a la vuelta de la esquina 410 Datanautas en el Grupo de Meetup. 329 Personas en el Grupo de Facebook. Organizadores Manuel Solorzano. Dennis Barreda. Freddy Cahuas. Edgar Marca 3
Machine Learning and natural language processing techniques are applied to big datasets to improve search, ranking and many other tasks (spam detection, ads recomendations, email categorization, machine translation, speech recognition, etc) 8
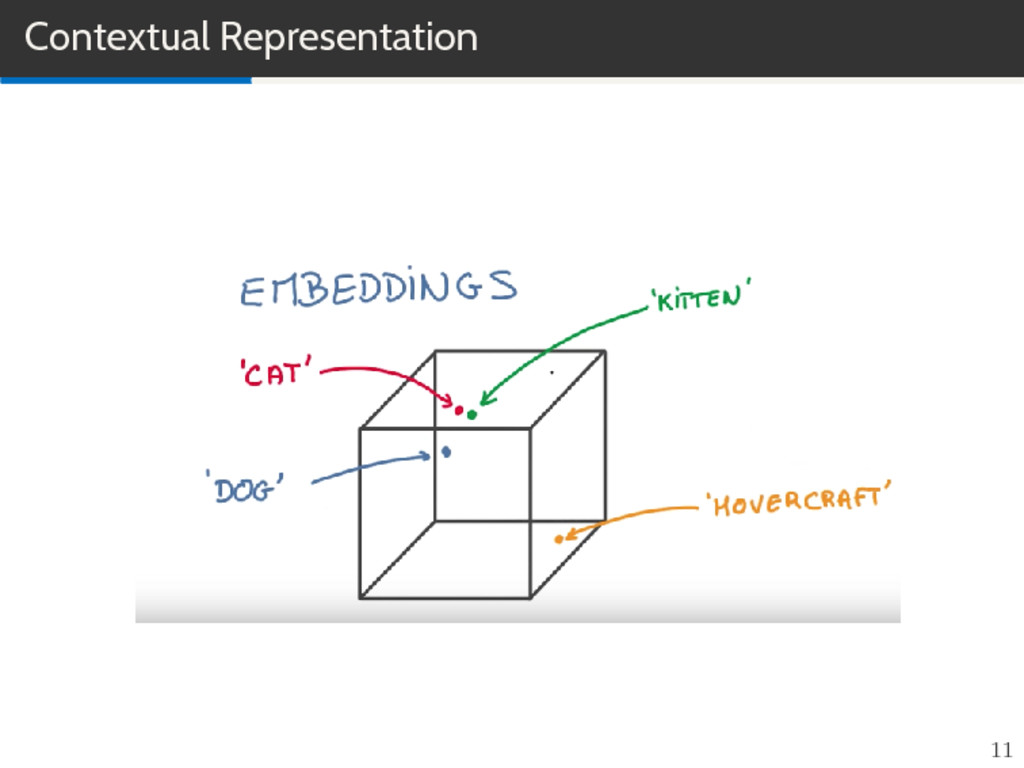
