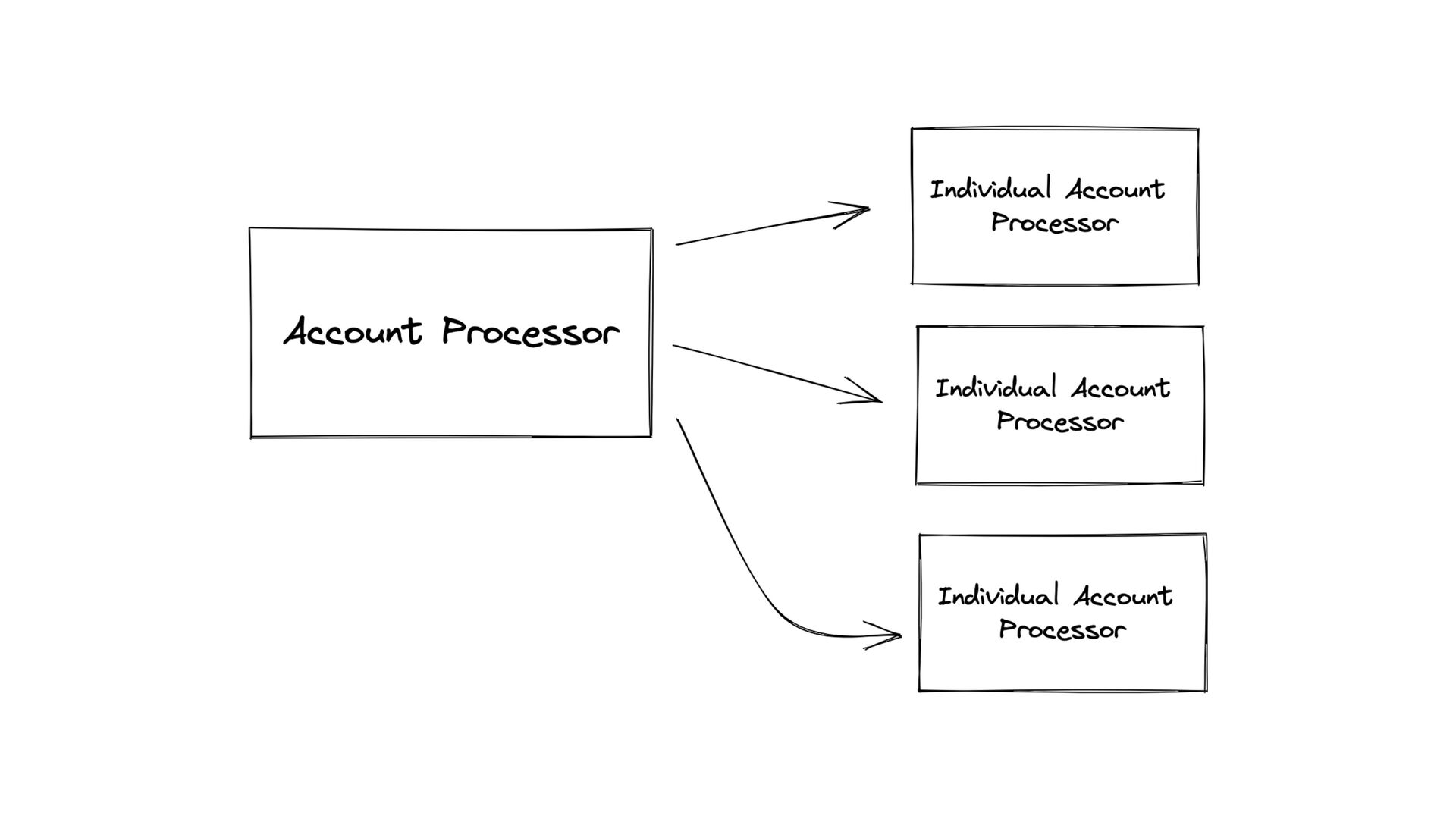
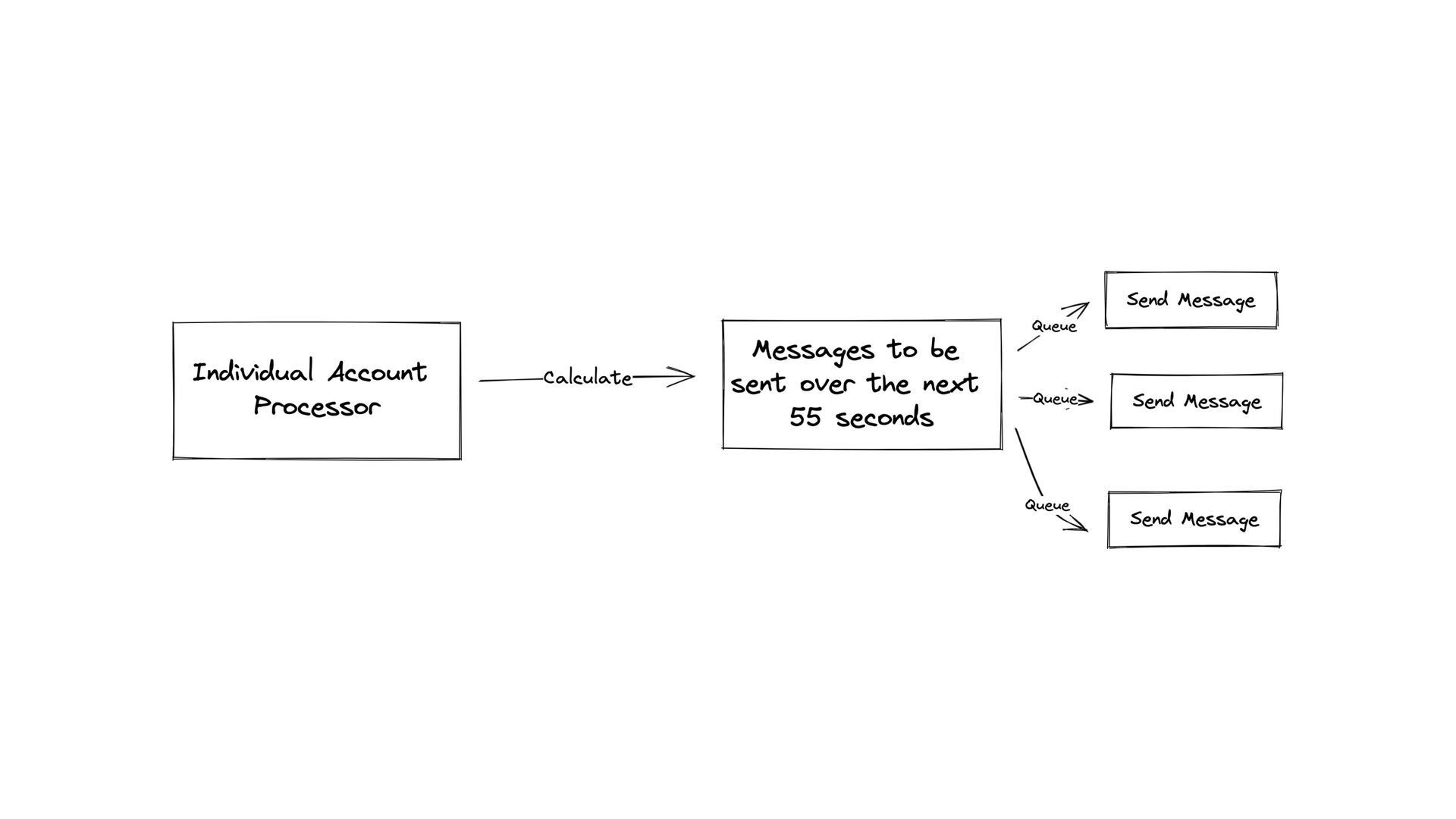
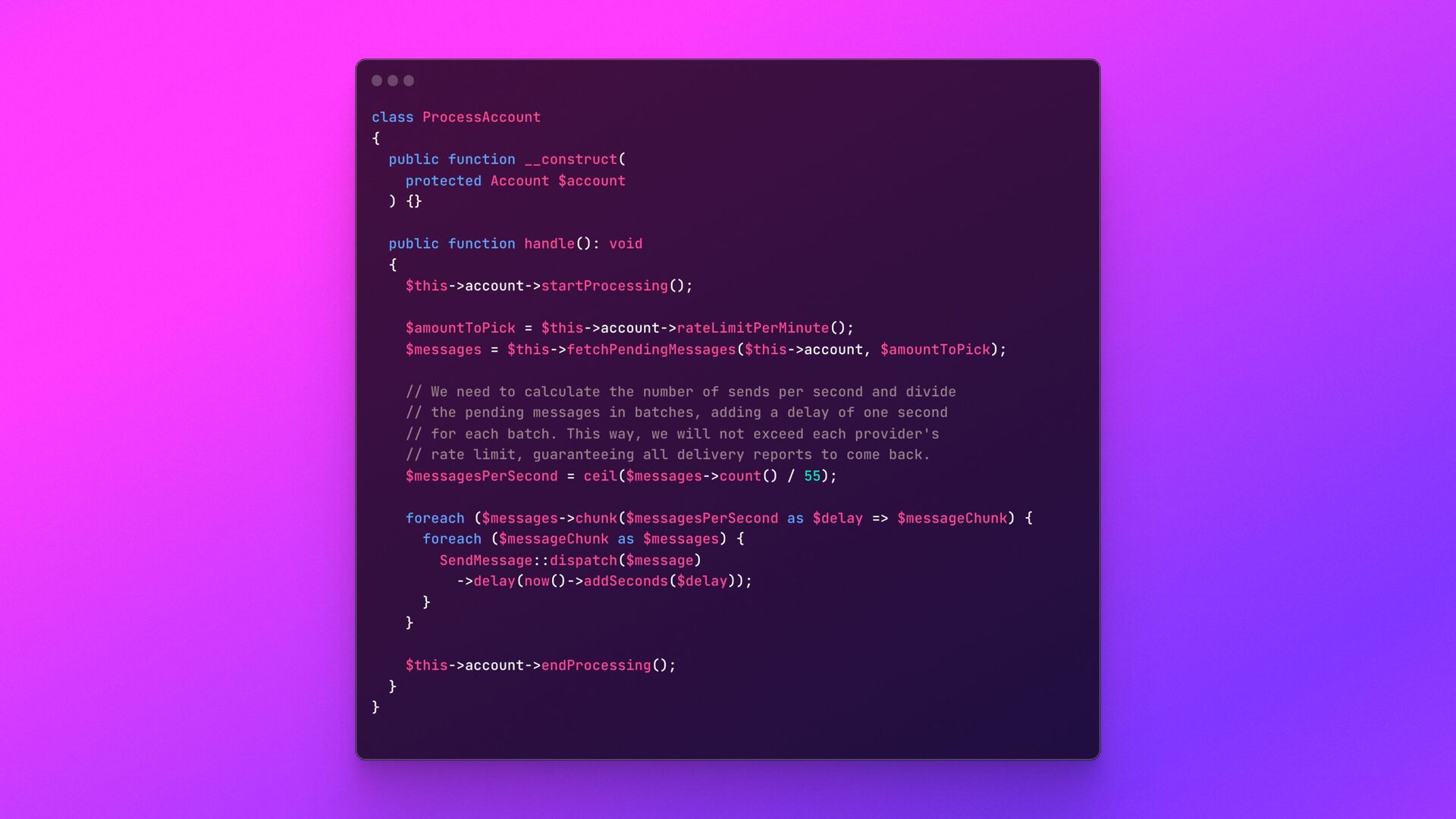
of data ( 100M + ) • Expensive geographic lookup • Slow • Expensive queries • Fairly database • Complex processes needed to run during the actual creation of each pending message record • Need to be FAST • High number of operations per second • The maximum amount of messages per minute per account needed to be calculated during runtime • We need to support dozens of SMS providers!