wcat⟩R4 = 0 (2) we can try to reduce the size of this space from R4 to something smaller and find a subspace that encodes the relationships between words. 15
probabilistic model that assigns probability to any sequence of n words P(w1 , w2 , . . . , wn) Unigrams Assuming that the word ocurrences are completely independent P(w1 , w2 , . . . , wn) = Πn i=1 P(wi) (3) 19
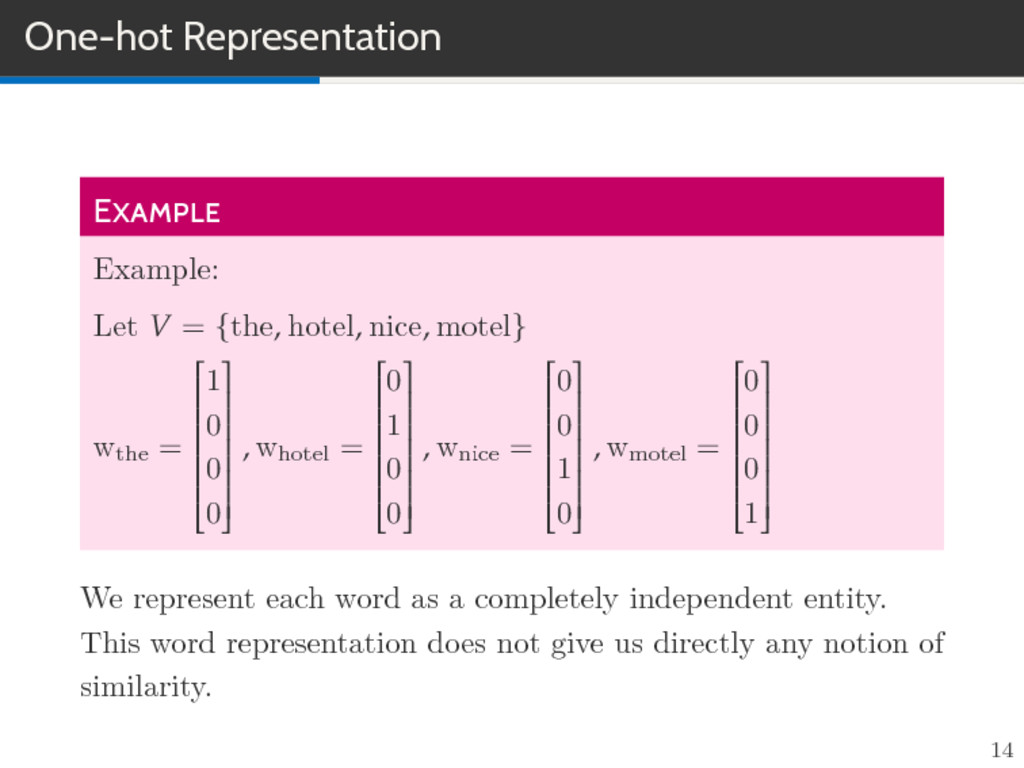
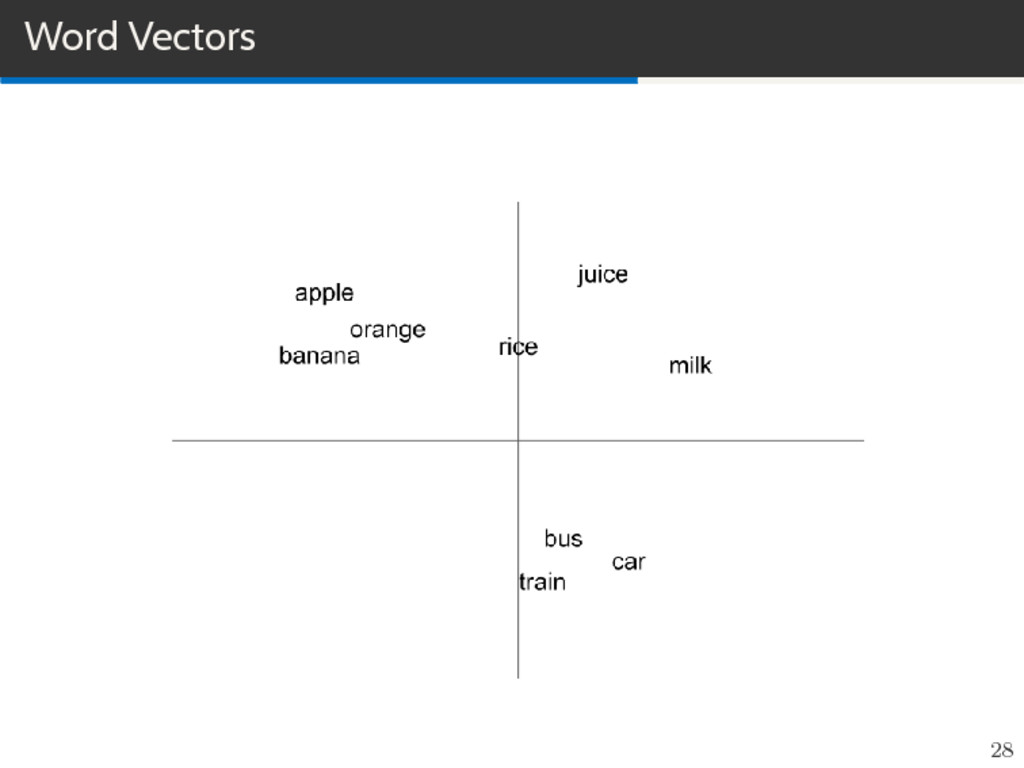
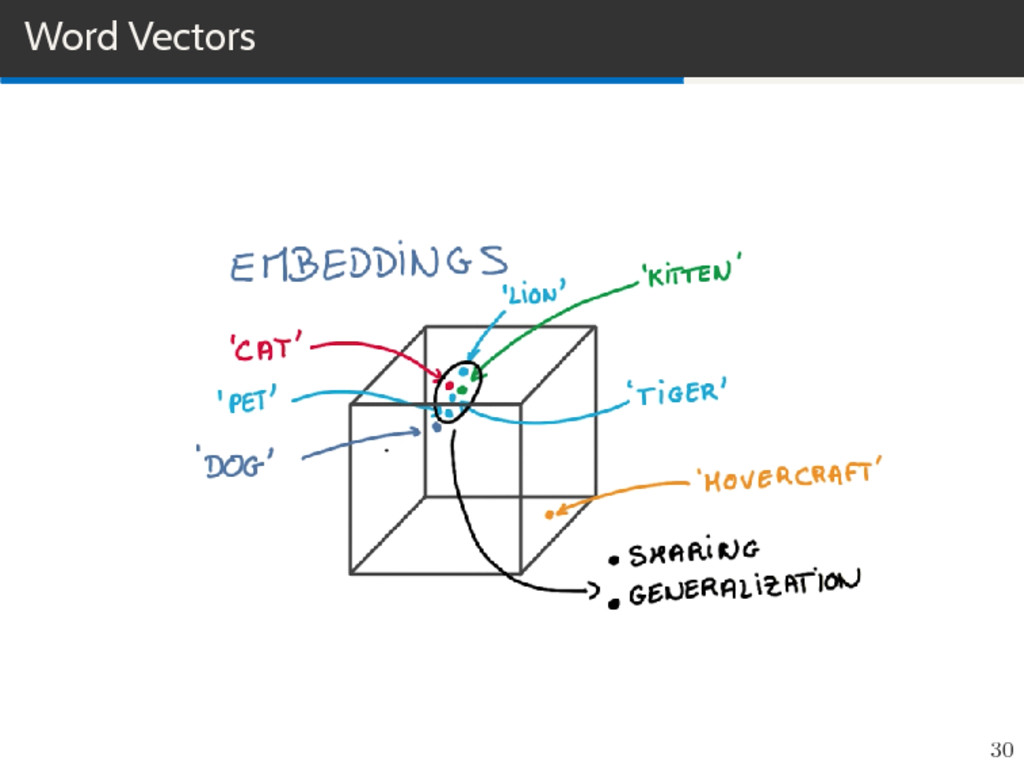
feature learning techniques in NLP where words or phrases from the vocabulary are mapped to vectors of real numbers in a low-dimensional space relative to the vocabulary size (”continuous space”). Vector space models (VSMs) represent (embed) words in a continous vector space. Semantically similar words are mapped to nearby points. Basic idea is Distributional Hypothesis: words that appear in the same context share semantic meaning. 21