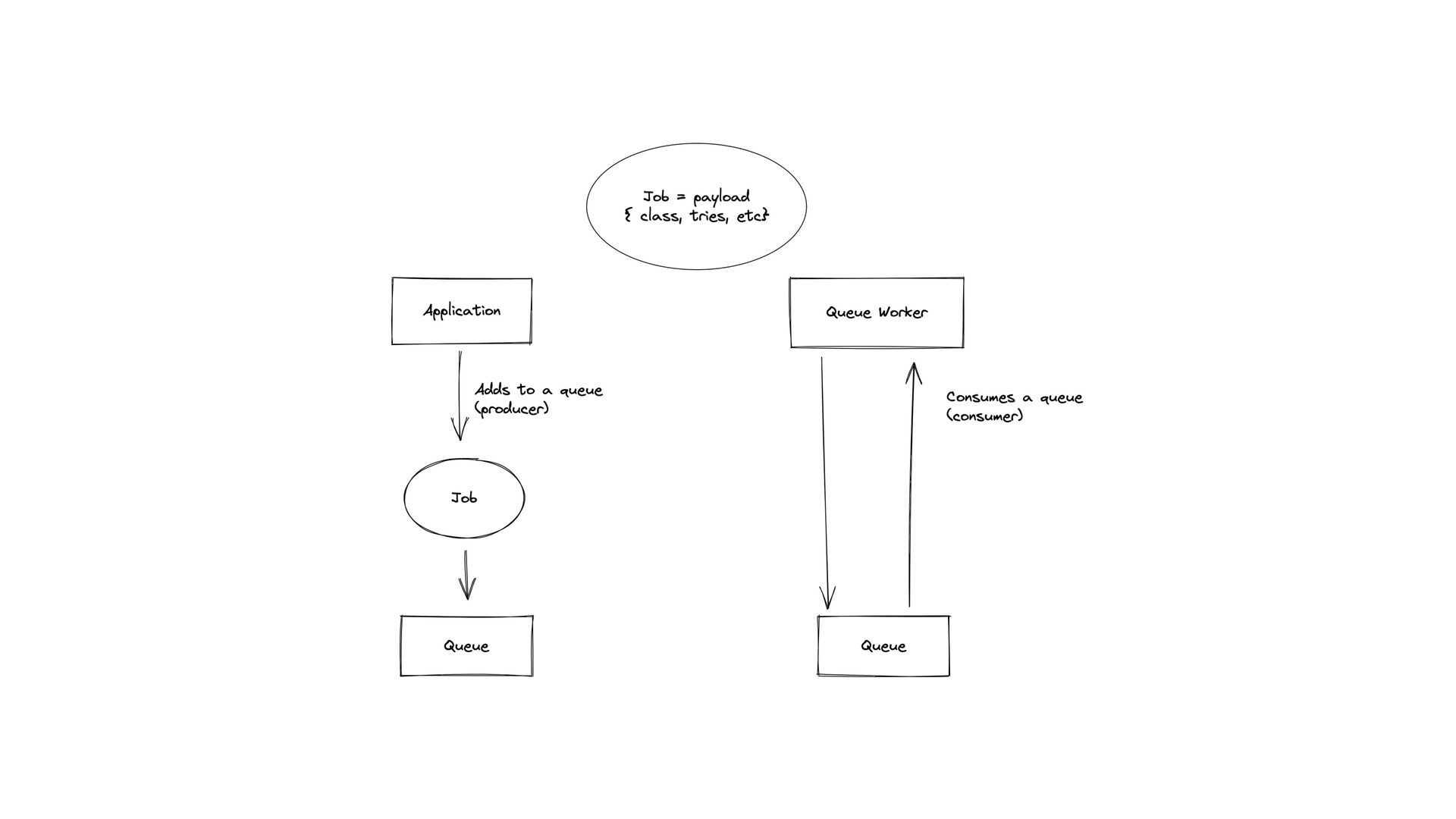
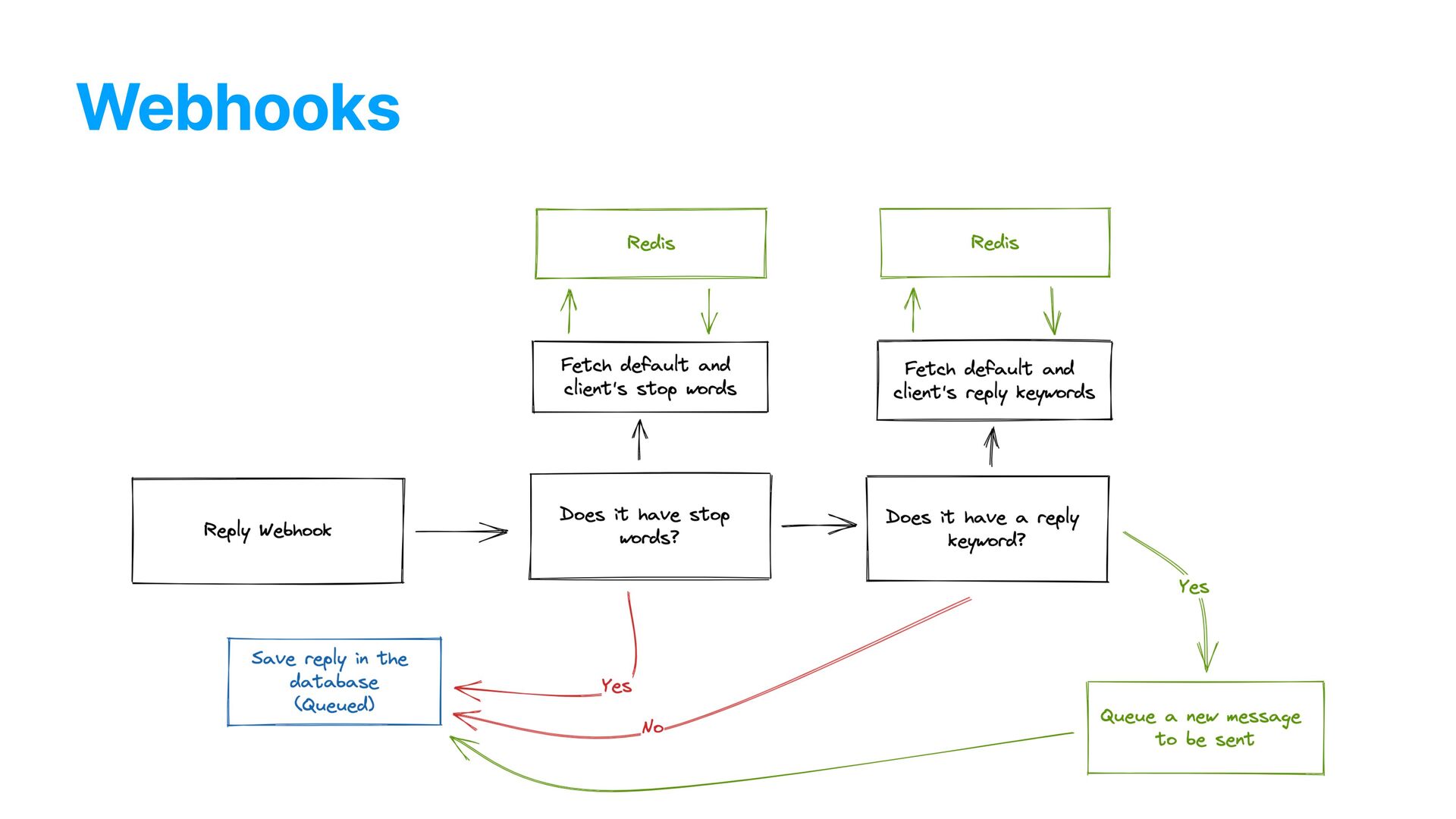
but expensive operations in high scale • “Stop word” verifications against the database • Would possibly trigger another command to block a number from receiving messages • Would happen after receiving a “reply keyword” (e.g: yes) • Adds a pending message to the database
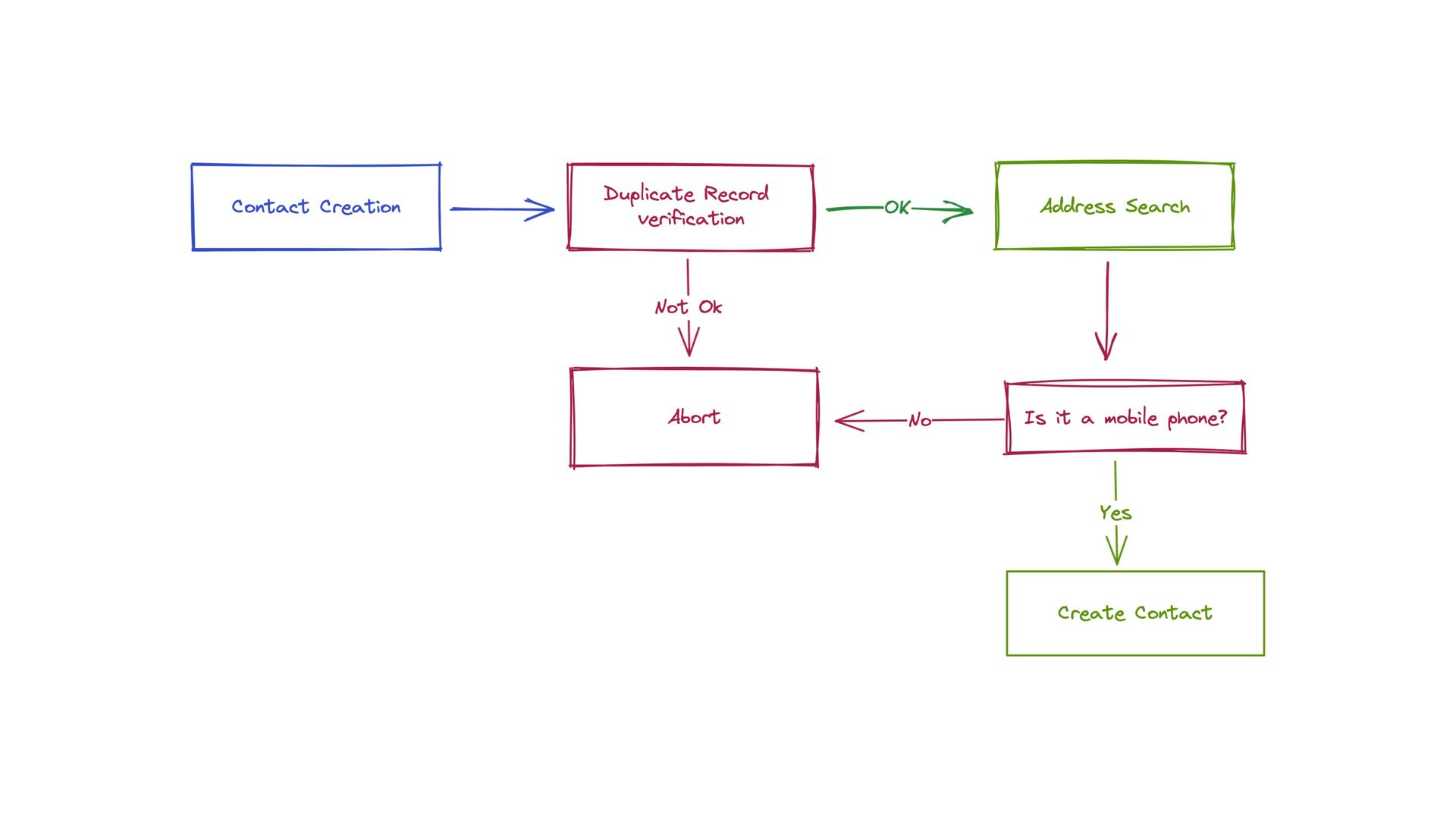
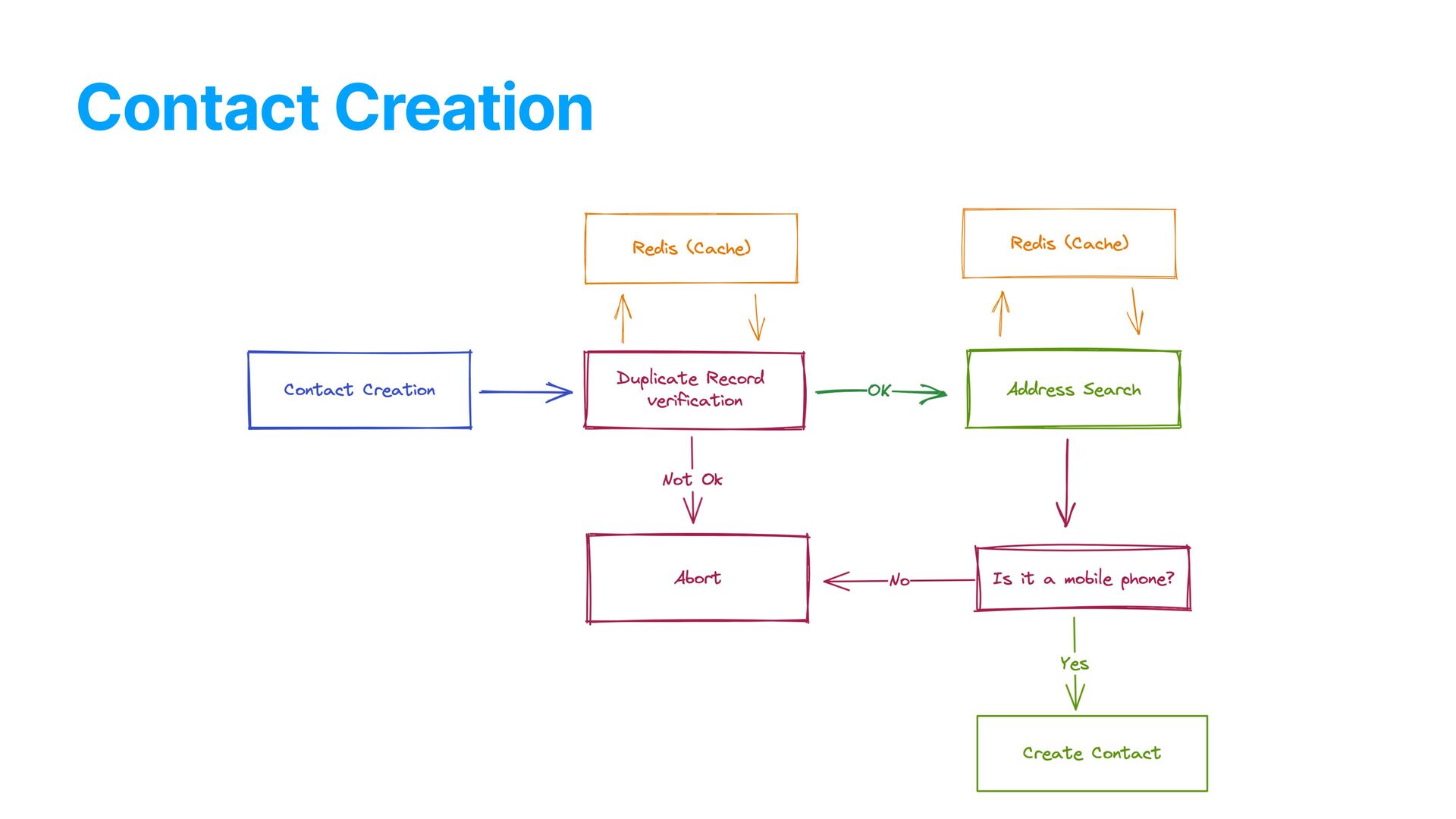
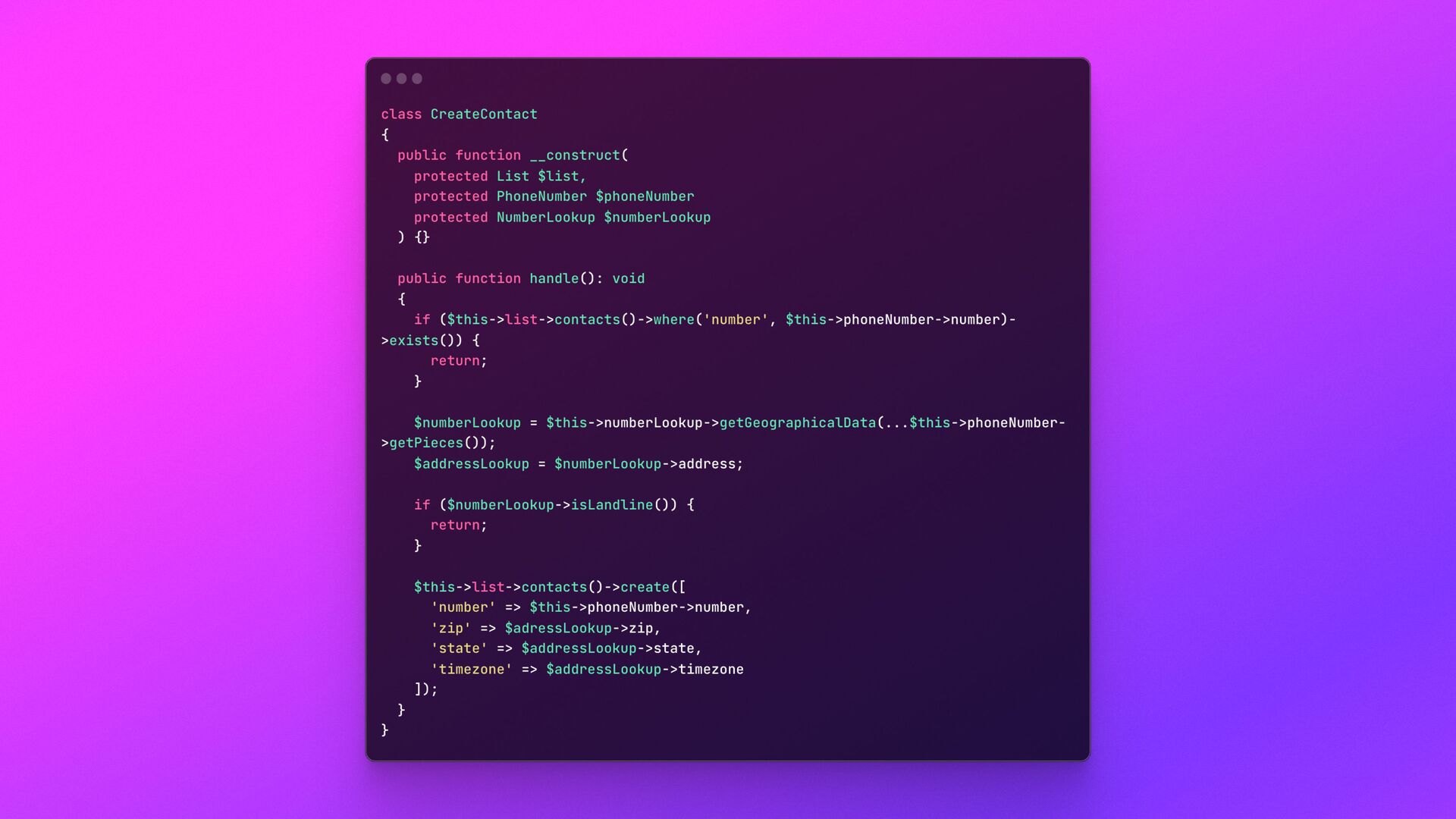
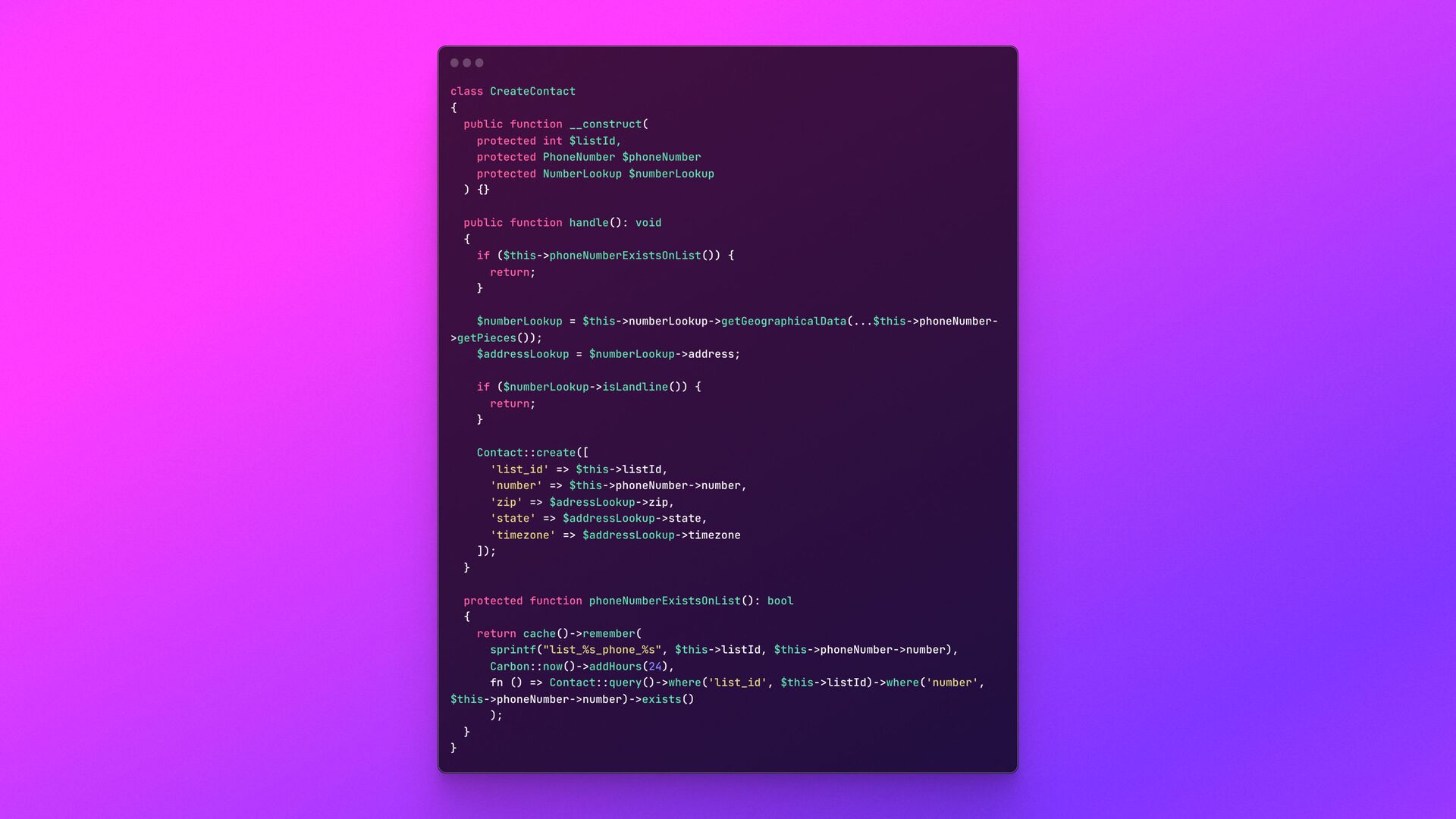
data generation through the contact’s phone number • High amount of queries to create each content • High number of contacts being created at any minute
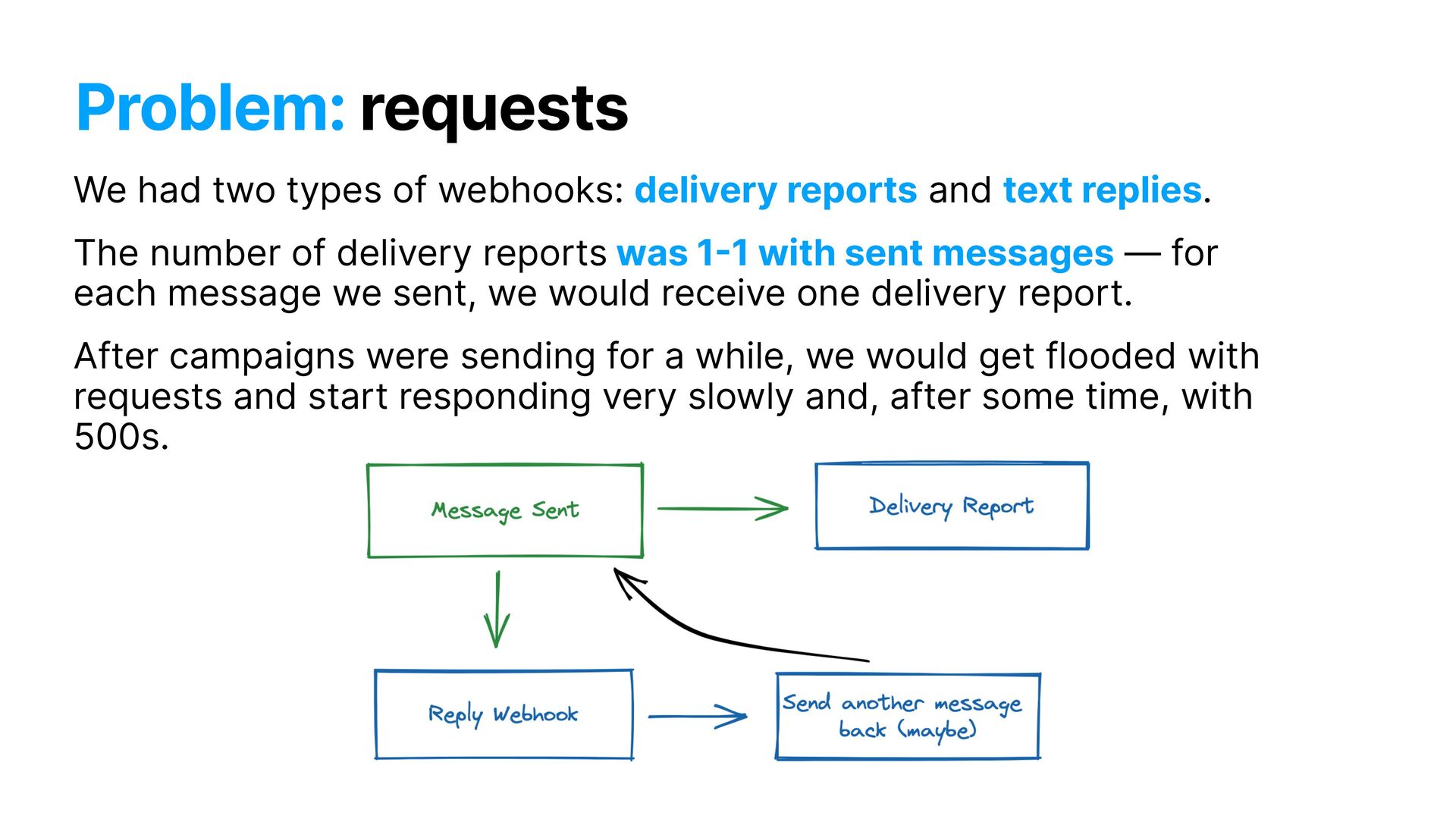