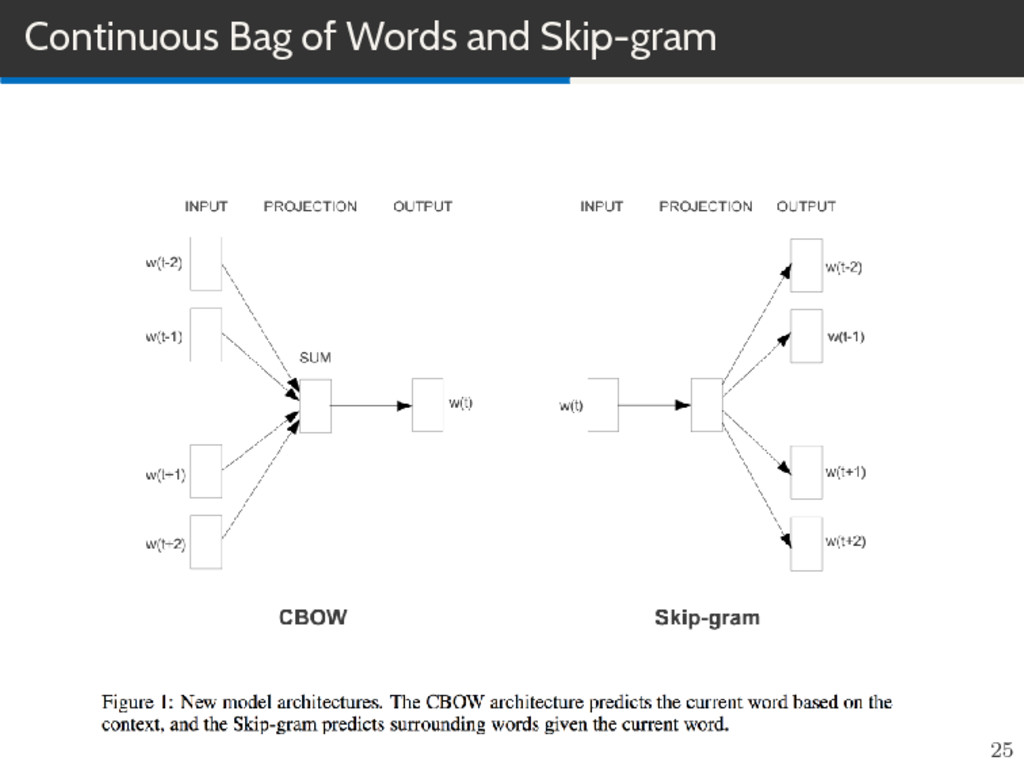
by Mikolov et al. (2013) Efficient Estimation of Word Representations in Vector Space https://arxiv.org/abs/1301.3781. Distributed Representations of Words and Phrases and their Compositionality https://arxiv.org/abs/1310.4546. 24
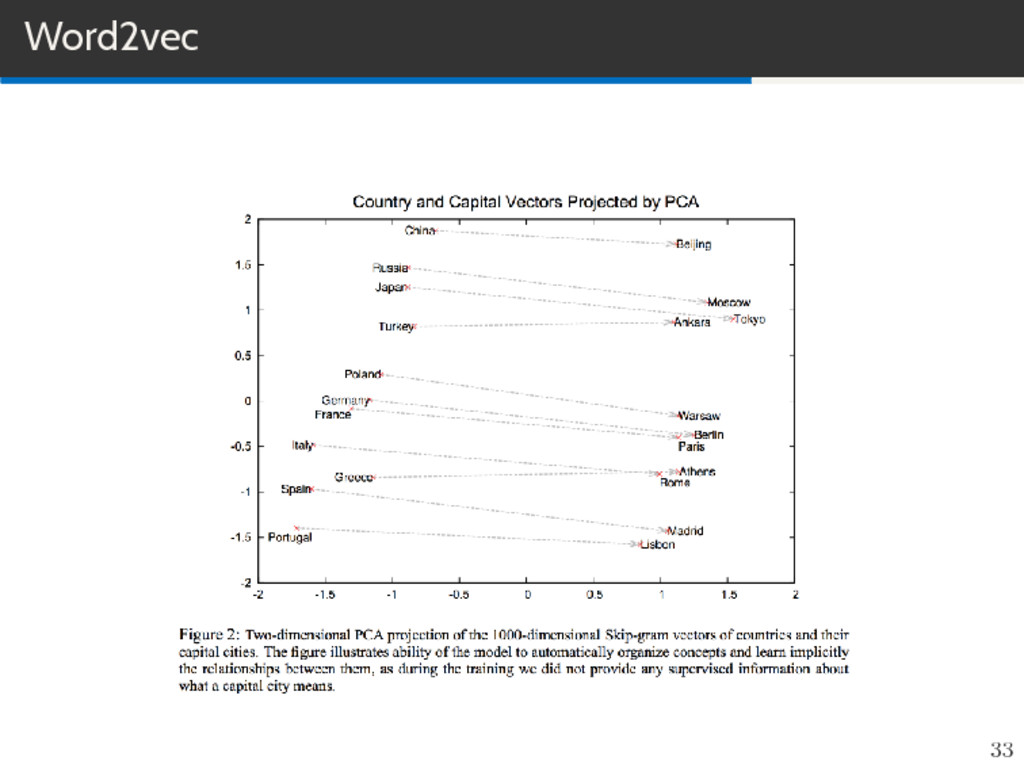
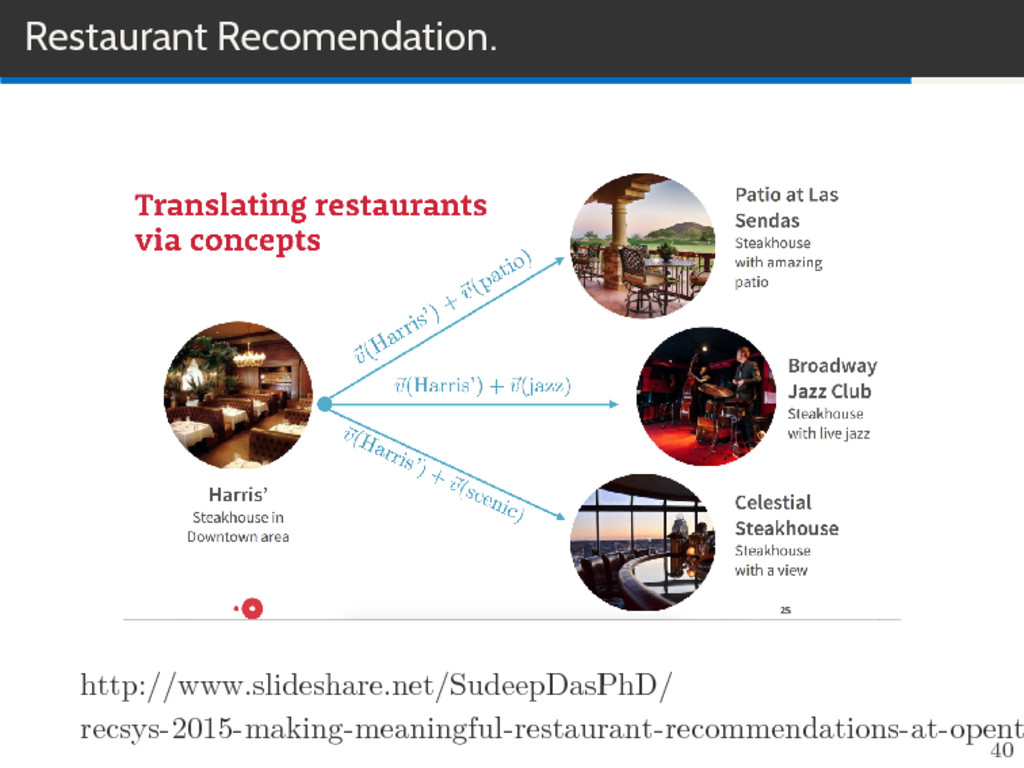
vfrance + vitaly ≈ vrome Learns from raw text Huge splash in NLP world. Comes pretrained. (If you don’t have any specialize vocabulary) Word2vec is computationally efficient model for learning word embeddings. Word2Vec is a successful example of ”shallow” learning. Very simple Feedforward neural network with single hidden layer, backpropagation, and no non-linearities. 32
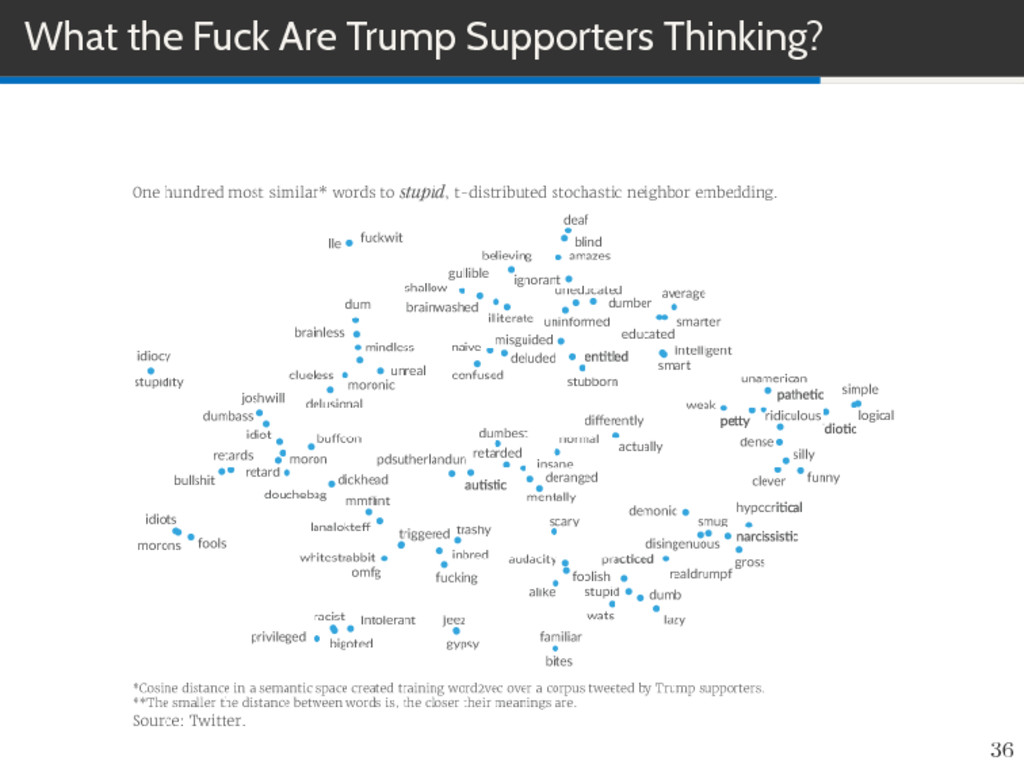
million tweets belonging to more than two thousand hard-core Trump supporters. Distances between those vectors encoded the semantic distance between their associated words (e.g. the vector representation of the word morons was near idiots but far away from funny) Link: https://medium.com/adventurous-social-science/ what-the-fuck-are-trump-supporters-thinking-ecc16fb66a8d 38
![WORD2VEC FROM INTUITION TO PRACTICE USING GENSIM Edgar Marca [email protected]](https://files.speakerdeck.com/presentations/d36bc21dc7ce4a59a4b79f878a5641fa/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}