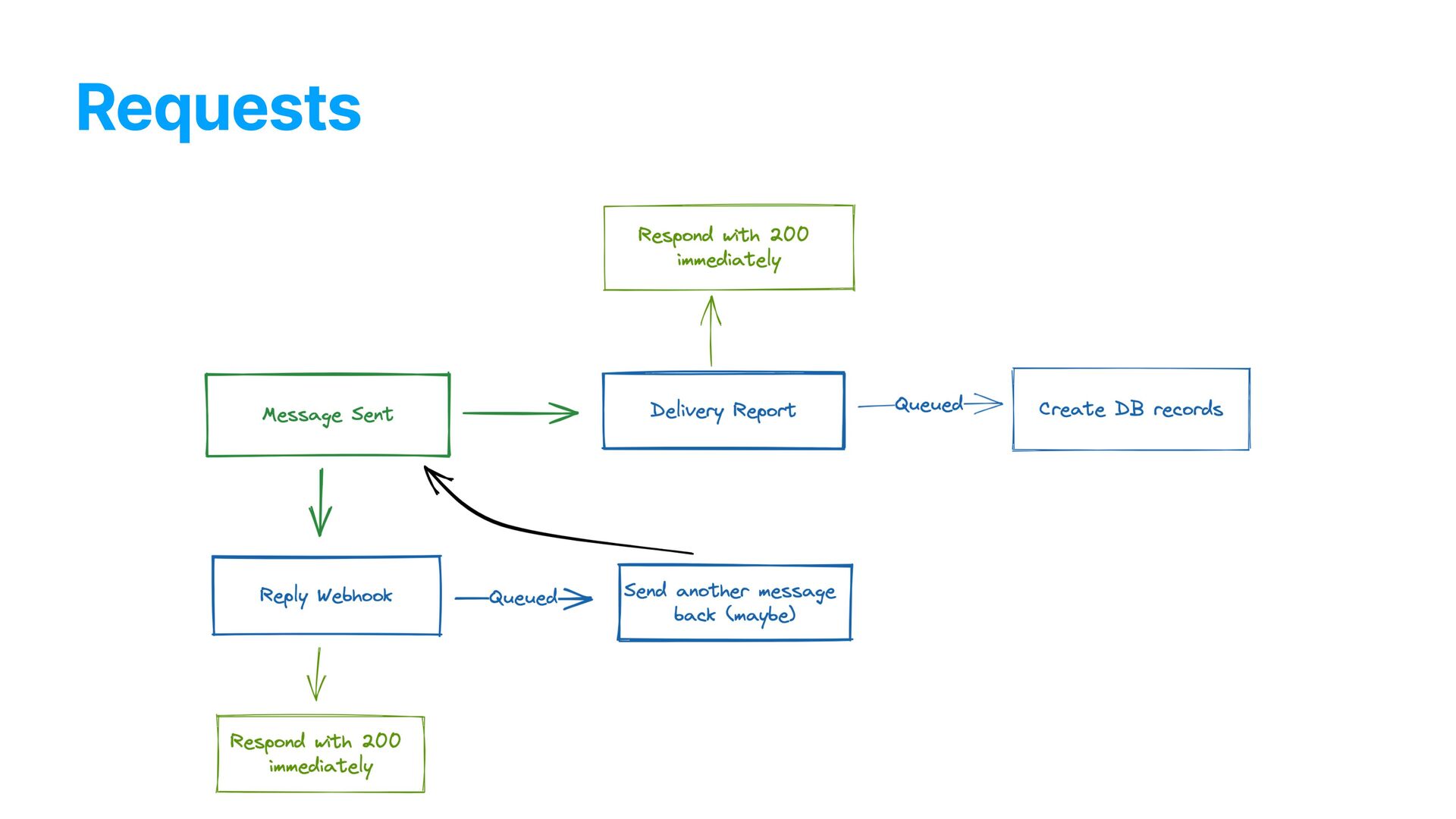
and text replies. The number of delivery reports was 1 - 1 with sent messages — for each message we sent, we would receive one delivery report. After campaigns were sending for a while, we would get flooded with requests and start responding very slowly and, after some time, with 500s.
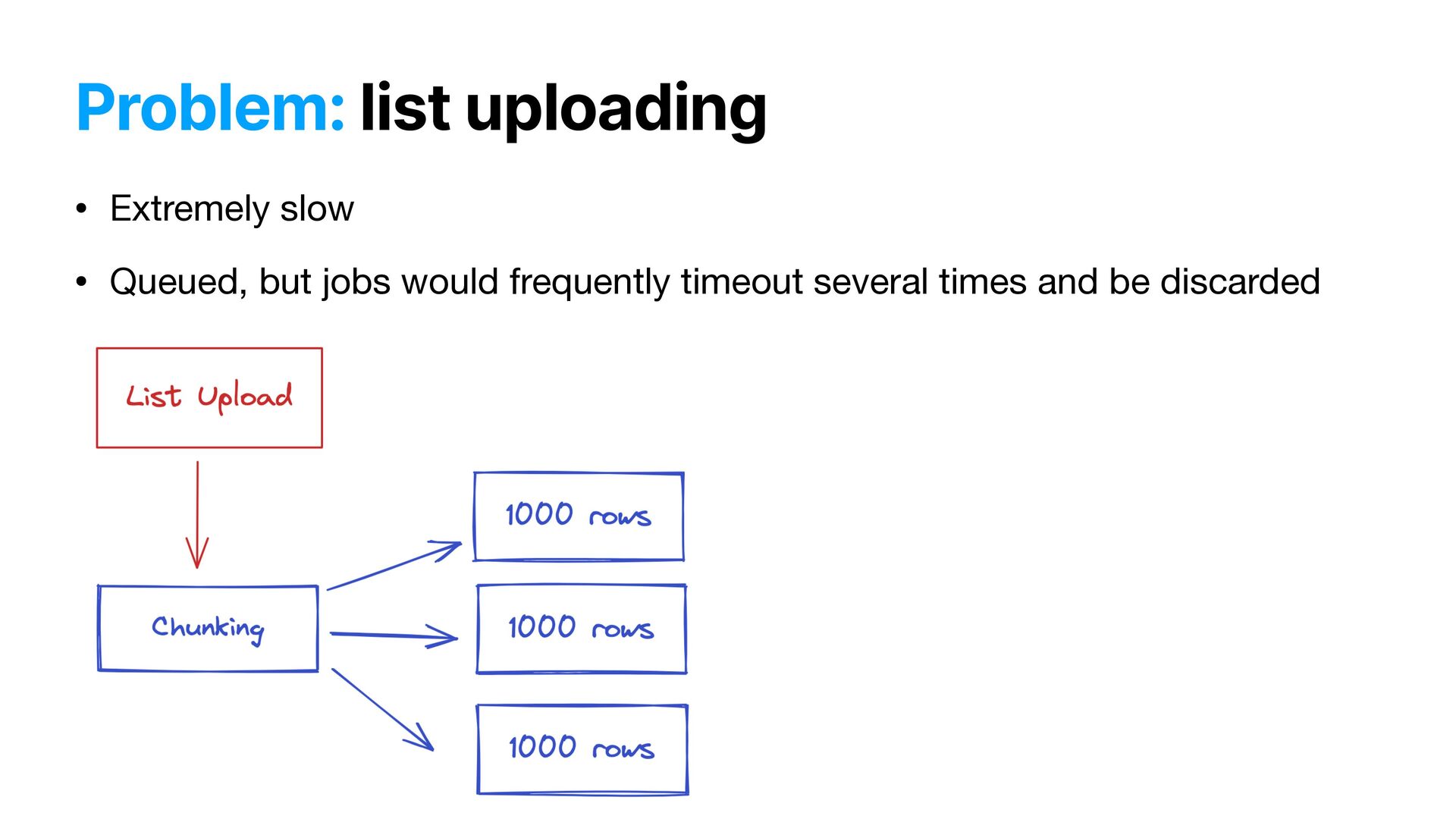
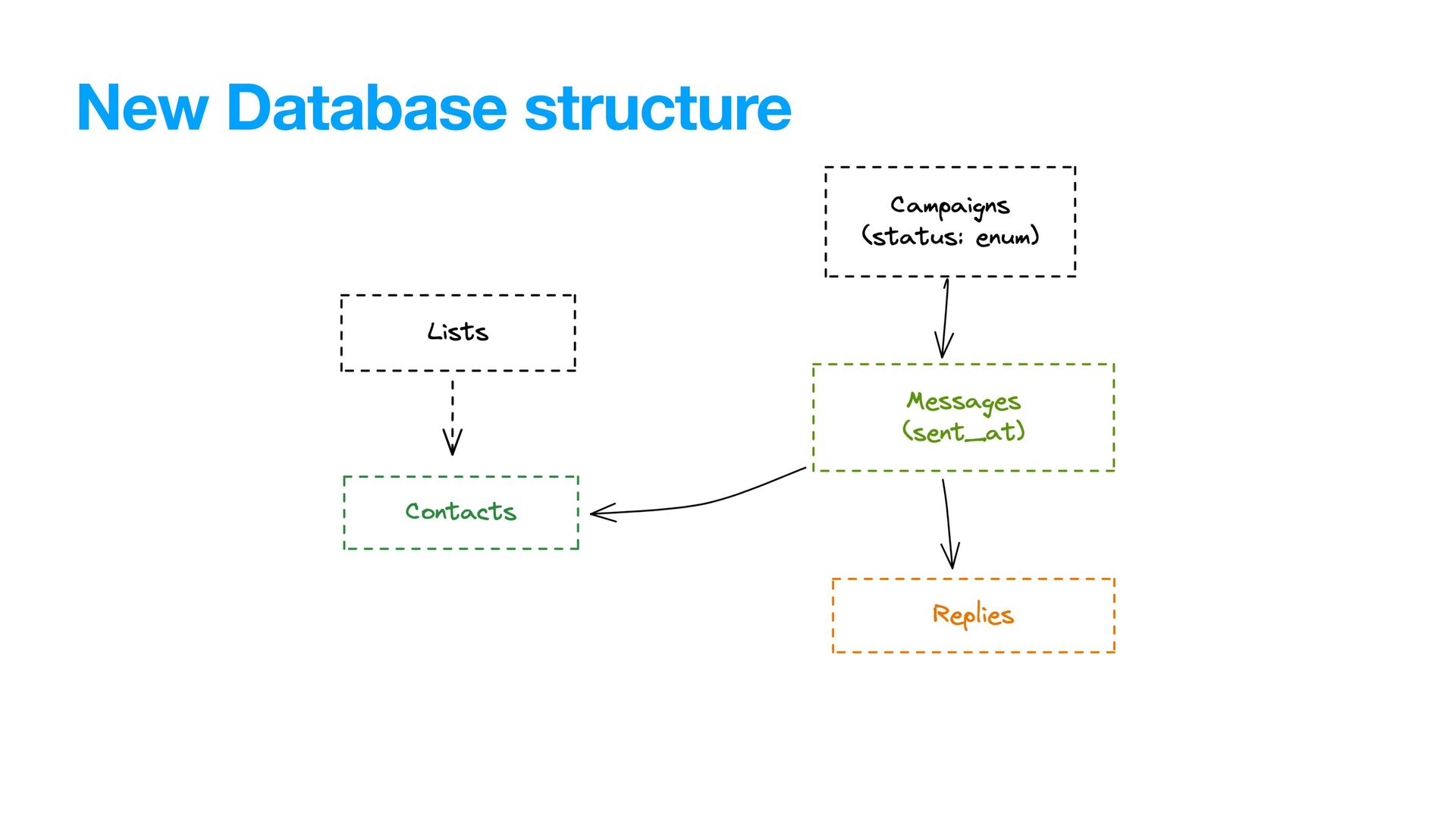
fairly large and it didn’t. The fact that pausing/resuming campaigns and sending messaged involved *moving* data between collections obviously did not help.
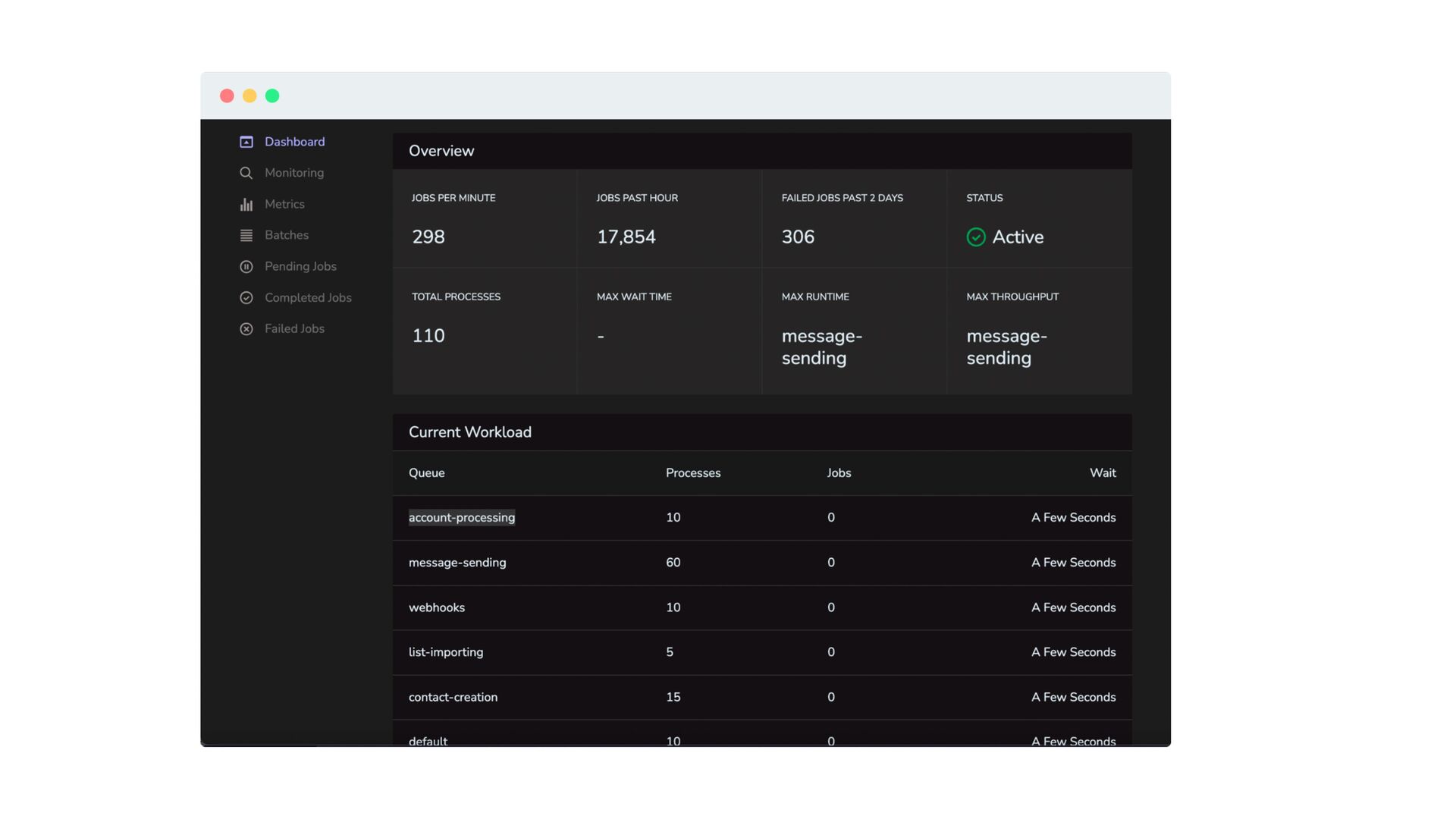
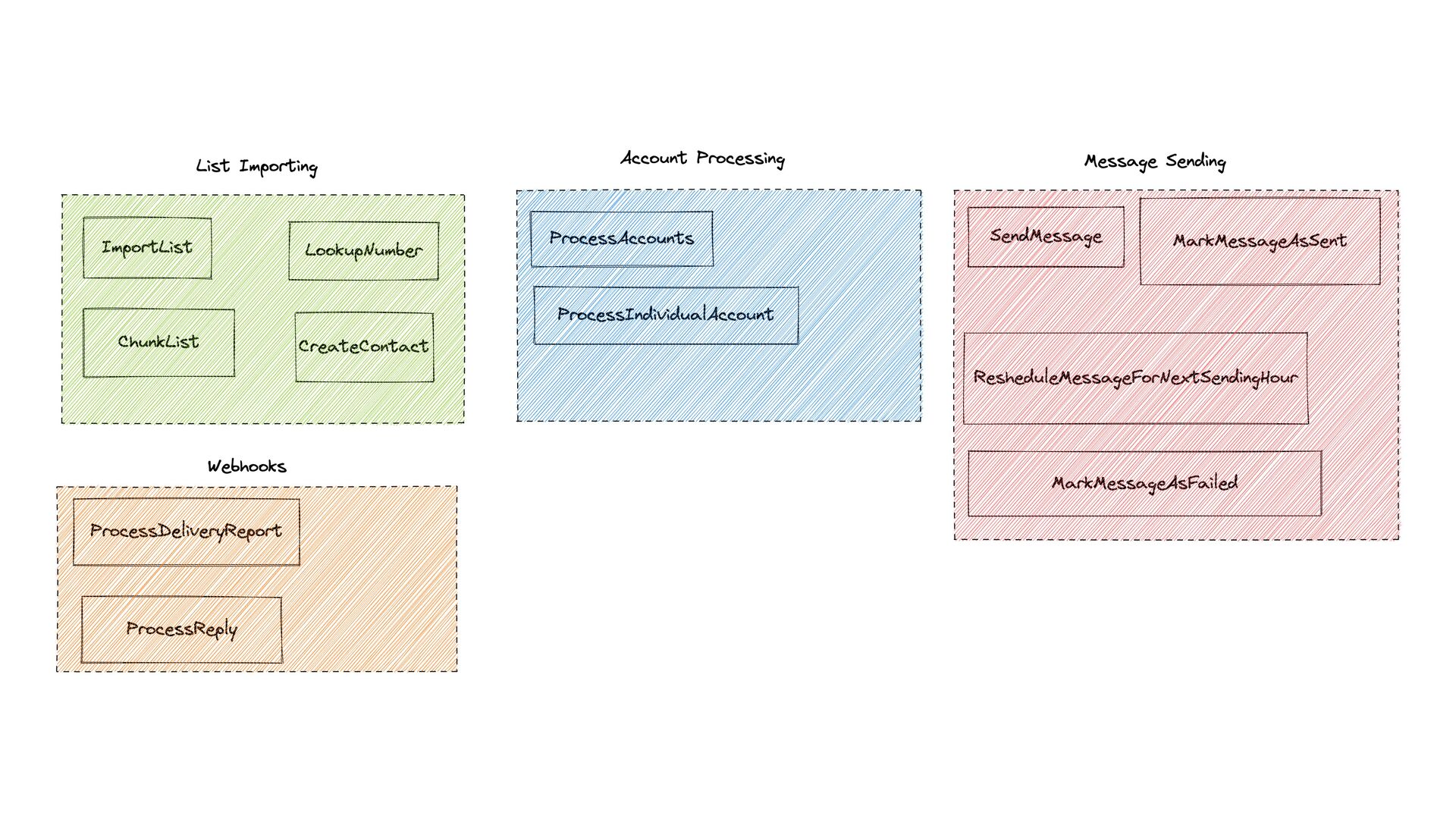
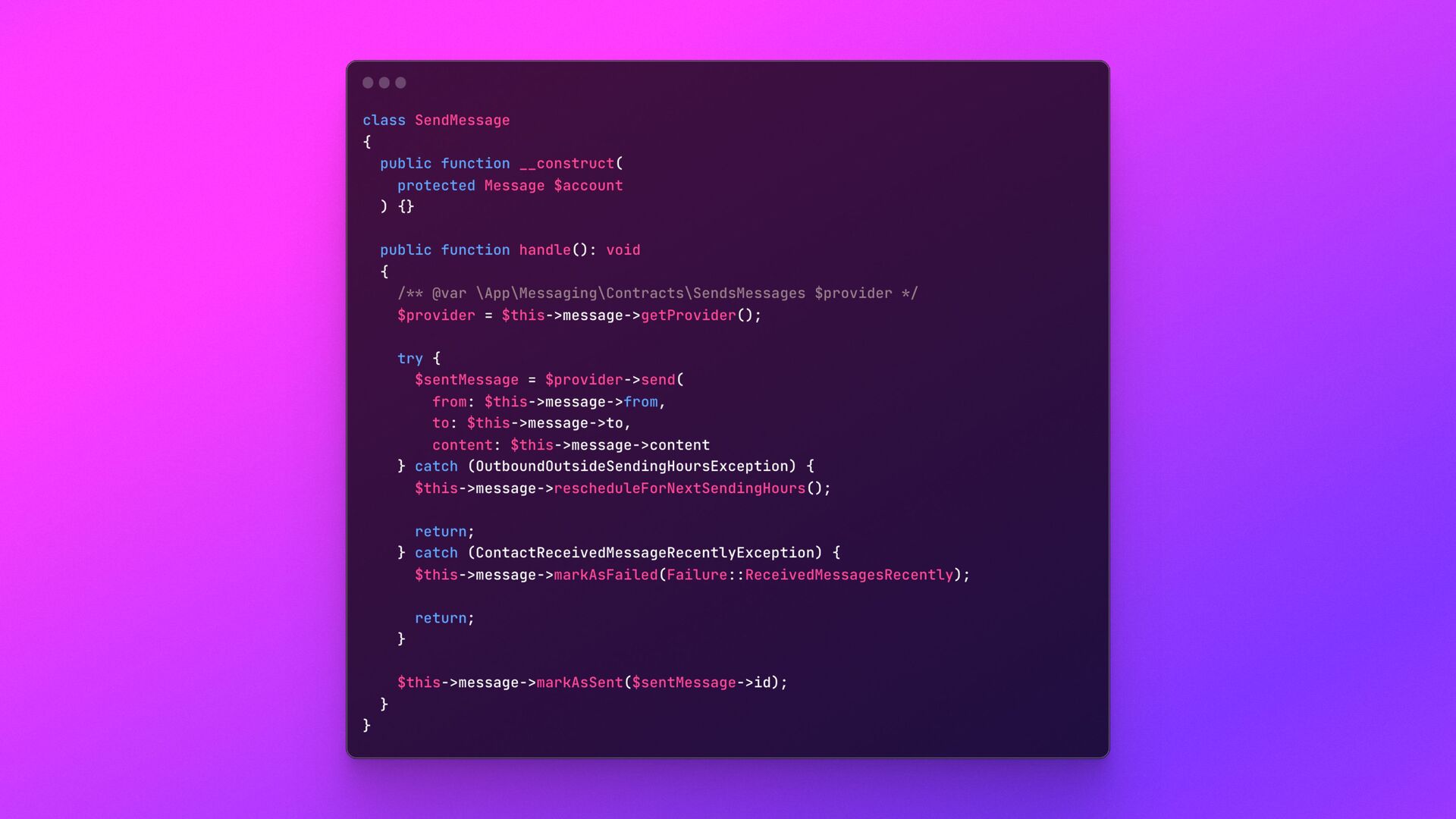
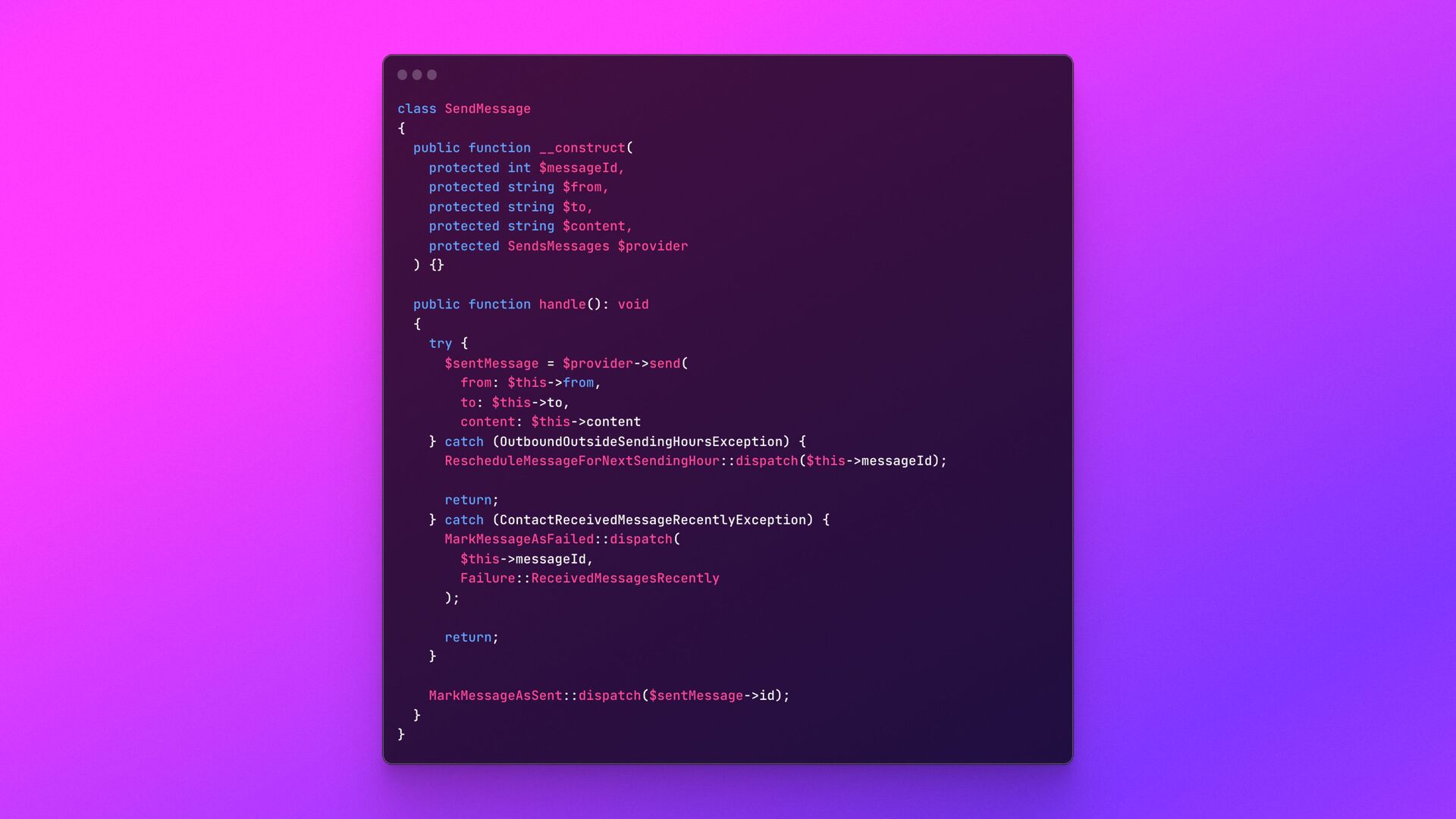
messages — did not have a UI, logs, or anything. Monitoring was very complicated. Adding new drivers was very complicated too, since code needed to be added to Laravel *and* to the Go script.
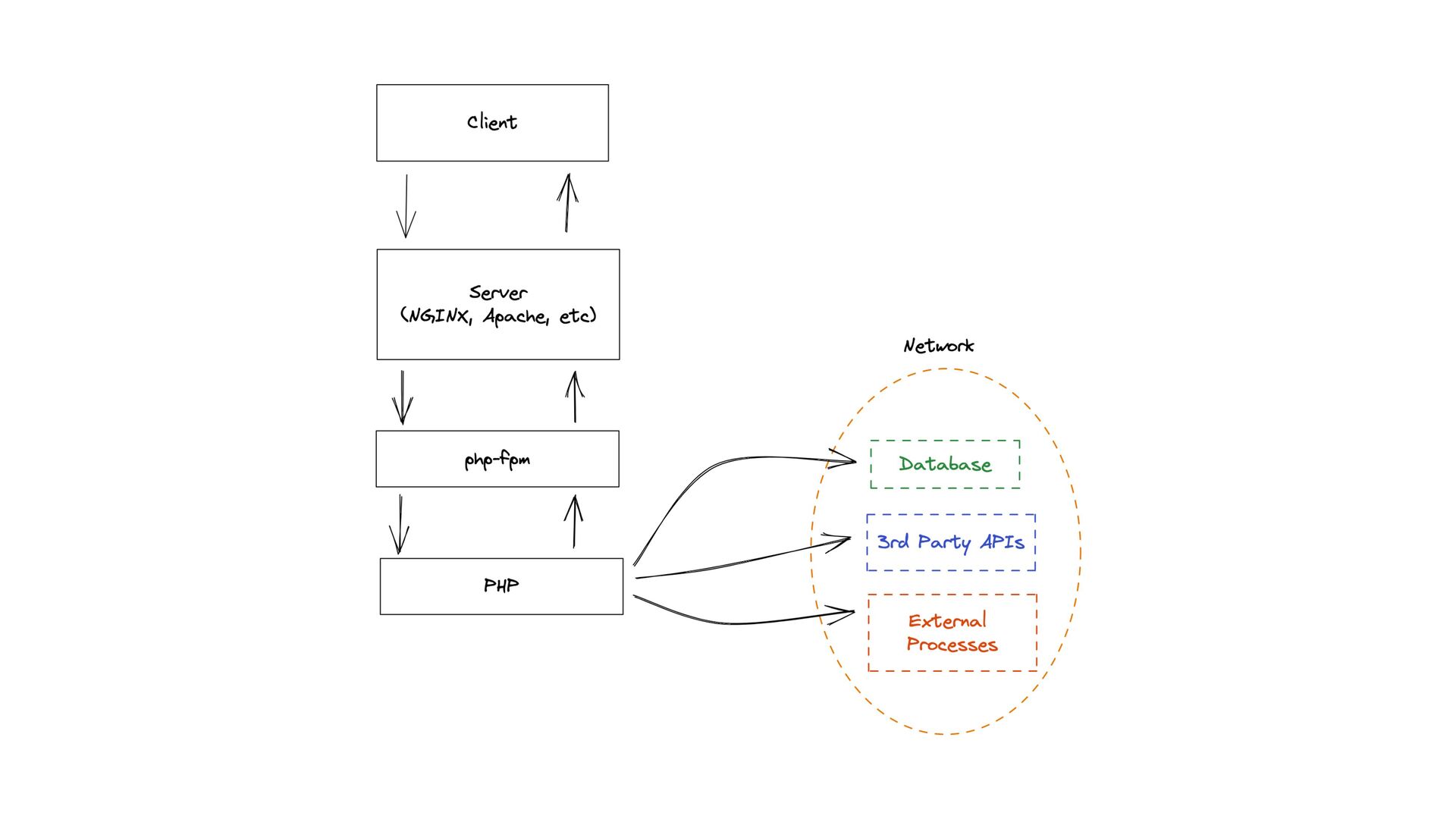
the fancy tooling and hype things and forget about the basics, sometimes optimizing things that were never a problem. • Does your database have the necessary indexes? • Does your database have the correct data types?(looking at you, VARCHAR ( 255 ) ) • Are your server and process manager ( NGINX and PHP - FPM, for example) correctly configured? • Are your queries optimized? • Do you have tools to show you where the bottleneck is? ( Observability)
in programming. They break even more often when they’re external. And even more often in high-scale environments. Accept that they *are* going to break, and instead focus on writing good countermeasures to those problems and ensuring you have good observability — that is, you can spot them as soon as they happen.
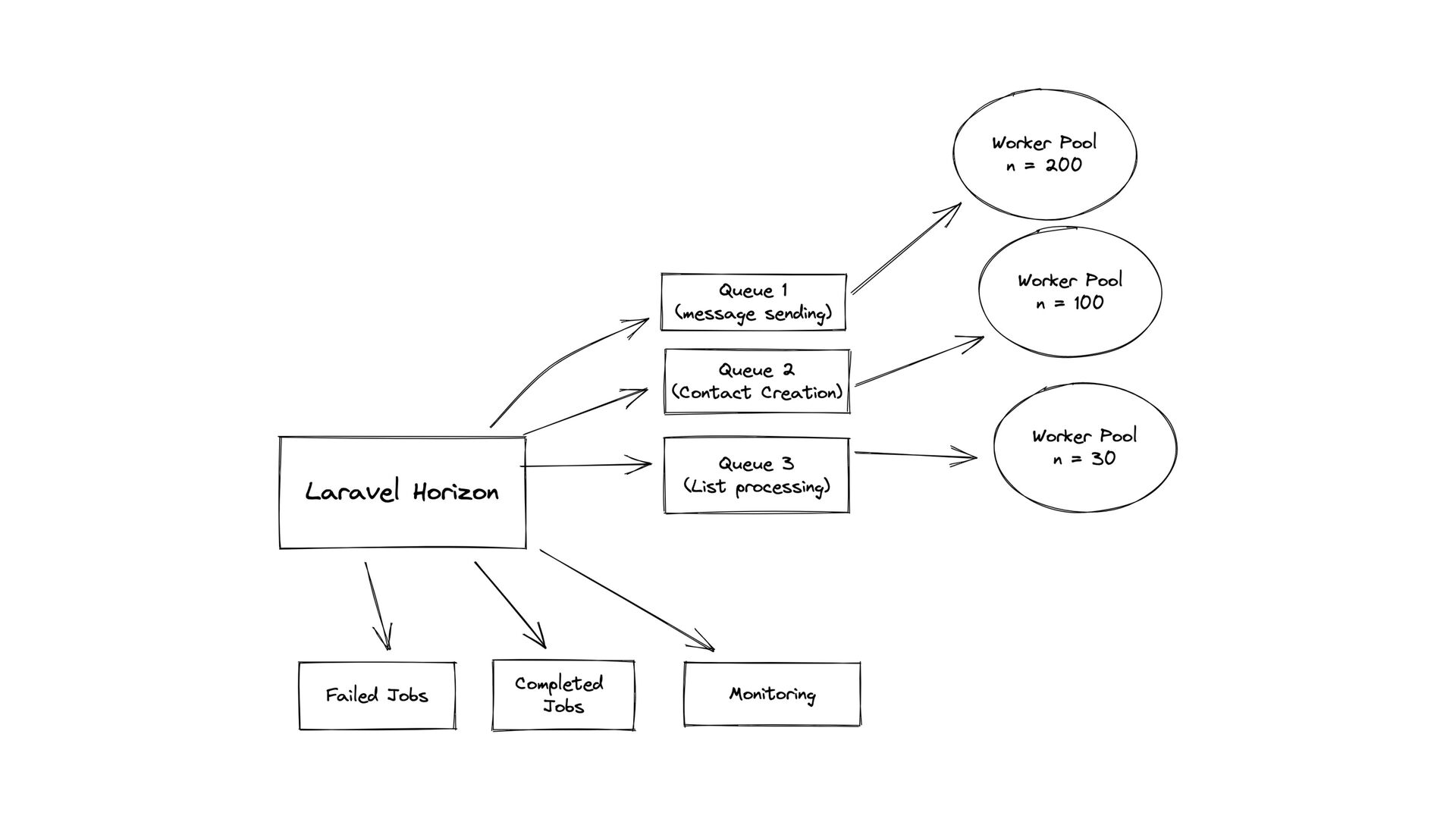
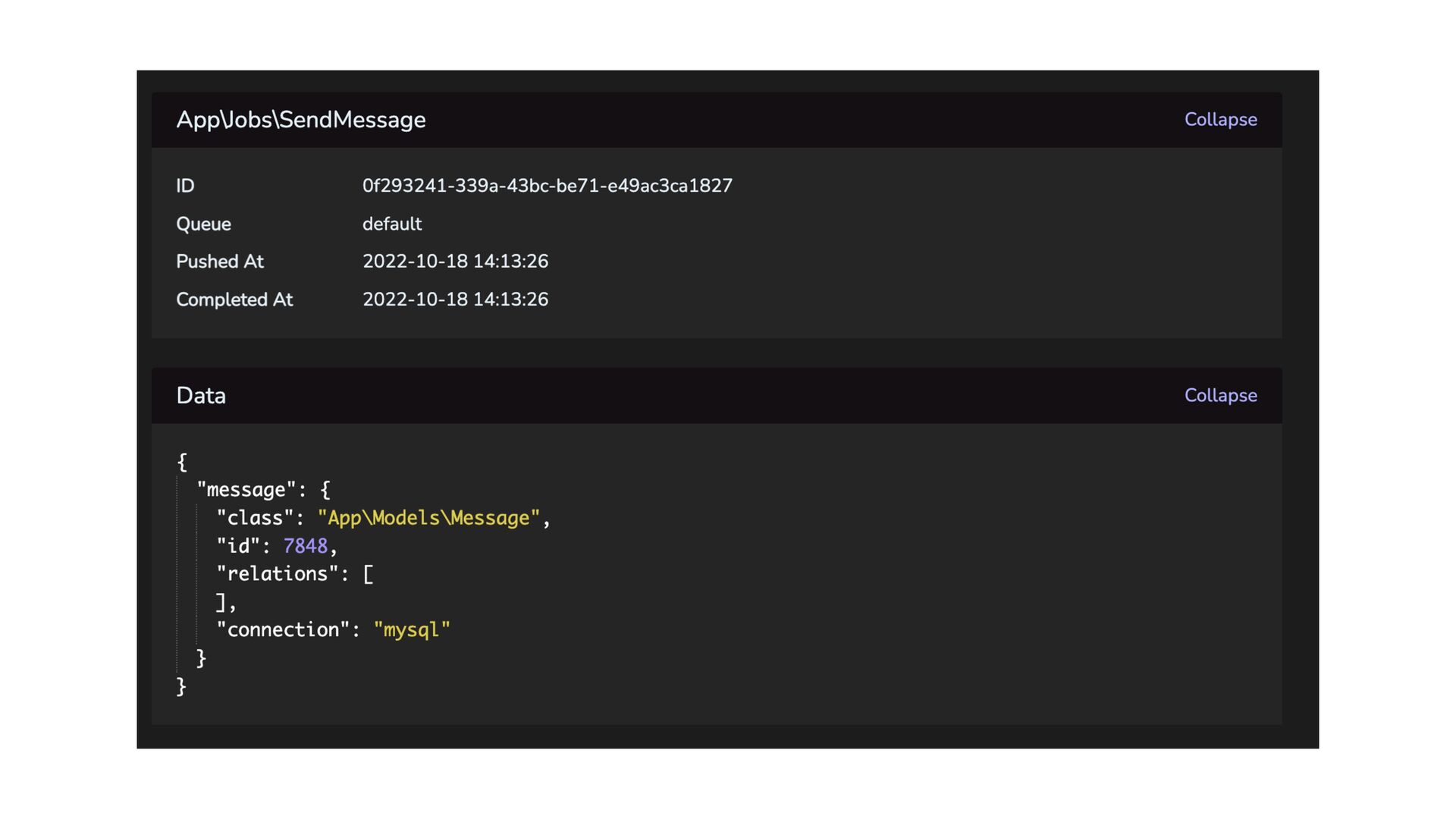
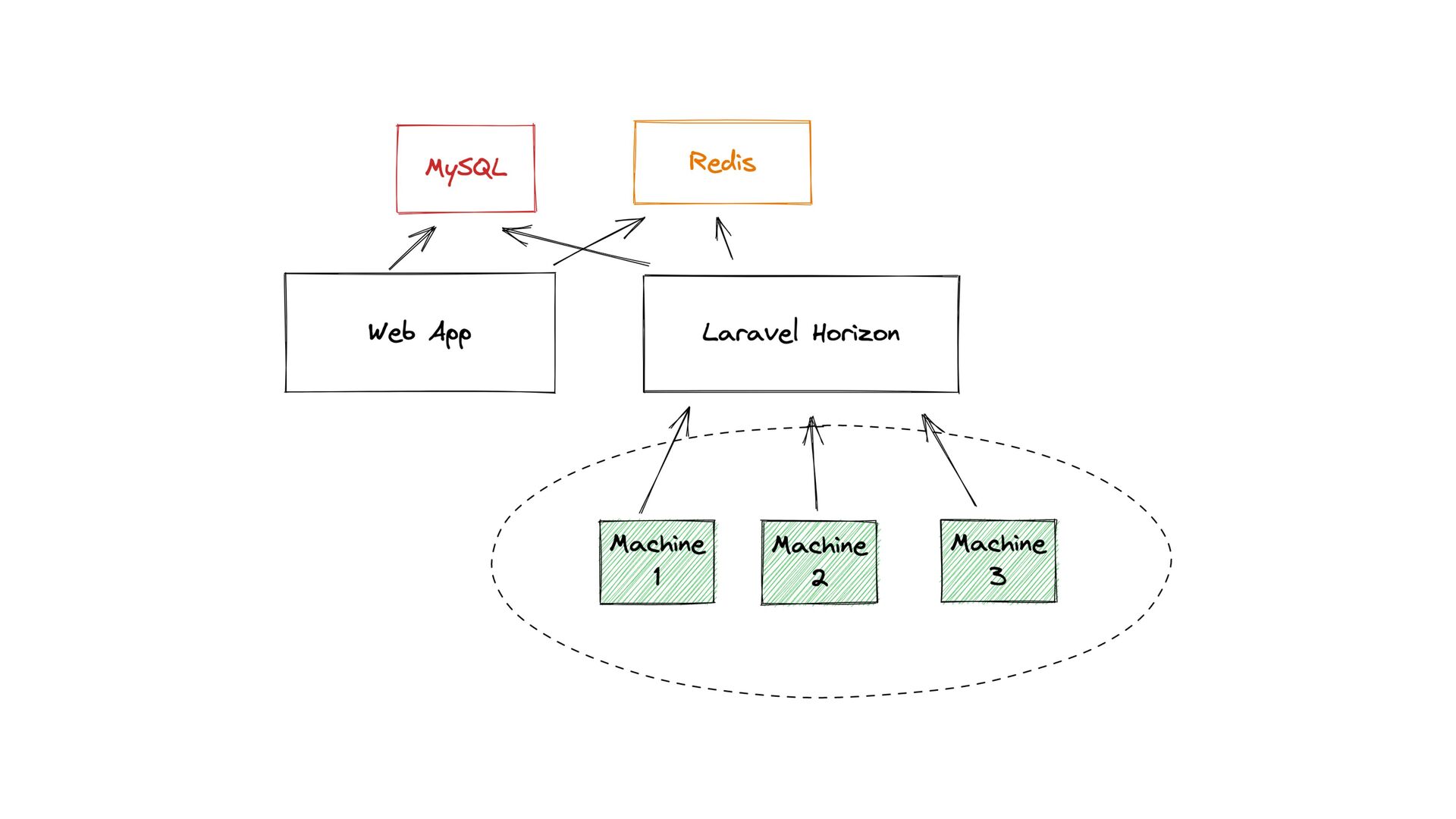
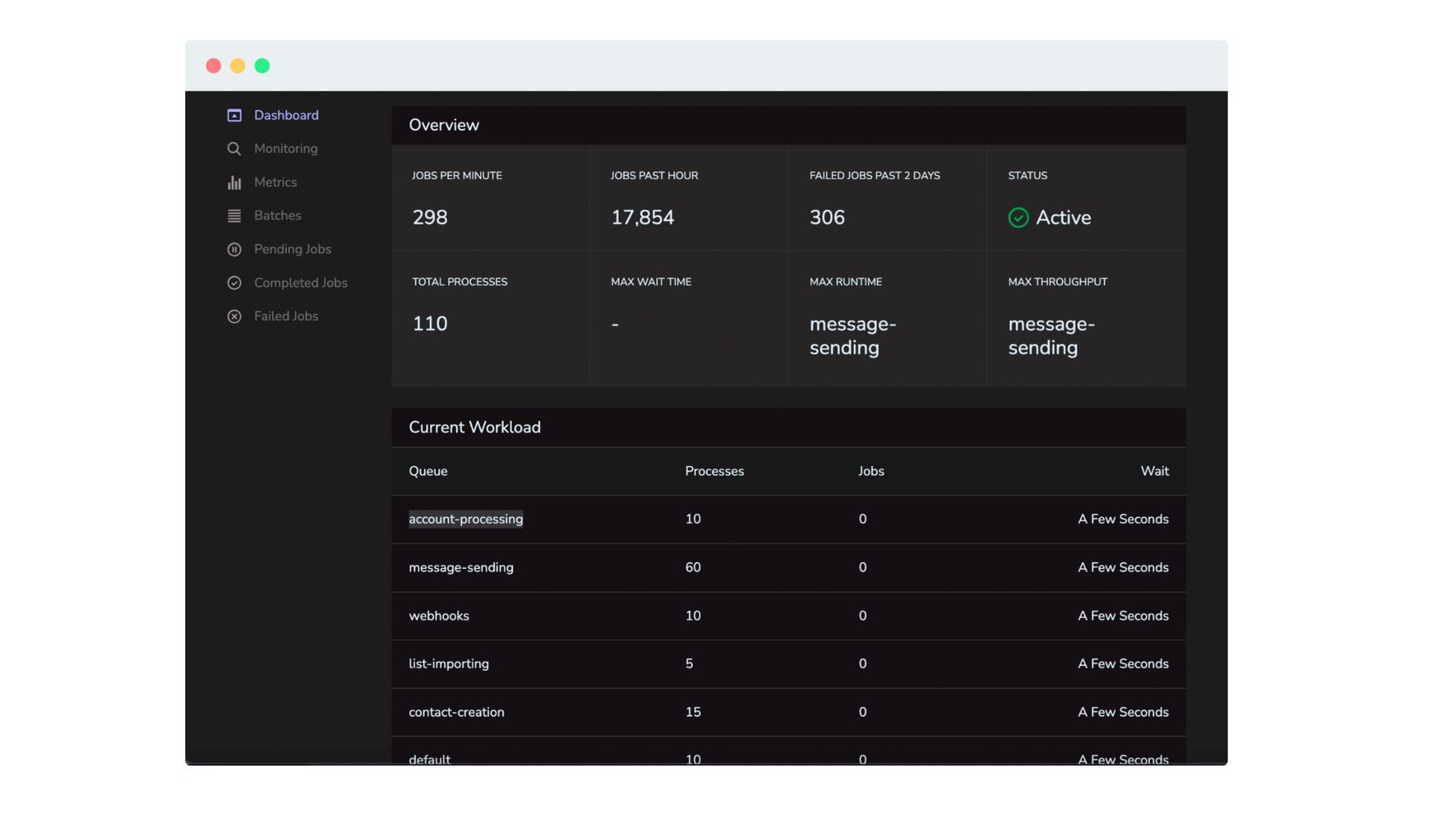
sweat • 300M+ imported contacts a day • 500M+ jobs processed in a 12h timeframe • 30,000+ requests/minute • Infrastructure cost under $1000/month • Easily horizontally scalable • Easy queue management and monitoring through Horizon • Easy to add new providers • Well-tested, easy to maintain, extend, and modify codebase
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}